一、ComfyUI 核心原理
ComfyUI 作为当前最具灵活性的生成式 AI 图像工具之一,其核心价值在于将复杂的扩散模型生成流程拆解为可定制的节点化工作流。要深入理解 ComfyUI,需从生成式 AI 的底层逻辑出发,逐步延伸至其特有的工作流引擎设计。
(一)生成式 AI 与扩散模型基础
生成式人工智能(Generative AI)是一类通过学习数据分布生成新内容的技术,而扩散模型(Diffusion Models)是其中近年来最受关注的分支。ComfyUI 的核心功能基于扩散模型中的 Stable Diffusion 实现,因此理解扩散模型的基本原理是掌握 ComfyUI 的前提。
1.生成式 AI 的技术演进
生成式 AI 的发展经历了从早期的自编码器(Autoencoders)、生成对抗网络(GANs)到扩散模型的迭代。
- 自编码器通过 "编码 - 解码" 结构学习数据压缩与重建,但生成能力有限,难以控制输出多样性;
- GANs 通过生成器与判别器的对抗训练生成逼真内容,但存在训练不稳定、模式崩溃(Mode Collapse)等问题;
- 扩散模型则通过模拟 "噪声添加 - 噪声去除" 的过程学习数据分布,具有生成质量高、可控性强的优势,逐渐成为图像生成的主流技术。
Stable Diffusion 作为扩散模型的典型代表,由 CompVis、Stability AI 等机构联合开发,其开源特性为 ComfyUI 等工具的诞生奠定了基础。
2.扩散模型的核心逻辑
扩散模型的工作流程可分为前向扩散 与反向扩散两个阶段:
- 前向扩散(Forward Diffusion) :通过固定的噪声调度器(Noise Scheduler),逐步向原始图像中添加高斯噪声,最终将图像转化为完全随机的噪声(耗时 T 步)。数学上,这一过程可表示为:
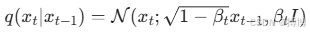
其中,βt为噪声系数,xt为第 t 步的带噪图像,I为单位矩阵。 - 反向扩散(Reverse Diffusion) :通过训练一个神经网络(通常为 U-Net)学习从带噪图像中移除噪声的过程,从纯噪声逐步还原出清晰图像。模型的目标是预测噪声ϵθ(xt,t),并通过如下公式迭代更新图像:
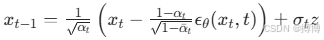
其中,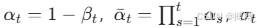 为噪声标准差,z为随机噪声(t>1时)。
为噪声标准差,z为随机噪声(t>1时)。
扩散模型的优势在于:通过逐步去噪过程实现高质量生成,且噪声调度器、去噪步数等参数可灵活调整,为后续的可控性优化(如 ComfyUI 的节点化调参)提供了基础。
(二)Stable Diffusion 的技术架构
Stable Diffusion 在传统扩散模型的基础上引入了 "潜在空间(Latent Space)" 优化,大幅降低了计算成本,同时保留了生成质量。其核心组件包括 U-Net、VAE、CLIP,三者的协同工作是 ComfyUI 工作流设计的底层逻辑。
1.潜在扩散模型(Latent Diffusion Models)的革新
传统扩散模型直接在像素空间(Pixel Space)进行扩散,计算量随图像尺寸呈平方级增长(如 512×512 图像含 262144 个像素)。Stable Diffusion 通过VAE(变分自编码器) 将图像压缩至低维潜在空间(如 512×512 图像压缩为 64×64 latent 向量),扩散过程仅在潜在空间进行,计算效率提升约 1000 倍。
潜在空间的特性:
- 维度远低于像素空间(如 64×64×4),降低计算负担;
- 保留图像的关键语义信息(如形状、颜色、纹理),确保生成质量;
- 支持跨模态映射(如文本到 latent 的转换),为 "文生图" 提供可能。
2.核心组件的功能与协作
Stable Diffusion 的三大核心组件分工明确,且均在 ComfyUI 中以节点形式存在(如 CheckpointLoader 加载包含 U-Net 的模型,CLIPTextEncode 处理文本输入):
-
U-Net :扩散过程的核心去噪网络 ,输入带噪 latent 向量与时间步t,输出预测的噪声。其结构包含编码器(下采样提取特征)、瓶颈层(融合多尺度特征)、解码器(上采样恢复分辨率),并通过跳跃连接(Skip Connections)保留细节信息。ComfyUI 中,U-Net 通常包含在 Checkpoint 模型文件(如 sd3.5_medium.safetensors)中,由 CheckpointLoader 节点加载。
-
VAE(变分自编码器) :负责像素空间与潜在空间的双向转换。
- 编码器(Encoder):将像素图像(如 PNG/JPG)压缩为 latent 向量;
- 解码器(Decoder):将生成的 latent 向量还原为像素图像。
在 ComfyUI 中,VAE 通常与 Checkpoint 绑定(如节点 26 的输出 26,2 指向 VAE),也可通过单独的 VAELoader 节点加载自定义 VAE。
-
CLIP(Contrastive Language-Image Pretraining) :实现文本与图像的跨模态匹配,为 "文生图" 提供条件引导。CLIP 包含文本编码器(Text Encoder)与图像编码器(Image Encoder),通过对比学习(Contrastive Learning)将文本与图像映射至同一语义空间。在 ComfyUI 中,TripleCLIPLoader 节点(如文档中的节点 84、91)可加载多个 CLIP 模型(如 clip_g、clip_l、t5xxl),CLIPTextEncode 节点则将文本转换为 U-Net 可理解的条件向量。
(三)ComfyUI 的工作流引擎原理
ComfyUI 的核心创新在于将 Stable Diffusion 的生成流程拆解为节点化模块,并通过工作流引擎实现模块间的协同。其设计思想类似于 "可视化编程",用户无需编写代码即可通过连接节点定制生成逻辑。
1.节点化抽象的设计思想
ComfyUI 将生成过程中的每个功能单元抽象为 "节点(Node)",每个节点包含:
- 输入(Inputs):需用户配置的参数(如 CheckpointLoader 的 ckpt_name、KSampler 的 steps);
- 输出(Outputs):节点处理后的结果(如 CheckpointLoader 输出模型、VAE、CLIP);
- 执行逻辑(Class Type):节点的核心功能实现(如 CLIPTextEncode 的文本编码逻辑)。
例如,文档中的节点 26(CheckpointLoaderSimple)的功能是加载 Stable Diffusion 模型,其输入为 ckpt_name(模型文件名),输出包括模型(U-Net)、VAE、CLIP 等组件,这些输出可作为其他节点(如 KSampler、VAEDecode)的输入。
2.工作流的执行逻辑:依赖解析与拓扑排序
当用户在 ComfyUI 中提交工作流时,引擎需完成以下步骤:
- 依赖解析:分析节点间的连接关系(如节点 29 的 model 输入依赖节点 26 的输出),构建有向无环图(DAG);
- 拓扑排序:按依赖关系对节点进行排序(如先执行 CheckpointLoader,再执行 CLIPTextEncode,最后执行 KSampler);
- 并行执行:对无依赖关系的节点(如两个独立的 CLIPTextEncode 节点)进行并行计算,提升效率;
- 数据传递:按排序结果依次执行节点,将输出数据传递至下游节点(如将 CLIPTextEncode 的编码结果传入 KSampler 的 positive/negative 输入)。
这种机制确保了工作流的灵活性:用户可自由增减节点(如添加图像修复节点)、调整连接关系(如更换 CLIP 模型),而引擎会自动适配执行逻辑。
二、ComfyUI 系统结构
ComfyUI 采用 "前端 - 后端分离 " 的架构,前端负责工作流的可视化编辑,后端处理模型加载、计算调度等核心逻辑。其系统结构可分为整体架构、前端系统、后端系统、数据流转机制四个层面。
(一)整体架构设计
ComfyUI 的架构以 "模块化" 与 "可扩展" 为核心,支持自定义节点、第三方插件集成,同时保持跨平台兼容性(Windows/macOS/Linux)。
1.前端 - 后端分离架构
- 前端:基于 Web 技术(HTML、CSS、JavaScript)构建,通过浏览器提供可视化界面,与后端通过 HTTP/WebSocket 通信;
- 后端:基于 Python 构建,核心依赖 PyTorch(深度学习计算)、FastAPI(API 服务)、WebSocket 库(实时通信),负责执行工作流逻辑。
这种架构的优势在于:
- 前端与后端解耦,便于独立开发(如前端可替换为自定义界面);
- 支持远程访问(如通过局域网或互联网控制后端服务);
- 后端可部署在高性能服务器(如 GPU 服务器),前端通过轻量设备(如平板)操作。
2.核心模块划分
ComfyUI 的后端系统可划分为五大核心模块,各模块通过接口协同工作:
| 模块名称 | 功能描述 | 关键组件示例 |
|---|---|---|
| 节点管理模块 | 负责节点的注册、加载、实例化,支持自定义节点开发 | NodeClass、NodeRegistry |
| 模型管理模块 | 加载与管理 Checkpoint、VAE、CLIP、LoRA 等模型,支持模型缓存与动态切换 | ModelLoader、ModelCache |
| 计算引擎模块 | 基于 PyTorch 实现张量计算,支持 CPU/GPU 加速,负责节点执行逻辑 | TorchBackend、ComputeScheduler |
| 工作流引擎模块 | 解析工作流 JSON、进行拓扑排序、调度节点执行 | WorkflowParser、DependencySolver |
| 通信模块 | 提供 RESTful API 与 WebSocket 接口,处理前端请求、返回生成进度 / 结果 | FastAPI、WebSocketServer |
(二)前端系统详解
前端是用户与 ComfyUI 交互的主要入口,其核心功能包括工作流画布、节点面板、属性编辑器、实时预览等。
1.界面组件构成
ComfyUI 的前端界面由五大组件构成,布局采用 "左侧工具栏 + 中间画布 + 右侧属性面板" 的经典设计:
- 节点面板(Node Palette):位于左侧,按功能分类展示节点(如 "加载器""编码器""采样器"),支持搜索(如输入 "KSampler" 快速定位采样器节点);
- 工作流画布(Workflow Canvas):位于中间,是工作流编辑的核心区域,支持节点拖拽、连线、缩放、复制粘贴;
- 属性面板(Properties Panel):位于右侧,选中节点后显示其输入参数(如 KSampler 的 steps、cfg),支持实时修改;
- 状态栏(Status Bar):位于底部,显示生成进度、GPU 占用、错误信息等;
- 菜单栏(Menu Bar):位于顶部,提供工作流保存 / 加载、设置、帮助等功能。
2.工作流可视化与交互逻辑
前端通过以下机制实现工作流的可视化与交互:
- 节点渲染:每个节点以矩形框表示,包含名称、输入端口(左侧)、输出端口(右侧),端口颜色对应数据类型(如 latent 向量为紫色,图像为绿色);
- 连线逻辑:用户拖拽节点输出端口至另一节点输入端口时,前端验证数据类型是否匹配(如 latent 输出只能连接至 latent 输入),不匹配则禁止连线;
- 实时保存:工作流修改后自动保存至浏览器本地存储(LocalStorage),避免意外丢失;
- 历史记录:支持撤销(Ctrl+Z)、重做(Ctrl+Y)操作,记录节点添加、删除、参数修改等历史;
- 缩放与平移:通过鼠标滚轮缩放画布,拖拽空白区域平移,适配复杂工作流的编辑。
(三)后端系统详解
后端是 ComfyUI 的 "大脑",负责处理模型加载、计算执行、API 请求等核心任务,其性能直接影响生成速度与稳定性。
1.节点执行引擎
节点执行引擎是后端的核心,其工作流程包括:
- 节点实例化:根据工作流 JSON 中的 class_type(如 KSampler)创建节点实例,初始化输入参数;
- 依赖注入:将上游节点的输出数据注入当前节点的输入参数(如将 EmptyLatentImage 的输出传入 KSampler 的 latent_image);
- 执行逻辑调用:调用节点的 run () 方法执行核心功能(如 KSampler 的 run () 方法实现扩散采样);
- 输出缓存:将节点输出数据缓存至内存,避免重复计算(如同一 CLIP 编码结果被多次使用时直接复用)。
例如,文档中节点 29(KSampler)的执行流程为:
class KSampler:
def run(self, model, positive, negative, latent_image, steps, cfg, ...):
# 1. 初始化采样器(如euler)与调度器(如simple)
sampler = EulerSampler(model, scheduler="simple")
# 2. 执行扩散采样(steps步去噪)
latent = sampler.sample(
latent_image=latent_image,
positive_cond=positive,
negative_cond=negative,
steps=steps,
cfg=cfg
)
# 3. 返回生成的latent向量
return {"samples": latent}2.模型管理系统
模型管理系统负责加载、缓存、释放各类模型,支持动态切换以适应不同工作流需求:
- 模型加载流程 :
- 根据节点输入的模型名称(如 ckpt_name="sd3.5_medium.safetensors")定位文件路径;
- 检查模型缓存(若已加载则直接复用,否则从磁盘读取);
- 解析模型文件(如 Checkpoint 包含 U-Net、VAE、CLIP 等组件);
- 将模型加载至指定设备(GPU 优先,内存不足时 fallback 至 CPU)。
- 模型缓存策略:采用 LRU(最近最少使用)缓存,当内存 / 显存不足时,自动释放最久未使用的模型,平衡性能与资源占用;
- 模型格式支持:兼容.safetensors(安全)、.ckpt(传统)、.bin(权重片段)等格式,支持 LoRA、ControlNet 等扩展模型的动态加载。
3.计算资源调度
为高效利用 GPU/CPU 资源,后端采用多级调度策略:
- 设备分配:优先将模型与计算任务分配至 GPU(如 NVIDIA CUDA),小批量数据或轻量计算可分配至 CPU;
- 显存优化:通过模型分片(Model Sharding)、梯度检查点(Gradient Checkpointing)减少显存占用;
- 任务队列:当多个工作流同时提交时,按优先级(如用户手动指定)排队执行,避免资源竞争;
- 动态批处理:将多个小批量生成任务合并为一个批次(Batch),提升 GPU 利用率(如同时生成 4 张图时,批量大小设为 4)。
(四)数据流转机制
ComfyUI 中,数据在节点间的传递遵循严格的格式规范,确保不同节点(包括自定义节点)之间的兼容性。核心数据类型包括 latent 向量、图像张量、文本编码向量等。
1.潜在空间(Latent Space)数据处理
latent 向量是 ComfyUI 中最核心的数据类型,贯穿从生成到解码的全过程:
- 格式定义:通常为 4 维张量(Batch, Channels, Height, Width),如批量大小 1、4 通道、64×64 尺寸的 latent 表示为 (1,4,64,64);
- 生成流程:EmptyLatentImage 节点生成初始 latent(全零或随机噪声),KSampler 节点通过扩散过程优化 latent,VAEDecode 节点将 latent 解码为图像;
- 操作支持:支持裁剪、缩放、拼接等操作(如通过 LatentCrop 节点调整 latent 尺寸),为局部生成(如人脸修复)提供基础。
2.节点间数据传递规范
节点间的数据传递需满足 "类型匹配" 与 "格式兼容" 原则:
- 类型匹配:输出端口的类型必须与输入端口的类型一致(如 CLIPTextEncode 的输出为 "CONDITIONING" 类型,只能连接至 KSampler 的 positive/negative 输入);
- 格式兼容:即使类型相同,格式也需兼容(如 512×512 的 latent 不能直接输入至要求 1024×1024 的节点,需先通过 LatentUpscale 节点处理);
- 元数据携带:数据传递时会附带元数据(如图像的尺寸、通道数),下游节点可根据元数据自动适配处理逻辑(如 VAE 解码时根据 latent 尺寸计算输出图像尺寸)。
例如,文档中节点 32(EmptyLatentImage)生成 (1,4,64,64) 的 latent,传递至节点 29(KSampler)进行优化,再传递至节点 30(VAEDecode)解码为 (1,3,512,512) 的 RGB 图像,最终由节点 31(SaveImage)保存。
三、ComfyUI 使用方法
ComfyUI 的使用门槛高于一键式工具(如 Automatic1111),但通过节点化工作流可实现高度定制化的图像生成。本节从环境搭建、基础操作、工作流构建到高级技巧,全面讲解其使用方法。
(一)环境搭建与初始化
ComfyUI 的运行依赖 Python 环境、PyTorch 库及 GPU 支持(推荐 NVIDIA GPU,显存≥8GB),环境搭建的正确性直接影响后续使用体验。
1.软硬件需求
- 硬件 :
- GPU:NVIDIA GPU(支持 CUDA 11.7+,如 RTX 3060/4090),显存≥8GB(512×512 图像生成);
- CPU:多核处理器(如 Intel i5/i7,AMD Ryzen 5/7);
- 内存:≥16GB(避免模型加载时内存溢出);
- 存储:≥100GB(存放模型文件,单个 Checkpoint 约 2-10GB)。
- 软件 :
- 操作系统:Windows 10/11、macOS 12+、Linux(Ubuntu 20.04+);
- Python:3.10.x(推荐,兼容性最佳);
- PyTorch:2.0+(需匹配 CUDA 版本,如 cu118)。
2.安装步骤与配置
以 Windows 系统为例,详细安装步骤如下:
-
步骤 1:安装 Python
从Python 官网下载 Python 3.10.x,勾选 "Add Python to PATH",安装完成后通过
python --version验证。 -
步骤 2:克隆 ComfyUI 仓库
打开命令提示符(CMD),执行:
git clone https://github.com/comfyanonymous/ComfyUI.git cd ComfyUI -
步骤 3:安装依赖
执行以下命令安装所需库(国内用户可添加豆瓣源加速):
pip install -r requirements.txt -i https://pypi.douban.com/simple/若使用 NVIDIA GPU,需确保安装 CUDA 版本的 PyTorch:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 -
步骤 4:放置模型文件
将下载的 Checkpoint(如 sd3.5_medium.safetensors)放入ComfyUI/models/checkpoints目录;
CLIP 模型(如 clip_g.safetensors)放入ComfyUI/models/clip目录;
VAE 模型放入ComfyUI/models/vae目录。
-
步骤 5:启动 ComfyUI
执行
python main.py,启动成功后会显示本地访问地址(通常为http://127.0.0.1:8188),在浏览器中打开即可使用。
详细安装流程,可以看我的CSDN博客:在Windows 11+I7+32GB内存+RTX 3060上部署Stable Diffusion 3.5 Medium详细步骤_stable diffusion电脑配置-CSDN博客
3.常见问题排查
- 模型加载失败:检查模型路径是否正确(如 Checkpoint 是否在 checkpoints 目录)、模型文件是否完整(可通过 MD5 校验);
- GPU 未利用 :确认 PyTorch 安装了 CUDA 版本(执行
python -c "import torch; print(torch.cuda.is_available())",返回 True 则正常); - 显存不足 :降低图像尺寸(如从 1024×1024 改为 512×512)、减少批量大小(batch_size=1)、启用显存优化(修改
main.py中的--lowvram参数)。
(二)基础界面与核心概念
熟悉 ComfyUI 的界面组件与核心概念,是构建工作流的前提。
1.界面布局详解
启动 ComfyUI 后,界面分为三个核心区域:
- 左侧节点面板:按功能分类显示所有可用节点,如 "loaders"(加载器)、"conditioning"(条件处理)、"sampling"(采样)、"image"(图像操作)等。展开 "loaders" 可找到 CheckpointLoaderSimple、TripleCLIPLoader 等节点。
- 中间画布:工作流编辑区域,可通过拖拽节点、连接端口构建流程。右键点击画布可呼出菜单(如清空画布、导入 / 导出工作流)。
- 右侧属性面板:选中节点后,显示其可配置参数。例如,选中 KSampler 节点,可修改 seed(种子)、steps(采样步数)、cfg(引导系数)等。
2.节点类型与属性
ComfyUI 的节点按功能可分为六大类,每类节点的核心属性如下:
-
加载器节点(Loaders):
- CheckpointLoaderSimple:加载 Stable Diffusion 模型,核心属性为 ckpt_name(模型文件名);
- TripleCLIPLoader:加载多个 CLIP 模型,核心属性为 clip_name1/2/3(CLIP 文件名);
- VAELoader:加载自定义 VAE 模型,核心属性为 vae_name。
-
条件处理节点(Conditioning):
- CLIPTextEncode:将文本转换为条件向量,核心属性为 text(文本提示词)、clip(关联的 CLIP 模型);
- Conditioningtune:调整条件向量的权重,核心属性为 strength(强度)。
-
采样节点(Sampling):
- KSampler:执行扩散采样,核心属性为 steps(步数)、cfg(引导系数)、sampler_name(采样器类型,如 euler)、scheduler(调度器,如 simple);
- EmptyLatentImage:生成空 latent,核心属性为 width/height(尺寸)、batch_size(批量大小)。
-
解码节点(Decoding):
- VAEDecode:将 latent 解码为图像,核心属性为 samples(latent 数据)、vae(VAE 模型)。
-
图像操作节点(Image):
- SaveImage:保存图像,核心属性为 filename_prefix(文件名前缀)、images(图像数据);
- ImageScale:缩放图像,核心属性为 scale_by(缩放倍数)。
-
工具节点(Utils):
- SeedRandomizer:生成随机种子,核心属性为 seed(初始种子);
- Switch:根据条件切换数据流向,核心属性为 mode(模式)。
3.工作流的基本要素
一个完整的工作流需包含四大要素:
- 模型加载:通过 CheckpointLoader 等节点加载生成所需的模型;
- 条件输入:通过 CLIPTextEncode 等节点提供文本 / 图像条件;
- 生成核心:通过 KSampler 等节点执行扩散采样,生成 latent;
- 结果输出:通过 VAEDecode 解码 latent 为图像,并通过 SaveImage 保存。
(三)基础工作流构建
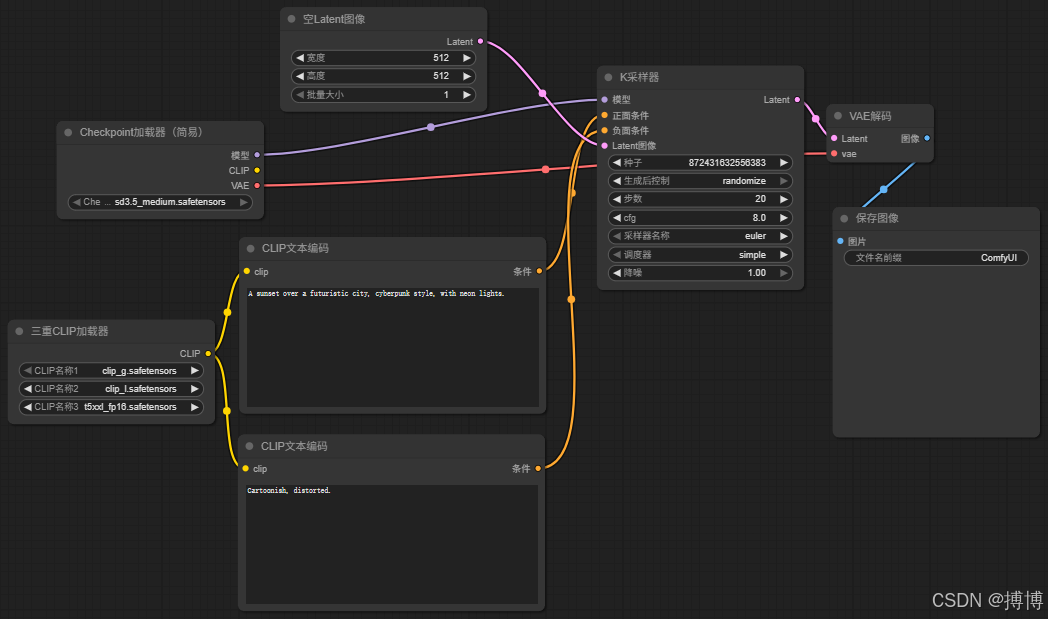
以 "文生图" 为例,讲解基础工作流的构建步骤,涵盖从模型加载到图像保存的完整流程。
1.文生图(Text-to-Image)工作流
目标:根据文本提示词 "a cat sitting on a windowsill, sunny day, photorealistic" 生成写实风格图像。
步骤 1:加载核心模型
- 从左侧节点面板拖拽 "CheckpointLoaderSimple" 至画布,在右侧属性面板设置 ckpt_name 为 "sd3.5_medium.safetensors";
- 拖拽 "TripleCLIPLoader" 至画布,设置 clip_name1="clip_g.safetensors"、clip_name2="clip_l.safetensors"、clip_name3="t5xxl_fp16.safetensors"。
步骤 2:构建文本条件
- 拖拽两个 "CLIPTextEncode" 节点至画布(分别用于正向 / 反向提示词);
- 选中第一个 CLIPTextEncode 节点,设置 text 为 "a cat sitting on a windowsill, sunny day, photorealistic",并将其 "clip" 输入端口与 TripleCLIPLoader 的输出端口连接;
- 选中第二个 CLIPTextEncode 节点,设置 text 为 "blurry, low detail, dark, no lighting and shadow, distorted",同样连接至 TripleCLIPLoader 的输出。
步骤 3:生成空 Latent
- 拖拽 "EmptyLatentImage" 至画布,设置 width=512、height=512、batch_size=1。
步骤 4:配置采样器
- 拖拽 "KSampler" 至画布,按以下方式连接输入:
- model:连接 CheckpointLoaderSimple 的 "model" 输出;
- positive:连接第一个 CLIPTextEncode 的输出;
- negative:连接第二个 CLIPTextEncode 的输出;
- latent_image:连接 EmptyLatentImage 的输出;
- 在属性面板设置 steps=20、cfg=8、sampler_name="euler"、scheduler="simple"、seed = 随机值(如 123456)。
步骤 5:解码与保存图像
- 拖拽 "VAEDecode" 至画布,连接 samples=KSampler 的输出、vae=CheckpointLoaderSimple 的 "vae" 输出;
- 拖拽 "SaveImage" 至画布,设置 filename_prefix="ComfyUI_cat",连接 images=VAEDecode 的输出。
步骤 6:执行工作流
点击画布上方的 "Queue Prompt" 按钮,ComfyUI 将按依赖关系执行节点,生成的图像会保存至ComfyUI/output目录(可在 SaveImage 节点中修改路径)。
2.图生图(Image-to-Image)工作流
图生图是在现有图像基础上进行修改(如风格迁移、局部重绘),核心是通过 VAE 编码器将图像转换为 latent,再进行扩散采样。
额外步骤:
- 拖拽 "LoadImage" 节点至画布,设置 image = 待处理图像路径;
- 拖拽 "VAEEncode" 节点至画布,连接 pixels=LoadImage 的输出、vae=CheckpointLoader 的 VAE 输出,将图像编码为 latent;
- 将 KSampler 的 latent_image 输入从 EmptyLatentImage 改为 VAEEncode 的输出,并设置 denoise=0.7(值越低,保留原图越多)。
(四)高级功能与技巧
掌握高级功能可大幅提升 ComfyUI 的使用效率,实现更复杂的生成需求(如批量生成、风格微调)。
1.自定义节点开发与集成
ComfyUI 支持通过 Python 脚本开发自定义节点,扩展其功能(如添加图像滤镜、接入外部 API)。开发步骤如下:
-
步骤 1:创建节点类 :继承
Node基类,定义输入(INPUT_TYPES)、输出(RETURN_TYPES)与执行逻辑(run 方法):class MyCustomNode: @classmethod def INPUT_TYPES(s): return { "required": { "image": ("IMAGE",), # 输入为图像类型 "brightness": ("FLOAT", {"default": 1.0, "min": 0.1, "max": 2.0}) } } RETURN_TYPES = ("IMAGE",) FUNCTION = "adjust_brightness" def adjust_brightness(self, image, brightness): # 实现亮度调整逻辑 return (image * brightness,) -
步骤 2:注册节点 :在
ComfyUI/custom_nodes目录下创建文件夹(如my_nodes),将脚本放入其中,并在__init__.py中注册:from .my_node import MyCustomNode NODE_CLASS_MAPPINGS = {"MyCustomNode": MyCustomNode} NODE_DISPLAY_NAME_MAPPINGS = {"MyCustomNode": "亮度调整节点"} -
步骤 3:重启 ComfyUI:自定义节点会自动加载,可在左侧面板中找到并使用。
2.工作流优化与参数调优
- 采样器选择:不同采样器生成效果差异显著,euler 适合快速预览,dpmpp_2m_karras 适合高质量生成,ddim 生成速度快但细节较少;
- 步数与 CFG 权衡:steps 增加可提升细节(如从 20 增至 50),但生成时间延长;cfg 过高(如 > 12)会导致图像过饱和,过低(如 < 5)会降低文本相关性;
- 种子与多样性:固定 seed 可复现结果,随机 seed 可增加多样性;通过 SeedRandomizer 节点批量生成不同 seed 的图像,选择最优结果;
- 模型切换技巧:通过 "CheckpointSwitcher" 节点在工作流中动态切换模型(如先用人像模型生成主体,再用风景模型优化背景)。
3.批量生成与自动化配置
对于需要生成大量图像的场景(如数据集构建),可通过以下方式实现自动化:
- 批量提示词:使用 "TextList" 节点导入提示词列表,配合 "Loop" 节点依次生成;
- API 调用:通过 Python 脚本调用 ComfyUI 的 API(如前文用户需求中的脚本),批量提交工作流;
- 工作流模板:将常用工作流保存为 JSON 模板,通过 "Load Workflow" 快速加载,修改提示词后即可生成。
(五)典型应用场景案例
ComfyUI 的灵活性使其适用于多种场景,以下为三个典型案例:
1.艺术创作:赛博朋克风格生成
需求 :生成 "未来城市日落,赛博朋克风格,霓虹灯光" 的艺术图像。
关键节点配置:
- 正向提示词:"A sunset over a futuristic city, cyberpunk style, neon lights, vibrant colors, highly detailed";
- 采样器:steps=30,cfg=7.5,sampler_name="dpmpp_2m_karras";
- 额外节点:添加 "StyleModelLoader" 加载赛博朋克风格 LoRA 模型,通过 "LoraLoader" 节点调整权重(strength=0.7)。
2.设计辅助:产品原型渲染
需求 :生成 "无线耳机,白色,简约设计,放在木质桌面上,自然光" 的产品原型图。
关键节点配置:
- 图生图工作流:以耳机线稿为输入,denoise=0.6;
- 正向提示词:"wireless earbuds, white, minimalist design, wooden table, natural light, product photography";
- 后期处理:添加 "ImageSharpen" 节点增强锐度,"ColorBalance" 节点调整色调。
3.科研实验:模型对比研究
需求 :对比不同 CLIP 模型(clip_g vs clip_l)对生成结果的影响。
关键节点配置:
- 复制两套 CLIP 加载与文本编码节点,分别使用 clip_g 与 clip_l;
- 保持其他参数(seed、steps、cfg)一致,通过 "ImageGrid" 节点将生成结果拼接,直观对比差异。
四、ComfyUI 接口组成与开发
ComfyUI 提供完善的编程接口,支持外部工具调用、自动化工作流执行、自定义节点开发等高级功能。其接口体系包括 RESTful API、WebSocket 实时接口、工作流 JSON 规范等。
(一)API 接口体系
ComfyUI 的后端通过 FastAPI 提供接口服务,支持 HTTP 请求与 WebSocket 实时通信,满足不同场景的需求。
1.RESTful API 核心端点
ComfyUI 的主要 API 端点如下,所有请求需以http://localhost:8188为基础 URL:
| 端点路径 | 请求方法 | 功能描述 | 请求体示例 |
|---|---|---|---|
/prompt |
POST | 提交工作流,返回任务 ID | {"prompt": {...}, "client_id": "my_script"} |
/history |
GET | 获取任务历史记录,需指定 prompt_id | ?prompt_id=abc123 |
/queue |
GET | 获取当前任务队列状态 | - |
/upload/image |
POST | 上传图像至服务器(用于图生图工作流) | multipart/form-data格式,包含图像文件 |
/executed |
GET | 检查任务是否执行完成,需指定 prompt_id | ?prompt_id=abc123 |
例如,提交工作流的请求体中,prompt字段为工作流的 JSON 结构(如用户提供的文档中的节点配置),client_id用于标识调用方。
2.WebSocket 实时接口
WebSocket 接口用于实时获取生成进度(如采样步数、剩余时间),连接地址为ws://localhost:8188/ws?client_id=my_script。
消息格式:
-
服务器发送的进度消息:
{ "type": "progress", "data": { "prompt_id": "abc123", "progress": 0.75, # 进度(0-1) "current_step": 15, "total_steps": 20, "node": "KSampler" # 当前执行的节点 } } -
生成完成消息(json):
{ "type": "executed", "data": { "prompt_id": "abc123", "outputs": { "31": {"images": [{"filename": "ComfyUI_123.png", "type": "image"}]} } } }
(二)工作流 JSON 规范
ComfyUI 的工作流以 JSON 格式存储,包含节点定义、输入参数、连接关系等信息,是 API 调用的核心数据。
设置好工作流之后,可以导出工作流的API.
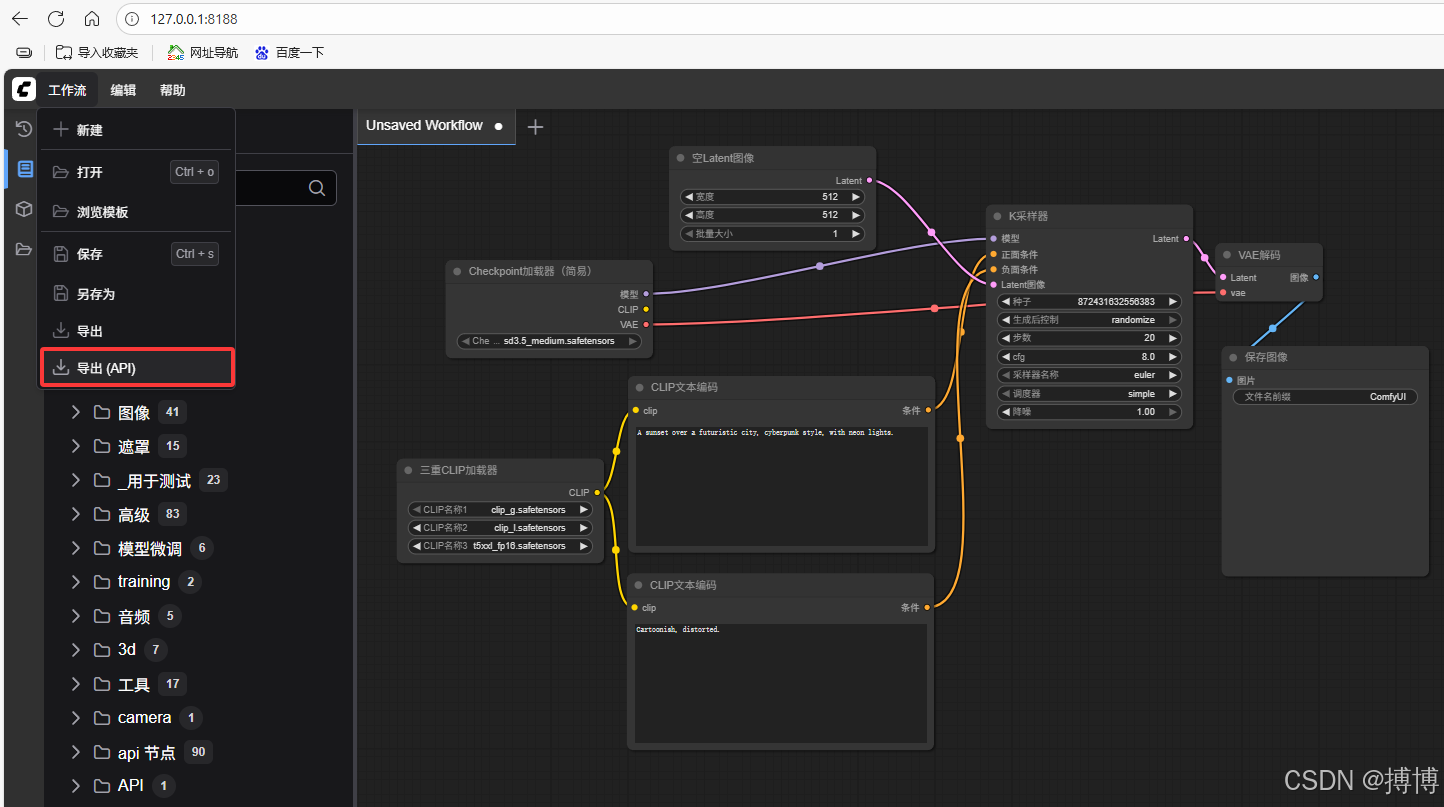
1.节点定义格式
工作流 JSON 是一个字典,键为节点 ID(如 "26""27"),值为节点详情,每个节点包含以下字段:
inputs:节点的输入参数(如ckpt_name、text),其中依赖其他节点的参数以[节点ID, 输出索引]表示(如"model": ["26", 0]表示引用节点 26 的第 0 个输出);class_type:节点的类名(如 "CheckpointLoaderSimple"),用于后端识别节点类型;_meta:元数据(可选),包含节点标题等信息,用于前端显示。
例如,文档中节点 29(KSampler)的定义(json):
"29": {
"inputs": {
"seed": 264797974609293,
"steps": 20,
"cfg": 8,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["26", 0], # 引用节点26的第0个输出(模型)
"positive": ["27", 0], # 引用节点27的输出(正向条件)
"negative": ["28", 0], # 引用节点28的输出(反向条件)
"latent_image": ["32", 0] # 引用节点32的输出(空latent)
},
"class_type": "KSampler",
"_meta": {"title": "K采样器"}
}2.输入输出连接规则
节点间的连接需遵循以下规则:
- 输出索引:节点的输出按顺序编号(从 0 开始),如 CheckpointLoaderSimple 的输出通常为 model, clip, vae,对应索引 0、1、2;
- 类型匹配:输入参数的类型需与输出参数的类型一致(如 "model" 类型的输出只能连接至 "model" 类型的输入);
- 多输出支持:部分节点支持多输出(如 TripleCLIPLoader 输出多个 CLIP 模型),可通过不同索引连接(如 "84", 0、"84", 1)。
3.元数据(_meta)的作用
_meta字段主要用于前端显示,不影响后端执行,常见键包括:
title:节点在前端显示的名称(如 "Checkpoint 加载器(简易)");description:节点功能描述(可选);category:节点在左侧面板中的分类(如 "loaders")。
(三)外部调用与集成
通过 API 接口,可将 ComfyUI 集成到其他系统(如设计工具、自动化流水线),以下为 Python 调用示例。
1.Python SDK 与调用示例
使用requests库调用 ComfyUI 的 API,实现批量生成图像(python):
import json
import requests
import time
COMFYUI_API = "http://localhost:8188"
def submit_workflow(workflow):
"""提交工作流并返回prompt_id"""
response = requests.post(
f"{COMFYUI_API}/prompt",
json={"prompt": workflow, "client_id": "batch_generator"}
)
return response.json().get("prompt_id")
def wait_for_completion(prompt_id, timeout=300):
"""等待任务完成,返回生成结果"""
start_time = time.time()
while time.time() - start_time < timeout:
response = requests.get(f"{COMFYUI_API}/history?prompt_id={prompt_id}")
history = response.json()
if prompt_id in history:
return history[prompt_id]["outputs"]
time.sleep(2)
raise TimeoutError("任务超时")
# 加载工作流模板(如用户提供的JSON)
with open("workflow_template.json", "r") as f:
workflow = json.load(f)
# 批量生成(修改提示词)
prompts = [
"a dog playing in the park, sunny",
"a cat sleeping on a couch, cozy"
]
for i, prompt in enumerate(prompts):
# 更新正向提示词
workflow["27"]["inputs"]["text"] = f"{prompt}, photorealistic"
# 提交工作流
prompt_id = submit_workflow(workflow)
print(f"提交任务 {i+1},ID:{prompt_id}")
# 等待完成
result = wait_for_completion(prompt_id)
print(f"任务 {i+1} 完成,图像路径:{result['31']['images'][0]['filename']}")2.第三方工具集成方案
- 设计软件插件:为 Photoshop、Figma 等设计工具开发插件,通过 API 调用 ComfyUI 生成素材,直接导入设计项目;
- 自动化流水线:结合 Airflow、Prefect 等工作流调度工具,定时生成图像(如每日生成天气预报配图);
- Web 应用集成:在 Web 应用中嵌入 ComfyUI 的 API 调用,为用户提供在线图像生成功能(需注意资源限制)。
(四)自定义节点开发指南
自定义节点是扩展 ComfyUI 功能的核心方式,以下为开发的详细规范与流程。
1.节点类结构与方法
一个完整的自定义节点需包含以下部分:
- INPUT_TYPES:类方法,定义输入参数的名称、类型、默认值等;
- RETURN_TYPES:类属性,定义输出参数的类型;
- FUNCTION:类属性,指定执行逻辑的方法名;
- run 方法:实现节点的核心功能,输入为 INPUT_TYPES 定义的参数,输出需与 RETURN_TYPES 匹配。
示例:图像翻转节点(python)
class ImageFlip:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"image": ("IMAGE",), # 输入为图像类型
"direction": (["horizontal", "vertical"], {"default": "horizontal"}) # 下拉选择
}
}
RETURN_TYPES = ("IMAGE",) # 输出为图像类型
FUNCTION = "flip_image" # 执行方法名为flip_image
def flip_image(self, image, direction):
# 图像翻转逻辑(image为PyTorch张量,形状为[B, H, W, C])
if direction == "horizontal":
flipped = image.flip(dims=[2]) # 水平翻转(W维度)
else:
flipped = image.flip(dims=[1]) # 垂直翻转(H维度)
return (flipped,)2.输入输出参数定义
参数类型需遵循 ComfyUI 的规范,常用类型包括:
- 基础类型:
INT(整数)、FLOAT(浮点数)、STRING(字符串)、BOOLEAN(布尔值); - 媒体类型:
IMAGE(图像张量,形状 B, H, W, C)、LATENT(latent 张量,形状 B, C, H, W)、CONDITIONING(文本条件向量); - 模型类型:
MODEL(U-Net 模型)、CLIP(CLIP 模型)、VAE(VAE 模型); - 枚举类型:通过元组定义可选值(如
(["option1", "option2"], ...))。
3.调试与发布流程
- 调试 :将节点脚本放入
custom_nodes目录,启动 ComfyUI 时添加--debug参数,通过控制台输出的错误信息排查问题; - 测试:在工作流中添加自定义节点,检查输入输出是否符合预期,参数调整是否生效;
- 发布 :将节点打包为插件(包含
__init__.py与核心脚本),上传至 GitHub 或 ComfyUI 社区,供其他用户下载使用。
五、ComfyUI 的优势、局限与未来趋势
ComfyUI 作为生成式 AI 工具的代表,其设计理念与技术实现反映了行业的发展方向。深入分析其优势、局限与未来趋势,可帮助用户更好地利用工具并把握技术演进。
(一)与同类工具的对比优势
相比 Automatic1111、Stable Diffusion WebUI 等一键式工具,ComfyUI 的核心优势在于灵活性与可控性:
1.灵活性与可控性
- 工作流可视化:用户可直观看到生成的每一步(如 latent 生成→采样→解码),便于调试;
- 节点自由组合:支持任意节点的连接(如同时使用多个 CLIP 模型、混合不同 LoRA 权重),实现复杂逻辑(如先修复人脸,再优化背景);
- 无黑箱操作:所有参数(如采样器、步数、CFG)均暴露给用户,无隐藏默认值,结果可复现性强。
2.性能与扩展性
- 资源利用高效:无多余 UI 渲染与后台进程,GPU 利用率更高(如生成速度比 Automatic1111 快 10%-20%);
- 自定义节点生态:社区已开发数千个自定义节点(如 ControlNet、Image2Image+),覆盖从图像修复到 3D 生成的多种功能;
- 低耦合架构:支持替换核心组件(如用 TensorRT 加速的 U-Net 替换原生模型),便于性能优化。
(二)当前局限与挑战
尽管 ComfyUI 优势显著,但其在易用性、资源消耗等方面仍存在局限:
1.学习门槛与易用性
- 新手友好度低:节点化设计要求用户理解扩散模型的基本原理(如 latent、CLIP 作用),入门成本高于一键式工具;
- 工作流复杂度高:简单的文生图也需连接 6-8 个节点,复杂工作流(如多模型混合)可能包含数十个节点,编辑成本高;
- 文档不完善:官方文档较为简略,自定义节点的使用说明依赖社区贡献,新用户易遇瓶颈。
2.资源消耗与优化空间
- 显存占用高:复杂工作流(如 1024×1024 图像 + 多个 LoRA)需 12GB 以上显存,普通用户难以负担;
- 生成速度:尽管单步效率高,但复杂工作流的总耗时可能更长(如添加多个后处理节点);
- 跨平台支持有限:对 AMD GPU 与 macOS 的优化不足,部分节点(如 TensorRT 加速)仅支持 NVIDIA GPU。
(三)未来发展方向
随着生成式 AI 技术的演进,ComfyUI 的发展将围绕功能扩展、易用性提升、生态完善三个方向展开:
1.多模态支持与功能扩展
- 多模态生成:支持文本、图像、音频、3D 模型的联合生成(如输入文本与音频,生成匹配的视频);
- 实时交互:通过低延迟采样算法(如 PLMS、DDIM 快速模式),实现 "边调整参数边生成" 的实时预览;
- AI 辅助设计:集成大语言模型(如 GPT-4),自动生成工作流(如用户输入 "生成赛博朋克风格图像",AI 自动配置节点与参数)。
2.社区生态与标准化建设
- 节点标准化:制定自定义节点的输入输出规范,解决不同节点间的兼容性问题;
- 工作流市场:建立官方工作流分享平台,用户可上传 / 下载模板(如 "产品渲染模板""人像修复模板"),降低复用成本;
- 企业级支持:提供私有部署方案、技术支持与培训服务,满足企业用户(如设计公司、游戏工作室)的定制化需求。
结语
ComfyUI 通过节点化工作流的设计,将复杂的扩散模型生成过程转化为可编辑、可扩展的可视化逻辑,为用户提供了前所未有的控制权。从原理层面的扩散模型与潜在空间,到系统结构的前端后端分离,再到使用方法的工作流构建与 API 调用,ComfyUI 的每一个细节都体现了 "以用户为中心" 的技术理念。
尽管当前存在学习门槛高、资源消耗大等局限,但其灵活可控的核心优势已使其成为专业用户的首选工具。随着社区生态的完善与技术的迭代,ComfyUI 有望在生成式 AI 的浪潮中持续引领工具设计的创新方向,为艺术创作、设计辅助、科研实验等领域提供更强大的支持。
对于用户而言,深入掌握 ComfyUI 不仅是提升图像生成效率的手段,更是理解生成式 AI 技术底层逻辑的途径。通过节点的连接与调试,用户能直观感受到 AI 如何将文本转化为图像,如何通过数学与神经网络的协同创造出逼真的视觉内容 ------ 这正是技术与艺术融合的魅力所在。