哎哟我,难得起了个大早来学习。
先从昨天的UE开始吧
UE
虚幻引擎的动画系统架构是怎样的?
虚幻引擎的动画系统架构基于骨骼网格、动画蓝图和动画状态机构建,其中骨骼网格包含骨骼层次结构和网格数据,动画蓝图提供可视化的动画逻辑编辑环境,动画状态机管理不同动画状态之间的转换和混合。整个工作流程是动画蓝图读取角色的游戏状态(如移动速度、是否跳跃等),通过动画状态机决定播放哪个动画,然后对骨骼网格进行骨骼变换,最终渲染出动画效果。系统还支持动画混合、IK(反向运动学)、动画蒙太奇、动画压缩、动画重定向等高级功能,并通过LOD系统、动画压缩、GPU动画等技术确保在大型项目中的性能表现。
如何在动画蓝图中实现IK(反向运动学)?
IK(反向运动学)是解决"已知末端位置求关节角度"的数学问题,底层原理基于雅可比矩阵法和CCD(Cyclic Coordinate Descent)算法,通过从目标位置反向计算关节角度来实现动画效果。在虚幻引擎中主要通过Two Bone IK节点(用于四肢控制)和Look At节点(用于头部朝向)来实现,引擎已经处理了复杂的数学计算和性能优化,开发者只需要在动画蓝图中配置目标骨骼、目标位置、权重和限制参数即可。IK需要考虑关节旋转限制、避免奇异解、处理多解问题等约束,UE通过设置关节限制、权重调整、优先级处理来解决这些问题,同时使用GPU加速、LOD系统、缓存机制来确保实时游戏中的性能表现。
什么是动画蒙太奇?
动画蒙太奇是虚幻引擎中的可重用动画片段系统,允许开发者将多个动画片段组合成复杂的动画序列,它是一个动画容器,可以包含多个动画片段并支持动态组合、混合和过渡。蒙太奇支持动画片段的添加、删除、重新排序,可以设置每个片段的播放时间、混合权重、过渡效果,还可以添加动画通知来触发游戏逻辑,常用于角色的复杂动作序列,比如攻击连击、受伤反应、交互动画等,也可以用于过场动画、环境动画等。蒙太奇提供可视化的动画编辑界面,支持实时预览和调试,可以动态调整动画参数,实现灵活的动画控制,大大简化了复杂动画序列的创建和管理。
如何理解动画压缩?虚幻引擎中有哪些动画压缩技术?
动画压缩是为了减少动画文件大小和内存占用同时保持动画质量的技术,动画数据通常包含大量的关键帧信息,直接存储会占用大量空间,压缩技术通过去除冗余数据、量化数值、预测编码等方式来减少数据量。虚幻引擎的动画压缩技术包括关键帧压缩(只保存重要的关键帧,中间帧通过插值计算)、曲线压缩(对动画曲线进行简化和量化)、量化压缩(将浮点数转换为整数,减少精度但节省空间)、预测编码(基于前一帧预测当前帧,只存储差异数据)和LOD压缩(根据距离使用不同精度的动画数据)。压缩效果可以显著减少动画文件大小(通常减少50-80%),降低内存占用,提高加载速度,但需要在文件大小和动画质量之间找到平衡点。
如何理解根运动和动画重定向?在虚幻引擎中如何应用?
根运动是动画中角色根骨骼(通常是臀部或腰部)的移动信息,它直接影响角色的世界位置,而不仅仅是视觉上的动画效果,在虚幻引擎中通过Root Motion组件来捕获和应用根运动,让角色的实际移动与动画同步。动画重定向是将一个角色的动画应用到另一个不同骨骼结构的角色上的技术,UE通过骨骼映射、比例调整、IK补偿等方式实现重定向,让不同体型和骨骼结构的角色可以共享相同的动画资源,大大提高了动画资源的复用性和开发效率,在大型项目中特别有用,可以减少动画制作的工作量并保持动画的一致性。
根运动就是我们在制作动画时先明确一个移动的值,然后在放入UE的动画系统后开启根运动就会通过编码的方式获取这个移动的值并把这个值作用到实际的场景中的几何位置上实现动画驱动的移动。而重定向的底层是因为本质上动画就是驱动骨骼进行几何变化,我们只需要把原来动画的网格体和需要复用动画的网格体建立骨骼之间的映射关系后就可以复用动画
什么是网络复制?如何实现?
网络复制是虚幻引擎中将服务器上的Actor状态同步到客户端的机制,确保所有玩家看到相同的游戏世界状态。实现网络复制主要通过Replicated属性标记,当你在C++中使用UPROPERTY(Replicated)或在蓝图中设置Replicated属性时,引擎会自动将标记的变量从服务器同步到所有客户端。引擎使用UDP协议进行数据传输,支持可靠和不可靠的复制,对于重要的游戏状态使用可靠复制确保数据到达,对于频繁变化的数据使用不可靠复制提高性能。复制系统还支持条件复制(只复制给特定客户端)、压缩复制(减少带宽使用)、预测复制(减少延迟感知)等高级功能,同时提供RepNotify回调函数让客户端在收到复制数据时执行自定义逻辑,实现复杂的网络游戏功能。
RPC函数是什么?有哪些类型?
RPC(Remote Procedure Call,远程过程调用)函数是允许在不同机器上执行函数的网络通信机制,让客户端可以调用服务器上的函数,或者服务器可以调用客户端上的函数。UE中的RPC函数类型包括Server RPC(客户端调用服务器函数,用于发送玩家输入、请求服务器验证等)、Client RPC(服务器调用客户端函数,用于更新UI、播放特效等客户端特定操作)、Multicast RPC(服务器调用所有客户端的函数,用于同步游戏事件、播放音效等需要所有玩家看到的效果)。RPC函数使用UFUNCTION(Server)、UFUNCTION(Client)、UFUNCTION(NetMulticast)等宏标记,引擎会自动处理网络传输、可靠性、安全性等问题,确保函数调用能够正确地在网络环境中执行,同时提供参数验证、权限检查等安全机制防止作弊。
到目前为止我们发现UE的宏作用非常大,包括类定义(使用UCLASS()宏标记类,让类参与反射系统)、属性声明(使用UPROPERTY()宏暴露属性给蓝图和编辑器)、函数声明(使用UFUNCTION()宏暴露函数给蓝图和网络系统)、网络复制(使用Replicated宏标记需要同步的属性)、RPC函数(使用Server、Client、NetMulticast宏标记网络函数)、委托声明(使用DECLARE_DELEGATE等宏声明委托类型)、模块定义(在.Build.cs文件中使用模块相关的宏)、插件开发(使用插件相关的宏定义插件结构)、自定义编辑器工具(使用编辑器相关的宏集成到UE编辑器中)、资产类型(使用资产相关的宏定义自定义资产类型)等等...一般我们在C++中讨论的宏的作用都是简单的文本替换,而在UE中却大放异彩,我们不禁想问,宏的本质到底是什么,是什么导致了UE中的宏如此重要?
宏的本质是编译时的代码生成和元编程工具 ,传统C++中宏主要用于简单的文本替换,但在UE中宏的作用被大大扩展了。UE中宏如此重要的根本原因是UE需要实现复杂的跨系统集成,包括C++和蓝图的互操作、反射系统、网络复制、编辑器集成等功能,这些功能需要大量的样板代码和元数据。UE使用了自己的构建工具链(Unreal Build Tool),在编译过程中会扫描这些宏并生成相应的C++代码,比如UCLASS()宏会生成反射信息、序列化代码、垃圾回收支持等,UPROPERTY()宏会生成属性访问器、网络复制代码、编辑器集成等。这种设计让开发者只需要用宏"标记"一下,就能自动获得完整的引擎功能支持,大大简化了开发复杂度,这就是为什么UE的宏系统如此强大和重要,它们不仅仅是文本替换,而是整个引擎架构的基石。
如何在虚幻引擎中实现网络游戏?
在虚幻引擎中实现网络游戏主要通过GameMode、PlayerController和网络组件来构建,首先需要设置网络模式(客户端-服务器或P2P),然后使用Replicated属性标记需要同步的游戏状态,使用RPC函数处理客户端和服务器之间的通信。GameMode负责管理游戏规则和玩家生成,PlayerController处理玩家输入和客户端逻辑,网络组件负责具体的网络通信。实现过程中需要区分服务器权威逻辑和客户端预测逻辑,使用网络预测减少延迟感知,通过Actor复制确保所有客户端看到相同的游戏状态,使用RPC函数处理玩家输入、游戏事件、UI更新等。同时需要处理网络延迟、带宽优化、反作弊等问题,使用UE提供的网络调试工具进行测试和优化,确保网络游戏的稳定性和公平性。
和Unity相比呢?
UE已经集成了完整的网络通信框架,开发者不需要像Unity那样手动处理底层的Socket连接。UE提供了GameMode、PlayerController、网络组件等高级抽象,以及Replicated属性、RPC函数等便捷的网络功能,开发者只需要配置网络模式(客户端-服务器或P2P),标记需要同步的属性,使用RPC函数处理通信,引擎会自动处理底层的网络连接、数据传输、同步逻辑等复杂细节。而Unity需要开发者自己实现Socket连接、数据序列化、状态同步等底层功能,或者使用第三方网络库。这就是为什么UE在网络游戏开发方面更加便捷,引擎已经处理了大部分网络通信的复杂性,让开发者可以专注于游戏逻辑的实现。
如何理解网络带宽优化?网络带宽优化的技术有哪些?
网络带宽优化是为了减少网络数据传输量,提高网络游戏性能的技术,因为网络带宽是有限的资源,过多的数据传输会导致延迟增加和游戏卡顿。UE的网络带宽优化技术包括数据压缩(对网络数据进行压缩减少传输量)、预测编码(只传输数据变化的部分而不是完整数据)、优先级管理(重要数据优先传输,次要数据延迟传输)、LOD系统(根据距离和重要性使用不同精度的数据)、插值技术(客户端预测中间帧减少服务器更新频率)、量化压缩(将浮点数转换为整数减少数据大小)、条件复制(只向需要的客户端发送数据)、批量传输(将多个小数据包合并成大数据包减少网络开销)。
什么是网络预测?如何在虚幻引擎中处理网络延迟?虚幻引擎的网络调试工具有哪些?
网络预测是客户端在收到服务器确认之前就执行操作的技术,通过预测服务器的响应来减少玩家感知的延迟,比如玩家移动时客户端立即更新位置,然后等待服务器确认,如果预测错误再进行修正。在UE中处理网络延迟主要通过Lag Compensation(延迟补偿,服务器回滚到玩家操作时的状态进行验证)、网络平滑(客户端插值平滑处理网络抖动)、预测回滚(客户端预测服务器响应,出错时回滚到正确状态)、带宽优化(减少数据传输量降低延迟)等技术。UE的网络调试工具包括Network Profiler(分析网络性能和数据传输)、Network Insights(可视化网络流量和延迟)、Stat Net(显示网络统计信息)、Network Debugger(调试网络连接和同步问题)、Packet Analyzer(分析网络数据包内容)等,这些工具帮助开发者识别网络问题、优化网络性能、调试网络同步错误。
虚幻引擎的AI系统架构是怎样的?
虚幻引擎的AI系统架构基于**Behavior Tree(行为树)、Blackboard(黑板)和AIController(AI控制器)**构建,其中行为树是AI决策的核心,通过节点式图形界面定义AI的行为逻辑和决策流程,支持复杂的条件判断和行为组合。黑板是AI的数据存储系统,用于存储AI需要的信息如目标位置、当前状态、环境数据等,支持数据共享和动态更新。AIController是AI的控制中心,负责管理AI的生命周期、处理感知输入、协调行为树和黑板,同时处理AI的移动、动画、网络同步等功能。整个AI系统还集成了感知系统(视觉、听觉、触觉)、寻路系统(NavMesh、NavLink)、群体AI(Mass AI)、机器学习集成等功能,提供完整的AI开发解决方案,支持从简单的巡逻AI到复杂的群体行为等各种AI需求。
那这里又不得不提经典的问题了:状态机和行为树的区别?
状态机和行为树都是AI决策系统,但状态机基于状态转换,每个状态代表AI的一个行为模式,通过条件触发状态切换,结构相对简单但扩展性有限,适合简单的AI逻辑。行为树基于任务执行,使用树形结构组织AI行为,通过选择器、序列、装饰器等节点组合复杂的决策逻辑,具有更好的可读性和扩展性,适合复杂的AI需求。
虚幻引擎的感知系统是什么?
虚幻引擎的感知系统是AI感知周围环境信息的机制,让AI能够"看到"、"听到"、"感觉到"周围的世界。感知系统包括视觉感知(AI能够看到视野范围内的玩家、物体、环境信息)、听觉感知(AI能够听到声音、脚步声、枪声等音频信息)、触觉感知(AI能够感知碰撞、接触等物理信息)。感知系统通过感知组件(Perception Component)实现,可以配置感知范围、感知角度、感知过滤器等参数,支持感知记忆(AI能够记住之前感知到的信息)、感知优先级(不同感知信息的重要性排序)、感知共享(多个AI之间共享感知信息)等功能。这个系统让AI能够做出更智能的决策,比如看到玩家时进行攻击、听到声音时进行搜索、感知到危险时进行躲避等,是AI行为系统的重要组成部分。
感知系统的底层原理基于几何检测和物理模拟,其中视线检测通过射线追踪(Raycast)实现,从AI的眼睛位置向目标方向发射射线,检测射线是否被障碍物阻挡,如果射线到达目标则AI"看到"了目标;听觉感知通过声音传播模拟实现,计算声源到AI的距离,考虑声音衰减、障碍物阻挡、环境音效等因素,确定AI是否能听到声音;触觉感知通过碰撞检测实现,当AI与其他物体发生物理接触时触发感知事件。感知系统还使用空间分区(如四叉树、八叉树)来优化检测性能,只检测AI周围相关区域的对象,同时支持感知记忆,AI会记住之前感知到的信息并在一定时间内保持这些记忆,实现更智能的感知行为。
如何在UE中实现群体行为?
在UE中实现群体行为主要通过Mass AI系统和群体模拟技术来实现,Mass AI是UE5的新一代AI系统,专门用于处理大量AI实体的群体行为,通过ECS(Entity Component System)架构高效管理成千上万的AI实体。群体行为实现包括聚集行为(AI向群体中心聚集)、分离行为(AI之间保持距离避免碰撞)、对齐行为(AI朝向群体平均方向)、避障行为(AI避开障碍物和其他AI)、跟随行为(AI跟随领导者)等。UE还提供了群体调试工具来可视化群体行为,支持群体行为的参数调整和性能优化,通过Mass AI系统可以实现高效的群体模拟,让大量AI实体能够表现出自然的群体行为,同时保持良好的性能表现。
虚幻引擎的UI系统有哪些?主要组件有哪些?如何创建自定义UI控件?
虚幻引擎的UI系统主要包括UMG(Unreal Motion Graphics)和Slate两个框架,UMG是专门为游戏UI设计的可视化UI系统,提供Widget Blueprint、Widget Component、HUD等组件,支持拖拽式UI设计和蓝图编程;Slate是UE的底层UI框架,用于编辑器界面和复杂UI实现,提供更底层的控制能力。UMG的主要组件包括Widget Blueprint(UI蓝图,用于设计UI界面)、Widget Component(UI组件,可以将UI附加到3D对象上)、HUD(平视显示器,用于游戏内UI显示)、User Widget(用户控件,UI的基本单位)等。创建自定义UI控件需要继承UUserWidget类,使用UCLASS()宏标记,实现自定义的UI逻辑和样式,可以通过C++编写复杂的UI功能,然后在蓝图中使用这些自定义控件,实现更灵活和强大的UI系统。
UMG和Slate的区别在于使用场景和复杂度,UMG是专门为游戏开发者设计的高级UI框架,提供可视化的Widget Blueprint编辑器,支持拖拽式UI设计,适合快速创建游戏界面,主要面向游戏UI开发,使用简单但功能相对有限。Slate是UE的底层UI框架,用于构建编辑器界面和复杂的UI系统,提供更底层的控制能力和更丰富的UI功能,但需要更多的编程知识,主要用于UE编辑器本身的界面开发。UMG实际上是基于Slate构建的,但提供了更友好的开发体验。
在UI中如何处理用户输入?和游戏中处理输入有何区别?
在UI中处理用户输入主要通过UMG的输入绑定系统 ,将键盘按键、鼠标点击、触摸事件等绑定到UI控件的特定函数上,同时使用焦点管理控制哪个控件处于活动状态,只有获得焦点的控件才能接收键盘输入,UI输入处理主要关注界面交互如按钮点击、菜单导航等。与游戏输入处理的区别在于,UI输入处理界面交互,使用UMG的输入绑定和焦点管理,这些输入通常不会传递给游戏逻辑;而游戏输入处理使用Enhanced Input System处理游戏操作如角色移动、射击等,直接影响游戏逻辑,两者需要协调工作,当UI处于活动状态时游戏输入通常会被屏蔽,避免UI操作意外触发游戏动作,UE的输入系统会智能地管理这种优先级确保不会冲突。
虚幻引擎的性能分析工具?
虚幻引擎的性能分析工具包括Unreal Insights(新一代性能分析工具,提供详细的CPU、GPU、内存分析)、GPU Visualizer(分析GPU渲染性能,显示渲染管线各阶段耗时)、Memory Profiler(分析内存使用情况,检测内存泄漏)、Stat命令(实时显示各种性能统计信息)、Performance Monitor(监控帧率、CPU使用率等关键指标)等。
虚幻引擎的内存管理优化技术有哪些?
虚幻引擎的内存管理优化技术包括对象池(预先分配对象,避免频繁的内存分配和释放)、内存碎片整理(定期整理内存碎片,提高内存使用效率)、垃圾回收优化(调整垃圾回收频率和策略,减少GC暂停时间)、智能指针(使用TSharedPtr、TWeakPtr等自动管理内存生命周期)、内存预分配(在游戏开始时预分配常用对象,避免运行时分配)、LOD系统(根据距离使用不同精度的资产,减少内存占用)、资产流送(动态加载和卸载资产,控制内存使用)、内存压缩(压缩不常用的数据,减少内存占用)、内存监控(实时监控内存使用情况,及时发现问题)、平台特定优化(针对不同平台的内存特性进行优化)等,这些技术共同作用确保游戏在有限内存环境下稳定运行。
虚幻引擎是如何实现跨平台的?
UE的跨平台原理是直接使用各个平台的原生编译工具链将C++代码编译成平台特定的机器码,UE没有自己的编译器,而是维护和使用Windows的Visual Studio、Mac的Xcode、Linux的GCC、移动平台的NDK等标准编译器,通过抽象层设计将不同平台的功能包装成统一接口,使用条件编译处理平台差异,为每个平台提供对应的实现代码,最终实现一套C++代码可以编译到Windows、Mac、Linux、移动平台、主机平台等多个平台,相比Unity的中间语言方式,UE直接编译到原生平台性能更好但维护成本更高。
虚幻引擎就差不多这样吧,这东西还得花时间慢慢学。
现在正式进入项目,我们从渲染和物理引擎这两个部分的项目开始吧,因为感觉好久没看了,用项目顺便回顾知识点了。
渲染
我学习渲染相关的知识主要包括GAMES101,LearnOpenGL,Unity的Shader以及UE的Nanite和Lumen,我们来一个一个复习一下。
首先是GAMES101:
我们用课后的作业来总结学习的内容吧,大体上来说是七次作业,分别是实现旋转/投影与三角形光栅化,引入 Z-buffer 做可见性与插值,搭建渲染管线并实现多种着色(Phong/法线/纹理/凹凸/位移),实现 Bézier 曲线(De Casteljau),进入光线追踪(光线与三角形求交、基础光照与渲染器框架),加入加速结构(如 BVH)以加速求交,实现路径追踪(直接/全局光照与重要性采样优化)。
渲染管线的大致流程是?
顶点着色器(到裁剪空间)→ 图元装配 → 裁剪 → 透视除法(到 NDC)→ 视口变换(到屏幕)→ 光栅化生成片元 → 片元着色 → 深度测试/混合。
光栅化的原理,作用和意义是什么?
光栅化的原理是把连续的几何图元(三角形等)在屏幕空间离散为像素片元:顶点经 MVP 变换到裁剪空间,透视除法到 NDC,再视口映射到屏幕后,对每个像素做覆盖判定(如边函数/重心坐标),并对深度与属性(颜色/法线/UV)做透视正确插值,通过深度测试保留最近片元写入颜色缓冲。其作用是高效、并行地把三维场景转换为二维图像,是实时渲染管线的核心阶段,与片元着色一起产生最终画面。
深度缓存是什么?如何实现的?
深度缓冲(Z-buffer)是给每个屏幕像素维护"当前最近"的深度值,用于片元可见性判定以确保遮挡关系正确;实现上,先分配与帧缓同尺寸的深度数组并每帧清为正无穷,光栅化时对覆盖像素用透视正确的重心坐标插值得到片元深度z,执行深度测试(z小于已存深度则通过),通过则更新该像素的深度与颜色,否则丢弃;可选支持不同比较函数、关闭深度写入或反向深度以提升稳定性与性能。
如何搭建的渲染管线,实现了哪些着色?
用 C++ 在 CPU 上自建了可编程渲染管线:顶点经模型/视图/投影(MVP)变换到裁剪空间,裁剪后做透视除法到 NDC,再视口变换到屏幕;随后对三角形做屏幕空间光栅化,用边函数判定覆盖,并对颜色/法线/UV/视空间坐标等做透视正确的重心插值;用深度缓冲做可见性(更小z通过)并写入帧缓;片元阶段通过可切换的片元"着色器"计算最终颜色。法线用逆转置矩阵变换到视空间,片元 payload 提供 view_pos/normal/texcoord/texture,光照采用两点光源的 Blinn-Phong(环境+漫反射+高光)。已实现的着色包括:法线可视化、Phong/Blinn-Phong、纹理着色(从纹理采样作为 kd)、凹凸贴图(TBN + 高度图梯度扰动法线)、位移贴图(按高度图微移位置并重算法线)。
什么是贝塞尔曲线?
贝塞尔曲线能让我们"用少量控制点"得到平滑曲线,但一般只严格经过"首末两个控制点",中间控制点用于"牵引形状"(不必在曲线上)。若要求"曲线逐点穿过你给定的一整串点",通常用分段贝塞尔/样条(如 Catmull-Rom、B 样条)或做拟合求控制点。
学习贝塞尔曲线能以少量参数高效表达平滑形状,比如曲面细分中有使用。在曲面细分里,贝塞尔做的事可以概括为:把粗糙的控制网(少量控制点)转成一块块可平滑评估的"贝塞尔补丁",渲染时根据屏幕需求把这些补丁自适应细分成更密的几何(微多边形),并且能直接、稳定地计算任意参数位置的点和法线,从而得到光滑外观。
如何理解光线追踪和路径追踪?
光线追踪是一种从相机(像素)向场景发射射线、寻找与几何体最近交点并按材质与光源模型计算光能贡献的成像方法;
光线追踪的典型流程是:对每个像素从相机发出主射线穿过成像平面,借助加速结构(如 BVH)在场景中求最近交点;未命中返回环境/背景色,命中则在交点处依据法线、材质与光源计算辐射亮度:先做直接光照(采样光源并发阴影射线判遮挡),再按材质生成后继射线------镜面/透明材质沿反射/折射方向递归追踪,漫反射/粗糙材质可按 BSDF 进行重要性采样累积间接光(Whitted 仅跟踪反射/折射,路径追踪用蒙特卡洛在半球上随机多次反弹);将各项贡献按能量守恒合成,并用递归/样本上限与(可选)俄罗斯轮盘终止控制代价,最终把每像素结果写入帧缓(现代流程常结合降噪与色调映射)。
路径追踪是用蒙特卡洛随机采样来数值求解渲染方程的光传输方法:从相机为每个像素发射主射线,命中后依据材质的BSDF按重要性随机采样出射方向并多次弹射,沿途累积直接与间接光照的贡献;通过俄罗斯轮盘控制路径长度以避免无限递归,理论上无偏且能自然呈现全局光照(软阴影、色溢、焦散等),但在样本数较低时会有噪点。
这里可能要复习一下这些概念,太久没复习看着这些名词都觉得怪怪的。
BSDF(双向散射分布函数)是一个统一的材质散射模型,包含反射的 BRDF 和透射(包含折射在内)的 BTDF,它不直接"指定一个唯一方向",而是给出从入射方向到各个出射方向的能量分配规律与相应的概率密度,我们据此进行随机采样来决定下一跳射线的方向,并用 BSDF 值与几何因子对贡献加权;俄罗斯轮盘是为避免路径无限延长的无偏截断方法,在每次弹射按某个存活概率 p 独立决定是否终止,若存活则把当前路径权重除以 p(保证期望不变),它不是"越没中越容易中"的递增几率游戏,而是每次独立抽样、通常依照当前通量/反照率或弹射深度自适应设置 p;"样本数较低会有噪点"里的样本,主要指每像素的路径条数(SPP,通常是一条主射线产生的一条完整随机弹射链),也可包含在某些弹射处对光源或半球的额外采样数,蒙特卡罗做的事就是用这些随机样本来近似积分,样本越多方差按约 1/√N 下降、噪点越少;渲染方程则是我们要解的目标:像素(或表面点)在出射方向上的辐射亮度等于自发光加上对所有入射方向的"入射亮度×BSDF×cosθ"的半球积分,它把直接光照、间接光、反射/透射、焦散等统一在同一能量守恒框架下,路径追踪正是用蒙特卡罗随机采样来数值求解这项积分。
简单地说,路径追踪是光线追踪的一种;传统光线追踪只沿确定的反射/折射与阴影射线走,速度快、画面干净但几乎没有间接光;路径追踪用随机采样来解渲染方程,能还原全局光照更真实但在低样本下会有噪点(可配合降噪)。
针对路径追踪如何降噪?
路径追踪先把每个像素累加得到的颜色存在一个 framebuffer 里(每像素做 SPP 次随机采样求平均),渲染结束后把这个 framebuffer 转成一张 OpenCV 的浮点彩色图(CV_32FC3),然后做两种图像后处理降噪方案:默认方案是"保边去噪 + 轻微平滑",先按 SPP 自适应设置强度(样本少就更强,样本多就更弱),用双边滤波在尽量不糊边缘的情况下压噪,比如窗口大小 15,sigmaColor = 0.1 * (16/spp)、sigmaSpace = 10,再接一遍很小的 3×3 高斯模糊把残留的小颗粒点抹匀;高级方案是把图像临时转成 8 位,跑 OpenCV 的彩色非局部均值去噪(fastNlMeansDenoisingColored),同样按 SPP 调整强度参数 h = 10 * (16/spp),最后再转回浮点图;两种方式都属于"图像空间后处理",不需要额外的法线、深度或反照率辅助通道,做完去噪再进行简单的伽马/色调映射并输出 raw_output.ppm 与 denoised_output.png,整体思路就是渲染先出一张有噪的低样本结果,再根据样本多少自适应地做保边滤波把噪点压下去。
如何利用CUDA进行渲染的加速?
把场景数据(顶点/三角形/材质/BVH)打平成连续数组或SoA并上传到显存(本项目还用到了__constant__常量区),保证对齐与合并访问;把CPU里的递归(反射/折射与BVH遍历)改成GPU友好的迭代/显式栈或无栈遍历,并用"路径状态"结构体在单个线程内推进多次弹射与俄罗斯轮盘;为每个线程初始化独立RNG(如curand)做采样,避免相关性;控制分支发散(不同材质、是否命中/阴影、反射/折射都会让warp发散),必要时做代码重排或阶段化(wavefront)以提升占用;调优线程块、寄存器与访存,尽量做到合并读、减少全局原子操作,BVH/三角数据可用纹理/常量内存加速;处理数值稳健性(float主导、自相交epsilon、法线修正)以减少"黑斑/漏光";最后把GPU端帧缓回拷到主机,做去噪与色调映射(本项目用OpenCV双边/非局部均值降噪,CPU端完成)。
然后是我们的LearnOpenGL中的内容:
如何理解PBR材质?具体在代码中如何实现?
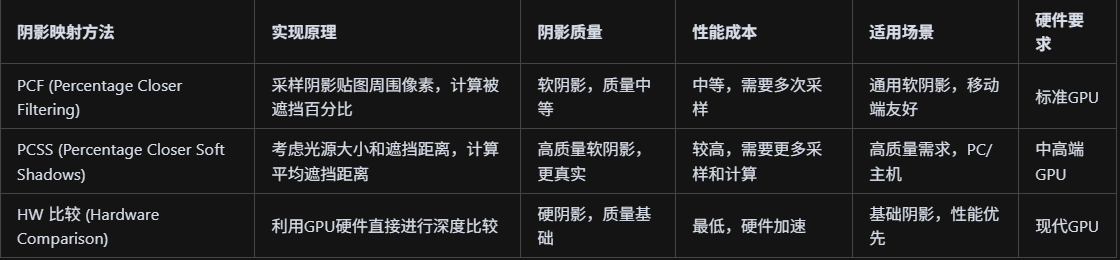
有哪些阴影映射方法?底层原理是什么?
如何基于计算着色器来优化SSAO/Bloom等后处理效果?
如何在OpenGL中实现GPU实例化?
然后是Unity的Shader的内容:
Unity的Shader是什么?
Unity 的 Shader 是在 GPU 上运行、用 HLSL(由 ShaderLab 包装)编写的渲染程序,用于定义网格的顶点与像素如何被变换与着色,进而决定材质外观(如光照、纹理、透明、后处理等),本质上是 Unity 渲染管线的可编程阶段。
Unity 在 ShaderLab 外壳里使用标准 HLSL,并提供一套自己的宏、内置变量与编译指令(同时兼容早期 Cg 语法习惯,如 fixed/half、UnityCG.cginc 等)。
什么是ShaderLab、HLSL、Surface Shader、Shader Graph?它们关系与取舍?
ShaderLab是Unity的着色器配置外壳,用来描述属性、SubShader/Pass及渲染状态;HLSL是真正在GPU上执行的着色代码,写在ShaderLab的程序块中并由Unity跨平台编译;Surface Shader是Built-in渲染管线下的高层语法,自动生成包含光照/阴影的HLSL,开发快但控制力较弱;Shader Graph是可视化节点工具,面向URP/HDRP,快速迭代与协作友好,遇到复杂需求可用自定义函数或自定义Pass扩展;取舍上,追求极致控制与性能用ShaderLab+手写HLSL,内置管线标准光照快速落地用Surface Shader,URP/HDRP常规材质与效果首选Shader Graph且必要时混合自定义代码,一句话:三者都以HLSL为落地执行,ShaderLab负责组织与配置。
这里补充一下Unity的几种渲染管线:

除自定义外,Unity 主流有 Built-in、URP、HDRP 三条管线;Built-in 以经典 Lambert/Blinn-Phong 为主,兼容旧项目与维护成本低但扩展性弱、物理一致性与画质一般;URP 面向多平台与性能,采用简化 PBR、前向渲染并支持 Renderer Feature/自定义 Pass,内置 Volume 后处理(如 Bloom、DOF、Color Grading、SSAO 等),反射以探针/平面反射为主(SSR在部分版本为实验或需自研);HDRP 面向高端 PC/主机,全面 PBR 与物理相机/曝光、体积光、区域光、Decal、SSR/SSGI 等高级特性,画质最强但成本与平台要求最高;可以概括为从 Built-in→URP→HDRP 画面与物理一致性递增、功能更全,但运行成本与对平台的要求也升高,其中 URP 跨平台与性能最均衡,HDRP 最写实,Built-in 最兼容存量资产。
Forward 与 Deferred 渲染的差异、优缺点及典型使用场景?
Forward 渲染是在物体逐灯光逐片元直接做光照,管线简单、内存带宽占用低、透明物体与MSAA原生友好,但灯光数增加时代价线性上升(每个物体重复被多光照),适合移动端/VR/透明大量/风格化与低光源场景;Deferred 渲染先用几何通道输出G-Buffer(法线/反照率/粗糙度/深度等),再在屏幕空间一次性累加光照,能高效处理大量动态光、便于做SSAO/SSR/体积光等屏幕空间效果,画质与灵活性强,但对显存与带宽要求高、透明支持差(透明通常回退Forward)、与MSAA天然不合(常用TAA/FXAA或特殊方案)、在移动端与低端GPU上性价比差;典型选择是移动/VR/少灯场景用Forward(或Forward+以缓解多灯瓶颈),PC/主机、PBR且多动态灯的大场景用Deferred,而在Unity中URP多用Forward/Forward+,HDRP默认Deferred并对透明分层走Forward混合。
简单地说,场景几何只绘制一次写入 G-Buffer,随后在屏幕空间仅对被灯覆盖的像素做光照累加,因此在大量动态光、几何复杂或 overdraw 高的场景中更稳更高效,并更易叠加 SSAO/SSR 等屏幕空间效果。
Properties / SubShader / Pass / Tags 的作用?常见 Tag(如 RenderType、Queue)的用途?
Properties 定义材质面板中可调节的参数(如贴图、颜色、数值),供美术或脚本动态修改;SubShader 是渲染管线的备选方案,按硬件能力或渲染特性排序,引擎会选第一个兼容的;Pass 是具体的渲染通道,包含顶点/片元着色器代码和渲染状态设置,一个 SubShader 可有多个 Pass(如正向/阴影/深度预通道等);Tags 是给渲染引擎的元数据,RenderType 告诉引擎这是什么类型的物体(如 Opaque/Transparent/Background),Queue 控制渲染顺序(如 Background/Geometry/Transparent/Overlay),还有 IgnoreProjector 避免被投影器影响、ForceNoShadowCasting 强制不投射阴影等,这些 Tag 帮助引擎做正确的渲染排序、剔除、后处理与阴影处理。
Surface Shader、Shader Graph 最终如何落地到 HLSL?各自适用场景?
Surface Shader 是 Unity 内置管线的代码生成器,你写一个 surface function 描述表面属性(如 Albedo、Normal、Emission),Unity 自动生成包含光照/阴影/前向/延迟等完整 Pass 的 HLSL,开发快但控制力弱且不支持 URP/HDRP;Shader Graph 是可视化节点编辑器,你连接各种节点(采样、数学运算、光照模型等),Unity 实时生成对应的 HLSL 代码,深度集成 URP/HDRP 且支持自定义函数节点和自定义 Pass,迭代快、协作友好但复杂自定义时受限;两者最终都会生成标准的顶点/片元着色器 HLSL 代码,由 Unity 跨平台编译到 GPU 执行,Surface Shader 适合 Built-in 管线的标准材质快速开发,Shader Graph 适合 URP/HDRP 的现代工作流和美术协作,当需要极致控制或复杂特效时仍可混合手写 HLSL 的自定义函数或自定义 Pass。
顶点到片元的数据插值流程(语义、插值精度、透视校正)?
顶点着色器输出的数据通过光栅化阶段自动插值传递给片元着色器,插值过程遵循透视校正:距离摄像机越远的像素插值权重越小,确保在透视投影下插值结果正确;插值精度由数据类型决定,float 是最高精度但带宽成本高,half 是中等精度适合大部分计算,fixed 是低精度但移动端性能好,Unity 会根据平台自动优化精度;语义方面,POSITION 输出裁剪空间坐标,TEXCOORD 系列传递 UV 坐标、法线、切线等自定义数据,COLOR 传递顶点色,SV_POSITION 是片元着色器输入的系统语义表示屏幕坐标;插值过程中,法线需要重新归一化,切线空间变换需要构建 TBN 矩阵,世界坐标和视线方向等需要从顶点传递到片元进行插值,最终在片元着色器中得到每个像素的插值数据用于光照计算。
常见的空间转换矩阵和坐标系?
Unity 中常见的空间变换矩阵包括 unity_ObjectToWorld 将顶点从对象空间转换到世界空间,UNITY_MATRIX_VP 是视图投影矩阵将世界坐标转换到裁剪空间,UNITY_MATRIX_M 是模型矩阵等同于 unity_ObjectToWorld,还有 unity_WorldToObject 是对象到世界矩阵的逆矩阵用于法线变换;坐标系方面,对象空间是模型自身的局部坐标系,世界空间是场景的全局坐标系,视图空间是摄像机为中心的坐标系,NDC 是标准化设备坐标用于裁剪,切线空间是以顶点法线为 Z 轴、切线为 X 轴、副切线为 Y 轴的局部坐标系用于法线贴图;变换流程通常是对象空间→世界空间→视图空间→裁剪空间→NDC→屏幕空间,法线从对象空间到世界空间需要用 unity_WorldToObject 的转置矩阵,切线空间法线贴图需要构建 TBN 矩阵进行空间转换。
Lambert、Blinn-Phong 与 PBR(金属度-粗糙度)的核心差异与实现要点?
Lambert 是最基础的漫反射模型,只考虑表面法线与光源方向的点积,实现简单但缺乏真实感,适合风格化渲染;Blinn-Phong 在 Lambert 基础上增加了高光项,用半程向量(视线方向与光源方向的中间向量)与法线的点积计算高光,比 Phong 模型更高效且效果更自然,但仍是经验模型;PBR 基于物理的渲染模型,使用金属度-粗糙度工作流,金属度控制材质是金属还是电介质,粗糙度控制微表面分布从而影响反射的锐利程度,BRDF 函数更复杂但能准确模拟真实世界的材质特性。
IBL(环境光照)采样、反射/折射、Fresnel 近似(Schlick)如何实现?
IBL 环境光照通过预计算的立方体贴图(通常是天空盒)实现,用表面法线作为采样方向获取环境光照颜色;反射用 Unity 内置的 reflect 函数计算反射方向(视线方向关于法线的反射),然后用反射方向采样环境 Cubemap 或屏幕空间反射;折射用 refract 函数计算折射方向(根据折射率),同样用折射方向采样环境贴图;Fresnel 效应用 Schlick 近似公式实现,F0 是基础反射率,用视线方向与法线的点积计算 Fresnel 系数,边缘反射强、正面反射弱,这些效果组合使用能模拟真实的水面、玻璃、金属等材质的光照表现。
阴影映射(PCF/PCSS/HW 比较)在 Built-in/URP/HDRP 的差异与要点?
阴影映射在 Unity 不同管线中的实现差异较大:Built-in 管线使用传统的阴影映射,支持 PCF 软阴影但质量有限,阴影距离和分辨率受限制,性能相对较低;URP 管线优化了阴影映射性能,支持级联阴影映射(CSM)和软阴影,但功能相对简化,适合移动端和中等画质需求;HDRP 管线提供最先进的阴影技术,支持屏幕空间阴影(Screen Space Shadows)、距离场阴影(Distance Field Shadows)、体积阴影(Volumetric Shadows)等,阴影质量最高但计算成本也最高,适合高端 PC 和主机平台。
PCF(Percentage Closer Filtering)是软阴影的基础技术,通过采样阴影贴图周围多个像素并计算被遮挡的百分比来产生软阴影效果,原理是在阴影比较时不仅检查当前像素是否被遮挡,还检查周围像素的遮挡情况,然后取平均值作为软阴影强度;PCSS(Percentage Closer Soft Shadows)是更高级的软阴影技术,不仅考虑遮挡百分比,还考虑光源大小和遮挡物的距离,通过计算遮挡物的平均距离来调整软阴影的软硬程度,能产生更真实的软阴影效果;HW 比较(Hardware Comparison)是硬件加速的阴影比较,利用 GPU 的硬件功能直接进行深度比较,比软件实现更快,但功能相对简单,主要用于硬阴影或作为其他软阴影技术的基础。
Unity的Shader中有哪些常见的纹理采样模式?纹理采样一般发生在渲染管线的哪个阶段?
Unity Shader 中常见的纹理采样模式包括点采样 (Point/Nearest Neighbor)直接取最近像素值,双线性采样 (Bilinear)对周围四个像素进行插值,三线性采样 (Trilinear)结合 MIP 层级进行插值,各向异性采样(Anisotropic)处理倾斜视角下的纹理压缩,立方体贴图采样(Cubemap)用于环境反射和 IBL;纹理采样主要发生在片元着色器(Fragment Shader)阶段,因为只有在这个阶段才能获得精确的 UV 坐标和进行逐像素的颜色计算,顶点着色器虽然也可以采样纹理但通常只用于顶点级别的计算,片元着色器中的纹理采样会直接影响最终像素的颜色输出,是光照计算、材质表现和特效实现的核心环节。
贴图压缩格式(BC/ETC/ASTC)对画质与带宽的影响与选择策略?
BC 格式(如 BC1/BC3/BC7)主要用于 PC 平台,BC1 适合无透明度的贴图且压缩率高但质量一般,BC3 支持 Alpha 通道但压缩率稍低,BC7 质量最好但压缩率最低;ETC 格式主要用于 Android 平台,ETC1 不支持 Alpha 通道但压缩率高,ETC2 支持 Alpha 但压缩率稍低;ASTC 格式是新一代压缩标准,支持多种压缩率(如 4x4、6x6、8x8),质量好且压缩率高,但需要较新的硬件支持;选择策略上,PC 平台优先考虑 BC7 获得最佳质量,移动端 Android 用 ETC2,iOS 用 ASTC,对于法线贴图等对质量敏感的贴图使用更高质量的压缩格式,对于细节较少的贴图可以使用更高压缩率,平衡画质和带宽需求。(这里的带宽指的是 GPU 从显存读取纹理数据到着色器处理单元时的数据传输量,具体来说就是纹理贴图在显存和 GPU 之间传输时占用的数据量大小)
介绍`ZTest`、`ZWrite`、`Cull`、`Blend`这四个渲染状态。
ZTest 控制深度测试的通过条件,如 LEqual(小于等于通过)、Always(总是通过)、GEqual(大于等于通过),关闭时所有像素都通过深度测试;ZWrite 控制是否将当前像素的深度值写入深度缓冲,开启时写入深度缓冲用于后续像素的深度测试,关闭时不写入;Cull 控制面剔除,Back 剔除背面(只渲染正面),Front 剔除正面(只渲染背面),Off 不剔除(双面渲染);Blend 控制颜色混合模式,如 SrcAlpha OneMinusSrcAlpha(标准透明混合)、One One(加法混合)、One OneMinusSrcAlpha(预乘透明混合),关闭时不进行混合直接覆盖。
渲染状态参数写在 ShaderLab 的 Pass 块中,具体位置在 CGPROGRAM 或 HLSLPROGRAM 之前。
cs
Shader "Custom/ExampleShader"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
_Color ("Color", Color) = (1,1,1,1)
_Glossiness ("Smoothness", Range(0,1)) = 0.5
_Metallic ("Metallic", Range(0,1)) = 0.0
}
SubShader
{
Tags { "RenderType"="Opaque" "Queue"="Geometry" }
Pass
{
// 渲染状态设置
ZTest LEqual // 深度测试:小于等于通过
ZWrite On // 深度写入:开启
Cull Back // 面剔除:剔除背面
Blend SrcAlpha OneMinusSrcAlpha // 混合模式:标准透明混合
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_fog
#include "UnityCG.cginc"
sampler2D _MainTex;
float4 _MainTex_ST;
float4 _Color;
float _Glossiness;
float _Metallic;
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
float3 normal : NORMAL;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
float3 worldNormal : TEXCOORD1;
float3 worldPos : TEXCOORD2;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldPos = mul(unity_ObjectToWorld, v.vertex).xyz;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = tex2D(_MainTex, i.uv) * _Color;
return col;
}
ENDCG
}
}
}半透明排序问题的处理思路?
首先按深度从远到近排序半透明物体,确保远处的透明物体先渲染,近处的后渲染,这样混合结果才正确;使用透明度预通道技术,先渲染所有不透明物体,再按深度排序渲染半透明物体,避免透明物体之间的错误混合;对于复杂透明物体,可以使用双通道渲染,先渲染背面再渲染正面,确保正确的深度顺序;在 Shader 中设置正确的混合模式(如 SrcAlpha OneMinusSrcAlpha)和深度测试(ZTest LEqual ZWrite Off),确保透明物体不写入深度缓冲但进行深度测试。
Stencil是什么?典型用途?
Stencil(模板缓冲)是 GPU 的一个特殊缓冲区,用于控制哪些像素被渲染,每个像素都有一个模板值,可以通过比较和修改模板值来控制渲染;典型用途包括描边效果,先渲染物体到模板缓冲,再渲染稍大的物体作为描边;UI 裁剪,用模板缓冲标记 UI 区域,只在该区域内渲染 UI 元素;门户/体积标记,用模板缓冲标记特殊区域,控制后续渲染;合成控制,用模板缓冲控制多个渲染结果的合成方式;反射/折射,用模板缓冲标记反射/折射区域,避免重复渲染;深度预通道,用模板缓冲优化透明物体的渲染顺序;这些用途的核心思想是用模板缓冲作为"遮罩",精确控制哪些像素参与渲染,实现复杂的渲染效果和性能优化。
如何理解屏幕空间后处理效果?有哪些常见的后处理?
屏幕空间后处理效果是对整张屏幕图像进行处理的渲染技术,先将场景渲染到 RenderTexture,再用后处理 Shader 对每个像素进行处理,最后输出到屏幕;常见后处理包括 Bloom(泛光效果),通过提取高亮区域并模糊产生发光效果;景深(Depth of Field),根据深度信息模糊前景或背景;运动模糊(Motion Blur),根据物体运动方向进行模糊;色彩校正(Color Grading),调整色调、饱和度、对比度等;抗锯齿(Anti-aliasing),如 FXAA、TAA 等平滑边缘;屏幕空间环境光遮蔽(SSAO),模拟环境光遮蔽提升真实感;屏幕空间反射(SSR),在屏幕空间计算反射;边缘检测描边,通过检测颜色或深度变化产生描边效果;扭曲效果,通过扰动 UV 坐标产生扭曲;这些后处理可以叠加使用,通过 Volume 系统或自定义后处理管线实现,提升画面表现力和真实感。
Volume 系统又是什么?
Volume 系统是 Unity URP/HDRP 中的后处理管理框架,用于组织和控制各种后处理效果。
GPU Instancing 与 SRP Batcher是什么?如何在Unity的Shader中使用?
GPU Instancing 是 Unity 的批量渲染优化技术,允许一次性渲染大量相同网格的实例,减少 DrawCall 数量;SRP Batcher 是 Scriptable Render Pipeline 的批处理优化,将使用相同 Shader 变体的多个对象合并到一个批次中,减少 CPU 开销;在 Shader 中使用 GPU Instancing 需要添加 #pragma multi_compile_instancing 指令,声明实例化相关的宏,用 UNITY_INSTANCING_BUFFER_START/END 定义实例属性,用 UNITY_ACCESS_INSTANCED_PROP 访问实例属性;SRP Batcher 要求 Shader 使用 CBUFFER 或 GPU 实例化,避免每对象设置材质属性,通过 SRP Batcher 可以显著减少 CPU 开销
Compute Shader是什么?有哪些应用场景?
Compute Shader 是 GPU 的通用计算着色器,不参与图形渲染管线,而是直接在 GPU 上执行并行计算任务;它使用 HLSL 编写,通过 numthreads 定义线程组大小,用 StructuredBuffer 或 RWStructuredBuffer 进行数据读写,支持 Barrier 同步线程;典型应用场景包括粒子系统,在 GPU 上计算粒子位置、速度、生命周期等属性,然后通过 GPU Instancing 批量渲染;GPU Transform,在 GPU 上计算大量物体的变换矩阵,避免 CPU 瓶颈;物理模拟,如布料、流体、软体等复杂物理计算;图像处理,如模糊、边缘检测、降噪等后处理效果;几何处理,如 LOD 计算、顶点动画、程序化几何生成;数据压缩/解压,利用 GPU 并行能力加速数据处理;这些应用的核心优势是充分利用 GPU 的并行计算能力,将计算密集型任务从 CPU 转移到 GPU,显著提升性能,特别适合处理大量数据或复杂计算任务。
如何理解Unity Shader中的变体与关键词管理?
Unity Shader 中的变体(Variants)是由不同关键词组合生成的 Shader 版本,每个变体都是完整的 Shader 代码;关键词管理通过 #pragma shader_feature 和 multi_compile 指令实现,shader_feature 在构建时根据使用情况决定是否包含变体,multi_compile 会生成所有可能的变体组合;变体爆炸是指关键词数量增加时,变体数量呈指数增长,如 10 个关键词可能产生 1024 个变体,导致构建时间过长和包体过大;管理策略包括使用 shader_feature 而非 multi_compile,在构建时剔除未使用的变体;使用变体剔除(Variant Stripping)移除不需要的变体;合理组织关键词,避免不必要的组合;使用全局和局部关键词,全局关键词影响所有 Shader,局部关键词只影响特定 Shader;关键词数量有限制(通常 256 个),需要合理分配;变体管理是 Shader 性能优化的重要环节,需要在功能性和性能之间找到平衡。
bash
Shader "Custom/VariantExample"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
_Color ("Color", Color) = (1,1,1,1)
}
SubShader
{
Tags { "RenderType"="Opaque" }
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
// 关键词定义 - 这些就是关键词
#pragma shader_feature _USE_TEXTURE
#pragma shader_feature _USE_COLOR
#pragma multi_compile _LIGHT_DIRECTIONAL _LIGHT_POINT _LIGHT_SPOT
#pragma multi_compile _SHADOW_ON _SHADOW_OFF
#include "UnityCG.cginc"
sampler2D _MainTex;
float4 _Color;
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = v.uv;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
// 根据关键词选择不同的渲染逻辑
#ifdef _USE_TEXTURE
col = tex2D(_MainTex, i.uv);
#endif
#ifdef _USE_COLOR
col *= _Color;
#endif
#ifdef _LIGHT_DIRECTIONAL
// 方向光计算
col *= 1.2;
#elif defined(_LIGHT_POINT)
// 点光源计算
col *= 1.0;
#elif defined(_LIGHT_SPOT)
// 聚光灯计算
col *= 0.8;
#endif
#ifdef _SHADOW_ON
// 阴影计算
col *= 0.7;
#endif
return col;
}
ENDCG
}
}
}