mKG-RAG: Multimodal Knowledge Graph-Enhanced RAG for Visual Question Answering
Authors: Xu Yuan, Liangbo Ning, Wenqi Fan, Qing Li
Deep-Dive Summary:
mKG-RAG:基于多模态知识图谱增强的RAG用于视觉问答
摘要
近年来,检索增强生成(Retrieval-Augmented Generation, RAG)被提出用于扩展多模态大型语言模型(Multimodal Large Language Models, MLLMs)的内部知识,通过将外部知识数据库融入生成过程,广泛应用于基于知识的视觉问答(Visual Question Answering, VQA)任务。尽管取得了令人瞩目的进展,但基于传统RAG的VQA方法依赖于非结构化文档,忽视了知识元素之间的结构化关系,常常引入无关或误导性的内容,从而降低了答案的准确性和可靠性。为了克服这些挑战,一个有前景的解决方案是通过引入结构化的多模态知识来增强生成过程。因此,在本文中,我们提出了一种基于多模态知识图谱(multimodal KGs)的全新多模态知识增强生成框架(mKG-RAG),用于知识密集型VQA任务。具体而言,我们的方法利用MLLM驱动的关键词提取和视觉-文本匹配,从多模态文档中提炼出语义一致且模态对齐的实体/关系,构建高质量的多模态知识图谱作为结构化的知识表示。此外,我们引入了一种双阶段检索策略,配备了问题感知的多模态检索器,以提高检索效率并优化精度。全面的实验表明,我们的方法显著优于现有方法,为基于知识的VQA设立了新的技术标杆。
1 引言
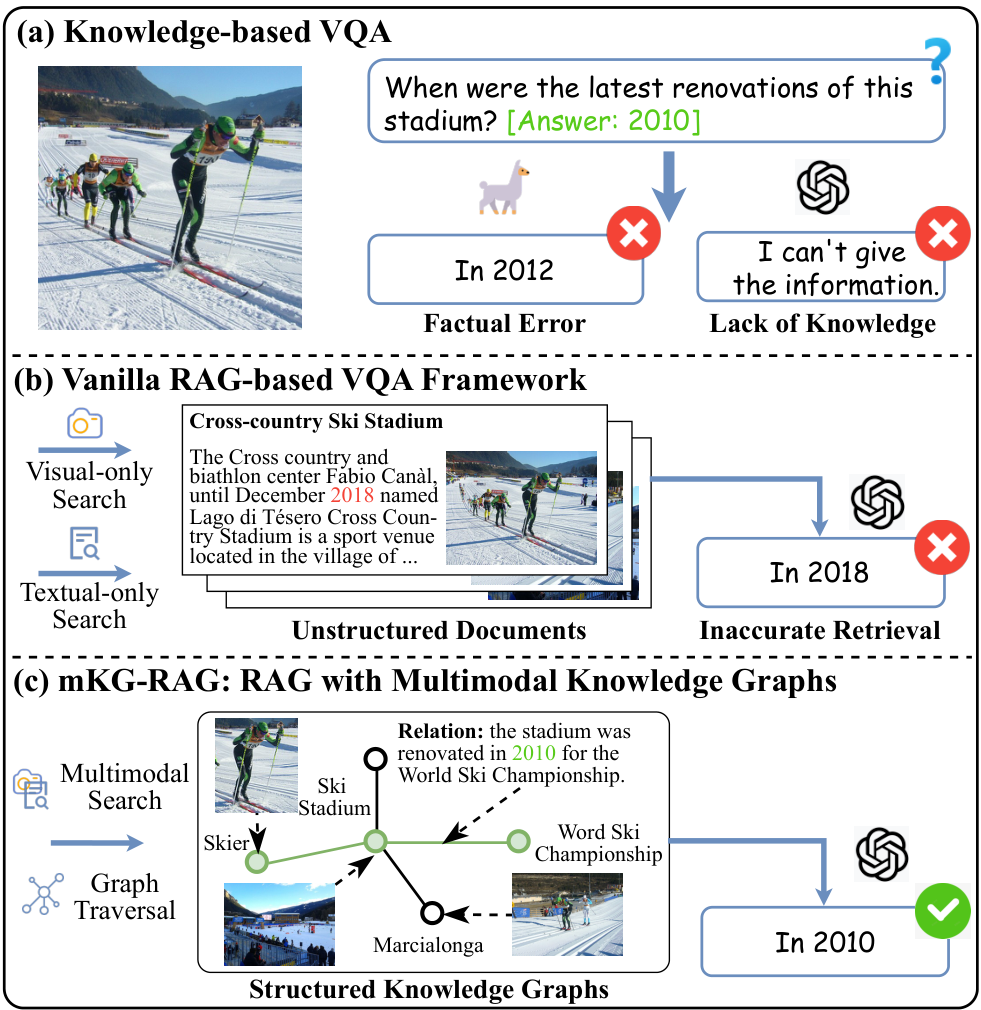
视觉问答(VQA)2, 19 是一项位于视觉与语言理解交叉领域的挑战性任务,要求模型能够解读图像并回答相关问题。这一能力在多个领域带来了显著的进步,包括医学图像诊断33和客户服务支持12。近年来,由于强大的视觉-语言理解和推理能力,多模态大型语言模型(MLLMs)35, 30, 50, 7 为传统的VQA任务提供了有前景的解决方案。例如,LLaVA 35 展示了与大型语言模型(LLMs)的推理能力相结合的强大表征能力。尽管取得了显著的进展,MLLMs 在知识密集型VQA场景40, 6(称为基于知识的VQA)中面临关键限制,特别是在需要百科全书式知识、长尾事实回忆或超出即时视觉输入的上下文推理的场景中。如图1(a)所示,当被问及体育场的最新翻新日期时,典型的MLLMs 表现出两种典型的失败模式:生成看似合理但事实上不正确的回答,或完全拒绝回答。这些问题源于MLLMs 训练语料中相关知识的稀缺以及记忆低频事实的固有困难6。
近年来,检索增强生成(RAG)16 在解决这些挑战方面显示出巨大潜力,通过利用外部知识数据库补充MLLMs 的内部知识,从而实现更准确的答案生成32, 4, 11。具体来说,从外部知识数据库中检索多个与查询相关的文档,并作为上下文信息增强MLLMs 的生成过程。尽管取得了成功,基于纯文本文档或段落的传统RAG方法在VQA中常常引入无关甚至误导性的信息38, 51,从而损害生成答案的准确性和可靠性。此外,这些方法通常忽略了知识元素之间的结构关系,限制了MLLMs 的推理能力。如图1(b)所示,嘈杂且非结构化的上下文使得MLLMs 难以识别和利用相关的支持证据。为了克服这些限制,一个有前景的方向是检索结构化知识,例如知识图谱(KGs)23 用于增强生成22, 15, 59。然而,在VQA设置中,由于涉及多模态推理,仅依赖文本KGs 是次优的,因为两种模态对于识别相关知识都至关重要。因此,将多模态知识图谱集成到检索增强的VQA框架中,为知识密集型场景生成可靠且精确的响应提供了更强大的解决方案,如图1©所示。
然而,从多模态知识图谱中检索相关知识以增强基于知识的VQA任务的生成过程极具挑战性。首先,现成的多模态KGs 36 通常围绕常见实体构建,常常缺乏知识密集型问题所需的百科全书式或长尾知识,使其在基于知识的VQA中直接使用无效。此外,当前用于基于知识的VQA的知识来源40, 6 通常以非结构化文档形式组织,包含大量的上下文噪声,难以提取构建高质量多模态KGs 所需结构化的实体和关系。此外,从数百万文档构建的大型知识图谱,每个文档可能包含数百个实体和关系,显著扩大了搜索空间。因此,在这样的图谱上直接进行检索在计算上效率低下,并对检索精度产生不利影响。
为了解决上述挑战,本文提出了mKG-RAG,一个新颖的检索增强生成框架,集成了多模态知识图谱,旨在增强MLLMs 在基于知识的VQA任务中的推理能力。具体来说,引入了一个多模态知识图谱构建模块,将非结构化的多模态文档(如维基百科文章)转化为结构化的知识表示。该模块利用MLLM驱动的关键词提取和视觉-文本对齐,从外部多模态文档中提取语义一致且模态对齐的实体和关系。为了实现高效检索,mKG-RAG 开发了一种双阶段搜索范式,结合了粗粒度的文档召回和细粒度的实体/关系检索。粗阶段通过识别可能包含相关证据的候选文档有效缩小搜索空间,而细阶段通过从这些可能噪声的文档动态构建的多模态KGs 中检索与查询相关的实体和关系来优化结果。在检索过程中,与之前依赖孤立单模态检索器的方法不同,我们引入了一个基于高质量问题-证据数据集训练的问题感知多模态检索器,以在提出的搜索范式中进一步提升检索精度。在两个常用基准上的全面评估表明,mKG-RAG 表现出色,在E-VQA 上实现了36.3%的准确率,在InfoSeek 上实现了40.5%的准确率。
本文的贡献总结如下:
- 我们提出了mKG-RAG,一个新颖的多模态知识增强生成框架,将RAG与多模态KGs 集成,以增强MLLMs 的知识推理能力。据我们所知,这是首次探索多模态知识图谱在知识密集型VQA任务中的潜力。
- 我们的框架开发了一个多模态KG构建流程,允许从多模态文档中提取图像-文本对齐的实体和关系。此外,双阶段检索模式结合问题感知多模态检索器,使我们能够充分发挥与多模态KGs 结合的RAG的潜力。
- 大量实验表明,mKG-RAG 显著优于强大的基线,在E-VQA 和InfoSeek 上建立了新的最先进结果。
2 相关工作
得益于大型语言模型(LLM)的快速发展 8, 49, 9, 57, 18, 17, 45, 42,多模态大型语言模型(MLLM)在各种视觉-语言任务中展现出了卓越的理解和推理能力 35, 50, 55。除了LLM主干之外,MLLM还包含两个关键组件:视觉编码器和视觉-语言集成模块。前者通常使用预训练的视觉编码器 14,而后者的设计差异较大,例如基于MLP的投影器 35、Perceiver 1 和 Q-Former 13。虽然MLLM在处理人类查询和解释视觉上下文方面表现出色,但它们仍然容易出现知识空白和幻觉问题。尽管这一问题是所有LLM固有的,但在MLLM中更为突出,原因是高质量、大规模多模态数据的可用性有限。
传统的视觉问答(VQA)基准 2, 19 主要在视觉上下文中评估视觉-语言理解能力,而知识密集型VQA通过要求超出图像内容的具体或详细知识显著增加了挑战。早期的基准如OK-VQA 39 和 A-OKVQA 48 强调了常识知识在VQA中的重要性,这可以通过在大规模多样化语料上训练的MLLM有效解决。然而,E-VQA 40 和 InfoSeek 6 引入了更大的挑战,涵盖了广泛的维基百科实体,并需要关于这些实体的细粒度知识。因此,现代MLLM往往无法准确回答此类问题,因为相关知识要么缺失,要么在训练数据中呈现长尾分布。
检索增强生成(RAG)常用于LLM中,以解决信息过时和幻觉等问题 16, 41。通过动态结合外部知识与模型的内置能力,RAG为需要广泛知识的任务提供了一种高效方法。受此启发,RA-VQA 31、Wiki-LLaVA 4 和 EchoSight 53 成功地将检索增强应用于知识密集型VQA,但它们的检索受到多模态查询与文本知识库之间模态差距的限制 29。近期研究 11, 56 利用MLLM从检索到的段落中识别相关信息,但这依赖于对MLLM的多次调用,导致推理开销显著增加。此外,现有的基于RAG的方法通常检索非结构化文档,忽视了检索来源中的噪声以及知识元素之间的逻辑关系。这导致知识嘈杂且无序,增加了MLLM的推理负担。为了应对这一挑战,近期研究开始探索使用知识图谱(KG),它提供了实体及其关系的结构化表示,以增强LLM的生成能力 22, 27, 15, 59, 38。然而,这些努力主要集中在文本KG上,多模态KG的潜力很大程度上尚未被探索。为了弥合这一差距,我们的工作首次将多模态KG集成到RAG框架中,专门为需要细粒度外部知识的视觉-语言任务设计。
3 提出的方法:mKG-RAG 3'
在基于知识的视觉问答(VQA)任务中,模型接收图像-问题对 ( I q , q ) (I_q, q) (Iq,q) 作为输入,并需要生成文本答案 a a a,可能利用可访问的知识库 B B B 作为额外的上下文。在我们的设定中,知识源由多模态文档组成。我们提出的多模态检索增强生成框架(mKG-RAG)的核心目标有两个:(1)有效地将非结构化的知识库 B B B 转换为结构化的多模态知识图谱(KG);(2)从多模态知识图谱中精确检索与查询相关的知识,同时捕捉潜在的结构关系,从而扩展多模态大语言模型(MLLMs)的知识范围。
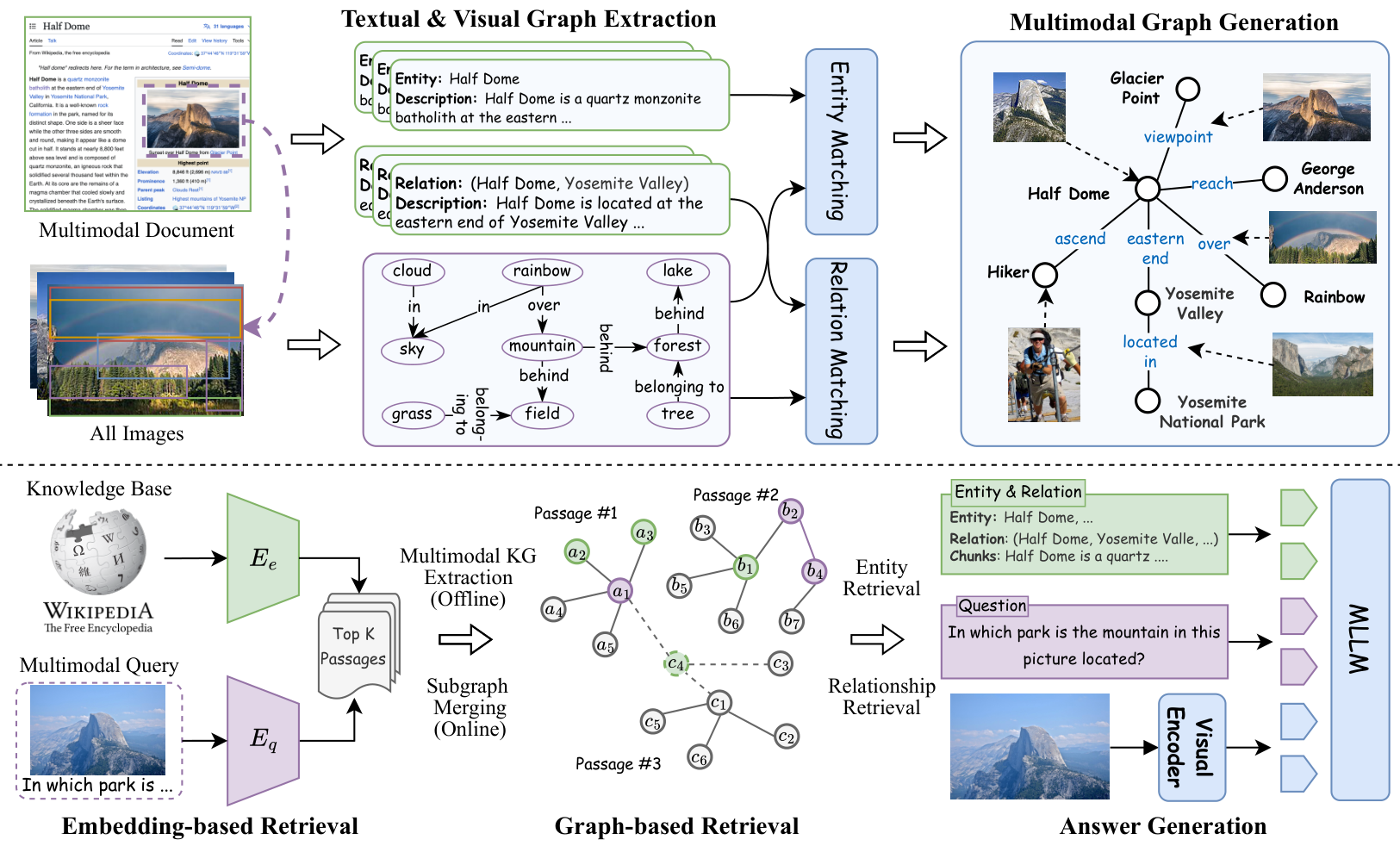
mKG-RAG 的视觉工作流程如图 2 所示,展示了两个关键创新点。首先,引入了一个多模态知识图谱构建流程,利用 MLLMs 将普通的多模态文档转换为结构化的知识表示,即图谱。然后,提出了一种双阶段检索范式,通过初始粗粒度向量搜索检索的文档子图,构建查询特定的多模态知识图谱,并在其上执行细粒度的图谱检索。
3.1 多模态知识图谱构建
现有的检索增强型视觉问答(VQA)模型在处理噪声上下文时面临困难,并且由于检索的是零散的文本片段,往往忽略了结构化关系。一个有前景的解决方案是从结构化知识来源(如知识图谱)中检索信息。然而,现成的多模态知识图谱(KG)36 通常是为常见实体设计的,不适合处理涉及详细或长尾知识的VQA案例,更不用说特定领域甚至私有知识。因此,本研究探索了一种有效的多模态知识图谱构建流程,从可访问的多模态文档中提取语义一致且模态对齐的实体和关系,以支持基于知识的VQA任务。具体而言,对于每个文档 ( T , I ) ∈ B (T, I) \in B (T,I)∈B,其中文章 T = { t 1 , . . . , t n } T = \{t_1, ..., t_n\} T={t1,...,tn} 通常包含多个部分, I = { i 1 , . . . , i m } I = \{i_1, ..., i_m\} I={i1,...,im} 是一组图像,我们首先将其分割成可管理的片段。没有图像的部分根据固定的块大小16进行拆分或合并,而包含图像的部分则完整保留,以保持图像与文本的对齐。如图2所示,每个片段随后通过三个关键模块进行处理。文本图谱提取模块从文本中识别实体及其关系,而视觉图谱提取模块从图像中检测显著对象及其交互关系。最后,多模态图谱生成模块将文本和视觉实体及关系融合成一个统一的多模态图谱。
文本图谱提取 :遵循先前工作20,我们通过提示大型语言模型(LLM)处理每个文本片段,识别关键实体(节点)和有意义的关系(边),从而形成文本子图 G t = ( N , E ) G_t = (N, E) Gt=(N,E)。如图2示例,每个实体 n ∈ N n \in N n∈N 包含一个唯一的名称和详细描述,提供抽象表示以便于后续检索。每个关系 e i ∈ E e_i \in E ei∈E 连接头实体和尾实体 ( n i , n j ) (n_i, n_j) (ni,nj),并包含简洁的关系摘要。
视觉图谱提取 :文本子图提炼了文本片段的骨架,包括信息丰富的实体和关系,但缺乏视觉元素,而视觉元素是VQA任务中的关键组成部分。一个简单的策略是直接将 G t G_t Gt 与对应的图像36结合。然而,考虑到图像通常包含多个对象和背景噪声,我们提出通过细粒度的区域信息增强文本子图。每个区域可能代表一个单独的实体或两个及以上实体之间的关系,如图2所示。为简化起见,本研究仅关注二元关系,将超关系37的研究留给未来工作。具体而言,我们采用场景图生成(SGG)技术25提取精确的视觉子图 G v = ( V , R ) G_v = (V, R) Gv=(V,R),其中 V V V 表示具有预测类别标签和边界框的视觉对象集合, R = { r i j } i ≠ j R = \{r_{ij}\}_{i \neq j} R={rij}i=j 表示对象之间的视觉关系。与目标检测47不同,SGG 提供了额外的关系信息,有助于高效的视觉-文本关系匹配。
多模态图谱生成:构建流程的核心挑战在于将文本和视觉图谱合并成语义一致且模态对齐的多模态图谱。基于图像-文本相似度46直接匹配文本和视觉实体/关系局限于浅层或全局对齐,缺乏捕捉细粒度和上下文对应关系的能力。鉴于多模态大型语言模型(MLLM)35在视觉-语言理解方面的出色能力,一个有前景的解决方案是使用 MLLM 作为视觉-文本匹配器,有效对齐语义一致的视觉和文本实体/关系。因此,设计了以下提示:
视觉-文本匹配提示 :<Prefix Instruction> <IMAGE> [Textual Entities & Relationships][Visual Entities & Relationships]
其中,<Prefix Instruction> 解释文本和视觉图谱的输入格式,并指导 MLLM 匹配其实体和关系。<IMAGE> 表示视觉图谱对应的图像,仅包含原始图像,不包含额外区域。为了让 MLLM 理解图谱结构,我们将 G t G_t Gt 和 G v G_v Gv 转换为自然语言格式。对于 G t G_t Gt,每个实体和关系使用其名称和相关描述表示为句子。视觉对象和关系在 G v G_v Gv 中编码为 <Object-ID>: <category>, <bbox> 和 <Relation-ID>: <subject>, <relation>, <object>。重要的是,视觉实体仅包含预测类别和归一化边界框,MLLM 可以从中在 <IMAGE> 中定位相应区域,而无需实际区域图像54。此设计通过允许同时处理 G v G_v Gv 中的所有对象和关系实现高效推理。为了确保 MLLM 遵循前缀指令并产生期望输出,我们通过提供几个高质量示例进一步增强其推理能力。详细提示见附录A。
整个视觉-文本匹配过程表示为:
M = { ( n , v ) i } i = 1 N c ∪ { ( e , r ) j } j = 1 N r = F m l l m ( I , g t , g v ) . \mathcal{M}=\{(n,v)i\}{i=1}^{N_{c}}\cup\{(e,r)j\}{j=1}^{N_{r}}=\mathcal{F}{mllm}(I,g{t},g_{v}). M={(n,v)i}i=1Nc∪{(e,r)j}j=1Nr=Fmllm(I,gt,gv).
这里, M \mathcal{M} M 表示一个包含 N c N_c Nc 个匹配实体和 N r N_r Nr 个匹配关系的集合。如图2所示, v v v(或 r r r)的图像区域作为属性附加到其对应的文本对应项 n n n(或 e e e)上。由于视觉关系 r r r 涉及两个对象区域,我们使用其边界框的并集合并它们。
通过上述步骤,我们为每个文档片段生成一个图像-文本对齐的多模态子图 G G G。这些子图随后通过合并相同的节点和边聚合成完整图谱。值得注意的是,仅来自同一文档的子图会被合并,确保每个文档产生一个独立的多模态知识图谱。在检索过程中,来自不同文档的相关知识图谱根据检索结果动态组合。由于构建过程与查询无关,整个流程可以离线执行,每个文档只需处理一次。
3.2 双阶段检索范式
为了充分发挥构建的多模态知识图谱的潜力,我们进一步引入了一种受人类认知过程启发的双阶段检索框架。当面对不熟悉的多模态查询时,人类通常会:(1) 从大量的外部多模态资源中筛选出相关的支持证据,然后 (2) 分析并将提取的信息组织成连贯的结构用于推理 59。我们的框架因此实现了粗粒度的向量相似性搜索,随后进行细粒度的图谱检索。
基于嵌入的检索 :对于包含数百万段落的大型知识库,直接进行图谱检索是低效的,因为每个段落可能包含数百个节点和边,极大地扩展了搜索空间。因此,我们首先使用向量搜索进行粗粒度召回,得到矩阵 S S S:
S = { s i = ⟨ E q ( I q , q ) ⋅ E e ( I i , T i ) ⟩ , i = 1 , . . . , N } , {\bf S}=\{s_{i}=\langle{\mathcal E}{q}(I{q},q)\cdot{\mathcal E}{e}(I{i},T_{i})\rangle,i=1,...,N\}, S={si=⟨Eq(Iq,q)⋅Ee(Ii,Ti)⟩,i=1,...,N},
其中 ⟨ ⟩ \langle\rangle ⟨⟩ 表示余弦相似度; E q \mathcal{E}_q Eq 和 E e \mathcal{E}_e Ee 分别是为查询和证据设计的多模态编码器,如图 3 所示。基于矩阵 S S S,收集得分最高的 K a K_a Ka 个文档。
基于图谱的检索:以往的方法直接从候选文档中检索文本片段 53,这往往会引入上下文噪声并损害推理性能。相比之下,我们的方法通过基于图谱的检索来识别与查询相关的实体和关系。这些实体和关系作为提炼的知识表示,显著减少了噪声,并实现了更准确的检索。
具体来说,通过合并第一阶段检索到的候选文档对应的离线生成子图,构建查询特定的多模态图谱 G m G_m Gm。通过仅合并相关文档,这种在线策略有效减少了跨文档知识不一致性导致的模糊实体和关系 15。接下来,通过计算多模态查询与 G m G_m Gm 中每个实体/关系的嵌入相似度,识别与查询相关的实体和关系。给定实体和关系的嵌入向量可形式化为 f e = E e ( n , v ) f_e = \mathcal{E}_e(n, v) fe=Ee(n,v) 和 f r = E e ( e , r ) f_r = \mathcal{E}_e(e, r) fr=Ee(e,r)。这里,将选择前 K g K_g Kg 个最佳匹配的候选者,例如图 2 中的实体 a 1 a_1 a1 和关系 ( b 2 , b 4 ) (b_2, b_4) (b2,b4)。结合 K g K_g Kg 个匹配的实体或关系,我们得到一个相关的子图 G o G_o Go。然而,仅基于相似性的检索可能会产生不完整的信息,可能忽略回答问题所需的关键证据。为此,我们利用图谱的固有结构属性,通过纳入其 1-hop 邻居的信息扩展 G o G_o Go,即:
KaTeX parse error: Undefined control sequence: \o at position 77: ...v\!{\mathrm{e}}\̲o̲\mathrm{rSal}}\...
其中图谱遍历通过广度优先搜索实现。值得注意的是,我们仅选择性地纳入与查询相关的邻居,如图 2 中的绿色节点所示。
检索到的上下文包括图谱元素(实体和关系)及其相关的文本片段。前者提供结构化的知识概要,而后者提供上下文细节。最后,将拼接后的图像、问题和上下文输入到多模态大语言模型(MLLMs)中以生成答案。
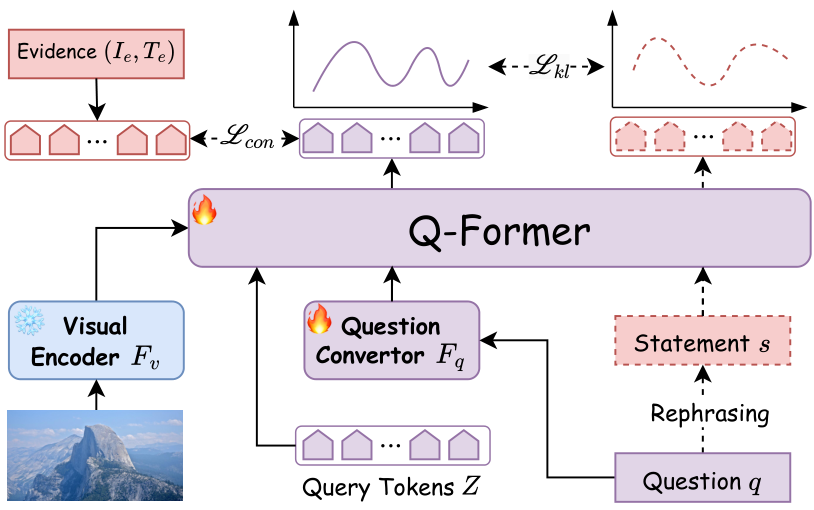
问题感知的多模态检索器:标准的多模态检索器针对语义相似性进行优化,而非问题相关性,常常无法检索到生成答案所需的确切证据,即使返回的内容在语义上相关。为解决这一问题,本研究提出了一种问题感知的多模态检索器(QM-Retriever),专门针对视觉问答(VQA)任务的证据检索。
如图 3 所示,该检索器改编自 Q-Former 28,通过加入额外的视觉编码器 F F F 和问题转换器 F q F_q Fq。我们采用 BLIP-2 28 预训练的视觉编码器作为 F F F 来提取图像特征。问题转换器将疑问句式的问题重新表述为陈述形式,以解决与证据文本的语法不匹配问题,否则可能影响检索精度。重要的是,重新表述过程发生在潜在空间而非语言空间。给定图像-问题对 ( I q , q ) (I_q, q) (Iq,q),QM-Retriever 将其编码为固定大小的嵌入 Z q Z_q Zq:
Z q ⟶ _ ( 8 − 8 ) − 2 π Γ O T I R e T ⟨ ⟨ α β ⟩ , T q ( q ) ⟩ ) , Z_{q}\stackrel{\}{\longrightarrow}(8-8)-\frac{2\pi}{\Gamma{\mathrm{OTIReT}}}\langle\langle\frac{\alpha}{\beta}\rangle,\mathcal{T}{q}(q)\rangle)\mathrm{,} Zq⟶(8−8)−ΓOTIReT2π⟨⟨βα⟩,Tq(q)⟩),
其中 Z Z Z 是 Q-Former 引入的一组可学习标记。生成的嵌入 Z q Z_q Zq 可用于基于向量的检索。需要注意的是,QM-Retriever 在作为证据编码器时省略了问题转换器。
为了优化 QM-Retriever,基于 E-VQA 40 的训练集构建了一个查询-证据数据集,其中每个多模态查询 ( I q , q ) (I_q, q) (Iq,q) 与其对应的真实证据 ( I e , T e ) (I_e, T_e) (Ie,Te) 配对。这里, T e T_e Te 表示证据文本, I e I_e Ie 指证据部分的相关图像。对于没有视觉内容的段落,使用黑色图像作为占位符。
QM-Retriever 的优化涉及两个关键目标:(1) 问题-证据对齐。为了检索与查询相关的证据,我们采用对比学习 21, 5,通过鼓励正向查询-证据对在批次中具有相似的表示,而与负向对形成对比,来对齐多模态查询和证据的特征,即:
KaTeX parse error: Undefined control sequence: \d at position 41: ...{C o m}\ =\ -\,\̲d̲0\Theta\frac{\e...
这里, B B B 表示批次大小, τ \tau τ 是温度参数。(2) 问题重新表述。我们利用大语言模型(LLMs)将原始问题 q q q 转换为强调场景上下文的陈述语句 s s s。通过用 QM-Retriever 编码 ( I q , s ) (I_q, s) (Iq,s),我们获得陈述表示 Z s Z_s Zs 作为参考。然后,测量 Kullback-Leibler 散度以最小化 Z q Z_q Zq 和 Z s Z_s Zs 分布之间的差异。最后,总目标被表述为由超参数控制的线性组合:
L = L c o n + α D K L ( p ( Z q ∣ I q , q ) ∣ ) p ( ( Z s ∣ I q , s ) ) ) . \mathcal{L}=\mathcal{L}{c o n}+\alpha\;D{K L}(p(Z_{q}|I_{q},q)\mid)\,p((Z_{s}|I_{q},s))). L=Lcon+αDKL(p(Zq∣Iq,q)∣)p((Zs∣Iq,s))).
值得注意的是,Q-Former 使用 BLIP-2 的权重初始化,并与 F q F_q Fq 共同微调,而 F F F 保持冻结状态。
4 实验
4.1 实验设置
数据集和知识库。我们在 E-VQA 40 和 InfoSeek 6 数据集上评估了我们的方法,这两个数据集包含与维基百科文档相关的问题-答案对。E-VQA 提供了一个包含 200 万个维基百科页面的知识库,其中每个问题-答案对都标注了支持性的维基百科文章、相关证据段落以及关联的图像。对于 InfoSeek,由于没有公开的知识库,我们使用了由 EchoSight 53 过滤的 E-VQA 中的 10 万个文档子集作为我们的知识来源。
实现细节。我们使用 Llama-3.2-11B-Vision 模型作为多模态大型语言模型(MLLM),用于多模态知识图谱构建,包括文本实体-关系识别和视觉-文本匹配。采用轻量级的一阶段场景图生成(SGG)模型 EGTR 25 来为知识库中的图像生成场景图。在第一阶段检索中,我们使用 FAISS 26 进行高效的近似最近邻搜索,并选择前 10 个( K a K_a Ka)最佳匹配的文档。对于图谱检索,我们根据经验将 K g K_g Kg 和 I I I 分别设置为 10 和 1。除非另有说明,我们采用 LLaVA-More 10 作为多模态答案生成器,遵循 RefectiVA 11 的设置。更多细节请参见附录 B。
4.2 性能比较
检索结果
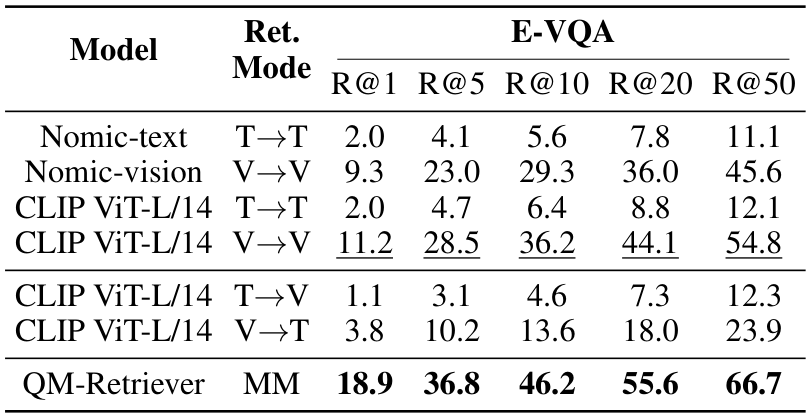
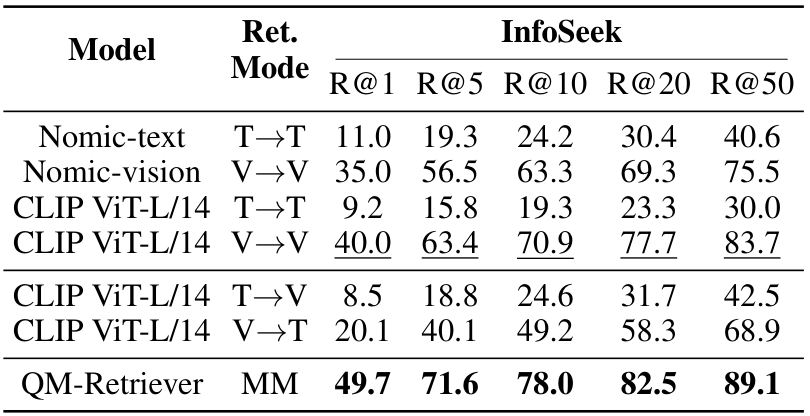
为了评估使用QM-Retriever进行多模态检索的有效性,我们与单模态和跨模态检索器进行了比较分析,以选择与视觉问答(VQA)查询最相关的文档。具体来说,我们使用Nomic-Embed-v1.5 43和CLIP ViT-L/14@336 46作为检索基线,并考察了四种可行的检索组合:文本到文本(T→T)、视觉到视觉(V→V)、文本到视觉(T→V)和视觉到文本(V→T)。
表1和表2分别报告了在E-VQA和InfoSeek上的召回率(Recall)分数。QM-Retriever始终优于所有基线方法,平均提升幅度为9.9%(E-VQA)和7.0%(InfoSeek),超越了第二好的方法。强大的召回性能确保了mKG-RAG在细粒度检索阶段构建的高度相关的知识图谱上运行,这一点也得到了我们消融研究的进一步支持。此外,结果显示V→V检索始终优于其他单模态和跨模态配置,凸显了视觉内容在VQA任务中的关键作用。

Qwen2-VL:400GPT-40: XI can't answer without specific details.mKG-RAG:250-metre


Q: Who designed this museum?
Q: What is the surface area of this lake? Q: How long is the track at this velodrome?
Qwen2-VL:PARKGPT-40:New York City Department of Parks and Recreation mKG-RAG:Abingdon Square Conservancy Abingdon Square



GPT-40:a ring of dark spots

mKG-RAG:brownish spots Q: What is the architectural style of this mosque?
Q: What forms a ring on the larger end of the egg of this bird?
Q: Who is in charge of maintaining this park?
E-VQA和InfoSeek的结果
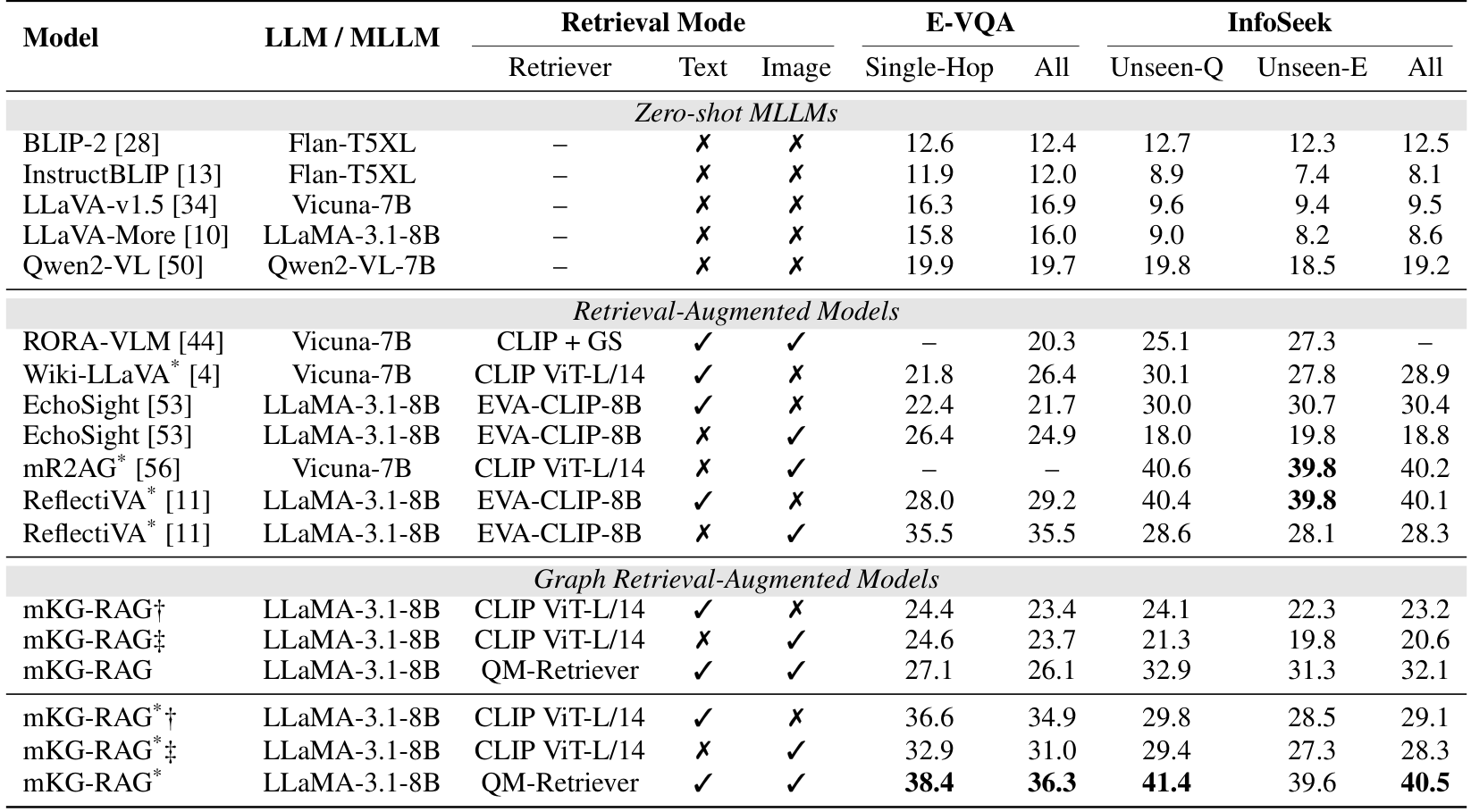
在本节中,我们将mKG-RAG与零样本多模态大语言模型(MLLMs)和基于RAG的方法在上述基准数据集上进行比较。表3的结果表明,零样本MLLMs在基于知识的VQA任务中表现挣扎,特别是在InfoSeek数据集上。这些局限性凸显了整合外部知识的迫切需要。通过将LLaVA-More与mKG-RAG结合,我们取得了显著的改进,在E-VQA上提升超过20.3%,在InfoSeek上提升31.9%,这突显了检索增强的价值。
此外,我们的方法在两个数据集上均达到了最先进的性能。在微调设置下,mKG-RAG超越了mR2AG和ReflectiVA*。即使不进行微调,mKG-RAG也分别比EchoSight高出1.2%和1.7%。这些结果凸显了将RAG与多模态知识图谱相结合的优势,并展示了我们QM-Retriever的有效性。表3还包括两个mKG-RAG变体,它们分别用纯文本和纯视觉的CLIP替代QM-Retriever进行实体/关系检索,但仍使用QM-Retriever检索的文档构建多模态知识图谱。在纯文本变体中,问题和图像标题都被用作查询以提供更多上下文,这解释了其性能优于纯视觉版本的原因。然而,这两个变体都不如我们使用QM-Retriever的完整方法有效。
跨架构的一致性
在表4中,我们提供了跨不同参数规模的MLLMs的VQA分数的详细比较,包括Intern VL3 58、LLaMA-3.2-Vision 2、LLaVA-v1.5 34、DeepSeek-VL2 52和Qwen2.5-VL 3。当这些模型与我们的mKG-RAG框架结合时,在单跳查询上的平均性能提升为9.4%,在整体场景中的提升为8.7%,这表明该方法在不同架构和规模上具有很强的泛化能力。
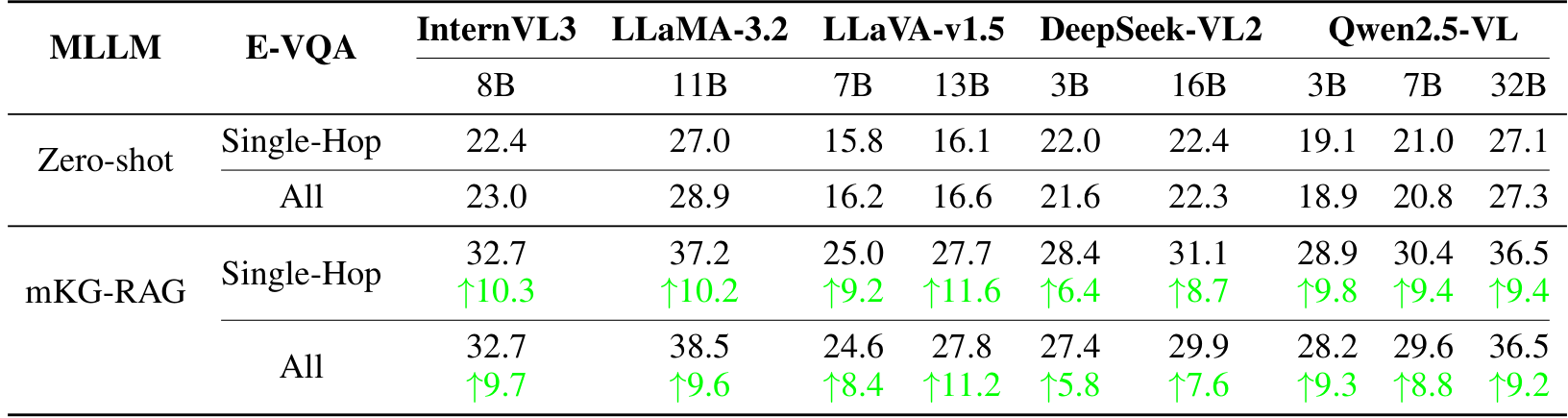
定性结果
图4展示了mKG-RAG与零样本Qwen2-VL和GPT-4o的定性比较。虽然后两者倾向于产生看似合理但不正确或回避性的回答,但mKG-RAG始终能够处理知识密集型查询,尤其是那些涉及精确数值和时间推理的查询。

4.3 消融研究
粗粒度检索的影响
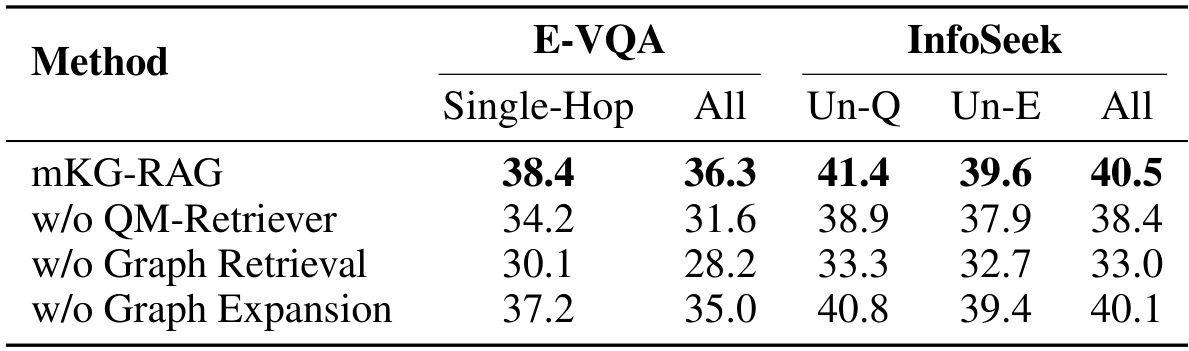
为了量化粗粒度文档检索的影响,我们进行了一项消融实验,用仅基于视觉的 CLIP (ViT-L/14@336) 替换 QM-Retriever。在 E-VQA 数据集上,mKG-RAG 的 VQA 准确率下降了 4.7%,在 InfoSeek 数据集上下降了 2.1%。这一结果明确表明第一阶段检索的关键作用,以及 QM-Retriever 相较于单模态替代方案的优越性。
基于图的检索的有效性
在我们的方法中,从文档中提取的实体和关系形成了一个精炼的知识图谱,减少了噪声,并实现了比直接文本块匹配更有效的检索。为了验证这一观点,我们用一种简单的基于块的替代方案替换了基于图的检索。具体来说,我们将检索到的文档分割成固定大小的块,并选择与给定问题和图像描述相关的块。如表 5 所示,基于块的检索导致准确率大幅下降,在 E-VQA 上下降了 8.1%,在 InfoSeek 上下降了 7.5%。
图扩展的贡献
mKG-RAG 通过一跳邻居扩展增强了构建的子图,有效捕捉了可能缺失但相关的知识连接。表 5 显示,省略图扩展会导致性能持续下降,在 E-VQA 上下降了 1.3%,在 InfoSeek 上下降了 0.4%,证明了其对 mKG-RAG 的关键贡献。
检索数量变化的影响
在表 6 中,我们进一步分析了检索的实体和关系数量 K g K_g Kg 对我们方法的影响。随着 K g K_g Kg 从 1 增加到 20,mKG-RAG 及其变体的整体准确率逐渐提高,因为更高的召回率增加了捕获相关知识的可能性。然而,当 K g > 10 K_g > 10 Kg>10 时,由于上下文较长且噪声增多,收益逐渐减小。因此,设置 K g = 10 K_g = 10 Kg=10 是一个实用的折衷方案。值得注意的是,即使在 K g = 1 K_g = 1 Kg=1 时,mKG-RAG 仍然表现出竞争力,这得益于其图扩展策略,使模型能够收集额外的相关信息。
B. 实施细节
QM-Retriever
在提出的 QM-Retriever 中,我们引入了一个问题转换器 F q F_q Fq,用于将疑问句转化为陈述句形式,从而减少与证据文本的语法不匹配。问题转换器包含两个线性投影层,中间由 ReLU 激活函数分隔。这种转换在潜在空间中进行, F q F_q Fq 将原始问题的词嵌入重新表述为陈述性表示,然后将其传递给 Q-Former 的 BERT 编码器。
在训练过程中,问题转换器 F q F_q Fq 和 Q-Former 联合优化,而视觉编码器 F v F_v Fv 保持冻结状态。QM-Retriever 在我们标注的包含 221K 个查询-证据对的数据集上训练 25 个 epoch,使用 AdamW 优化器和 CosineLR 调度器,初始学习率为 1 0 − 5 10^{-5} 10−5。训练配置还包括批大小为 64,KL 散度系数为 2,输入图像大小为 224 × 224 224 \times 224 224×224,问题和证据的最大 token 长度均为 512。
微调
根据 ReflectiVA 11 的实验设置,我们采用 LLaVA-More 10 作为多模态答案生成器。由于 ReflectiVA 专门针对相关段落过滤和答案生成进行了优化,我们相应地对我们的方法 (mKG-RAG*) 进行微调,确保总批大小为 32,学习率为 1.5 × 1 0 − 4 1.5 \times 10^{-4} 1.5×10−4。为了保持模型在已建立的 MLLM 基准上的性能,我们在微调数据集中增加了来自 LLaVA-Instruct-150K 数据集 35 的样本。遵循 Wiki-LLaVA 4 的策略,我们提高了这些样本的采样概率,确保它们在每个 mini-batch 中约占一半。
Vision-Text Matching Prompt
Based on the provided image, visual scene graph, and textual entities and relationships, match visual objects/relations in the image with the provided textual entities/relationships.
Input Format:
Each textual entity are formatted as ["entity"]<entity-name><entity-type><entity-description>, which contains the following information:
- entity-name: Name of the entity;
- entity-type: Name of the entity type;
- entity-description: Comprehensive description of the entity's attributes and activities.
Each textual relationship are formatted as ["relation"]<source-entity>|<target-entity>|<relation-description>/<relation-strength>, which contains the following information:
- source-entity: name of the source entity, as defined in the textual entities;
- target-entity: name of the target entity, as defined in the textual entities;
- relation-description: explanation as to why the source entity and the target entity are related to each other;
- relation-strength: a numeric score indicating the strength of the relationship between.
The scene graph provides the object and relationship information in the image, which is formatted as:
<object-0>: <object-category>,<object-bbox><object-1>: <object-category>,<object-bbox><relation-0>: <object-0> <relation-name> <object-1><relation-2>: <object-1> <relation-name> <object-3>
The <object-bbox> is the bounding box of each object region, represented as (x1, y1, x2, y2) with floating numbers ranging from 0 to 1. These values correspond to the top left x, top left y, bottom right x, and bottom right y.
论文摘要(中文)
以下是对所提供论文片段的中文总结,保留了原始 markdown 格式中的图像部分,并按照原文结构组织内容。
匹配步骤:
步骤 1: 确定与整体图像最相关的文本实体,并提取以下信息:
- 实体名称:最能代表整体图像的实体名称;
- 强度:匹配强度的数值分数,范围为 0 到 10。
图像匹配格式为:("matching"|<image>/<entity-name><strength>)。
步骤 2: 对场景图中的每个对象,如果该对象在视觉上描绘了输入数据中识别的文本实体,则提取以下信息:
- 对象 ID:场景图中对象的 ID;
- 实体名称:对象所代表的实体名称;
- 强度:匹配强度的数值分数,范围为 0 到 10。
每个对象匹配格式为:("matching"|<object-id>/<entity-name><strength>)。
步骤 3: 对场景图中的每个关系,如果该关系在视觉上代表了输入数据中识别的文本关系,则提取以下信息:
- 关系 ID:场景图中关系的 ID;
- 源实体:关系所代表的源实体;
- 目标实体:关系所代表的目标实体;
- 强度:匹配强度的数值分数,范围为 0 到 10。
每个关系匹配格式为:("matching"|<relation-id>|<source-entity><target-entity>|<strength>)。
步骤 4: 对于没有对应文本实体或关系的对象或关系,请忽略它们。
图 5:用于匹配视觉和文本实体/关系的提示
视觉-文本匹配示例
文本实体:
("entity"|"MOUNT FUJI"|"location"|"Mount Fuji is an active stratovolcano located on Japan's Honshu Island, with a peak elevation of 3,776.24 meters.")("entity"|"HONSHU ISLAND"|"location"|"Honshu Island is the largest island of Japan, where Mount Fuji is situated.")("entity"|"CHERRY BLOSSOMS"|"concept"|"Cherry blossoms are a symbol of Japan, known for their beauty and cultural significance, often associated with the arrival of spring.")("entity"|"SHINKANSEN"|"technology"|"The Shinkansen, also known as the bullet train, is a network of high-speed railway lines in Japan.")
文本关系:
("relationship"|"MOUNT FUJI"|"HONSHU ISLAND"|"Mount Fuji is located on Honshu Island, making the island its geographical setting."|9)("relationship"|"MOUNT FUJI"|"CHERRY BLOSSOMS"|"Both Mount Fuji and cherry blossoms are iconic symbols of Japan, often celebrated together in cultural contexts."|8)("relationship"|"MOUNT FUJI"|"SHINKANSEN"|"Mount Fuji and the Shinkansen are both recognized as national symbols of Japan."|7)
图像描述:
图像描述为富士山和在其前方经过的新干线电动车。
场景图:
<object-0>: train, (0.06, 0.64, 1.0, 0.77)<object-1>: fence, (0.0, 0.8, 0.98, 0.88)<object-2>: snow, (0.25, 0.29, 0.67, 0.49)<object-3>: mountain, (0.0, 0.3, 1.0, 0.64)<relation-0>: <object-0> over <object-1><relation-1>: <object-2> on <object-3><relation-2>: <object-3> behind <object-0>
输出:
("mapping"|<image>|"MOUNT FUJI"|8)("mapping"|<object-3>|"MOUNT FUJI"|9)("mapping"|<object-0>|"SHINKANSEN"|7)("mapping"|<relation-2>|"MOUNT FUJI"|"SHINKANSEN"|7)
以上内容总结了论文中关于视觉与文本匹配的具体步骤、示例数据以及输出结果,旨在帮助理解如何将图像中的对象和关系与文本实体进行对应匹配。
Original Abstract: Recently, Retrieval-Augmented Generation (RAG) has been proposed to expand
internal knowledge of Multimodal Large Language Models (MLLMs) by incorporating
external knowledge databases into the generation process, which is widely used
for knowledge-based Visual Question Answering (VQA) tasks. Despite impressive
advancements, vanilla RAG-based VQA methods that rely on unstructured documents
and overlook the structural relationships among knowledge elements frequently
introduce irrelevant or misleading content, reducing answer accuracy and
reliability. To overcome these challenges, a promising solution is to integrate
multimodal knowledge graphs (KGs) into RAG-based VQA frameworks to enhance the
generation by introducing structured multimodal knowledge. Therefore, in this
paper, we propose a novel multimodal knowledge-augmented generation framework
(mKG-RAG) based on multimodal KGs for knowledge-intensive VQA tasks.
Specifically, our approach leverages MLLM-powered keyword extraction and
vision-text matching to distill semantically consistent and modality-aligned
entities/relationships from multimodal documents, constructing high-quality
multimodal KGs as structured knowledge representations. In addition, a
dual-stage retrieval strategy equipped with a question-aware multimodal
retriever is introduced to improve retrieval efficiency while refining
precision. Comprehensive experiments demonstrate that our approach
significantly outperforms existing methods, setting a new state-of-the-art for
knowledge-based VQA.
PDF Link: 2508.05318v1
部分平台可能图片显示异常,请以我的博客内容为准
