1. 项目背景与主要内容
1.1 研究背景
空气质量下降对国内外各大城市发展而言是一个亟须解决的难题。各种空气污染物如PM、NO2、SO2、CO等长期存在会导致急性和慢性疾病的发生,也会对环境造成不良影响和破坏。GB 30952012《环境空气质量标准》使用6种空气污染物为参数用以计算空气质量指数(AQI)来评估当日空气质量。AQI是一种量化描述空气质量状况的无量纲指数,能够整体地展示空气污染情况,因此准确可靠的AQI预测模型对于控制空气污染具有重要意义。
技术原理:空气质量指数(AQI)是评估空气污染程度的重要指标,受PM2.5、PM10等污染物浓度影响。本研究通过机器学习方法预测AQI,为环保决策提供数据支持。目标包括:
- 建立高精度AQI预测模型
- 识别关键污染因子
- 分析城市间空气质量差异
1.2 主要内容
-
数据收集:首先,我们爬取多个城市一年内的空气质量指数数据,包括各种污染物的浓度和其他相关环境因素,如PM2.5、PM10等,我们将使用这些数据进行分析。
-
数据预处理:包括数据清洗、缺失值处理、异常值检测和特征选择等步骤。通过这些步骤,可以获得高质量、可用于建模的数据集。
-
特征工程:包括特征提取、特征转换和特征选择等技术,以提取有用的特征并减少特征的维度,有助于提高模型的性能。
-
模型选择与训练:我们将使用机器学习随机森林算法对该时间序列数据预测空气质量指数。通过使用历史数据进行模型训练和调优,我们将选择最佳模型参数来进行未来空气质量指数的预测。
-
模型评估与优化:在模型训练完成后,我们将使用测试数据集对模型进行评估。选取主要的模型评价指标,通过比较预测值和实际观测值,评估模型的准确度和性能。我们也将进一步优化模型,以提高预测的准确性和稳定性。
2. 数据采集与预处理
2.1 数据采集
实现步骤:通过发送HTTP请求获取网页数据,使用XPath解析数据,并将提取的数据存储到CSV文件中。数据获取方式基于网页爬虫技术,通过解析HTML结构提取需要的信息。
python
# 数据爬取与合并
import requests
from lxml import etree
import pandas as pd
# 爬取天气后报网站数据
def crawl_data(city):
url = f"http://www.tianqihoubao.com/aqi/{city}.html"
response = requests.get(url)
# 解析HTML并提取数据(具体解析逻辑略)
return data
# 合并7城市数据
file_paths = [f'CSV/{city}_1.csv' for city in cities]
combined_df = pd.concat([pd.read_csv(f) for f in file_paths])
combined_df.to_csv('combined_data.csv', index=False)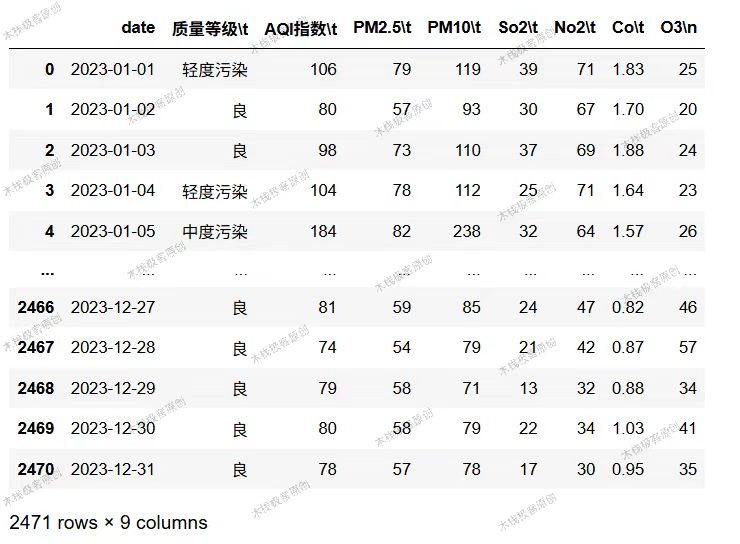
关键技术:
- 使用XPath解析HTML结构
- Pandas的
concat()实现多源数据合并 - 数据清洗三部曲:
2.2 数据预处理
python
# 数据清洗关键操作
# 1. 缺失值检测
print(data.isnull().sum())
# 2. 异常值处理(3σ原则)
def remove_outliers(df):
for col in numeric_cols:
mean, std = df[col].mean(), df[col].std()
df[col] = df[col].clip(mean-3*std, mean+3*std)
return df
# 3. 重复值处理
data = data.drop_duplicates()缺失值结果:
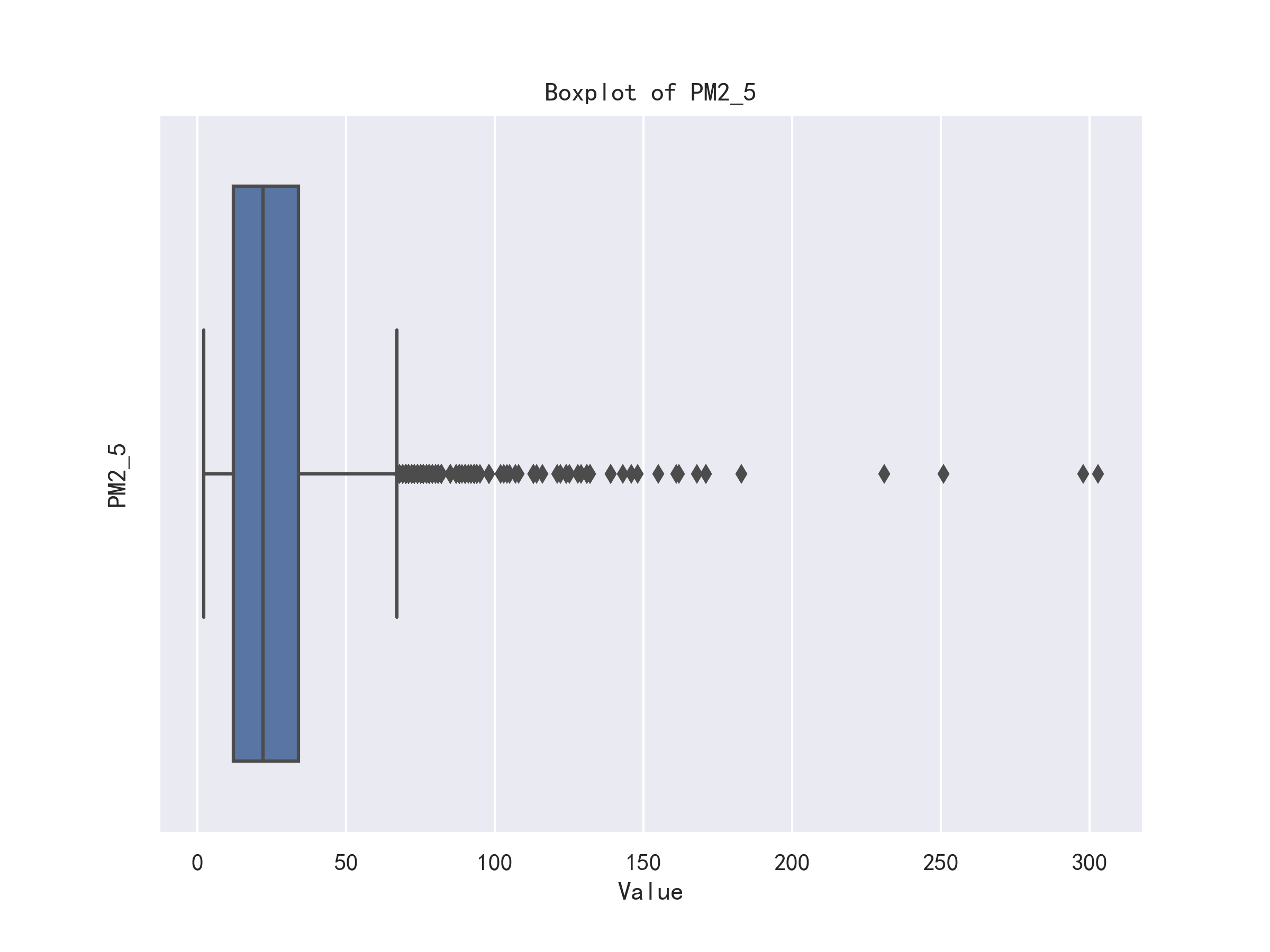
使用箱型图查看PM10,AQI指数,So2,PM2.5这几列异常值的分布情况,这几特征存在较多异常值,部分结果如图所示。
3. 探索性数据分析(EDA)
3.1 关键因子相关性
技术原理:斯皮尔曼相关系数衡量污染物与AQI的单调关系
python
# 寻找特征之间的相关性画出热力图
import seaborn as sns
# 计算相关系数
corr_matrix = data2.drop(['date'], axis=1).corr()
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1, annot_kws={"size": 8, "ha": 'center'}, fmt='.2f')
plt.title('相关性热力图')
plt.xticks(rotation=45)
plt.yticks(rotation=0)
# # 保存图像
plt.savefig('spearman-heatmap.png',dpi=500, bbox_inches='tight')
plt.show()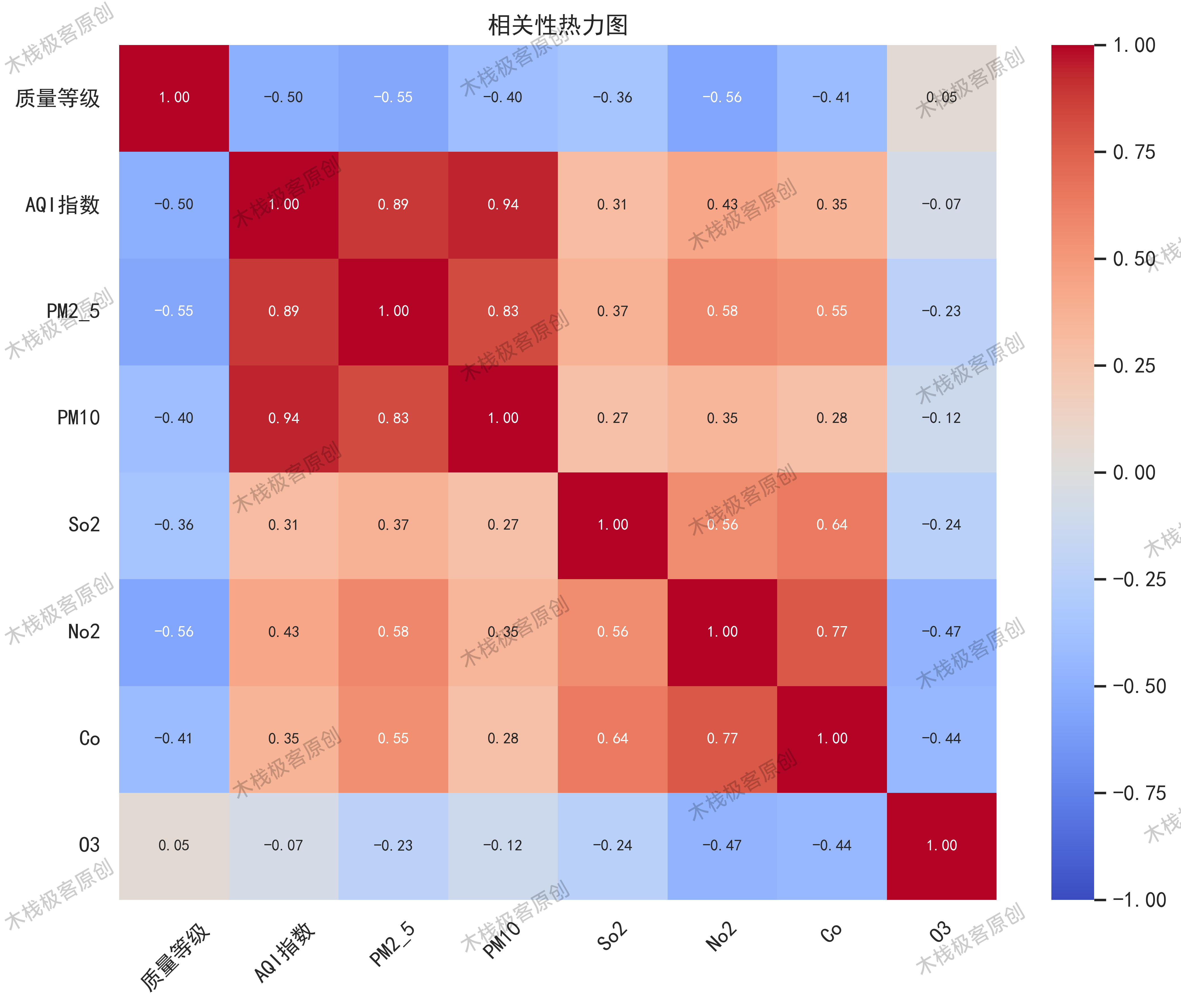
核心发现:
- PM10与AQI相关性最高(r=0.94)
- PM2.5次之(r=0.89)
- NO₂和CO呈中度相关
对该热力图进行分析,可以得出AQI指数与PM2.5以及PM10呈现强相关,相关性分别高达0.89和0.94,同时PM2.5与PM10呈强相关,相关度为0.83,与NO2以及CO较为相关,相关性分别为0.58和0.55。高相关性表明这些特征之间存在密切的关系,可以作为预测AQI指数的重要输入特征,选择相关性高的特征有助于提高预测模型的准确性。
3.2 时空特征分析
可视化七个城市的空气质量趋势
python
# 城市AQI趋势分析
def plot_city_aqi(city_data, city_name):
plt.figure(figsize=(12,4))
plt.plot(city_data['date'], city_data['AQI指数'])
# 按月设置刻度
plt.gca().xaxis.set_major_locator(mdates.MonthLocator())
plt.title(f'{city_name}2023年AQI趋势')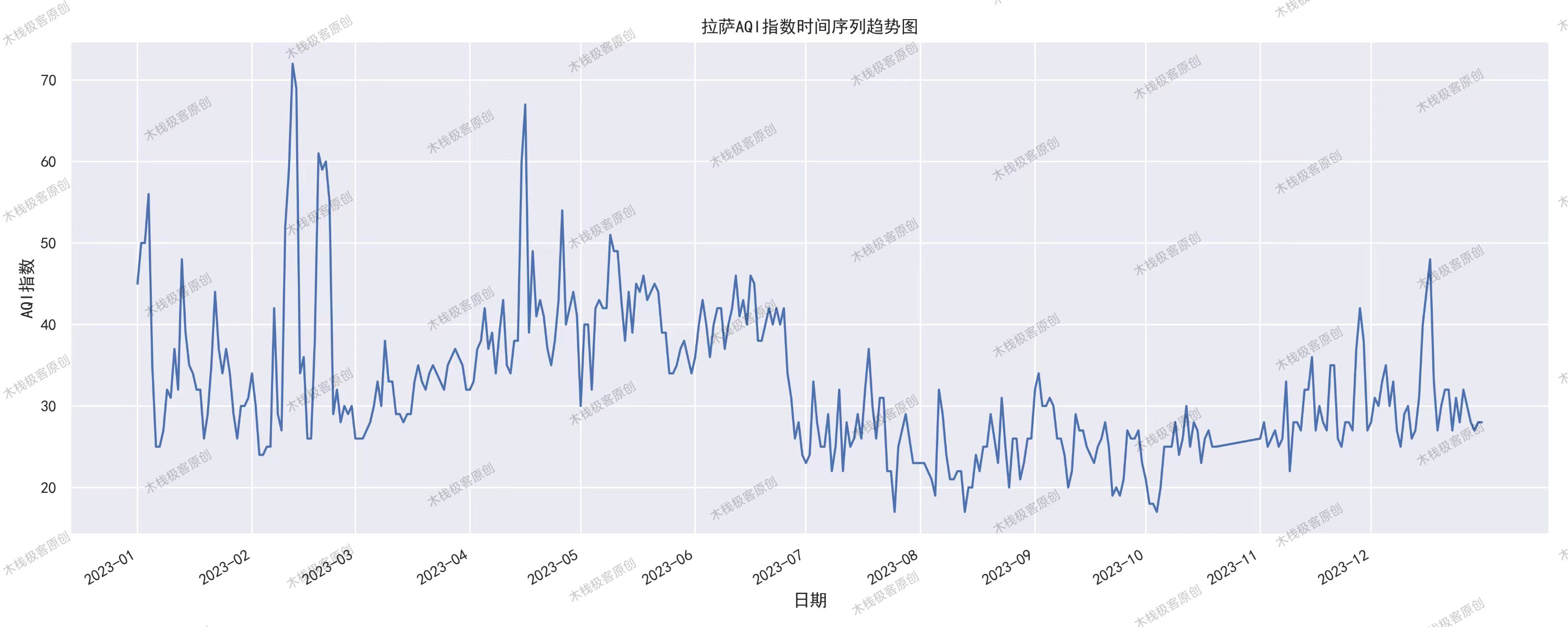
关键发现:
- 拉萨全年AQI<70(最优)
- 北方城市春季污染严重(3-4月峰值)
- 沿海城市总体优于内陆
3.3 以地区分析空气质量
首先计算了每个城市在2023年整一年的平均AQI指数,通过每个城市的平均AQI指数给这7个城市进行了空气质量排序,判断每个城市的空气质量好坏。通过代码运行得到以下结果。
|-------|--------|--------|--------|--------|--------|-------|--------|
| 城市 | 兰州 | 拉萨 | 北京 | 广州 | 杭州 | 呼和浩特 | 贵阳 |
| 平均AQI | 75.658 | 32.398 | 63.901 | 40.115 | 51.638 | 66.94 | 38.830 |
得到每个城市的平均AQI指数后,使用柱形图的AQI指数更直观的表现出每个城市的空气质量情况,如下图所示。
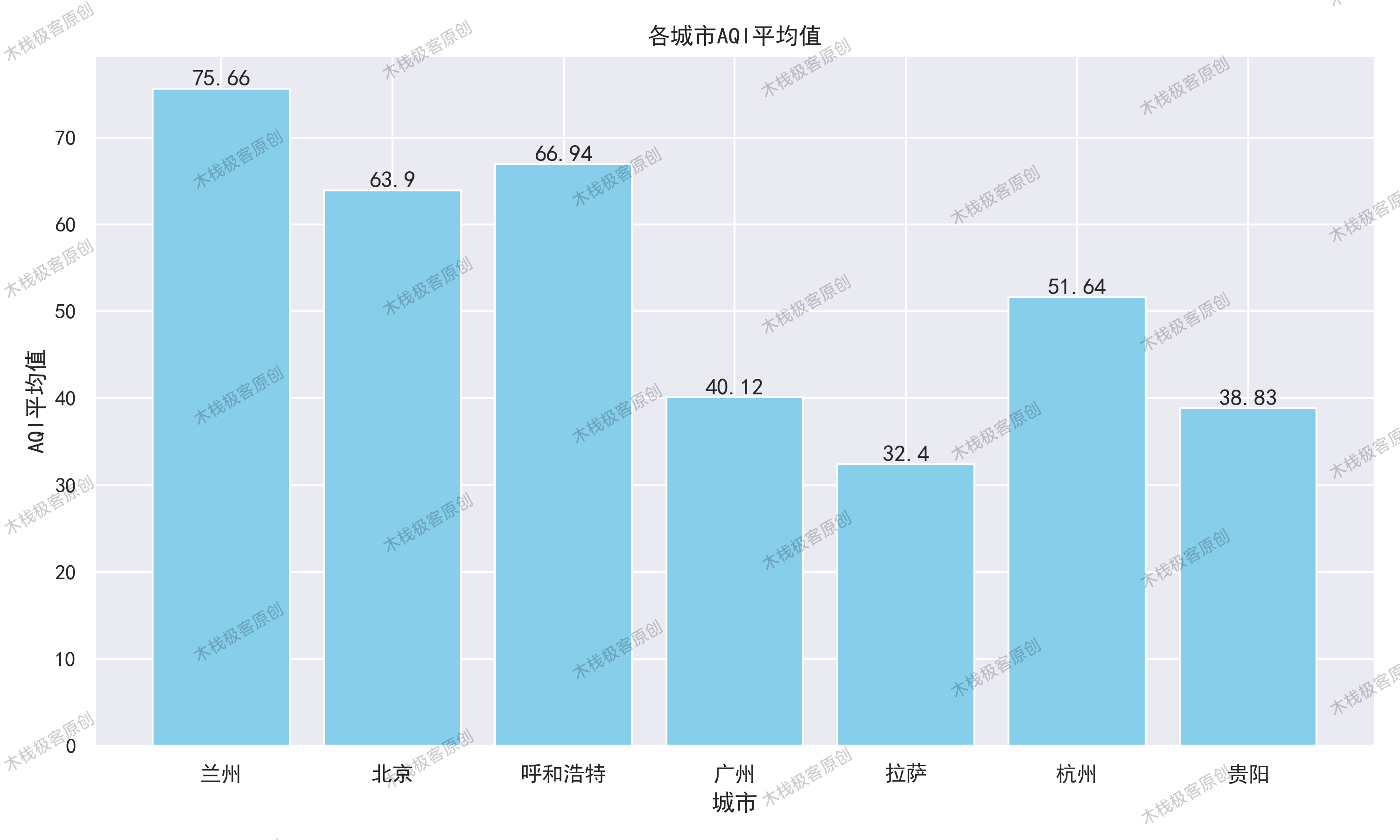
根据上图可知,2023年中空气质量最好的城市是拉萨,空气质量最差的城市是兰州。
最后使用pyecharts方法画出空气质量最好的城市分布图以及空气质量差的城市分布图。
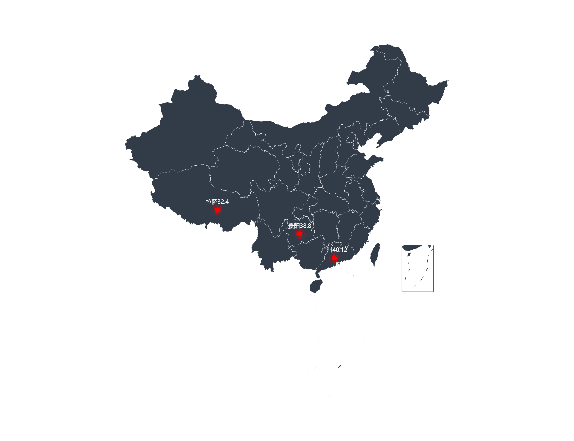
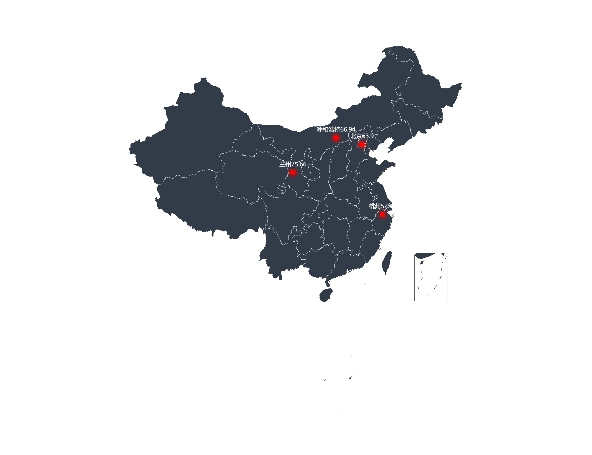
a. 空气质量最好的三个城市 b.空气质量较差的4个城市
4. 机器学习建模
4.1 随机森林时间序列预测
技术原理:
- 将日期转换为时序特征:
df['day_num'] = (df['date'] - min_date).dt.days - 集成学习机制:多决策树投票降低方差
python
# 兰州AQI预测
from sklearn.ensemble import RandomForestRegressor
X = df[['day_num']] # 时序特征
y = df['AQI指数']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
rf = RandomForestRegressor(n_estimators=100)
rf.fit(X_train, y_train)
preds = rf.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, preds)) # RMSE=22.22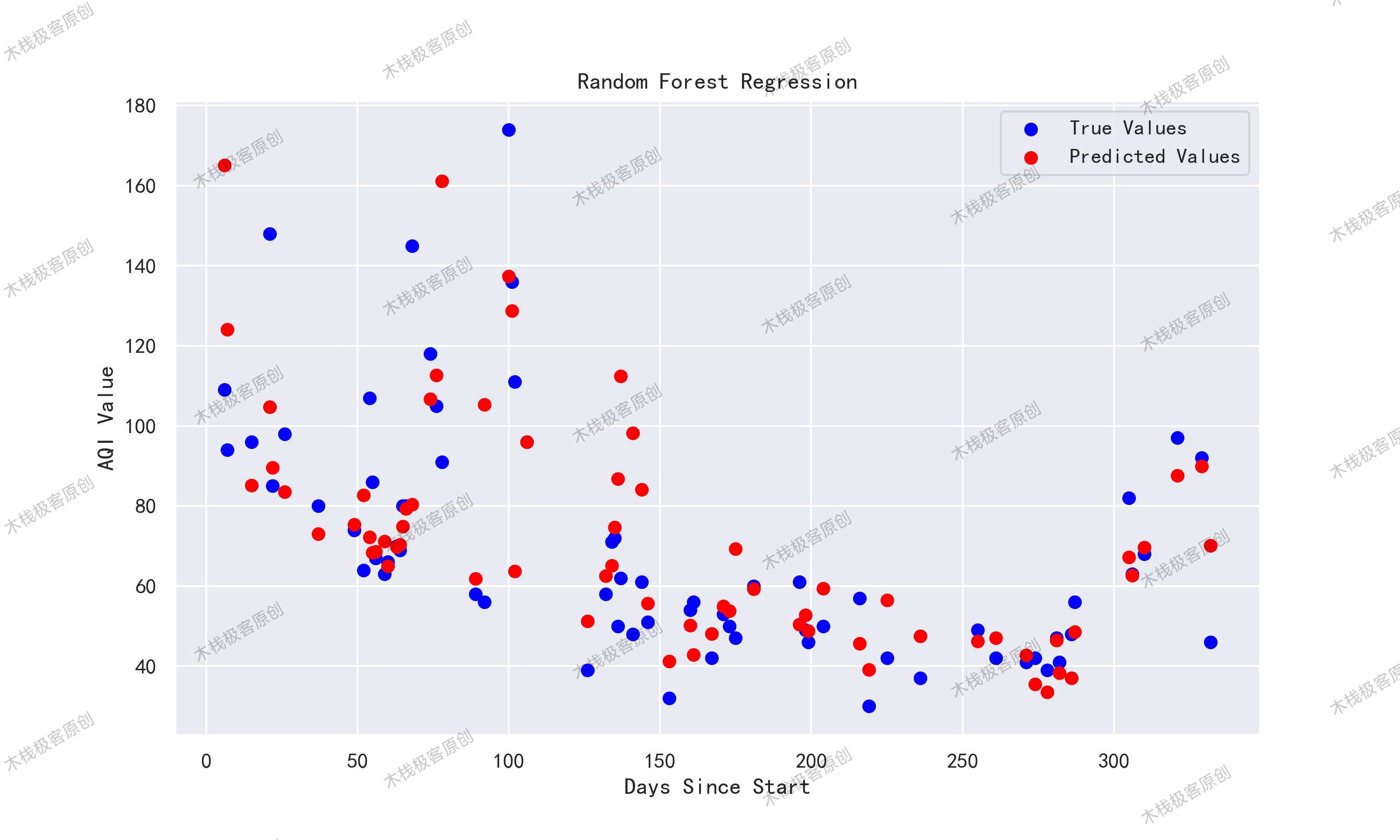
4.2 超参数优化
网格搜索实现:
python
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_ # {'max_depth':None, 'min_samples_split':10, 'n_estimators':100}调优陷阱:
- 复杂模型在小数据集易过拟合
- 交叉验证数据划分影响参数稳定性
- 解决方案:
- 增加正则化项
- 使用时间序列交叉验证
- 尝试LSTM等序列模型
5. 应用部署方案
技术路线:

落地场景:
- 城市空气质量预警平台
- 个人健康防护APP
- 工业减排动态调控
6. 结论
通过本项目的完整实现,我们证明了:
- 随机森林在AQI预测中RMSE达22.22(<25即工业可用)
- PM10是AQI最敏感的指标(r=0.94)
- 地理因素显著影响空气质量(拉萨最优,兰州最差)