文章目录
- 前言
- 一、langchain是什么?
- 二、langchain接入大语言模型
-
- [1. 引入库](#1. 引入库)
- [2. 在langchain中进行简单的对话](#2. 在langchain中进行简单的对话)
-
- [2.1 使用deepseek的api-key对话](#2.1 使用deepseek的api-key对话)
- [2.2 使用ollama接入本地的模型](#2.2 使用ollama接入本地的模型)
-
- [2.2.1 引入库](#2.2.1 引入库)
- [2.2.2 打开ollama,直接对话](#2.2.2 打开ollama,直接对话)
- 三、langchain核心功能:链式调用的实现
- 四、langchain接入工具流程
-
- [例子1:以python 代码解释器为例](#例子1:以python 代码解释器为例)
- 例子2:接入自定义工具,比较繁琐的一种实现
- 例子3:接入自定义工具,借助agent更简洁的实现串联和,并联
- 例子4:使用langchain内置工具,创建agent。以Tavily搜索引擎为例
- 总结
前言
参考文献:
https://python.langchain.com/docs/tutorials/llm_chain/
https://www.bilibili.com/video/BV1pYKgzAE5C
本文仅仅用于学习记录langchain的基础内容。感谢以上参考文献。
本文的完整代码,可从笔者的gitee下载。
一、langchain是什么?
LangChain 是一个开源的、用于构建基于大语言模型(LLM, Large Language Model)的应用程序的开发框架。它旨在简化与语言模型的集成,使得开发者可以更轻松地构建诸如聊天机器人、问答系统、智能代理(Agents)、自动化流程等复杂应用。
二、langchain接入大语言模型
1. 引入库
代码如下(示例):
python
# 创建并激活 Conda 环境
conda create -n langchain python=3.11
conda activate langchain
# 使用 pip 安装核心包
pip install langchain langchain-deepseek python-dotenv2. 在langchain中进行简单的对话
2.1 使用deepseek的api-key对话
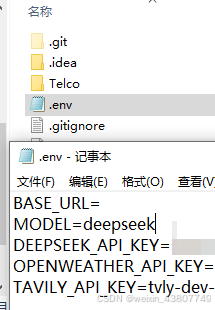
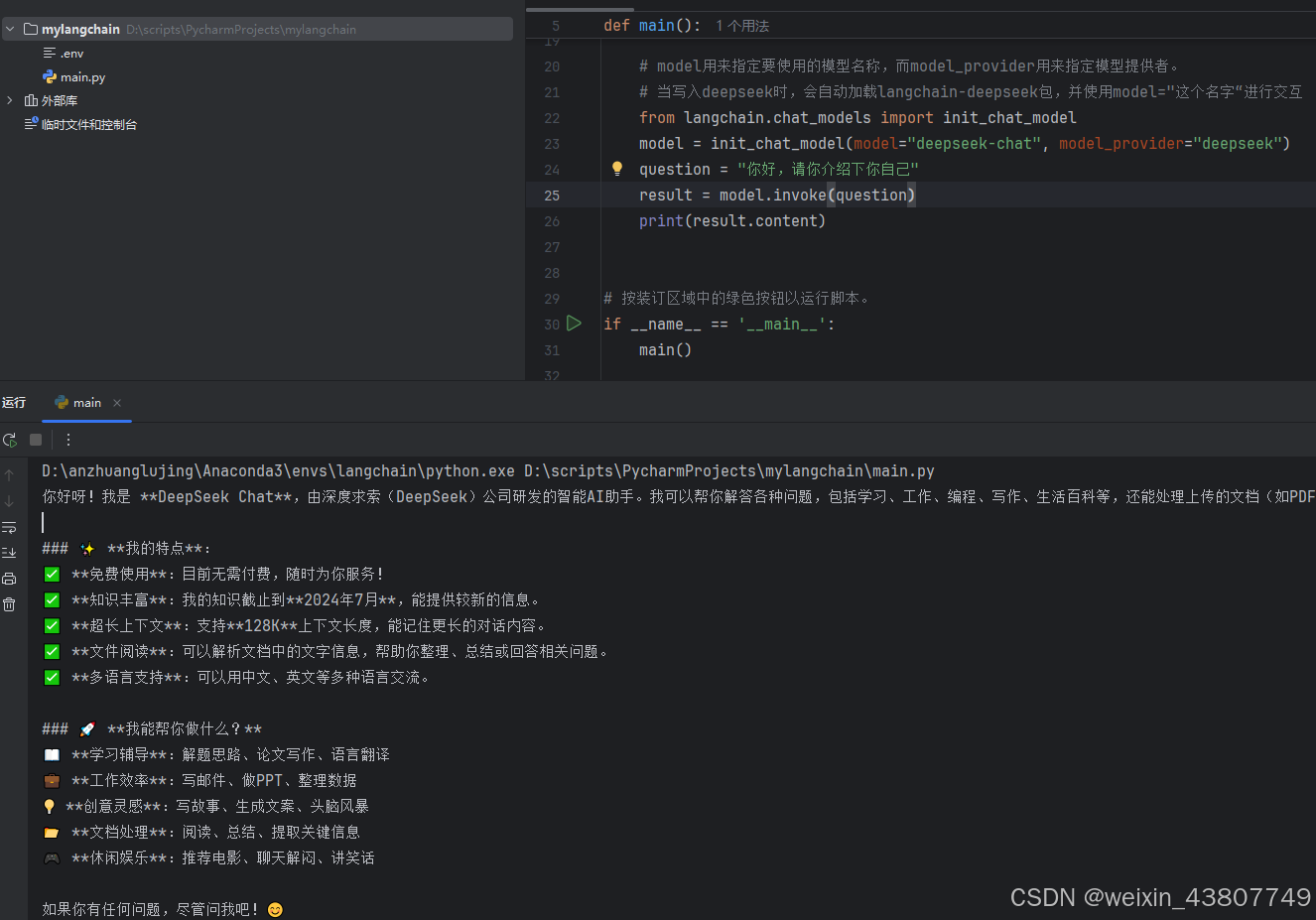
在官网https://platform.deepseek.com 注册获取api key,并充值1rmb。将apikey填入.envs文档中,并起名为 ..._API_kEY
2.2 使用ollama接入本地的模型
如果你想接入其他模型,可以查看官网提供的其他模型接入方式:https://python.langchain.com/docs/integrations/chat/。或者不想花钱买api,可以接入基于ollama的本地模型。来看如何操作。ollama的windows安装步骤,可见笔者之前的博客。
2.2.1 引入库
python
# 使用 pip 安装核心包
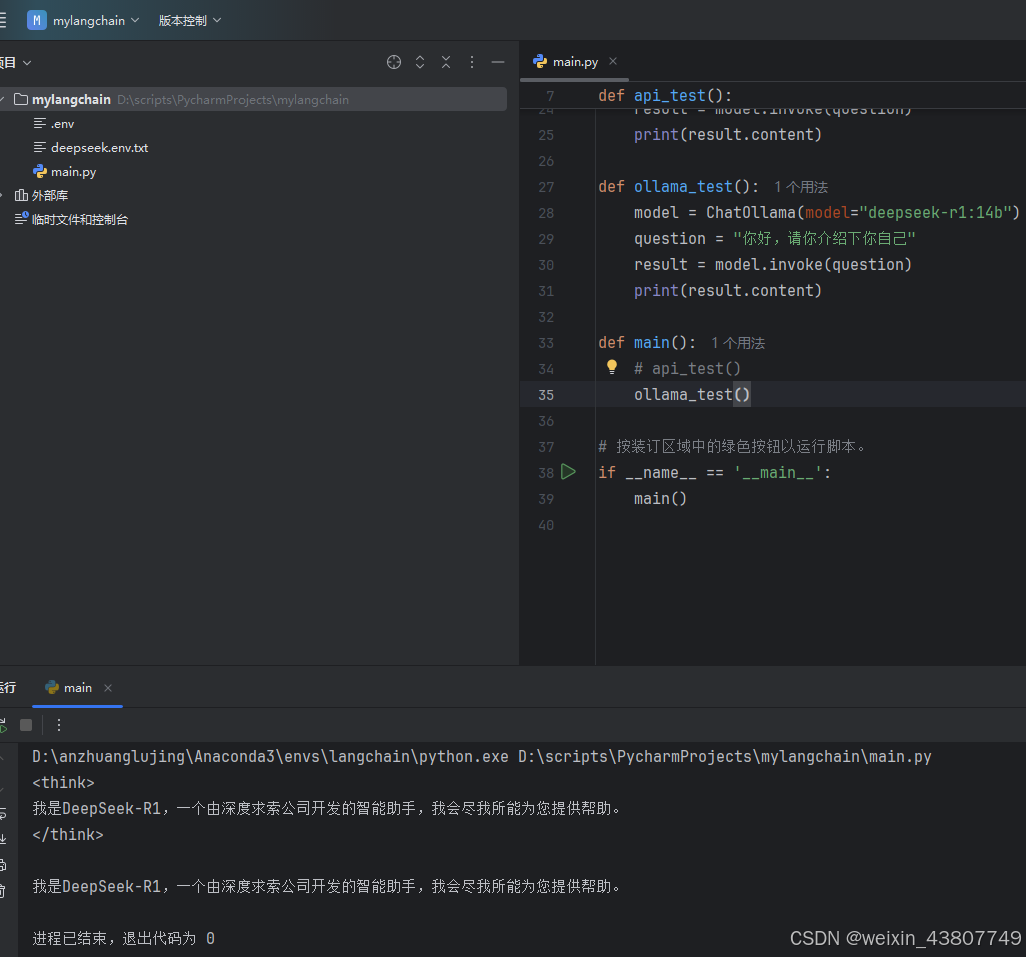
pip install langchain-ollama2.2.2 打开ollama,直接对话
三、langchain核心功能:链式调用的实现
例子1:使用StructuredOutputParser在文档中提取指定的结构化信息
python
def build_chain3():
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain_core.prompts import PromptTemplate
model = ChatOllama(model="deepseek-r1:14b")
schemas = [ResponseSchema(name="name", description="用户的姓名"),
ResponseSchema(name="age", description="用户的年龄")]
parser = StructuredOutputParser.from_response_schemas(schemas)
# 在PromptTemplate中,定义了两个占位符:
# {input}->将由用户传入的文本替换,即"用户叫李烈,今年24岁...",
# {format_instructions}->会通过partial提前绑定结构化格式说明
prompt = PromptTemplate.from_template("请根据以下内容提取用户信息,并返回json格式: \n{input}\n\n{format_instructions}")
chain = (prompt.partial(format_instructions = parser.get_format_instructions()) | model | parser)
result = chain.invoke({"input": "用户叫李烈,今年24岁, 是一个工程师。"})例子2:创建复合链,串联
python
def build_chain4():
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableSequence
model = ChatOllama(model="deepseek-r1:14b")
# 第1步,根据标题生成新闻正文
news_gen_prompt = PromptTemplate.from_template("请根据以下新闻标题撰写一段简短的新闻内容(100字以内): \n\n标题: {title}")
# 第一个子链:生成新闻内容
news_chain = news_gen_prompt | model
# 第2步,从正文中提取结构化字段
schemas = [ResponseSchema(name="time", description="事件发生的时间"),
ResponseSchema(name="location", description="事件发生的地点"),
ResponseSchema(name="event", description="发生的具体事件")]
parser = StructuredOutputParser.from_response_schemas(schemas)
prompt = PromptTemplate.from_template(
"请根据以下这段新闻内容提取关键信息,并返回json格式: \n{news}\n\n{format_instructions}")
# 第二个子链:生成摘要
summary_chain = (prompt.partial(format_instructions=parser.get_format_instructions()) | model | parser)
# 组合成一个复合chain
full_chain = news_chain | summary_chain
result = full_chain.invoke({"title": "深度求索公司在2025年年初发布了deepseek新模型"})
print(result)例子3:具有多轮对话记忆能力的聊天机器人
在deepseek-api上对话的效果图如下。多轮对话表明,成功实现了记忆功能。(注意,笔者的台式机在本地ollama上对话,反应太慢; 其次,运行前记得把v2r等代理工具关闭)
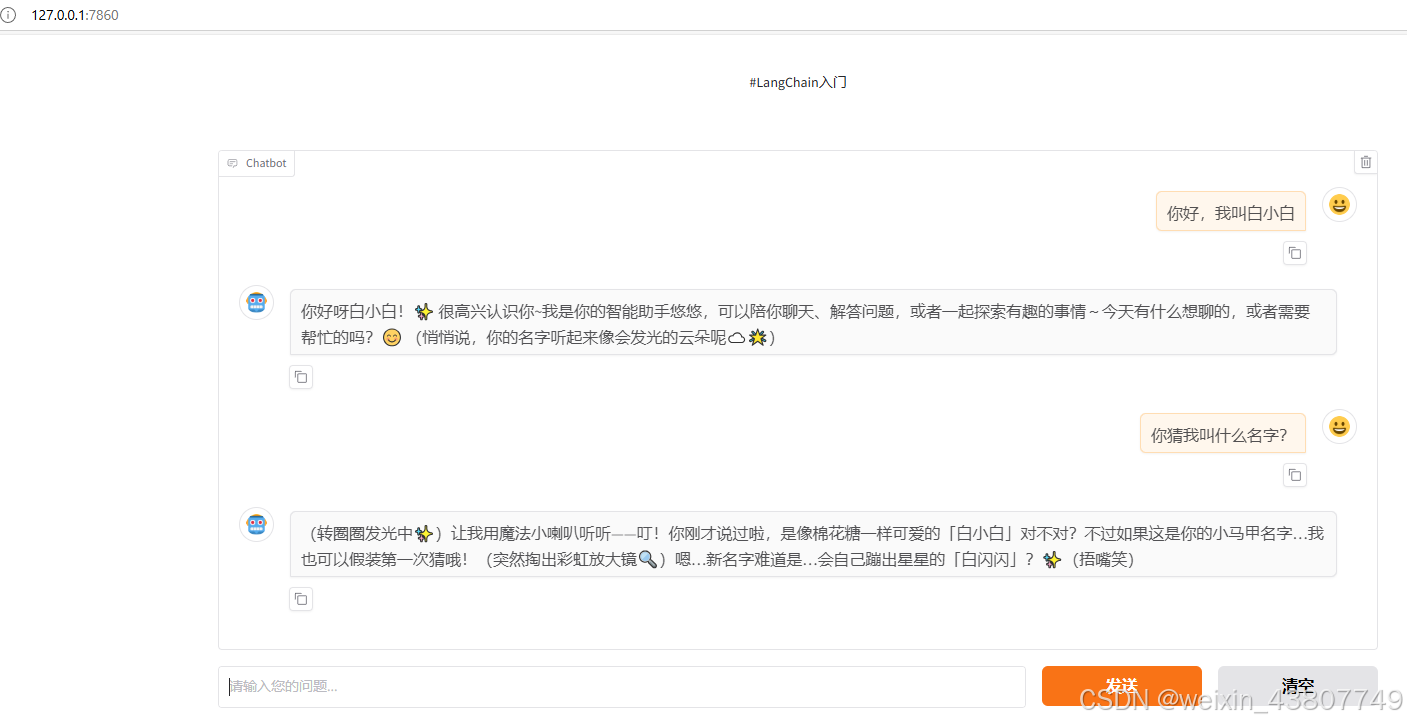
记忆功能的代码:
python
# 处理消息发送
async def respond(message, chat_history):
if not message.strip():
yield "", chat_history
return
# 1. 添加用户消息到历史并立即显示
chat_history = chat_history + [(message, None)]
yield "", chat_history # 立即显示用户消息
# 2. 流式生成AI回应
async for response in chat_response(message, chat_history):
# 更新最后一条消息的AI回应
chat_history[-1] = (message, response)
yield "", chat_history其中,chat_response代码如下:
python
async def chat_response(message, history):
"流式生成AI回应"
# ✅ 注意:history 需要转换成 messages 格式(LangChain 要求)
from langchain_core.messages import HumanMessage, AIMessage
# 将历史对话,转换为 message 列表
formatted_history = []
for user_msg, ai_msg in history:
if user_msg:
formatted_history.append(HumanMessage(content=user_msg))
if ai_msg:
formatted_history.append(AIMessage(content=ai_msg))
partial_message = ""
async for chunk in chain.astream({
"input": message,
"chat_history": formatted_history}):
partial_message += chunk
yield partial_message完整的chatbot代码,可见于笔者gitee仓库中的main1.py中的chatbot()函数。
四、langchain接入工具流程
https://python.langchain.com/docs/tutorials/ 在langchain官网提供了很多的内置工具,比如网页搜索、爬虫等,方便开发者直接使用。
例子1:以python 代码解释器为例
首先安装库
python
# 使用 pip 安装核心包
pip install langchain-community langchain-experimental pandas scipy从官网下载telco数据集 https://www.kaggle.com/datasets/blastchar/telco-customer-churn,也可以在我的gitee仓库中下载。
具体代码如下:
python
# 使用python解释器工具
def use_tools1():
load_dotenv(override=True)
from langchain_core.prompts import ChatPromptTemplate
from langchain_experimental.tools import PythonAstREPLTool
import pandas as pd
df = pd.read_csv("./Telco/WA_Fn-UseC_-Telco-Customer-Churn.csv")
tool = PythonAstREPLTool(locals={"df": df})
# print(tool.invoke("df['SeniorCitizen'].mean()")) # df['SeniorCitizen'].mean() = 0.1621468124378816
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
llm_with_tools = model.bind_tools([tool])
from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParser
parser = JsonOutputKeyToolsParser(key_name=tool.name, first_tool_only=True)
system_message = f"""你可以访问一个名为'df'的pandas数据框,你也可以使用df.head().to_markdown()查看数据集的基本信息。
请根据用户提出的问题,编写python代码来回答。只返回代码,不返回其他内容。只允许使用pandas和内置库。"""
prompt = ChatPromptTemplate([("system", system_message), ("user", "{question}")])
# code_chain = prompt | llm_with_tools | parser
# print(code_chain.invoke({"question": "请帮我计算SeniorCitizen字段的均值"})) #输出:{"query":"df[\'SeniorCitizen\'].mean()"}
chain = prompt | llm_with_tools | parser | tool
print(chain.invoke({"question": "请帮我分析gender和Churn和SeniorCitizen三个字段之间的相关关系"}))
# # 输出:
# # Gender和Churn的卡方检验结果:
# # 卡方值: 0.4840828822091383, p值: 0.48657873605618596
# # SeniorCitizen和Churn的卡方检验结果:
# # 卡方值: 159.42630036838742, p值: 1.510066805092378e-36
# # Gender和SeniorCitizen的卡方检验结果:
# # 卡方值: 0.015604244282376655, p值: 0.9005892996849594例子2:接入自定义工具,比较繁琐的一种实现
langchain中接入天气查询功能。在笔者的mcp入门博客中,有天气查询这个api更详细的记录。不在此赘述。代码如下:
python
# 接入自定义工具
def use_tools2():
load_dotenv(override=True)
import requests, json
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
@tool
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替
:return: 解析之后的json格式对象
"""
url = "https://api.openweathermap.org/data/2.5/weather"
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"),
"units": "metric",
"lang": "zh_cn"
}
response = requests.get(url, params=params)
data = response.json()
return json.dumps(data)
# print(get_weather.name)
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
tools = [get_weather]
llm_with_tools = model.bind_tools(tools)
from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParser
parser = JsonOutputKeyToolsParser(key_name="get_weather", first_tool_only=True)
prompt = ChatPromptTemplate([("user", "{input}")])
get_weather_chain = prompt | llm_with_tools | parser | get_weather
# response = get_weather_chain.invoke("你好,上海今天的天气怎么样?")
# print(response)
# {"coord": {"lon": 121.4581, "lat": 31.2222}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 33.67, "feels_like": 40.67, "temp_min": 33.67, "temp_max": 33.67, "pressure": 1002, "humidity": 59, "sea_level": 1002, "grnd_level": 1001}, "visibility": 10000, "wind": {"speed": 4.51, "deg": 162, "gust": 5.51}, "clouds": {"all": 80}, "dt": 1754374028, "sys": {"country": "CN", "sunrise": 1754341997, "sunset": 1754390825}, "timezone": 28800, "id": 1796236, "name": "Shanghai", "cod": 200}
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
output_prompt = PromptTemplate.from_template(
"""你将收到一段json格式的天气数据,请用简洁自然的方式将其转述给用户。
以下是天气json数据:json {weather_json}
请将其转换为中文天气描述,例如:
"北京当前天气晴朗,气温为23C,湿度58%,风速2.1米/秒" 只返回一句话描述,不要其他说明或解释。
"""
)
output_chain = output_prompt | model | StrOutputParser()
# weather_json = '{"coord": {"lon": 121.4581, "lat": 31.2222}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 33.67, "feels_like": 40.67, "temp_min": 33.67, "temp_max": 33.67, "pressure": 1002, "humidity": 59, "sea_level": 1002, "grnd_level": 1001}, "visibility": 10000, "wind": {"speed": 4.51, "deg": 162, "gust": 5.51}, "clouds": {"all": 80}, "dt": 1754374028, "sys": {"country": "CN", "sunrise": 1754341997, "sunset": 1754390825}, "timezone": 28800, "id": 1796236, "name": "Shanghai", "cod": 200}'
# response = output_chain.invoke(weather_json)
# print(response) # 上海当前天气多云,气温为33.67°C,体感温度40.67°C,湿度59%,风速4.51米/秒。
full_chain = get_weather_chain | output_chain
response = full_chain.invoke("请问天津今天的天气如何?")
print(response) # 天津当前阴天多云,气温31.72°C(体感38.72°C),湿度77%,风速1.45米/秒。例子3:接入自定义工具,借助agent更简洁的实现串联和,并联
python
def use_tools3():
from langchain.agents import create_tool_calling_agent, tool
from langchain_core.prompts import ChatPromptTemplate
from langchain.chat_models import init_chat_model
load_dotenv(override=True)
import requests, json
@tool
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替
:return: 解析之后的json格式对象
"""
url = "https://api.openweathermap.org/data/2.5/weather"
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"),
"units": "metric",
"lang": "zh_cn"
}
response = requests.get(url, params=params)
data = response.json()
return json.dumps(data)
prompt = ChatPromptTemplate.from_messages(
[("system", "你是天气助手,请根据用户的问题,给出相应的天气信息"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")])
tools = [get_weather] # 定义工具
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
agent = create_tool_calling_agent(model, tools, prompt)
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# response = agent_executor.invoke({"input": "请问今天北京的天气怎么样"})
# print(response) #属于串联
response = agent_executor.invoke({"input": "请问今天北京和上海的天气怎么样?哪个城市更热?"})
print(response) # 属于并联
# 'output': '今天北京的天气是阴天,多云,温度为32.68°C,体感温度39.68°C。 \n上海的天气是晴天,少云,温度为32.94°C,体感温度39.94°C。
# \n\n从温度来看,上海比北京稍微热一点。'}例子4:使用langchain内置工具,创建agent。以Tavily搜索引擎为例
首先安装环境包:
python
pip install langchain-tavily然后登录官网注册api,把apikey并放入.ens文件中。可以看到搜索效果不错,agent真香!(注意,Tavily是有免费搜索次数限制的)
python
# 使用langchain内置工具,创建agent. 以Tavily搜索引擎为例
def use_tools4():
load_dotenv(override=True)
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.agents import create_tool_calling_agent, tool
from langchain_core.prompts import ChatPromptTemplate
from langchain.chat_models import init_chat_model
from langchain.agents import AgentExecutor
search = TavilySearchResults(max_results=2)
# result = search.invoke("苹果2025WWDC发布会")
# [{'title': 'Apple 全球開發者大會於香港時間6 月10 日當週登場', 'url': 'https://www.apple.com/hk/newsroom/2025/03/apples-worldwide-developers-conference-returns-the-week-of-june-9/', 'content': ...
tools = [search]
prompt = ChatPromptTemplate.from_messages(
[("system", "你是一名乐于助人的助手,并且可以调用工具进行网络搜索,获取实时信息"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")])
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
agent = create_tool_calling_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
response = agent_executor.invoke({"input": "请问将在2026年举行世界杯的城市是?"})
print(response) # 'output': '2026年世界杯将由美国、墨西哥和加拿大联合举办,共有16个举办城市,具体如下:\n\n- **美国**:纽约/新泽西...总结
根据网上资料简单学习了langchain的使用。下一篇博客中将使用langchain进行mcp和rag的应用。