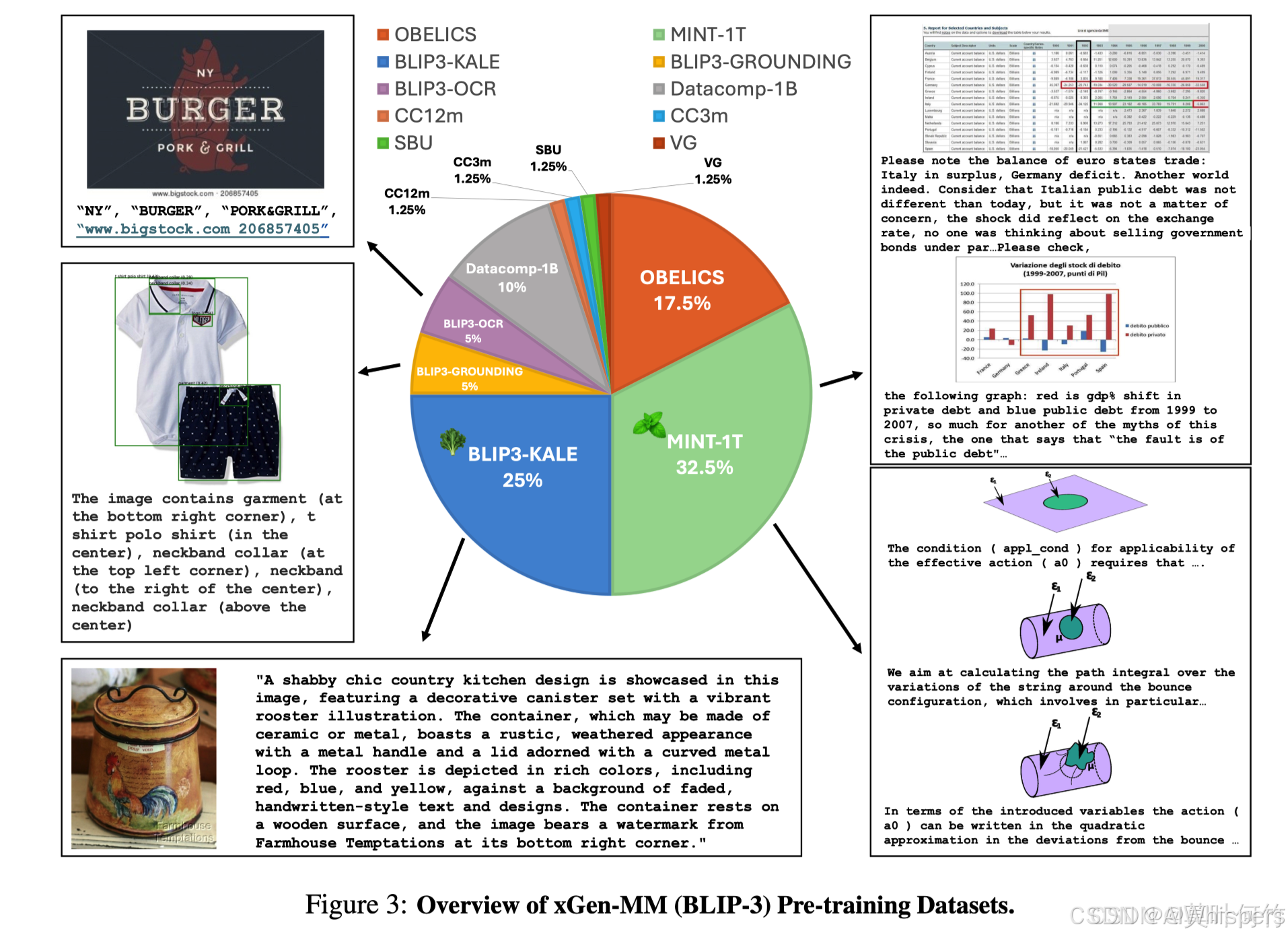
文章目录
BLIP3
今天学习一下BLIP3,BLIP3相对BLIP2做了比较大的改进,主要是针对BLIP2的下面几个问题:
1. 只支持单图像输入,不能算是一个自然的多模态交互形式
2. 损失函数由三部分组成,可能存在多任务目标不一致的情况。
3. 数据上,数据量小,多样性不足。
针对上述问题,我们来过一下BLIP3的核心内容。
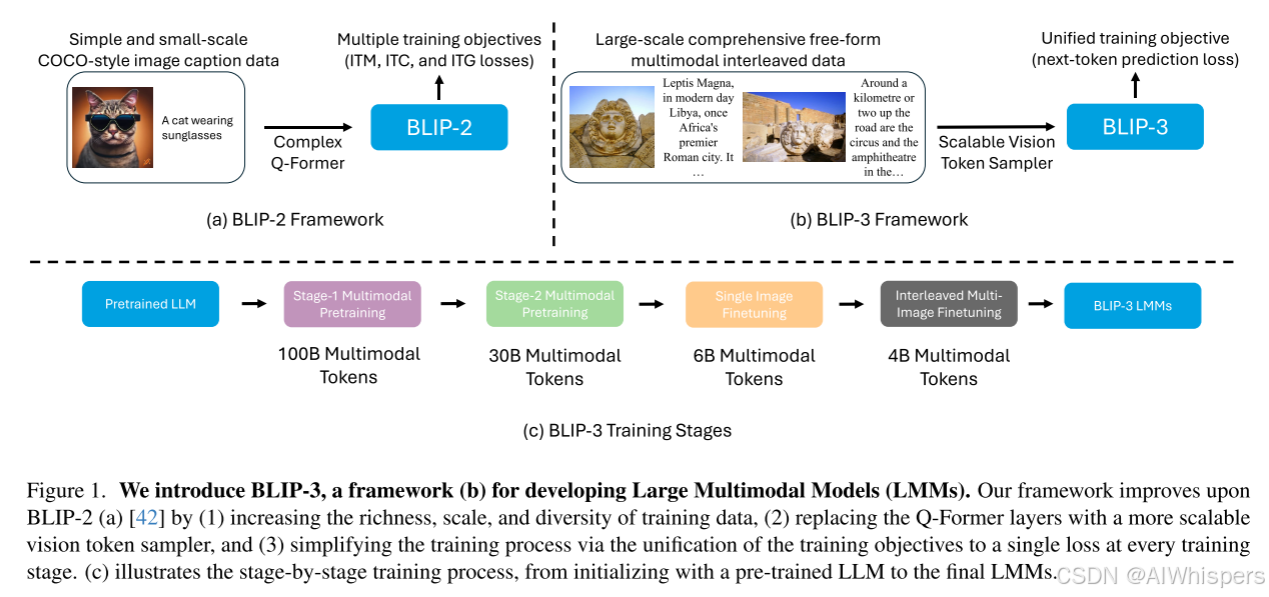
架构
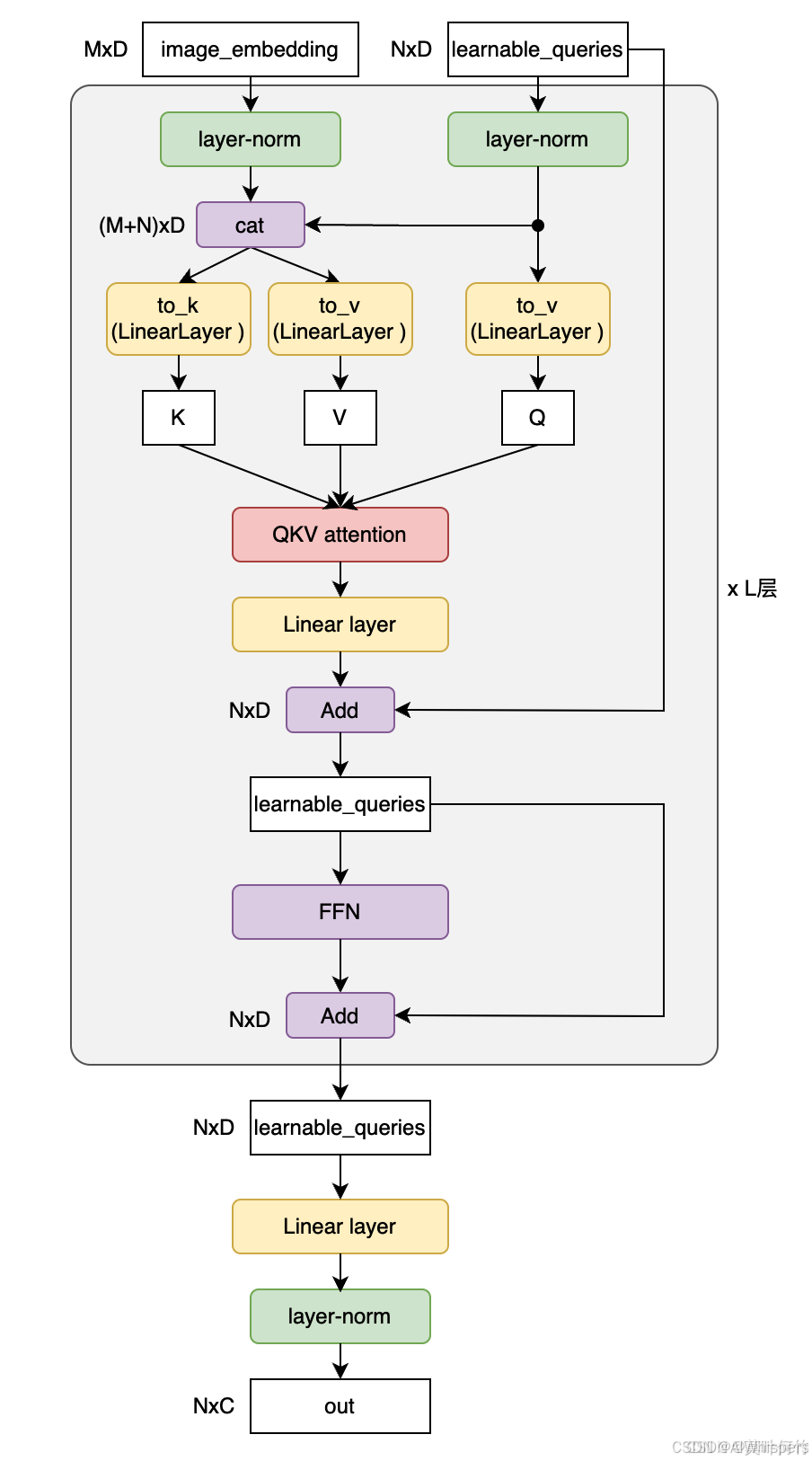
BLIP3舍弃了BLIP2提出的Q-Former架构,而是采用了Flamingo提出的Perceiver Resampler的做法,其实二者的核心都差不多,都是讲图像编码器得到的视觉token的输入再映射到一个固定数量的token。整体架构如图所示:
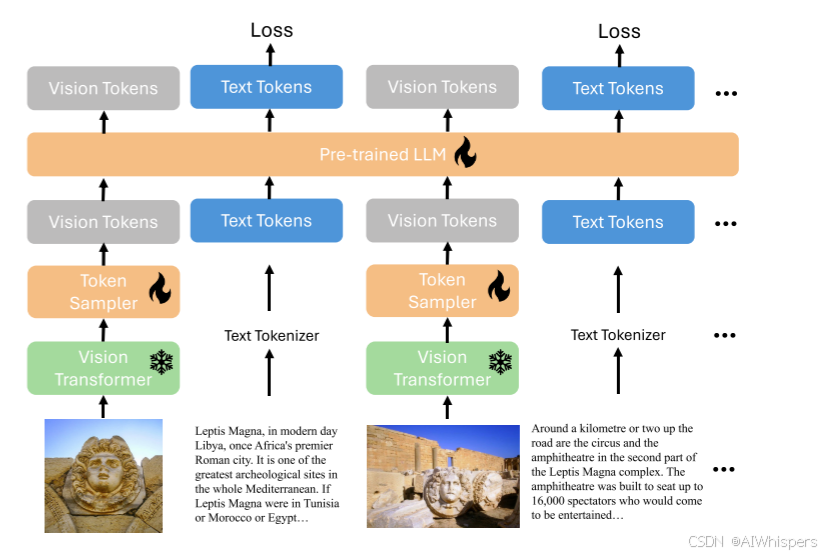
Any-Resolution Vision Token Sampling
任意分辨率视觉token采样:
- 首先匹配最近的分辨率
- 再进行切分patch,因为sigLIP的输入的分辨率是384x384,所以将一个768x768的图片切分为4个patch,外加一个resize的整体的patch,应该就是下采样,使其分辨率降低。所以总共有5个patch。
- 将这5个patch输入到视觉编码器,得到5x24x24xd=5x576xD.
- 然后将其输送到Perceiver Resampler得到5x128xD=640xD这个token数量的维度,然后再作为图像信息输进去
其实上述的核心就是图像信息更加细粒度了,另一个是不管任意分辨率,都能得到固定长度的图像表示。
这一点确实是合理的,如果直接输到视觉编码器里面,patch划分后是更粗粒度一些,但是也包含所有的信息,这种做法,其实也不是很理解。
训练
整个训练分为预训练,指令微调,DPO偏好对齐
数据
本文产生了大量的数据集。现在看来,最大的贡献其实就是数据集,整个的架构目前感觉用MLP连接更合理,也不需要将得到的视觉的token转换为一个固定的数量。