一.为什么需要RAG(AI幻觉)
大模型LLM在某些情况下给出的回答很可能错误的,涉及虚构甚至是故意欺骗的信息。
二.什么是RAG
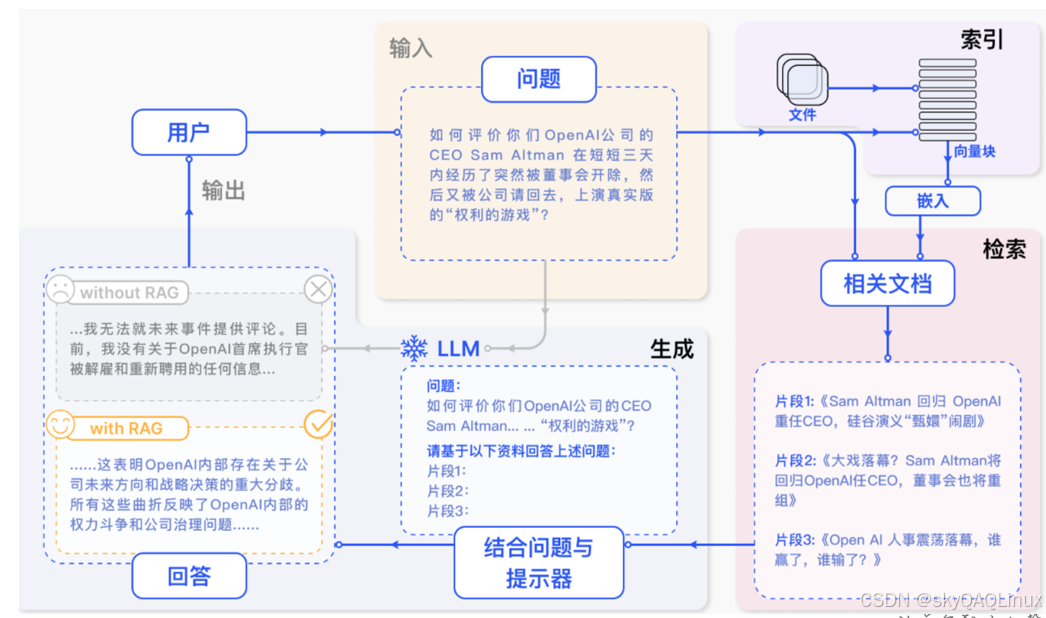
RAG是一种结合"信息检索"和"文本生成"的技术,旨在提升生成式AI模型的准确性和可靠性。它通过以下两个核心步骤工作:
1. 信息检索(Retrieval)
当收到用户提问时,RAG首先从外部知识库(如数据库、文档或网页)中检索与问题相关的信息片段,而不是仅依赖模型训练时学到的知识。
2..文本生成(Generation)
将检索到的相关信息和用户问题一起输入生成模型,生成更精准、基于事实的答案。
三.RAG的分块策略
•按照字符数来切分
•按固定字符数 结合overlapping window
•按照句子来切分
•递归方法 RecursiveCharacterTextSplitter
四.RAG向量和向量检索
1.Embeddings****向量化
(1)向量检索
根据用户的输入,与向量数据库中存放的文本向量进行相似度计算匹配,并检索返回最为相似的内容
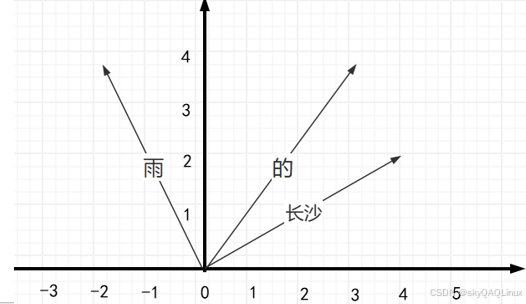
(2)数据内容转为向量(目前的向量模型可实现)
2.本地大模型
Ollama向量模型本地部署:官方网址:https://ollama.com/
3.向量间的相似度计算
常用的向量相似度计算方法包括:
-余弦相似度Cosine:基于两个向量夹角的余弦值来衡量相似度。
-欧式距离L2:通过计算向量之间的欧几里得距离来衡量相似度。
-点积:计算两个向量的点积,适合归一化后的向量
4.**"top-k"**语义检索
在根据向量相似度检索向量时,能够找出的相似向量一般是多个,如果我们不需要这么多或者要控制相似度的大小,top-k 语义检索就派上了用场。