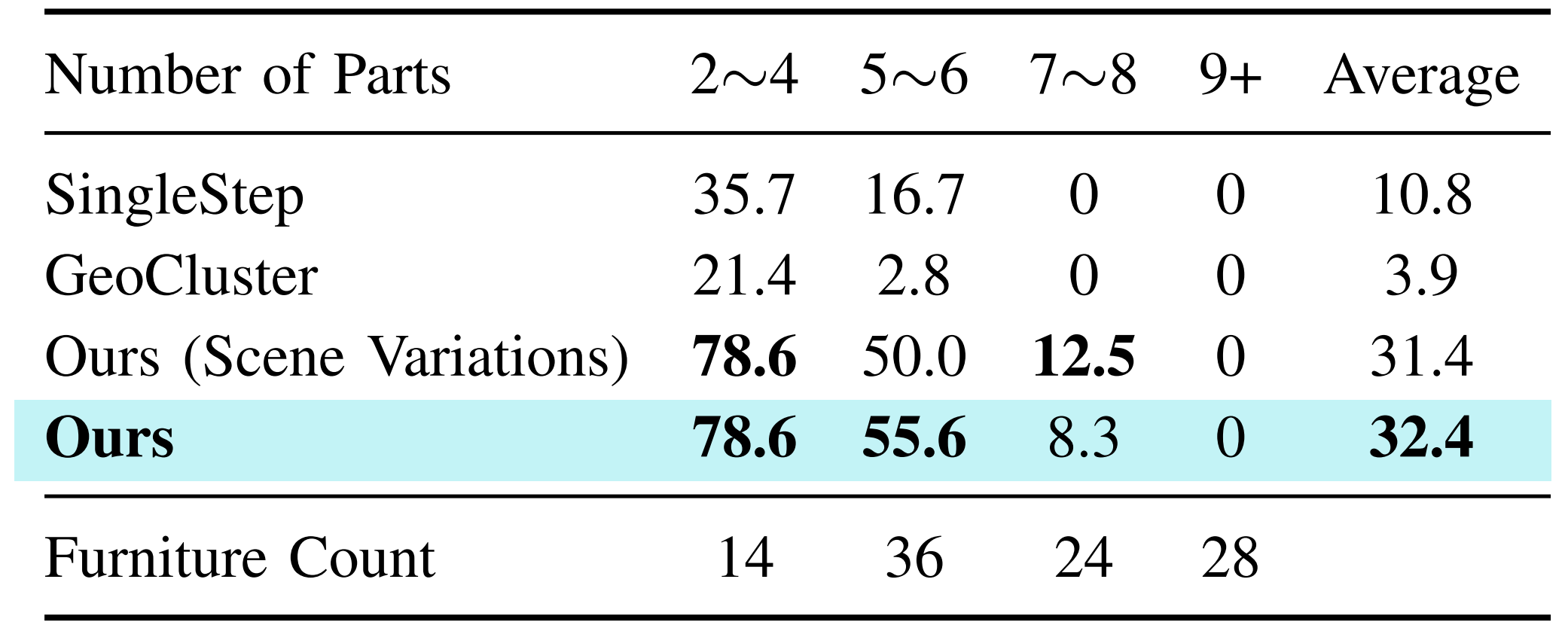
相比之下,机器人通常通过
模仿学习*59-A survey of imitation learning: Algorithms, recent developments, and challenges*
或强化学习*43-Deep reinforcement learning for robotics: A survey of realworld successes*
来学习此类技能,这两种方法都需要显著更多的数据和计算资源
故让机器人能够像人类一样将抽象的操作手册转化为现实世界的动作,仍然是一个重大挑战。毕竟手册通常是为人类理解而设计,采用简单的示意图和符号来传达操作过程
总之,这种抽象性使得机器人难以理解这些说明,并从中推导出可执行的操作策略 32-Ikea manuals at work: 4d grounding of assembly instructions on internet videos,2024
49-Ikea-manual: Seeing shape assembly step by step,2022
48-Translating a visual lego manual to a machine-executable plan
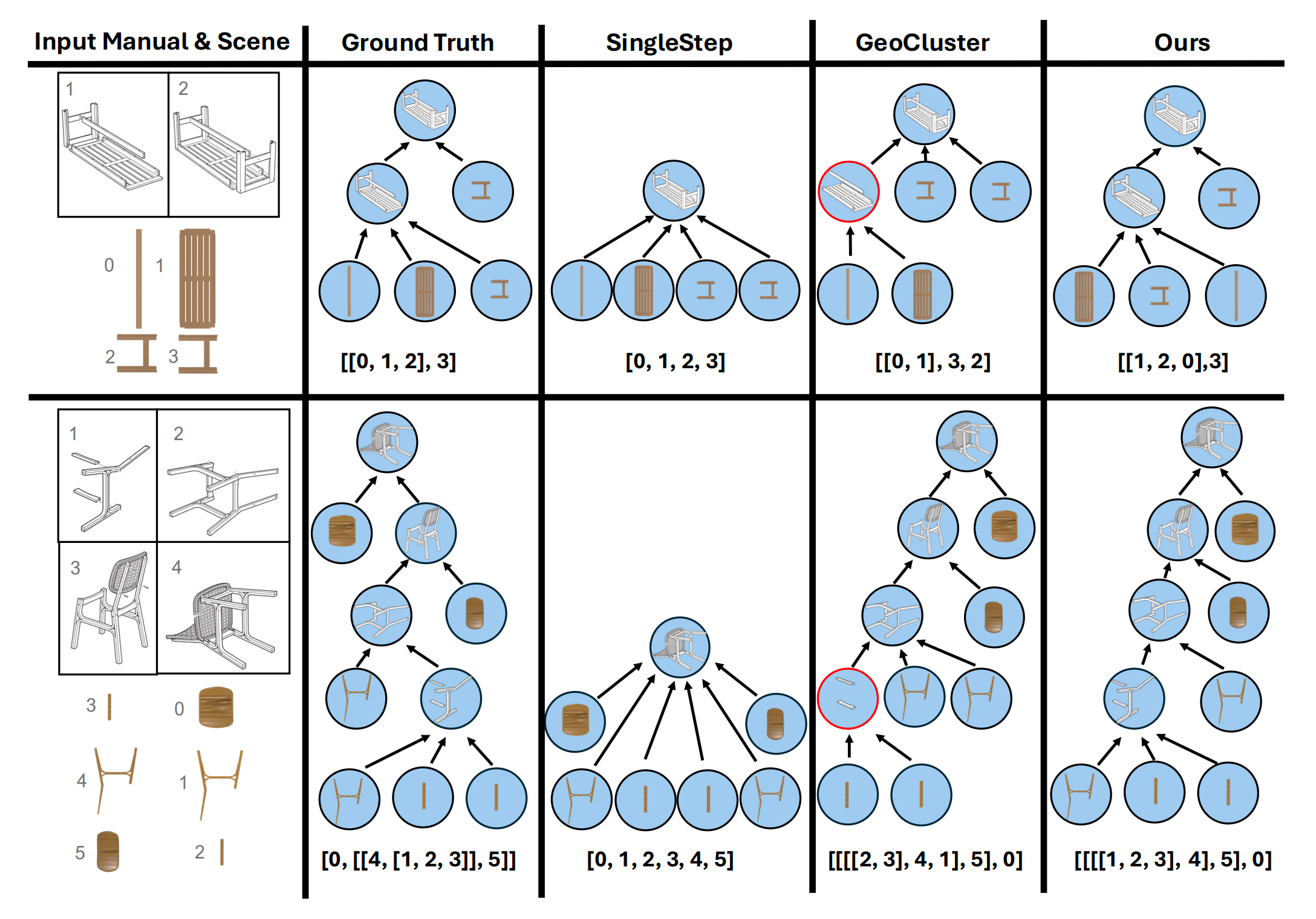
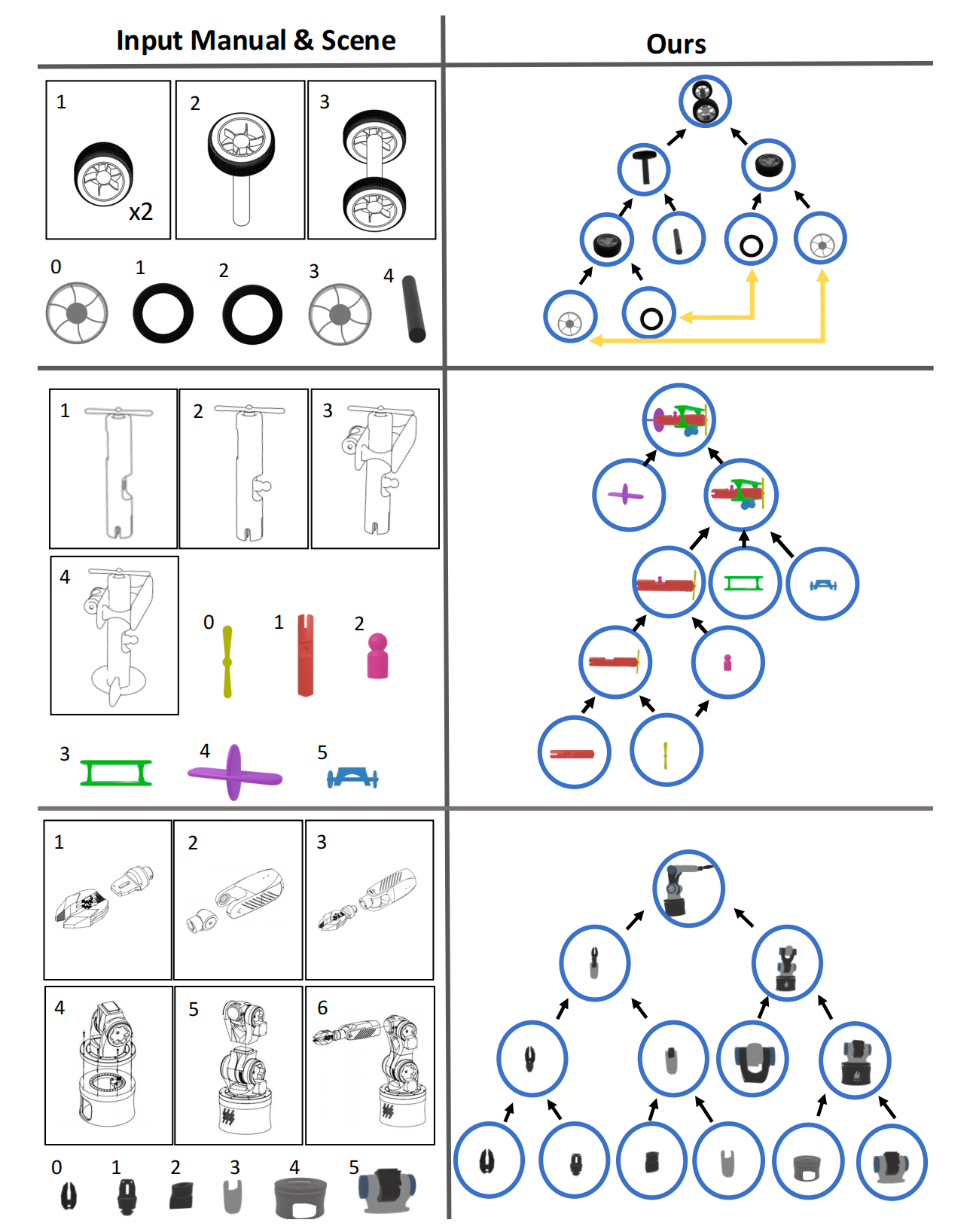
它们将高层目标分解为中层子目标,并捕捉任务流程及其依赖关系,例如顺序步骤或可并行的子任务。例如,家具组装手册指导组件的准备与组合,并确保所有步骤按照正确顺序进行32-*Ikea manuals at work*
提取这种结构对于机器人复制类似人类的理解并有效管理复杂任务至关重要
19-Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation
33-Structurenet: Hierarchical graph networks for 3d shape generation
在完成任务分解后,机器人需要推断每一步的具体信息,如涉及的组件及其空间关系。例如,在烹饪任务中,说明图片和文本可能涉及选择食材、工具和器皿,并按特定顺序进行排列*38-Robocook: Long-horizon elasto-plastic object manipulation with diverse tools*
最后,机器人需要生成一系列动作来完成任务,如抓取、放置和连接组件
以往的研究尝试
利用草图图片*42-Rt-sketch: Goal-conditioned imitation learning from hand-drawn sketches*
或轨迹*15-Rt-trajectory: Robotic task generalization via hindsight trajectory sketches*
来学习操作技能,但这些方法总是局限于相对简单的台面任务
6-Neural shape mating: Self-supervised object assembly with adversarial shape priors
13-Learning how to match fresco fragments
20-Automate: A dataset and learning approach for automatic mating of cad assemblies
27-Ikea furniture assembly environment for long-horizon complex manipulation tasks
29-Learning 3d part assembly from a single image
36-Diffassemble: A unified graph-diffusion model for 2d and 3d reassembly
53-Leveraging se (3) equivariance for learning 3d geometric shape assembly
46-Asap: Automated sequence planning for complex robotic assembly with physical feasibility
45-Assemble them all: Physics-based planning for generalizable assembly by disassembly
总体而言,可以将零件装配分为几何装配和语义装配两类
几何装配仅依赖于几何线索,例如表面形状或边缘特征,来判断部件如何装配在一起 6-Neural shape mating: Self-supervised object assembly with adversarial shape priors
53-Leveraging se (3) equivariance for learning 3d geometric shape assembly
37-Breaking bad: A dataset for geometric fracture and reassembly
10-Generative 3d part assembly via part-whole-hierarchy message passing
相比之下,语义装配主要利用关于部件的高级语义信息来引导装配过程 13-Learning how to match fresco fragments
20-Automate: A dataset and learning approach for automatic mating of cad assemblies
27-Ikea furniture assembly environment for long-horizon complex manipulation tasks
29-Learning 3d part assembly from a single image
45-Assemble them all: Physics-based planning for generalizable assembly by disassembly
以往关于家具组装的研究主要针对该问题的不同方面,包括运动规划
41-Can robots assemble an ikea chair?
多机器人协作
25-Ikeabot: An autonomous multi-robot coordinated furniture assembly system
以及组装姿态估计
29-Learning 3d part assembly from a single image
58-Roboassembly: Learning generalizable furniture assembly policy in a novel multi-robot contact-rich simulation environment
30-Category-level multi-part multijoint 3d shape assembly
研究人员还开发了若干数据集和仿真环境以促进该领域的研究。例如
Wang等人49-Ikea-manual: Seeing shape assembly step by step
和Liu等人32-Ikea manuals at work:4d grounding of assembly instructions on internet videos
引入了包含家具三维模型和基于说明书结构化组装步骤的IKEA家具组装数据集
此外,Lee等人27-*Ikea furniture assembly environment for long-horizon complex manipulation tasks*
和Yu等人58-Roboassembly: Learning generalizable furniture assembly policy in a novel multi-robot contact-rich simulation environment开发了用于IKEA家具组装的仿真环境
而Heo等人16-Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation则提供了可复现的真实家具组装基准
另一个方向是利用VLM为机器人学习提供高层次指令和感知理解
VLM可辅助
任务描述17-Copa, 18-rekep
环境理解19-Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation
任务规划
47-Chatgpt for robotics: Design principles and model abilities
56-React: Synergizing reasoning and acting in language models
62-large language models as commonsense knowledge for largescale task planning
甚至直接进行机器人控制*28-Manipllm: Embodied multimodal large language model for object-centric robotic manipulation*
此外,Goldberg等人*14-Blox-net: Generative design-for-robot-assembly using vlm supervision, physics simulation, and a robot with reset*展示了VLM如何协助机器人装配任务的设计
从演示中学习(LfD)在获取机器人操作技能方面取得了令人瞩目的成果 *12-mobile aloha, 64-Viola: Imitation learning for vision-based manipulation with object proposal priors, 7-Diffusion policy*
关于机器人装配中LfD的更全面综述,可参考Zhu和Hu的工作 65-Robot learning from
demonstration in robotic assembly: A survey
其核心思想是学习一种能够模仿专家的行为的策略
然而,先前的学习方法通常需要细粒度的示范,例如
机器人轨迹7-Diffusion policy
或视频 22-Egomimic: Scaling imitation learning via egocentric video
40-Roboclip: One demonstration is enough to learn robot policies
21-View: Visual imitation learning with waypoints
收集这些示范往往非常耗费人力,并且并不总是可行
有些研究提出从粗粒度的示范中学习,比如手绘的期望场景草图*42-Rt-sketch: Goal-conditioned imitation learning from hand-drawn sketches, 2024*
或粗略的轨迹草图15-Rt-trajectory: Robotic task generalization via hindsight trajectory sketches
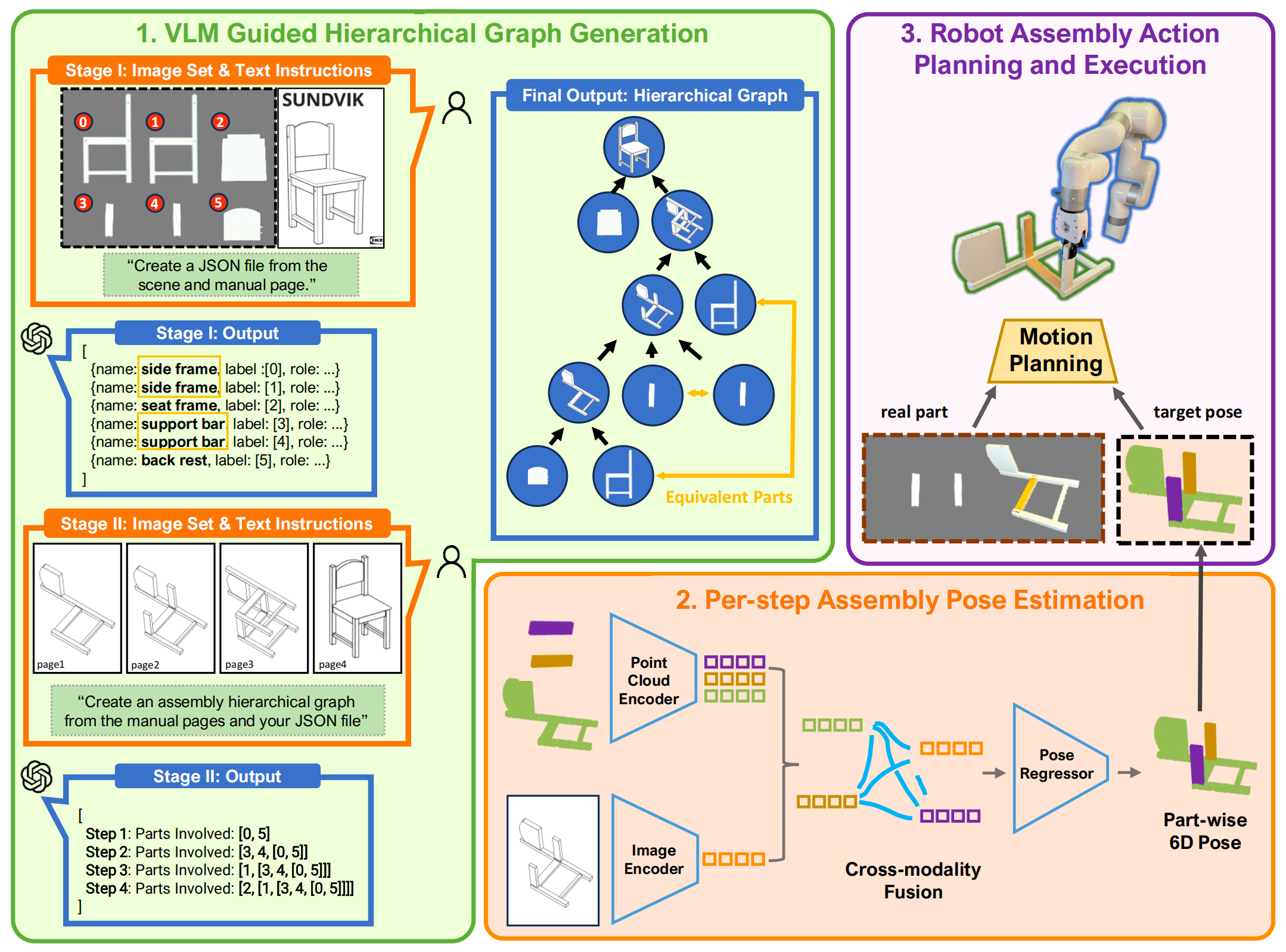
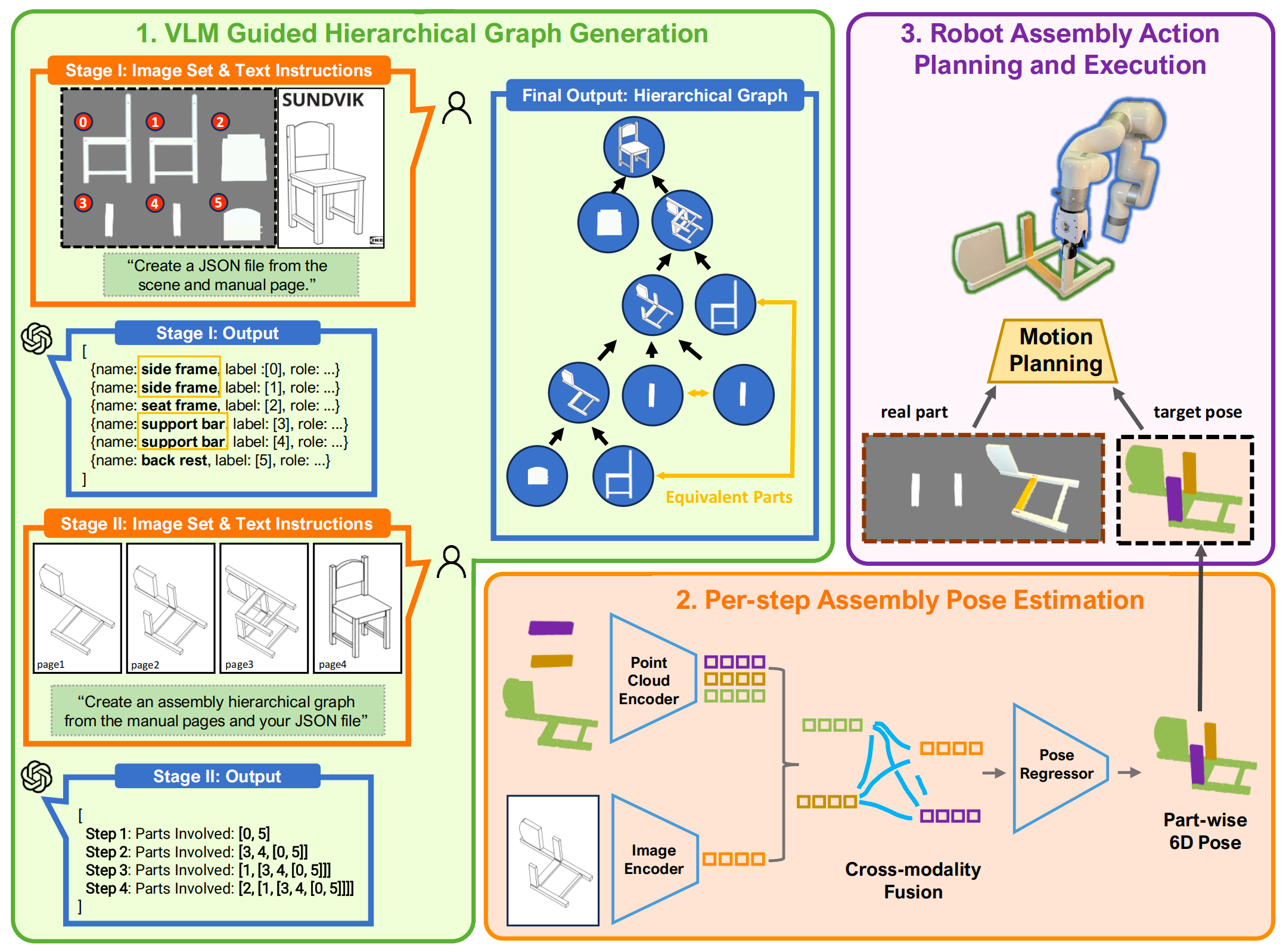
作者将椅子的座位描述为:名称:座架,标签:2,角色:供人坐在椅子上,座位提供了基本的支撑和舒适感,并位于椅子框架的中央 we describe the chair's seat as name: seat frame, label: 2, role: for people sitting on a chair, the seat offers essential support and comfortand is positioned centrally with in the chair's frame.
这里的"2"表示该三元组对应于预装配场景图像中用索引2标记的物理部件。该三元组格式通过将所有输出结构化为统一的数据格式,提高了可解释性并确保了一致性
对于图像编码器,作者选择了DeepLabV3+的编码器组件,该组件以MobileNetV2为主干,并包含空洞空间金字塔池化(ASPP)模块
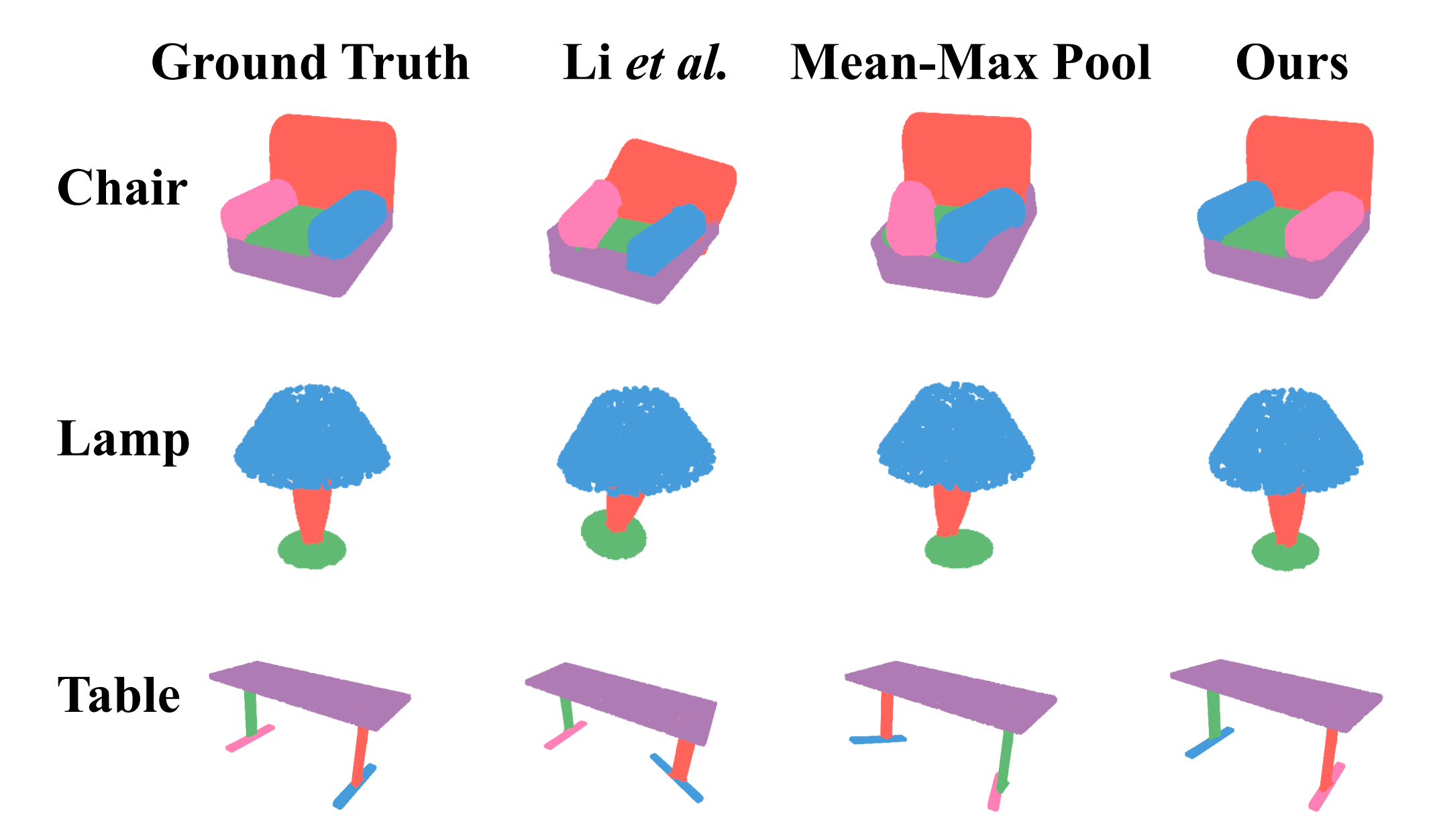
之所以做出这一选择,是因为DeepLabV3+在自动编码器的基础上引入了空洞卷积,使模型能够有效捕捉多尺度结构和空间信息 4,5。它能够从图像I生成多通道特征图,且采用mean-max pool 61方法来提取全局向量从特征图中提取特征

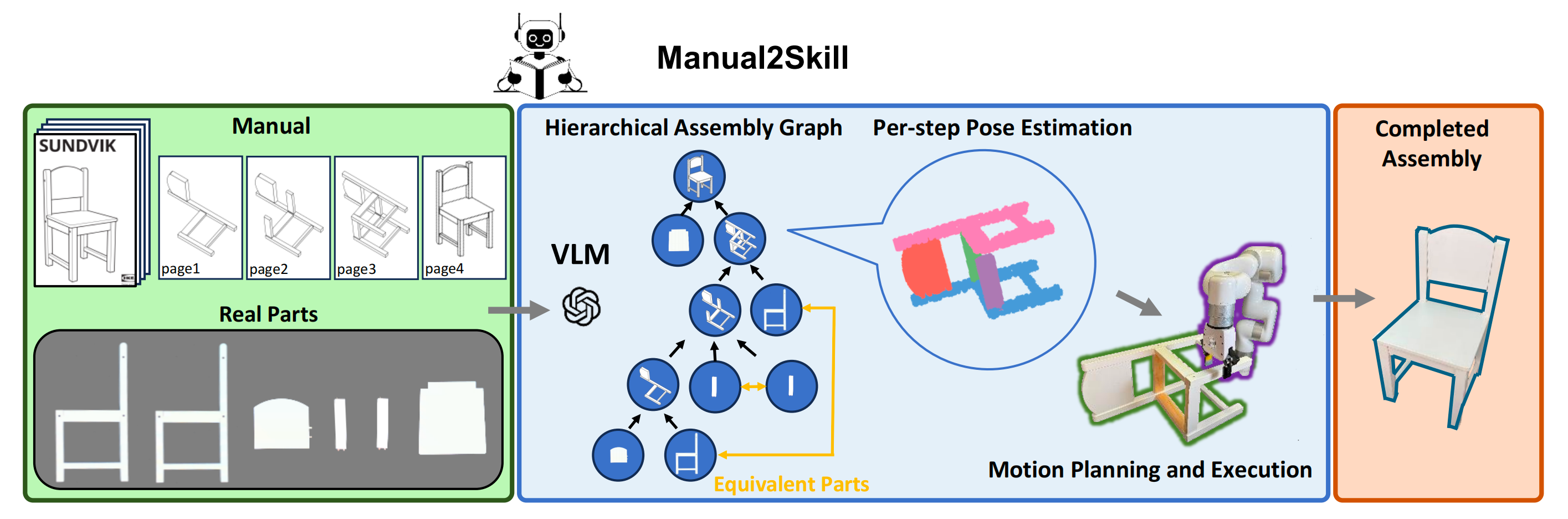
,其中每张图像