一、机器学习概述
机器学习(Machine Learning, ML)是人工智能的核心分支,旨在通过算法让计算机从数据中自动学习规律并优化性能,而无需显式编程。这一技术领域起源于20世纪50年代,随着计算能力的提升和大数据时代的到来,在21世纪得到了迅猛发展。
1. 基本概念
机器学习通过数据训练模型,使其能够识别模式、做出预测或决策。与传统编程不同,机器学习系统不是通过直接编写规则,而是通过分析大量数据来"学习"如何完成任务。
2. 核心思想
其核心是"从经验中自动改进",这一思想模仿了人类的学习过程。机器学习系统通过不断调整内部参数,逐步提高在特定任务上的表现。
3. 关键三要素
机器学习的实现依赖于三大基本要素:
- 数据:训练材料,包括结构化数据(如数据库表格)和非结构化数据(如文本、图像)
- 模型:输入到输出的映射函数,如决策树、神经网络等
- 算法:优化方法如梯度下降、随机梯度下降等
机器学习算法分类
1. 监督学习(Supervised Learning)
监督学习使用标注数据训练模型,需要提供输入数据和对应的正确输出(标签)。主要应用包括:
-
分类:预测离散类别
- 垃圾邮件识别(二分类)
- 手写数字识别(多分类)
- 医疗影像诊断(如识别肿瘤类型)
-
回归:预测连续数值
- 房价预测(基于面积、位置等特征)
- 股票价格预测
- 销售预测
常用算法:
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树
- 随机森林
2. 无监督学习(Unsupervised Learning)
无监督学习从无标签数据中发现隐藏的结构和模式。主要应用包括:
-
聚类:
- K-Means:客户细分、文档分类
- 层次聚类:生物学的物种分类
- DBSCAN:异常检测
-
降维:
- 主成分分析(PCA):数据可视化、特征提取
- t-SNE:高维数据可视化
- 自编码器:图像压缩
-
关联规则学习:
- 购物篮分析(啤酒与尿布)
- 推荐系统
3. 强化学习(Reinforcement Learning)
强化学习通过环境交互学习最优策略,其核心是"试错学习"。主要特点包括:
-
应用场景:
- 游戏AI(AlphaGo、星际争霸AI)
- 机器人控制(行走、抓取)
- 自动驾驶决策
- 金融交易策略
-
关键概念:
- 智能体(Agent)
- 环境(Environment)
- 奖励(Reward)
- 策略(Policy)
-
算法分类:
- 基于价值的方法(Q-Learning)
- 基于策略的方法(Policy Gradients)
- Actor-Critic方法
机器学习库
在Python中进行机器学习开发时,Scikit-learn是最常用的机器学习库之一。它提供了各种监督学习和无监督学习算法,以及数据预处理、模型评估等工具,是机器学习入门和实践的最佳选择
bash
pip install scikit-learn ==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
#篇使用版本为1.0.2
python
#导入方法如下
import sklearn二、KNN(K-Nearest Neighbors,K近邻)算法
1.核心思想
KNN是一种基于实例的监督学习算法,其核心假设是"相似的数据点在特征空间中彼此靠近"。通过计算待预测样本与训练集中所有样本的距离,选择最近的K个邻居,根据这些邻居的类别(分类任务)或数值(回归任务)进行预测。本篇以分类为主。
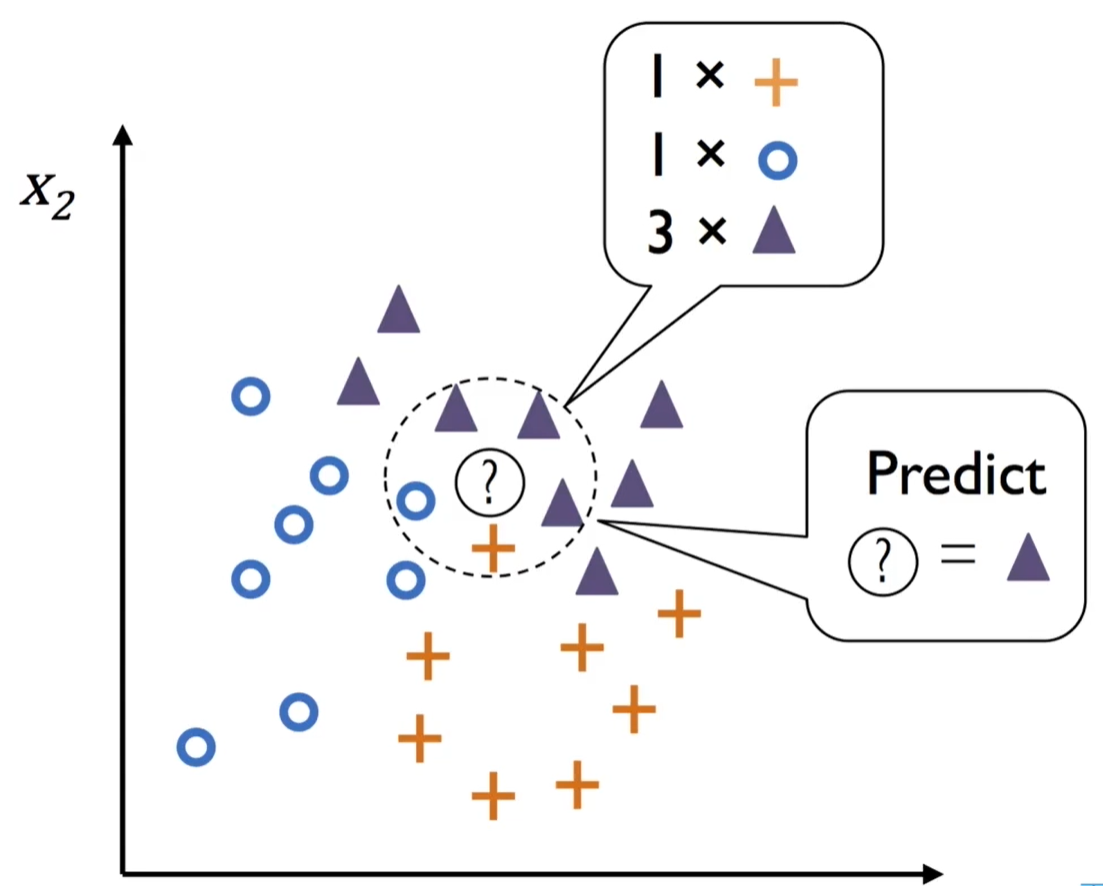
算法步骤
数据准备
标准化/归一化特征:消除量纲差异对距离计算的影响(如使用StandardScaler)
- 详细步骤:
- 计算每个特征的均值(μ)和标准差(σ)
- 对每个特征值x进行变换:(x-μ)/σ
- 示例:若特征A的范围是0-1000,特征B的范围是0-1,标准化后两个特征都服从均值为0、标准差为1的分布
- 应用场景:当特征的单位不同(如身高cm vs 体重kg)或数值范围差异较大时
距离计算
常用距离度量:
欧氏距离(默认):适用于连续特征
- 公式:d(x,y)=√(∑(x_i-y_i)^2)
- 几何解释:两点在n维空间中的直线距离
- 示例:在二维空间中,点(1,3)和(4,7)的距离为√((1-4)^2 + (3-7)^2)=5
曼哈顿距离:适用于网格路径数据
- 公式:d(x,y)=∑|x_i-y_i|
- 别称:城市街区距离
- 适用场景:棋盘格移动、城市道路规划等网格状路径系统
- 示例:在二维网格中,(1,3)到(4,7)的距离为|1-4| + |3-7|=7
选择K个最近邻
按距离排序,选取前K个样本
- 关键步骤:
- 计算待分类样本与所有训练样本的距离
- 将所有距离按从小到大排序
- 选择距离最小的K个样本
- 注意事项:K值通常取奇数(如3/5/7)以避免平票情况
投票决策
统计K个邻居的类别频率,将待分类样本划入频率最高的类别
- 具体流程:
- 统计K个邻居中每个类别出现的次数
- 选择出现次数最多的类别作为预测结果
- 平票处理:可随机选择或考虑更小的K值
- 扩展:也可使用加权投票,距离近的邻居投票权重更大
数据准备
标准化/归一化特征:消除量纲差异对距离计算的影响(如使用StandardScaler)
- 详细步骤:
- 计算每个特征的均值(μ)和标准差(σ)
- 对每个特征值x进行变换:(x-μ)/σ
- 示例:若特征A的范围是0-1000,特征B的范围是0-1,标准化后两个特征都服从均值为0、标准差为1的分布
- 应用场景:当特征的单位不同(如身高cm vs 体重kg)或数值范围差异较大时
距离计算
常用距离度量:
欧氏距离(默认):适用于连续特征
- 公式:
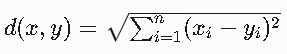
- 几何解释:两点在n维空间中的直线距离
- 示例:在二维空间中,点(1,3)和(4,7)的距离为√((1-4)^2 + (3-7)^2)=5
曼哈顿距离:适用于网格路径数据
- 公式:
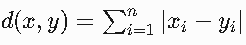
- 别称:城市街区距离
- 适用场景:棋盘格移动、城市道路规划等网格状路径系统
- 示例:在二维网格中,(1,3)到(4,7)的距离为|1-4| + |3-7|=7
选择K个最近邻
按距离排序,选取前K个样本
- 关键步骤:
- 计算待分类样本与所有训练样本的距离
- 将所有距离按从小到大排序
- 选择距离最小的K个样本
- 注意事项:K值通常取奇数(如3/5/7)以避免平票情况
投票决策
统计K个邻居的类别频率,将待分类样本划入频率最高的类别
- 具体流程:
- 统计K个邻居中每个类别出现的次数
- 选择出现次数最多的类别作为预测结果
- 平票处理:可随机选择或考虑更小的K值
- 扩展:也可使用加权投票,距离近的邻居投票权重更大
关键参数与优化
关键参数与优化
K值选择
K值的选择直接影响KNN模型的性能:
- K值过小(如K=1) :
- 模型会过于关注局部噪声点,导致过拟合
- 决策边界变得非常复杂且不规则
- 示例:在图像分类中,K=1可能导致对个别异常像素过于敏感
- K值过大 :
- 模型会忽略数据的局部特征,导致欠拟合
- 决策边界过度平滑,可能错过重要模式
- 示例:在房价预测中,过大的K值可能使不同社区的房价差异被平均化
-
-
优化方法:
-
交叉验证:
- 采用k折交叉验证(如5折或10折)评估不同K值
- 网格搜索:系统性地测试K值范围(如1-20)
-
经验法则:
- K≈√n(n为训练样本数)
- 通常选择奇数K值以避免平票情况
- 对于分类问题,初始可尝试K=3,5,7等小值
-
三、knn算法的运用
class sklearn.neighbors.KNeighborsClassifier( n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
| 参数名 | 类型/选项 | 默认值 | 作用 |
|---|---|---|---|
n_neighbors |
int | 5 | 近邻数K,决定投票的样本数量 |
weights |
'uniform', 'distance'或可调用对象 |
'uniform' |
权重分配方式: - 'uniform':等权重投票 - 'distance':按距离反比加权 |
algorithm |
'auto', 'ball_tree', 'kd_tree', 'brute' |
'auto' |
近邻搜索算法: - 'ball_tree'/'kd_tree':树结构加速搜索(维度<20时高效) - 'brute':暴力搜索(适合小数据集) |
p |
int | 2 | 闵可夫斯基距离的幂参数: - p=1:曼哈顿距离 - p=2:欧氏距离 |
metric |
str或可调用对象 | 'minkowski' |
距离度量标准(如'cosine'、'euclidean') |
n_jobs |
int或None | None | 并行计算线程数(-1表示使用所有CPU核心) |
| 法名 | 功能 | 示例 |
|---|---|---|
fit(X, y) |
存储训练数据(惰性学习) | knn.fit(X_train, y_train) |
predict(X) |
返回预测类别 | y_pred = knn.predict(X_test) |
predict_proba(X) |
返回样本属于各类别的概率(基于邻居类别的频率) | prob = knn.predict_proba([[1.5]])→ [[0.6, 0.4]] |
score(X, y) |
计算准确率(分类)或R²分数(回归) | accuracy = knn.score(X_test, y_test) |
kneighbors(X) |
返回K近邻的索引和距离 | dist, indices = knn.kneighbors([[0.5]]) |
四、算法示例
python
from matplotlib import pyplot as plt
import numpy as np
#knn算法预测
from sklearn.neighbors import KNeighborsClassifier
data = np.loadtxt('datingTestSet2.txt', delimiter='\t')
neigh = KNeighborsClassifier(n_neighbors=5)
x=data[:800,:-1]
y=data[:800,-1]
neigh.fit(x,y)
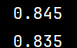
print(neigh.score(x,y))#准确率,自测
c1=data[800:,:-1]
c2=data[800:,-1]
right=neigh.score(c1,c2)
print(right)