目录
[一. 主从复制存在的问题](#一. 主从复制存在的问题)
[二. 主节点发生故障时的手动处理流程](#二. 主节点发生故障时的手动处理流程)
[三. Redis Sentinel (哨兵)](#三. Redis Sentinel (哨兵))
[3.2.关于 Sentinel 节点数量的重要考量](#3.2.关于 Sentinel 节点数量的重要考量)
[2.1. 安装Docker](#2.1. 安装Docker)
[2.5.使用 Docker Compose 进行容器编排](#2.5.使用 Docker Compose 进行容器编排)
[五. 主从切换的具体流程](#五. 主从切换的具体流程)
5.1.主观下线 (Subjective Down, SDown)
[5.2. 客观下线 (Objective Down, ODown)](#5.2. 客观下线 (Objective Down, ODown))
[5.3. 选举哨兵 Leader (Leader Sentinel Election)](#5.3. 选举哨兵 Leader (Leader Sentinel Election))
[5.4. Leader Sentinel 挑选新 Master](#5.4. Leader Sentinel 挑选新 Master)
在本篇文章里面,如果出现下面这些名称,就默认是表格中对应的描述
| 名词 | 描述 |
|---|---|
| 主节点 | Redis 主服务,负责处理写请求和数据同步。 |
| 从节点 | Redis 从服务,负责复制主节点数据并提供读服务。 |
| Redis 数据节点 | 主节点和从节点的统称,构成数据存储的核心部分。 |
| 主从节点 | 主节点与从节点的逻辑组合,形成数据复制和读写分离的架构。 |
| 哨兵节点 | 监控 Redis 数据节点的节点,负责故障检测和自动切换。 |
| 哨兵节点集合 | 若干哨兵节点的抽象组合,共同维护 Redis 高可用性。 |
| Redis 哨兵(Sentinel) | 若干 redis-sentinel 进程的集合,是 Redis 提供的高可用方案。 |
| 应用方 | 哨兵节点集合和 Redis 主从节点的使用者,泛指一个或多个客户端。 |
一. 主从复制存在的问题
Redis 的主从复制模式是其核心功能之一,它允许将主节点(Master)上的数据变更异步地同步到一个或多个从节点(Slave)。这种机制使得从节点能够发挥两个关键作用:
-
数据备份与故障恢复:从节点作为主节点数据的实时副本。当主节点发生故障变得不可用时,从节点可以作为数据的后备存储"顶"上来,最大程度地保证数据不丢失(虽然主从复制本质上是最终一致性模型)。这为系统提供了基础的数据冗余能力。
-
读写分离与读负载分担:主节点通常专注于处理写操作,而所有的读请求可以被负载均衡到各个从节点上执行。这有效地分散了主节点的读压力,显著提升了系统的整体读吞吐量和并发处理能力。
然而,主从复制模式并非万能,它自身也遗留了几个关键问题:
-
故障切换自动化程度低(高可用性问题) :当主节点真正发生故障时,识别故障、选举新的主节点、并将应用流量切换到新主节点的整个过程通常**需要人工干预。**这种复杂且依赖人工的操作导致故障恢复时间(RTO)难以得到有效保障,系统的高可用性存在短板。
-
写压力与存储瓶颈无法分散(存储与性能限制问题):主从复制成功地将读压力分散到从节点,但所有的写操作仍然必须由单一的主节点处理。同时,整个数据集也完全存储在单个主节点上。这意味着主节点在写吞吐量和存储容量方面依然受到单机物理资源的严格限制,无法通过增加从节点来水平扩展写能力或存储空间。
针对第一个问题(高可用性 ),Redis 提供了 哨兵(Sentinel) 机制来解决。哨兵通过监控主从节点状态、自动检测故障、执行主节点选举和故障转移,实现了主从切换的自动化,大幅提升了系统的可用性。
针对第二个问题(写扩展与存储分布式 ),则需要使用 Redis 集群(Cluster) 方案。Redis 集群通过将数据分片(Sharding)存储在多个主节点上,并辅以主从复制,实现了数据的分布式存储、写请求的分担以及存储容量的水平扩展,从而突破了单机资源的限制。
在本文中,我们着重讲解哨兵这个机制,至于Redis集群,我会在后续文章进行讲解。
二. 主节点发生故障时的手动处理流程
2.1.人工处理的流程
在介绍哨兵之前,我们就先讲讲主节点发生故障时的一般处理方法------人工处理
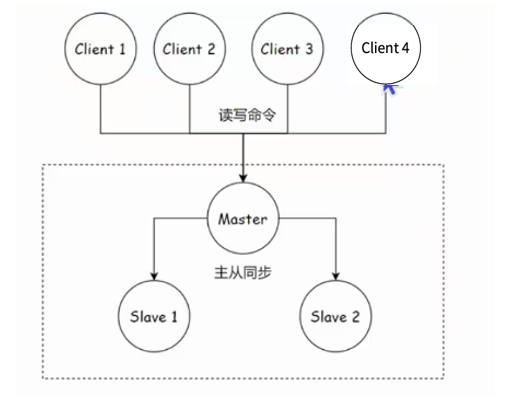
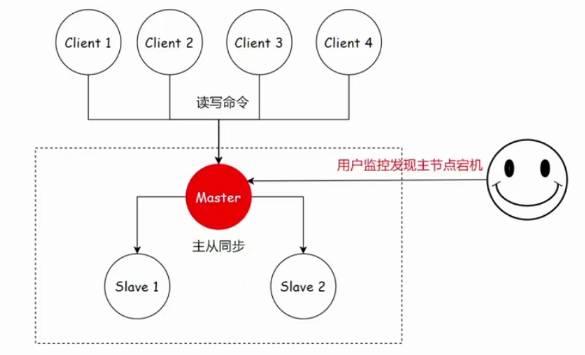
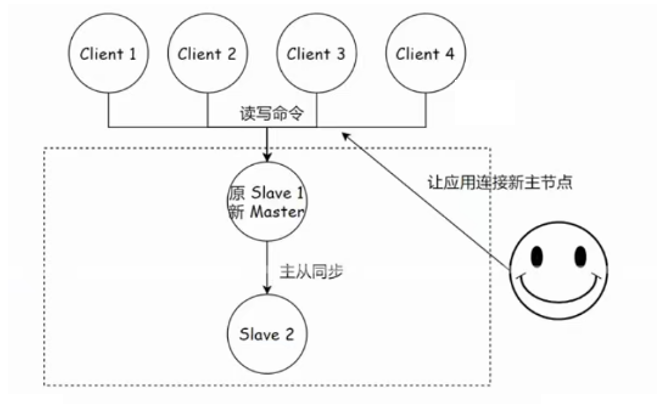
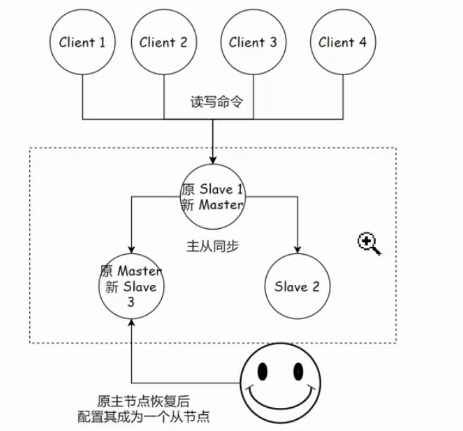
在 Redis 主从复制模式下,一旦主节点发生故障,后续的故障恢复过程高度依赖人工操作,步骤相对繁琐且容易出错。下图大致展示了人工恢复的关键步骤:
-
故障发现与确认:运维团队通过监控系统(如告警、指标异常)检测到主节点发生故障或不可用,确认需要进行主备切换。
-
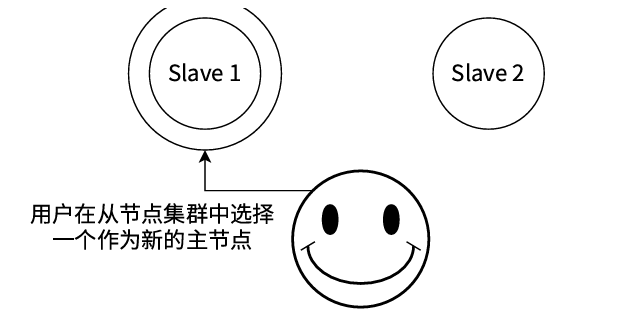
选举并提升新主节点 :运维人员从存活的从节点中选择一个数据相对完整、状态良好的节点(例如图中选择的
slave1),在该节点上执行 SLAVEOF NO ONE 命令,将其提升为新的主节点 (newMaster)。 -
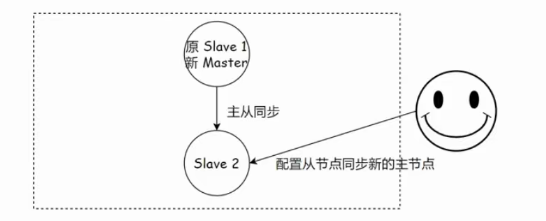
重定向其他从节点 :运维人员登录到剩余的从节点(例如图中的
slave2),逐一执行 SLAVEOF {newMasterIp} {newMasterPort} 命令 ,将它们重新配置为从新的主节点 (newMaster) 进行数据同步。 -
更新客户端配置 :运维人员需要修改所有应用程序客户端的连接配置,将其指向新主节点 (
newMaster) 的 IP 地址 ({newMasterIp}) 和端口 ({newMasterPort}),以确保后续读写请求发送到正确节点。这通常涉及修改配置文件、发布配置更新或重启应用。 -
处理旧主节点(可选) :如果故障的旧主节点后续恢复服务,运维人员需要在其上执行
SLAVEOF {newMasterIp} {newMasterPort}命令,将其降级并配置为从属于新的主节点 (newMaster),重新加入复制集群。
2.2.人工恢复的挑战与局限性
先看看这些最表象的
-
操作繁琐耗时:整个过程涉及多个手动命令执行、节点状态检查、配置更新等步骤,耗时较长。
-
故障恢复时间 (RTO) 不可控:恢复速度完全依赖于运维人员的响应速度、操作熟练度和问题复杂度,难以保证服务中断时间在可接受范围内。
-
操作风险高:人工操作极易出错(如选错新主节点、配置命令输入错误、遗漏更新某些客户端等),可能导致数据不一致、服务中断时间延长甚至二次故障。
-
缺乏自动化决策:如何选择最优的新主节点(如考虑复制偏移量最大)、如何处理旧主节点恢复时的数据冲突等,都需要人工判断和干预。
-
监控依赖性强:整个流程的启动严重依赖于监控系统及时准确地发现故障。
只要是涉及到人工干预, 不说繁琐, 至少很烦人~~
另外, 这个操作过程如果出错了咋办?? 可能会导致问题更加严重~~
通过人工干预的做法, 就算程序猿第一时间看到了报警信息, 第一时间处理~~
恢复的过程, 也需要 半个小时, 以上~~
这半个小时里, 整个 redis 就一直不能写???? 显然是不合适的~
手工去恢复,完全不是一个好方案。
事实上,在实际的后端服务器开发中,监控程序扮演着至关重要的角色!
服务器系统通常被要求具备极高的可用性,必须能够 7x24 小时不间断地稳定运行。然而,现实是服务器在长期运行过程中,难免会遇到各种意料之外的"状况"------可能是硬件故障、软件崩溃、资源耗尽,或是突发的流量洪峰。这些问题的发生往往难以预测,我们无法确切知道"意外"会在何时降临。
显然,完全依赖人工值守来时刻关注服务器运行状态是不切实际的,也是低效的。因此,我们需要编写专门的监控程序,让程序自动地、持续地"盯住"服务器的运行脉搏。
监控程序的核心作用在于实时探测服务器的健康状态和关键性能指标 (如CPU、内存、磁盘、网络、服务响应时间与错误率等)。一旦它检测到任何异常或超过预设的阈值(例如服务无响应、错误率飙升、资源严重不足),就意味着服务器可能出现了故障或性能严重下降。
此时,监控程序的价值不仅在于发现问题,更在于触发及时的警报 。它会立即联动"报警程序",通过多种渠道(如短信、电话、邮件、微信、钉钉、飞书等)将告警信息推送出去。这些警报会清晰地通知到负责的程序员:"服务器XXX出现严重问题,请立即处理!"
在互联网公司,尤其是大型企业,对此有着严格的要求:程序员必须保持手机24小时开机,并随时准备响应告警 。这种"随时待命"的状态是保障服务可用性的关键一环。需要特别注意的是,告警信息往往不仅仅是发送给直接负责人的 。为了确保问题能被足够重视并快速解决,告警通常会同步或升级发送给责任人的直属领导,甚至在必要时发送给更高层级的管理者。
在这种机制下,关键时刻的响应速度至关重要 。如果因为错过告警电话或未能及时处理问题而导致服务长时间中断或产生重大影响(即"掉链子"),这不仅会影响业务,更会直接影响个人评价。领导层会对此形成负面的看法,而错失关键响应时机,很可能让期待中的升职加薪机会不得不"往后稍稍"了。因此,构建可靠、及时的监控与报警体系,并确保团队能有效响应,是保障服务稳定和个人职业发展的双重基石。
而哨兵,就是一种监控程序。
三. Redis Sentinel (哨兵)
3.1.哨兵架构
当 Redis 主节点发生故障时,Redis Sentinel 架构能够自动完成故障检测、故障转移决策与执行,并实时通知客户端应用程序 。这套机制极大地减少了人工干预的需求,是构建 真正高可用性(High Availability, HA) Redis 服务的核心组件。
架构概览
Redis Sentinel 本身是一个分布式系统 ,由多个独立的 Sentinel 进程(节点) 组成。这些 Sentinel 节点共同协作,负责监控一组 Redis 数据节点(包含一个主节点和其关联的从节点)。
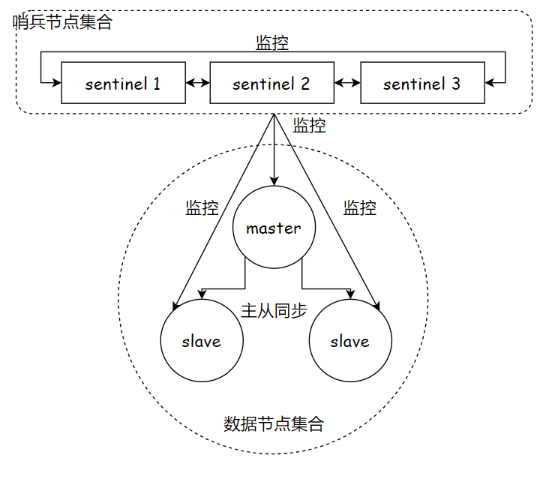
核心功能与工作原理
-
持续监控 (Monitoring)
-
Sentinel 节点之间 以及 Sentinel 节点与 Redis 数据节点之间 ,会建立 TCP 长连接。
-
通过这些长连接,Sentinel 节点会定期向所有被监控的 Redis 主节点、从节点以及其他 Sentinel 节点发送心跳探测(PING)。
-
监控的目标是及时发现任何节点(尤其是主节点)的不可用状态。
-
-
故障检测与共识达成
-
主观下线 (SDOWN - Subjectively Down) :当某个 Sentinel 节点在预设的超时时间内 未能收到某个 Redis 数据节点(主节点和从节点)的有效响应(PONG),它会在本地将该节点标记为"主观下线"。这表示该 Sentinel 节点个人认为目标节点故障。
-
客观下线 (ODOWN - Objectively Down) :仅凭一个 Sentinel 的主观判断是不够的,主要是为了防止网络瞬时抖动或单个 Sentinel 节点自身问题导致的误判 。发现主节点主观下线的 Sentinel 会向 Sentinel 集群中的其他节点发起询问。
-
只有当超过预设的法定人数(Quorum,通常配置为 Sentinel 节点总数的半数以上) 的 Sentinel 节点都同意主节点不可达时,Sentinel 集群才会达成共识,将主节点标记为"客观下线 "。这确保了故障判断的可靠性与准确性。
-
-
领导者 Sentinel选举 (Leader Election)
-
一旦主节点被确认为客观下线 (ODOWN) ,Sentinel 集群会自动触发一个领导者 Sentinel选举流程。
-
多个 Sentinel 节点会基于分布式共识算法(通常是 Raft 协议的变种)进行协商 ,选举出一个领导者 Sentinel (Leader Sentinel) 。这个领导者 Sentinel 将全权负责协调和执行后续的故障转移操作。
-
-
自动故障转移 (Automatic Failover)
-
由选举产生的领导者 Sentinel 负责执行以下关键步骤:
-
选举新主节点 :领导者 Sentinel 会从当前存活的、状态良好的从节点池中 ,根据预设的规则(如节点优先级、复制偏移量最大、Run ID 最小等),自动评估并选择出一个最优的从节点作为新的主节点候选者。
-
提升新主节点 :领导者 Sentinel 会命令 被选中的从节点执行
SLAVEOF NO ONE命令,将其提升为新的主节点 (new Master)。 -
重配置其他从节点 :领导者 Sentinel 会命令 所有其他存活的从节点执行
SLAVEOF {newMasterIP} {newMasterPort}命令,将它们重新配置为从属于新的主节点,开始从新主节点同步数据。 -
处理旧主节点 :如果故障的旧主节点后续恢复在线,领导者 Sentinel 会自动将其重新配置为从节点 ,执行
SLAVEOF {newMasterIP} {newMasterPort}命令,使其降级并加入新主节点的复制拓扑。
-
-
通知客户端 (Notification) :这是实现无缝切换的关键环节 。Sentinel 节点(通常是领导者)会通过发布/订阅(Pub/Sub)通道或其他客户端库支持的集成机制 ,实时地向所有连接的 Redis 客户端应用程序广播主节点变更的信息 (即新主节点的地址和端口)。这使得客户端能够自动感知并切换到新的主节点进行后续的读写操作。
-
高可用保障
整个流程------从故障检测、共识确认、领导者选举、新主选举与提升、从节点重配置到客户端通知 ------完全自动化 ,无需人工介入。这显著缩短了故障恢复时间(RTO),最大程度地减少了服务中断,满足了高可用系统的严苛要求。
3.2.关于 Sentinel 节点数量的重要考量
-
单点故障风险 :虽然技术上可以只部署一个 Sentinel 节点 ,但这严重违背了高可用的设计原则:
- 如果这唯一的 Sentinel 节点自身发生故障或不可达 ,那么当 Redis 数据节点(尤其是主节点)真正发生故障时,整个系统将完全丧失自动故障恢复能力,退化为需要人工干预的状态。
-
误判风险增加 :单个 Sentinel 节点更容易受到网络问题(如抖动、延迟、丢包) 的影响。它独自做出的"主观下线"判断缺乏其他节点的验证(无法达成客观下线) ,导致将正常节点误判为故障的概率显著增高,可能引发不必要的故障转移,反而破坏服务稳定性。
-
推荐部署 :因此,在生产环境中,强烈建议部署至少三个(或更多奇数个)Sentinel 节点,并将法定人数(Quorum)配置为超过半数(例如 3 个节点时配置 Quorum=2)。这提供了:
-
Sentinel 自身的容错能力:允许少量 Sentinel 节点故障而不影响集群功能。
-
更高的故障判断可靠性:通过多数共识机制有效抵御网络瞬断造成的误判。
-
真正的自动化高可用:确保在主节点故障时,自动化恢复流程能够可靠触发和执行。
-
四.使用Docker搭建环境
首先我们需要知道,我们要搭建的环境是下面这个
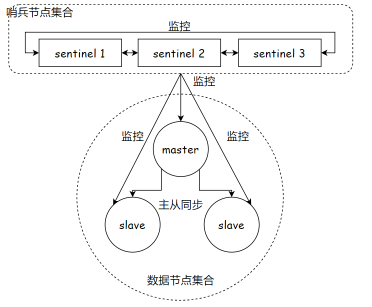
理论上,这6个服务节点应当部署在6台独立的物理或云服务器主机上,以实现真正的分布式架构、资源隔离和高可用性。
然而,在当前实际操作中,我们受限于仅拥有一台云服务器资源 。因此,只能暂时在这单一服务器上完成所有节点的环境搭建和部署 。需要明确指出的是:在实际生产环境中,将所有关键节点集中部署于单台服务器是存在严重风险的! 这种做法缺乏容错能力,一旦该服务器发生故障,将导致所有服务同时中断。我们此刻的选择,完全是资源限制下的权宜之计。
将如此多的节点密集部署在同一台主机上,会带来显著的挑战:
-
资源冲突风险高: 多个节点竞争同一台主机的 CPU、内存、磁盘 I/O 和网络带宽资源,极易因资源不足导致性能瓶颈或相互干扰(即"打架")。
-
配置管理复杂: 各个节点依赖的端口号、配置文件路径、数据存储目录 等资源需要严格区分。手动部署时必须极其谨慎地规划,确保每个节点使用不同的端口、独立的配置和专属的数据存储区域,避免因配置重叠(端口冲突、文件覆盖)引发服务故障。
-
部署流程繁琐且易错: 整个过程类似于手动配置复杂的主从复制架构,步骤繁杂,需要精细化管理。
-
与真实多机部署差异大: 单机环境无法模拟真实的网络拓扑、跨主机通信延迟以及多机部署特有的运维场景(如主机宕机处理),导致本地搭建的环境与实际生产环境存在较大差异,可能掩盖潜在问题。
Docker 容器技术为高效解决上述难题提供了强大支持。
我们可以将传统的虚拟机(Virtual Machine, VM)视为一种解决方案:它通过软件层(Hypervisor)在物理主机上模拟出完整的虚拟硬件环境 ,从而允许在一台物理机上运行多个相互隔离的、拥有各自操作系统的"虚拟电脑"。然而,虚拟机的一个显著缺点是资源开销巨大 :每个 VM 都需要运行一个完整的操作系统内核和用户空间,会消耗大量的 CPU、内存和磁盘空间。这对于我们资源本就有限的云服务器来说,负担过重,难以承受(即"压力山大")。
相比之下,Docker 是一种轻量级的虚拟化技术 。它利用了 Linux 内核的容器化特性(如 cgroups 和 namespaces),能够在操作系统层面创建隔离的运行时环境(容器) 。每个容器共享宿主机的操作系统内核,但拥有独立的文件系统、网络配置和进程空间。这使得 Docker 容器能够提供类似虚拟机的环境隔离效果 ,同时极大地降低了资源消耗(启动更快、占用内存和磁盘空间更少)。即使是配置相对普通的云服务器,也能轻松运行多个 Docker 容器,为每个节点提供独立的运行环境。
正是由于这些显著优势------高效的资源利用、出色的环境隔离、便捷的配置管理和部署一致性 ------Docker 已成为现代后端开发和运维领域中极其流行且不可或缺的核心技术组件。它完美契合了我们当前在单台服务器上模拟多节点部署的需求。
我们会把6个节点全部安装到Docker里面。
2.1. 安装Docker
什么是Docker?什么是镜像?

接下来我将在Ubuntu系统安装Docker
1.确认操作系统
cat /etc/*release*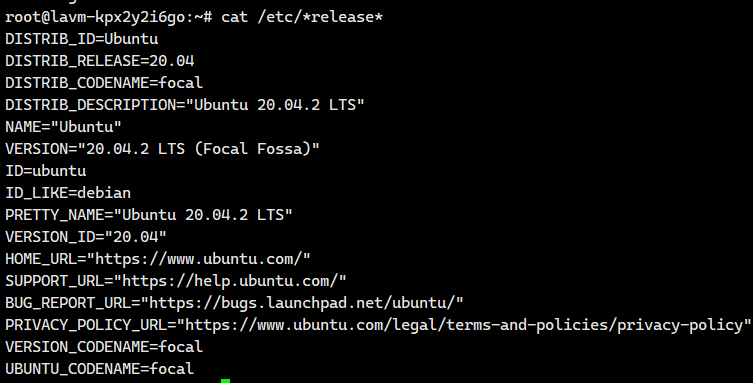
更新 apt 包索引
bash
sudo apt-get update2.添加Docker官方密钥
bash
sudo apt install apt-transport-https ca-certificates curl software-properties-common -y
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -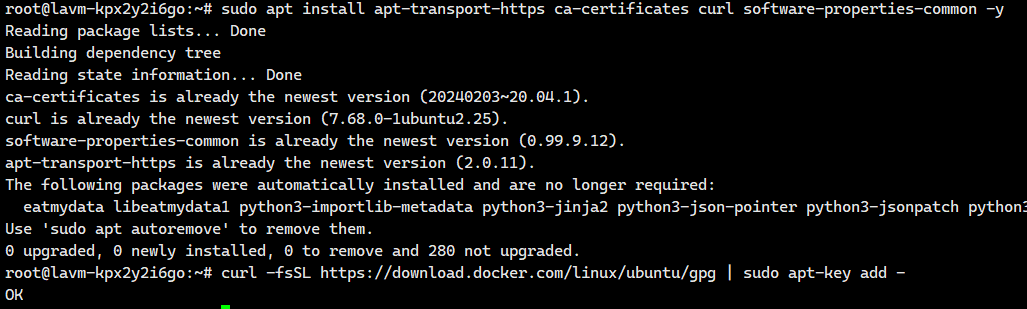 一定需要看到这个OK,才算是添加好了密钥
一定需要看到这个OK,才算是添加好了密钥
3 添加阿里云Docker APT源
bash
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"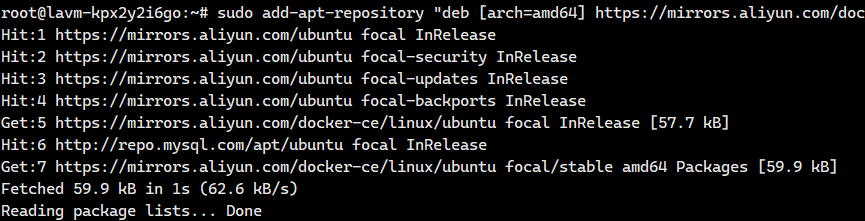
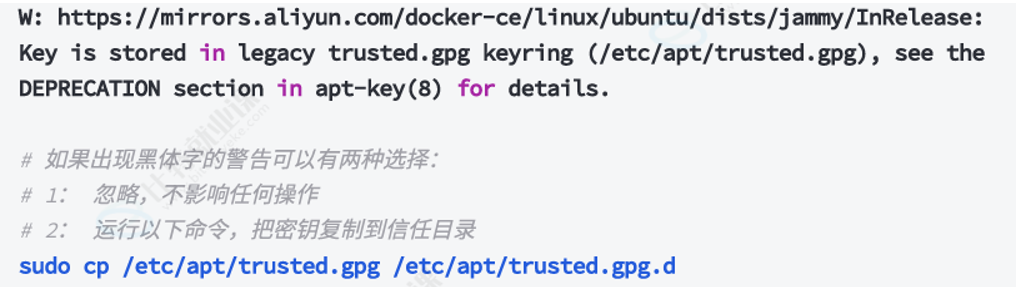
注意:如果出现了下面这种报错,请按照下面这个图这么干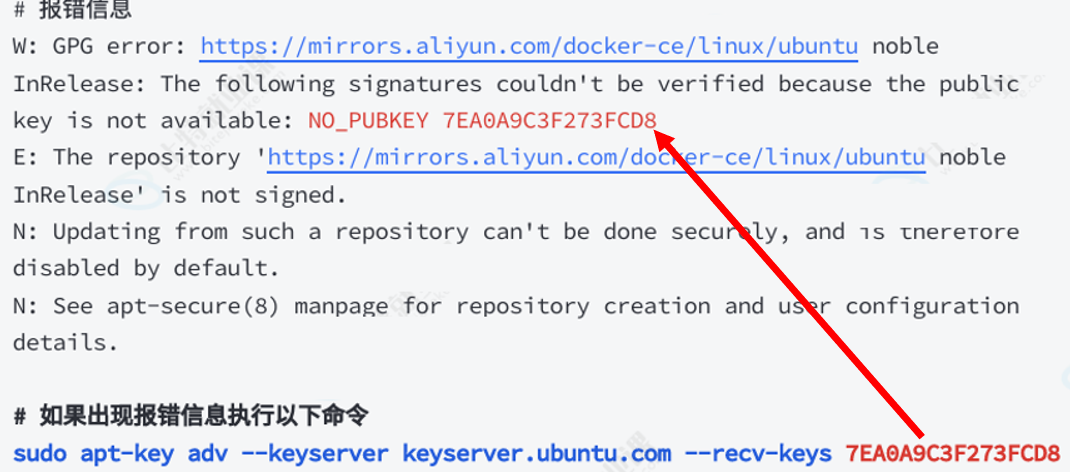
4 更新APT包索引
bash
sudo apt update
注意:
5 安装Docker CE
bash
sudo apt install docker-ce docker-ce-cli containerd.io -y
6 查看Docker服务状态
bash
sudo systemctl status docker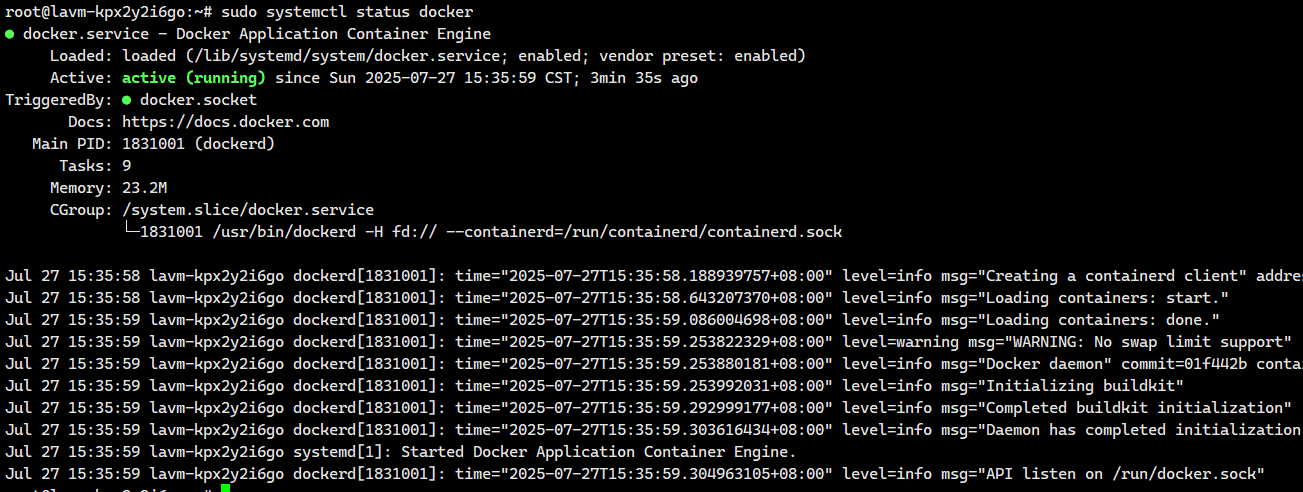 这个就是已经在运行当中了
这个就是已经在运行当中了
如果没有在启动,我们就执行下面这个命令
bash
# 如果Docker未启动则启动Docker服务
sudo systemctl start docker7 查看Docker版本
bash
sudo docker version
8 设置开机自启动
bash
# 设置开机⾃启动
sudo systemctl enable docker
# 查看是否开机启动
sudo systemctl list-unit-files|grep docker.service

9 关闭防火墙
bash
# 停止防火墙
sudo systemctl stop ufw
# 查看防⽕墙
sudo systemctl status ufw
# 禁⽤防⽕墙开机⾃启动
sudo systemctl disable ufw
10 重启、停止和卸载(直接跳过)
bash
# 重启
sudo systemctl restart docker
# 关闭
sudo systemctl stop docker
# 卸载
sudo apt-get purge docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin docker-ce-rootless-extras -y
# 删除两个相关目录
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd11.修改镜像源
注意:我们现在还是不能使用Docker,因为它的镜像源默认是在国外的,我们得修改一下镜像源。
创建或修改 /etc/docker/daemon.json:
bash
vim /etc/docker/daemon.json然后添加下面这个即可
bash
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://dockerhub.timeweb.cloud",
"https://huecker.io"
]
}重启服务:
bash
#重新加载服务配置
sudo systemctl daemon-reload
#重启Docker服务
sudo systemctl restart docker
#验证镜像源配置
docker info
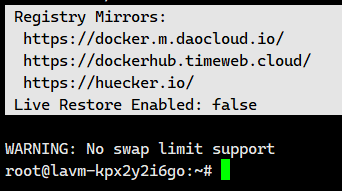
我们这就算是配置好了。
12.Docker常用命令(只是作为参考的)
bash
# ================================
# Docker 容器生命周期管理
# ================================
# 启动已停止运行的容器(容器需已存在)
docker start 容器名
# 重启正在运行的容器(会停止后重新启动)
docker restart 容器名
# 停止运行中的容器(优雅停止,发送SIGTERM信号)
docker stop 容器名
# 修改容器重启策略(容器退出时自动重启)
docker update --restart=always 容器名
# --restart 参数选项说明:
# no - 容器退出时,不重启容器(默认值)
# on-failure - 只有在非0状态退出时才重启容器
# always - 无论退出状态如何,总是重启容器(适合生产环境关键服务)
# ================================
# Docker 镜像管理
# ================================
# 查看本地所有 Docker 镜像(包含镜像ID、仓库、标签、大小等信息)
docker images
# 强制删除一个或多个 Docker 镜像
docker rmi -f [镜像名或镜像ID]
# 示例删除多个镜像:
# docker rmi -f nginx:latest mysql:8.0
# ================================
# Docker 容器管理
# ================================
# 查看正在运行的容器列表(简略信息)
docker ps
# 查看所有容器列表(包含已停止的容器)
docker ps -a
# 仅显示所有容器的ID(常用于批量操作)
docker ps -aq
# 强制删除一个或多个容器
docker rm -f 容器ID/容器名
# 示例删除多个容器:
# docker rm -f container1 container2
# ================================
# 日志与监控
# ================================
# 查看容器的日志输出(默认显示最后日志)
docker logs 容器ID/容器名
# 实时跟踪容器日志(类似 tail -f)
docker logs -f 容器ID/容器名
# 查看容器最近30分钟的日志
docker logs --since 30m 容器ID/容器名
# ================================
# 其他常用命令补充
# ================================
# 进入正在运行的容器(启动交互式终端)
docker exec -it 容器名 /bin/bash
# 查看容器资源使用情况(CPU、内存、网络等)
docker stats 容器名
# 查看容器详细信息(包含配置、网络、挂载等)
docker inspect 容器名
# 将容器保存为新的镜像(持久化修改)
docker commit 容器名 新镜像名:标签2.2.安装docker-compose
apt install docker-compose
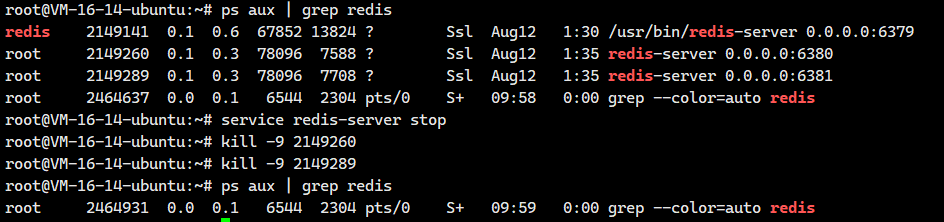
2.3.停止之前的redis服务器
2.4.使用Docker获取到redis的镜像
docker pull redis:5.0.9
Docker 镜像:开箱即用的运行环境
通过 docker pull 获取的镜像,不仅仅是一个应用程序包。它实质上是一个精心构建、自包含的文件系统快照。这个快照里包含了:
-
一个精简的基础操作系统环境: 通常是一个高度优化的 Linux 发行版(如 Alpine, Ubuntu, CentOS 的精简版本),仅包含运行目标软件所必需的核心库和工具,极大地减小了镜像体积。
-
预安装并配置好的软件: 例如,一个
redis镜像就已经在精简的操作系统之上预安装、配置好了 Redis 服务器及其所有依赖项。
从镜像到运行的服务:极致的便捷性
Docker 的强大之处在于,一旦镜像拉取到本地,启动一个可用的服务变得极其简单 。你只需要执行类似 docker run 的命令,基于这个 redis 镜像创建并启动一个容器实例。
-
容器化运行: 该容器在运行时,会利用镜像中的文件系统 ,并拥有独立的进程空间、网络栈等资源(通过 Linux 内核的 Namespaces 和 Cgroups 实现隔离)。
-
服务立即可用: 容器启动后,其中预装的 Redis 服务器随即运行起来 。这意味着,无需在宿主机上进行复杂的手动安装、配置和依赖管理,一个功能完备的 Redis 服务就已经准备就绪并开始监听端口提供服务了。

2.5.使用 Docker Compose 进行容器编排
在本场景中,我们涉及部署一个包含 多个 Redis 服务节点(主/从服务器)和多个 Redis Sentinel(哨兵)节点 的分布式架构。每个 Redis Server 实例和每个 Redis Sentinel 进程都将运行在 各自独立的 Docker 容器 中(总计 6 个容器)。
手动管理和协调这么多相互关联的容器(包括启动顺序、网络连接、配置注入等)会非常复杂且容易出错。这正是 Docker Compose 工具发挥威力的地方。
Docker Compose 的核心在于 "声明式配置" 。我们只需编写一个清晰、结构化的 YAML 格式配置文件(通常是 docker-compose.yml)。在这个文件中,我们可以:
-
明确定义所需的各个服务(Service): 例如,
redis-master,redis-replica1,redis-replica2,sentinel1,sentinel2,sentinel3。 -
详细配置每个服务的参数:
-
指定使用的 Docker 镜像(如
redis:latest,bitnami/redis-sentinel)。 -
设置容器端口映射(将容器内部端口暴露到宿主机)。
-
配置容器间网络(确保它们能相互通信)。
-
挂载数据卷(持久化 Redis 数据)。
-
传递环境变量(用于动态配置,如主节点地址、端口、密码等)。
-
设置资源限制(CPU, 内存)。
-
定义服务间的依赖关系和启动顺序(例如,Sentinel 依赖 Redis 主节点启动)。
-
一键式操作,简化全生命周期管理
一旦这个 docker-compose.yml 配置文件编写完成,后续的操作就变得极其简便:
-
启动整个应用栈: 只需在配置文件所在目录执行
docker-compose up -d命令。Docker Compose 会自动解析配置文件,按需拉取镜像(如果本地没有),然后按定义创建并启动所有指定的容器,并处理好它们之间的网络和依赖关系。 -
停止并清理整个应用栈: 执行
docker-compose down命令,即可停止所有容器并移除由 Compose 创建的网络、卷等资源(根据配置选项决定是否移除卷)。 -
查看状态/日志: 使用
docker-compose ps查看状态,docker-compose logs查看日志。
实际操作
从技术上讲,完全可以将这 6 个容器(3个数据节点 + 3个哨兵节点)的定义都放在同一个 docker-compose.yml 文件中。使用 docker-compose up 命令即可一次性启动所有容器,这非常方便。
但是还是存在一些问题的。
-
潜在的启动顺序问题: 然而,采用这种"一锅端"的启动方式,可能会带来一个 观察上的小麻烦 :由于 Docker Compose 默认会并行启动所有服务(或在资源允许时尽快启动),哨兵节点容器很可能比 Redis 数据节点容器更早启动完成并进入运行状态 。
-
哨兵的监控行为与影响: 哨兵一旦启动,就会立刻尝试去连接并监控其配置文件中指定的主节点。如果此时主节点(或从节点)的容器 仍在启动过程中(尚未准备好接收连接) ,哨兵节点在初始的几次监控检查中 就可能无法连接到主节点 。根据哨兵的工作机制,这可能会触发它 记录"主节点主观下线 (SDOWN)"甚至开始"客观下线 (ODOWN)"的判定流程。
-
对实际功能与观察的影响:
-
对集群功能的影响: 幸运的是,这通常不会对集群的最终稳定状态造成实质性影响。一旦所有 Redis 数据节点最终成功启动并运行,哨兵节点在后续的监控检查中会重新发现健康的主节点,之前产生的"下线"判定会被纠正,集群会进入预期的正常运行模式。哨兵系统本身是设计为容错和最终一致的。
-
对日志观察和体验的影响: 尽管不影响大局,这种 初始阶段的"误报" 会在 哨兵节点的日志中产生相关的错误或警告信息 (如连接失败、主观下线判定等)。这可能会 干扰开发或运维人员对日志的解读,尤其是在初次部署或排查问题时,看到这些初始错误信息容易引起不必要的困惑,需要额外的时间去甄别它们是短暂的启动现象还是真正的持续故障。
-
为了有效解决潜在的服务启动顺序问题,并提升部署过程的可观察性与管理便捷性,我们应采用以下分治策略进行容器规划:
-
独立的数据节点组 (
docker-compose-data.yml):-
将 三个 Redis 数据节点(一个主节点 + 两个从节点) 的所有配置、网络设置、卷定义等,集中定义在一个专用的 Docker Compose YAML 文件中
-
这个文件专注于 Redis 数据服务的部署和管理,确保主从复制关系正确建立,数据持久化配置完备。
-
-
独立的哨兵节点组 (
docker-compose-sentinel.yml):-
将 三个 Redis Sentinel(哨兵)节点 的所有相关配置(如监控目标、判定参数、网络等),完全定义在另一个独立的 Docker Compose YAML 文件中
-
这个文件专注于哨兵监控集群的部署和管理,明确哨兵节点的职责与相互通信。
-
来看看吧
首先,我们先给数据节点容器组创建一个目录------redis-data,给哨兵节点容器组创建一个目录------redis-sentinel
2.5.1.配置数据节点组
接着我们进入redis-data,创建一个docker-compose.yml
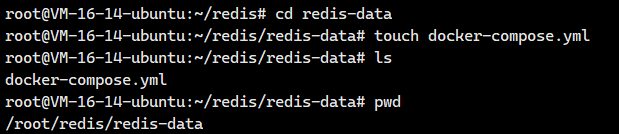
我们把下面的内容粘贴进去。
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379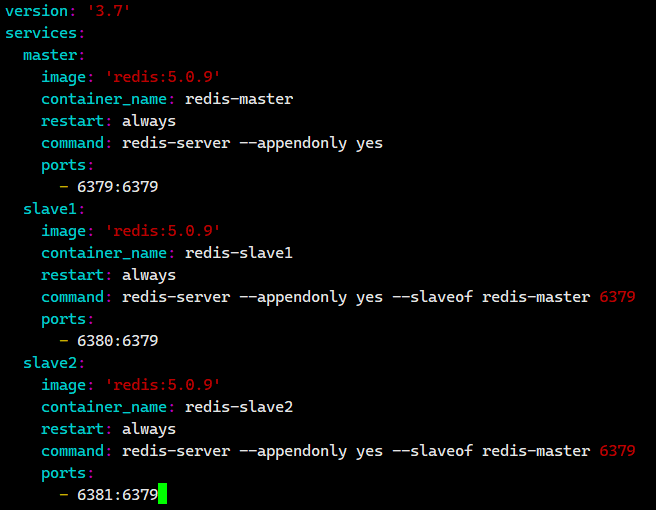
保存退出即可。
接下来我们执行下面这个命令来
docker-compose up -d
注意:
- 如果启动后发现前⾯的配置有误,需要重新操作,使⽤ docker-compose down 即可停⽌并删除 刚才创建好的容器.
- 这里的操作必须保证⼯作⽬录在yml的同级⽬录中,才能⼯作.
我们也可以去查看一下有没有启动成功
docker ps
都成功了。我们再看看端口号的情况
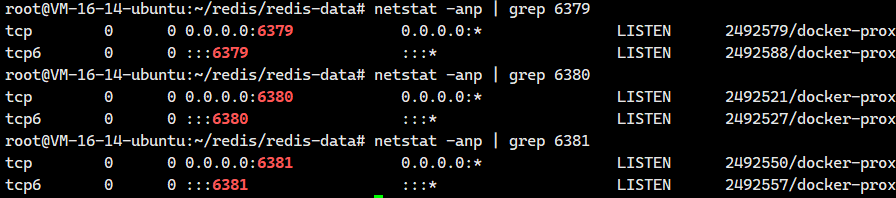
很好,接下来我们可以试着去连接这3个服务器
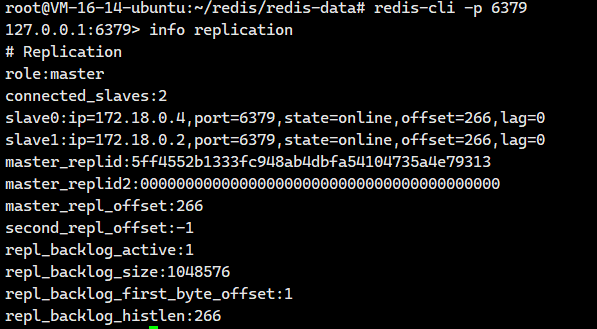
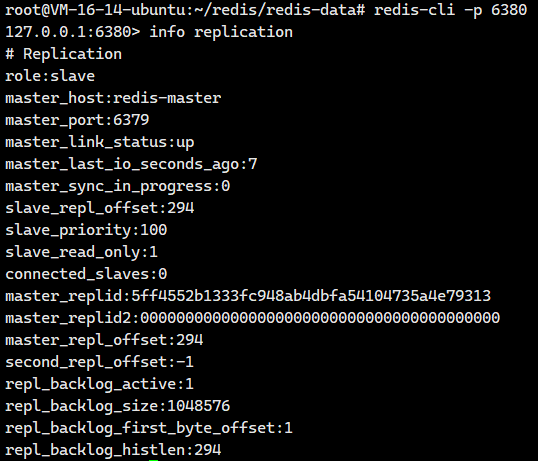
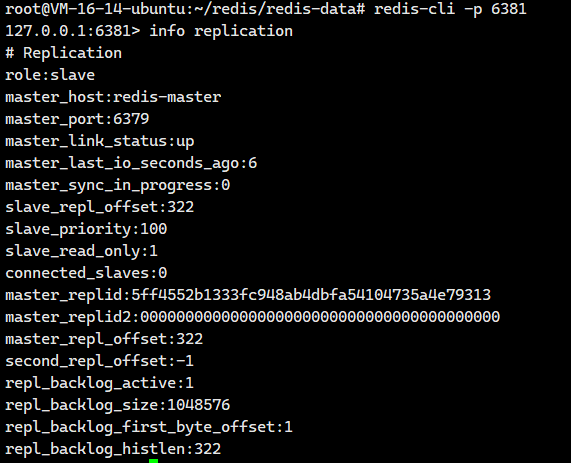
都是没有问题的!!现在数据节点都是没有问题的了
2.5.2.配置哨兵节点组
redis哨兵节点是单独的进程。
也可以把redis-sentinel放到和上⾯的redis的同⼀个yml中进⾏容器编排.此处分成两组,主要是为 了两⽅⾯:
- 观察⽇志⽅便
- 确保redis主从节点启动之后才启动redis-sentinel.如果先启动redis-sentinel的话,可能触发额 外的选举过程,混淆视听.(不是说先启动哨兵不⾏,⽽是观察的结果可能存在⼀定随机性).
我们接下来打开这个docker-compose.yml,把下面的内容粘贴进去
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379保存退出。
有了上面这个配置文件还不够,上面这个文件只是创建哨兵的,但是哨兵自己还需要另外一个配置文件,我们现在就来创建一下(一个哨兵一个配置文件)
接下来我们直接把下面的内容分别粘贴到sentinel1.conf sentinel2.conf sentinel3.conf 三个文件里面即可
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000至于这个配置文件的什么含义,我们会在下一个小节进行讲解。
接下来我们就启动我们的哨兵进程
docker-compose up -d
如果启动后发现前⾯的配置有误,需要重新操作,使⽤ docker-compose down 即可停⽌并删除 刚才创建好的容器.
我们看看有没有启动成功
docker ps
乍一看,哨兵进程启动成功了,我们去看看哨兵有没有在监视各个节点
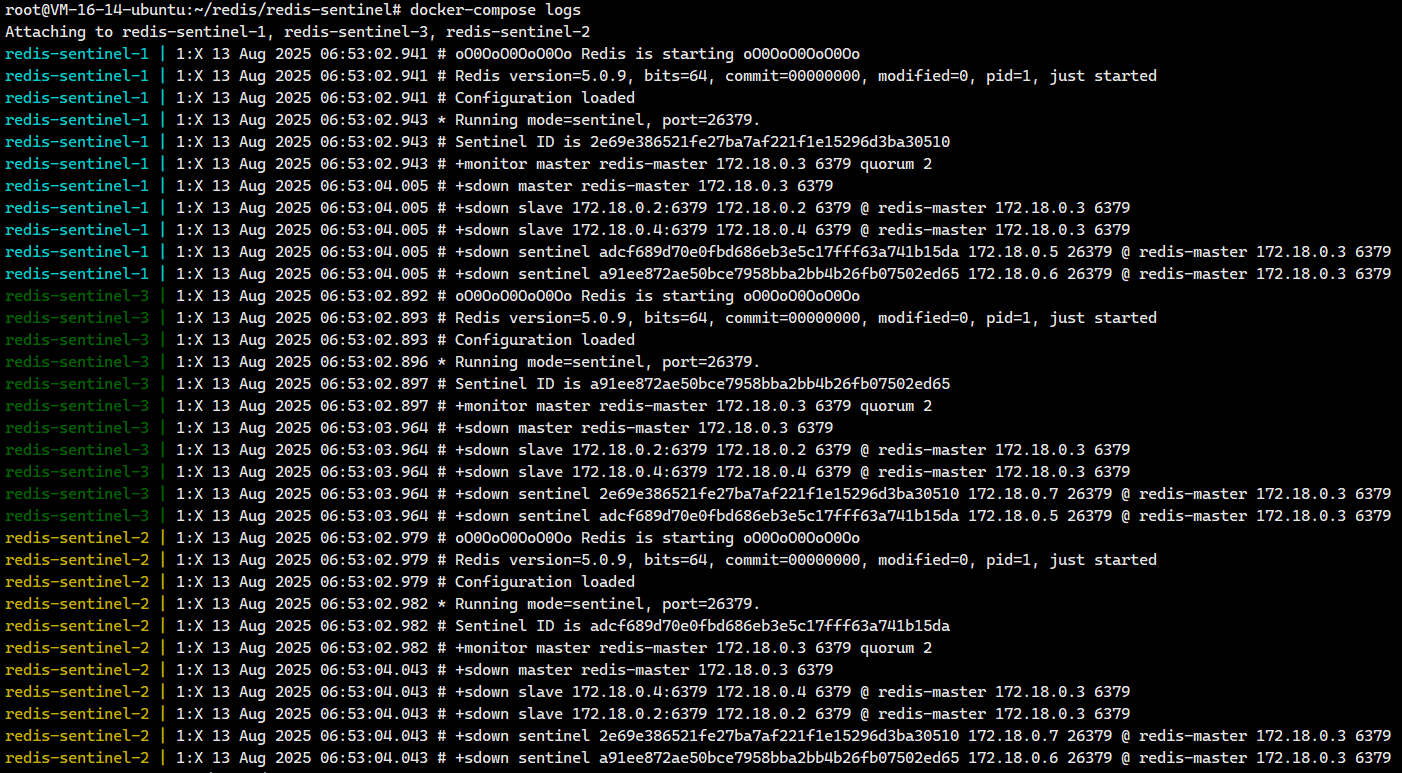
我们仔细一看,没有出现红色的字体,我们可能觉得没什么事,但是我们得仔细观察一下啊。!!!
我们拿一个节点的情况来看看,以 redis-sentinel-1 为例
1:X 13 Aug 2025 06:43:07.390 # +monitor master redis-master 172.18.0.3 6379 quorum 2
1:X 13 Aug 2025 06:43:08.450 # +sdown master redis-master 172.18.0.3 6379
1:X 13 Aug 2025 06:43:08.450 # +sdown slave 172.18.0.2:6379 ...
1:X 13 Aug 2025 06:43:08.450 # +sdown slave 172.18.0.4:6379 ...
1:X 13 Aug 2025 06:43:08.450 # +sdown sentinel adcf689d... 172.18.0.5 26379 ...
1:X 13 Aug 2025 06:43:08.450 # +sdown sentinel a91ee872... 172.18.0.6 26379 ...关键信息解读
-
监控初始化(正常):
+monitor master redis-master 172.18.0.3 6379 quorum 2-
Sentinel 开始监控名为
redis-master的主节点(IP172.18.0.3,端口6379) -
法定人数(quorum)为 2,表示需要至少 2 个 Sentinel 同意才能进行故障转移
-
-
主节点主观下线(异常):
+sdown master redis-master 172.18.0.3 6379-
sdown= Subjective Down(主观下线) -
该 Sentinel 无法连接到主节点(172.18.0.3:6379)
-
-
从节点全部下线(异常):
+sdown slave 172.18.0.2:6379 ... +sdown slave 172.18.0.4:6379 ...-
两个从节点(172.18.0.2 和 172.18.0.4)也被标记为不可用
-
表示整个 数据层完全瘫痪
-
-
其他 Sentinel 全部下线(最严重问题):
+sdown sentinel ... 172.18.0.5 26379 ... +sdown sentinel ... 172.18.0.6 26379 ...-
该 Sentinel 认为 其他两个 Sentinel 实例(172.18.0.5 和 172.18.0.6)都不可用
-
表示 Sentinel 集群内部网络完全中断
-
问题本质
所有三个 Sentinel 日志都显示相同的模式:
-
✅ 成功启动并尝试监控主节点
-
❌ 1 秒后同时报告:
-
主节点宕机
-
所有从节点宕机
-
其他 Sentinel 全部宕机
-
这明确表明存在 全局网络故障 或 IP 地址配置错误,导致:
-
Sentinel 无法访问 Redis 数据节点(主/从)
-
Sentinel 之间无法互相通信
-
整个集群处于完全分割状态
其实当前部署的核心问题在于 网络隔离。
我们部署了两组 Docker 服务:
-
三个 Redis 服务器节点 (redis-server) :它们通过一个 docker-compose 命令启动,Docker 会自动为这组服务创建一个独立的、私有的 桥接网络(通常命名为 <目录名>_default,例如 redis-data_default)。在这个网络内,各容器之间可以通过 IP 地址 或服务名(如 redis-master)相互访问,因为 Docker 内置了 DNS 解析,服务名会自动映射到该网络内对应容器的 IP。
-
三个 Redis Sentinel 节点:它们是通过 另一个 docker-compose 命令(可能在不同的目录或配置文件中)启动的。同样,Docker 会为这组 Sentinel 服务自动创建 另一个独立的桥接网络(例如 redis-sentinel_default)。
我们可以查看一下docker里面的网络情况
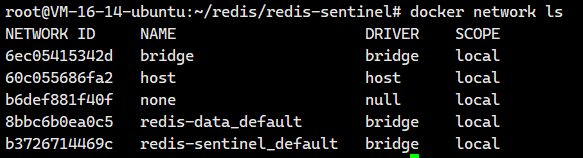
关键问题就在这里:
-
默认情况下,这两个由不同
docker-compose命令创建的网络是相互隔离的。它们就像是两个不同的局域网。 -
Redis Sentinel 节点运行在
redis-sentinel_default网络中。 -
Redis 主从节点(
redis-master,redis-slave等)运行在redis-data_default网络中。 -
因此,当 Sentinel 节点尝试访问
redis-master这个"域名"时:-
由于 Sentinel 在其自身的网络 (
redis-sentinel_default) 中,Docker 只会在 该网络内 尝试解析redis-master。 -
而真正的
redis-master服务存在于 另一个网络 (redis-data_default) 中,Sentinel 所在的网络里根本没有这个服务。 -
结果就是 Sentinel 节点无法解析
redis-master的地址,更无法连接到它 。这就是为什么所有 Sentinel 日志都疯狂报告主节点、从节点以及其他 Sentinel 节点全部+sdown(主观下线)的根本原因------它们完全找不到对方!
-
解决方案:让所有服务共享同一个网络
要解决这种网络隔离问题,必须确保 Redis 服务器节点 和 Redis Sentinel 节点 都运行在 同一个 Docker 网络 中。这样,Docker 内置的 DNS 才能在整个服务组内正确解析服务名(如 redis-master),实现相互通信。
我们完全可以规划一个共享网络: 可以创建一个自定义的 Docker 网络,或者指定其中一个 docker-compose 项目使用另一个项目已创建的网络(通常更推荐让所有服务定义在一个 docker-compose.yml 文件中)。
我们现在选择redis-data_default作为那个共享网络。
现在我们需要去配置文件里面进行修改一下
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis-data_default也就是在最后面添加下面这个即可
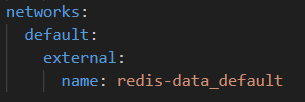
我们修改配置文件之后保存退出。
使⽤ docker-compose down 即可停⽌并删除 刚才创建好的容器.
docker-compose down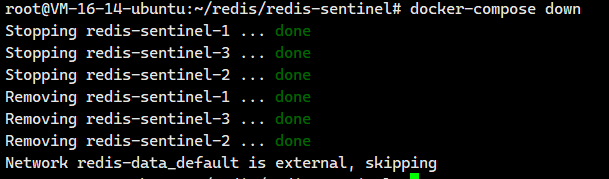
我们重新启动一下
docker-compose up -d
我们可以等一会之后再去看一下日志
docker-compose logs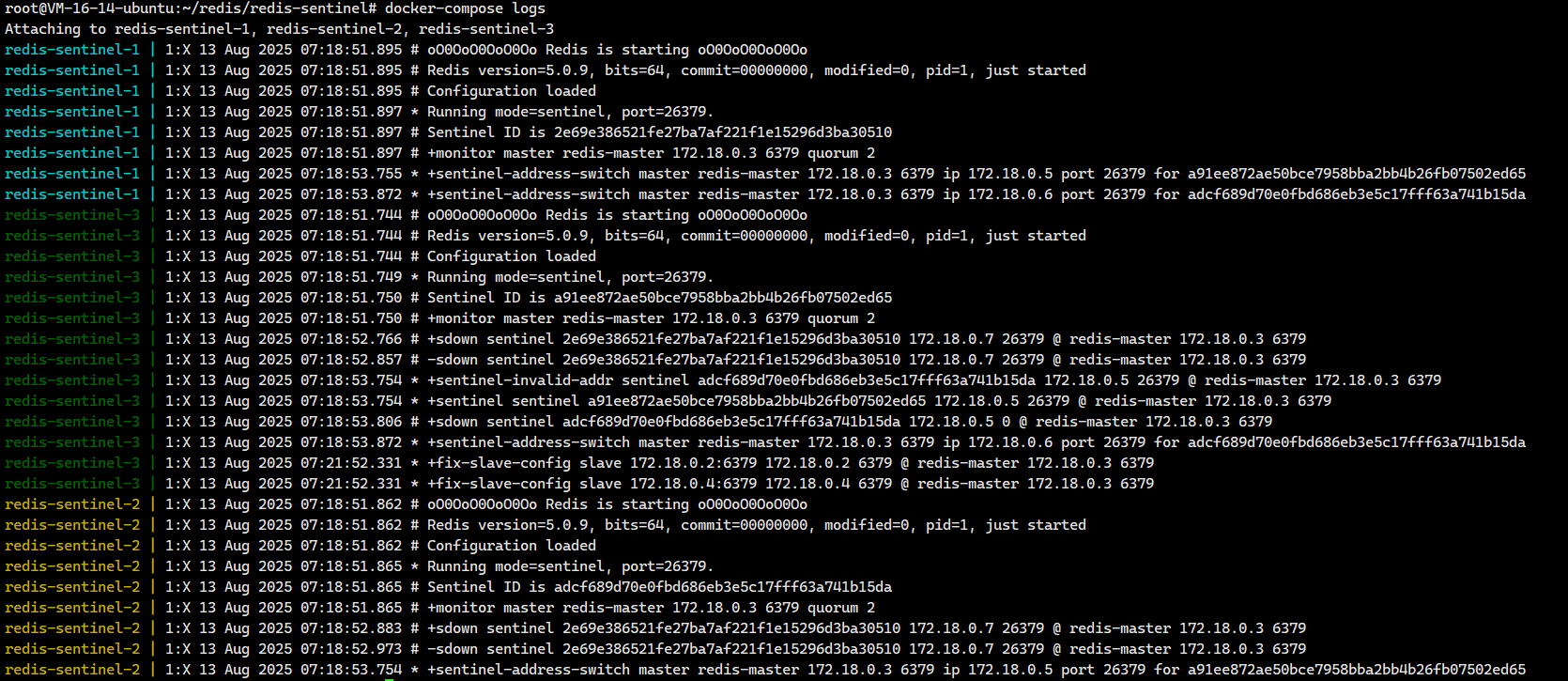
我们可以看到系统在启动过程中出现了一些短暂的网络波动或地址解析问题,但最终自动恢复正常。
当然如果你看不懂,也可以复制下来给chatgpt看看。
如果你不知道有没有问题,可以先登陆一个哨兵节点去看看
redis-cli -p 26379然后执行下面这两个
sentinel master redis-master sentinel sentinels redis-master大家一一去看看是不是我们配置的信息即可,我这里不演示
此外,我们可以去看看sentinel1.conf,sentinel2.conf,sentinel3.conf里面的内容
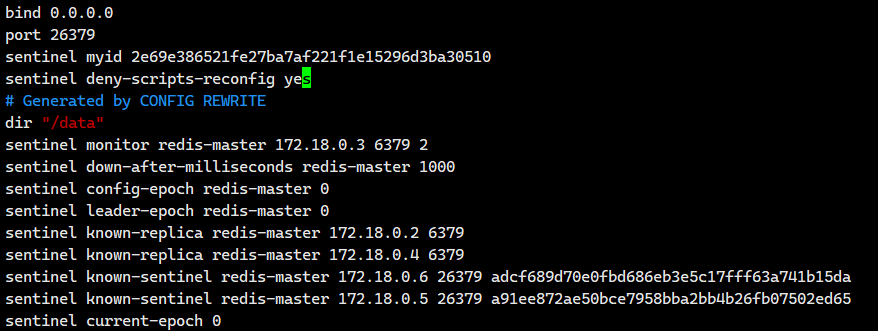
我们发现比我们之前配置的内容要多了一些东西,这些多了的东西就是哨兵运行起来之后自动写进去的。
2.5.3.哨兵配置文件讲解
我们在
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000这个 Redis Sentinel 配置定义了哨兵节点的核心监控行为,以下是每行配置的详细解释:
bind 0.0.0.0-
作用:指定哨兵服务监听的网络接口
-
含义 :
0.0.0.0表示哨兵将监听所有可用网络接口(包括本地回环、内网IP、公网IP等),允许来自任何网络位置的连接请求port 26379
-
作用:设置哨兵服务的监听端口
-
含义 :哨兵将在 26379 端口 上运行,这是 Redis Sentinel 的默认端口号
sentinel monitor redis-master redis-master 6379 2
-
作用:定义哨兵监控的主节点配置
-
参数分解:
-
redis-master(第一个):哨兵系统中主节点的逻辑名称(可自定义) -
redis-master(第二个):主节点的实际访问地址(此处使用 Docker 容器服务名) -
6379:主节点的 Redis 服务端口 -
2:法定人数(quorum) - 表示需要至少 2 个哨兵节点同意才能判定主节点失效sentinel down-after-milliseconds redis-master 1000
-
-
作用:设置主节点失效判定时间阈值
-
参数分解:
-
redis-master:要配置的主节点名称(需与监控配置中的名称一致) -
1000:毫秒单位的时间阈值(1000ms = 1秒)
-
-
含义 :当哨兵连续 1 秒无法与主节点通信 时,该哨兵会将主节点标记为**"主观下线"**(SDOWN)
深入理解 sentinel monitor 配置
sentinel monitor <主节点名> <主节点地址> <主节点端口> <法定票数>这个是 Sentinel 配置中最核心的指令,用于告知 Sentinel 节点它需要监控哪个 Redis 主节点及其相关参数。
- <主节点名> : 这是哨兵系统内部用来标识这个特定主节点集群的逻辑名称。它是由用户自定义的(例如 redis-master, my-app-cache),**在整个哨兵集群中必须保持一致,**用于区分不同的主节点实例。哨兵之间通信以及故障转移后报告新主节点时都会使用这个名字。
- <主节点地址> : 这是哨兵节点需要连接以进行监控的实际网络地址。**在传统部署中,这通常是主节点服务器的 IP 地址。**然而,在 Docker 环境中 ,得益于 Docker 内置的 DNS 服务发现机制,我们可以直接使用 Redis 主节点容器的服务名称 (例如 redis-master)。Docker 会自动将这个名称解析为对应容器的内部 IP 地址,极大地简化了配置,尤其是在容器 IP 可能变动的情况下。
- <主节点端口> : 这是目标 Redis 主节点实际监听服务的端口号(通常是 6379)。哨兵节点将通过此端口与 Redis 主节点建立连接,发送监控命令和接收响应。
- <法定票数>(quorum) : 这是 Sentinel 集群中达成客观下线 (Objectively Down, ODOWN) **判定所需的最低同意票数。其核心作用在于防止单点误判。**考虑这样的场景:某个哨兵节点自身网络出现临时故障,导致它无法访问主节点,此时该哨兵会认为主节点"主观下线 (Subjectively Down, SDOWN)"。如果仅凭单个哨兵的判断就认定主节点故障并触发故障转移,可能会导致不必要的切换(脑裂风险)。引入法定票数机制后,**必须至少有 <法定票数> 个哨兵节点都独立判定该主节点为"主观下线"(SDOWN),才能将其状态升级为"客观下线"(ODOWN),之后故障转移流程才会真正启动。**这大大提高了故障判定的准确性和系统的健壮性。通常,法定票数设置为 (哨兵节点总数 / 2) + 1(向上取整)是一个合理的值(例如 3 个哨兵时设为 2)。
深入理解 sentinel down-after-milliseconds 配置
sentinel down-after-milliseconds <主节点名> <毫秒数>这个配置项定义了哨兵节点判断主节点或从节点失效的超时阈值。
- 心跳检测机制: Sentinel 节点会周期性地(默认每秒一次)向它监控的 Redis 主节点(以及从节点)发送 PING 命令(即"心跳包")来检查其健康状态。节点需要及时回复 PONG 响应。
- 超时判定: <毫秒数> 参数设定了哨兵等待节点响应的最大时间窗口。如果在连续多次心跳检测中,目标节点在设定的 <毫秒数> 内都未能回复有效的 PONG 响应,那么发出检测的哨兵节点就会单方面将该节点标记为 "主观下线"(SDOWN) 状态。
意义与权衡:
- 敏感性: 这个值设置得越小,哨兵对节点故障的感知就越快。例如设置为 1000(1秒),意味着一次心跳无响应就可能触发 SDOWN。
- 可靠性: 然而,设置过小也容易引发误判。网络中的瞬时抖动、服务器短暂的高负载都可能导致响应延迟超过阈值,从而被误认为节点故障。
设置建议: 需要根据实际的网络环境和应用容忍度来权衡。生产环境中,为了平衡敏感性和可靠性,这个值通常设置在 3000(3秒)到 5000(5秒)或更高,而不是示例中的 1000(1秒)。设置过短(如 1秒)在非理想网络条件下可能会产生过多不必要的 SDOWN 告警甚至触发不必要的 ODOWN 投票流程。
2.6.哨兵节点的作用演示
2.6.1.手动关闭主节点
我们直接手动把主节点干掉
docker stop redis-master运行结果
root@VM-16-14-ubuntu:~/redis/redis-sentinel# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
caca1cb89a13 redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26379->26379/tcp, [::]:26379->26379/tcp redis-sentinel-1
9a60ceee476a redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26380->26379/tcp, [::]:26380->26379/tcp redis-sentinel-2
10f35cc7984d redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26381->26379/tcp, [::]:26381->26379/tcp redis-sentinel-3
2456204b18eb redis:5.0.9 "docker-entrypoint.s..." 2 hours ago Up 2 hours 0.0.0.0:6380->6379/tcp, [::]:6380->6379/tcp redis-slave1
eaf4b03a2299 redis:5.0.9 "docker-entrypoint.s..." 2 hours ago Up 2 hours 0.0.0.0:6379->6379/tcp, [::]:6379->6379/tcp redis-master
eb9623ec8da8 redis:5.0.9 "docker-entrypoint.s..." 2 hours ago Up 2 hours 0.0.0.0:6381->6379/tcp, [::]:6381->6379/tcp redis-slave2
root@VM-16-14-ubuntu:~/redis/redis-sentinel# docker stop redis-master
redis-master
root@VM-16-14-ubuntu:~/redis/redis-sentinel# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
caca1cb89a13 redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26379->26379/tcp, [::]:26379->26379/tcp redis-sentinel-1
9a60ceee476a redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26380->26379/tcp, [::]:26380->26379/tcp redis-sentinel-2
10f35cc7984d redis:5.0.9 "docker-entrypoint.s..." About an hour ago Up About an hour 6379/tcp, 0.0.0.0:26381->26379/tcp, [::]:26381->26379/tcp redis-sentinel-3
2456204b18eb redis:5.0.9 "docker-entrypoint.s..." 2 hours ago Up 2 hours 0.0.0.0:6380->6379/tcp, [::]:6380->6379/tcp redis-slave1
eb9623ec8da8 redis:5.0.9 "docker-entrypoint.s..." 2 hours ago Up 2 hours 0.0.0.0:6381->6379/tcp, [::]:6381->6379/tcp redis-slave2这个时候哨兵节点已经开始干活了。我们来看看日志
docker-compose logs注意这个命令得在哨兵配置文件所在目录下执行

日志的内容其实有点混乱,我给大家整理了一下:
1. 故障检测阶段(主观下线 → 客观下线)
主观下线(SDOWN)
-
08:39:22.416 :哨兵2(redis-sentinel-2)首先检测到主节点不可用,标记为
+sdown(主观下线) -
08:39:22.432 :哨兵3(redis-sentinel-3)也检测到主节点不可用,标记
+sdown -
08:39:22.407 :哨兵1(redis-sentinel-1)同样标记主节点
+sdownSentinel-2 报告主观下线
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.416 # +sdown master redis-master 172.18.0.3 6379
Sentinel-3 报告主观下线
redis-sentinel-3 | 1:X 13 Aug 2025 08:39:22.432 # +sdown master redis-master 172.18.0.3 6379
Sentinel-1 报告主观下线
redis-sentinel-1 | 1:X 13 Aug 2025 08:39:22.407 # +sdown master redis-master 172.18.0.3 6379
客观下线(ODOWN)
Sentinel-2 确认满足法定人数(quorum=2),触发客观下线:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.469 # +odown master redis-master 172.18.0.3 6379 #quorum 2/2大家注意
-
sdown:主观下线:本哨兵节点认为主节点已经挂了
-
odown:客观下线,好几个哨兵节点都认为主节点已经挂了
2. 领导者选举阶段
发起故障转移
Sentinel-2 尝试发起故障转移:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.469 # +try-failover master redis-master 172.18.0.3 6379投票过程
所有 Sentinel 投票给 Sentinel-2(ID: adcf689d...):
# Sentinel-2 自投
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.473 # +vote-for-leader adcf689d70e0fbd686eb3e5c17fff63a741b15da 1
# Sentinel-1 投票
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.480 # 2e69e386521fe27ba7af221f1e15296d3ba30510 voted for adcf689d70e0fbd686eb3e5c17fff63a741b15da 1
# Sentinel-3 投票
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.480 # a91ee872ae50bce7958bba2bb4b26fb07502ed65 voted for adcf689d70e0fbd686eb3e5c17fff63a741b15da 1选举结果
Sentinel-2 当选领导者:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.525 # +elected-leader master redis-master 172.18.0.3 63793. 故障转移执行阶段
选择新主节点
Sentinel-2 选择从节点 172.18.0.2:6379 为新主节点:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.625 # +selected-slave slave 172.18.0.2:6379 172.18.0.2 6379 @ redis-master 172.18.0.3 6379提升新主节点
发送 SLAVEOF NOONE 命令:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.625 * +failover-state-send-slaveof-noone slave 172.18.0.2:6379 172.18.0.2 6379 @ redis-master 172.18.0.3 6379等待从节点晋升:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:22.725 * +failover-state-wait-promotion slave 172.18.0.2:6379 172.18.0.2 6379 @ redis-master 172.18.0.3 6379晋升成功:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:23.551 # +promoted-slave slave 172.18.0.2:6379 172.18.0.2 6379 @ redis-master 172.18.0.3 6379重配置从节点
将另一个从节点 172.18.0.4:6379 指向新主节点:
# 发送重配置命令
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:23.601 * +slave-reconf-sent slave 172.18.0.4:6379 172.18.0.4 6379 @ redis-master 172.18.0.3 6379
# 重配置完成
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:24.618 * +slave-reconf-done slave 172.18.0.4:6379 172.18.0.4 6379 @ redis-master 172.18.0.3 63794. 切换完成阶段
故障转移结束
Sentinel-2 确认故障转移完成:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:24.670 # -odown master redis-master 172.18.0.3 6379
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:24.671 # +failover-end master redis-master 172.18.0.3 6379主节点切换广播
通知所有 Sentinel 主节点已切换:
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:24.671 # +switch-master redis-master 172.18.0.3 6379 172.18.0.2 6379旧主节点处理
将原主节点 172.18.0.3:6379 标记为从节点并下线:
# 标记为从节点
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:24.671 * +slave slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379
# 主观下线(因旧主已宕机)
redis-sentinel-2 | 1:X 13 Aug 2025 08:39:25.715 # +sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 63795. 配置传播阶段
Sentinel 同步新配置
Sentinel-2 将新配置广播给其他 Sentinel:
# Sentinel-3 接收配置更新
redis-sentinel-3 | 1:X 13 Aug 2025 08:39:23.601 # +config-update-from sentinel adcf689d70e0fbd686eb3e5c17fff63a741b15da 172.18.0.6 26379 @ redis-master 172.18.0.3 6379
redis-sentinel-3 | 1:X 13 Aug 2025 08:39:23.601 # +switch-master redis-master 172.18.0.3 6379 172.18.0.2 6379
# Sentinel-1 接收配置更新
redis-sentinel-1 | 1:X 13 Aug 2025 08:39:23.601 # +config-update-from sentinel adcf689d70e0fbd686eb3e5c17fff63a741b15da 172.18.0.6 26379 @ redis-master 172.18.0.3 6379
redis-sentinel-1 | 1:X 13 Aug 2025 08:39:23.601 # +switch-master redis-master 172.18.0.3 6379 172.18.0.2 6379其他 Sentinel 更新拓扑
Sentinel-1 和 Sentinel-3 将旧主节点标记为从节点并下线:
# Sentinel-3 标记旧主下线
redis-sentinel-3 | 1:X 13 Aug 2025 08:39:24.609 # +sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379
# Sentinel-1 标记旧主下线
redis-sentinel-1 | 1:X 13 Aug 2025 08:39:24.637 # +sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379整个过程在约2秒内完成(08:39:22.416 - 08:39:24.671),证明我的Sentinel集群配置正确且响应迅速。
客户端检验哨兵节点是否完成任务
我们尝试登陆原来的主节点,发现挂了

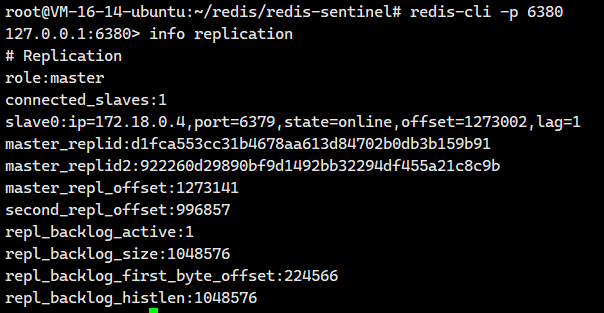
我们尝试登陆原来的从节点6380,发现它晋升为主节点了
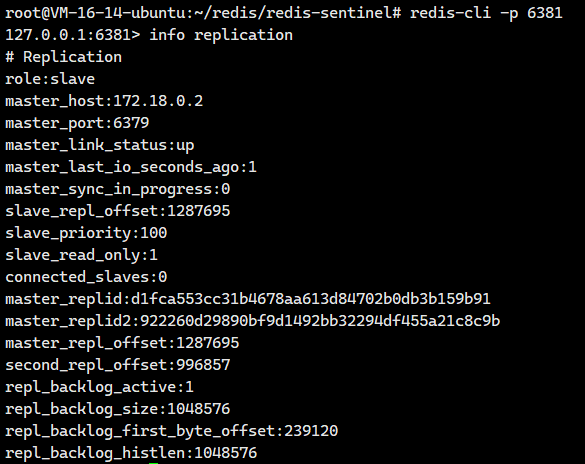
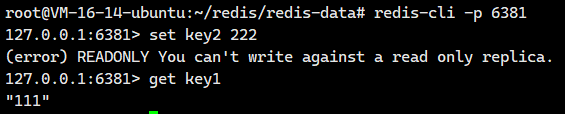
我们尝试登陆原来的从节点6381,发现它还是从节点啊。
我们仔细观察下面这两个东西
master_host:172.18.0.2
master_port:6379172.18.0.2是谁啊?我们可以通过下面这个命令看看
# 在 docker-compose.yml 所在目录执行
docker-compose ps -q | xargs docker inspect -f '{{.Name}} {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' | sed 's#^/##'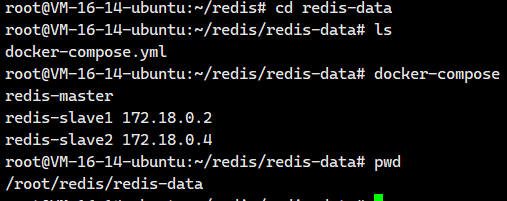
哦!172.18.0.2就是原来的从节点6380,也就是现在的主节点。
2.6.2.让挂掉的主节点重新启动
我们执行下面这个命令让挂掉的主节点重新启动
docker start redis-master运行完之后,我们可以检测一些有没有启动成功
root@VM-16-14-ubuntu:~/redis/redis-sentinel# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
caca1cb89a13 redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 3 hours 6379/tcp, 0.0.0.0:26379->26379/tcp, [::]:26379->26379/tcp redis-sentinel-1
9a60ceee476a redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 3 hours 6379/tcp, 0.0.0.0:26380->26379/tcp, [::]:26380->26379/tcp redis-sentinel-2
10f35cc7984d redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 3 hours 6379/tcp, 0.0.0.0:26381->26379/tcp, [::]:26381->26379/tcp redis-sentinel-3
2456204b18eb redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 3 hours 0.0.0.0:6380->6379/tcp, [::]:6380->6379/tcp redis-slave1
eaf4b03a2299 redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 6 seconds 0.0.0.0:6379->6379/tcp, [::]:6379->6379/tcp redis-master
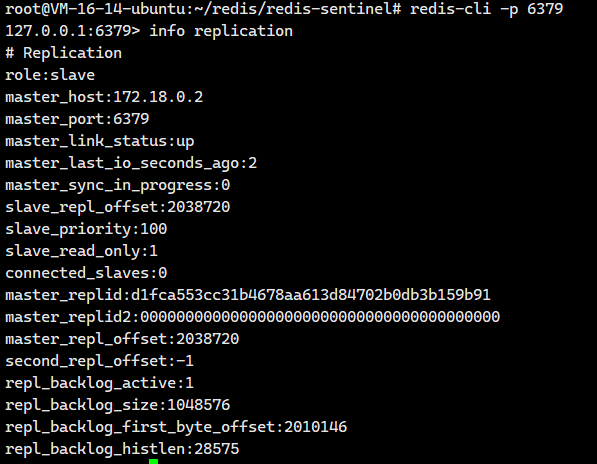
eb9623ec8da8 redis:5.0.9 "docker-entrypoint.s..." 3 hours ago Up 3 hours 0.0.0.0:6381->6379/tcp, [::]:6381->6379/tcp redis-slave2我们重新登陆一下原来的6379主节点,发现重启之后它变成一个从节点了

我们回到新主节点6380看看
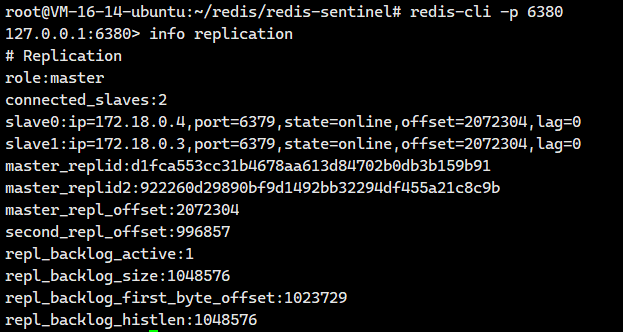
看到它的slave就有2个了。
其实我们可以去看看日志里面的内容!!
我们看看日志里面的内容

1. 检测旧主节点恢复(-sdown)
所有哨兵节点检测到旧主节点恢复网络连接,移除主观下线标记:
# Sentinel-1 移除主观下线
redis-sentinel-1 | 1:X 13 Aug 2025 10:01:12.950 # -sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379
# Sentinel-2 移除主观下线
redis-sentinel-2 | 1:X 13 Aug 2025 10:01:12.518 # -sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379
# Sentinel-3 移除主观下线
redis-sentinel-3 | 1:X 13 Aug 2025 10:01:13.139 # -sdown slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 63792. 重配置为从节点(+convert-to-slave)
哨兵领导者(Sentinel-2)自动将恢复的旧主节点重配置为新主节点的从节点:
# Sentinel-2 执行转换命令
redis-sentinel-2 | 1:X 13 Aug 2025 10:01:22.463 * +convert-to-slave slave 172.18.0.3:6379 172.18.0.3 6379 @ redis-master 172.18.0.2 6379事实上,日志里面只显示了这两点,其实还有一些数据同步的信息。
五. 主从切换的具体流程
假定当前环境如上⽅介绍,三个哨兵(sentenal1,sentenal2,sentenal3),⼀个主节点(redis-master),两 个从节点(redis-slave1,redis-slave2)。
当主节点出现故障,就会触发重新⼀系列过程。
5.1.主观下线 (Subjective Down, SDown)
在 Redis 哨兵(Sentinel)架构中,哨兵节点持续监控其负责的 Redis 主节点(redis-master)的状态。其核心机制之一是通过定期的心跳包(或称 PING 命令)来探测主节点的活性。
当某个哨兵节点按照配置的间隔时间发送心跳包后,未能如期收到主节点的有效响应时(例如响应超时、连接被拒绝或返回错误),站在该哨兵节点的角度,它认为主节点出现了严重的通信故障或服务不可用。
此时,该哨兵节点会单方面 将主节点标记为 "主观下线"(SDown) 状态。这个判断被称为"主观"的,因为它仅基于当前哨兵节点自身的视角和网络连通性 。单个哨兵节点检测到的心跳丢失,可能是由主节点真正宕机、主节点与这个哨兵节点之间的**瞬时网络波动、网络分区(Network Partition)**或其他局部性故障引起的。因此,仅凭一个哨兵节点的判断,还不足以断定主节点已完全不可用并触发自动故障转移。
主观下线是哨兵故障检测流程中的初步判定,它为后续需要多个哨兵节点协作确认的"客观下线"判定奠定了基础。
5.2. 客观下线 (Objective Down, ODown)
当哨兵节点将主节点标记为 主观下线 (SDown) 后,这只是单个哨兵的初步判断。为了确认主节点确实不可用并安全地启动故障转移流程,需要多个哨兵节点进行协商并达成共识。
此时,检测到主节点主观下线的哨兵节点(例如 sentinel1、sentinel2、sentinel3)会发起投票,向集群中的其他哨兵节点询问它们对该主节点状态的看法(即是否也认为该主节点已下线)。每个哨兵节点根据自己的检测结果进行投票。
关键机制:法定票数 (Quorum)
在哨兵的配置中,我们可以通过下面这个来配置法定票数
sentinel monitor <master-name> <ip> <port> <quorum> 这个命令(例如:sentinel monitor redis-master 172.22.0.4 6379 2)定义了一个关键参数:<quorum>(法定票数) 。这个值代表了确认主节点客观下线所需的最少同意票数。
达成客观下线:
-
当认为主节点已下线的哨兵节点数量 达到或超过 配置的法定票数
<quorum>(在示例中为 2)时, -
哨兵集群集体判定主节点已失效。
-
此时,主节点的状态将被正式提升为 "客观下线"(ODown)。
客观下线的含义:
-
共识达成: ODown 状态表示哨兵集群作为一个整体,基于多数哨兵的独立检测结果,确认主节点存在严重故障或不可达。
-
故障转移触发点: 主节点被标记为 ODown 是触发自动故障转移 (Automatic Failover) 流程的核心前提条件。哨兵集群将开始选举新的主节点。
当然,也可能出现非常严重的网络波动导致所有哨兵都联系不上主节点而被误判为 ODown 的情况。
然而,从系统可用性的实际角度来看:
客户端视角: 如果出现如此严重的网络问题,导致所有哨兵都无法访问主节点,那么客户端的连接请求也几乎必然失败 。此时,主节点虽然进程可能仍在运行,但实质上已经无法为客户端提供任何服务。
服务不可用即"挂掉": 在分布式系统的语境下,一个节点是否"挂掉"并不仅仅指其进程崩溃。只要该节点无法被其服务对象(客户端)正常访问并提供预期服务,它就可以被视为"挂掉"或"失效" 。客观下线 (ODown) 正是哨兵集群对这种服务不可用状态的权威认定。即使根源是网络问题而非进程崩溃,从保障整个系统可用性的目标出发,触发故障转移以恢复服务也是必要且正确的操作。
因此,客观下线 (ODown) 是哨兵机制中一个至关重要的状态,它通过多节点协商和法定票数机制,在最大程度上减少单点误判的风险,并正式宣告主节点服务不可用,为后续的故障恢复奠定基础。
5.3. 选举哨兵 Leader (Leader Sentinel Election)
当主节点被判定为 客观下线 (ODown) 后,哨兵集群需要启动故障转移流程,将其中一个从节点(Slave)提升为新的主节点(Master)。为了避免决策冲突和确保操作的一致性,这个关键的故障转移工作并非由所有哨兵节点共同执行,而是需要选举出一个唯一的领导者哨兵(Leader Sentinel)来全权负责。
这个领导者选举过程,通常基于 Raft 共识算法 的核心思想来实现(或类似的分布式共识协议)。其目标是在哨兵节点间快速、安全地选出一个获得多数派认可的代表。
选举过程详解(以三个哨兵节点 S1、S2、S3 为例):
-
发起拉票请求: 每个哨兵节点(S1、S2、S3)意识到需要选举 Leader 时,会立即向集群中的所有其他哨兵节点 (对于 S1,就是 S2 和 S3)发送一个"拉票请求"(本质上是一个"我想当 Leader"的投票请求)。这导致总共产生 N*(N-1) 条请求(3个节点就是 3*2=6 条:S1->S2, S1->S3, S2->S1, S2->S3, S3->S1, S3->S2)。
-
处理投票请求与投票: 当一个哨兵节点(例如 S2)收到来自另一个哨兵节点(例如 S1)的拉票请求时:
-
S2 会检查自己的投票状态。
-
核心规则:每个哨兵在每一轮选举中只有一票,且遵循"先到先得"原则。
-
如果 S2 还没有给任何其他节点投过票 (即 S1 是第一个向 S2 拉票的节点),那么 S2 就会投给 S1,并回复一个"同意"的投票响应。
-
如果 S2 已经投给了其他节点 (例如之前收到了 S3 更早的请求并投给了 S3),那么 S2 就会拒绝 S1 的请求,回复一个"不同意"的投票响应。
-
-
统计票数与选出 Leader:
-
哨兵节点收集来自其他哨兵的投票响应。
-
关键条件:如果一个哨兵节点收到的"同意票"数量 >= 哨兵集群的一半的节点个数,它即当选为 Leader。
-
成功选出: 例如,如果 S1 收到了 S2 和 S3 的同意票(共 2 票 >= 多数派 2),S1 即成为 Leader。
-
-
处理选举失败(平票):
-
如果一轮投票结束后,没有任何节点获得足够的多数票(例如,投票分布为 S1 投 S2, S2 投 S3, S3 投 S1,每人只得 1 票),则选举失败。
-
此时,哨兵集群会等待一个随机时间(随机性有助于打破对称)后,发起新一轮的选举。这个过程会持续,直到成功选出一个 Leader。
-
奇数节点的优势: 这就是为什么强烈建议将哨兵节点数量配置为奇数 (如 3、5、7)。奇数节点天然更容易形成明确的多数派(如 3选2, 5选3),极大降低了平票发生的概率,减少了选举轮次和整体耗时。偶数节点(如 2、4)则显著增加了平票的可能性和选举开销。
-
-
Leader 的职责: 成功当选的 Leader Sentinel 独享执行故障转移的权限 。它的核心任务是从存活的从节点中,根据预设规则(如优先级、复制偏移量、Run ID 等)挑选出一个最合适的从节点,并将其提升为新的主节点。一旦新的主节点被成功选出并配置好,其他哨兵节点会感知到这个变化,整个故障转移的核心阶段即告结束。
核心特点与理解要点:
-
"先下手为强"与网络延时: Raft 类选举的核心机制确实倾向于让最先、最广泛地发出有效拉票请求的节点当选 。网络延时在其中扮演了关键角色------网络状况更好、响应更快的哨兵节点更有可能率先将拉票请求送达其他节点,从而获得宝贵的"第一票"。这引入了一定的随机性。
-
"谁当选"不重要,"能选出"才重要: 对于整个系统而言,具体是哪一个哨兵节点成为 Leader 并不重要 。关键在于能够快速、可靠地选举出一个唯一的 Leader,由它来有序地执行故障转移操作,避免多个节点同时尝试提升从节点造成的混乱(脑裂)。
-
现实类比 (精简版): 想象三位管理员(哨兵 S1、S2、S3)共同负责一个关键系统(Redis 集群)。当主负责人(主节点)突然失联(ODown),需要提拔一位副手(Slave)接替。这个提拔决策本身不需要三人同时插手。于是,他们迅速内部协商:管理员 A 率先提议"我来负责这次提拔吧?"如果 B 和 C 之前没答应别人且都同意 A,那么 A 得票超过半数(2/3),成为本次操作的负责人(Leader)。他随后完成提拔工作,系统恢复运转。
哨兵内部是怎么避免平票的情况的发生的?
我们说如果一个哨兵节点收到的"同意票"数量 >= 哨兵集群的一半的节点个数,它即当选为 Leader。
事实上哨兵在计算总节点个数的一半的公式还是做了一些功夫的。
总节点个数的一半的计算公式:
总节点个数的一半 = floor(N / 2) + 1-
floor(N / 2)表示对N / 2的结果向下取整。 -
+ 1表示在这个基础上再加 1 ,确保最终结果严格大于 N 的一半。
为什么是 "严格大于一半"?
因为如果只是"等于一半",在偶数个节点的情况下,就可能出现两个对等的群体(各占一半),双方都无法说服对方,导致僵局(死锁)。要求"严格大于一半"就能确保在任何情况下,有且只有一个群体能获得多数支持(除非超过一半的节点同时故障,但这通常意味着系统整体不可用)。
举例说明(哨兵场景):
-
3 个哨兵节点 (N=3):
-
一半是:3 / 2 = 1.5
-
向下取整 floor(1.5) = 1
-
多数派 = 1 + 1 = 2
-
解读: 在 3 个哨兵中,需要至少获得 2 票才能成为 Leader。不可能出现两个节点同时获得 2 票的情况(因为总票数只有 3 票,如果 A 得 2 票,B 最多只能得 1 票)。平票(每人 1 票)时无法选出 Leader,需要重试。
-
-
5 个哨兵节点 (N=5):
-
一半是:5 / 2 = 2.5
-
向下取整 floor(2.5) = 2
-
多数派 = 2 + 1 = 3
-
解读: 在 5 个哨兵中,需要至少获得 3 票才能成为 Leader。同样,不可能有两个节点同时获得 3 票(总票数 5)。最多允许 2 个节点故障或失联,系统仍然能选出 Leader(因为剩下的 3 个节点能形成 3 > floor(5/2)=2 的多数派)。
-
-
4 个哨兵节点 (N=4 - 不推荐偶数):
-
一半是:4 / 2 = 2
-
向下取整 floor(2) = 2
-
多数派 = 2 + 1 = 3
-
解读: 在 4 个哨兵中,需要至少获得 3 票 才能成为 Leader。问题:
-
容错性降低: 只能容忍 1 个节点故障(因为剩下 3 个节点刚好满足多数派 3)。而 3 节点集群也能容忍 1 个故障(满足多数派 2),但用了 4 个节点。
-
容易僵局/开销大: 如果两个节点各获得 2 票,或者三个节点分别获得 1 票(剩下 1 票弃权或给第四个),都无法达到 3 票。平票概率比奇数节点高,选举可能需要更多轮次,增加延迟和网络开销。这就是为什么建议使用奇数个哨兵节点(3, 5, 7)------ 它们能以更少的节点数量达到相同的容错能力(例如 3 节点和 4 节点都只容 1 错),并且大大降低平票概率。
-
-
5.4. Leader Sentinel 挑选新 Master
一旦哨兵 Leader 被成功选举出来,它的核心职责就是从存活的从节点(Slaves)中挑选出最合适的一个,并将其提升为新的主节点(Master)。
这个选择过程并非随机,而是遵循一套严格的、具有明确优先级的筛选规则 ,旨在确保新主节点具备最佳的数据完整性和服务能力。
挑选规则详解(按优先级顺序应用):
-
优先级(Priority - 最高优先级):
-
每个 Redis 从节点在其配置文件 (
redis.conf) 中都有一个slave-priority(或replica-priority)配置项,用于设定其成为主节点的优先级。 -
规则:
slave-priority数值最小的从节点优先级最高。 -
行为: Leader 会检查所有可用从节点的
slave-priority值。如果发现唯一一个 优先级数值最低(即配置值最小)的节点,则直接选择它。 -
类比(蛋哥提拔助教): 这就像杨校长(配置文件)明确钦定 了某位助教老师(从节点)作为重点培养对象(
slave-priority设得很低)。蛋哥(Leader Sentinel)看到这个"钦定"标识,就会优先提拔这位助教成为新的主讲老师(Master)。
-
-
复制偏移量(Replication Offset - 次高优先级):
-
如果多个从节点的优先级相同 (或者都未显式配置优先级,使用默认值),则比较它们的复制偏移量(Replication Offset)。
-
复制偏移量表示从节点从原主节点(或上游从节点)复制数据的进度 。数值越大,表示该从节点拥有的数据越新、越接近故障前主节点的状态。
-
规则:复制偏移量最大的从节点胜出。
-
行为: Leader 会查询所有候选从节点的复制偏移量,选择拥有最高复制偏移量的节点。这最大程度保证了新主节点的数据最新,减少数据丢失风险。
-
类比(蛋哥提拔助教): 如果没有钦定人选(提前指定好了的Master),蛋哥(Leader Sentinel)就会看哪位助教老师的备课进度最快最全(复制偏移量最大)。比如一共 20 个课件,A 助教已经备完 18 个(高 Offset),而 B、C 助教只备了 5、6 个(低 Offset),那么 A 助教自然胜出,成为新主讲。
-
-
运行 ID(Run ID - 最低优先级):
-
如果经过前两轮比较,仍有多个从节点的优先级和复制偏移量都完全相同 (这种情况比较罕见),则最后比较它们的 Run ID。
-
Run ID 是每个 Redis 节点在启动时自动生成的一个唯一随机字符串标识符。它没有特定的业务含义。
-
规则:Run ID 按字典序(lexicographical order)最小的从节点胜出。 (本质上是"随机"挑选一个,但规则明确)
-
行为: Leader 比较这些"平票"节点的 Run ID,选择其中字典序最小的那个(例如
aaaa小于aaab)。这只是一个简单明确的最终决策机制。 -
类比(蛋哥提拔助教): 如果几位助教既没有被钦定,备课进度又完全一样(优先级和 Offset 都相同),蛋哥就只好"看眼缘"了------谁的名字(Run ID)起得比较顺眼(按字母排序最小),就选谁来当新主讲。
-
Leader Sentinel 执行新主节点提升流程:
一旦Leader Sentinel根据上述规则选定了目标从节点(假设是 Slave-X),它将立即执行以下操作来完成主节点切换:
-
提升新主节点:
-
Leader Sentinel 向 Slave-X 发送
SLAVEOF NO ONE命令。 -
该命令使 Slave-X 立即停止其复制角色,并晋升自身为主节点。它开始接受客户端的写入请求。
-
-
重配置其他从节点:
-
Leader Sentinel 向所有剩余的从节点(包括可能因网络问题暂时失联但存活的) 发送
SLAVEOF <new-master-ip> <new-master-port>命令。 -
该命令将这些从节点重新配置为 Slave-X(新主节点)的从节点。它们开始从新主节点同步数据。
-
-
通知与更新(隐含):
-
其他哨兵节点会持续监控集群状态。当它们发现:
-
原主节点下线(ODown)。
-
一个新的主节点(Slave-X)出现并被提升。
-
其他从节点已被重新指向这个新主节点。
-
-
哨兵集群会自动更新其内部配置,将 Slave-X 识别为新的主节点,并持续监控其状态。客户端通过查询哨兵也能获取到新的主节点地址。
-
六.注意事项
部署和使用 Redis 哨兵模式以实现高可用时,需要牢记以下重要原则和限制:
-
哨兵节点数量与部署:
-
避免单点故障: 绝对不要只部署一个哨兵节点。 如果唯一的哨兵节点自身发生故障或变得不可达,整个哨兵监控和自动故障转移功能将完全失效,系统将失去高可用性保障。
-
推荐奇数个节点: 强烈建议将哨兵节点数量配置为奇数(如 3、5、7)。 这在基于 Raft 的 Leader 选举过程中至关重要。奇数节点能更有效地形成明确的多数派(Quorum Majority),显著降低选举过程中出现平票的概率,减少选举轮次,提高故障转移的效率和可靠性。偶数节点(如 2、4)虽然也能工作,但会增加平票风险和选举开销。
-
-
哨兵节点的角色:
- 专注监控与管理: 哨兵节点本身不存储任何 Redis 应用数据。 它们唯一的职责是监控 Redis 主节点和从节点的状态、发现故障 、协调自动故障转移 (选举 Leader、选择并提升新主节点)以及提供配置发现服务 给客户端。数据的存储和读写请求仍然完全由 Redis 主节点和从节点负责处理。
-
解决的问题与核心价值:
- 核心目标:高可用性(High Availability, HA): 哨兵模式主要解决的是 Redis 服务在单点故障(主节点宕机)时的持续可用性问题 。它通过自动检测故障、选举新主节点、更新客户端配置,使得在主节点不可用时,服务能在较短时间内(通常在几秒到几十秒内)自动恢复,最大限度地减少服务中断时间。
-
固有的局限性:
-
无法保证强一致性与零数据丢失: 哨兵 + 主从复制架构不能完全消除在极端情况下丢失已确认写入数据的可能性。 这是因为 Redis 主从复制默认是**异步(asynchronous)**的:
-
主节点在将写操作传播给从节点之前就可能回复客户端成功。
-
如果主节点在写操作传播到足够多从节点之前发生故障,且无法恢复,那么这个已向客户端确认的写操作就会永久丢失(即使后续选出的新主节点是最新的从节点)。哨兵对此无能为力。若需更高数据安全性,需考虑半同步复制(Redis 企业版支持)或更高级别持久化策略,但这通常伴随性能开销。
-
-
无法扩展数据容量: 哨兵 + 主从复制架构本身并不能增加 Redis 的数据存储容量。 所有数据副本(主节点和从节点)都存储完全相同 的全量数据集。因此,整个集群能存储的数据量受限于单个节点(通常是主节点)的最大内存容量。
- 容量瓶颈: 当业务数据量接近或超过单台服务器的物理内存容量时,这种架构将无法满足需求,会面临内存不足(OOM)、性能急剧下降或服务不可用等问题。
-
为了解决单机内存容量瓶颈问题,Redis 引入了 Redis Cluster(集群) 模式。
至于集群,我们下篇文章再讲解。