yolov11 标注 部署 训练 全流程
数据采集和标注
数据采集最好用实际用到的摄像头采集的数据。
数据标注,对于目标检测的数据标注一般用labelimg,对于图像分割的数据集的标注我一般用ISAT。
数据采集如下:

labelimg
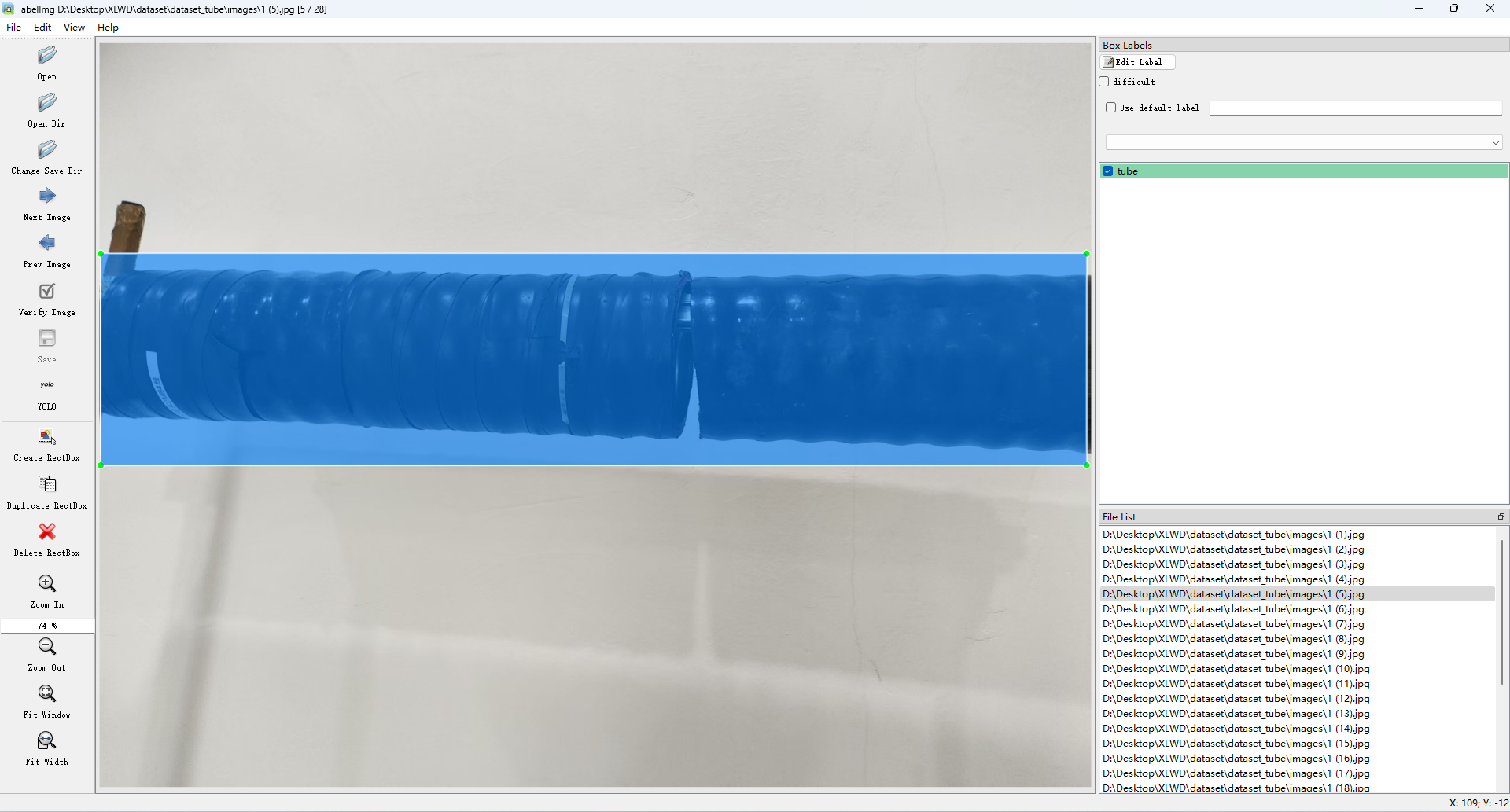
快捷键:W 开始标注,就是绘制矩形框;Crtl + S 保存标注
ISAT
git下载源码到本地,直接运行即可
bash
python main.py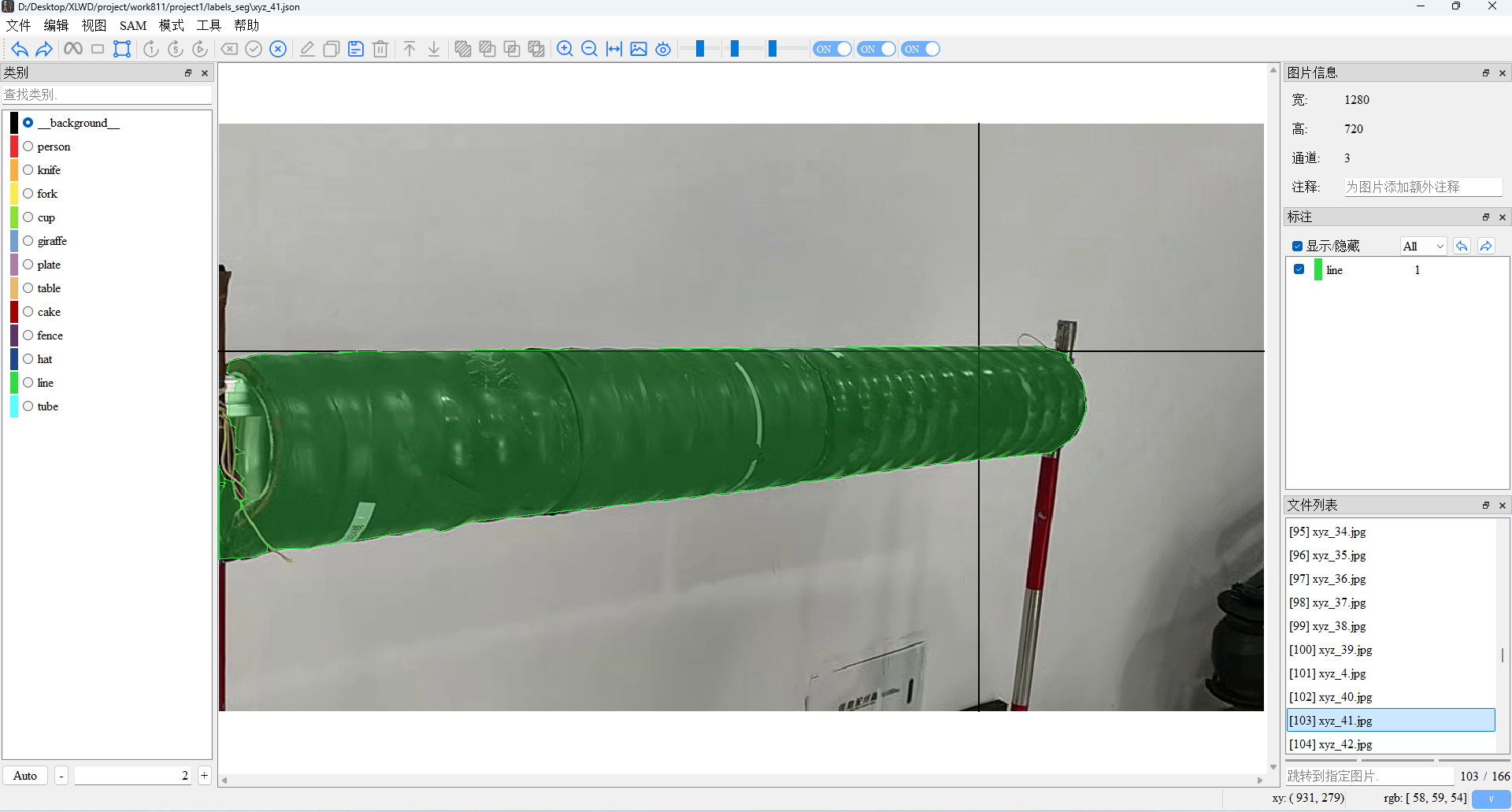
可以自己去添加标签,然后点击SAM2加载模型,利用SAM2进行相对自动的标注,效率提高。
标签格式如下:
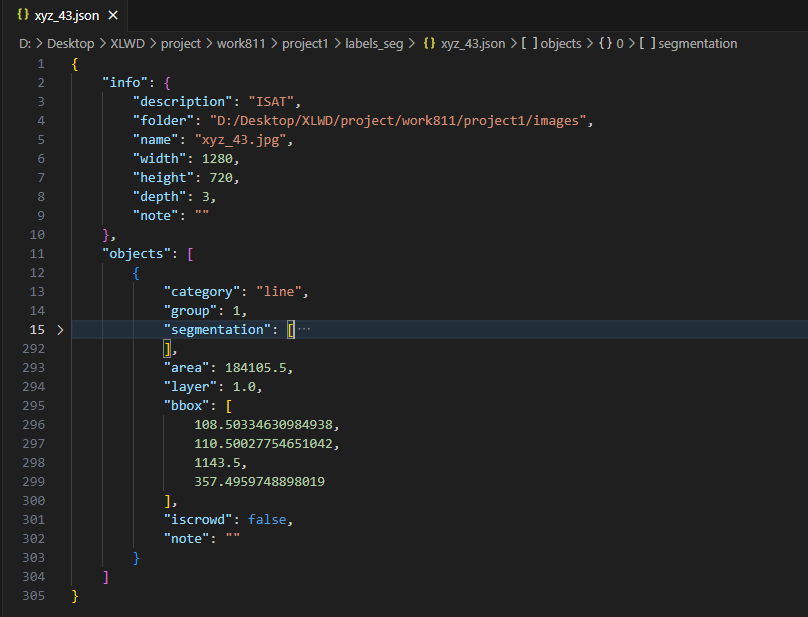
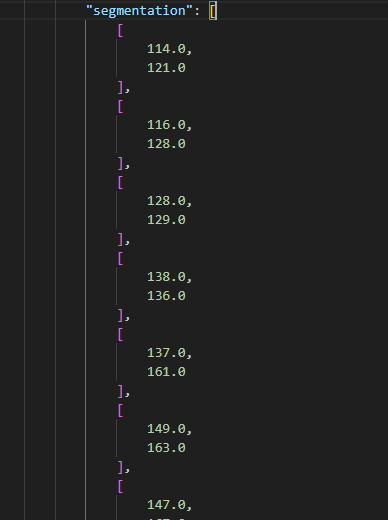
yolov11 分割标签的格式是
分割数据集中单行的格式如下:
bash
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>这是一个 YOLO 数据集格式的示例,其中单张图像包含两个对象,分别由一个 3 点分割和一个 5 点分割组成。
bash
0 0.681 0.485 0.670 0.487 0.676 0.487
1 0.504 0.000 0.501 0.004 0.498 0.004 0.493 0.010 0.492 0.0104
ISAT有他自己的格式转换器,也可以自己写一个脚本进行格式转换。
python
import json
import os
import cv2
# json to txt
def json_to_txt(json_filepath,image_filepath,txt_savapath):
json_files=[i for i in os.listdir(json_filepath) if i.endswith("json")]
for i in json_files:
#新建一个数据list
info_list=[]
json_path=os.path.join(json_filepath,i)
with open(json_path,"r") as r:
json_info=json.load(r)
r.close()
# imagePath=json_info["imagePath"]
imagePath= os.path.splitext(i)[0] + ".jpg"
print(imagePath)
#得到图像宽高
h,w=cv2.imread(os.path.join(image_filepath,imagePath)).shape[:2]
shapes=json_info["shapes"]
for shape in shapes:#每一个区域
row_str=""#初始化一行
label=shape["label"]
row_str+=label
points=shape["points"]
for point in points:
x=round(float(point[0])/w,6)#小数保留6位
y = round(float(point[1]) / h, 6) # 小数保留6位
row_str+=" "+str(x)+" "+str(y)
row_str+="\n"
info_list.append(row_str)
with open(os.path.join(txt_savapath,i.replace(".json",".txt")),"w") as w:
w.writelines(info_list)
w.close()
print(f"已保存文件{i.replace('.json','.txt')}")
# 将标签替换为对应的数字
def txt1_txt2(classtxt_filepath, txt_folder_path):
# 读取标签与数字的对应关系
label_to_number = {}
with open(classtxt_filepath, 'r') as file:
for line in file:
number, label = line.strip().split()
label_to_number[label] = number
# 遍历文件夹中的所有 .txt 文件
for filename in os.listdir(txt_folder_path):
if filename.endswith('.txt'):
file_path = os.path.join(txt_folder_path, filename)
# 读取需要替换标签的文件内容
with open(file_path, 'r') as file:
lines = file.readlines()
# 替换标签
new_lines = []
for line in lines:
for label, number in label_to_number.items():
line = line.replace(label, number)
new_lines.append(line)
# 将替换后的内容写回原文件
with open(file_path, 'w') as file:
file.writelines(new_lines)
from collections import defaultdict
if __name__ == "__main__":
# json_filepath=r"D:\SSJ\Work\ultralytics-main\datasets\picture\json"#包含json文件的目录
# image_filepath=r"D:\SSJ\Work\ultralytics-main\datasets\picture"#包含原图文件的目录
# txt_savapath=r"D:\SSJ\Work\ultralytics-main\datasets\picture\labels"#txt保存目录
# json_to_txt(json_filepath,image_filepath,txt_savapath)
# # 调用函数
# classtxt_filepath = r'D:\SSJ\Work\ultralytics-main\datasets\picture\classes.txt' # 原始文本文件路径
# txt_filepath = r"D:\SSJ\Work\ultralytics-main\datasets\picture\labels" # 替换后的文本文件路径
# txt1_txt2(classtxt_filepath, txt_filepath)数据增强
只针对目标检测的数据集,不针对图像分割的数据集。
数据增强+划分数据集的脚本如下:augment_and_split.py
bash
# -*- coding: utf-8 -*-
"""
数据增强和数据集划分一体化脚本
功能:对目标检测数据集进行数据增强,然后自动划分训练集、验证集和测试集
"""
import torch
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
import os
import random
import shutil
import argparse
# 设置随机种子
random.seed(42)
class DataAugmentationOnDetection:
def __init__(self):
super(DataAugmentationOnDetection, self).__init__()
def resize_keep_ratio(self, image, boxes, target_size):
"""
参数类型: image:Image.open(path), boxes:Tensor, target_size:int
功能:将图像缩放到size尺寸,调整相应的boxes,同时保持长宽比(最长的边是target size
"""
old_size = image.size[0:2] # 原始图像大小
# 取最小的缩放比例
ratio = min(float(target_size) / (old_size[i]) for i in range(len(old_size)))
new_size = tuple([int(i * ratio) for i in old_size])
# boxes 不用变化,因为是等比例变化
return image.resize(new_size, Image.BILINEAR), boxes
def resizeDown_keep_ratio(self, image, boxes, target_size):
""" 与上面的函数功能类似,但它只降低图片的尺寸,不会扩大图片尺寸"""
old_size = image.size[0:2]
ratio = min(float(target_size) / (old_size[i]) for i in range(len(old_size)))
ratio = min(ratio, 1)
new_size = tuple([int(i * ratio) for i in old_size])
return image.resize(new_size, Image.BILINEAR), boxes
def resize(self, img, boxes, size):
return img.resize((size, size), Image.BILINEAR), boxes
def random_flip_horizon(self, img, boxes, h_rate=1):
"""随机水平翻转"""
if np.random.random() < h_rate:
transform = transforms.RandomHorizontalFlip(p=1)
img = transform(img)
if len(boxes) > 0:
x = 1 - boxes[:, 1]
boxes[:, 1] = x
return img, boxes
def random_flip_vertical(self, img, boxes, v_rate=1):
"""随机垂直翻转"""
if np.random.random() < v_rate:
transform = transforms.RandomVerticalFlip(p=1)
img = transform(img)
if len(boxes) > 0:
y = 1 - boxes[:, 2]
boxes[:, 2] = y
return img, boxes
def center_crop(self, img, boxes, target_size=None):
"""中心裁剪"""
w, h = img.size
size = min(w, h)
if len(boxes) > 0:
# 转换到xyxy格式
label = boxes[:, 0].reshape([-1, 1])
x_, y_, w_, h_ = boxes[:, 1], boxes[:, 2], boxes[:, 3], boxes[:, 4]
x1 = (w * x_ - 0.5 * w * w_).reshape([-1, 1])
y1 = (h * y_ - 0.5 * h * h_).reshape([-1, 1])
x2 = (w * x_ + 0.5 * w * w_).reshape([-1, 1])
y2 = (h * y_ + 0.5 * h * h_).reshape([-1, 1])
boxes_xyxy = torch.cat([x1, y1, x2, y2], dim=1)
# 边框转换
if w > h:
boxes_xyxy[:, [0, 2]] = boxes_xyxy[:, [0, 2]] - (w - h) / 2
else:
boxes_xyxy[:, [1, 3]] = boxes_xyxy[:, [1, 3]] - (h - w) / 2
in_boundary = [i for i in range(boxes_xyxy.shape[0])]
for i in range(boxes_xyxy.shape[0]):
# 判断x是否超出界限
if (boxes_xyxy[i, 0] < 0 and boxes_xyxy[i, 2] < 0) or (boxes_xyxy[i, 0] > size and boxes_xyxy[i, 2] > size):
in_boundary.remove(i)
# 判断y是否超出界限
elif (boxes_xyxy[i, 1] < 0 and boxes_xyxy[i, 3] < 0) or (boxes_xyxy[i, 1] > size and boxes_xyxy[i, 3] > size):
in_boundary.append(i)
boxes_xyxy = boxes_xyxy[in_boundary]
boxes = boxes_xyxy.clamp(min=0, max=size).reshape([-1, 4])
label = label[in_boundary]
# 转换到YOLO格式
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
xc = ((x1 + x2) / (2 * size)).reshape([-1, 1])
yc = ((y1 + y2) / (2 * size)).reshape([-1, 1])
wc = ((x2 - x1) / size).reshape([-1, 1])
hc = ((y2 - y1) / size).reshape([-1, 1])
boxes = torch.cat([xc, yc, wc, hc], dim=1)
# 图像转换
transform = transforms.CenterCrop(size)
img = transform(img)
if target_size:
img = img.resize((target_size, target_size), Image.BILINEAR)
if len(boxes) > 0:
return img, torch.cat([label.reshape([-1, 1]), boxes], dim=1)
else:
return img, boxes
def random_bright(self, img, u=120, p=1):
"""随机亮度变换"""
if np.random.random() < p:
alpha = np.random.uniform(-u, u) / 255
img += alpha
img = img.clamp(min=0.0, max=1.0)
return img
def random_contrast(self, img, lower=0.5, upper=1.5, p=1):
"""随机增强对比度"""
if np.random.random() < p:
alpha = np.random.uniform(lower, upper)
img *= alpha
img = img.clamp(min=0, max=1.0)
return img
def random_saturation(self, img, lower=0.5, upper=1.5, p=1):
"""随机饱和度变换"""
if np.random.random() < p:
alpha = np.random.uniform(lower, upper)
img[1] = img[1] * alpha
img[1] = img[1].clamp(min=0, max=1.0)
return img
def add_gasuss_noise(self, img, mean=0, std=0.1):
"""添加高斯噪声"""
noise = torch.normal(mean, std, img.shape)
img += noise
img = img.clamp(min=0, max=1.0)
return img
def add_salt_noise(self, img):
"""添加盐噪声"""
noise = torch.rand(img.shape)
alpha = np.random.random() / 5 + 0.7
img[noise[:, :, :] > alpha] = 1.0
return img
def add_pepper_noise(self, img):
"""添加椒噪声"""
noise = torch.rand(img.shape)
alpha = np.random.random() / 5 + 0.7
img[noise[:, :, :] > alpha] = 0
return img
def get_image_list(image_path):
"""根据图片文件,查找所有图片并返回列表"""
files_list = []
for root, sub_dirs, files in os.walk(image_path):
for special_file in files:
if special_file.lower().endswith(('.jpg', '.jpeg', '.png', '.bmp')):
files_list.append(special_file)
return files_list
def get_label_file(label_path, image_name):
"""根据图片信息,查找对应的label"""
# 获取不带扩展名的文件名
base_name = os.path.splitext(image_name)[0]
fname = os.path.join(label_path, base_name + ".txt")
data2 = []
if not os.path.exists(fname):
return data2
if os.path.getsize(fname) == 0:
return data2
else:
with open(fname, 'r', encoding='utf-8') as infile:
for line in infile:
data_line = line.strip("\n").split()
data2.append([float(i) for i in data_line])
return data2
def save_Yolo(img, boxes, save_path, prefix, image_name):
"""保存增强后的图像和标签"""
if not os.path.exists(save_path):
os.makedirs(save_path)
images_dir = os.path.join(save_path, "images")
labels_dir = os.path.join(save_path, "labels")
if not os.path.exists(images_dir):
os.makedirs(images_dir)
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
try:
# 保存图像
img.save(os.path.join(images_dir, prefix + image_name))
# 保存标签
label_name = prefix + os.path.splitext(image_name)[0] + ".txt"
with open(os.path.join(labels_dir, label_name), 'w', encoding="utf-8") as f:
if len(boxes) > 0:
for data in boxes:
str_in = ""
for i, a in enumerate(data):
if i == 0:
str_in += str(int(a))
else:
str_in += " " + str(float(a))
f.write(str_in + '\n')
except Exception as e:
print(f"ERROR: {image_name} is bad. Error: {e}")
def run_augmentation(image_path, label_path, save_path):
"""运行数据增强"""
print("开始数据增强...")
image_list = get_image_list(image_path)
print(f"找到 {len(image_list)} 张图片")
DAD = DataAugmentationOnDetection()
for i, image_name in enumerate(image_list):
print(f"处理进度: {i+1}/{len(image_list)} - {image_name}")
try:
img = Image.open(os.path.join(image_path, image_name))
boxes = get_label_file(label_path, image_name)
boxes = torch.tensor(boxes)
# 执行数据增强
# 1. 水平翻转
t_img, t_boxes = DAD.random_flip_horizon(img, boxes.clone())
save_Yolo(t_img, t_boxes, save_path, prefix="fh_", image_name=image_name)
# 2. 垂直翻转
t_img, t_boxes = DAD.random_flip_vertical(img, boxes.clone())
save_Yolo(t_img, t_boxes, save_path, prefix="fv_", image_name=image_name)
# 3. 中心裁剪
t_img, t_boxes = DAD.center_crop(img, boxes.clone(), 1024)
save_Yolo(t_img, t_boxes, save_path, prefix="cc_", image_name=image_name)
# 4. 图像变换(需要转换为tensor)
to_tensor = transforms.ToTensor()
to_image = transforms.ToPILImage()
img_tensor = to_tensor(img)
# 亮度变化
t_img = DAD.random_bright(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="rb_", image_name=image_name)
# 对比度变化
t_img = DAD.random_contrast(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="rc_", image_name=image_name)
# 饱和度变化
t_img = DAD.random_saturation(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="rs_", image_name=image_name)
# 高斯噪声
t_img = DAD.add_gasuss_noise(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="gn_", image_name=image_name)
# 盐噪声
t_img = DAD.add_salt_noise(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="sn_", image_name=image_name)
# 椒噪声
t_img = DAD.add_pepper_noise(img_tensor.clone())
save_Yolo(to_image(t_img), boxes, save_path, prefix="pn_", image_name=image_name)
except Exception as e:
print(f"处理 {image_name} 时出错: {e}")
continue
print("数据增强完成!")
def split_dataset(aug_path, save_dir):
"""划分数据集为训练集、验证集和测试集"""
print("开始划分数据集...")
# 创建文件夹
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_val_path = os.path.join(images_dir, 'val')
img_test_path = os.path.join(images_dir, 'test')
label_train_path = os.path.join(labels_dir, 'train')
label_val_path = os.path.join(labels_dir, 'val')
label_test_path = os.path.join(labels_dir, 'test')
# 创建目录
for path in [images_dir, labels_dir, img_train_path, img_val_path, img_test_path,
label_train_path, label_val_path, label_test_path]:
os.makedirs(path, exist_ok=True)
# 数据集划分比例:训练集80%,验证集15%,测试集5%
train_percent = 0.8
val_percent = 0.15
test_percent = 0.05
# 获取增强后的标签文件列表
aug_labels_dir = os.path.join(aug_path, 'labels')
total_txt = [f for f in os.listdir(aug_labels_dir) if f.endswith('.txt')]
num_txt = len(total_txt)
if num_txt == 0:
print("警告:没有找到标签文件!")
return
print(f"总共找到 {num_txt} 个标签文件")
# 计算各集合的数量
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
# 随机打乱文件列表
random.shuffle(total_txt)
# 划分数据集
train_files = total_txt[:num_train]
val_files = total_txt[num_train:num_train + num_val]
test_files = total_txt[num_train + num_val:]
print(f"训练集: {len(train_files)}, 验证集: {len(val_files)}, 测试集: {len(test_files)}")
# 复制文件到对应目录
def copy_files(file_list, img_dst, label_dst):
for txt_file in file_list:
base_name = os.path.splitext(txt_file)[0]
# 复制标签文件
src_label = os.path.join(aug_labels_dir, txt_file)
dst_label = os.path.join(label_dst, txt_file)
shutil.copy2(src_label, dst_label)
# 复制对应的图像文件
# 查找对应的图像文件(可能有多重前缀)
aug_images_dir = os.path.join(aug_path, 'images')
for img_file in os.listdir(aug_images_dir):
if img_file.startswith(base_name) or base_name in img_file:
src_img = os.path.join(aug_images_dir, img_file)
dst_img = os.path.join(img_dst, img_file)
shutil.copy2(src_img, dst_img)
break
# 复制训练集
copy_files(train_files, img_train_path, label_train_path)
print(f"训练集文件复制完成: {len(os.listdir(img_train_path))} 张图片, {len(os.listdir(label_train_path))} 个标签")
# 复制验证集
copy_files(val_files, img_val_path, label_val_path)
print(f"验证集文件复制完成: {len(os.listdir(img_val_path))} 张图片, {len(os.listdir(label_val_path))} 个标签")
# 复制测试集
copy_files(test_files, img_test_path, label_test_path)
print(f"测试集文件复制完成: {len(os.listdir(img_test_path))} 张图片, {len(os.listdir(label_test_path))} 个标签")
print("数据集划分完成!")
def main(image_path, label_path):
"""主函数:执行数据增强和数据集划分"""
print("=" * 50)
print("数据增强和数据集划分一体化脚本")
print("=" * 50)
# 获取上级目录
parent_dir = os.path.dirname(label_path)
print(f"上级目录: {parent_dir}")
# 创建aug文件夹路径(数据增强结果)
aug_path = os.path.join(parent_dir, 'aug')
print(f"数据增强结果保存路径: {aug_path}")
# 创建end文件夹路径(划分后的数据集)
end_path = os.path.join(parent_dir, 'end')
print(f"划分后数据集保存路径: {end_path}")
# 检查输入路径
if not os.path.exists(image_path):
print(f"错误:图像路径不存在: {image_path}")
return
if not os.path.exists(label_path):
print(f"错误:标签路径不存在: {label_path}")
return
# 第一步:执行数据增强
print("\n第一步:执行数据增强...")
run_augmentation(image_path, label_path, aug_path)
# 第二步:划分数据集
print("\n第二步:划分数据集...")
split_dataset(aug_path, end_path)
print("\n" + "=" * 50)
print("所有操作完成!")
print(f"数据增强结果保存在: {aug_path}")
print(f"划分后的数据集保存在: {end_path}")
print("=" * 50)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='数据增强和数据集划分一体化脚本')
parser.add_argument('--image-path', type=str,
default='D:\Desktop\XLWD\dataset\dataset_tube\images',
help='图像文件夹路径')
parser.add_argument('--label-path', type=str,
default='D:\Desktop\XLWD\dataset\dataset_tube\label',
help='标签文件夹路径')
args = parser.parse_args()
# 执行主函数
main(args.image_path, args.label_path) 模型训练
tube.yaml
bash
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Crack-seg dataset by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/segment/crack-seg/
# Example usage: yolo train data=crack-seg.yaml
# parent
# ├── ultralytics
# └── datasets
# └── crack-seg ← downloads here (91.2 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/Desktop/XLWD/dataset/dataset_tube/end # dataset root dir
train: images/train # train images (relative to 'path') 3717 images
val: images/val # val images (relative to 'path') 112 images
test: # test images (optional)
# test: test/images # test images (relative to 'path') 200 images
nc: 1
# Classes
names:
0: tube训练脚本
bash
from ultralytics import YOLO
# import os
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# # 消除异步性,但是会带来性能的损失
if __name__ == '__main__':
# Load a COCO-pretrained YOLO11n model
# model = YOLO("yolo11n.pt")
model = YOLO(r"D:/SSJ/Work/ultralytics-main/yolo11n.pt",task='detect') # yolo11n-seg.pt segment
# model = YOLO(r"D:/SSJ/Work/ultralytics-main/yolo11n.pt",task='detect')
# model = YOLO(r"D:/SSJ/Work/ultralytics-main/runs/detect/train30/weights/best.pt",task='detect')
# # Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="D:/Desktop/XLWD/dataset/dataset_tube/end/tube.yaml", epochs=100, batch=64,device=0,workers = 2)# imgsz=320,
目标检测训练结果一般保存在runs\detect里面
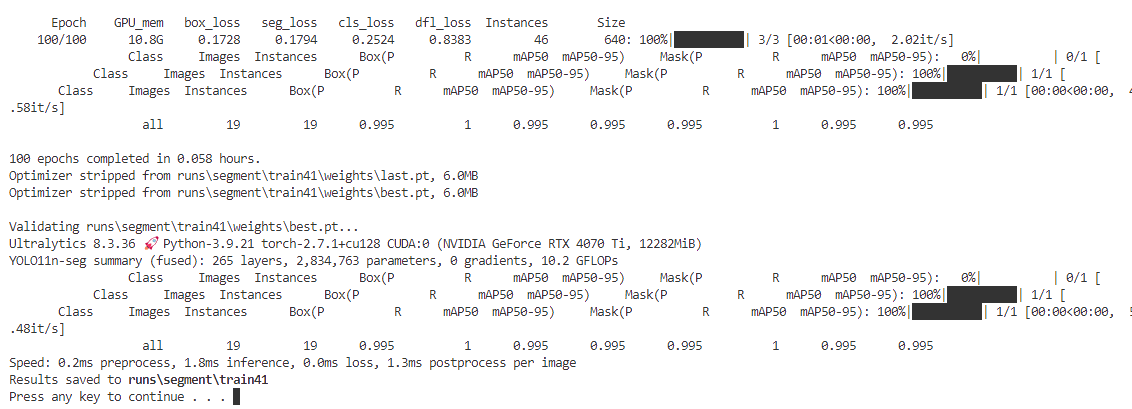
图像分割训练结果一般保存在runs\segment里面
模型测试
track_and_save_video.py
bash
import cv2
from ultralytics import YOLO
def yolo_pre():
yolo=YOLO(r'D:\SSJ\Work\ultralytics-main\runs\segment\train41\weights\best.pt')
video_path=r"D:\Desktop\XLWD\dataset\dataset_tube\xyz.mp4" #检测视频的地址
cap = cv2.VideoCapture(video_path) # 创建一个 VideoCapture 对象,用于从视频文件中读取帧
# 获取视频帧的维度
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# 创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(r"D:\Desktop\XLWD\dataset\dataset_tube\xyz-segment.mp4", fourcc, 20.0, (frame_width, frame_height)) #保存检测后视频的地址
while cap.isOpened():
status, frame = cap.read() # 使用 cap.read() 从视频中读取每一帧
if not status:
break
result = yolo.track(source=frame,conf=0.5,data = "wire-seg.yaml")
# for res in result:
# boxes = res.boxes # Boxes object for bounding box outputs
# for i, box in enumerate(boxes):
# x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()
# id = box.id
# print(id)
result = result[0]
anno_frame = result.plot(boxes=True,labels=True)
cv2.imshow('行人', anno_frame)
out.write(anno_frame) #写入保存
# 注释的框架是通过调用 result.plot() 获得的,它会在框架上绘制边界框和标签。
# 带注释的框架使用 cv2.imshow() 窗口名称"行人"显示。
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
print('保存完成')
video_yolo_path=r'D:\Desktop\XLWD\dataset\dataset_tube\xyz-segment.mp4'
return video_yolo_path
if __name__ == "__main__":
yolo_pre()模型部署
主要示例为部署在jetson nano上做测试;
打开wifi,MobaXterm and RealVNC 远程连接 jetson nano 进行开发。
pt_to_onnx.py
bash
from ultralytics import YOLO
# Load a model
model = YOLO(r"D:\Desktop\XLWD\dataset\dataset_tube\tube-segment.pt",task='segment') # load a custom trained
# Export the model
model.export(format='onnx',imgsz = 640)#engineonnx 转 engine 需要在jetson nano 上完成:
bash
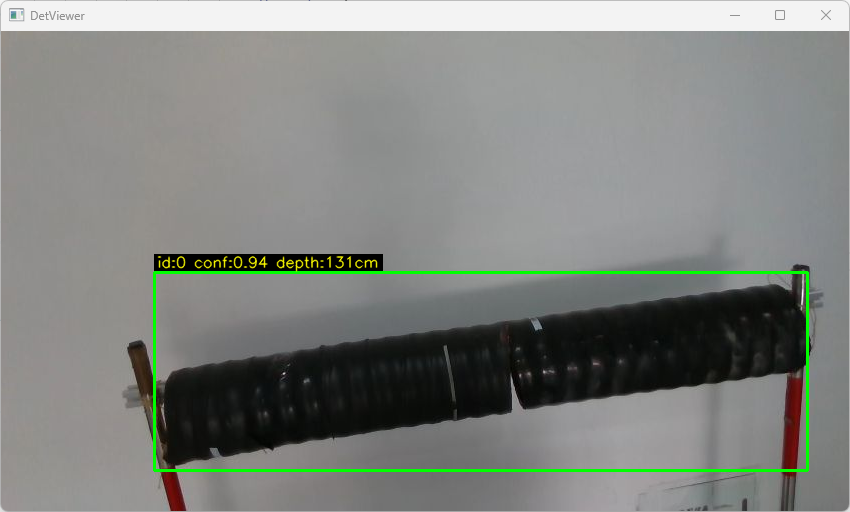
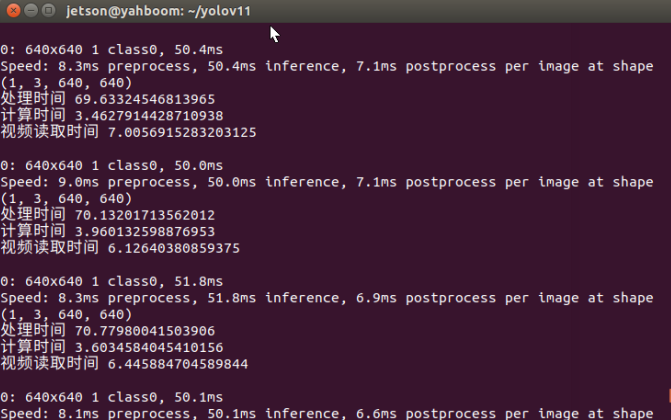
trtexec --onnx=/home/jetson/yolov11/yolov8n.onnx --saveEngine=yolov8n.engine --fp16测速:转换为engine格式后每帧的处理时间大概在70ms左右
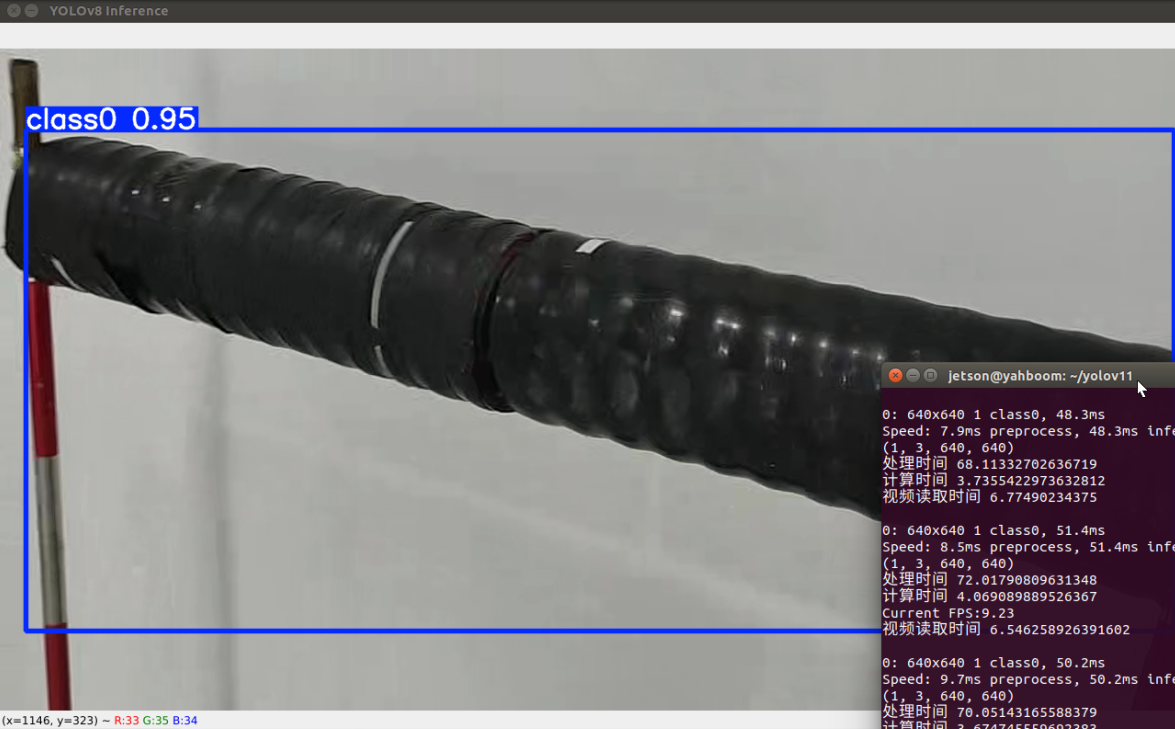
如果能获取深度值,然后再进行计算以及网络通信,可以得到id,conf,和depth