学习文档
官网的k8s上关于scheduler的文档基本可以分为这两部分
介绍 scheduler 的基本概念
介绍 scheduler 的配置 KubeSchedulerConfiguration 的参数
介绍 scheduler 的命令行参数
kube-scheduler 选择 node 通过下面这两步
-
过滤(Filtering)
-
打分(Scoring)
为了提高 kube-scheduler 的效率,我们其实没有必要遍历集群中所有的node之后再挑选出一个合适的node进行容器的调度,这里 KubeSchedulerConfiguration 提供了一个参数
yaml
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50percentageOfNodesToScore 就表示在集群中需要进行评分的node的比例,这里指定为 50 表示只需要扫描比较集群中一半的node即可
为了让所有的node都接受公平性调度,scheduler 调度节点按照轮询的策略进行,比如下面这些node
bash
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6Scheduler 计算的策略是按照 node1 -> node5 -> node2 -> node6 -> node3 -> node4 来进行的
第一次筛选如果只到node6,则下次筛选会从 node3 进行,依次循环往复遍历到每个节点
Kube-schedluer 的参数,介绍几个关键的参数
bash
--secure-port int Default: 10259 # 默认的启动端口
--config string # 配置文件的路径(指定KubeSchedulerConfiguration的路径)配置参数
Kube-scheduler 的配置统一配置在 KubeSchedulerConfiguration 中
参考官方的一个模板
yaml
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: multipoint-scheduler
plugins:
# Disable the default QueueSort plugin
queueSort:
enabled:
- name: 'CustomQueueSort'
disabled:
- name: 'DefaultQueueSort'
# Enable custom Filter plugins
filter:
enabled:
- name: 'CustomPlugin1'
- name: 'CustomPlugin2'
- name: 'DefaultPlugin2'
disabled:
- name: 'DefaultPlugin1'
# Enable and reorder custom score plugins
score:
enabled:
- name: 'DefaultPlugin2'
weight: 1
- name: 'DefaultPlugin1'
weight: 3调度框架
调度框架由一个个的插件组成,每个pod的调度模块分为两个部分 scheduling cycle 和 binding cycle
调度循环为一个 pod 选择合适的 node,而绑定循环来执行调度循环选择好的决策
scheduling cycle 和 binding cycle 共同组成了 scheduling context
注意:scheduling cycle 所属的 plugins 必须是线性运行的,一个接着一个运行;而 binding cycle 所属的 plugins 是可以并行执行的
整体架构如下
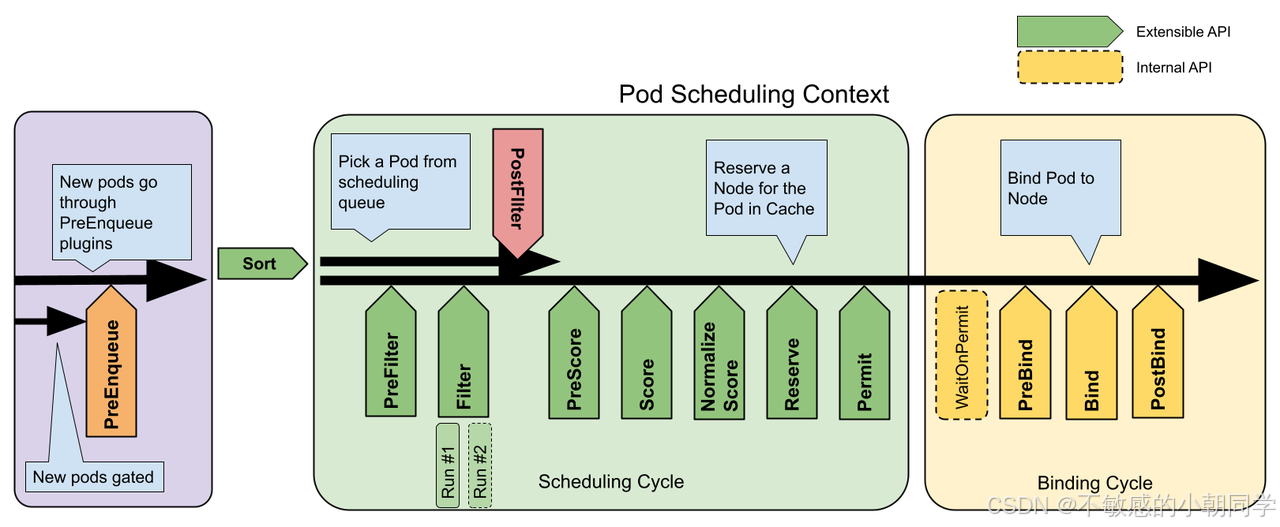
基本流程
编写一个自定义的 scheduler 可分为如下
-
编写插件
-
部署scheduler到集群里面
-
配置使用的插件列表
-
下发pod验证
自己部署一个scheduler
clone仓库
我们去 k8s 官网 clone 好对应版本的 k8s 集群的代码仓库

比如我的版本是1.23
检查编译是否能够通过
Clone 下来之后执行 makefile,注意这里的go版本不要高于当前你编译使用的go版本
开始编译
出现下面这个标识未报错则编译成功
进入到 编译后的产物的目录,找到对应的二进制文件 kube-scheduler 即代表成功
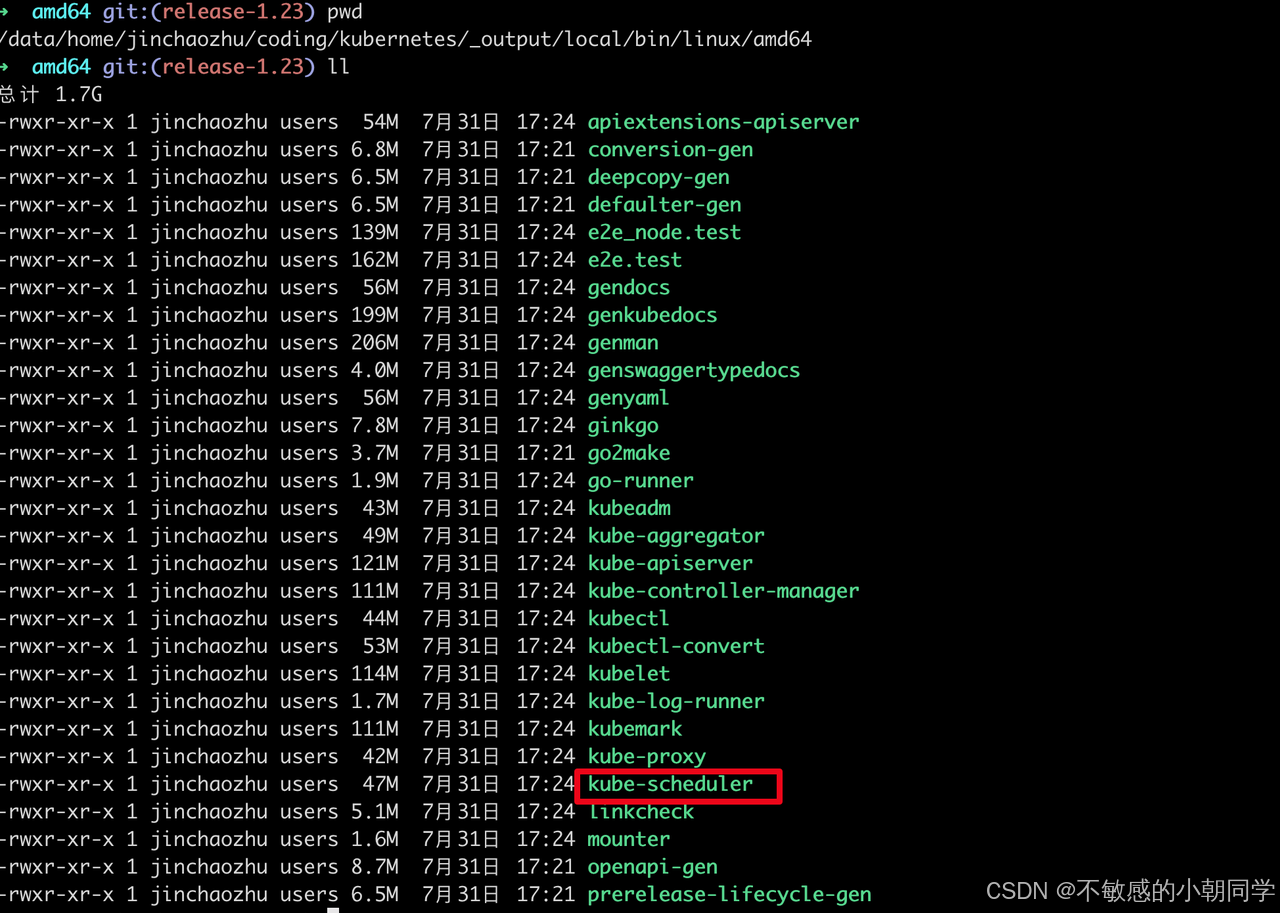
构建镜像
编写DockerFile
DockerFile
FROM busybox
ADD ./_output/local/bin/linux/amd64/kube-scheduler /usr/local/bin/kube-scheduler推送到自己的镜像仓库

查看远程仓库是否有该镜像
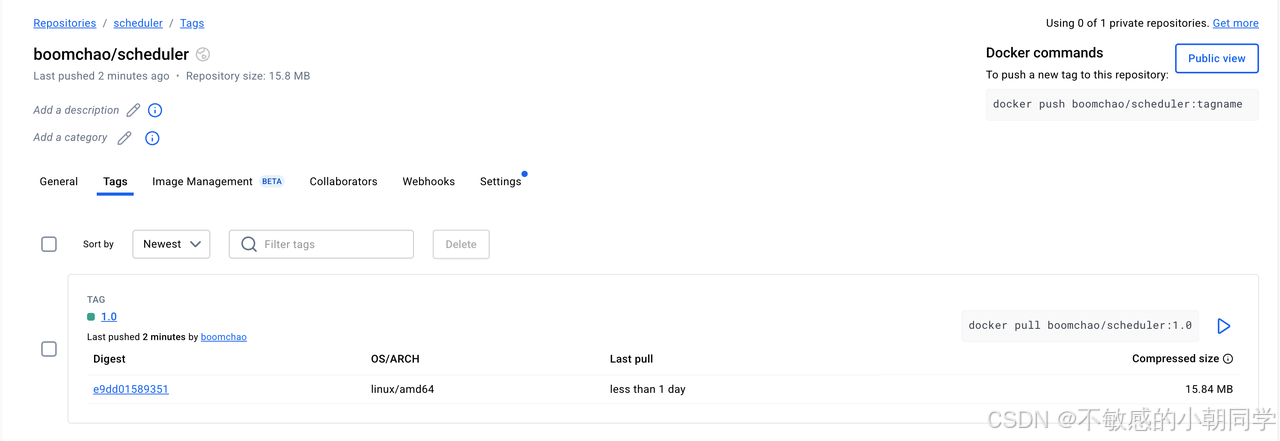
镜像已经上传成功
部署自定义的scheduler
部署自定义的scheduler
yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-kube-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-volume-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:volume-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: my-scheduler-extension-apiserver-authentication-reader
namespace: kube-system
roleRef:
kind: Role
name: extension-apiserver-authentication-reader
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: my-scheduler-config
namespace: kube-system
data:
my-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 1
template:
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: boomchao/scheduler:1.0
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-config注意配置在cm里面的 KubeSchedulerConfiguration 的版本
yaml
apiVersion: kubescheduler.config.k8s.io/v1beta2 # 这里版本需要注意
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler # 我们自定义的scheduler名称
leaderElection:
leaderElect: false 太高的版本可能报错如下

因为我们用的是 release-1.23 版本
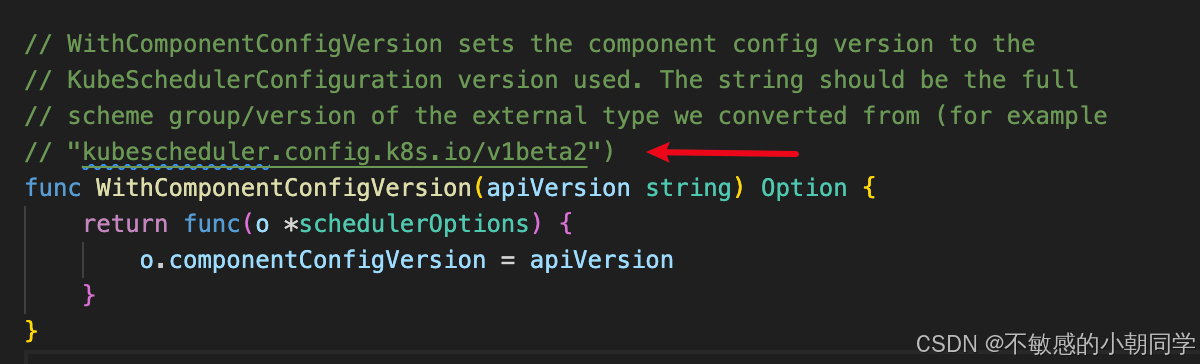
用其他版本 alpha 或者 v1 很可能识别不出来
部署成功后查看日志
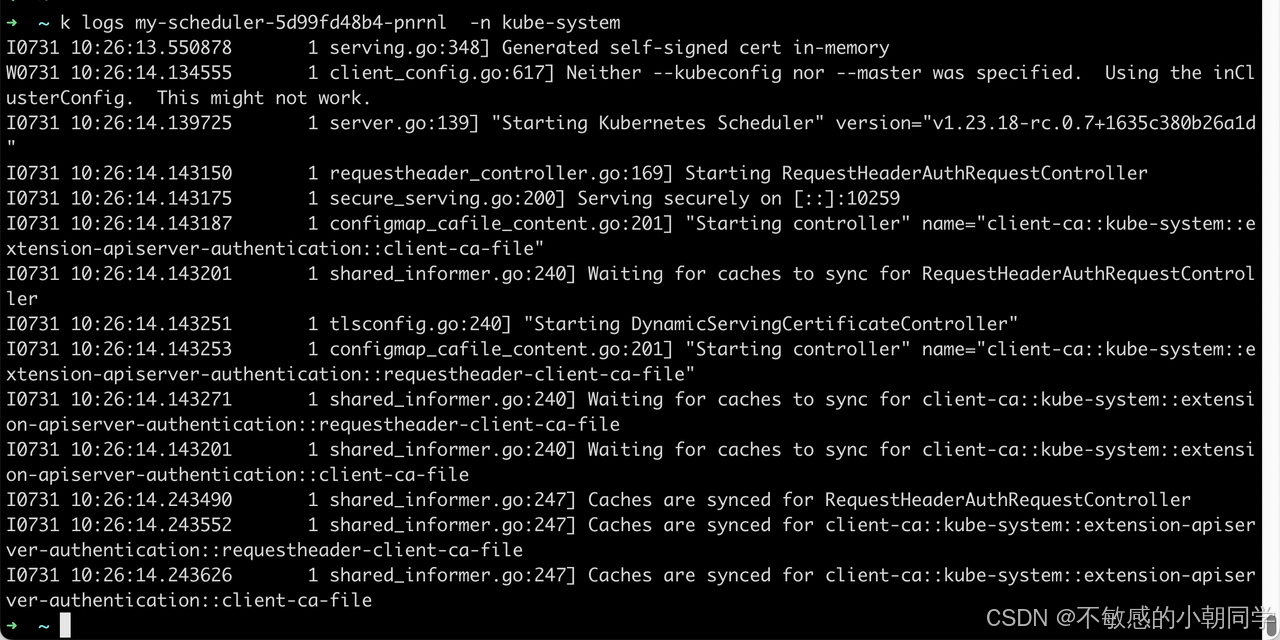
部署成功
尝试部署一个pod使用我们自定义的调度器
yaml
apiVersion: v1
kind: Pod
metadata:
name: annotation-second-scheduler
labels:
name: multischeduler-example
spec:
schedulerName: my-scheduler
containers:
- name: pod-with-second-annotation-container
image: nginx部署成功后查看pod上的对应的调度器的名称,可以看到是我们自定义的 scheduler
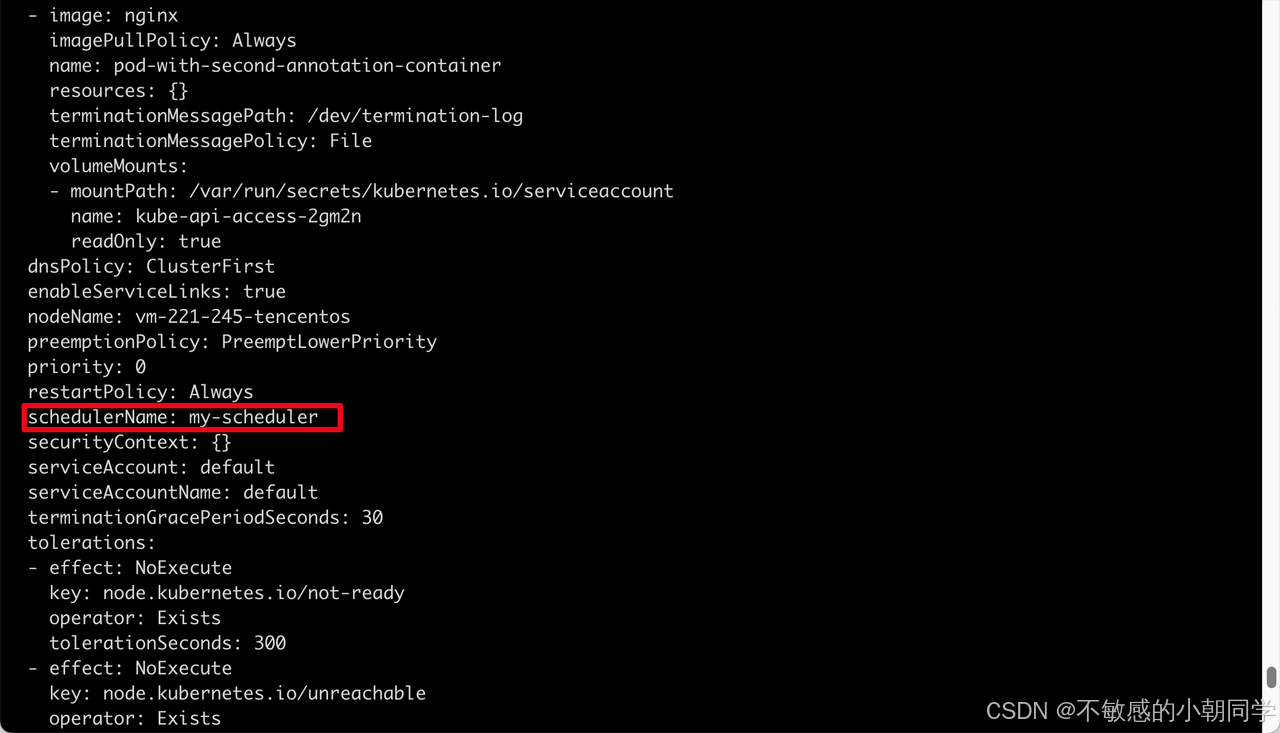
插件解析
基本概念
区分三个概念
-
Profiles:配置的调度策略
-
Extension points:细分的调度策略,比如有
- queueSort:用来对 pending 的 pod(也就是待调度的pod)进行排序
- preFilter:预过滤,用来在过滤之前对集群或者node做提前处理
- filter:过滤,用来筛选出具体的 node 进行 pod 的派发
- postFilter: 后过滤,主要用来应对筛选不成功的情况,也就是没有任何一个 pod 能够匹配上 node
- score:打分,用来对上面筛选出的 node 进行打分,分数最高的 node 将会承担起运行pod的任务
- bind:将 pod 绑定到具体的 node 上
-
plugins:用来实现上面具体的调度策略,每个 plugin 必定属于某一个特定的 Extension-points
注意上面的 Extension points,每个Extension point的特性是不同的,比如
- queueSort 就只支持一个plugin
- filter 就支持多个 plugin 依次执行
- postFilter 只要有一个 plugin 对 pod 执行结果是 schedulable,剩余的插件便不会继续执行
- bind 插件用来将pod与node对应,只要一个bind插件处理了pod,其他多余的bind插件便不会再执行
所有的 Extension points 参考 Scheduler Configuration
插件接口
插件的API接口如下
go
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*PodInfo, *PodInfo) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(CycleState, *v1.Pod) *Status
}所有的插件都需要先定位到具体作用的位置(也就是调度过程中的哪个 extension-point ),比如是在 queueSort 阶段阶段就只需要实现上面的 QueueSortPlugin 接口即可;在 PreFilter 阶段只需要实现 上面的 PreFilterPlugin 接口即可
编写的插件必须统一注册到原始的 Registry 这个 map 里面
go
type PluginFactory = func(runtime.Unknown, FrameworkHandle) (Plugin, error)
type Registry map[string]PluginFactory
func NewRegistry() Registry {
return Registry{
fooplugin.Name: fooplugin.New,
barplugin.Name: barplugin.New,
// New plugins are registered here.
}
}实际编写自定义插件的时候,只需要在启动参数指定即可,指定了之后便会自动注册到这个map里面,比如
go
import (
scheduler "k8s.io/kubernetes/cmd/kube-scheduler/app"
)
func main() {
command := scheduler.NewSchedulerCommand(
scheduler.WithPlugin("example-plugin1", ExamplePlugin1),
scheduler.WithPlugin("example-plugin2", ExamplePlugin2))
if err := command.Execute(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}查看代码 scheduler.WithPlugin,实际调用的还是 Register 方法将其注册到总的map里面

配置文件启用插件
配置文件怎么配置插件开启,每个插件都对应 KubeSchedulerConfiguration 中的一个配置项,对应结构体如下
go
type KubeSchedulerConfiguration struct {
// ... other fields
Plugins Plugins
PluginConfig []PluginConfig
}
type Plugins struct {
QueueSort []Plugin
PreFilter []Plugin
Filter []Plugin
PostFilter []Plugin
PreScore []Plugin
Score []Plugin
Reserve []Plugin
Permit []Plugin
PreBind []Plugin
Bind []Plugin
PostBind []Plugin
}
type Plugin struct {
Name string
Weight int // Only valid for Score plugins
}
type PluginConfig struct {
Name string
Args runtime.Unknown
}特别要注意上面的 Plugin.Weight 字段,这个字段只有 score 插件才会有这个分数
默认开启的一些插件
QueueSort
go
// Less is the function used by the activeQ heap algorithm to sort pods.
// It sorts pods based on their priority. When priorities are equal, it uses
// PodQueueInfo.timestamp.
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}可以看到 queuSort 的实现是先比较优先级,优先级高的先调度;否则优先级一样则按照时间顺序来进行的,默认越早创建的pod越早进行调度
Filter
NodeName 插件实现了 Filter
go
// Filter invoked at the filter extension point.
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo.Node() == nil {
return framework.NewStatus(framework.Error, "node not found")
}
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}比较 pod 的名字是否和 node 的名字相同
Score
ScorePlugin 我们仔细看其实现的接口
go
type ScorePlugin interface {
Plugin
// Score is called on each filtered node. It must return success and an integer
// indicating the rank of the node. All scoring plugins must return success or
// the pod will be rejected.
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
// ScoreExtensions returns a ScoreExtensions interface if it implements one, or nil if does not.
ScoreExtensions() ScoreExtensions
}
// ScoreExtensions is an interface for Score extended functionality.
type ScoreExtensions interface {
// NormalizeScore is called for all node scores produced by the same plugin's "Score"
// method. A successful run of NormalizeScore will update the scores list and return
// a success status.
NormalizeScore(ctx context.Context, state *CycleState, p *v1.Pod, scores NodeScoreList) *Status
}Score 方法用来衡量指标具体的维度值,而 NormalizeScore 方法用来返回维度值具体的分数(1-100)
我们看一个具体的实现
go
// Score invoked at the Score extension point.
// The "score" returned in this function is the matching number of pods on the `nodeName`,
// it is normalized later.
func (pl *SelectorSpread) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
.......
// 获取节点信息
nodeInfo, err := pl.sharedLister.NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
// 返回节点上的pod的数量
count := countMatchingPods(pod.Namespace, s.selector, nodeInfo)
return int64(count), nil
}
// NormalizeScore invoked after scoring all nodes.
// For this plugin, it calculates the score of each node
// based on the number of existing matching pods on the node
// where zone information is included on the nodes, it favors nodes
// in zones with fewer existing matching pods.
func (pl *SelectorSpread) NormalizeScore(ctx context.Context, state *framework.CycleState, pod *v1.Pod, scores framework.NodeScoreList) *framework.Status {
if skipSelectorSpread(pod) {
return nil
}
countsByZone := make(map[string]int64, 10)
maxCountByZone := int64(0)
maxCountByNodeName := int64(0)
// 按照节点的地域来进行分数的区分;更新每个区域的pod的数量
for i := range scores {
if scores[i].Score > maxCountByNodeName {
maxCountByNodeName = scores[i].Score
}
nodeInfo, err := pl.sharedLister.NodeInfos().Get(scores[i].Name)
if err != nil {
return framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", scores[i].Name, err))
}
zoneID := utilnode.GetZoneKey(nodeInfo.Node())
if zoneID == "" {
continue
}
countsByZone[zoneID] += scores[i].Score
}
for zoneID := range countsByZone {
if countsByZone[zoneID] > maxCountByZone {
maxCountByZone = countsByZone[zoneID]
}
}
haveZones := len(countsByZone) != 0
maxCountByNodeNameFloat64 := float64(maxCountByNodeName)
maxCountByZoneFloat64 := float64(maxCountByZone)
MaxNodeScoreFloat64 := float64(framework.MaxNodeScore)
// 计算最终的分数
// 1. 先对分数进行规范化
// 2. 计算每个节点的最终分数,考虑到节点的Pod数量和节点所属区域内的pod总数量
// 3. 二次平衡节点分数和区域分数
for i := range scores {
// initializing to the default/max node score of maxPriority
fScore := MaxNodeScoreFloat64
if maxCountByNodeName > 0 {
fScore = MaxNodeScoreFloat64 * (float64(maxCountByNodeName-scores[i].Score) / maxCountByNodeNameFloat64)
}
// If there is zone information present, incorporate it
if haveZones {
nodeInfo, err := pl.sharedLister.NodeInfos().Get(scores[i].Name)
if err != nil {
return framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", scores[i].Name, err))
}
zoneID := utilnode.GetZoneKey(nodeInfo.Node())
if zoneID != "" {
zoneScore := MaxNodeScoreFloat64
if maxCountByZone > 0 {
zoneScore = MaxNodeScoreFloat64 * (float64(maxCountByZone-countsByZone[zoneID]) / maxCountByZoneFloat64)
}
fScore = (fScore * (1.0 - zoneWeighting)) + (zoneWeighting * zoneScore)
}
}
scores[i].Score = int64(fScore)
}
return nil
}zoneWeight 的值为 2/3,也即代表着节点所属区域分数权重占比2/3,节点本身pod数量的分数权重占比 1/3
Bind
对应代码如下
go
// New creates a DefaultBinder.
func New(_ runtime.Object, handle framework.Handle) (framework.Plugin, error) {
return &DefaultBinder{handle: handle}, nil
}
// Bind binds pods to nodes using the k8s client.
func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
klog.V(3).InfoS("Attempting to bind pod to node", "pod", klog.KObj(p), "node", nodeName)
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
}
err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})
if err != nil {
return framework.AsStatus(err)
}
return nil
}
// Handle provides data and some tools that plugins can use. It is
// passed to the plugin factories at the time of plugin initialization. Plugins
// must store and use this handle to call framework functions.
type Handle interface {
....
// IterateOverWaitingPods acquires a read lock and iterates over the WaitingPods map.
IterateOverWaitingPods(callback func(WaitingPod))
// GetWaitingPod returns a waiting pod given its UID.
GetWaitingPod(uid types.UID) WaitingPod
// RejectWaitingPod rejects a waiting pod given its UID.
// The return value indicates if the pod is waiting or not.
RejectWaitingPod(uid types.UID) bool
// ClientSet returns a kubernetes clientSet.
ClientSet() clientset.Interface
// KubeConfig returns the raw kube config.
KubeConfig() *restclient.Config
// EventRecorder returns an event recorder.
EventRecorder() events.EventRecorder
SharedInformerFactory() informers.SharedInformerFactory
....
}代码也很直观,选择好node之后,将这个pod 的 NodeName 字段与传入的参数做绑定
这里我们注意一个参数就是 state *framework.CycleState 另外一个就是构造参数传入的 framework.Handle
CyCleState 其实就是为当前的scheduling context提供一个上下文,因为binding cycles是可以并行执行的,插件可以通过这个参数来区分是否在处理正确的请求;其次是可以通过这个变量在不同的 extension-point 之间传递一些必要的信息,类似于golang直接上下文传递的 context.WithValue
framework.Handle 的主要作用就是里面提供了访问k8s的API,比如 clientset,informer,以及提供接口用于 approve/deny pending 的 pod
一次完整的Scheduling-context流程
查看 scheduler 的方法
go
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}可以看到整体调用流程就是启动一个队列,然后循环执行 schedule 过程,一直等待 ctx 结束然后关闭队列 这三个步骤即可
Kube-scheduler 整个调度流程大概如下
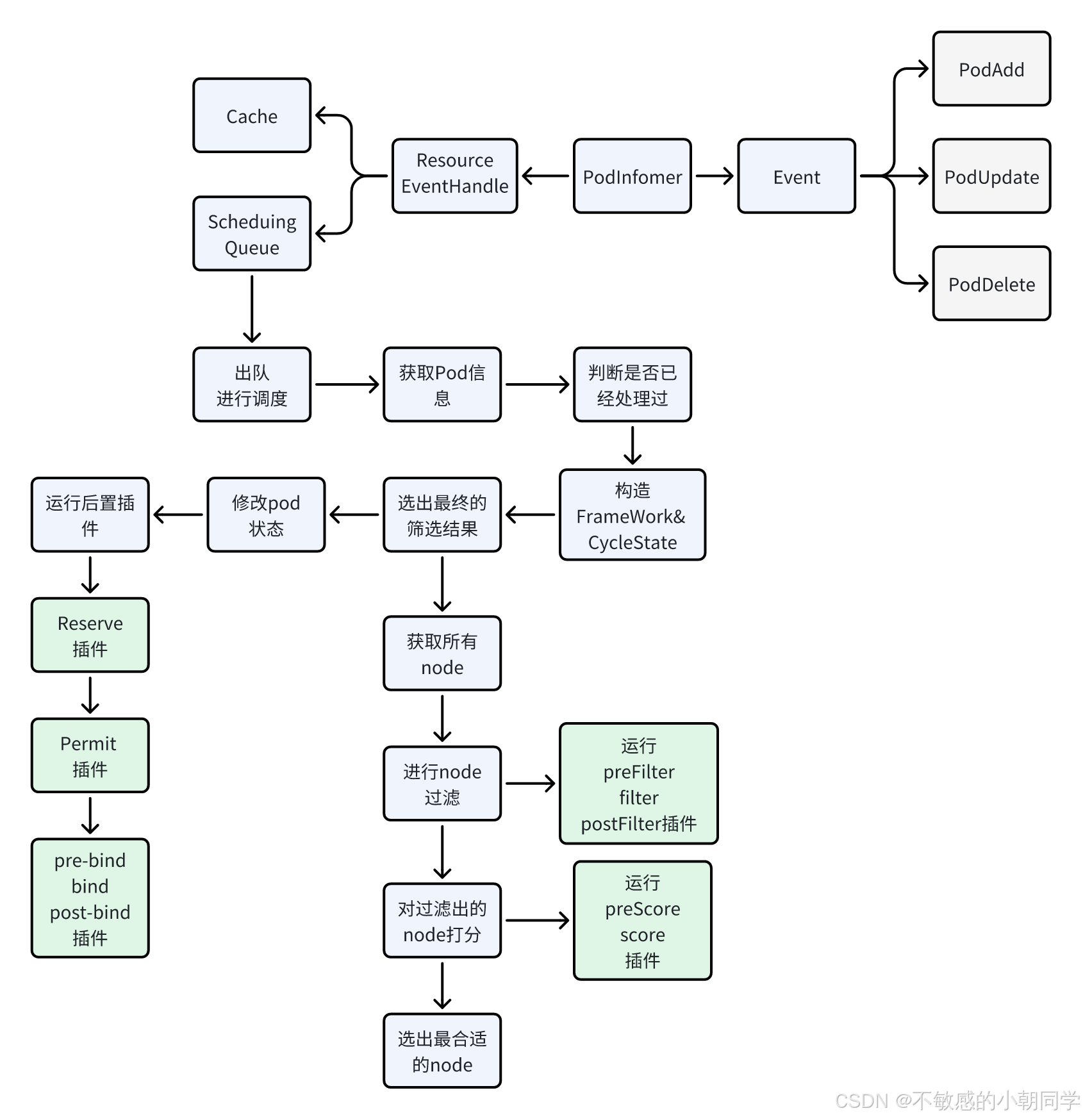
启动队列
- 定义一个优先队列
- 从 informer 里面获取相关的 pod 事件
- 塞入队列
- 供下游 scheduler 处理
源码分析
go
// Profiles are required to have equivalent queue sort plugins.
lessFn := profiles[c.profiles[0].SchedulerName].QueueSortFunc()
podQueue := internalqueue.NewSchedulingQueue(
lessFn,
c.informerFactory,
.......
)可以看到定义的 QueueSort 插件主要是用在了这个队列上
Scheduler 会启动一个 pod 的 Informer 然后触发 eventHandler 之后就会入队
go
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
gvkMap map[framework.GVK]framework.ActionType,
) {
// scheduled pod cache
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
.....
},
// 这里添加到scheduler的缓存中
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
)
// unscheduled pod queue
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
......
},
// 这里添加到scheduler的队列中
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
)
.....
}开启调度流程
-
获取待调度的 pod
-
判断该pod是否是被删除的或者是AssumePod
-
为每个 pod 构造 Framework 以及 CycleState
-
进行节点的筛选获取最终的结果(也就是这个pod应该调度到具体哪个 node 上)
-
找到所有可行的node
- 运行 preFilter, filter,postFilter 等插件
-
对上面的Node进行打分
- 运行 preScore, score 等插件
-
按照分数选中最合适的node
-
-
修改 pod 的状态为 Assume,表示已经执行过 score 阶段了,避免被二次操作
-
运行后置插件
- 运行 reserve 插件
- 运行 permit 插件
- 异步执行绑定插件,执行 prebind、bind、postBind 等插件
具体是怎么应用插件的呢,我们来以一个 filter 插件来进行举例
go
// 主方法执行
feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, extenders, fwk, state, pod)
func (g *genericScheduler) findNodesThatFitPod(ctx context.Context, extenders []framework.Extender, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
...
// 获取所有的node信息
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
.......
// 挑选合适的node
feasibleNodes, err := g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)
if err != nil {
return nil, diagnosis, err
}
feasibleNodes, err = findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}仔细查看 findNodesThatPassFilters 代码
go
func (g *genericScheduler) findNodesThatPassFilters(
........
nodes []*framework.NodeInfo) ([]*v1.Node, error) {
numNodesToFind := g.numFeasibleNodesToFind(int32(len(nodes)))
// Create feasible list with enough space to avoid growing it
// and allow assigning.
feasibleNodes := make([]*v1.Node, numNodesToFind)
....
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
nodeInfo := nodes[(g.nextStartNodeIndex+i)%len(nodes)]
// 运行所有的过滤插件,这里会记录状态
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == framework.Error {
errCh.SendErrorWithCancel(status.AsError(), cancel)
return
}
// 如果运行成功才会把结果记录到下面的两个变量
// 一个是可用的node数量加1
// 一个是添加到可用的nodeSlice中
if status.IsSuccess() {
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo.Node()
}
} else {
....
}
}
.........
feasibleNodes = feasibleNodes[:feasibleNodesLen]
if err := errCh.ReceiveError(); err != nil {
statusCode = framework.Error
return nil, err
}
return feasibleNodes, nil
}参考文档
https://kubernetes.io/docs/tasks/extend-kubernetes/configure-multiple-schedulers/
https://v1-29.docs.kubernetes.io/docs/reference/scheduling/config/#multiple-profiles