1 支持向量机
1.1 故事引入
-
看下图左边,蓝色和红色的点混在一起,这就像一堆数据,没办法用一条简单的直线把它们分开。再看下图右边,有一条直线把蓝色和红色的点分开,这就是SVM在找的"决策边界",它能把不同类别的数据分开。SVM的目标就是找到这样一条线,让不同类别的数据分得最开;

-
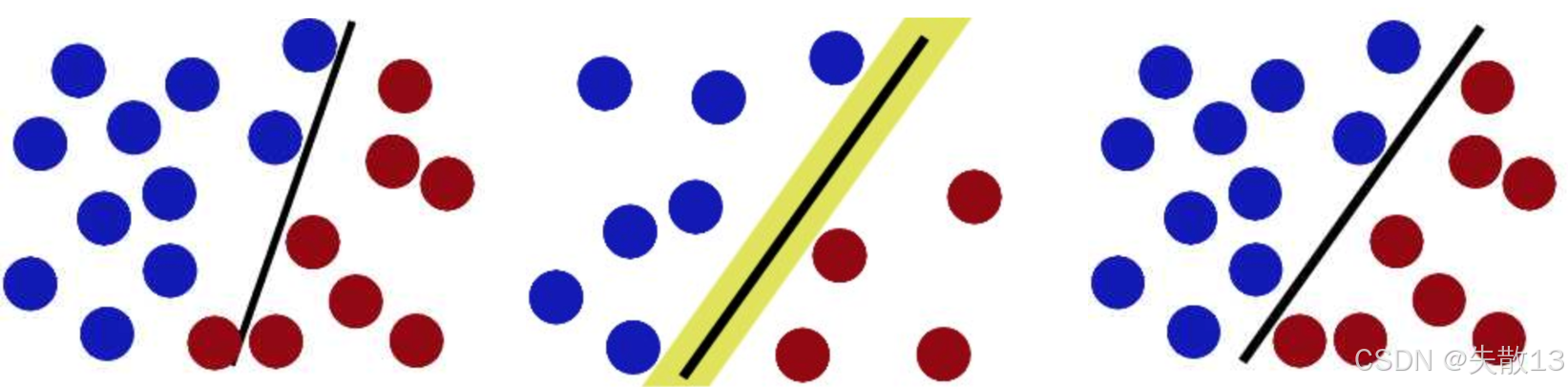
下图有三条线;
- 左边的线,离蓝色和红色的点都太近,这样分类效果肯定不好,新的数据一来可能就会分错;
- 中间那条线,周围有个黄色的区域,这代表"间隔",SVM要找的就是间隔最大的那条线,这样分类才最稳定;
- 右边那条线就是间隔最大的,它离两边的点都最远,分类效果最好,这就是SVM的核心思想------最大化间隔;
-
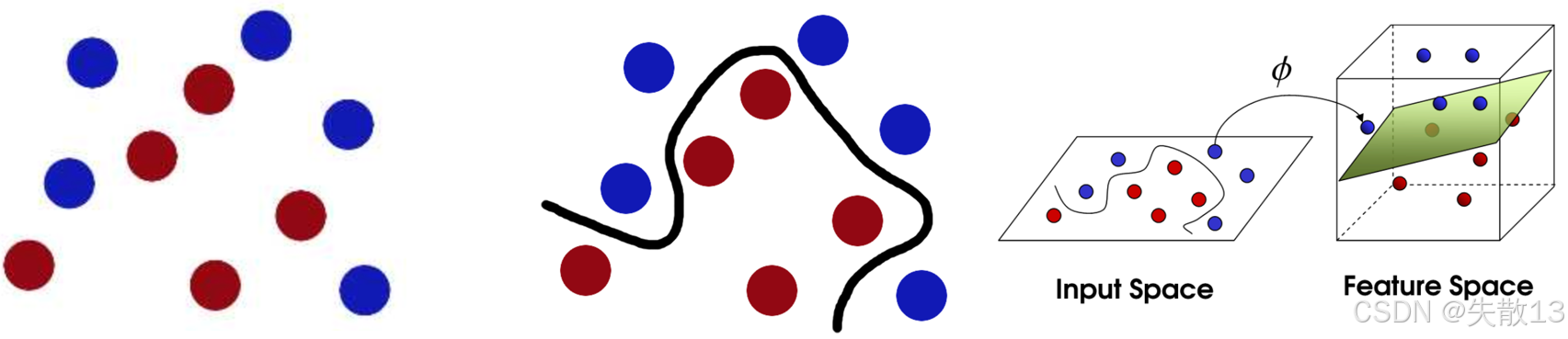
对于下面的三张图:
- 左图,蓝色和红色的点在一个平面上怎么都分不开,就像数据在低维度下没办法分类;
- 在中间的图中,有一条曲线把它们分开了,这说明有时候得用曲线或者高维度的方式来分类;
- 右图,它展示了SVM怎么把低维度的"输入空间"(Input Space)通过一个函数 φ 映射到高维度的"特征空间"(Feature Space);
- 在高维度空间里,原本分不开的点就能用一个平面(超平面)分开;
- 这就是SVM的"核技巧",不用真的计算高维度的点,而是通过核函数来计算点之间的关系;
1.2 概述
-
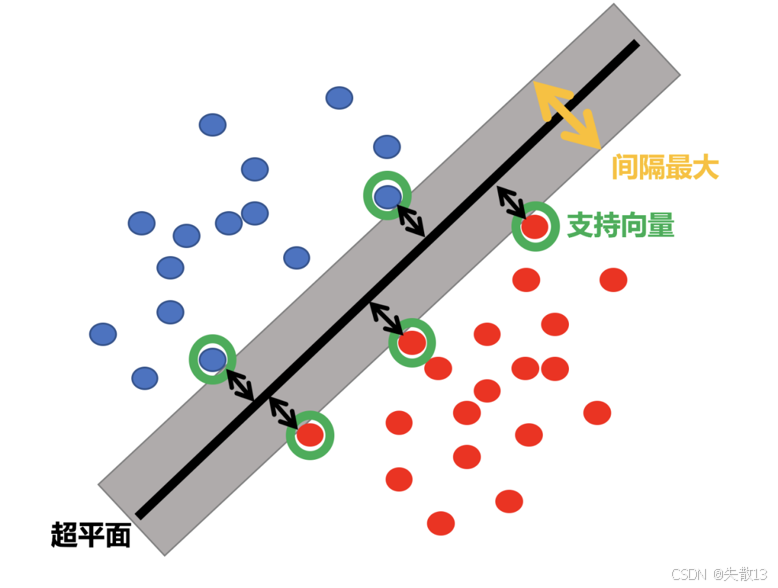
**支持向量机(SVM)**的目标是找到一个超平面,将数据样本分成两类,并且使得这两类之间的间隔最大;
- 下图中的黑色实线就是这个超平面,而两侧的虚线则表示间隔的边界;
- 绿色圆圈标记的点是支持向量,这些点是离超平面最近的样本点,对确定超平面的位置起到关键作用;
- 间隔越大,分类器的泛化能力通常越好,因为它对新数据的分类更稳定;
-
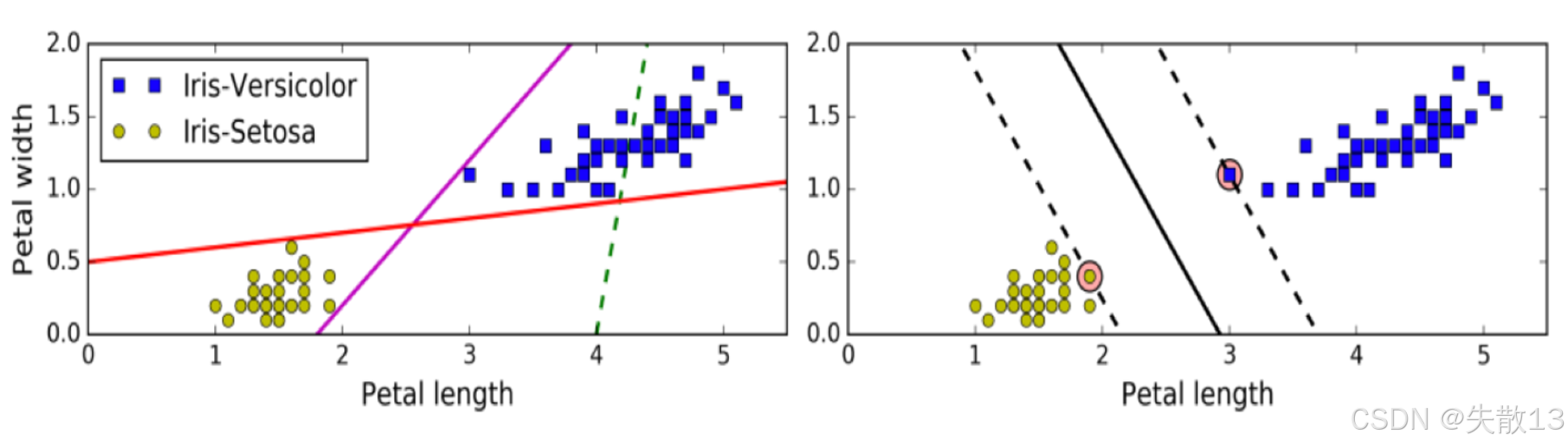
下图比较了不同的分类超平面;
- 左边的图显示了一些可能的分类线,但这些线并没有最大化间隔;
- 右边的图则展示了 SVM 找到的最大间隔超平面。可以看到,SVM 的超平面离两类样本的距离最远,这样可以在分类时提供更好的容错能力;
-
硬间隔要求所有样本都必须被正确分类,并且在分类正确的情况下寻找最大间隔。然而,如果数据中存在异常值(Outlier)或者样本本身线性不可分,硬间隔就无法实现。左边的图显示了一个异常值导致无法找到硬间隔的情况,而右边的图则显示了即使存在异常值,SVM 仍然尝试找到一个合理的超平面;
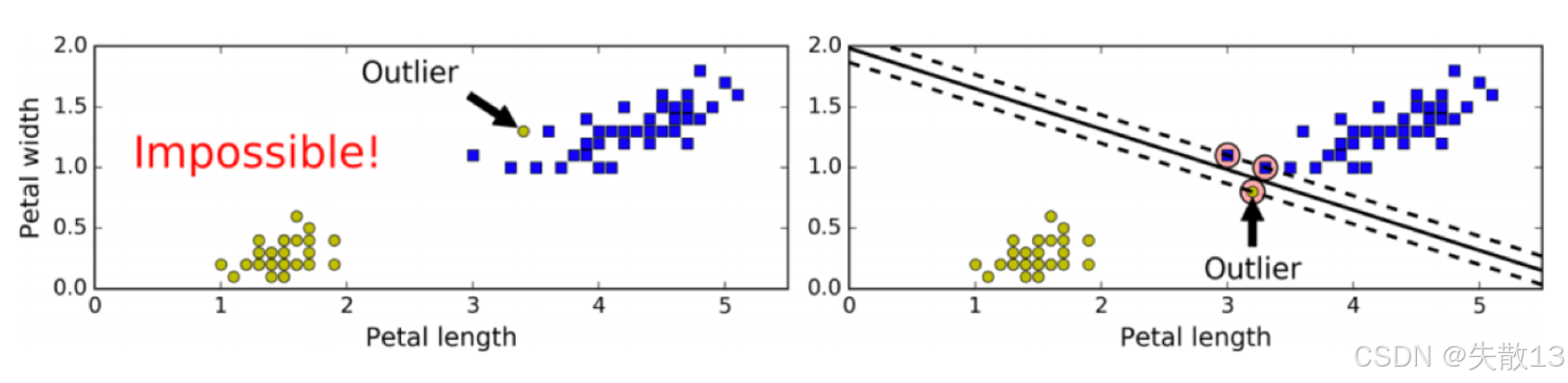
-
软间隔允许部分样本在最大间隔之内,甚至在错误的一边,以寻找最大间隔。目标是在保持间隔宽阔和限制间隔违例之间找到平衡;
- 惩罚系数 C 控制这个平衡:C 值越小,间隔越宽,但允许的间隔违例越多;C 值越大,间隔越窄,但对间隔违例的惩罚越重;
- 左边的图显示了 C=100 时的情况,间隔较窄,违例较少;右边的图显示了 C=1 时的情况,间隔较宽,违例较多;
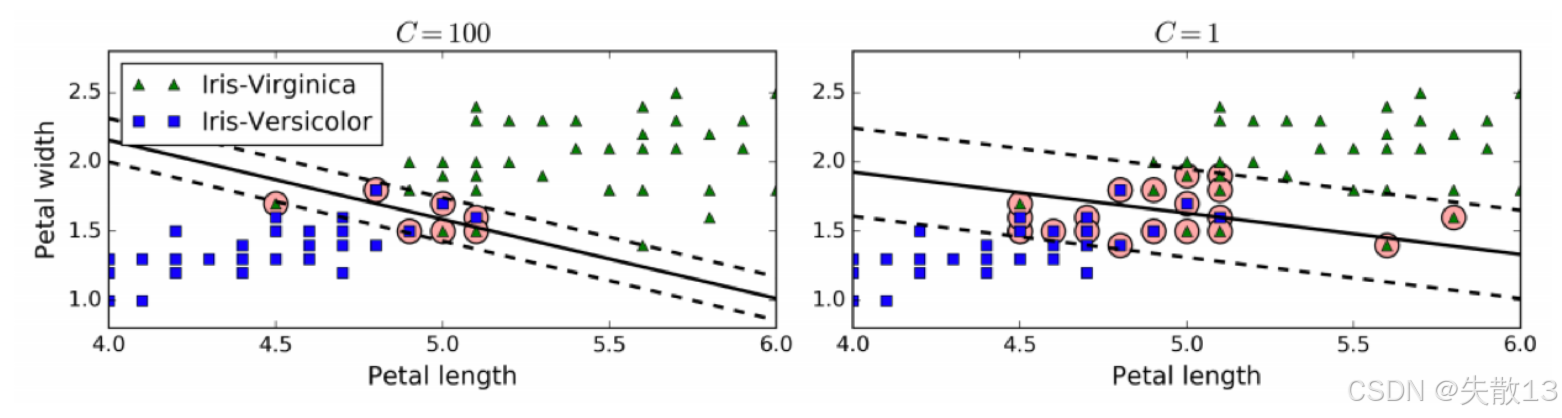
-
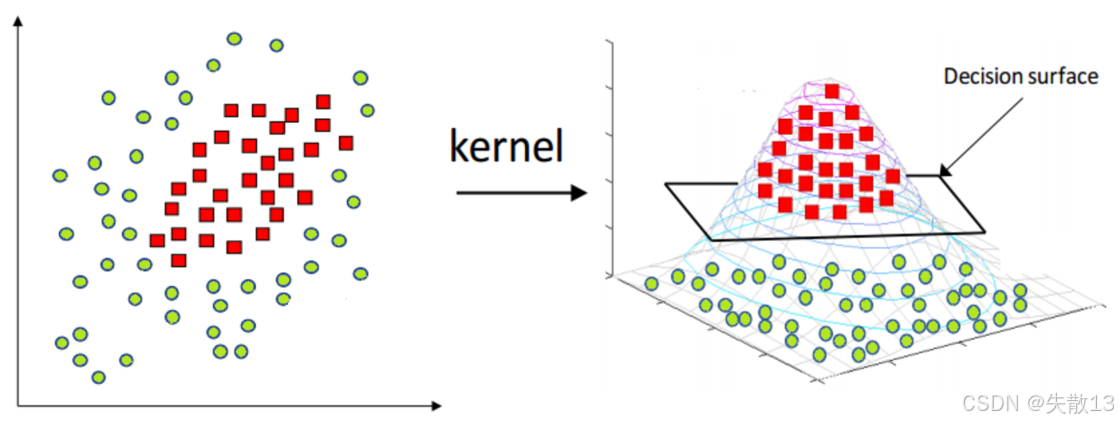
**核函数(Kernel)**将原始输入空间映射到新的特征空间,使得原本线性不可分的样本在新的特征空间中变得线性可分;
- 左边的图显示了原始空间中线性不可分的样本,右边的图显示了通过核函数映射到新特征空间后,样本变得线性可分,并且可以找到一个决策表面(Decision surface)来分隔两类样本;
- 常用的核函数包括线性核、多项式核、径向基函数(RBF)核等;
2 API&案例
2.1 API介绍
-
简介:
pythonclass sklearn.svm.LinearSVC(C=1.0)-
库/框架 :
scikit-learn(通常简称为sklearn),这是一个常用的Python机器学习库; -
类 :
sklearn.svm.LinearSVC,这是scikit-learn库中用于线性支持向量分类的类; -
C:惩罚系数,类似于线性回归中的正则化系数。C值越大,模型对误分类的惩罚越重,模型越倾向于正确分类每个样本,但可能会导致过拟合;C值越小,模型对误分类的惩罚越轻,模型可能更简单,但可能会导致欠拟合;
-
-
示例代码:
python# 从sklearn.svm模块中导入LinearSVC类 from sklearn.svm import LinearSVC # 创建LinearSVC类的实例,设置惩罚系数C为30 mysvc = LinearSVC(C=30) # 使用训练数据X_standard和对应的标签y来训练模型 mysvc.fit(X_standard, y) # 输出模型在训练数据上的准确率 print(mysvc.score(X_standard, y))
2.2 案例:使用LinearSVC进行鸢尾花分类
-
自定义的决策边界绘制工具:
pythonimport numpy as np import matplotlib.pyplot as plt def plot_decision_boundary(model,axis): x0,x1 = np.meshgrid( np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1) ) X_new = np.c_[x0.ravel(),x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"]) # plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map) plt.contourf(x0,x1,zz,cmap=custom_map) def plot_decision_boundary_svc(model,axis): x0,x1 = np.meshgrid( np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1) ) X_new = np.c_[x0.ravel(),x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"]) # plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map) plt.contourf(x0,x1,zz,cmap=custom_map) w= model.coef_[0] b = model.intercept_[0] # w0* x0 + w1* x1+ b = 0 #=>x1 = -w0/w1 * x0 - b/w1 plot_x = np.linspace(axis[0],axis[1],200) up_y = -w[0]/w[1]* plot_x - b/w[1]+ 1/w[1] down_y = -w[0]/w[1]* plot_x - b/w[1]-1/w[1] up_index =(up_y >= axis[2])&(up_y <= axis[3]) down_index =(down_y>= axis[2])&(down_y<= axis[3]) plt.plot(plot_x[up_index],up_y[up_index],color="black") plt.plot(plot_x[down_index],down_y[down_index],color="black") -
导包:
pythonfrom sklearn.datasets import load_iris # 加载鸢尾花数据集 import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.svm import LinearSVC # 导入线性支持向量机分类器 from sklearn.metrics import accuracy_score # 用于计算模型准确率 from plot_util import plot_decision_boundary # 导入自定义的决策边界绘制工具 -
加载数据:
python# 1.加载数据 # 加载鸢尾花数据集,return_X_y=True表示分别返回特征数据和标签 X,y=load_iris(return_X_y=True) print(y.shape) # (150,)。150个样本 print(X.shape) # (150, 4)。每个样本4个特征 # 为了简化问题,只选取标签为0和1的样本(前两类鸢尾花),且只使用前两个特征 x = X[y<2,:2] # 取y<2的样本,且只保留前两个特征 y = y[y<2] # 相应的标签也只保留y<2的部分 print(y.shape) # 输出 (100,)。 前两类各50个 # 绘制标签为0的样本,用红色表示 plt.scatter(x[y==0,0],x[y==0,1],c='red') # 绘制标签为1的样本,用蓝色表示 plt.scatter(x[y==1,0],x[y==1,1],c='blue') plt.show()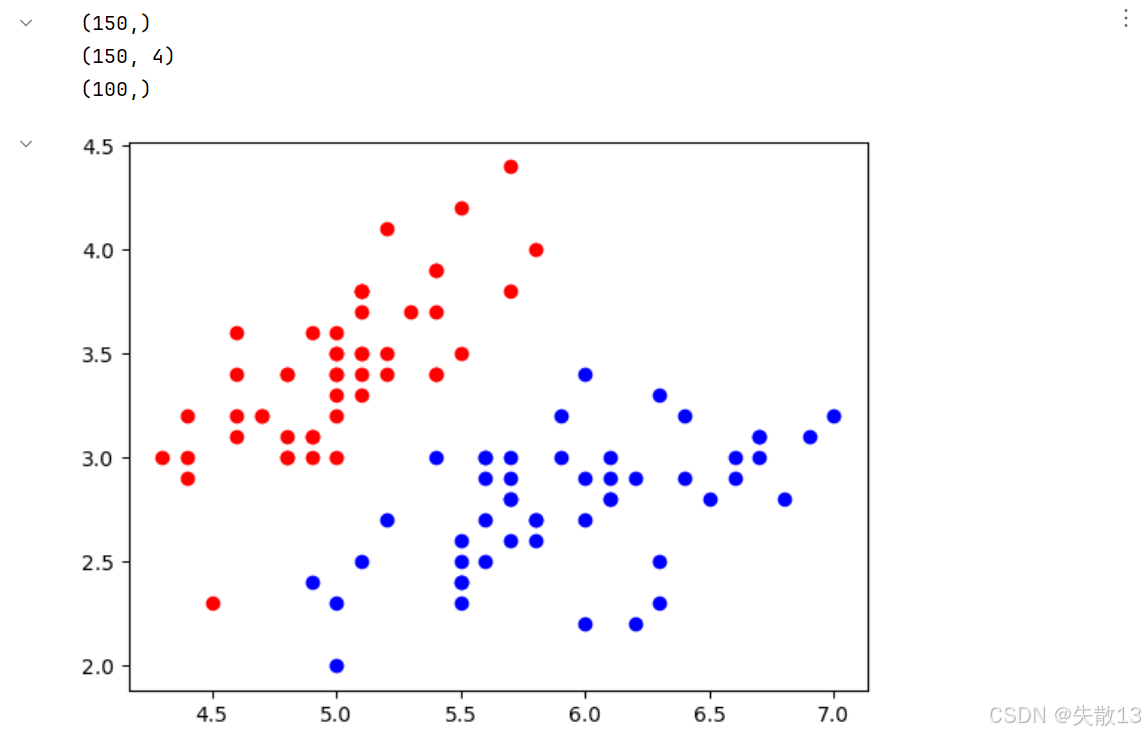
-
数据的预处理:
python# 2.数据的预处理 # 创建标准化转换器,将数据转换为均值为0,标准差为1的标准正态分布 transform = StandardScaler() # 对特征数据进行拟合和转换,计算均值和标准差并应用到数据上 x_tran = transform.fit_transform(x) -
模型训练:
python# 3.模型训练 # 创建线性支持向量机分类器实例,设置惩罚系数C为10 # C值越大,对误分类的惩罚越重,模型可能更复杂,容易过拟合 model=LinearSVC(C=10) model.fit(x_tran,y) y_pred = model.predict(x_tran) # 计算并打印模型在训练数据上的准确率 # 准确率 = 正确预测的样本数 / 总样本数 print(accuracy_score(y_pred,y)) # 通常会接近1.0,因为是在训练数据上评估
-
可视化:
python# 4.可视化 # 绘制模型的决策边界,axis参数指定了坐标轴的范围 plot_decision_boundary(model,axis=[-3,3,-3,3]) # 在决策边界图上绘制标签为0的标准化样本点,红色表示 plt.scatter(x_tran[y == 0, 0], x_tran[y == 0, 1], c='red') # 在决策边界图上绘制标签为1的标准化样本点,蓝色表示 plt.scatter(x_tran[y==1,0],x_tran[y==1,1],c='blue') plt.show()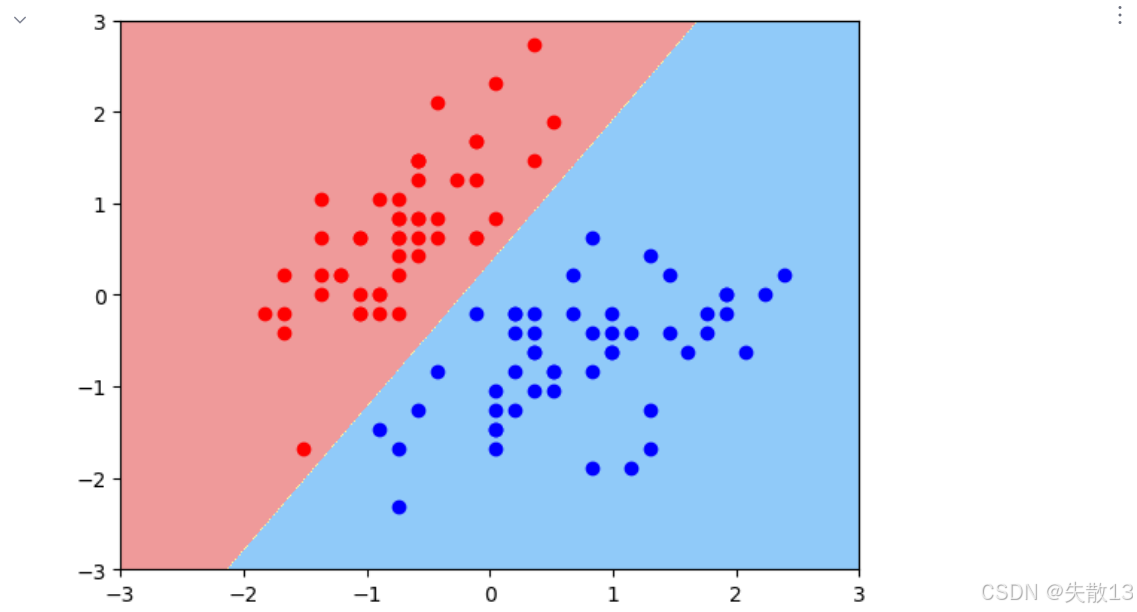
2.3 惩罚系数C对超平面的影响
-
导包、加载数据、数据预处理同上;
-
C 值越大,间隔越窄,但对间隔违例的惩罚越重;
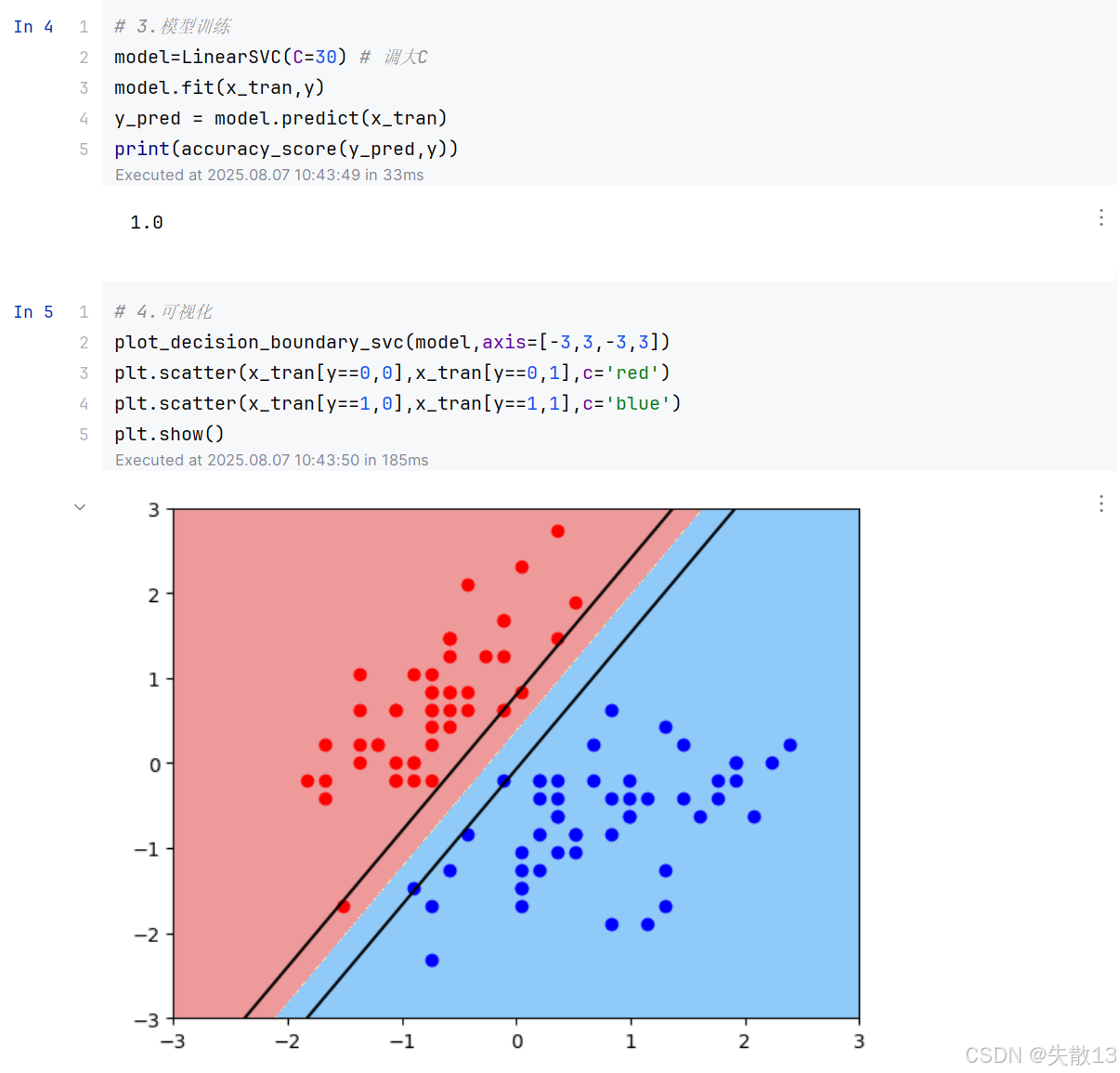
-
C 值越小,间隔越宽,但允许的间隔违例越多;
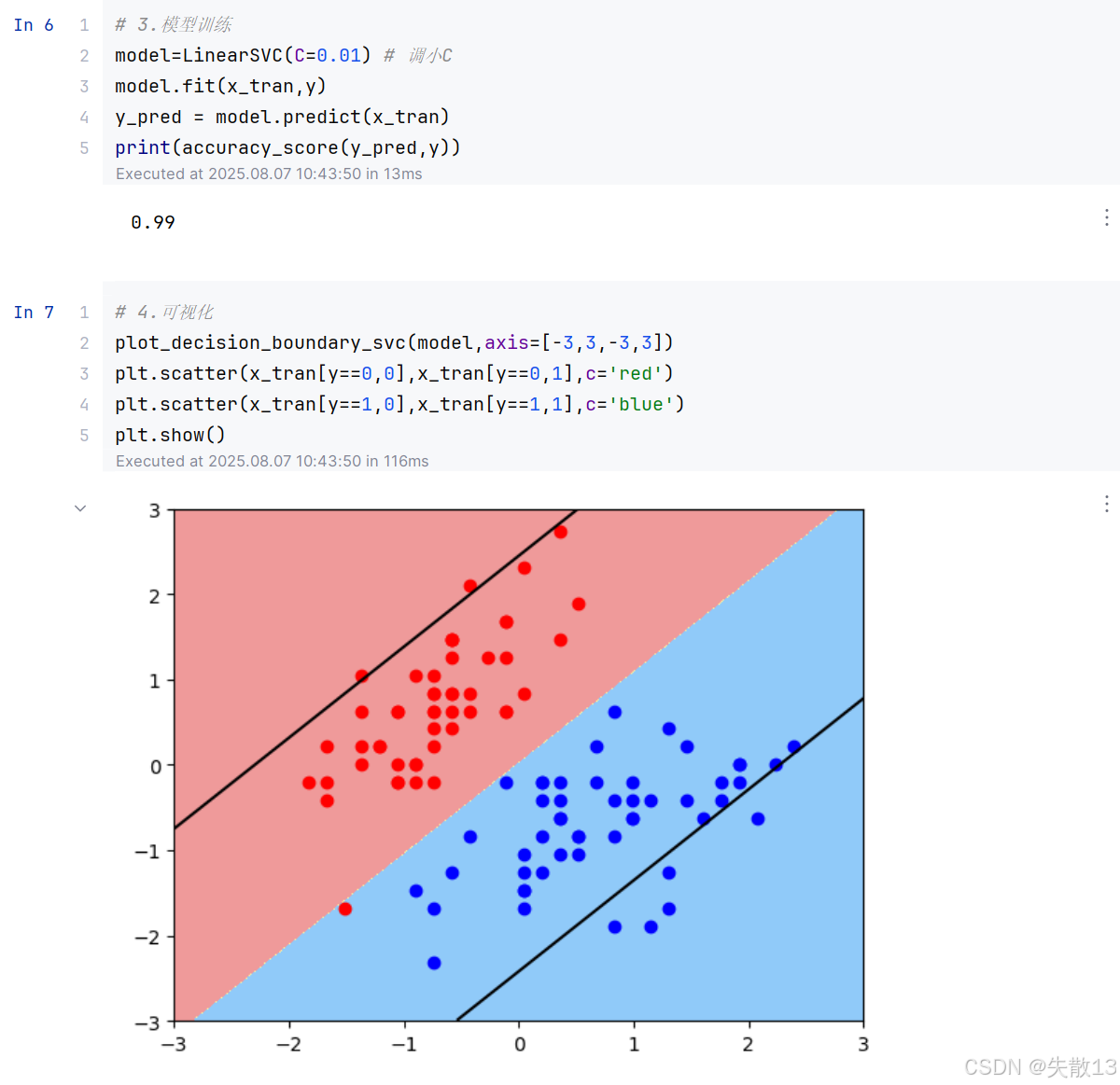
3 SVM算法原理
3.1 支持向量机原理
-
SVM思想 :找到一组参数(w,b)(w, b)(w,b),使得构建的超平面函数能够最优地分离两个集合;
-
样本空间中任意点xxx到超平面(w,b)(w, b)(w,b)的距离公式 :
r=∣wTx+b∣∥w∥ r = \frac{|w^T x + b|}{\|w\|} r=∥w∥∣wTx+b∣- 其中,www是超平面的法向量,bbb是超平面的截距,xxx是样本点,∥w∥\|w\|∥w∥是www的范数;
-
最大间隔的约束条件:
- 对于样本点xix_ixi和对应的标签yiy_iyi,有:
{wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=−1 \begin{cases} w^T x_i + b \geq +1, & y_i = +1 \\ w^T x_i + b \leq -1, & y_i = -1 \end{cases} {wTxi+b≥+1,wTxi+b≤−1,yi=+1yi=−1 - 这意味着对于正样本(yi=+1y_i = +1yi=+1),wTxi+bw^T x_i + bwTxi+b至少为+1+1+1;
- 对于负样本(yi=−1y_i = -1yi=−1),wTxi+bw^T x_i + bwTxi+b至多为−1-1−1;
- 对于样本点xix_ixi和对应的标签yiy_iyi,有:
-
支持向量:距离超平面最近的几个训练样本点,使得上述约束条件中的等号成立;
-
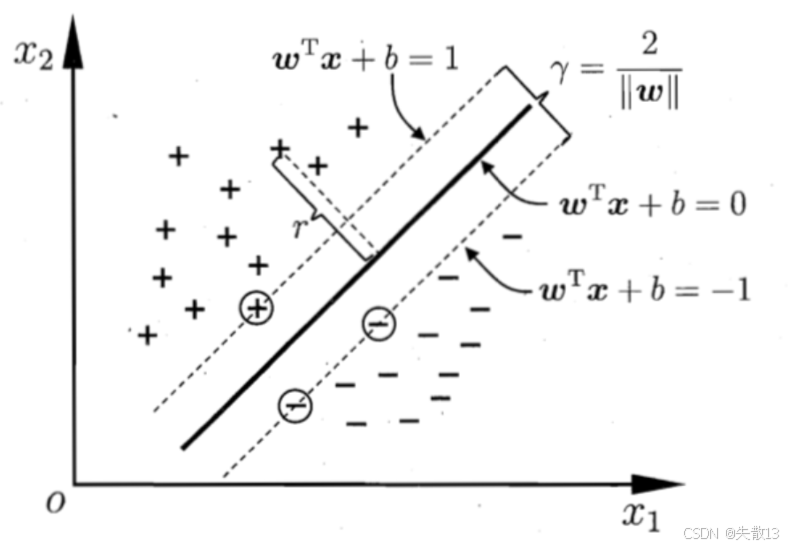
两个异类支持向量到超平面的距离之和,也是最大间隔距离公式:
γ=2∥w∥ \gamma = \frac{2}{\|w\|} γ=∥w∥2
-
目标函数 :
maxw,b2∥w∥ \max_{w, b} \frac{2}{\|w\|} w,bmax∥w∥2- 同时满足约束条件yi(wTxi+b)≥1y_i (w^T x_i + b) \geq 1yi(wTxi+b)≥1,其中i=1,2,⋯ ,mi = 1, 2, \cdots, mi=1,2,⋯,m;
-
目标函数的进一步优化 :
minw,b12∥w∥2 \min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2- 同时满足约束条件yi(wTxi+b)≥1y_i (w^T x_i + b) \geq 1yi(wTxi+b)≥1,其中i=1,2,⋯ ,mi = 1, 2, \cdots, mi=1,2,⋯,m;
-
添加核函数后的目标函数和约束条件:
- 目标函数:minw,b12∥w∥2\min_{w, b} \frac{1}{2} \|w\|^2minw,b21∥w∥2
- 约束条件:∑i=1n(1−yi(wTΦ(xi)+b))≤0\sum_{i=1}^n (1 - y_i (w^T \Phi(x_i) + b)) \leq 0∑i=1n(1−yi(wTΦ(xi)+b))≤0
- 其中,Φ(xi)\Phi(x_i)Φ(xi)是将样本xix_ixi映射到高维特征空间的函数;
-
构建拉格朗日函数 :L(w,b,α)=12∥w∥2−∑i=1nαi(yi(wTΦ(xi)+b)−1)L(w, b, \alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i (y_i (w^T \Phi(x_i) + b) - 1)L(w,b,α)=21∥w∥2−∑i=1nαi(yi(wTΦ(xi)+b)−1)
- 其中,αi\alpha_iαi是拉格朗日乘子;
-
对偶问题转换 :minw,bmaxαL(w,b,α)⟺maxαminw,bL(w,b,α)\min_{w, b} \max_{\alpha} L(w, b, \alpha) \Longleftrightarrow \max_{\alpha} \min_{w, b} L(w, b, \alpha)minw,bmaxαL(w,b,α)⟺maxαminw,bL(w,b,α)
-
对www求偏导并令其等于0:
-
首先,将拉格朗日函数展开:
L=12∥w∥2−∑i=1nαi(yiwTΦ(xi)+yib−1)L=12∥w∥2−∑i=1nαiyiwTΦ(xi)+αiyib−αi L = \frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i (y_i w^T \Phi(x_i) + y_i b - 1) \\ L = \frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i y_i w^T \Phi(x_i) + \alpha_i y_i b - \alpha_i L=21∥w∥2−i=1∑nαi(yiwTΦ(xi)+yib−1)L=21∥w∥2−i=1∑nαiyiwTΦ(xi)+αiyib−αi -
对www求偏导:
∂L∂w=w−∑i=1nαiyiΦ(xi)=0 \frac{\partial L}{\partial w} = w - \sum_{i=1}^n \alpha_i y_i \Phi(x_i) = 0 ∂w∂L=w−i=1∑nαiyiΦ(xi)=0 -
得到:
w=∑i=1nαiyiΦ(xi) w = \sum_{i=1}^n \alpha_i y_i \Phi(x_i) w=i=1∑nαiyiΦ(xi)
-
-
对bbb求偏导并令其等于0:
- 对bbb求偏导:
∂L∂b=∑i=1nαiyi=0 \frac{\partial L}{\partial b} = \sum_{i=1}^n \alpha_i y_i = 0 ∂b∂L=i=1∑nαiyi=0 - 得到:
∑i=1nαiyi=0 \sum_{i=1}^n \alpha_i y_i = 0 i=1∑nαiyi=0
- 对bbb求偏导:
-
将对www和bbb的偏导结果代入拉格朗日函数 :首先,将w=∑i=1nαiyiΦ(xi)w = \sum_{i=1}^n \alpha_i y_i \Phi(x_i)w=∑i=1nαiyiΦ(xi)代入拉格朗日函数
KaTeX parse error: Can't use function '' in math mode at position 317: ... \\alpha_i \\\\ 由于̲\sum_{i=1}^n \a...
3.2 多元支持向量机原理
-
求解当 α 是什么值时拉格朗日函数最大
α∗=argmaxα(∑i=1nαi−12∑i,j=1nαiαjyiyjΦT(xi)Φ(xj)) \alpha^* = \arg \max_{\alpha} \left( \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i,j=1}^n \alpha_i \alpha_j y_i y_j \Phi^T(x_i) \Phi(x_j) \right) α∗=argαmax(i=1∑nαi−21i,j=1∑nαiαjyiyjΦT(xi)Φ(xj))-
这一步是为了找到最优的拉格朗日乘子 α\alphaα,使得拉格朗日函数最大化
-
αi\alpha_iαi 是拉格朗日乘子,对应每个样本的权重
-
yiy_iyi 是样本的标签(+1 或 -1)
-
Φ(xi)\Phi(x_i)Φ(xi) 是将样本 xix_ixi 映射到高维特征空间的函数
-
ΦT(xi)Φ(xj)\Phi^T(x_i) \Phi(x_j)ΦT(xi)Φ(xj) 是高维特征空间中样本 xix_ixi 和 xjx_jxj 的内积
-
-
将上述公式化简成极小值问题
minα12∑i=1n∑j=1nαiαjyiyj(Φ(xi)⋅Φ(xj))−∑i=1nαi \min_{\alpha} \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j (\Phi(x_i) \cdot \Phi(x_j)) - \sum_{i=1}^n \alpha_i αmin21i=1∑nj=1∑nαiαjyiyj(Φ(xi)⋅Φ(xj))−i=1∑nαi-
约束条件:
s.t. ∑i=1nαiyi=0αi≥0,i=1,2,...,n \text{s.t. } \sum_{i=1}^n \alpha_i y_i = 0 \\ \alpha_i \geq 0, \quad i = 1, 2, \ldots, n s.t. i=1∑nαiyi=0αi≥0,i=1,2,...,n -
将最大化问题转换为最小化问题,便于求解
-
目标函数是原拉格朗日函数的对偶形式
-
约束条件确保了最优解的可行性:
- ∑i=1nαiyi=0\sum_{i=1}^n \alpha_i y_i = 0∑i=1nαiyi=0 是对偶问题的约束条件
- αi≥0\alpha_i \geq 0αi≥0 是拉格朗日乘子的非负约束
-
-
将训练样本带入上面2步骤公式,求解出 αi\alpha_iαi 值。将 αi\alpha_iαi 值代入下面公式计算 w,bw, bw,b 的值
w∗=∑i=1Nαi∗yiΦ(xi)b∗=yi−∑i=1Nαi∗yi(Φ(xi)⋅Φ(xj)) w^* = \sum_{i=1}^N \alpha_i^* y_i \Phi(x_i) \\ b^* = y_i - \sum_{i=1}^N \alpha_i^* y_i (\Phi(x_i) \cdot \Phi(x_j)) w∗=i=1∑Nαi∗yiΦ(xi)b∗=yi−i=1∑Nαi∗yi(Φ(xi)⋅Φ(xj))- 求解出最优的 αi∗\alpha_i^*αi∗ 后,代入上述公式计算超平面的参数 w∗w^*w∗ 和 b∗b^*b∗
- w∗w^*w∗ 是超平面的法向量
- b∗b^*b∗ 是超平面的截距
-
求得分类超平面
w∗Φ(x)+b∗=0 w^* \Phi(x) + b^* = 0 w∗Φ(x)+b∗=0-
最终的分类超平面由 w∗w^*w∗ 和 b∗b^*b∗ 确定;
-
对于新样本 xxx,通过判断 w∗Φ(x)+b∗w^* \Phi(x) + b^*w∗Φ(x)+b∗ 的符号来确定其类别。
-
4 SVM核函数
4.1 概述
-
核函数将原始输入空间映射到新的特征空间,从而使原本线性不可分的样本可能在核空间中变得可分;
- 左图显示了原始空间(Original space)中线性不可分的样本(红色和蓝色点);
- 中间图显示了通过核函数映射到新的特征空间后,样本变得线性可分;
- 右图进一步展示了这种映射的效果;
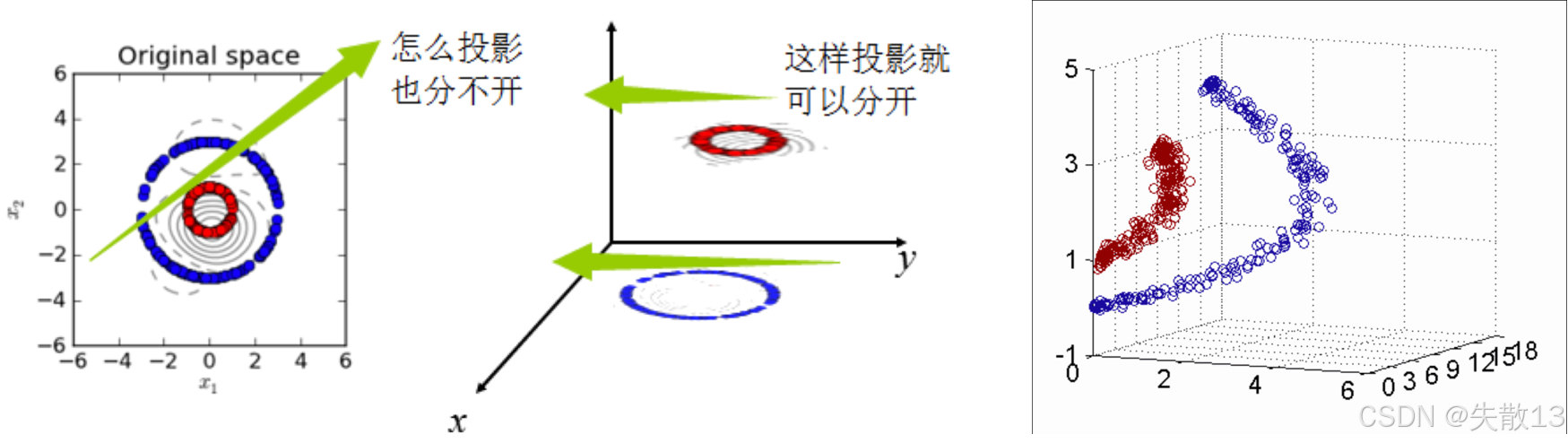
-
核函数分类:
名称 表达式 参数 线性核 \\kappa(\\boldsymbol{x}_i, \\boldsymbol{x}_j) = \\boldsymbol{x}_i\^T \\boldsymbol{x}_j 无参数 多项式核 \\kappa(\\boldsymbol{x}_i, \\boldsymbol{x}_j) = (\\boldsymbol{x}_i\^T \\boldsymbol{x}_j)\^d d \\geq 1 为多项式的次数 高斯核 \\kappa(\\boldsymbol{x}_i, \\boldsymbol{x}_j) = \\exp\\left( -\\frac{|\\boldsymbol{x}_i - \\boldsymbol{x}_j|^2}{2\\sigma^2} \\right) \\sigma \> 0 为高斯核的带宽(width) 拉普拉斯核 \\kappa(\\boldsymbol{x}_i, \\boldsymbol{x}_j) = \\exp\\left( -\\frac{|\\boldsymbol{x}_i - \\boldsymbol{x}_j|}{\\sigma} \\right) \\sigma \> 0 Sigmoid 核 \\kappa(\\boldsymbol{x}_i, \\boldsymbol{x}_j) = \\tanh(\\beta \\boldsymbol{x}_i\^T \\boldsymbol{x}_j + \\theta) \\tanh 为双曲正切函数, \\beta \> 0 ,,, \\theta \< 0 - 高斯核(径向基函数)是最常用的核函数之一,它可以将样本投射到无限维空间,使得原本不可分的数据变得可分。
4.2 高斯核函數
-
高斯核函数 (Radial Basis Function Kernel,RBF 核)是支持向量机(SVM)中常用的核函数之一;
K(x,y)=e−γ∥x−y∥2 K(x, y) = e^{-\gamma \|x - y\|^2} K(x,y)=e−γ∥x−y∥2- x 和 y 是样本点; \\gamma 是超参数,控制高斯分布的宽度;
-
超参数 \\gamma 的作用:
- \\gamma 越大,高斯分布越窄,模型越容易过拟合;
- \\gamma 越小,高斯分布越宽,模型越容易欠拟合;
-
图示说明:
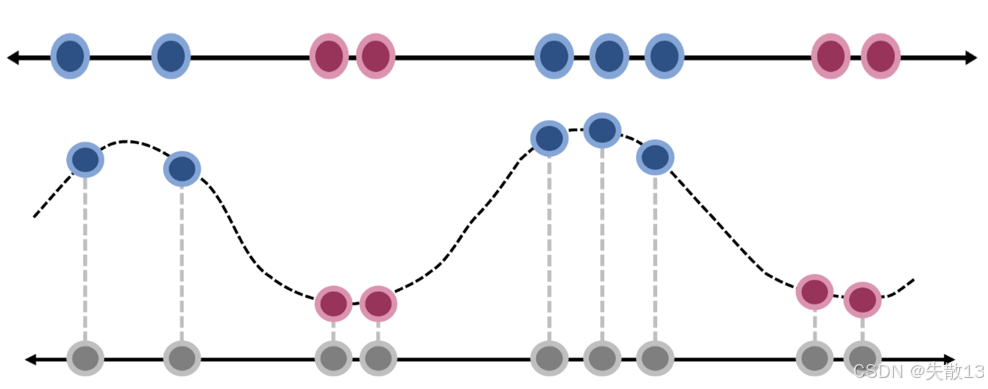
- 上方的图显示了原始样本点(蓝色和红色);
- 下方的图显示了通过高斯核函数映射后的样本点(蓝色和红色),可以看到样本点在新的特征空间中变得线性可分
-
API:
-
在
scikit-learn中,可以通过以下代码使用高斯核函数:pythonfrom sklearn.svm import SVC # kernel='rbf'表示使用高斯核函数;gamma是超参数,控制高斯分布的宽度 SVC(kernel='rbf', gamma=gamma)
-
-
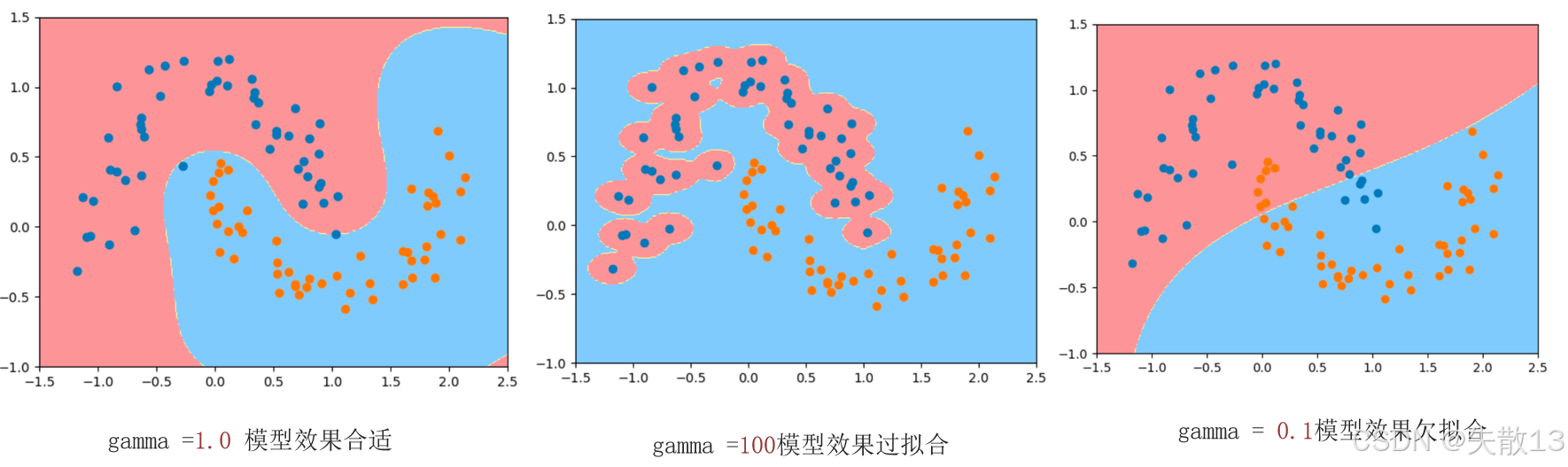
超参数 \\gamma 对模型的影响:
- 左图( \\gamma = 1.0 ):模型效果合适,分类边界合理;
- 中图( \\gamma = 100 ):模型效果过拟合,分类边界过于复杂,可能在训练集上表现很好,但在测试集上表现较差;
- 右图( \\gamma = 0.1 ):模型效果欠拟合,分类边界过于简单,无法有效区分样本;
4.3 案例
-
导包:
pythonfrom sklearn.datasets import make_moons import matplotlib.pyplot as plt # 生成月牙形数据集 from sklearn.pipeline import Pipeline # 构建机器学习工作流的管道 from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC # 支持向量机分类器 from plot_util import plot_decision_boundary # 自定义的决策边界绘制工具 -
准备数据:
python# 准备数据 # 生成带有噪声的月牙形数据集,noise=0.15控制噪声大小 # 月牙形数据是典型的非线性可分数据,适合展示核函数的效果 x,y=make_moons(noise=0.15) # 可视化原始数据分布 # 绘制标签为0的样本点 plt.scatter(x[y==0, 0], x[y==0, 1]) # 绘制标签为1的样本点 plt.scatter(x[y==1, 0], x[y==1, 1]) # 显示图形,可观察到数据呈月牙状分布,线性不可分 plt.show()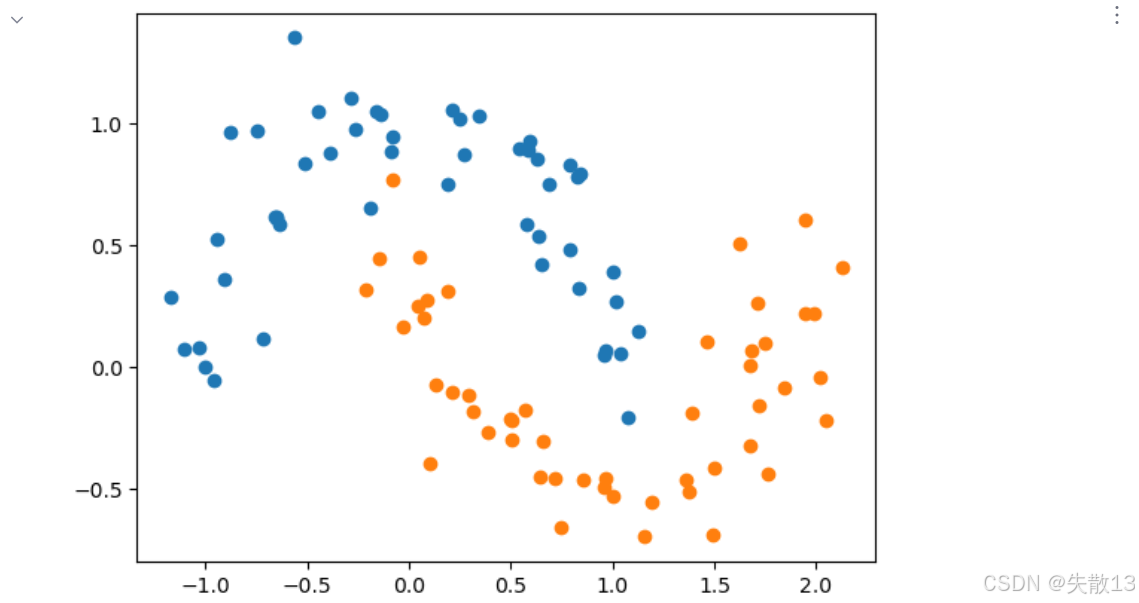
-
构建函数:
python# 构建函数:创建使用RBF核的SVM模型管道 def RBFsvm(gamma=0.1): # Pipeline用于将数据预处理和模型训练步骤串联起来 return Pipeline( [ # 第一步:数据标准化,将特征转换为均值为0、标准差为1的分布 ('std_scalar', StandardScaler()), # 第二步:使用SVM分类器,指定核函数为RBF(径向基函数) # gamma是RBF核的超参数,控制高斯函数的宽度 ('svc', SVC(kernel='rbf', gamma=gamma)) ] ) -
实验1:
python# 实验1:gamma=0.5时的模型效果 # 创建gamma=0.5的RBF SVM模型 svc1 = RBFsvm(0.5) # 单独获取管道中的标准化器,对数据进行标准化处理 x_std = svc1['std_scalar'].fit_transform(x) # 使用标准化后的数据训练模型 svc1.fit(x_std, y) # 绘制决策边界,设置坐标轴范围 plot_decision_boundary(svc1, axis=[-3, 3, -3, 3]) # 在决策边界图上绘制标准化后的样本点 plt.scatter(x_std[y==0, 0], x_std[y==0, 1]) plt.scatter(x_std[y==1, 0], x_std[y==1, 1]) # 显示图形,可观察到较合理的分类边界 plt.show()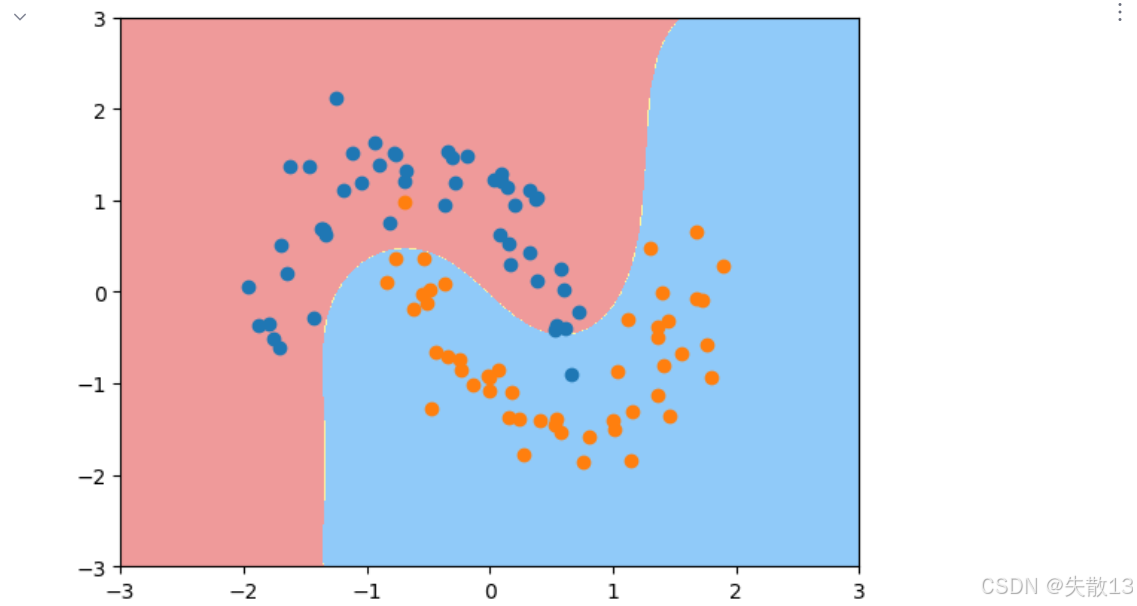
-
实验2:
python# 实验2:gamma=1.0时的模型效果 # 创建gamma=1.0的RBF SVM模型 svc1 = RBFsvm(1.0) # 使用原始数据训练模型(管道内部会自动进行标准化) svc1.fit(x, y) # 绘制决策边界,设置适合原始数据的坐标轴范围 plot_decision_boundary(svc1, axis=[-1.5, 2.5, -1, 1.5]) # 绘制原始样本点 plt.scatter(x[y==0, 0], x[y==0, 1]) plt.scatter(x[y==1, 0], x[y==1, 1]) # 显示图形,边界比gamma=0.5时更复杂一些 plt.show()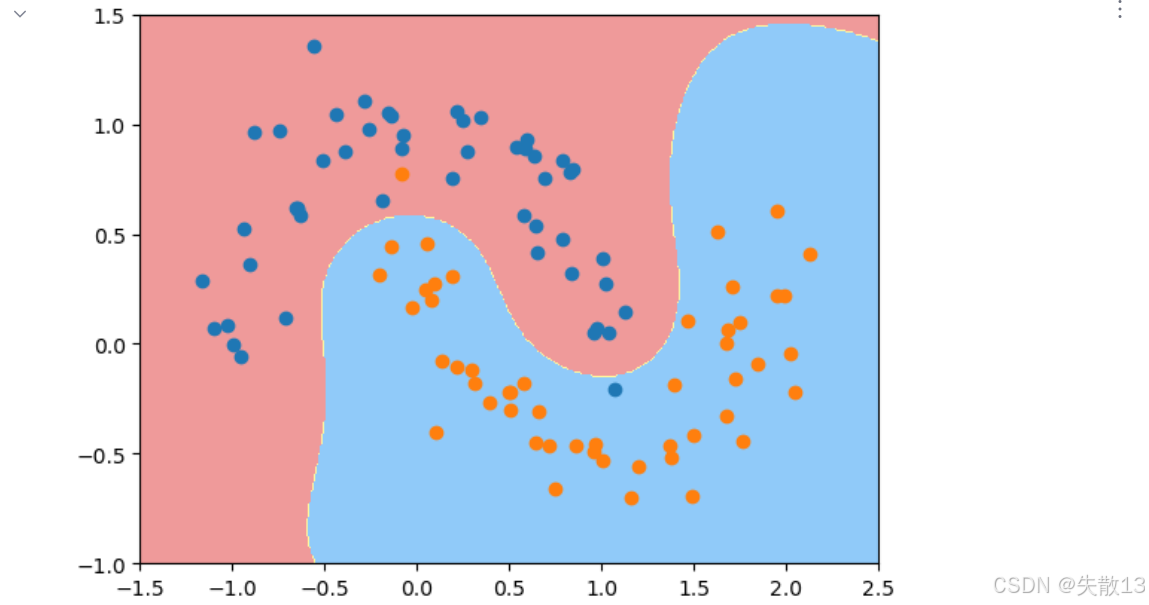
-
实验3:
python# 实验3:gamma=100时的模型效果 # 创建gamma=100的RBF SVM模型 svc2 = RBFsvm(100) svc2.fit(x, y) plot_decision_boundary(svc2, axis=[-1.5, 2.5, -1, 1.5]) plt.scatter(x[y==0, 0], x[y==0, 1]) plt.scatter(x[y==1, 0], x[y==1, 1]) # 显示图形,可观察到过拟合现象: # 决策边界非常复杂,过度拟合了训练数据中的噪声 plt.show()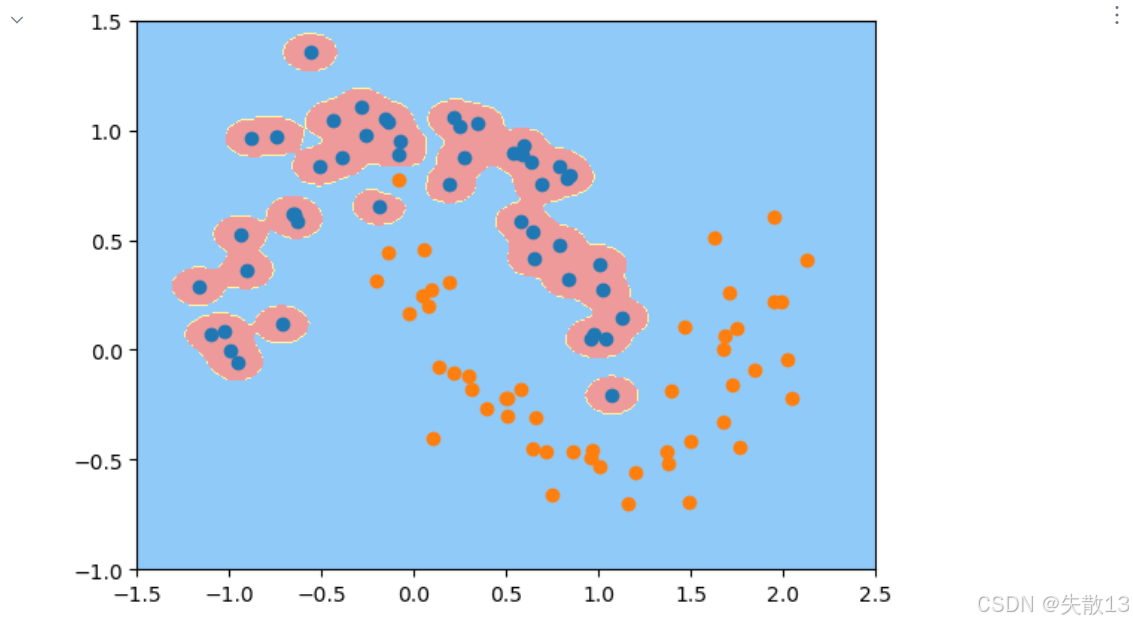
-
实验4:
python# 实验4:gamma=0.1时的模型效果 # 创建gamma=0.1的RBF SVM模型 svc3 = RBFsvm(0.1) svc3.fit(x, y) plot_decision_boundary(svc3, axis=[-1.5, 2.5, -1, 1.5]) plt.scatter(x[y==0, 0], x[y==0, 1]) plt.scatter(x[y==1, 0], x[y==1, 1]) # 显示图形,可观察到欠拟合现象: # 决策边界过于简单,无法很好地区分两类数据 plt.show()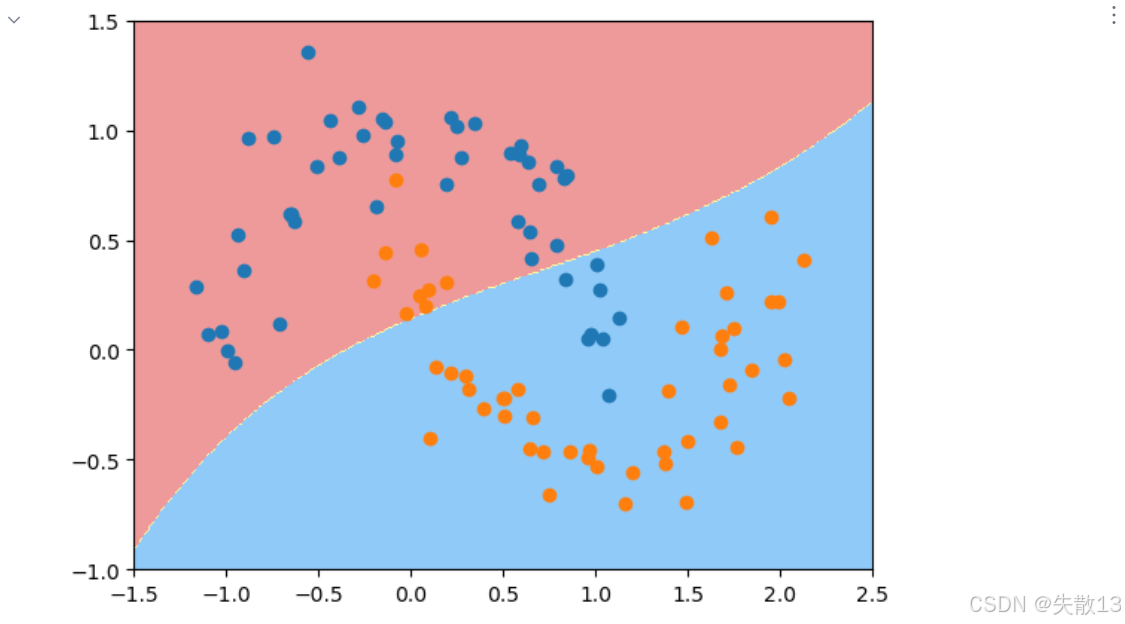
4.4 超参数 gamma 的意义和作用
-
高斯核函数(RBF)表达式 :
K(x,y)=e−γ∥x−y∥2 K(x, y) = e^{-\gamma \|x - y\|^2} K(x,y)=e−γ∥x−y∥2 -
对比高斯函数 :
g(x)=1σ2πe−12(x−μσ)2 g(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{1}{2} \left( \frac{x - \mu}{\sigma} \right)^2} g(x)=σ2π 1e−21(σx−μ)2 -
超参数
gamma的意义:- 高斯核函数中的
gamma(γ\gammaγ)等价于高斯函数中的 12σ2\frac{1}{2\sigma^2}2σ21; gamma控制高斯分布的宽度;
- 高斯核函数中的
-
标准差(σ\sigmaσ)对数据分布的影响
-
标准差越大:数据越分散,图像越宽;
-
标准差越小:数据越集中,图像越窄;
-
-
超参数
gamma对模型的影响-
gamma越大:高斯分布越窄,数据变化越剧烈,模型容易过拟合; -
gamma越小:高斯分布越宽,数据变化越平缓,模型容易欠拟合;
-
-
看下图中曲线:
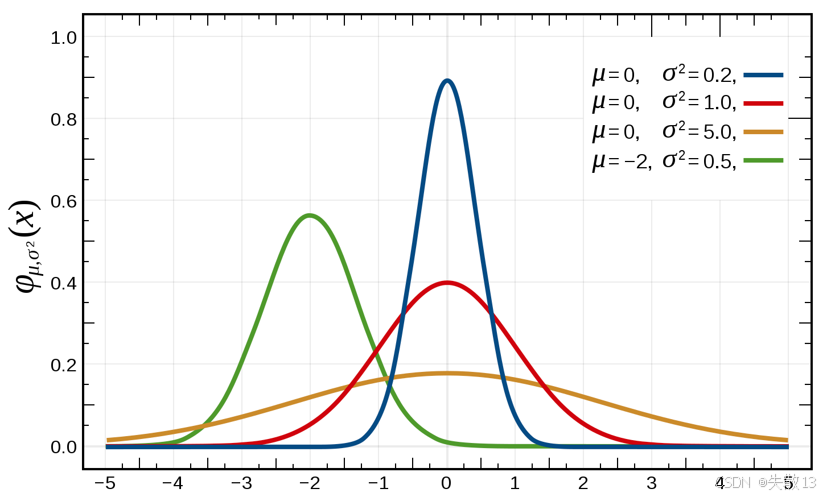
- 蓝色曲线:μ=0,σ2=0.2\mu = 0, \sigma^2 = 0.2μ=0,σ2=0.2(数据集中,图像窄)
- 红色曲线:μ=0,σ2=1.0\mu = 0, \sigma^2 = 1.0μ=0,σ2=1.0(数据较集中,图像较窄)
- 橙色曲线:μ=0,σ2=5.0\mu = 0, \sigma^2 = 5.0μ=0,σ2=5.0(数据分散,图像宽)
- 绿色曲线:μ=−2,σ2=0.5\mu = -2, \sigma^2 = 0.5μ=−2,σ2=0.5(数据集中,图像窄)