项目背景

- 研究动机EchoMimicV3 的开发旨在解决现有大模型视频扩散模型(Large-Scale Video Diffusion Models, LVDM)在人体动画生成中的两大问题:
- 高计算成本与慢推理速度:传统 LVDM 模型参数量庞大,导致训练和推理的计算开销高,难以在资源受限的场景中应用。
- 多任务支持不足:现有模型通常针对单一任务(如唇部同步或文本到视频)设计,缺乏统一的框架来同时处理多种动画任务(如唇部同步、文本到视频、图像到视频等)。
EchoMimicV3 的目标是通过一个轻量级模型实现"更快、更高质量、更高泛化能力、统一多任务支持"的目标,灵感来源于奥林匹克格言"更快、更高、更强------共同努力"。它通过创新的训练策略和架构设计,在保持高效的同时,提供与大模型相当的性能。
- 项目发展历程EchoMimic 系列包括以下几个版本:
- EchoMimicV1:专注于通过可编辑的地标条件实现逼真的音频驱动肖像动画,奠定了基础。
- EchoMimicV2:扩展到半身动画,简化了生成流程并提升了动画的自然度。
- EchoMimicV3:最新版本,统一了多模态(音频、图像、文本)和多任务(唇部同步、文本到视频、图像到视频等)的人体动画生成,参数量仅为1.3亿,显著提高了效率和通用性。
模型架构
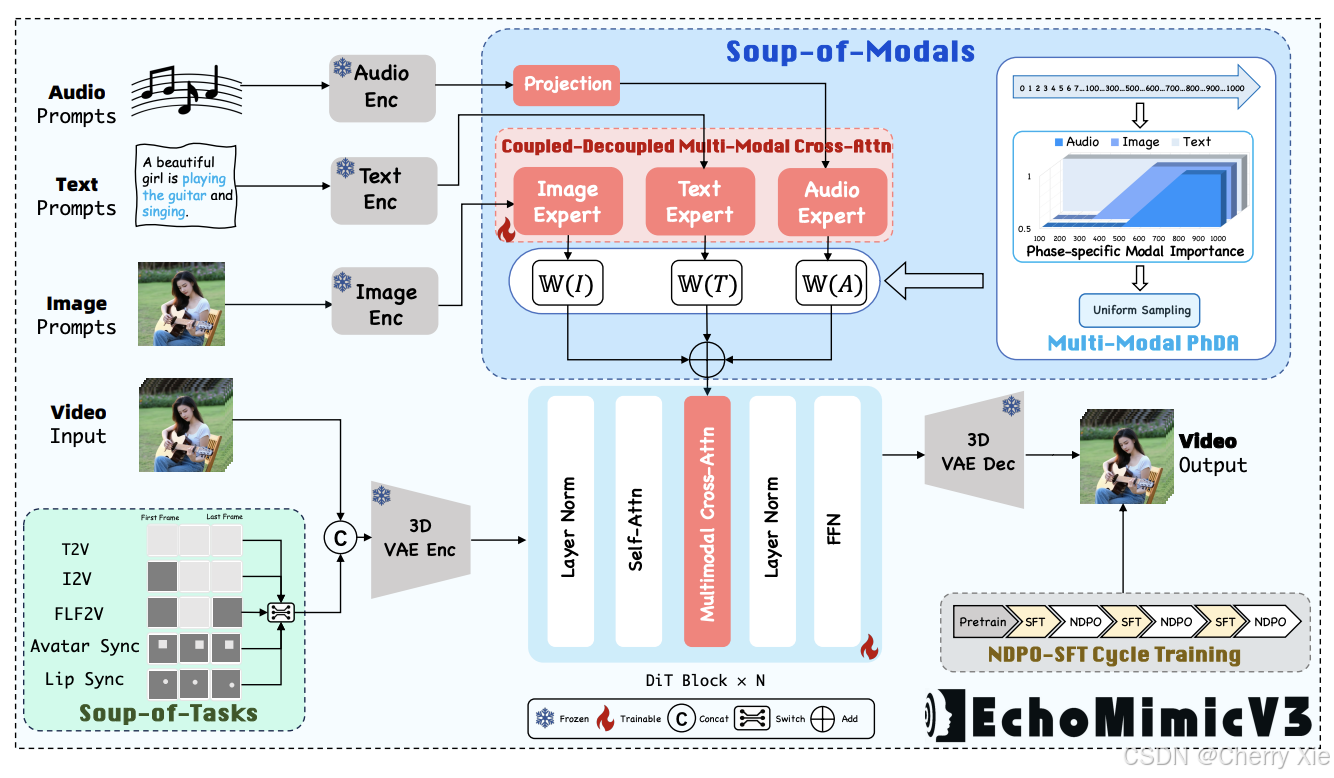
EchoMimicV3 的核心是一个基于紧凑型视频扩散模型(Compact Video Diffusion Model, CVDM)的框架,通过以下三大创新设计克服了轻量级模型在质量、泛化和多任务支持上的局限性:
- Soup-of-Tasks(任务融合)
-
设计理念:将多种动画任务(唇部同步、文本到视频、图像到视频、首末帧到视频)统一为时空重建问题,灵感来源于掩码自编码器(Masked Autoencoders, MAE)。具体而言:
- 唇部同步被视为口部空间区域的重建。
- 文本到视频(T2V)、图像到视频(I2V)、首末帧到视频(FLF2V)被视为中间时间帧的重建。
-
实现方式:通过统一的掩码序列输入(0-1掩码与视频潜在表示拼接),将不同任务的输入格式标准化。模型采用"从难到易"的训练策略,先训练复杂任务(如 I2V/FLF2V)以充分利用预训练知识,再通过指数移动平均(EMA)逐步引入简单任务(如唇部同步),实现跨任务知识迁移,避免灾难性遗忘。
- Soup-of-Modals(模态融合)
- 设计理念:通过"耦合-解耦-混合"工作流增强多模态处理能力,支持音频、图像和文本输入。
- 实现细节:耦合:共享查询 MLP 将所有模态(音频、图像、文本)耦合。
- 解耦:模态特定的交叉注意力模块为每种模态注入特定的键和值。
- 混合:引入多模态时间步相位感知动态分配(Multi-Modal Timestep Phase-aware Dynamic Allocation, Multi-Modal PhDA)机制,根据时间步阶段动态调整模态权重。例如:
- 文本条件在所有阶段保持一致重要性。
- 图像条件在早期和中期时间步阶段影响较大。
- 音频条件在初始阶段尤为重要。
通过线性组合融合模态专家分支,确保多模态输入的高效协同。
- 核心组件EchoMimicV3 的架构基于去噪 U-Net,集成了以下模块:
-
去噪 U-Net:从 Stable Diffusion v1.5 架构衍生,包含三层注意力机制:
- 参考注意力层:编码当前帧与参考图像的关系。
- 音频注意力层:捕获视觉与音频的交互。
- 时间注意力层:通过自注意力机制捕获连续帧之间的时间动态。
-
参考 U-Net:编码参考图像,保持面部身份和背景一致性,避免无关信息干扰。
-
音频编码器:基于预训练的 Wav2Vec 模型,提取音频特征并通过时间上下文连接相邻帧特征,增强唇部同步的真实性。
-
地标编码器:将面部地标图像编码为潜在空间特征,与多帧潜在表示融合,提升解剖结构和运动的精确性。
-
时间注意力层:通过重塑隐藏状态并沿时间轴应用自注意力,捕获帧间依赖关系,确保视频序列的时间一致性。
-
空间损失:在像素空间中直接学习面部结构,结合 MSE 和 LPIPS 损失,并引入时间步感知函数减少大时间步的权重,提升细节捕捉能力。
- 新颖训练与推理策略Negative DPO-SFT 循环训练:
- 提出负向直接偏好优化(Negative DPO),通过无配对的负样本拒绝不良分布,动态缓解空间不一致(如身份保持问题)和时间伪影(如颜色偏移)。该策略将负向 DPO 与监督微调(SFT)交织,简化传统 DPO 流程,同时保持高效性能。
- 相位感知负增强 CFG(PNG):在推理阶段,通过在特定扩散时间步应用加权负提示,抑制不自然的动作和颜色不一致等问题。
- 长视频 CFG:优化长视频生成(超过138帧),提升长时间序列的质量。
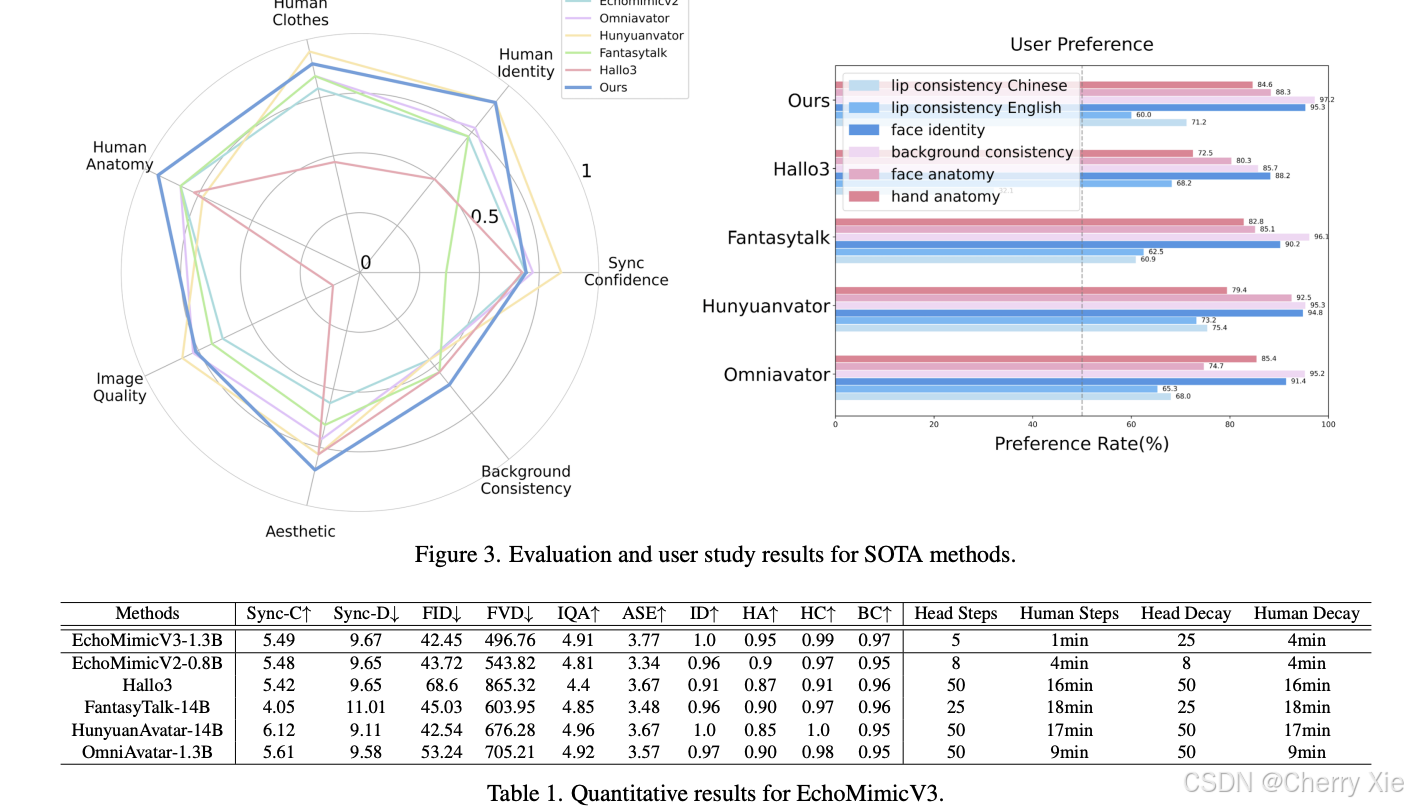
一些参数对比

看看效果
相关链接
项目地址:https://github.com/antgroup/echomimic_v3
官方地址:https://antgroup.github.io/ai/echomimic_v3/