一、技术概述
1. LoRA(Low-Rank Adaptation)
具体讲解:
LoRA:高效的深度学习模型微调技术及其应用
LoRA微调的代码细节
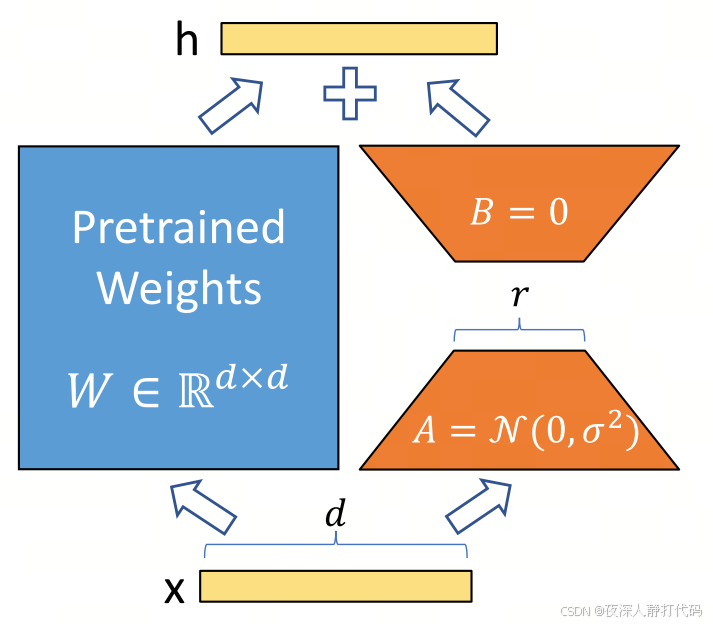
- 核心目标:通过轻量级微调让预训练模型(如 Stable Diffusion)"记住" 特定任务特征(如固定风格、角色、物体),无需全量微调。
- 模型结构 :
在预训练模型的关键层(主要是 Transformer 交叉注意力层的权重矩阵)中插入低秩分解模块。具体而言,将原权重矩阵 W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k分解为两个低秩矩阵 W A ∈ R d × r W_A \in \mathbb{R}^{d \times r} WA∈Rd×r 和 W B ∈ R r × k W_B \in \mathbb{R}^{r \times k} WB∈Rr×k,其中 r ≪ min ( d , k ) r \ll \min(d,k) r≪min(d,k)(通常取值为8至64)。通过 W + ( W A ⋅ W B ) W + (W_A \cdot W_B) W+(WA⋅WB)捕捉任务特征。原模型权重冻结,仅训练 W A W_A WA 和 W B W_B WB。 - 训练过程:
- 冻结预训练模型(如 Stable Diffusion)的全部原始权重,避免在后续训练中被更新;
- 针对特定任务(如 "梵高风格")准备训练数据(通常几十到几百张样本);样本筛选过程中,需确保数据多样性与质量,避免因样本单一引发的过拟合问题。
- 以文本提示(如 "a painting in Van Gogh style")为条件,仅优化低秩矩阵 W A W_A WA 和 W B W_B WB,通过反向传播不断调整这两个矩阵的参数,让低秩矩阵学习特定任务的特征;
- 训练完成后,仅保存低秩矩阵参数(通常几 MB 到几十 MB)。
- 推理过程:
- 加载原始预训练模型和训练好的 LoRA 低秩矩阵;
- 静态合并 ,将低秩矩阵的影响合并到原模型权重中,其数学表达式为:
W 合并 = W 原始 + W A W B W_{\text{合并}} = W_{\text{原始}} + W_A W_B W合并=W原始+WAWB动态调用,不直接修改原始模型权重,而是在推理时动态调用 LoRA 低秩矩阵,保留原始模型的完整性,允许根据不同的生成需求切换多种 LoRA 配置; - 向模型输入文本提示,模型生成符合 LoRA 训练目标的图像内容。例如,当 LoRA 矩阵是基于梵高绘画风格训练时,输入 "夜晚星空" 的文本提示,模型便能输出具有梵高笔触与色彩风格的星空图像 ;
- 关键特点 :
- 参数量极小(通常几 MB 到几十 MB),训练成本低;
- 需为每个任务(如 "梵高风格""特定角色")单独训练;
- 生成效果依赖训练数据质量,泛化性有限。
2. ControlNet
具体讲解:2023ICCV,《ControlNet:向文本到图像扩散模型添加条件控制》
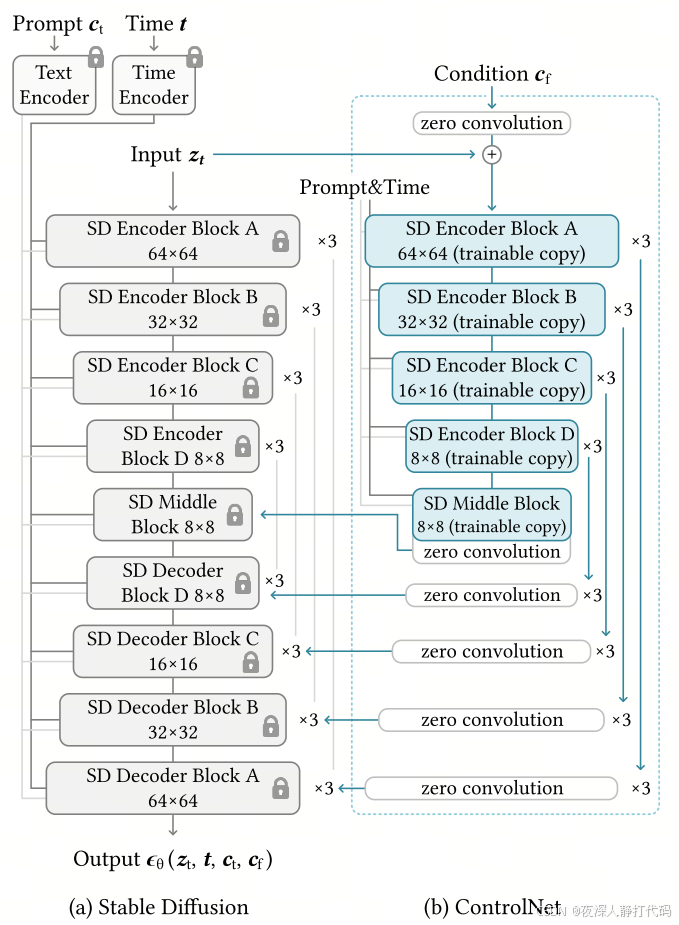
- 核心目标:精确控制生成图像的结构信息(如姿势、轮廓、深度、法线等),让模型 "按规则生成",解决文本提示难以控制细节的问题。
- 模型结构 :
采用**双分支并行架构,**由 "锁定网络" 和 "可训练网络" 两部分并行组成:- 锁定网络:复制预训练模型(如 Stable Diffusion 的 UNet)的部分权重(通常是前几层),训练中保持冻结,保留原模型已习得的图像生成先验知识,避免 "灾难性遗忘";
- 可训练网络:与锁定网络结构相同,但权重可训练,接收外部控制条件(如骨骼图、深度图)。通过参数更新,该网络学习将控制信号转化为适配生成任务的特征表示;
- 两者通过 "残差连接" 融合(可训练网络的输出与锁定网络的输出相加),使控制条件能引导特征生成,调节残差权重参数,可灵活控制条件信号的介入强度;
- 训练过程:
- 冻结预训练模型的原始权重;
- 准备带控制条件的训练数据,数据集需满足 "源控制图像 + 目标参考图像" 的对应关系。例如:
- 人体姿态控制:准备人体骨骼关节点标注图与真实人体照片的配对数据;
- 图像风格转换:使用黑白线稿与彩色完成图的组合;
- 场景结构控制:构建深度图与实景照片的对应样本。;
- 将文本提示与控制条件图像作为联合输入,驱动可训练网络进行特征提取与生成。通过反向传播,不断调整可训练网络的权重参数,使模型输出的特征能够精准匹配控制条件所定义的结构与语义信息。
- 针对不同控制类型(如姿势、深度、语义分割),需分别训练专用 ControlNet 模型。
- 推理过程:
- 加载预训练模型( Stable Diffusion )和训练好的 ControlNet 模型(如 ControlNet-Pose);
- 输入文本提示 (一个站在海边的人)用于提供语义、场景信息和控制条件(一张张开手臂的人体骨骼图)用于提供结构化信息;
- 控制条件进入 ControlNet 的可训练网络模块得到结构化特征,与基础模型中锁定的预训练网络特征进行深度融合,形成全新的复合特征,从而引导 UNet 生成符合结构约束的图像(如骨骼图对应的人体姿态)。生成一张"张开手臂站在海边的人"图像;
- 关键特点 :
- 支持多种控制类型(线稿、姿势、深度、语义分割等);
- 控制精度高,结构一致性强;
- 需为不同控制类型训练专用模型(如 ControlNet-Pose、ControlNet-Depth)
3. T2I-Adapter(Text-to-Image Adapter)
具体讲解:(2023AAAI)T2I-Adapter:学习挖掘文本到图像扩散模型的更可控能力
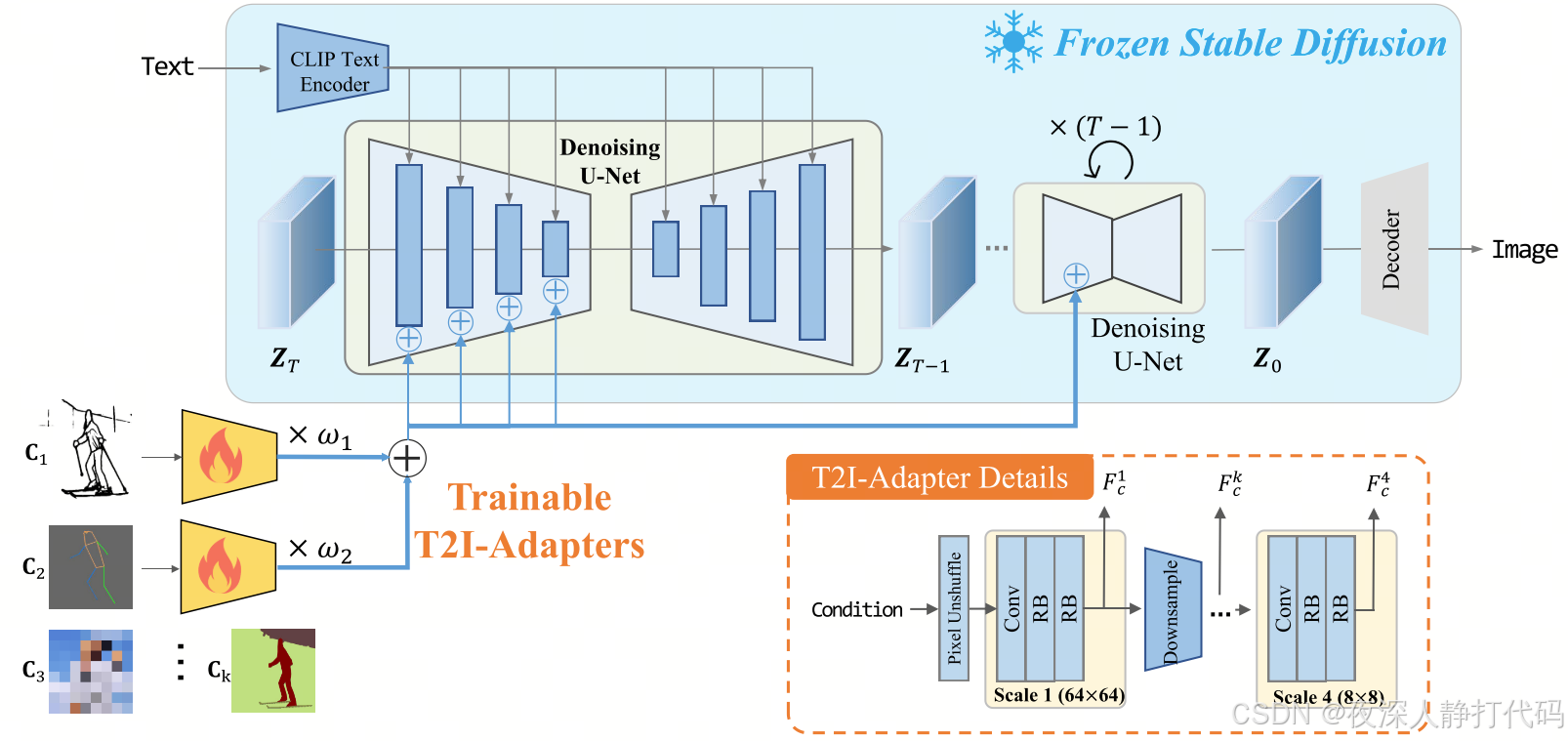
- 核心目标:通过图像提示(如风格参考图、构图示例)增强文本到图像生成的可控性,补充文本提示的不足。
- 模型结构 :
由 "图像编码器" 和 "特征融合模块" 组成:- 图像编码器:由多个 CNN 层构成,负责从参考图像中提取特征(如风格、色彩、构图);
- 特征融合模块:将图像编码器输出的特征与预训练模型(如 Stable Diffusion 的 UNet)对应层级的特征 "直接相加",实现图像提示与原模型特征的融合;
- 预训练模型的原始权重完全冻结,仅训练图像编码器和融合模块(总参数量约 10M)。
- 训练过程:
- 冻结预训练模型的全部权重;
- 准备训练数据,数据集包含三部分关键内容 ------"参考风格图 " 用于提供图像的视觉风格特征,"对应文本提示 " 从语义层面引导生成方向,"生成目标图" 则作为最终生成效果的参照标准;
- 训练图像编码器,使其能从参考图中提取有效特征;同时优化融合模块,确保图像特征与 UNet 特征的相加效果能引导生成符合预期的图像;
- 训练一次即可适配多种场景,但针对性较弱。
- 推理过程:
- 加载预训练模型和训练好的 T2I-Adapter;
- 输入文本提示"猴子摘桃"和参考图像"东方水墨画";
- 参考图像经图像编码器提取特征后,与 UNet 各层特征相加,使生成图像融入参考图的风格或构图;
- 生成一张"猴子摘桃的水墨画",呈现了文本所描述的内容,还拥有参考图像赋予的视觉风格。
- 关键特点 :
- 支持风格迁移、构图控制等,但图像特征对生成的 "指导力较弱"(简单相加易被文本特征覆盖);
- 泛化性有限,对复杂图像提示的忠实度不足;
- 可与文本提示结合,但融合效果较粗糙。
4. IP-Adapter(Image Prompt Adapter)
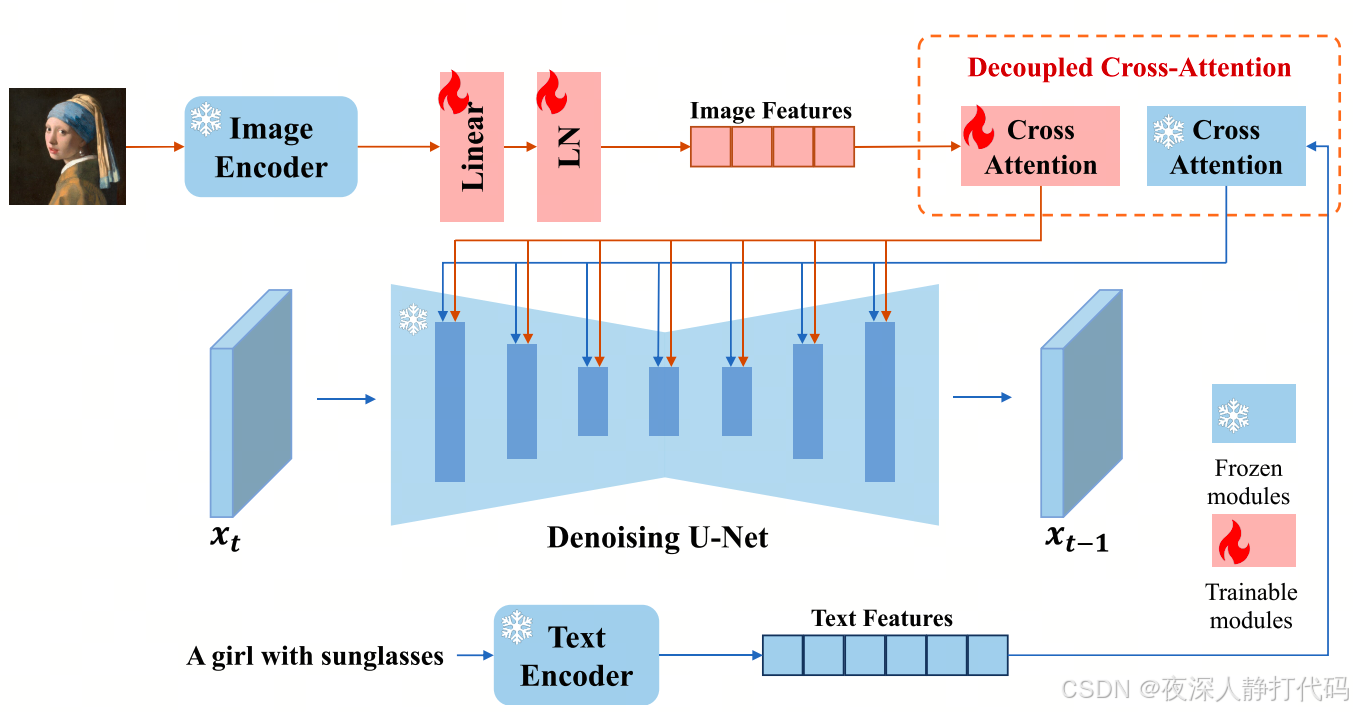
- 核心目标:通过参考图像作为提示,让模型在推理阶段 "实时学习" 图像特征(风格、内容),无需微调即可生成相似效果,兼顾灵活性与忠实度。
- 模型结构 :
由 "图像特征提取器""映射网络" 和 "解耦交叉注意力层" 组成:- 预训练模型的原始权重完全冻结,仅训练映射网络和解耦交叉注意力层(总参数量约 22M)。
- 图像特征提取器:使用预训练的 CLIP 图像编码器(如 ViT-L/14)提取参考图像的特征向量;
- 映射网络:轻量级 MLP 网络,通过非线性变换,将 CLIP 图像编码器提取的特征映射进行维度调整和语义适配,使其能够与下游预训练模型(如 Stable Diffusion)的输入格式兼容;
- 解耦交叉注意力层:对于扩散模型UNet中的每个交叉注意层,针对图像特征额外增加一个交叉注意层,实现文本与图像特征的解耦计算。在训练阶段,仅对新增的图像交叉注意力层和映射网络进行优化训练,而原始UNet模型保持冻结。
- 训练过程:
- 冻结预训练模型(如 Stable Diffusion)和 CLIP 图像编码器的权重;
- 准备大规模多模态训练数据,数据集需包含成对的高质量图像样本以及精准文本描述,覆盖多元场景、风格与主题;
- 训练映射网络,使其能将 CLIP 图像特征转换为预训练模型可理解的特征;同时训练解耦交叉注意力层,优化图像特征与 UNet 的交互方式,确保图像特征能有效引导生成;
- 训练一次即可适配任意参考图像,无需针对特定风格重复训练。
- 推理过程:
- 加载预训练模型、CLIP 图像编码器和训练好的 IP-Adapter;
- 输入文本提示和参考图像(如一张莫奈的画);
- 参考图像经 CLIP 图像编码器提取特征向量,再经映射网络转换后,输入解耦交叉注意力层,与文本特征并行引导 UNet 生成图像;
- 输出既符合文本提示,又贴近参考图像风格 / 内容的生成结果。
- 关键特点 :
- 零样本适配新风格(输入任意参考图即可生成相似效果),泛化性极强;
- 图像特征保留更完整(解耦注意力机制避免被文本特征覆盖);
- 可与 ControlNet / T2I-Adapter / LoRA 组合 等工具结合,实现 "风格 + 结构" 双重控制。
二、核心区别对比
| 对比维度 | LoRA | ControlNet | T2I-Adapter | IP-Adapter |
|---|---|---|---|---|
| 核心目标 | 让模型 "记住" 特定任务(微调) | 控制图像结构(如姿势、轮廓) | 用图像条件增强文本控制 | 用参考图实时引导生成(零样本适配) |
| 模型结构 | 低秩矩阵插入交叉注意力层 | 锁定网络 + 可训练网络(残差连接) | CNN 编码器 + 特征直接相加 | CLIP 提取器 + 映射网络 + 解耦交叉注意力 |
| 训练过程 | 为特定任务训练低秩矩阵,冻结原模型 | 为控制类型训练可训练网络,冻结锁定网络 | 训练 CNN 编码器和融合模块,冻结原模型 | 训练映射网络和解耦层,冻结原模型和 CLIP |
| 推理过程 | 加载 LoRA 权重合并到原模型,仅需文本提示 | 输入文本 + 控制条件,双网络特征融合 | 输入文本 + 参考图,特征简单相加 | 输入文本 + 参考图,特征解耦交互 |
| 对原模型的修改 | 修改部分权重(低秩矩阵) | 新增并行可训练副本(不修改原权重) | 新增 CNN 编码器(特征相加,不修改原权重) | 新增解耦交叉注意力层(不修改原权重) |
| 控制方式 | 依赖训练好的权重(无外部实时输入) | 依赖外部控制条件(如骨骼图、深度图) | 依赖图像条件提示(特征简单融合) | 依赖参考图像(特征解耦交互) |
| 泛化性 | 仅适用于训练过的任务 | 适用于同类型控制条件(如所有姿势图) | 有限(对复杂图像提示忠实度低) | 极强(支持未训练过的参考图) |
| 训练需求 | 需为每个任务单独训练 | 需为每种控制类型单独训练 | 训练一次可适配多种场景(效果一般) | 训练一次通用所有参考图 |
| 典型优势 | 特定任务生成稳定 | 结构控制精度高 | 轻量、易部署 | 灵活度高,零样本适配新风格 |
| 局限性 | 切换任务需更换权重,泛化弱 | 不直接控制风格,需配合其他工具 | 图像特征指导力弱,融合效果一般 | 对极端风格的控制精度略逊于专用 LoRA |