//TODO 写一个wordcount
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));
JavaRDD<String> rdd = javaSparkContext.textFile("E:\\ideaProjects\\spark_project\\data\\wordcount");
rdd.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
})
.groupBy(n -> n)
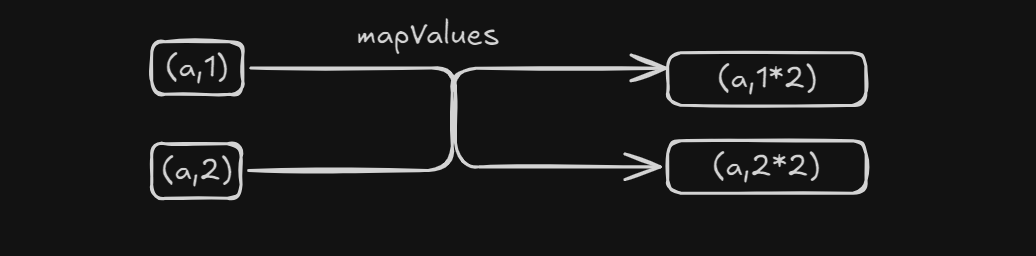
.mapValues(
iter -> {
int sum = 0;
for (String word : iter) {
sum++;
}
return sum;
}
).collect().forEach(System.out::println);
javaSparkContext.close();
所以,整个转换过程是:
输入:一行字符串(`String`)
用`split`方法:将该行字符串分割成字符串数组(`String\[\]`)
用`Arrays.asList`:将字符串数组转换为字符串列表(`List<String>`)
调用列表的`iterator`方法:得到字符串的迭代器(`Iterator<String>`)
在`flatMap`中,Spark会遍历这个迭代器,将每个字符串(单词)作为新元素放入结果RDD。
flatmap本质:都是将数组转换成一个可以逐个访问其元素的迭代器
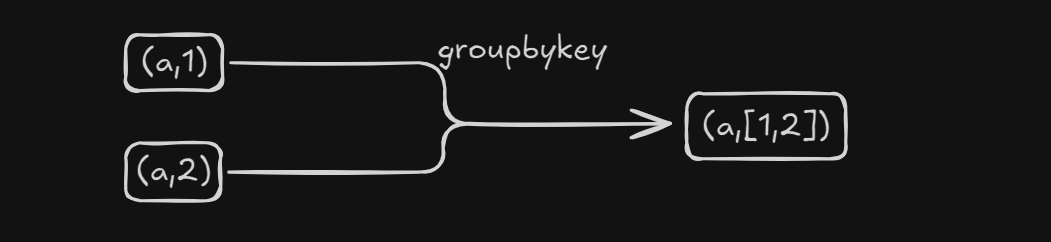
groupByKey
作用:将KV对按照K对V进行分组
代码实现
java复制代码
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));
Tuple2<String, Integer> a = new Tuple2<>("a", 1);
Tuple2<String, Integer> b = new Tuple2<>("b", 2);
Tuple2<String, Integer> c = new Tuple2<>("a", 3);
Tuple2<String, Integer> d = new Tuple2<>("b", 4);
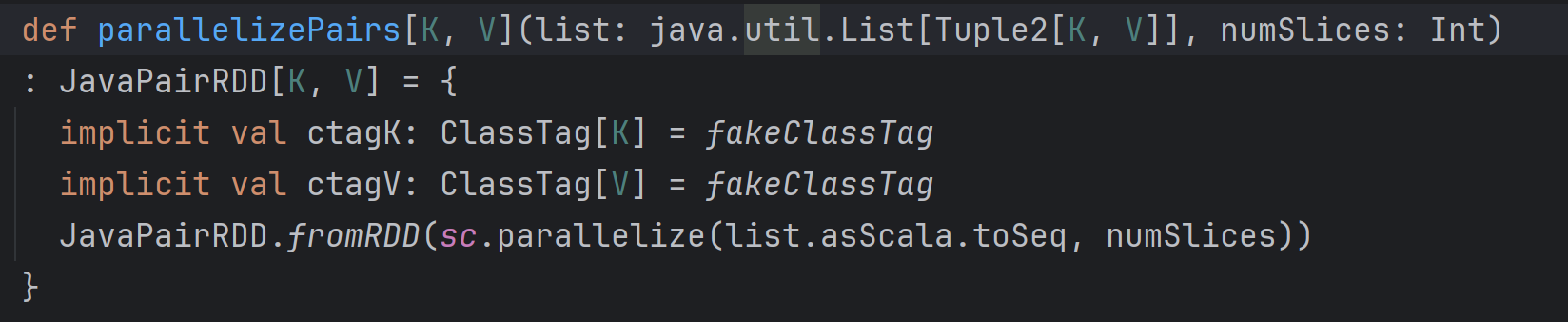
javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d))
.collect().forEach(System.out::println);
System.out.println();
javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d))
.groupByKey(3).collect().forEach(System.out::println);
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));
Tuple2<String, Integer> a = new Tuple2<>("a", 1);
Tuple2<String, Integer> b = new Tuple2<>("b", 2);
Tuple2<String, Integer> c = new Tuple2<>("a", 3);
Tuple2<String, Integer> d = new Tuple2<>("b", 4);
System.out.println();
javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d))
.groupByKey(3).mapValues(new Function<Iterable<Integer>, Integer>() {
@Override
public Integer call(Iterable<Integer> v1) throws Exception {
int sum = 0;
for (Integer v2 : v1) {
sum += v2;
}
return sum;
}
}).collect().forEach(System.out::println);
javaSparkContext.close();
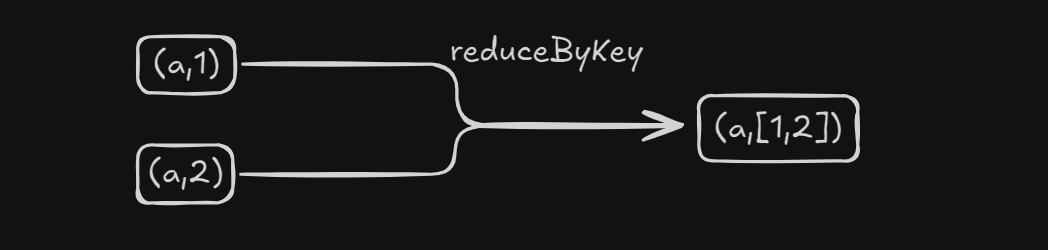
改进用reduceByKey
java复制代码
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));
Tuple2<String, Integer> a = new Tuple2<>("a", 1);
Tuple2<String, Integer> b = new Tuple2<>("b", 1);
Tuple2<String, Integer> c = new Tuple2<>("a", 2);
Tuple2<String, Integer> d = new Tuple2<>("b", 2);
ArrayList<Tuple2<String, Integer>> tuple2s = new ArrayList<>(Arrays.asList(a, b, c, d));
javaSparkContext.parallelizePairs(tuple2s)
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
})
.collect().forEach(System.out::println);
javaSparkContext.close();
groupby通过K和通过V分组的模板代码
java复制代码
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));
Tuple2<String, Integer> a = new Tuple2<>("a", 1);
Tuple2<String, Integer> b = new Tuple2<>("b", 1);
Tuple2<String, Integer> c = new Tuple2<>("a", 2);
Tuple2<String, Integer> d = new Tuple2<>("b", 2);
System.out.println();
javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d))
.groupBy(new Function<Tuple2<String, Integer>, Integer>() {
@Override
public Integer call(Tuple2<String, Integer> v1) throws Exception {
return v1._2(); //通过Values分组 将2改为1就是通过K分组
}
})
.collect().forEach(System.out::println);
javaSparkContext.close();