LLM协作新突破:用多智能体强化学习实现高效协同------解析MAGRPO算法
论文:LLM Collaboration With Multi-Agent Reinforcement Learning
arXiv:2508.04652 (cross-list from cs.AI)
LLM Collaboration With Multi-Agent Reinforcement Learning
Shuo Liu, Zeyu Liang, Xueguang Lyu, Christopher Amato
Subjects: Artificial Intelligence (cs.AI); Software Engineering (cs.SE)
一段话总结:
本文将LLM协作 建模为合作式多智能体强化学习(MARL) 问题,并形式化为Dec-POMDP ,以解决现有LLM微调框架依赖个体奖励导致协作困难的问题。为此,提出MAGRPO算法,通过集中式群体相对优势进行联合优化,同时保留去中心化执行以保证效率。实验表明,在写作(TLDR summarization、arXiv expansion)和编码(HumanEval、CoopHumanEval)协作任务中,MAGRPO能使LLM agents通过有效协作生成高质量响应,且效率优于单agent和其他多agent基线方法。该研究为MARL方法应用于LLM协作开辟了道路,并指出了相关挑战。
研究背景
想象一个场景:你让两个AI助手合作写一篇科普文章,一个负责介绍背景,一个负责讲解原理。结果呢?可能一个写得太简略,一个又过于冗长,风格完全不搭,甚至出现内容重复------这就是当前大型语言模型(LLM)协作时的常见问题。
近年来,LLM在各个领域大放异彩,但当需要多个LLM协同完成复杂任务(如联合写作、协作编码)时,却面临诸多挑战:
- 现有方法要么让LLM在推理时通过提示词互动(比如"你补充一下我的观点"),但模型固定不变,很容易答非所问或传播错误信息;
- 要么针对每个LLM单独微调,设计复杂的个体奖励(比如"这个LLM写得好就加分"),但奖励设计难度大,且多个LLM各自为战,缺乏全局协作意识。
而在机器人、游戏等领域,多智能体系统(MAS)早已通过强化学习实现了高效协作(比如多个机器人协同搬运物体)。受此启发,研究者们开始思考:能否将LLM协作也打造成一个"协作型团队",通过多智能体强化学习(MARL)让它们学会协同工作?这正是本文要解决的核心问题。
主要作者及单位信息
- 作者:Shuo Liu, Zeyu Liang, Xueguang Lyu, Christopher Amato*
- 单位:Khoury College of Computer Sciences, Northeastern University(美国东北大学Khoury计算机学院)
创新点
本文的独特之处在于跳出了"个体优化"的思维,为LLM协作提供了全新框架:
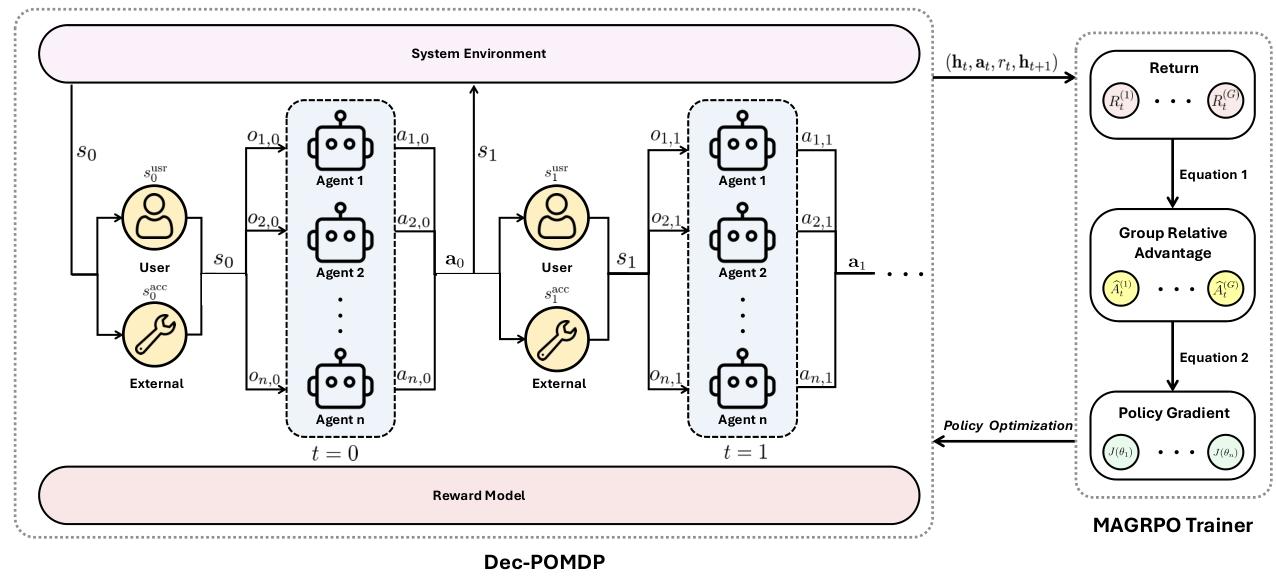
- 问题建模革新 :首次将LLM协作明确建模为合作式多智能体强化学习问题 ,并通过Dec-POMDP(去中心化部分可观测马尔可夫决策过程) 形式化,让协作目标更清晰。
- 算法创新 :提出MAGRPO(Multi-Agent Group Relative Policy Optimization)算法,结合"集中式训练、去中心化执行"模式------训练时用全局信息优化协作策略,执行时每个LLM独立决策,兼顾效率与协作性。
- 奖励设计简化 :摒弃复杂的个体奖励,采用联合奖励 (比如"两篇摘要是否结构合理、风格一致"),让LLM自然学会分工协作,无需手动设计角色规则。
研究方法和思路
核心思路:把LLM协作变成"团队游戏"
-
问题形式化:用Dec-POMDP定义协作规则
- 每个LLM是一个"智能体",接收自然语言提示(观测),生成文本或代码(动作)。
- 环境根据所有LLM的联合输出更新状态(比如任务进度、用户反馈)。
- 系统根据联合输出的质量给出联合奖励(比如写作任务中奖励"结构合理+风格一致",编码任务中奖励"代码可运行+功能互补")。
- 目标是让所有LLM共同优化策略,最大化累计奖励(即"团队总分")。
-
MAGRPO算法:让LLM学会"团队配合"
- 步骤1:多轮交互:每个回合中,LLM们根据各自的历史(之前的提示和输出)同步生成响应。
- 步骤2:群体采样:为了稳定训练,每个LLM生成多个候选响应(比如每个生成3个版本),形成"响应群体"。
- 步骤3:计算奖励:系统根据联合响应的质量(如结构、一致性、正确性)给出联合奖励。
- 步骤4:优化策略:通过"群体相对优势"(对比不同响应的奖励差异)更新每个LLM的策略,让它们逐渐学会"哪些输出能让团队得分更高"。
- 特点:训练时用全局信息(所有LLM的输出和奖励)优化,执行时每个LLM仅根据自己的观测独立决策,既保证协作又不牺牲效率。
实验方法:在写作和编码任务中"实战测试"
-
写作协作任务
- TLDR摘要生成:2个LLM分工,一个写精简摘要,一个写详细摘要,要求结构合理、风格一致。
- arXiv论文扩展:2个LLM从论文摘要扩展引言,一个写背景,一个写方法,要求内容连贯。
- 对比基线:单LLM、并行生成(无协作)、顺序生成(单向参考)、一轮讨论(双向参考)。
-
编码协作任务
- HumanEval/CoopHumanEval:2个LLM分工写Python函数,一个写辅助函数,一个写主函数,要求代码可运行、功能互补。
- 对比基线:单LLM、朴素拼接(无协作)、顺序生成(主函数参考辅助函数)、一轮讨论(互相参考)。
-
评估指标
- 写作:结构(长度比)、风格一致性(词汇相似度)、逻辑连贯性(过渡词使用)。
- 编码:结构完整性(函数定义正确)、语法正确性、测试通过率、协作质量(主函数是否有效调用辅助函数)。
主要贡献
- 理论层面:为LLM协作提供了坚实的数学框架(Dec-POMDP),证明了用MARL解决协作问题的可行性。
- 方法层面:MAGRPO算法无需复杂的个体奖励设计,仅通过联合奖励就能让LLM自主学会分工协作,降低了工程落地难度。
- 实践层面 :实验表明,MAGRPO在写作和编码任务中全面超越现有方法:
- 写作任务:速度是单LLM的3倍,结构合理性和风格一致性得分超95%(基线最高71.5%)。
- 编码任务:多轮MAGRPO的测试通过率达74.6%,协作质量达86.2%(单LLM分别为63.4%和无协作指标)。
- 领域价值:打开了MARL与LLM结合的新方向,为未来更复杂的多LLM协作(如大型软件开发、多步骤决策)奠定了基础。
思维导图:

详细总结:
1. 研究背景与动机
- LLM与MAS的潜力:LLM在多领域表现优异,但协作能力未被充分优化;MAS在协作任务(如游戏、机器人)中已展现潜力,可用于提升LLM协作。
- 现有方法的局限 :
- 提示级交互(如辩论、角色分配):依赖固定模型,易产生冲突信息,提示设计困难。
- 个体奖励微调:需为每个agent设计复杂奖励,且缺乏收敛保证。
2. 核心方法
- 问题形式化:将LLM协作定义为Dec-POMDP,包含状态(全局状态含可访问部分和用户状态)、观测(自然语言提示)、动作(自然语言响应)、联合奖励(基于可访问状态和联合动作)等要素。
- MAGRPO算法 :
- 核心思路:借鉴GRPO和MAPPO,通过群体蒙特卡洛样本估计期望回报,计算群体相对优势以稳定训练。
- 流程:每个episode中,agents同步生成响应,基于联合奖励更新历史,最终通过随机梯度下降优化策略。
3. 实验设计与结果
| 任务类型 | 数据集/任务 | 评估指标 | 关键结果(MAGRPO vs 基线) |
|---|---|---|---|
| 写作协作 | TLDR summarization | 结构(长度比)、风格一致性(Jaccard相似度)、逻辑连贯性(过渡词) | 速度是单模型3倍,结构和连贯性得分更高(98.7% vs 单模型6.6%) |
| 写作协作 | arXiv expansion | 同上 | 总回报显著高于并行生成、顺序生成等基线(93.1% vs 并行59.6%) |
| 编码协作 | HumanEval | 结构完整性、语法正确性、测试通过率、协作质量 | 多轮MAGRPO测试通过率74.6%,协作质量86.2%,优于单模型(63.4%)和朴素拼接(40.1%) |
| 编码协作 | CoopHumanEval | 同上 | 单轮/多轮MAGRPO总回报(83.7%/88.1%)高于所有基线,且方差更低 |
4. 贡献与局限
- 贡献 :
- 将LLM协作建模为合作式MARL问题;
- 提出MAGRPO算法优化协作;
- 验证其在写作和编码任务中的有效性;
- 分析现有方法局限和开放挑战。
- 局限与未来方向 :
- 局限:使用同质agent、数据集和模型规模有限、奖励模型简单;
- 未来:探索异质agent协作、扩大项目规模、设计更精细的奖励模型。
关键问题:
-
MAGRPO算法与现有多agent LLM协作方法的核心区别是什么?
现有方法多依赖提示级交互(无微调)或个体/角色条件奖励微调,存在协作低效、奖励设计复杂、缺乏收敛保证等问题;而MAGRPO将LLM协作建模为合作式MARL问题,通过集中式群体相对优势进行联合优化,同时保留去中心化执行,无需复杂个体奖励设计,且有更好的协作效果和收敛性。
-
在写作协作实验中,评估LLM生成内容质量的具体指标有哪些?
包括三类指标:(1)结构:两段摘要的长度比和独特词比;(2)风格一致性:基于独特词(或n-grams)的归一化Jaccard相似度;(3)逻辑连贯性:过渡词使用的类别数量(奖励随类别数对数增长)。总奖励为这些指标的加权和。
-
该研究指出的LLM协作领域开放挑战有哪些?
主要包括:(1)LLM基于自然语言的表示形式对MARL建模的挑战(如动作/观测空间大);(2)训练范式选择(CTDE vs DTE)的权衡;(3)奖励模型的设计需更精细以对齐人类偏好;(4)需探索异质agent协作及更大规模项目中的协作模式。
总结
本文通过将LLM协作建模为合作式多智能体强化学习问题,提出了MAGRPO算法,成功解决了现有方法中"协作低效"和"奖励设计复杂"的痛点。实验证明,经过MAGRPO训练的LLM团队,在写作和编码任务中能生成更高质量的结果,且效率显著提升。
解决的主要问题
- 现有LLM协作依赖提示词或个体奖励,协作性差、设计复杂。
- LLM在多轮交互中难以保持风格一致、功能互补。
主要成果
- 提出MAGRPO算法,实现LLM的高效协同训练。
- 在写作和编码任务中验证了方法的优越性,为MARL在LLM领域的应用提供了范例。