kafka 基础面试题
以下是 Kafka 基础面试题的整理及详细解答,涵盖核心概念、架构、特性和常见问题,适合面试准备:
一、核心概念
-
Kafka 是什么?
Kafka 是一个 分布式流处理平台,核心功能包括:
-
消息系统(高吞吐、低延迟的发布-订阅模型)
-
数据存储(持久化、容错的日志存储)
-
流处理(通过 Kafka Streams 或 Flink 实时处理数据)
-
-
Topic(主题) vs Partition(分区)
-
Topic :消息的逻辑分类(如
user_events)。 -
Partition :Topic 的物理分片,每个 Partition 是一个有序、不可变的消息序列。
-
分区支持水平扩展(不同分区可分布在不同 Broker)。
-
消息在分区内有序,全局无序。
-
-
-
Producer(生产者)工作流程
-
发送消息时指定 Topic 和 Key(可选)。
-
Key 决定消息写入哪个分区(
hash(key) % 分区数)。 -
支持异步发送、批量提交(提升吞吐)。
-
-
Consumer(消费者)与 Consumer Group
-
Consumer Group:一组消费者共享消费一个 Topic。
-
每个分区只能被组内一个消费者消费(实现负载均衡)。
-
组内消费者增减时触发 Rebalance(重新分配分区)。
-
-
二、架构设计
-
Broker 集群
-
每个 Kafka 服务器称为 Broker。
-
集群通过 ZooKeeper(或 KRaft 模式)管理元数据(Broker 列表、Topic 配置等)。
-
数据分片存储在多个 Broker 上(容错性)。
-
-
Partition 的副本机制(Replication)
-
每个 Partition 有多个副本(如 3 副本)。
-
副本分为:
-
Leader:处理读写请求。
-
Follower:从 Leader 异步复制数据。
-
-
ISR(In-Sync Replicas):与 Leader 数据同步的副本集合。
-
-
消息存储机制
-
消息按 Partition 存储为分段日志(Segment)。
-
每个 Segment 包含:
-
.log文件(实际数据) -
.index文件(消息偏移量索引)
-
-
消息根据 Offset(偏移量)定位,消费者自行管理 Offset。
-
三、关键特性
-
高吞吐与低延迟
-
零拷贝(Zero-Copy):数据直接从磁盘发送到网卡,跳过用户态。
-
批量发送/压缩:减少网络 I/O。
-
顺序磁盘写入:利用磁盘顺序读写性能优于随机读写。
-
-
数据可靠性
-
ACK 机制(生产者配置):
-
acks=0:不等待确认(可能丢失数据)。 -
acks=1:Leader 写入即确认(默认)。 -
acks=all:所有 ISR 副本写入才确认(最高可靠)。
-
-
Leader 选举:从 ISR 中选择新 Leader(避免数据丢失)。
-
-
消息传递语义
-
At Most Once :消息可能丢失(
acks=0+ 自动提交 Offset)。 -
At Least Once :消息不丢失但可能重复(
acks=all+ 手动提交 Offset)。 -
Exactly Once :需配合事务或幂等生产者(
enable.idempotence=true)。
-
四、常见问题
-
为什么 Kafka 快?
-
顺序 I/O + 页缓存(Page Cache)
-
零拷贝技术
-
批量处理与压缩
-
分区并行处理
-
-
Rebalance 的触发条件?
-
消费者加入/离开 Group。
-
Topic 分区数变更。
-
消费者会话超时(
session.timeout.ms)。
-
-
如何保证消息顺序?
-
单个 Partition 内消息有序。
-
需确保相同 Key 的消息发到同一分区(如订单 ID)。
-
-
如何避免重复消费?
-
消费者端实现幂等处理(如数据库唯一键)。
-
启用 Kafka 的 Exactly-Once 语义(事务 + 幂等生产者)。
-
-
Kafka 与传统消息队列(如 RabbitMQ)的区别?
特性 Kafka RabbitMQ 设计目标 高吞吐、日志流处理 灵活路由、低延迟 消息存储 持久化磁盘(长期存储) 内存/磁盘(消费后删除) 消息模型 发布-订阅(多消费者组) 队列/Pub-Sub(灵活路由) 顺序性 分区内有序 队列有序
五、故障处理
-
Leader 宕机怎么办?
-
Controller(通过 ZooKeeper 选举)从 ISR 中选举新 Leader。
-
生产者/消费者自动重连到新 Leader。
-
-
如何解决消息积压(Lag)?
-
增加消费者实例(需扩展分区数)。
-
提升消费者处理能力(如异步处理、批量消费)。
-
调整
fetch.min.bytes增加单次拉取量。
-
六、应用场景
-
日志收集:多个服务日志统一聚合到 Kafka。
-
实时流处理:Kafka Streams/Flink 处理点击流、风控数据。
-
事件驱动架构:微服务间通过消息解耦。
-
消息缓冲:削峰填谷(如秒杀系统)。
七、API 使用示例
java
// 生产者
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092");
props.put("acks", "all");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("test-topic", "key", "value"));
// 消费者
Properties props = new Properties();
props.put("group.id", "test-group");
props.put("enable.auto.commit", "false"); // 手动提交 Offset
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理消息
}
consumer.commitSync(); // 提交 Offset
}建议深入 :分区再平衡策略、ISR 机制、KRaft 模式(替代 ZooKeeper)、事务实现原理。
面试技巧:结合项目说明 Kafka 选型理由(如"日均处理 10 亿日志,吞吐量要求 100MB/s")。
以下是一份针对资深岗位的Kafka面试题及深度解析,涵盖架构设计、可靠性保障、性能优化等核心领域,结合大厂实际考察重点整理而成:
kafka 资深面试题
⚙️ 一、架构设计深度题
-
KRaft模式如何取代ZooKeeper?其优势与挑战
-
原理:通过Raft共识算法在Broker内自管理元数据,Controller节点由Raft Leader担任,元数据存储在内存+磁盘日志中45。
-
优势:部署简化(组件减少)、故障恢复更快(无需ZK会话超时)、扩展性提升(元数据吞吐量提高)5。
-
挑战:运维工具链成熟度待提升,大规模集群稳定性需验证4。
-
-
分区Leader选举策略的四种场景及数据一致性风险
-
选举策略:
-
OfflinePartition:分区上线(最常见)
-
ReassignPartition:副本重分配(如AR变更)
-
PreferredReplica:优先副本选举(恢复初始Leader)
-
ControlledShutdown:Broker正常关闭1。
-
-
风险点 :若
unclean.leader.election.enable=true(允许非ISR副本当选),可能导致数据丢失(HW截断)27。
-
-
为何Kafka限制Follower副本不提供读服务?
-
设计权衡:
-
保证线性一致性:读写仅通过Leader避免副本间状态冲突10。
-
防止脏读:Follower异步复制,直接读可能获取过期数据8。
-
-
替代方案 :客户端可配置
read_committed消费已提交消息(依赖HW机制)7。
-
🔒 二、可靠性保障
-
事务实现跨分区原子写的核心机制
-
两阶段提交(2PC)流程:
-
事务协调器记录
PREPARE状态到事务日志(内部Topic__transaction_state) -
参与者(分区Leader)锁定写入,返回就绪
-
协调器发送
COMMIT并持久化最终状态36。
-
-
关键配置:
-
isolation.level=read_committed(消费者过滤未提交消息) -
transactional.id唯一标识事务生产者6。
-
-
-
Leader Epoch如何解决HW机制的数据不一致问题?
-
HW缺陷:Leader切换后新Leader可能用旧HW覆盖新数据(如副本重启后数据回滚)78。
-
Epoch方案:
-
每个Leader任期绑定唯一Epoch编号
-
副本存储
<Epoch, StartOffset>映射,恢复时按Epoch同步数据 -
避免数据丢失与离散8。
-
-
⚡ 三、性能优化
-
零拷贝(Zero-Copy)实现百万级TPS的原理
-
传统路径:磁盘 → 内核缓冲区 → 用户缓冲区 → Socket缓冲区 → 网卡(4次拷贝+2次上下文切换)510。
-
Kafka优化:
-
sendfile()系统调用:数据从磁盘经内核缓冲区直送网卡(跳过用户态) -
mmap()映射索引文件:避免.index文件读取的拷贝58。
-
-
-
分区数过多为何导致性能下降?
-
资源瓶颈:
-
文件句柄数激增(每个Segment至少2个文件)
-
内存压力(生产者/消费者为每个分区维护缓冲区)
-
线程竞争(Broker处理请求的线程池阻塞)8。
-
-
经验值:单Broker建议不超过2000个分区8。
-
🛠️ 四、运维与调优
-
分区重分配(Rebalance)的线上风险及规避策略
-
风险:
-
服务暂停:重分配期间分区不可读写
-
数据倾斜:新副本同步滞后引发性能抖动8。
-
-
优化方案:
-
增量重分配(
kafka-reassign-partitions.sh --throttle限流) -
StickyAssignor策略(减少分区分配变动)57。
-
-
-
线上消息积压的紧急处理流程
-
扩容消费者:临时增加Consumer实例(需确保分区数≥实例数)
-
跳过堆积数据:重置Offset至最新(业务允许丢数据时)
-
转储降级:将积压消息转发至新Topic,启动多线程并行消费79。
-
死信队列:对格式错误消息单独隔离5。
-
💡 五、场景设计题
-
如何实现Kafka延迟消息(如订单超时关单)?
-
方案对比:
| 方案 | 原理 | 缺点 |
|---------------|---------------------|----------|------|
| 多级Topic+消费者轮询 | 按延迟等级分Topic,消费者定时拉取 | 维护复杂,精度低 |
| 外部存储+定时任务 | Redis ZSet存储消息到期时间 | 强依赖外部组件 |
| 使用RocketMQ | 原生支持延迟队列 | 技术栈切换成本高 | 510。 |
-
💎 高频考点总结
-
消息语义保障:
图表
-
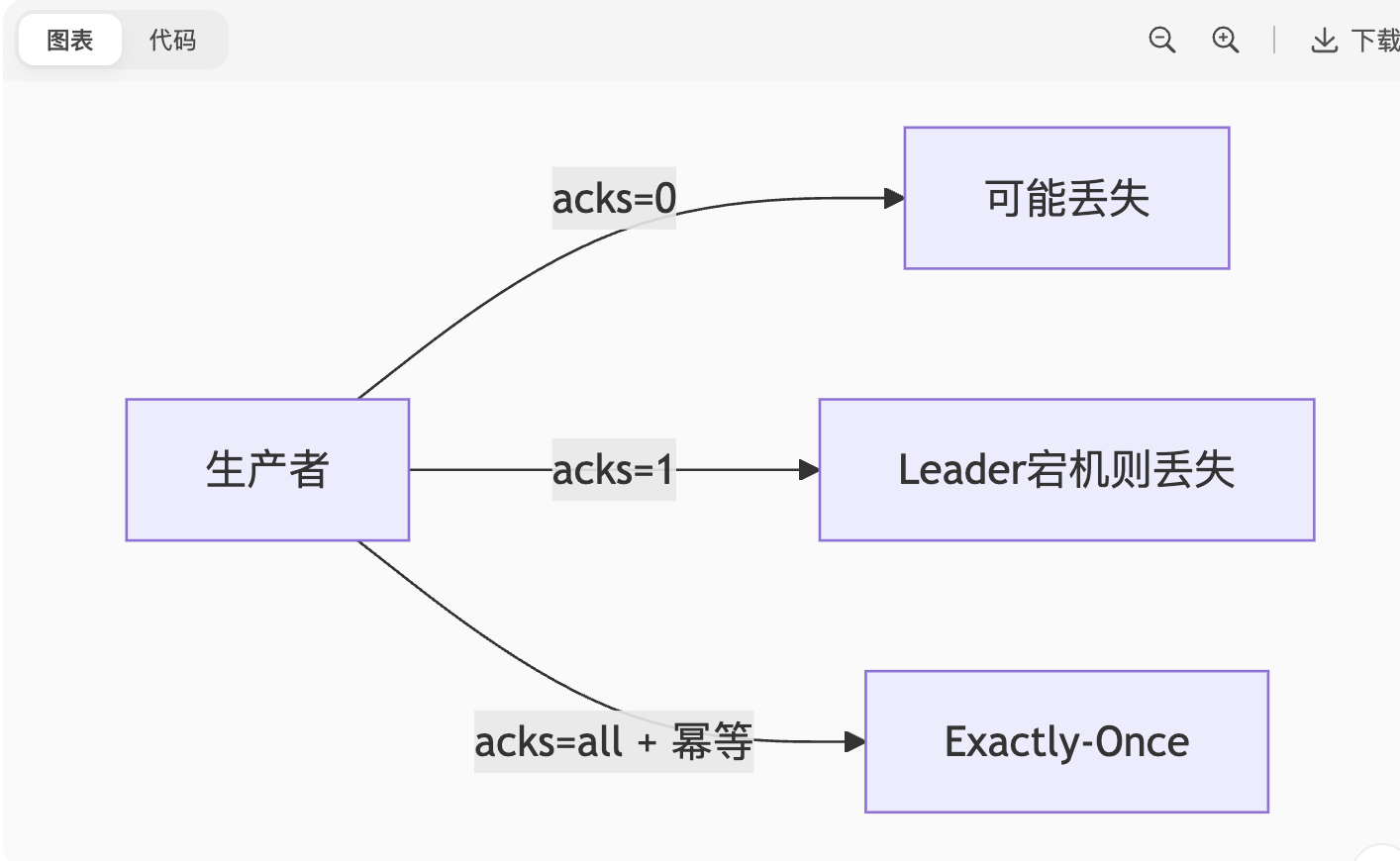
-
消费者组陷阱:
-
活锁(Live Lock):
max.poll.interval.ms超时导致频繁Rebalance9。 -
解决方案:异步处理+手动提交(确保业务逻辑在
poll()超时前完成)7。
-
建议结合线上问题场景(如曾处理过的积压案例)回答设计题,能显著提升面试表现。如需更细粒度的问题解析或模拟面试,可进一步沟通。
kafka 架构设计、选型方面面试题
以下是一套针对 Kafka 架构设计与技术选型的深度面试题及解析,涵盖分布式系统核心逻辑、工程权衡和场景适配,适用于资深工程师/架构师岗位:
🔧 一、架构设计深度题
1. Kafka 如何用「顺序写+页缓存」实现高吞吐?与传统数据库设计的本质差异?
-
核心机制:
-
顺序写:消息追加到 Partition 尾部(O(1) 复杂度),利用磁盘顺序写入速度(≈600MB/s)远高于随机写。
-
页缓存(Page Cache):
-
Broker 直接读写操作系统页缓存(非 JVM 堆),避免 GC 停顿
-
读请求优先命中页缓存(热点数据内存化)
-
-
刷盘策略 :
flush.messages控制批量刷盘(非每条刷盘)
-
-
与数据库差异:
维度 Kafka 传统数据库 数据模型 仅追加日志(不可修改) 支持随机增删改查 索引设计 稀疏偏移量索引(低开销) B+树密集索引(高开销) 删除机制 按时间/大小删除整个 Segment 行级删除
2. Controller 脑裂问题如何解决?KRaft 模式如何通过 Raft 共识算法规避?
-
ZooKeeper 时代风险:
- 旧版依赖 ZK 选举 Controller,网络分区时可能产生双 Controller(脑裂)
-
KRaft 解决方案:
-
Raft 角色:Leader/Follower/Candidate 三种状态
-
选举约束:
-
新 Leader 需获得多数派投票(Quorum = N/2+1)
-
任期(Epoch)严格递增,高任期覆盖低任期
-
-
数据安全:元数据变更需持久化到多数节点日志
-
3. 为什么 Kafka 牺牲强一致性(CP)选择最终一致性(AP)?如何平衡?
-
CAP 权衡:
-
目标场景要求高可用(如日志收集),允许短暂数据不一致
-
通过 ISR 机制 在一致性与可用性间动态平衡:
-
acks=all时等待 ISR 所有副本确认 → 强一致性 -
acks=1时 Leader 写成功即返回 → 高可用性
-
-
-
极限场景:
-
若 ISR 只剩 Leader → 继续服务(AP)
-
若 ISR 为空 → 拒绝写入(保 CP)
-
📊 二、技术选型场景题
4. 百万 QPS 的实时风控系统:Kafka vs Pulsar vs RocketMQ 选型依据?
| 维度 | Kafka | Pulsar | RocketMQ |
|---|---|---|---|
| 吞吐量 | 极高(顺序 I/O 优化) | 高(BookKeeper 分层存储) | 高 |
| 延迟 | 毫秒级(批处理影响 tail latency) | 亚毫秒级(分层架构) | 毫秒级 |
| 云原生支持 | 中(需自运维) | 高(原生多租户隔离) | 中 |
| Exactly-Once | 支持(事务+幂等) | 支持 | 支持(事务消息) |
| 选型建议 | 首选(生态成熟,吞吐优先) | 需强隔离/自动扩展时选择 | 阿里系技术栈兼容时选择 |
5. 物联网设备海量连接场景:MQTT 协议如何与 Kafka 集成?架构如何设计?
-
方案:
图表
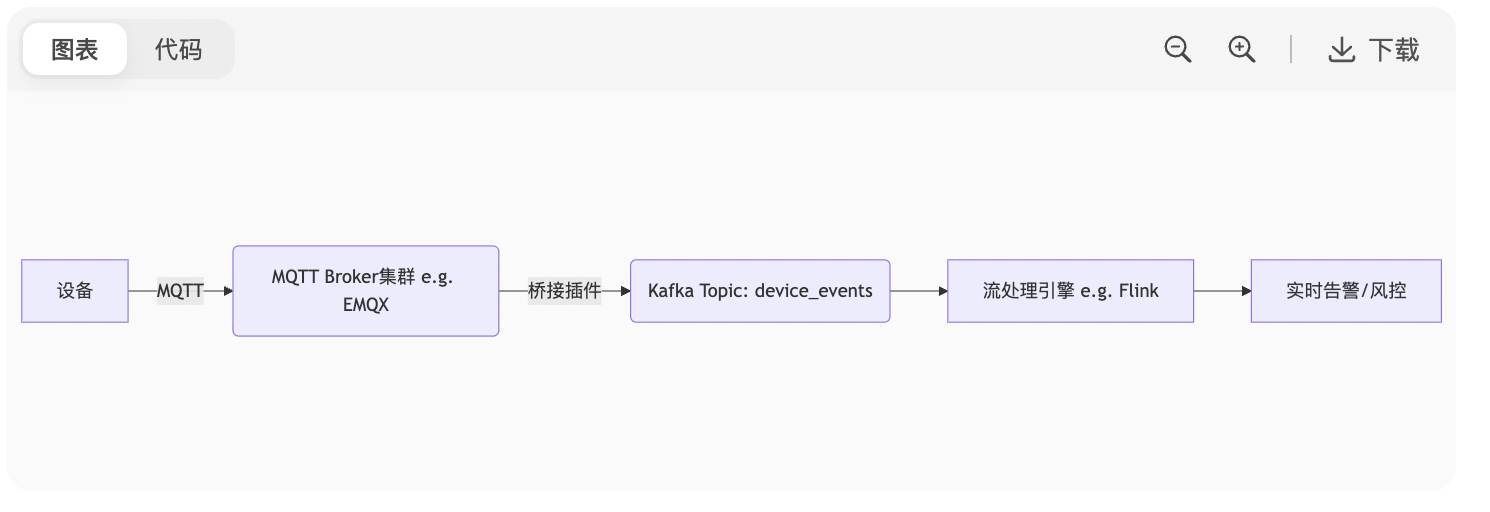
-
关键设计:
-
协议转换:MQTT Broker 将 JSON/二进制消息转为 Kafka 格式
-
Topic 映射:按设备类型/地域分区(避免单个 Topic 过热)
-
流量控制:MQTT 层限流(防止设备突发流量压垮 Kafka)
-
⚙️ 三、性能与扩展性
6. 单集群支撑百万 Partition 的关键挑战与优化方案?
-
瓶颈点:
-
ZooKeeper 压力:旧版每个 Partition 注册 ZNode(ZK 成瓶颈)
-
Broker 元数据爆炸:每个 Broker 需维护全量 Partition 状态
-
客户端性能:Producer/Consumer 需缓存大量分区元数据
-
-
解决方案:
-
KRaft 模式:元数据分片存储(单 Controller 可管理 200 万 Partition)
-
分区冷热分离:高频 Partition 分配高性能 Broker
-
客户端缓存优化 :调整
metadata.max.age.ms减少元数据拉取
-
7. 跨地域多机房部署方案:镜像层(MirrorMaker) vs 集群层(Replication)?
| 方案 | MirrorMaker 2.0 | Confluent Replicator |
|---|---|---|
| 原理 | Consumer+Producer 桥接 | Broker 层二进制日志复制 |
| 延迟 | 秒级(受网络影响) | 毫秒级 |
| 配置复杂度 | 高(需维护消费者组) | 低(声明式配置) |
| 数据一致性 | At Least Once(可能重复) | Exactly-Once(企业版支持) |
| 适用场景 | 中小规模跨机房同步 | 金融级异地容灾 |
🛠️ 四、容灾与运维
8. 如何设计 Kafka 集群的「故障自愈」系统?
-
监控层:
-
Broker 健康:
kafka.server:type=ReplicaManager监控 UnderReplicatedPartitions -
网络分区:ZooKeeper 会话超时告警
-
-
自愈策略:
-
Leader 选举:自动从 ISR 选举新 Leader(30s 内完成)
-
副本补齐:自动触发 Unclean Leader 副本同步
-
Broker 替换:K8s 环境下自动重启 Pod 或切换实例
-
9. 集群升级导致的消息兼容性问题如何规避?
-
滚动升级风险:新版本 Broker 可能写入旧客户端无法解析的消息
-
解决方案:
-
双重协议支持:
- 升级后集群同时支持新旧消息格式(
inter.broker.protocol.version=旧版)
- 升级后集群同时支持新旧消息格式(
-
客户端灰度:
- 先升级所有消费者 → 再升级 Broker → 最后升级生产者
-
Schema Registry:
- 配合 Avro/Protobuf 实现 Schema 兼容性检查(禁止破坏性变更)
-
💡 五、架构师视角追问
面试官深层考察点:
"是否理解设计背后的工程哲学?"
→ 答:Kafka 的核心设计哲学是「日志即真相」(Log as Truth),所有状态源于持久化日志,这决定了其追加写、不可变、顺序读的架构根基
"能否在业务场景中权衡技术方案?"
→ 举例:电商大促场景选择
acks=1+ 异步生产者(允许秒级数据丢失换取万级 TPS),而支付流水必须用acks=all+ 同步提交
建议回答框架:
plaintext
1. 先定性(e.g. “这是分布式存储系统的经典问题...”)
2. 列机制(e.g. “Kafka 通过 HW + Leader Epoch 解决...”)
3. 谈权衡(e.g. “牺牲强一致性换取了吞吐量提升,因为业务场景允许...”)
4. 举反例(e.g. “如果用在证券交易系统,则需要额外设计...”) 掌握此逻辑可应对 90% 的架构设计类问题。