逻辑结构的分类
(1)线性结构
- 线性表
(2)非线性结构
- 树结构
- 图结构
- 集合结构
**1.**树概念及结构
1.1****树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。
把它叫做树是因****为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
- 有一个特殊的结点,称为根结点,根节点没有前驱结点。
- 除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、......、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。
- 因此,树是递归定义的。
注意:树形结构中,子树之间不能有交集,否则就不是树形结构*(图)*
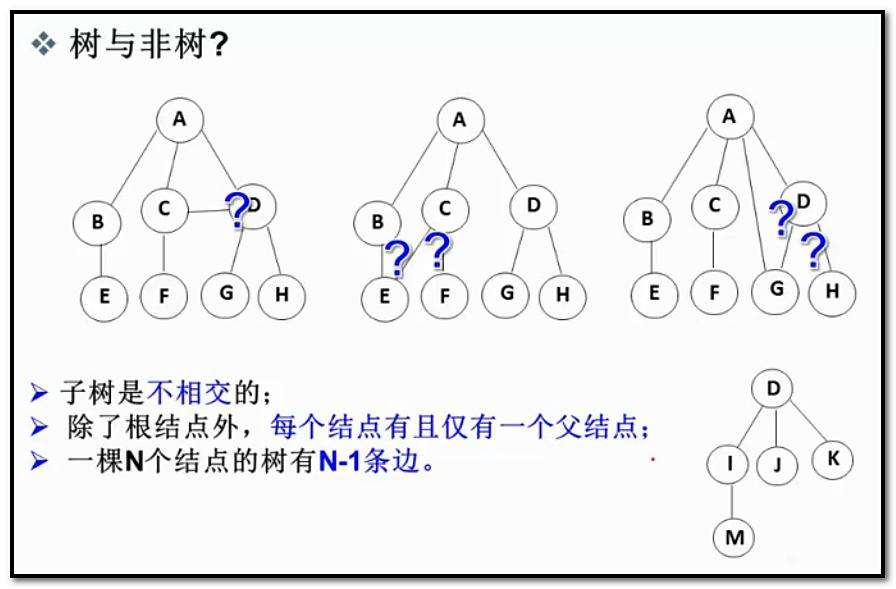
- 子树是不相交的++------树里面没有环++;(图)
- 除了根结点外,每个结点有且仅有一个父结点;
- 一棵N个结点的树有N-1条边;
1.2****树的相关概念
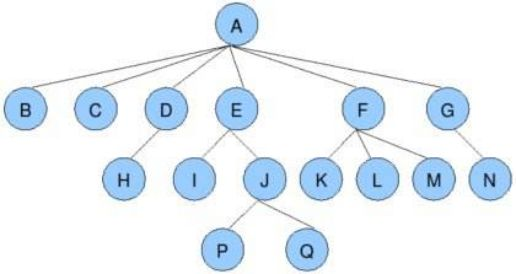
树的相关概念*(树中的概念都是类比"树"和"人类亲缘关系",来定义的)*
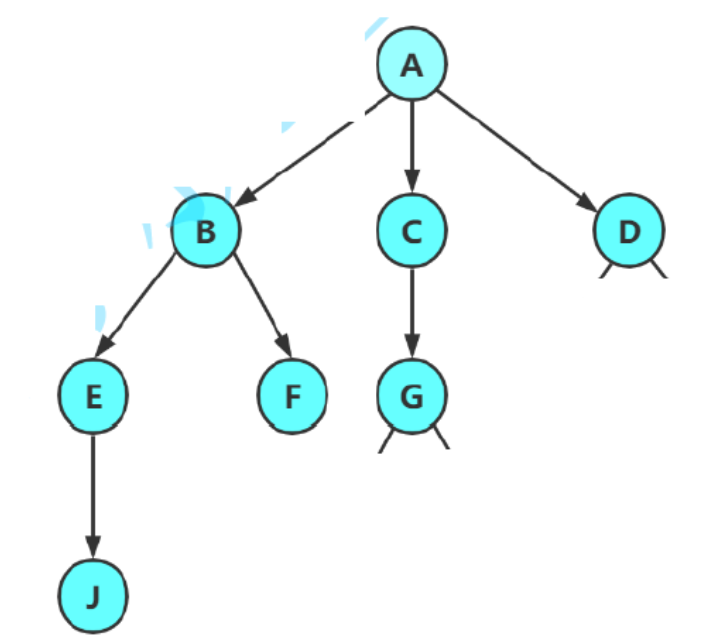
- ++节点的度++ :一个节点含有的子树的个数称为该节点的度; 如上图:A结点的度为6。
- 树的度 :一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
- ++叶节点(终端节点)++ :度为0的节点称为叶节点; 如上图:B、C、H、I...等节点。
- 分支节点(非终端节点) :度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
- ++双亲节点(父节点)++ :若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
- ++孩子节点(子节点)++ :一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
- (亲)兄弟节点 :具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
- 堂兄弟节点 :双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
- 节点的层次 :从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- ++树的高度(深度)++ :树中节点的最大层次; 如上图:树的高度为4
- ++节点的祖先++ :从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
- ++子孙++ :以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
- 森林 :由m(m>0)棵互不相交的树的集合称为森林;(并查集)
(子树之间不能称森林)
一颗树有两种结点构成:分支结点、叶子结点。
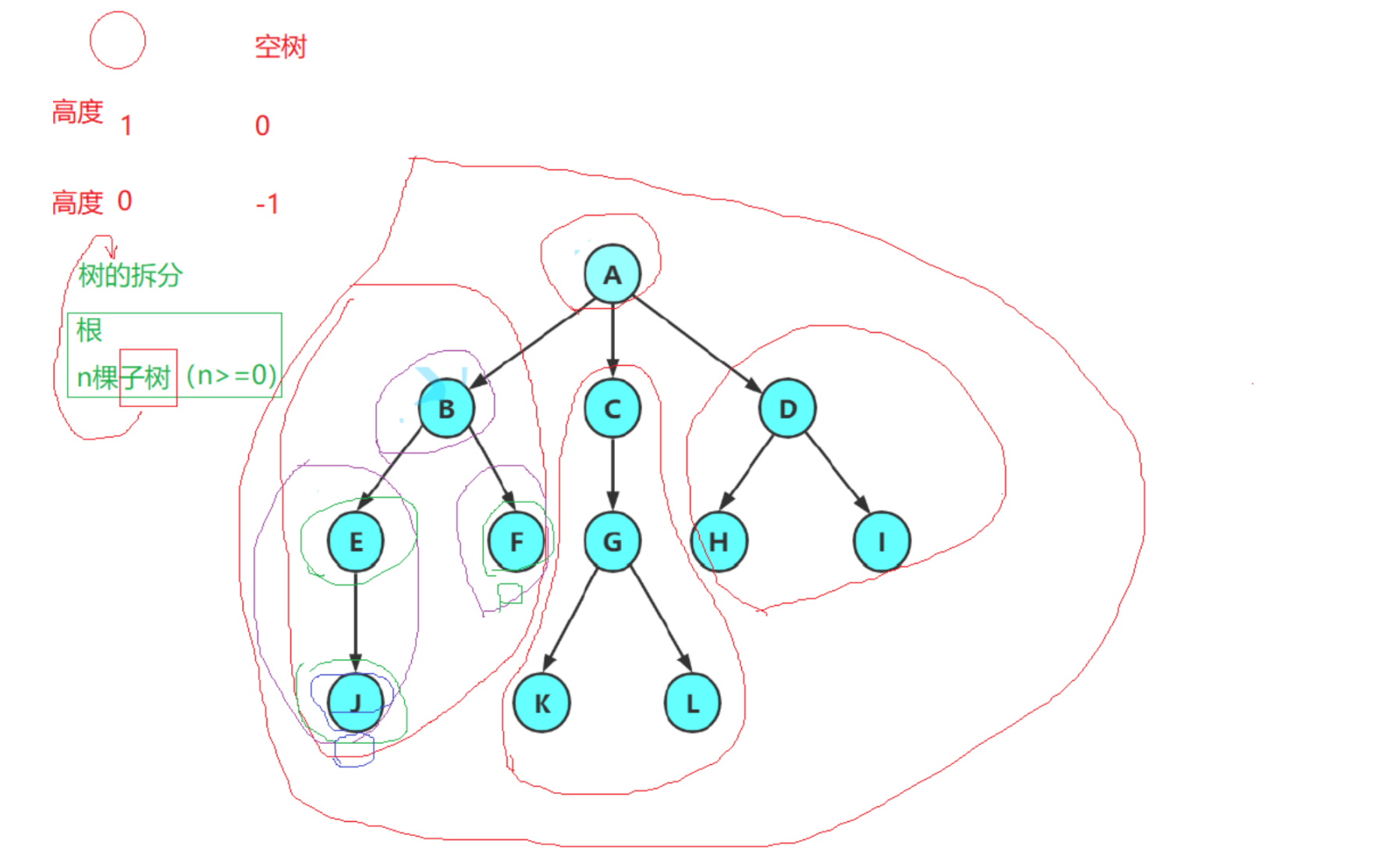
根节点的层次------有争议
- 根节点的层次为0(空树的高度为-1,比较奇怪)
- 根节点的层次为1(建议)
数组的下标从0开始,根本原因在于数组的访问a0的本质是指针解引用*(a+0)。
树的拆分 = 根 + n棵子树(=根 + m棵子树(=根+......))(递归思维)
1.3****树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了。
既要保存值域 ,也要保存结点和结点之间****的关系。
1.3.0 孩子表示法
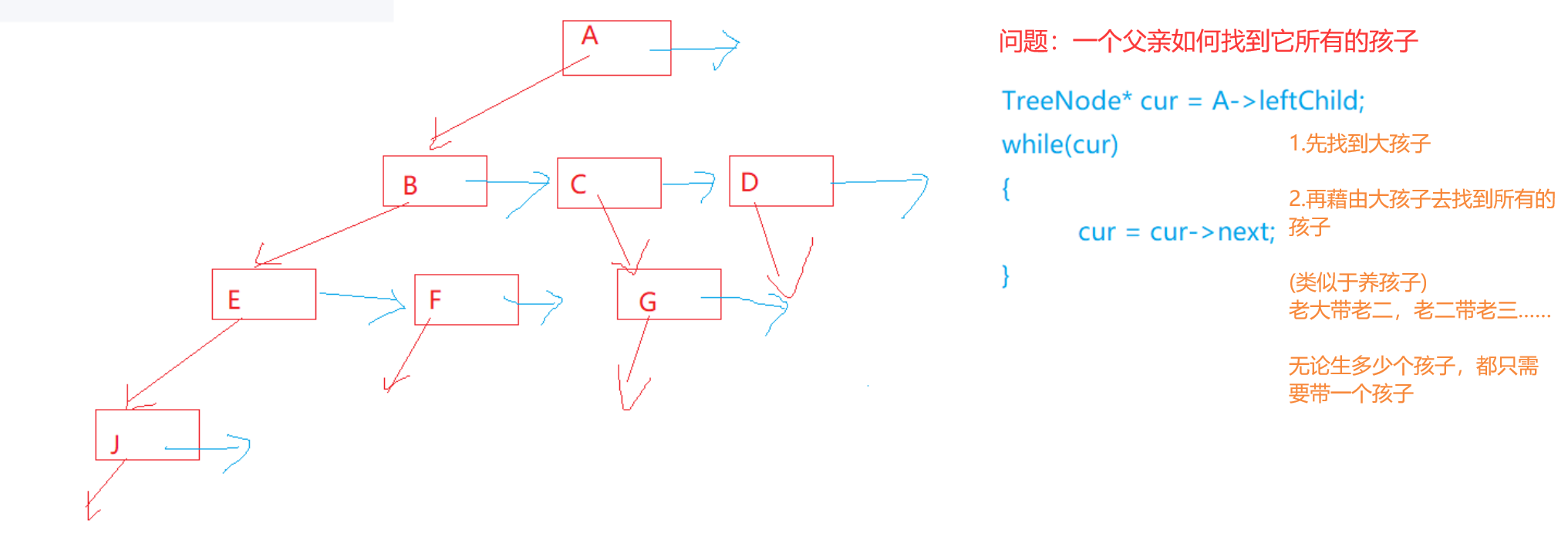
由于树的孩子结点数目是不确定的,就不能简单地像单链表一样一个结点使用一个指针链向下一个结点。

树的最大孩子结点数目------树的度N,是确定的,那每个结点就给N个指针。

但是只有度最大的结点会使用到全部6个数组空间,其他度很小的节点用这个结构就会产生很大的空间浪费。(二叉树的链式存储,是这种方式------二叉树最多两个孩子)

实际中树有很多种表示方式如:
双亲表示法 、孩子表示法 、孩子-双亲表示法 、孩子-兄弟表示法等。
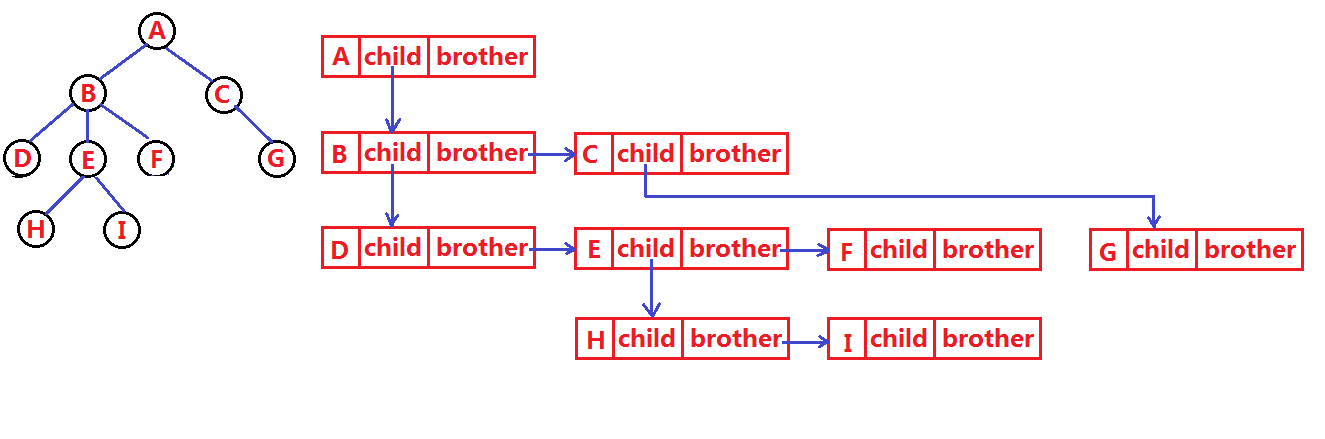
我们这里就简单的了解其中最常用的 孩子-兄弟表示法。(针对任意树)
(二叉树最常用孩子表示法,记录该结点所有的子树地址)
1.3.1 孩子-兄弟表示法
树的节点的结构
cpp
typedef int DataType;
struct Node
{
struct Node* first_Child; // 第一个孩子结点
struct Node* next_Brother; // 指向其下一个(亲)兄弟结点
DataType _data; // 结点中的数据域
};
1.3.2 双亲表示法(只能往上找父亲)
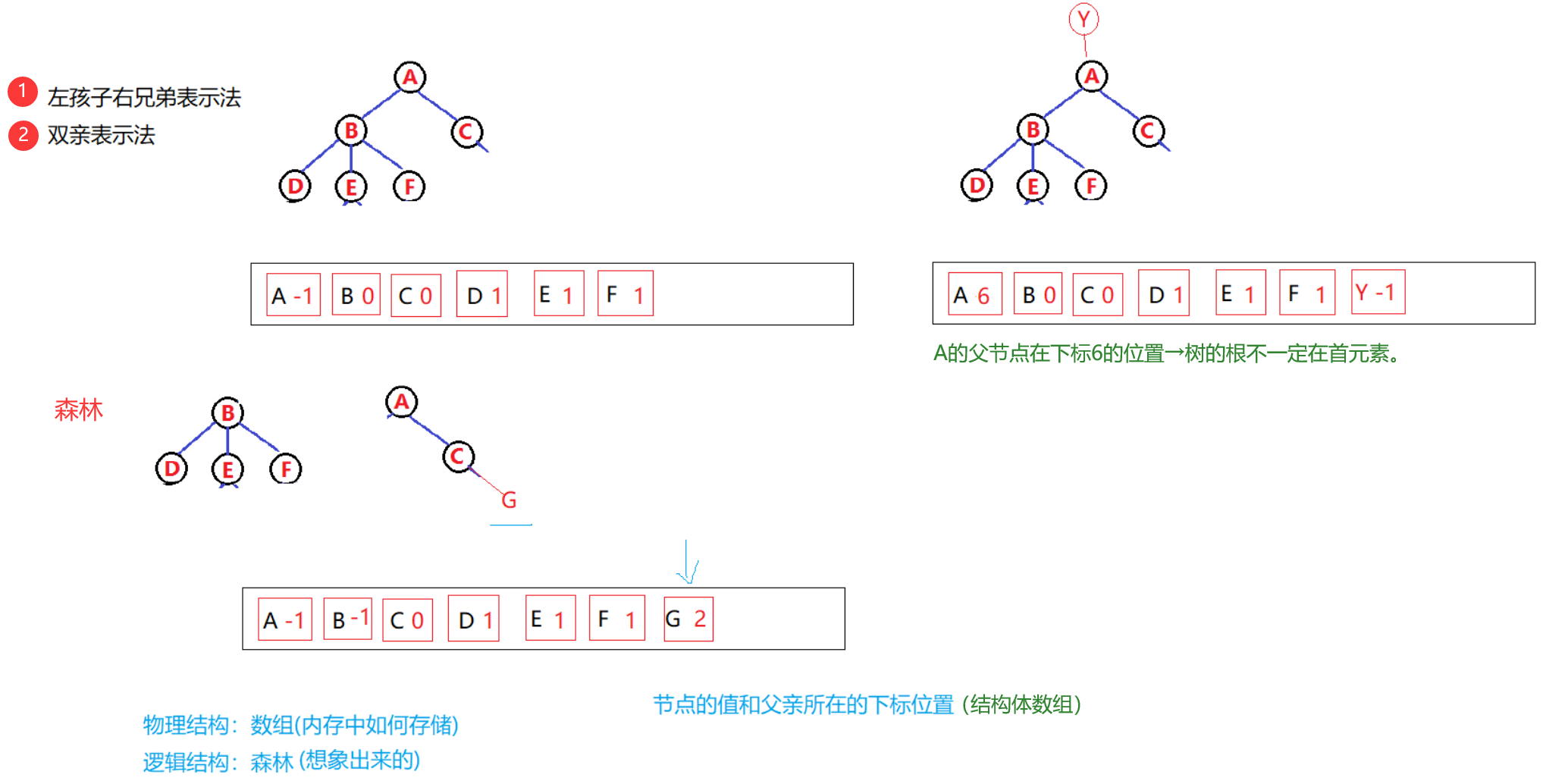
- 物理结构:数组(内存中如何存储)
- 逻辑结构:森林(想象出来的)
除了节点的值之外,只去存自己的双亲(父节点)。
- 存父节点的指针(地址)------链式存储
- 存父节点的下标------顺序存储
结果:只能往回找祖宗不能往下找孩子。
并查集就是这样设计的
好处:可以用一个存储结构(链表、顺序表)表示一个森林
- 怎么知道是几棵树?→看根的个数(根下标-1、父地址NULL)
- 怎么知道属于哪棵树?→一步一步往回找祖宗,看最后根下标,一样就属于同一棵树。
应用:判断两个元素是否属于同一个朋友圈。
1.3.3 孩子表示法(只能往下找孩子)
二叉树就是使用的这种表示法。
1.4****树在实际中的运用(表示文件系统的目录树结构)
数据结构的类型
- **存储型:**用于存储数据。
- **表示型:**表示某种结构(同时也是在存储数据)。(树、图)
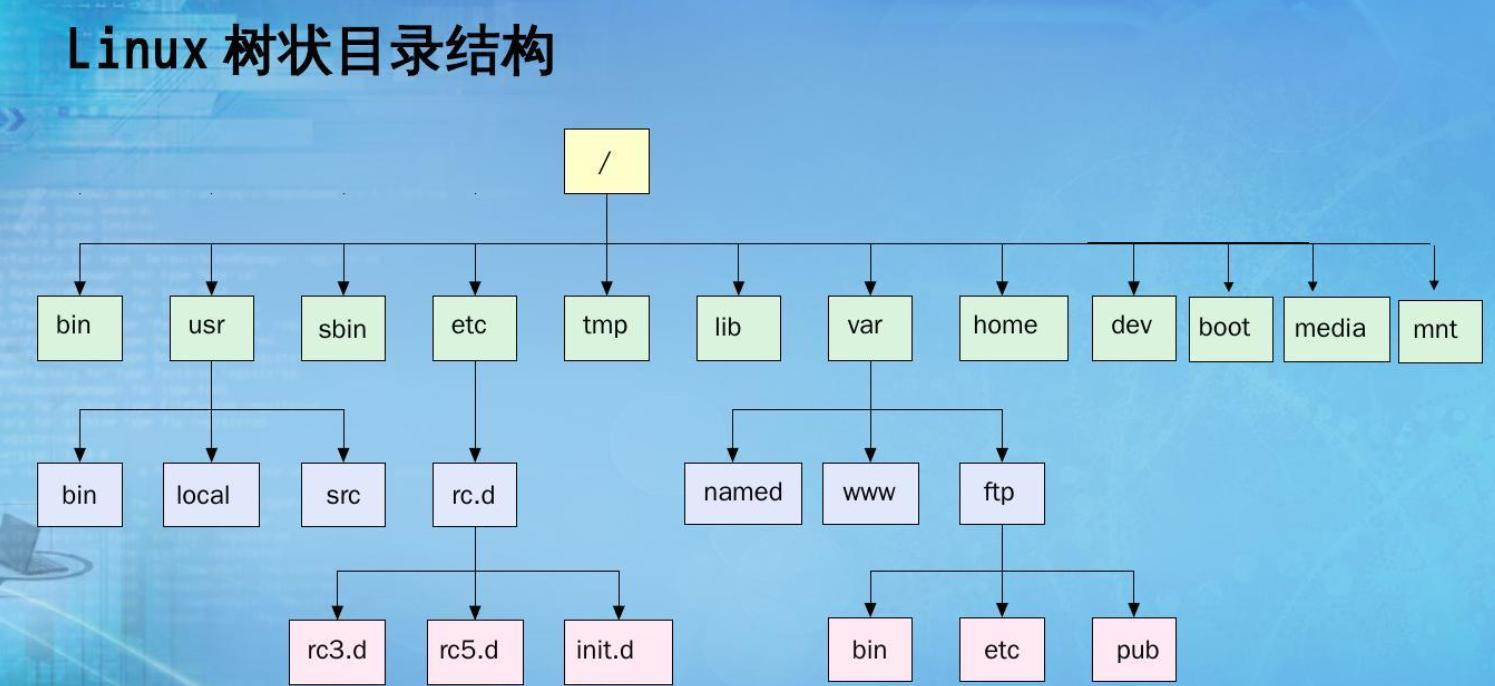
Windows的文件系统可以认为是一个森林。
C盘和D盘两个根目录可以认为是两个根,用的就是左孩子右兄弟表示法。
新建文件夹相当于新建一个兄弟。
平时画的思维导图也可以理解为一种树形结构。
2. 二叉树概念及结构
数据结构的核心应用还是存储数据,用树来存储数据没有多大的好处,除非像上面那种一个结点下面有多个分支的场景。
更多的时候,由很多数据需要存储,还是会选择:顺序表、链表。
树形结构比较复杂,实践当中用得并不多。
树这个部分真正用得多的是二叉树------最多有两个孩子的树。
(加了限制的树,才方便控制,才能广泛应用)
2.1 概念
一棵二叉树是结点的一个有限集合,该集合:
- 或者为空
- 由一个根节点加上两棵别称为左子树和右子树的二叉树组成
由于二叉树一个节点最多只有两个孩子,于是二叉树这里便把孩子作了严格的区分:
------左孩子、右孩子。
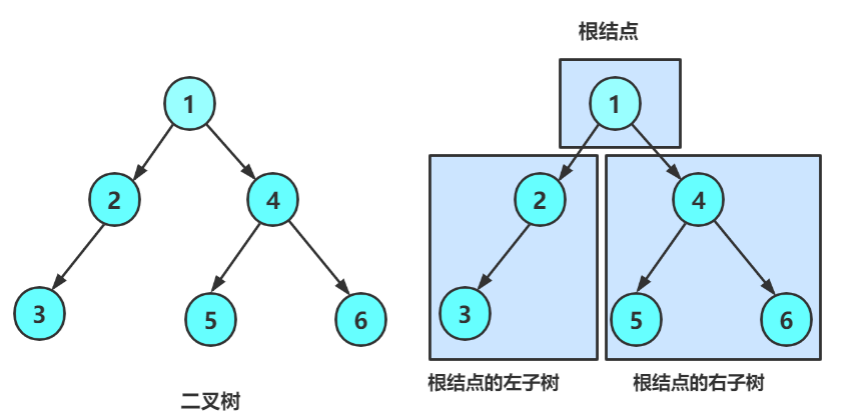
从上图可以看出:
- 二叉树不存在度大于2的结点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
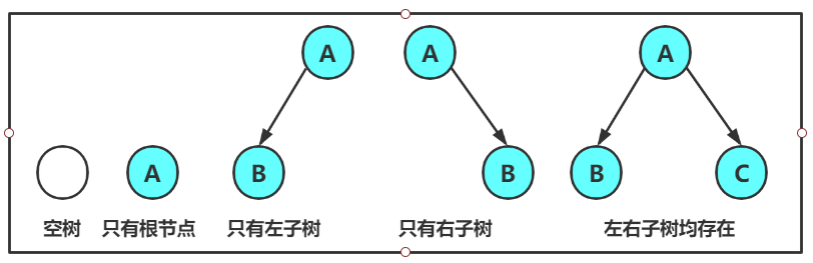
注意
对于任意的二叉树都是由以下几种情况复合而成的:
那二叉树用来存储数据有什么意义呢?
没什么意义,更适用的是顺序表、链表,没有必要用树来存。
二叉树单纯存储数据是没啥价值------不如顺序表/链表。
树→二叉树→更加限制的二叉树,才是实践中有比较多的应用。
以前的顺序表、链表主要用于存储数据,栈和队列在存储数据上加了一些要求。
这里学的数据结构除了进行数据存储,还要实现一些特定的功能。
应用①------搜索二叉树
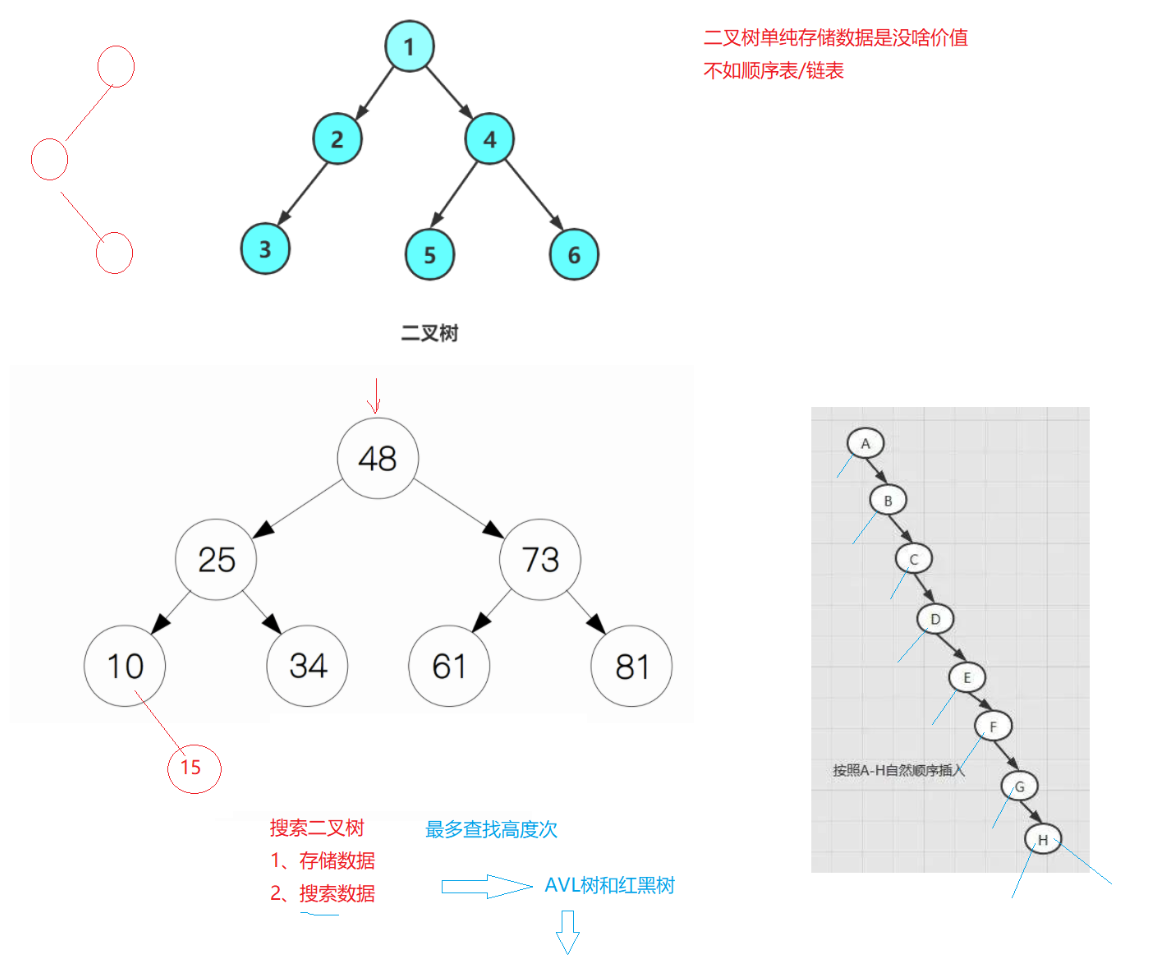

例子:找61一定在48右边。
→有没有可能在48左边呢?比如25的右边→答:不可能------因为当初61在插入的时候就不可能往48左边走,更不可能到达25右边的位置
→所以说二叉搜索树的特点:左子树的右孩子一定比父亲大、比爷爷小。
二叉搜索树(搜索二叉树)
要求
- 左子树 < 根 < 右子树*(这也是插入数据、查找数据的规则)*
应用
- 存储数据
- 查找数据
优势
- 最多查找高度次
缺陷
- 按自然顺序插入→搜索二叉树退化成链表------查找效率O(N)
(单链表只有一个指针,二叉树是两个指针,还有一个指向NULL)
AVL树、红黑树(搜索二叉树再扩展的两种树)
......
多叉搜索树(压缩高度)------M阶B树(数据库引擎)
......
二叉树线索化:方便遍历,实践中没什么用。
哈夫曼树(二叉树):主要用于文件压缩算法,实际当中用得比较少。
2.2 现实中的二叉树

2.3 特殊的二叉树
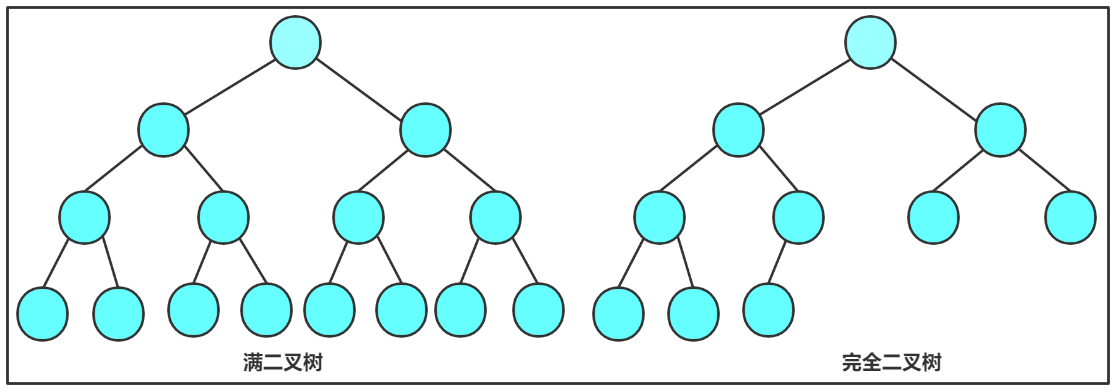
- 满二叉树 :一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k)-1,则它就是满二叉树。(前n-1层每个结点的度都是2,叶子结点都在最后一层)
- 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点,都与深度为K的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。
(前n-1层都是满的,最后一层不一定满,但是要求从左到右连续)
满二叉树是一种特殊的完全二叉树。
2.4****二叉树的性质
若规定根节点的层数为1,则一棵非空二叉树的**第i层上最多有2^(i-1)**个结点.
若规定根节点的层数为1,则深度为h的二叉树的最大结点数是(2^h)-1
对任何一棵二叉树,如果度为0其叶结点个数为n0,度为2的分支结点个数为n2,
则有 n0 = n2 +1。若规定根节点的层数为1,具有n个结点的满二叉树的深度 ,h = log2(n+1**)**。
(ps: log2(n+1)是log以2为底,n+1为对数)
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则:
① 序号为i的结点的双亲结点
- 若 i=0,i为根节点编号,无双亲节点。
- 若 i > 0,i位置节点的双亲序号:(i-1)/2;
② 序号为i的结点的孩子结点
- 若2i+1<n,左孩子序号:2i+1;
- 若2i+1>=n,则无左孩子;
- 若2i+2<n,右孩子序号:2i+2;
- 若2i+2>=n,则无右孩子;
性质选择题

2.5 二叉树的存储结构
二叉树一般可以使用两种结构存储:顺序结构、链式结构。
2.5.1 顺序存储
顺序结构存储:使用数组来存储 ,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。
而现实中使用中++只有堆才会使用数组来存储++,关于堆后面的章节会专门讲解。
二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
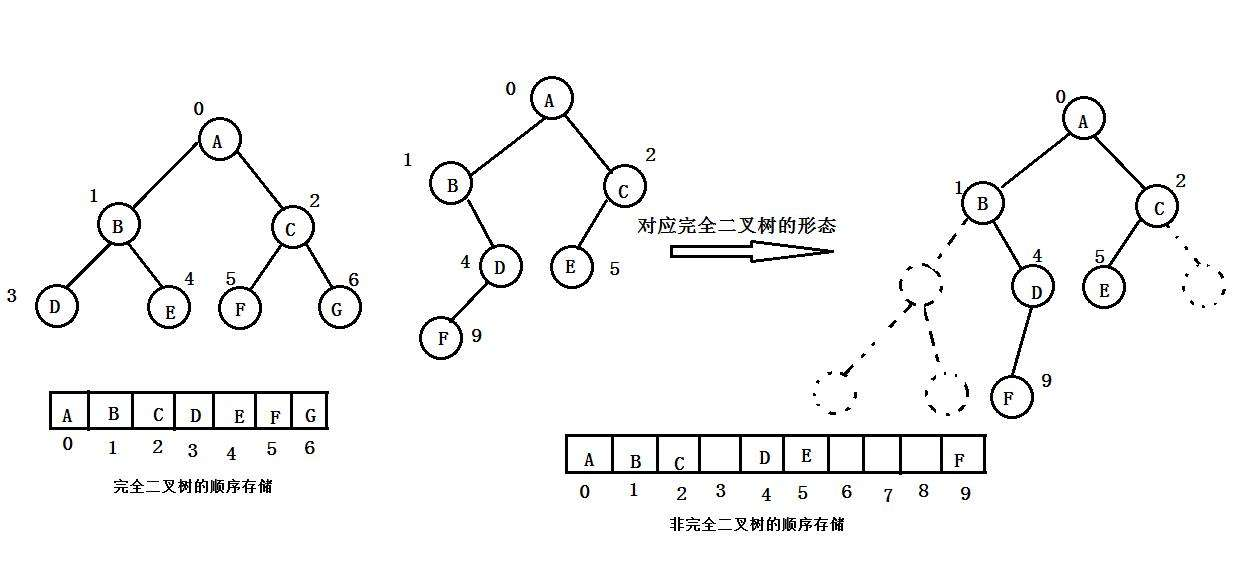
不存储父亲的下标。
而是
- 根据二叉树的结构,一层一层地,从左到右,依次存储;
- 留出对应的完全二叉树的缺失的位置的空间。
这样父亲的下标和孩子的下标就有了某种对应关系:

左孩子都是奇数位,右孩子都是偶数位*(减1除2和减2除2一样)*。
支持:父亲找孩子、孩子找父亲。
给到一个顺序存储的二叉树,还原树形结构:
先取一个*(第一层)→再取两个(第2层)→再取4个(第3层)*→再......

存的时候一层一层往里存,取的时候也一层一层往外取。
结论
数组存储只适合完全二叉树和满二叉树,用于存储普通二叉树,空间浪费大。
普通二叉树只适合链式存储。
2.5.2 链式存储
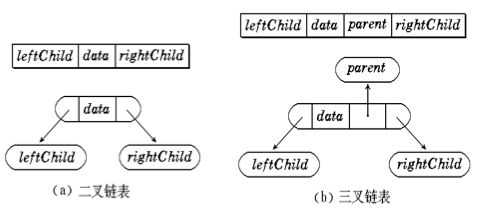
链式存储结构:是指用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。
通常的方法是:每个结点由三个域组成------数据域、左右指针域。
------左右指针分别用来给出:该结点左孩子和右孩子所在的链结点的存储地址 。
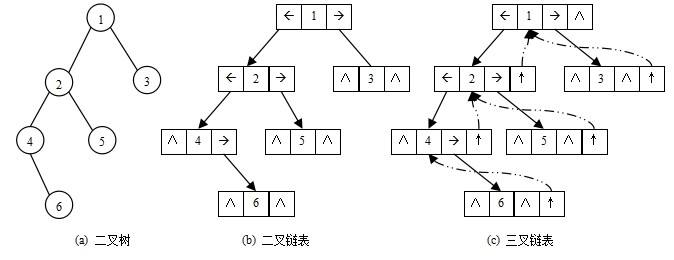
链式结构又分为:二叉链*(只能往下找)* 、三叉链*(可以往下、上找)*。
当前我们学习中一般都是二叉链,后面学到高阶数据结构如红黑树等会用到三叉链。
cpp
typedef int BTDataType;
// 二叉链
struct BinaryTreeNode
{
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点数据域
}
// 三叉链
struct BinaryTreeNode
{
struct BinTreeNode* _pParent; // 指向当前节点的双亲
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点数据域
};总结
