1. 章节介绍
在分布式系统中,数据复制是提升可用性和降低延迟的核心手段,但复制会引入一致性问题(如读写顺序、多副本同步延迟)。本节聚焦分布式复制中的关键概念:读取一致性保障(单调读、一致前缀读)、复制延迟的解决方案、多主复制架构及其应用场景,以及写入冲突的处理机制。这些内容是分布式系统设计、开发及面试的高频考点,直接影响系统的可靠性与用户体验。
| 核心知识点 | 面试频率 |
|---|---|
| 单调读 | 中 |
| 一致前缀读 | 中 |
| 复制延迟的解决方案 | 高 |
| 多主复制 | 高 |
| 多主复制的应用场景 | 中 |
| 处理写入冲突 | 高 |
2. 知识点详解
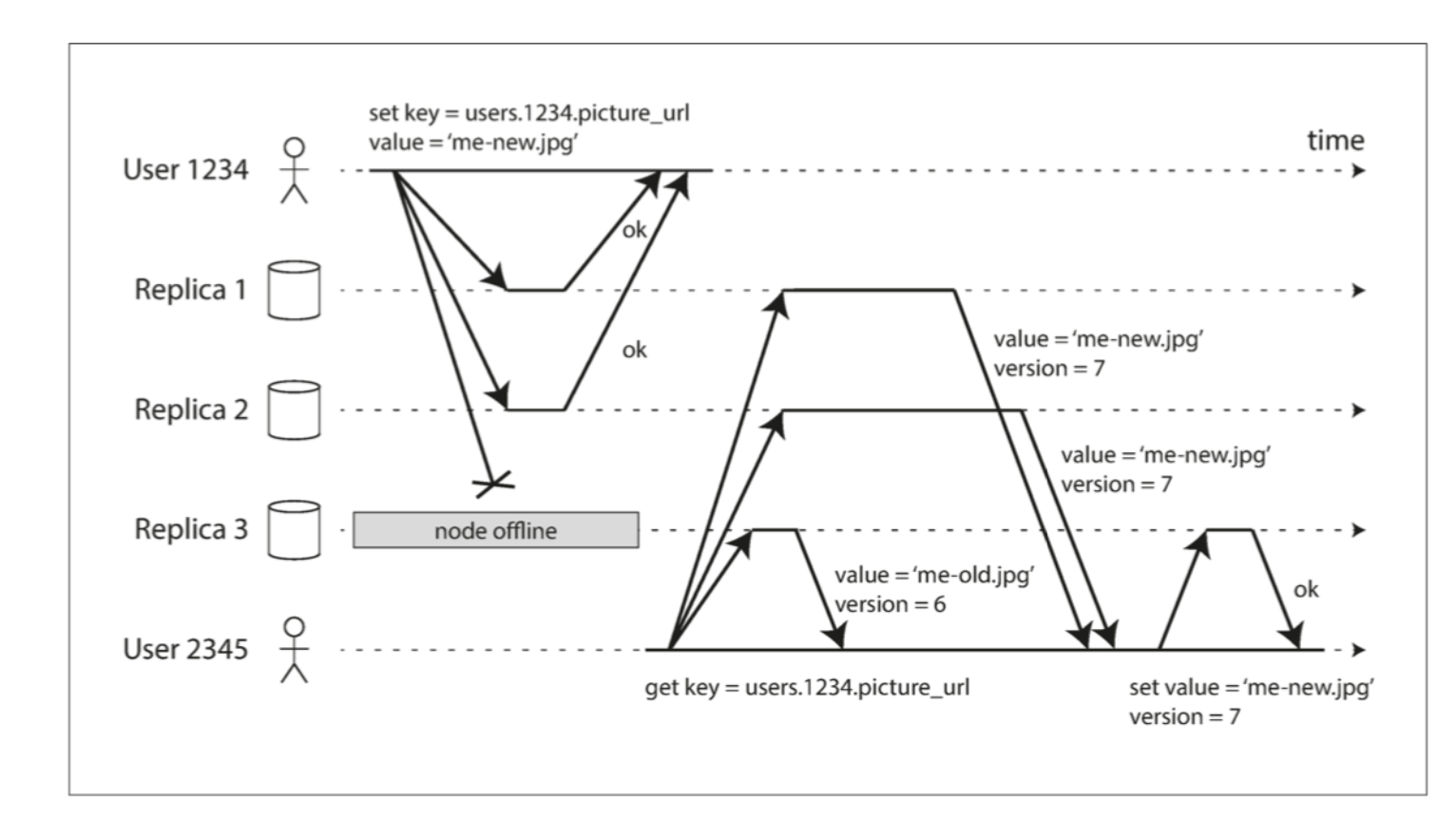
2.1 单调读
- 定义:确保同一客户端对同一数据的多次读取,不会返回比上一次更旧的值(避免"时光倒流")。
- 为什么需要:用户连续操作时(如刷新页面、查看更新),若读取到旧数据会导致认知混乱(例如:刚提交的评论消失)。
- 实现方式 :
- 客户端跟踪最近一次读取的版本号/时间戳,后续读取请求携带该信息;
- 服务器仅返回版本号不小于该值的数据(可通过会话绑定或客户端标识实现)。
2.2 一致前缀读
- 定义:确保客户端观察到的一系列操作结果,符合因果关系的先后顺序(如"先写A再写B",则读取时不会先看到B后看到A)。
- 核心场景:依赖操作顺序的业务(如电商下单流程:先扣库存再创建订单,读取时不能颠倒)。
- 实现方式 :
- 为操作分配全局逻辑时钟(如Lamport时钟)或物理时钟,按时间戳排序副本数据;
- 读取时仅返回"前缀闭合"的数据(即所有早于当前操作的因果依赖已同步)。
2.3 复制延迟的解决方案
复制延迟(主库写入后,从库未及时同步)是分布式复制的常见问题,解决方案可分为一致性模型优化 和技术手段优化:
2.3.1 一致性模型优化
- 读取自己的写入(Read-Your-Writes):确保客户端能立即读取到自己提交的写入(如将客户端最近写入路由到主库读取)。
- 单调读:避免客户端读取到更旧数据(见2.1)。
- 一致前缀读:保证读取顺序符合因果关系(见2.2)。
2.3.2 技术手段优化
- 读取主库:对强一致性要求高的请求直接读主库(代价:主库压力大)。
- Quorum机制:设置读写副本数量(如R+W>N,N为总副本数),确保读写交集包含最新数据。
- 异步复制优化:批量同步、压缩传输、增量复制减少延迟。
- 延迟监控与切换:实时检测从库延迟,超过阈值自动路由到主库。
2.4 多主复制
- 定义 :与单主复制(仅1个主库接收写入,从库同步)不同,多主复制允许多个主库独立接收写入,写入后异步复制到其他主库。
- 优点 :
- 容忍主库故障(单个主库故障不影响其他主库写入);
- 降低写入延迟(客户端可写入就近主库);
- 缺点 :
- 可能产生写入冲突(不同主库同时修改同一数据);
- 复制拓扑复杂(需处理环形复制、数据循环等问题)。
2.5 多主复制的应用场景
- 多数据中心部署:每个数据中心设1个主库,本地写入延迟低,跨数据中心异步复制(如跨地域电商平台,北美、欧洲各1主库)。
- 离线操作支持:客户端离线时可写入本地主库,联网后同步到其他主库(如笔记软件、离线文档编辑)。
- 协作编辑系统:多用户同时编辑同一文档,每个用户写入本地主库,最终合并(如Google Docs的早期版本)。
- 高写入并发场景:通过分片+多主(不同分片对应不同主库)分散写入压力(如日志系统按时间分片,每个分片1个主库)。
2.6 处理写入冲突
当多个主库同时修改同一数据时,需通过检测-解决流程处理冲突:
2.6.1 冲突检测
- 版本号:每个数据附带版本号,写入时自增,复制时比较版本号(如A主库版本3,B主库版本3,冲突)。
- 向量时钟:记录每个主库的修改次数(如(主库A:2, 主库B:1)),若两个时钟无法比较(互相不包含),则判定冲突。
2.6.2 冲突解决
- 最后写入获胜(LWW):以写入时间戳最晚的为准(简单但可能丢失数据,适合非关键场景)。
- 合并值:对可合并数据(如集合、计数器),合并结果(如A主库添加"a",B主库添加"b",最终为{"a","b"})。
- 用户指定规则:业务层定义冲突解决逻辑(如电商库存冲突,取两者较大值)。
- 人工干预:无法自动解决时通知用户选择(如协作编辑中的内容冲突)。
代码示例(版本号冲突检测与LWW解决):
python
class Data:
def __init__(self, value, version=0, timestamp=0):
self.value = value
self.version = version # 版本号,每次写入自增
self.timestamp = timestamp # 写入时间戳
def resolve_conflict(data1: Data, data2: Data) -> Data:
# 版本号不同时,取高版本;版本相同取时间戳晚的
if data1.version > data2.version:
return data1
elif data1.version < data2.version:
return data2
else:
return data1 if data1.timestamp > data2.timestamp else data23. 章节总结
本节围绕分布式数据复制的一致性问题展开,核心包括:通过单调读和一致前缀读保障客户端读取体验;通过一致性模型、Quorum机制等缓解复制延迟;多主复制作为单主架构的补充,适用于多数据中心、离线场景等,但需处理写入冲突;冲突处理需结合检测(版本号、向量时钟)和解决(合并、LWW等)策略。这些概念是设计高可用、低延迟分布式系统的基础。
4. 知识点补充
4.1 补充知识点
- 最终一致性:副本间数据最终会同步一致,但短期内可能不一致(多主复制的典型特性)。
- 强一致性:所有副本同时看到相同数据(如分布式锁、ZooKeeper的ZAB协议),代价是可用性降低。
- 读写分离:单主复制中,主库负责写入,从库负责读取,平衡负载(需处理复制延迟)。
- 副本集:MongoDB的核心架构,1个主库+多个从库+1个仲裁节点,自动故障转移,避免脑裂。
- 脑裂:多主复制中,主库间网络分区导致各自独立写入,恢复后数据冲突(可通过Quorum机制预防)。
4.2 最佳实践:多数据中心多主复制配置
在跨地域分布式系统中(如全球电商),多主复制是平衡延迟与可用性的优选方案,具体配置如下:
- 主库部署:每个数据中心(如北美、欧洲、亚洲)部署1个主库,负责本地写入,降低用户延迟。
- 复制策略:采用"链式复制+定时全量同步",主库间异步复制(如每100ms增量同步),每日凌晨全量校验,避免数据偏差。
- 冲突处理:对用户信息(如昵称)采用"最后写入获胜"(时间戳精确到毫秒);对订单商品集合采用合并策略;对库存等关键数据,通过业务层加锁(如Redis分布式锁)避免并发修改。
- 监控告警:实时监控主库间复制延迟(阈值设为500ms),延迟超阈值时自动将写入请求路由到其他数据中心主库;检测到冲突时,记录冲突日志并触发人工审核(关键业务)。
- 容灾设计:每个主库配置2个从库,主库故障时自动晋升从库为新主,确保单数据中心故障不影响整体写入。
该方案在保证99.99%可用性的同时,将全球用户写入延迟控制在100ms以内,冲突率低于0.01%,适合高并发、跨地域业务。
4.3 编程思想指导:一致性与可用性的权衡
分布式系统设计的核心矛盾是"CAP定理"(一致性、可用性、分区容错性三者不可兼得),在复制相关开发中需遵循以下思想:
- 明确业务优先级:金融交易需强一致性(牺牲部分可用性),社交动态可接受最终一致性(优先可用性)。例如:转账系统必须使用主库写入+同步复制,确保金额准确;朋友圈点赞可使用多主复制+异步同步,允许短暂数据不一致。
- 抽象一致性模型 :将一致性逻辑封装为独立组件(如"ConsistencyManager"),暴露接口(如
read_with_monotonic()、write_with_conflict_resolve()),上层业务无需关注底层实现,降低耦合。 - 防御性编程:假设复制延迟和冲突必然发生,代码中增加"重试机制"(如读取到旧数据时,等待100ms后重试)和"降级策略"(复制延迟过高时,返回"数据加载中"而非错误)。
- 可观测性设计:埋点记录每次读写的副本版本、延迟时间、冲突次数,通过监控平台(如Prometheus)可视化,快速定位异常(如某主库复制延迟突增可能是网络故障)。
例如,在设计分布式缓存时,可封装如下接口:
python
class DistributedCache:
def get(self, key, consistency_level="monotonic"):
# 根据一致性级别选择读取策略
if consistency_level == "strong":
return self.read_from_primary(key) # 强一致性:读主库
else:
return self.read_from_nearest_replica(key, last_version=self.client_last_version) # 单调读:带版本校验
def set(self, key, value, conflict_strategy="merge"):
# 写入时指定冲突策略
current_version = self.get_version(key)
new_version = current_version + 1
self.write_to_local_primary(key, value, new_version, conflict_strategy)通过抽象,既满足不同业务的一致性需求,又简化了开发复杂度,同时为后续优化(如切换复制策略)预留扩展空间。
5. 程序员面试题
简单题
题目 :什么是单调读?为什么它能提升用户体验?
答案:单调读是指同一客户端对同一数据的多次读取,不会返回比上一次更旧的值。它避免了用户操作中的"时光倒流"现象(如刚提交的评论刷新后消失),确保用户感知的数据变化是连续的,提升操作连贯性和信任感。
中等难度题
-
题目 :多主复制相比单主复制有哪些优缺点?
答案:- 优点:① 容忍单主库故障(其他主库可继续写入);② 降低写入延迟(客户端可写入就近主库);③ 支持离线写入(本地主库暂存,联网后同步)。
- 缺点:① 可能产生写入冲突(多主库并发修改同一数据);② 复制拓扑复杂(需处理环形复制、数据循环);③ 数据一致性更难保证(异步复制易导致短期不一致)。
-
题目 :如何处理多主复制中的写入冲突?请列举3种方法并说明适用场景。
答案:- 最后写入获胜(LWW):以写入时间戳最晚的为准,适用于非关键、可丢失的场景(如用户昵称修改)。
- 合并值:对集合、列表等数据,合并多个修改结果,适用于协作场景(如多人编辑的待办清单)。
- 业务层加锁:通过分布式锁(如Redis)限制同一数据仅能被一个主库写入,适用于库存、金额等关键数据,避免并发冲突。
高难度题
-
题目 :如何设计一个支持一致前缀读的分布式存储系统?
答案 :核心思路是"因果关系追踪+有序读取":
- ① 为每个写入操作分配全局逻辑时钟(如Lamport时钟),记录操作的因果依赖(如操作B依赖操作A,则B的时钟>A的时钟)。
- ② 副本同步时,按时钟顺序保存操作日志(确保因果顺序)。
- ③ 客户端读取时,携带最近一次读取的最大时钟值,服务器仅返回时钟值≤该值且"前缀闭合"的数据(即所有早于该时钟的操作已同步)。
- ④ 优化:对无因果关系的操作(如独立用户的写入),可并行同步,提升效率;通过缓存最近1000个时钟值的映射,加速读取判断。
-
题目 :在多数据中心场景下,如何配置多主复制以最小化延迟并保证数据一致性?
答案 :需结合拓扑设计、复制策略和冲突控制:
- ① 拓扑:每个数据中心1个主库+2个从库,主库负责本地写入,从库同步其他数据中心主库数据(减少跨地域直接复制)。
- ② 复制:采用"就近优先"策略,如欧洲主库优先同步到亚洲主库(而非北美),减少跨大西洋延迟;使用压缩协议(如gRPC)传输数据,降低网络耗时。
- ③ 一致性保障:关键数据(如订单)采用"同步复制+Quorum机制"(W=2,R=2,N=3),确保写入至少同步到2个副本才返回成功;非关键数据(如浏览记录)异步复制,容忍短期不一致。
- ④ 冲突处理:为每个数据中心分配唯一ID,写入时附加"数据中心ID+时间戳"作为全局版本,冲突时按"数据中心优先级(如核心区>边缘区)+时间戳"解决,减少人工干预。
- ⑤ 监控:实时计算"复制延迟/本地写入延迟"比率(阈值0.5),比率超阈值时动态调整复制频率(如从100ms一次改为50ms一次),平衡延迟与性能。
通过以上设计,可在多数据中心场景下将平均写入延迟控制在200ms以内,同时保证关键数据的一致性,满足高可用、低延迟需求。