
工业缺陷检测实训平台开发指导书
产品版本V4.0
文档版本02
版权声明
版权所有©EDUCN 2024。保留一切权利。
未得到本公司的书面许可,任何人不得以任何方式或形式对本手册内的任何部分进行复制、摘录、备份、修改、传播、翻译成其他语言,将其全部或部分用于商业用途。
免责声明
本手册内容依据现有信息制作,由于产品版本升级或其他原因,其内容有可能变更。EDUCN保留在没有任何通知或者提示的情况下对手册内容进行修改的权利。本手册仅作为使用指导,海云捷迅在编写本手册时已尽力保证其内容准确可靠,但并不确保手册内容完全没有错误或遗漏,本手册中的所有信息也不构成任何明示或暗示的担保。
邮箱:support@awcloud.com
前言
读者对象
本手册适合下列人员阅读:
- 产品用户
- 技术支持工程师
- 售前工程师
图形界面元素引用约定
| 格式 | 意义 |
|---|---|
| "" | 带双引号""的格式表示各类界面控件名称、数据输入或内容引用等,如单击"确定"。 |
| > | 多级菜单用" > "隔开。如选择"资源 > 物理机",表示选择"资源"菜单下的"物理机"子菜单项。 |
标志约定
本手册还采用各种醒目标志来表示在操作过程中应该特别注意的地方,这些标志的意义如下:
| 标志 | 意义 |
|---|---|
| 粗体 | 命令行以粗体样式标识。 |
举例说明
本手册举例说明部分的端口类型同实际可能不符,实际操作中需要按照各产品所支持的端口类型进行操作。
本手册部分举例的显示信息中可能含有其它产品系列的内容(如产品型号、描述等),具体显示信息请以实际使用的设备信息为准。
修改记录
修订记录累积了每次文档更新的说明。最新版本的文档包含以前所有版本文档的更新内容。
文档版本01(2024-01-23):第一次正式发布。
1 产品概述
工业缺陷检测实训平台是以工业互联网铝片表面缺陷检测应用为背景,面向高校人工智能、FPGA等技术的实训产品。为贴合真实应用场景,通过加入专业的工业相机、光源、传输履带、机械臂形成一套完整的智能检测应用系统,实现基于FPGA的数据推理、机械臂自动分拣和检测数据可视化展示等功能。
产品利用深度学习算法SSD和铝板表面缺陷数据集实现,并使用FPGA来运行模型应用可检测铝表面褶皱、脏污等缺陷类型,用户可二次开发增加缺陷种类。同时,结合教学内容与实际产业、岗位需求,该实训产品提供了丰富的实验课程及配套资源,让学生快速掌握相关技能知识,加强对行业需求的理解和认知。
2 功能架构
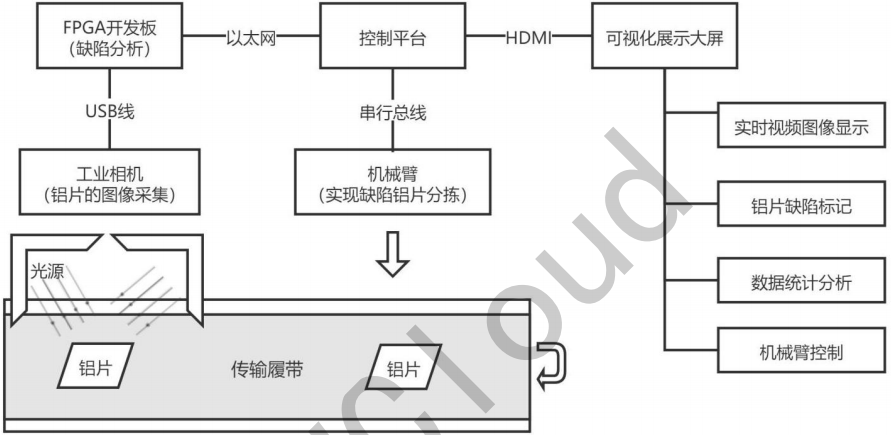
图 2-1 系统结构
- 传输履带:模拟工厂铝材产线履带传送过程,实现被检测铝片的传输。
- 工业相机:采用600万像素1/1.8"CMOS USB3.0工业面阵相机,通过USB传输方式与控制终端设备实现连接,实现被检测铝片的图像采集功能。
- 光源:采用亮度可调节条形光源,通过调节光源亮度,辅助实现铝片表现图像采集。
- 机械臂:采用AI视觉机械臂解决方案,抓手为吸盘结构。当平台检测到有缺陷的铝片时,机械臂自动从传送带上将有缺陷铝片抓取出来,实训缺陷铝片的自动分拣功能。
- 控制终端:用于控制缺陷检测的整体流程,包括基于FPGA的铝片缺陷检测服务、缺陷检测应用系统、机械臂控制服务。
- FPGA开发板:在FPGA开发板上运行铝片缺陷检测推理服务,实现对铝片缺陷种类及位置的判断,并将结果反馈给控制终端。
- 显示器:主要包括相机的视频流的实时显示,检测的铝片缺陷标记、数据的统计分析和机械臂的控制等几个部分。
- 报警器:当系统检测到缺陷铝片后通过报警器进行报警提示。
说明:开发板和机械臂ip配置为172.16.68.0/23网段。其中机械臂默认ip为:172.16.68.111/23,FPGA开发板的ip默认为172.16.68.111/23。
3 功能介绍
- 基于FPGA的缺陷检测:FPGA设备利用SSD深度学习算法和铝片表面缺陷数据集训练的模型进行推理。当相机采集到视频流图片后,会发送给推理服务获取推理结果,并将缺陷情况记录到数据库,同时对外提供检测情况的统计分析数据接口。
- 机械臂控制:系统采用5轴吸盘结构的机械臂,可通过平台实现机械臂的左右转向、抓取/释放等功能控制,同时可以结合缺陷检测应用实现缺陷铝片的自动分拣功能。
- 铝片表面缺陷检测可视化展示:通过平台页面实时展示当前检测铝片的原始图片和视频流图像,并对有缺陷的铝片进行缺陷点位标记和种类标注。对检测的历史数据进行精准的质量统计,实现产品检测良品率、检测数量的统计,有效保证产品质量。
- 传输履带及光源:为了模拟工厂铝材缺陷检测真实场景,系统配套的传输履带的速度和环形光源亮度均可调节。
4 模型产出
4.1 环境准备
在进行模型训练前,需要先准备好模型训练环境,这里选用的PaddleDetection项目进行的模型训练。
环境要求:
- ubuntu 18.04
- python == 3.6(如果条件不满足,可以考虑使用conda安装)
- CUDA(must include the cudnn) Version: 11.0
依赖安装:
bash
1. tar xf PaddelDetection.tar.gz
2. cd PaddleDetection
3. pip install -r requirements.txt
4. pip install paddlepaddle-gpu==2.1.3.post110 paddleslim==2.1.0 paddlelite==2.10 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
5. pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/cu110/torch_stable.html
6. # 验证paddlepaddle的安装
7. # python -c "import paddle;paddle.utils.run_check()"
8. # 如果出现错误,极有可能是由于cuda版本有问题应用paddlepaddle补丁:
bash
1. cd <paddlepaddle install dir>
2. # for example: cd /root/anaconda3/envs/paddle-2.1/lib/python3.6/site-packages/paddle
3. patch -p0 < <install dir>/paddle.patch
4. # for example, if the paddle.patch is in /root
5. # patch -p0 < /root/paddle.patch安装PaddleDetection:
bash
1. python setup.py install4.2 数据集准备
常用的制作数据集的软件有labelme、labelimg等,这里主要介绍labelimg的使用。需要用到ubuntu桌面。
安装labelimg:
bash
1. git clone https://github.com/tzutalin/labelImg.git
2. cd labelImg
3. apt-get install pyqt5-dev-tools
4. pip3 install --upgrade pip
5. pip3 install -r requirements/requirements-linux-python3.txt
6. make qt5py3labelimg使用 :
安装完labelimg后,执行下面命令打开labelimg软件:
bash
1. python3 labelImg.py执行命令后,会自动弹出labelimg的界面,如下图所示:
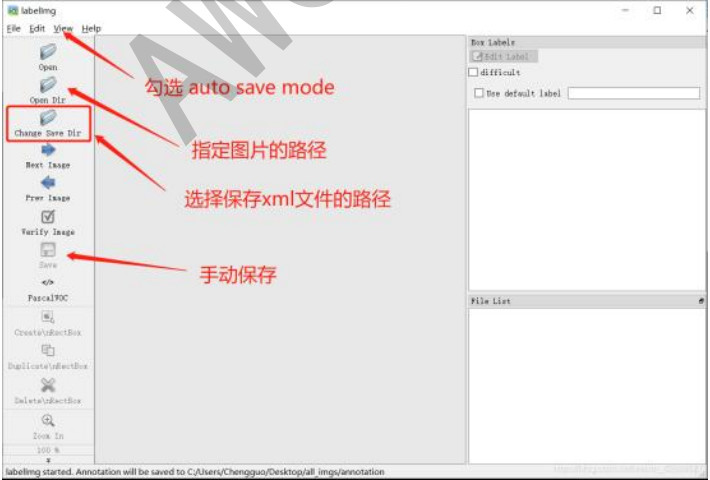
其中:
Open Dir:打开存放原文件的文件夹,JPEGImages文件夹。Change Save Dir:用于选择标签文件存放的位置,选择Annotations文件夹。- 在view菜单栏中打开
auto save mode格式,这个可以帮助我们自动的保存标记好的图片。 - 点击
creat RectBox开始标记,在labelImg中输入标签,如果感觉这个比较难检测,可以点击右上角的difficult。
快捷键:W(创建方框),A(上一张),D(下一张)。
标注完成后会得到一些标签,示例如下:
xml文件里面包含标注好图片的信息:
folder:图片所在目录filename:图片名称path:图片所在路径size:图片大小object:标注信息name:标注类别bndbox:标注框坐标
示例xml内容:
xml
<annotation>
<folder>Images</folder>
<filename>1.jpg</filename>
<path>C:\Users\tianhui\Desktop\aluminum inspection\Images\1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>1</depth>
</size>
<segmented>0</segmented>
<object>
<name>zhen kong</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>233</xmin>
<ymin>157</ymin>
<xmax>254</xmax>
<ymax>193</ymax>
</bndbox>
</object>
<object>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>256</xmin>
<ymin>180</ymin>
<xmax>282</xmax>
<ymax>209</ymax>
</bndbox>
</object>
</annotation>数据集制作 :
利用labelimg标注好数据集图片后,需要对标注的图片进行进一步处理,才能作为训练需要的数据集使用。
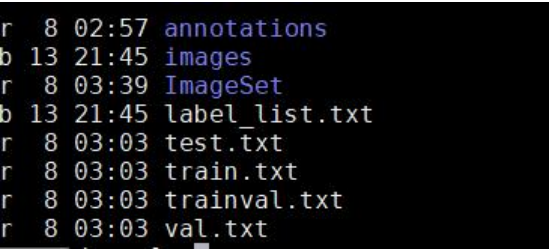
将图片与生成的xml文件分别存放在images和annotations目录,并创建一个ImageSet目录用来存放制作数据集时生成的临时文件,如下所示:
1. my_dataset # 根目录
2. |-- annotations # xml文件目录
3. |-- xxx.xml # 生成的xml文件
4. |-- images # 图像目录
5. |-- xxx.jpg(png or other) # 图片
6. |...
7. |-- label_list.txt # 数据集的类别名称
8. |-- ImageSet # 用于生成对应txt文件临时目录使用dataset_processing_one.py对数据集进行第一步处理:
python
1. import os
2. import random
3. trainval_percent = 0.95 # 训练集验证集总占比
4. train_percent = 0.9 # 训练集在trainval_percent里的train占比
5. xmlfilepath = './annotations'
6. txtsavepath = './images'
7. total_xml = os.listdir(xmlfilepath)
8. num = len(total_xml)
9. list = range(num)
10. tv = int(num * trainval_percent)
11. tr = int(tv * train_percent)
12. trainval = random.sample(list, tv)
13. train = random.sample(trainval, tr)
14. ftrainval = open('./ImageSet/trainval.txt', 'w')
15. ftest = open('./ImageSet/test.txt', 'w')
16. ftrain = open('./ImageSet/train.txt', 'w')
17. fval = open('./ImageSet/val.txt', 'w')
18. for i in list:
19. name = total_xml[i][:-4] + '\n'
20. if i in trainval:
21. ftrainval.write(name)
22. if i in train:
23. ftrain.write(name)
24. else:
25. fval.write(name)
26. else:
27. ftest.write(name)
28. ftrainval.close()
29. ftrain.close()
30. fval.close()
31. ftest.close()再使用dataset_processing_two.py对数据集进行进一步处理:
python
1. import os
2. import re
3. devkit_dir = './'
4. output_dir = './'
5. def get_dir(devkit_dir, type):
6. return os.path.join(devkit_dir, type)
7. def walk_dir(devkit_dir):
8. filelist_dir = get_dir(devkit_dir, 'ImageSet')
9. annotation_dir = get_dir(devkit_dir, 'annotations')
10. img_dir = get_dir(devkit_dir, 'images')
11. trainval_list = []
12. train_list = []
13. val_list = []
14. test_list = []
15. added = set()
16. for _, _, files in os.walk(filelist_dir):
17. for fname in files:
18. print(fname)
19. img_ann_list = []
20. if re.match('trainval.txt', fname):
21. img_ann_list = trainval_list
22. elif re.match('train.txt', fname):
23. img_ann_list = train_list
24. elif re.match('val.txt', fname):
25. img_ann_list = val_list
26. elif re.match('test.txt', fname):
27. img_ann_list = test_list
28. else:
29. continue
30. fpath = os.path.join(filelist_dir, fname)
31. for line in open(fpath):
32. name_prefix = line.strip().split()[0]
33. print(name_prefix)
34. added.add(name_prefix)
35. ann_path = annotation_dir + '/' + name_prefix + '.xml'
36. print(ann_path)
37. img_path = img_dir + '/' + name_prefix + '.jpg'
38. assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
39. assert os.path.isfile(img_path), 'file %s not found.' % img_path
40. img_ann_list.append((img_path, ann_path))
41. print(img_ann_list)
42. return trainval_list, train_list, val_list, test_list
43. def prepare_filelist(devkit_dir, output_dir):
44. trainval_list = []
45. train_list = []
46. val_list = []
47. test_list = []
48. trainval, train, val, test = walk_dir(devkit_dir)
49. trainval_list.extend(trainval)
50. train_list.extend(train)
51. val_list.extend(val)
52. test_list.extend(test)
53. with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
54. for item in trainval_list:
55. ftrainval.write(item[0] + ' ' + item[1] + '\n')
56. with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain:
57. for item in train_list:
58. ftrain.write(item[0] + ' ' + item[1] + '\n')
59. with open(os.path.join(output_dir, 'val.txt'), 'w') as fval:
60. for item in val_list:
61. fval.write(item[0] + ' ' + item[1] + '\n')
62. with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:
63. for item in test_list:
64. ftest.write(item[0] + ' ' + item[1] + '\n')
65. if __name__ == '__main__':
66. prepare_filelist(devkit_dir, output_dir)通过处理后,可以得到能够进行训练使用的数据集:
4.3 模型训练
配置文件修改:
bash
1. vim configs/datasets/voc.yml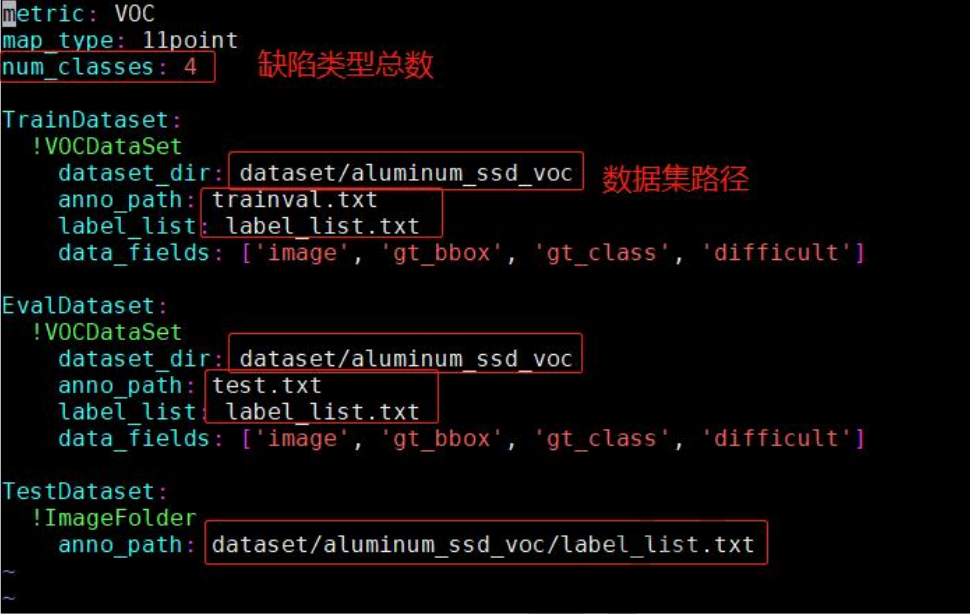
全精度训练:
bash
1. python tools/train.py -c configs/ssd/ssd_mobilenet_v1_300_120e_voc.yml --eval量化训练 :
修改configs/slim/quant/ssd_mobilenet_v1_qat.yml,将pretrain_weights参数指向ssd_mobilenet_v1_300_120e_voc文件所在路径,例如:
pretrain_weights: output/ssd_mobilenet_v1_300_120e_voc/best_model
执行训练命令:
bash
1. python tools/train.py -c configs/ssd/ssd_mobilenet_v1_300_120e_voc.yml --slim_config configs/slim/quant/ssd_mobilenet_v1_qat.yml --eval4.4 模型导出
最终导出的静态模型位于output_inference/ssd_mobilenet_v1_qat/:
bash
1. python tools/export_model.py \
2. -c configs/ssd/ssd_mobilenet_v1_300_120e_voc.yml \
3. --slim_config configs/slim/quant/ssd_mobilenet_v1_qat.yml \
4. -o weights=output/ssd_mobilenet_v1_qat/best_model4.5 模型转换
当前目录则会生成ssd_mobilenet_v1_opt.nb,该文件即是量化之后的模型:
bash
1. opt \
2. --model_dir=./PaddleDetection/output_inference/ssd_mobilenet_v1_qat/ \
3. --valid_targets=intel_fpga,arm \
4. --optimize_out_type=naive_buffer \
5. --optimize_out=ssd_mobilenet_v1_opt5 FPGA开发板推理
5.1 利用PADDLE-LITE推理
在FPGA上推理,这里使用Paddle-Lite,下面针对Paddle-Lite推理流程进行简要说明。
C++代码调用Paddle Lite执行预测库仅需以下五步:
- 引用头文件和命名空间
cpp
#include "paddle_api.h"
using namespace paddle::lite_api;- 指定模型文件,创建Predictor
cpp
// 1. Set MobileConfig
MobileConfig config;
// 2. Set the path to the model generated by opt tools
config.set_model_from_file(model_file_path);
// 3. Create PaddlePredictor by MobileConfig
std::shared_ptr<PaddlePredictor> predictor = CreatePaddlePredictor<MobileConfig>(config);- 设置模型输入(下面以全一输入为例)
cpp
std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
input_tensor->Resize({1, 3, 224, 224});
auto* data = input_tensor->mutable_data<float>();
for (int i = 0; i < ShapeProduction(input_tensor->shape()); ++i) {
data[i] = 1;
}如果模型有多个输入,每一个模型输入都需要准确设置shape和data。
- 执行预测
cpp
predictor->Run();- 获得预测结果
cpp
std::unique_ptr<const Tensor> output_tensor(
std::move(predictor->GetOutput(0)));
// 转化为数据
auto output_data = output_tensor->data<float>();下面是使用SSD模型进行推理的具体示例:
cpp
1. #include <iostream>
2. #include <vector>
3. #include "opencv2/core.hpp"
4. #include "opencv2/imgcodecs.hpp"
5. #include "opencv2/imgproc.hpp"
6. #include "paddle_api.h" // NOLINT
7. using namespace paddle::lite_api; // NOLINT
8. struct Object {
9. int batch_id;
10. cv::Rect rec;
11. int class_id;
12. float prob;
13. };
14. int64_t ShapeProduction(const shape_t& shape) {
15. int64_t res = 1;
16. for (auto i : shape) res *= i;
17. return res;
18. }
19. const char* class_names[] = {
20. "background", "aeroplane", "bicycle", "bird", "boat",
21. "bottle", "bus", "car", "cat", "chair",
22. "cow", "diningtable", "dog", "horse", "motorbike",
23. "person", "pottedplant", "sheep", "sofa", "train",
24. "tvmonitor"};
25. // fill tensor with mean and scale and trans layout: nhwc -> nchw, neon speed up
26. void neon_mean_scale(const float* din,
27. float* dout,
28. int size,
29. const std::vector<float> mean,
30. const std::vector<float> scale) {
31. if (mean.size() != 3 || scale.size() != 3) {
32. std::cerr << "[ERROR] mean or scale size must equal to 3\n";
33. exit(1);
34. }
35. float32x4_t vmean0 = vdupq_n_f32(mean[0]);
36. float32x4_t vmean1 = vdupq_n_f32(mean[1]);
37. float32x4_t vmean2 = vdupq_n_f32(mean[2]);
38. float32x4_t vscale0 = vdupq_n_f32(1.f / scale[0]);
39. float32x4_t vscale1 = vdupq_n_f32(1.f / scale[1]);
40. float32x4_t vscale2 = vdupq_n_f32(1.f / scale[2]);
41. float* dout_c0 = dout;
42. float* dout_c1 = dout + size;
43. float* dout_c2 = dout + size * 2;
44. int i = 0;
45. for (; i < size - 3; i += 4) {
46. float32x4x3_t vin3 = vld3q_f32(din);
47. float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0);
48. float32x4_t vsub1 = vsubq_f32(vin3.val[1], vmean1);
49. float32x4_t vsub2 = vsubq_f32(vin3.val[2], vmean2);
50. float32x4_t vs0 = vmulq_f32(vsub0, vscale0);
51. float32x4_t vs1 = vmulq_f32(vsub1, vscale1);
52. float32x4_t vs2 = vmulq_f32(vsub2, vscale2);
53. vst1q_f32(dout_c0, vs0);
54. vst1q_f32(dout_c1, vs1);
55. vst1q_f32(dout_c2, vs2);
56. din += 12;
57. dout_c0 += 4;
58. dout_c1 += 4;
59. dout_c2 += 4;
60. }
61. for (; i < size; i++) {
62. *(dout_c0++) = (*(din++) - mean[0]) * scale[0];
63. *(dout_c1++) = (*(din++) - mean[1]) * scale[1];
64. *(dout_c2++) = (*(din++) - mean[2]) * scale[2];
65. }
66. }
67. void pre_process(const cv::Mat& img, int width, int height, float* data) {
68. cv::Mat rgb_img;
69. cv::cvtColor(img, rgb_img, cv::COLOR_BGR2RGB);
70. cv::resize(rgb_img, rgb_img, cv::Size(width, height), 0.f, 0.f);
71. cv::Mat imgf;
72. rgb_img.convertTo(imgf, CV_32FC3, 1 / 255.f);
73. std::vector<float> mean = {0.5f, 0.5f, 0.5f};
74. std::vector<float> scale = {0.5f, 0.5f, 0.5f};
75. const float* dimg = reinterpret_cast<const float*>(imgf.data);
76. neon_mean_scale(dimg, data, width * height, mean, scale);
77. }
78. std::vector<Object> detect_object(const float* data,
79. int count,
80. float thresh,
81. cv::Mat& image) {
82. if (data == nullptr) {
83. std::cerr << "[ERROR] data can not be nullptr\n";
84. exit(1);
85. }
86. std::vector<Object> rect_out;
87. for (int iw = 0; iw < count; iw++) {
88. int oriw = image.cols;
89. int orih = image.rows;
90. if (data[1] > thresh && static_cast<int>(data[0]) > 0) {
91. Object obj;
92. int x = static_cast<int>(data[2] * oriw);
93. int y = static_cast<int>(data[3] * orih);
94. int w = static_cast<int>(data[4] * oriw) - x;
95. int h = static_cast<int>(data[5] * orih) - y;
96. cv::Rect rec_clip =
97. cv::Rect(x, y, w, h) & cv::Rect(0, 0, image.cols, image.rows);
98. obj.batch_id = 0;
99. obj.class_id = static_cast<int>(data[0]);
100. obj.prob = data[1];
101. obj.rec = rec_clip;
102. if (w > 0 && h > 0 && obj.prob <= 1) {
103. rect_out.push_back(obj);
104. cv::rectangle(image, rec_clip, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
105. std::string str_prob = std::to_string(obj.prob);
106. std::string text = std::string(class_names[obj.class_id]) + ": " +
107. str_prob.substr(0, str_prob.find(".") + 4);
108. int font_face = cv::FONT_HERSHEY_COMPLEX_SMALL;
109. double font_scale = 1.f;
110. int thickness = 2;
111. cv::Size text_size =
112. cv::getTextSize(text, font_face, font_scale, thickness, nullptr);
113. float new_font_scale = w * 0.35 * font_scale / text_size.width;
114. text_size = cv::getTextSize(
115. text, font_face, new_font_scale, thickness, nullptr);
116. cv::Point origin;
117. origin.x = x + 10;
118. origin.y = y + text_size.height + 10;
119. cv::putText(image,
120. text,
121. origin,
122. font_face,
123. new_font_scale,
124. cv::Scalar(0, 255, 255),
125. thickness,
126. cv::LINE_AA);
127. std::cout << "detection, image size: " << image.cols << ", "
128. << image.rows
129. << ", detect object: " << class_names[obj.class_id]
130. << ", score: " << obj.prob << ", location: x=" << x
131. << ", y=" << y << ", width=" << w << ", height=" << h
132. << std::endl;
133. }
134. }
135. data += 6;
136. }
137. return rect_out;
138. }
139. void RunModel(std::string model_file, std::string img_path) {
140. // 1. Set MobileConfig
141. MobileConfig config;
142. config.set_model_from_file(model_file);
143. // 2. Create PaddlePredictor by MobileConfig
144. std::shared_ptr<PaddlePredictor> predictor =
145. CreatePaddlePredictor<MobileConfig>(config);
146. // 3. Prepare input data from image
147. std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
148. const int in_width = 300;
149. const int in_height = 300;
150. input_tensor->Resize({1, 3, in_height, in_width});
151. auto* data = input_tensor->mutable_data<float>();
152. cv::Mat img = imread(img_path, cv::IMREAD_COLOR);
153. pre_process(img, in_width, in_height, data);
154. // 4. Run predictor
155. predictor->Run();
156. // 5. Get output and post process
157. std::unique_ptr<const Tensor> output_tensor(
158. std::move(predictor->GetOutput(0)));
159. auto* outptr = output_tensor->data<float>();
160. auto shape_out = output_tensor->shape();
161. int64_t cnt = ShapeProduction(shape_out);
162. auto rec_out = detect_object(outptr, static_cast<int>(cnt / 6), 0.6f, img);
163. int start = img_path.find_last_of("/");
164. int end = img_path.find_last_of(".");
165. std::string img_name = img_path.substr(start + 1, end - start - 1);
166. std::string result_name = img_name + "_ssd_detection_result.jpg";
167. cv::imwrite(result_name, img);
168. }
169. int main(int argc, char**argv) {
170. if (argc < 3) {
171. std::cerr << "[ERROR] usage: " << argv[0] << " model_file image_path\n";
172. exit(1);
173. }
174. std::string model_file = argv[1];
175. std::string img_path = argv[2];
176. RunModel(model_file, img_path);
177. return 0;
178. }5.2 封装推理模型服务
Paddle-Lite推理程序使用C++语言进行编写,需要在原有的程序上进行扩展,使得外部能够使用该程序进行模型推理,因此需要了解C++如何提供http服务。
这里使用了github项目上提供的httplib库,具体httplib相关用法可以查看https://github.com/yhirose/cpphttplib,下面简单介绍下httplib的使用:
cpp
1. #include "httplib.h"
2. using namespace httplib;
3. // 请求日志打印
4. std::string log(const Request &req, const Response &res) {
5. std::string s;
6. char buf[BUFSIZ];
7. s += "================================\n";
8. snprintf(buf, sizeof(buf), "%s %s %s", req.method.c_str(),
9. req.version.c_str(), req.path.c_str());
10. s += buf;
11. std::string query;
12. for (auto it = req.params.begin(); it != req.params.end(); ++it) {
13. const auto &x = *it;
14. snprintf(buf, sizeof(buf), "%c%s=%s",
15. (it == req.params.begin()) ? '?' : '&', x.first.c_str(),
16. x.second.c_str());
17. query += buf;
18. }
19. snprintf(buf, sizeof(buf), "%s\n", query.c_str());
20. s += buf;
21. s += dump_headers(req.headers);
22. s += "\n";
23. snprintf(buf, sizeof(buf), "%d %s\n", res.status, res.version.c_str());
24. s += buf;
25. s += dump_headers(res.headers);
26. s += "\n";
27. if (!res.body.empty()) { s += res.body; }
28. s += "\n";
29. return s;
30. }
31. // html页面
32. const char *html = R"(
33. <form id="formElem">
34. <input type="file" name="image_file" accept="image/*">
35. <input type="submit">
36. </form>
37. <script>
38. formElem.onsubmit = async (e) => {
39. e.preventDefault();
40. let res = await fetch('/post', {
41. method: 'POST',
42. body: new FormData(formElem)
43. });
44. console.log(await res.text());
45. };
46. </script>
47. )";
48. int main(int argc, char* argv[]){
49. Server svr;
50. // 一次只允许接收处理一个请求
51. svr.new_task_queue = [] { return new ThreadPool(1); };
52. // 定义GET请求接口,获取html页面显示
53. svr.Get("/", [](const Request & /*req*/, Response &res) {
54. res.set_content(html, "text/html");
55. });
56. // 定义POST请求接口
57. svr.Post("/predict", [](const Request &req, Response &res) {
58. // 获取上传的图片文件
59. auto image_file = req.get_file_value("image_file");
60. // 定义Mat格式数据,将图片信息写入其中,方便推理使用
61. cv::Mat img_decode;
62. std::vector<uchar> data(image_file.content.begin(), image_file.content.end());
63. img_decode = cv::imdecode(data, CV_LOAD_IMAGE_COLOR);
64. json k;
65. std::ifstream is("config.json");
66. is >> k;
67. // 根据上传的图片获取推理结果
68. std::string out_put = predict(k, img_decode);
69. // POST请求返回信息,这里返回推理结果
70. res.set_content(out_put, "text/plain");
71. });
72. // 请求日志显示
73. svr.set_logger([](const Request &req, const Response &res) {
74. printf("%s", log(req, res).c_str());
75. });
76. // http请求端口号定义
77. svr.listen("0.0.0.0", 8080);
78. return 0;
79. }5.3 FPGA开发板推理
下面是完整的使用FPGA开发板进行推理的流程:
a. 将ssd_detection_demo.tar.gz拷贝到fpga开发板/opt目录,执行:
bash
tar -xvf ssd_detection_demo.tar.gzb. 将ssd_detection_demo/ssd_mobilenet_v1/ssd_mobilenet_v1_opt.nb更换为4.5生成的ssd_mobilenet_v1_opt.nb模型文件
c. 将ssd_detection_demo/labels/label_list更换为4.2中的label_list文件
d. 编译:
bash
cd ssd_detection_demo/ssd_detection_src
./build.she. 将生成的ssd_detection文件拷贝到ssd_detection_demo目录:
bash
cp ssd_detection_src/build/ssd_detection ssd_detection_demo/f. 将推理程序做成服务:
bash
vim /etc/systemd/system/detect.service文件内容:
1. [Unit]
2. Description = Api Service
3. After = sshd.service
4. [Service]
5. Type = simple
6. User = root
7. Group = root
8. ExecStart = /bin/sh -c "bash /opt/ssd_detection_demo/run.sh"
9. [Install]
10. WantedBy = multi-user.targetg. 启动服务:
bash
systemctl enable detect.service
systemctl start detect.serviceh. 利用浏览器打开开发板ip:8080,能够成功显示推理界面,可以通过浏览器查看推理效果:

6 OpenCV图像基础识别
作为计算机视觉应用最广泛的库,opencv在图像处理中是绕不开的话题,本章节将做一部分opencv的基础功能介绍,以便在后续章节的图像处理中用户对用到的opencv函数有基本的认识。opencv有C++和Python两个版本,为了更好的入门,本章节的教程使用Python版本。
6.1 基本操作
- 读取图片
opencv使用cv2.imread(path, flags)来读入一张图片:
python
1. import cv2
2. # 加载灰度图
3. img = cv2.imread('lena.jpg', 0)- 参数path:图片的存放路径,注意:图片路径中不能有中文字符。
- 参数flags:根据图片的格式有三个读取方式,默认是彩色图,用法如下表所示。
| flags | 图片格式 |
|---|---|
| cv2.IMREAD_COLOR | 彩色图,默认值(1) |
| cv2.IMREAD_GRAYSCALE | 灰度图(0) |
| cv2.IMREAD_UNCHANGED | 包含透明通道的彩色图(-1) |
- 读取摄像头并显示
要使用摄像头,需要使用cv2.VideoCapture(path)创建VideoCapture对象,传入的参数可以是摄像头的编号,也可以是视频文件,cv2.imshow()用来显示图像。
python
1. # 打开摄像头并显示
2. import cv2
3. capture = cv2.VideoCapture(0)
4. while(True):
5. # 获取一帧
6. ret, frame = capture.read()
7. cv2.imshow('frame', frame)
8. if cv2.waitKey(1) == ord('q'):
9. breakcv2.VideoCapture参数path:摄像头的编号,0代表第一个摄像头,也可以是视频文件,如'test.mp4'cv2.imshow参数:根据图片的格式有三个读取方式,默认是彩色图
- 获取图片属性
img.shape函数可以获取图像的属性,彩色图返回高度、宽度和通道数,灰度图只返回高度和宽度。
python
1. import cv2
2. # 加载灰度图
3. img = cv2.imread('lena.jpg', 0)
4. print(img.shape)
5. # 打印(480, 640, 3),说明这是高480宽640的三通道图片6.2 图像变换
- 缩放
cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]])函数可以按照比例缩放图像,也可以按照指定的大小缩放图片,在图像的预处理中经常要使用此函数。
python
1. import cv2
2. img = cv2.imread('drawing.jpg')
3. # 按照指定的宽度、高度缩放图片
4. res = cv2.resize(img, (132, 150))
5. # 按照比例缩放,如x,y轴均放大一倍
6. res2 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
7. cv2.imshow('shrink', res), cv2.imshow('zoom', res2)
8. cv2.waitKey(0)- 参数src:图片
- 参数dsize:缩放后的图像大小,用元组(宽度,高度)表示,在使用等比例缩放时这个参数为None,如果指定参数dsize的值,则无论是否指定了参数fx和fy的值,都由参数dsize来决定目标图像的大小
- 参数fx:水平方向的缩放比例
- 参数fy:竖直方向的缩放比例
- 参数interpolation:interpolation代表插值方式,有三种值,默认是INTER_LINEAR,用法如下表所示。
| interpolation值 | 所用的插值方法 |
|---|---|
| INTER_NEAREST | 最近邻插值 |
| INTER_LINEAR | 双线性插值(默认设置) |
| INTER_AREA | 使用像素区域关系进行重采样。它可能是图像抽取的首选方法,因为它会产生无云纹理的结果。但是当图像缩放时,它类似于INTER_NEAREST方法。 |
| INTER_CUBIC | 4x4像素邻域的双三次插值 |
| INTER_LANCZOS4 | 8x8像素邻域的Lanczos插值 |
- 镜像
dst = cv2.flip(img, flipcode)可以水平或竖直镜像图像
python
1. import cv2
2. img = cv2.imread('drawing.jpg')
3. # 水平翻转图片
4. dst = cv2.flip(img, 1)- 参数src:图片
- 参数flipcode:代表翻转方式,有三个模式,用法如下表所示。
| flipCode | dst |
|---|---|
| >0 | 水平翻转 |
| =0 | 垂直翻转 |
| <0 | 水平和垂直翻转 |
6.3 图像平滑
图像平滑也称为图像模糊(Blurring),对图像使用低通滤波器可以去除图像中的高频成分(比如:噪音,边界),用来降低噪声和伪影的影响。在讲解之前,我们需要介绍一些概念:噪声、卷积和卷积核。
6.3.1 噪声
6.3.1.1 椒盐噪声
椒盐噪声(salt-and-pepper noise)也称为脉冲噪声,它是一种随机出现的白点或者黑点,其中白点称为盐噪声,黑点称为椒噪声。前者是高灰度噪声,后者属于低灰度噪声。一般两种噪声同时出现,呈现在图像上就是黑白杂点。
下面是图像加上椒盐噪声的效果:

6.3.1.2 高斯噪声
椒盐噪声是出现在随机位置、噪点灰度值基本固定的噪声,高斯噪声与其相反,是几乎每个点上都出现噪声、噪点灰度值的概率密度函数服从高斯分布。高斯概率密度函数如下所示:
f(x)=\\frac{1}{\\sqrt{2 \\pi} \\sigma} exp \\left(-\\frac{(x-\\mu)\^{2}}{2 \\sigma\^{2}}\\right)
几何上的高斯函数如下图所示,其中噪点的灰度值用(x)表示,灰度值的期望值用(\mu)表示,灰度值的标准差用(\sigma)表示。
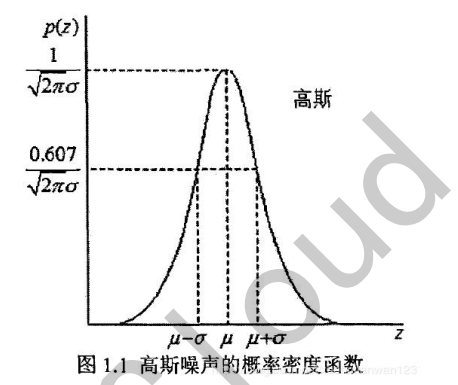
下面是图像加上高斯噪声的效果:

椒盐噪声和高斯噪声的对比如下表所示:
| 噪声种类 | 出现位置 | 灰度值 |
|---|---|---|
| 椒盐噪声 | 随机 | 基本是固定的(0或255) |
| 高斯噪声 | 固定的(基本在每一点上) | 噪声的幅值是随机的,噪点灰度值的概率密度函数服从高斯分布 |
6.3.2 卷积和滤波
6.3.2.1 卷积和卷积核
首先看下数学上卷积公式,可以理解为系统某一时刻的输出是由多个输入共同作用(叠加)的结果:
\\int_{-\\infty}\^{\\infty} f(\\tau) g(x-\\tau) d \\tau
卷积应用在在图像处理时,(f(x))可以理解为原始像素点(source pixel),所有的原始像素点叠加起来,就是原始图片了。(g(x))可以称为作用点,所有作用点合起来我们称为卷积核,卷积核上所有作用点依次作用于原始像素点后(即乘起来),线性叠加的输出结果,即是最终卷积的输出,也就是输出图片。
在图像处理中,卷积的过程如图所示,图像的像素矩阵和卷积核逐个相乘,得到输出像素值,算完之后,输入的像素框框再往右移一步继续计算,横向计算完后,再往下移一步继续计算,过程可以简化为下图:

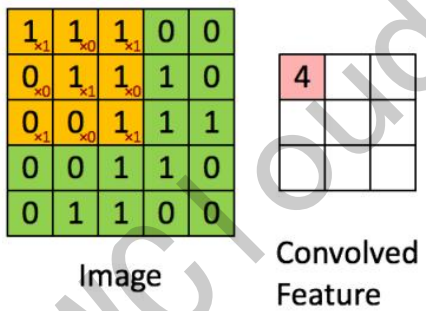
示例:输入图像是一个5x5矩阵,卷积核是3x3矩阵,输出图像是3x3矩阵。输出图像中第一个元素4的计算方式为:输入图像中3x3的区域与3x3的卷积核做内积:
4=1 × 1+0 × 1+1 × 1+0 × 0+1 × 1+0 × 1+1 × 0+0 × 0+1 × 1
更直观的卷积计算过程示例如下:
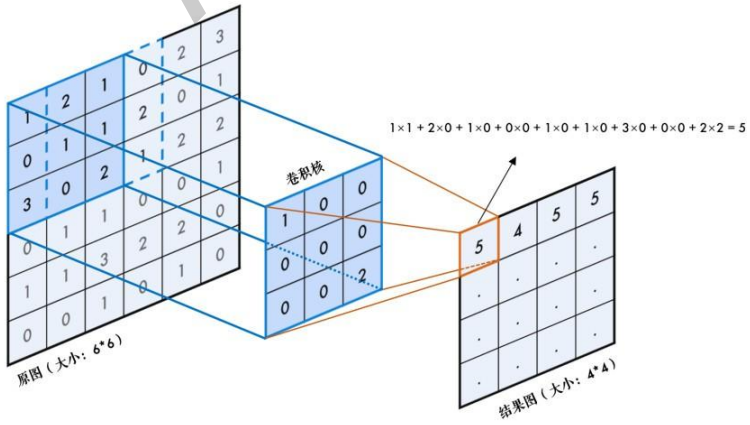
输入图像(6x6):
\\left\[\\begin{array}{lllll} 1 \& 1 \& 1 \& 0 \& 0 \\ 0 \& 1 \& 1 \& 1 \& 0 \\ 0 \& 0 \& 1 \& 1 \& 1 \\ 0 \& 0 \& 1 \& 1 \& 0 \\ 0 \& 1 \& 1 \& 0 \& 0 \\end{array}\\right
]
卷积核(3x3):
\\left\[\\begin{array}{lll} 1 \& 0 \& 1 \\ 0 \& 1 \& 0 \\ 1 \& 0 \& 1 \\end{array}\\right
]
输出图像(4x4):
\\left\[\\begin{array}{lll} 4 \& 3 \& 4 \\ 2 \& 4 \& 3 \\ 2 \& 3 \& 4 \\end{array}\\right
]
在上图中用3×3的卷积核对一副6×6的图像进行卷积,得到的是4×4的图,输出图片比输入图片小。在图像处理中,很多时候要求处理后不改变图像大小,此时可以对原图扩充一圈(填充padding)再卷积。
例如,给6x6的图像加上边框后变成8x8的图像,经过卷积后,输出图像是6x6,和输入图像大小一致:
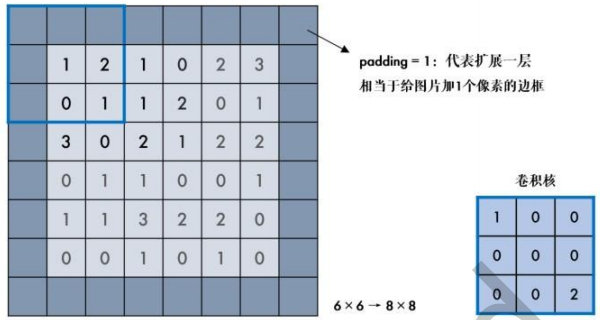
opencv使用cv2.copyMakeBorder(src, top, bottom, left, right, borderType, value)用来给图片添加边框,参数说明:
- src:原始图像
- top, bottom, left, right:上下左右要扩展的像素数
- borderType:边框类型,有5种类型,如下表所示
| borderType | 填充方式 |
|---|---|
| BORDER_REPLICATE | 直接复制最边缘的像素填充,例如:aaaa|abcdefg|ggggg |
| BORDER_REFLECT | 镜像法,即以最边缘的像素为对称轴,例如:fedcba|abcdefg|gfedec |
| BORDER_REFLECT_101 | 和上面类似BORDER_REFLECT,但在反射时会把边界空开,例如:fedcb|abcdefg|fedec |
| BORDER_WRAP | 以图像的左边界与右边界相连,上下边界相连。例如:cdefgh|abcdefgh|abcdefg |
| BORDER_CONSTANT | 固定的像素值填充 |
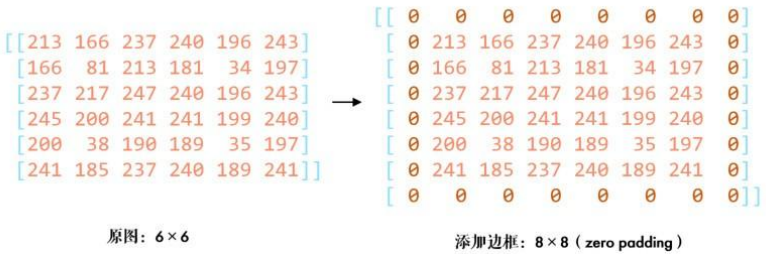
固定值填充 :
cv2.BORDER_CONSTANT方式将边框填充为固定值,例如填充0:
python
1. img = cv2.imread('6_by_6.bmp', 0)
2. # 固定值边框,统一都填充0 也称为zero padding
3. cons = cv2.copyMakeBorder(img, 1, 1, 1, 1, cv2.BORDER_CONSTANT, value=0)效果示例:
镜像填充 :
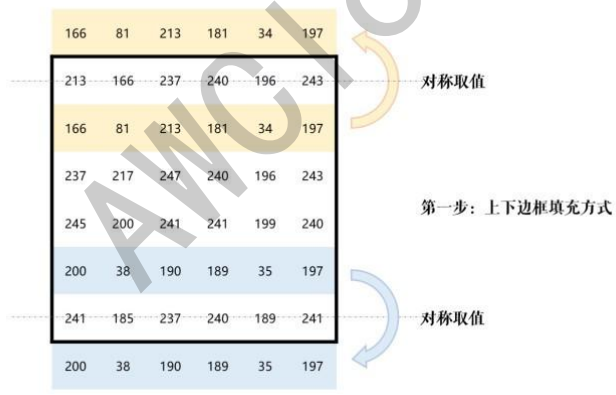
opencv的默认填充方式是镜像填充,使用方法如下:
python
1. img = cv2.imread('6_by_6.bmp', 0)
2. default = cv2.copyMakeBorder(img, 1, 1, 1, 1, cv2.BORDER_DEFAULT)首先进行上下填充,填充成与原图像边界对称的值,再进行左右填充,
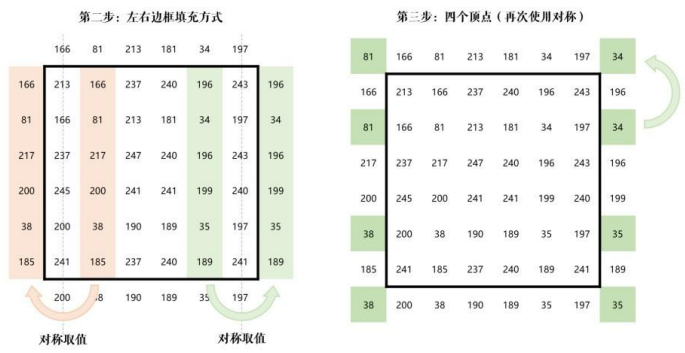
最后补充四个顶点:
6.3.3 均值滤波
均值滤波对目标像素及周边像素取平均值后再填回目标像素,均值滤波的卷积核内的值大小相等,卷积核为:
kernel =\\frac{1}{ width × height }\\left\[\\begin{array}{cccc} 1 \& 1 \& \\cdots \& 1 \\ 1 \& 1 \& \\cdots \& 1 \\ \\vdots \& \\vdots \& \\ddots \& \\vdots \\ 1 \& 1 \& \\cdots \& 1 \\end{array}\\right\]
以3×3的均值滤波卷积核为例:
kernel =\\frac{1}{9}\\left\[\\begin{array}{lll}1 \& 1 \& 1 \\ 1 \& 1 \& 1 \\ 1 \& 1 \& 1\\end{array}\\right\]
目标像素取周边9个(包括自身)像素的像素值加权平均,每个像素的权重相等。
opencv的均值滤波函数为cv2.blur(src, ksize[, dst[, anchor[, borderType]]]),用法如下:
python
1. img = cv2.imread('lena.jpg')
2. blur = cv2.blur(img, (3, 3)) # 均值模糊- 参数src:图片
- 参数ksize:卷积核的宽和高(必须是奇数),用元组表示。
- 参数borderType:边界像素填充方式,默认是镜像填充
6.3.4 方框滤波
方框滤波对目标像素及周边像素取求和后再填回目标像素,卷积核内的值大小相等,卷积核为:
kernel =\\alpha\\left\[\\begin{array}{cccc}1 \& 1 \& \\cdots \& 1 \\ 1 \& 1 \& \\cdots \& 1 \\ \\vdots \& \\vdots \& \\ddots \& \\vdots \\ 1 \& 1 \& \\cdots \& 1\\end{array}\\right\] 不同情况下 \\alpha=\\left{\\begin{array}{cc}\\frac{1}{ width × height } \& normalize == True \\ 1 \& normalize == False \\end{array}\\right.
当normalize = true时,方框滤波就变成了均值滤波;当normalize = false时,为非归一化的方框滤波,用于计算每个像素邻域内的积分特性。
以3×3、normalize = false的方框滤波卷积核为例:
kernel =\\left\[\\begin{array}{lll}1 \& 1 \& 1 \\ 1 \& 1 \& 1 \\ 1 \& 1 \& 1\\end{array}\\right\]
目标像素的值等于周边9个像素(包括自身)的像素和。
opencv的方框滤波函数为cv2.boxFilter(src, ddepth, ksize [, dst [, anchor [, normalize [, borderType ] ] ] ] ),用法如下:
python
1. img = cv2.imread('lena.jpg')
2. blur = cv2.boxFilter(img, -1, (3, 3), normalize=True)- 参数src:图片
- 参数ddepth:输出图像的深度,-1表示使用输入图像的深度
- 参数ksize:卷积核的宽和高(必须是奇数),用元组表示。
- 参数normalize:归一化标志,false时为非归一化,true时为均值滤波。
- 参数borderType:边界像素填充方式,默认是镜像填充
6.3.5 中值滤波
中值滤波法是非线性滤波,将图像的每个像素用邻域(以当前像素为中心的正方形区域)像素的中值代替。可以有效去除孤立的噪点,适用于去除椒盐噪声和斑点噪声。由于是非线性滤波,计算起来比其他滤波器要慢。
以3x3的像素窗为例,计算以点i,j为中心的函数窗像素中值步骤如下:
- 按强度值大小排列像素点(排序结果为144, 145, 146, 148, 150, 150, 151, 151, 250)
- 选择排序像素集的中间值作为点i,j的新值(i,j原来的像素值250用排序结果的中值150代替
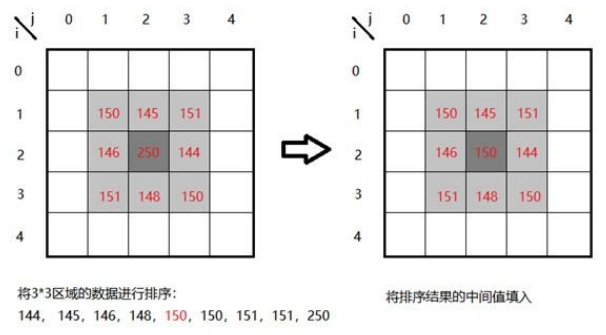
opencv的中值滤波函数为cv2.medianBlur(src, ksize[, dst]),用法如下:
python
1. img = cv2.imread('salt_noise.bmp', 0)
2. median = cv2.medianBlur(img, 5) # 中值滤波- 参数src:图片
- 参数ksize:像素窗的宽和高(必须是奇数),用元组表示。
中值滤波对椒盐噪声的效果如下图所示:

6.3.6 高斯滤波
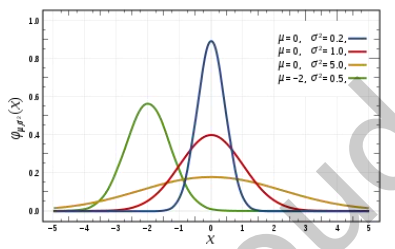
卷积核的每个值相当于该值相对应的像素值的权重,高斯滤波的卷积核权重是高斯分布的,越接近中心点像素的权重越高。
一维的高斯函数:
G(x)=\\frac{1}{\\sqrt{2 \\pi} \\sigma} exp \\left(-\\frac{(x-\\mu)\^{2}}{2 \\sigma\^{2}}\\right)
不同的(\mu)和(\sigma)时的高斯分布图如下所示:
二维的高斯函数是互相独立的两个一维高斯函数相乘:
G(x, y)=\\frac{1}{2 \\pi \\sigma_{x} \\sigma_{y}} exp \\left(-\\frac{\\left(x-\\mu_{x}\\right)^{2}+\\left(y-\\mu_{y}\\right)^{2}}{2 \\sigma_{x} \\sigma_{y}}\\right)=G(x) G(y)
二维的高斯函数分布图((\sigma=0))如下所示:
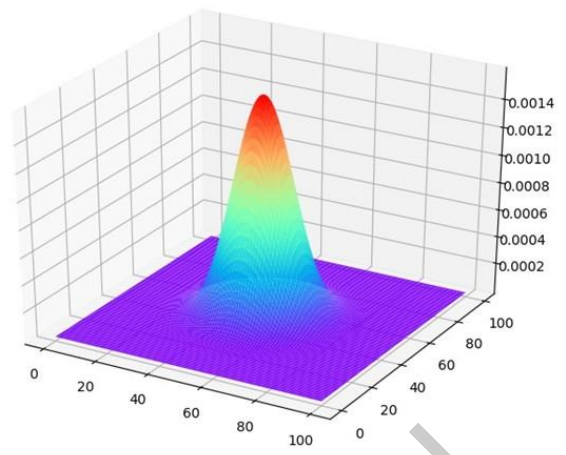
以3×3、(\sigma=0.8)的高斯核为例,以卷积核的中心位置为坐标原点进行取样,坐标如下:
| (-1,-1) | (0,-1) | (1,-1) |
|---|---|---|
| (-1,0) | (0,0) | (1,0) |
| (-1,1) | (0,1) | (1,1) |
将坐标代入高斯分布函数,得到卷积核:
\\left\[\\begin{array}{ccc} 0.057118 \& 0.12476 \& 0.057118 \\ 0.12476 \& 0.2725 \& 0.12476 \\ 0.057118 \& 0.12476 \& 0.057118 \\end{array}\\right
]
归一化取整后的卷积核:
\\frac{1}{16}\\left\[\\begin{array}{lll}1 \& 2 \& 1 \\ 2 \& 4 \& 2 \\ 1 \& 2 \& 1\\end{array}\\right
]
opencv中对应函数为cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]]]):
python
1. img = cv2.imread('gaussian_noise.bmp')
2. # 均值滤波vs高斯滤波
3. blur = cv2.blur(img, (5, 5)) # 均值滤波
4. gaussian = cv2.GaussianBlur(img, (5, 5), 1) # 高斯滤波,sigmaX = sigmaY = 1- 参数src:图片
- 参数ksize:高斯核的宽和高(必须是奇数),用元组表示。
- 参数sigmaX:水平方向的σ,值越大说明高斯函数越平缓,滤波后的图片越模糊;sigmaX为0时,由ksize.width和ksize.heigh自动确定
- 参数sigmaY:竖直方向的σ,如果sigmaY为零,则等于sigmaX
- 参数borderType:边界像素填充方式,默认是镜像填充
6.3.7 滤波器比较
不同方式滤波器的特点如下表所示:
| 滤波器种类 | 基本原理 | 特点 |
|---|---|---|
| 均值滤波 | 使用模板内所有像素的平均值代替模板中心像素灰度值 | 不能很好地保护图像细节,在图像去噪的同时也破坏了图像的细节,从而使图像变得模糊,不能很好地去除椒盐噪声 |
| 中值滤波 | 计算模板内所有像素中的中值,并用所计算出来的中值替代模板中心像素的灰度值 | 对噪声不是那么敏感,去除斑点和椒盐噪声优先使用中值滤波,但是容易导致图像的不连续性 |
| 高斯滤波 | 对图像邻域内像素进行平滑时,邻域内不同位置的像素被赋予不同的权值 | 对图像进行平滑的同时,能够更多的保留图像的总体灰度分布特征 |
7 机械臂控制
在缺陷检测过程中,识别到缺陷,需要通知机械臂进行抓取动作,将识别到的缺陷铝片捡取出来。
7.1 机械臂单个舵机控制
控制单个总线舵机对应的API为:
Arm_serial_servo_write(id, angle, time)
函数功能:控制总线舵机要运行到的角度。
参数解释:
- id:要控制的舵机的ID号,范围是1~6,每个ID号表示一个舵机,从最底端的舵机的ID为1,往上依次增加,最上面的舵机ID为6。
- angle:控制舵机要运行到的角度,除了5号舵机(ID=5),其他舵机的控制范围都是0180,5号舵机的控制范围是0270。
- time:控制舵机运行的时间,在有效范围内,舵机转动相同的角度,输入运行的时间越小,舵机运动越快。输入0则舵机以最快速度运行。
返回值:无。
代码如下:
python
1. import time
2. from Arm_Lib import Arm_Device
3. # 创建机械臂对象
4. Arm = Arm_Device()
5. time.sleep(.1)
6. # 单独控制一个舵机运动到某个角度
7. id = 6
8. Arm.Arm_serial_servo_write(id, 90, 500)
9. time.sleep(1)7.2 机械臂多个舵机同时控制
一次控制6个总线舵机对应的API为:
Arm_serial_servo_write6(S1, S2, S3, S4, S5, S6, time)
函数功能:同时控制机械臂的六个舵机要运动到的角度。
参数解释:
- S1:1号舵机的角度值0~180。
- S2:2号舵机的角度值0~180。
- S3:3号舵机的角度值0~180。
- S4:4号舵机的角度值0~180。
- S5:5号舵机的角度值0~270。
- S6:6号舵机的角度值0~180。
- time:控制舵机运行的时间,在有效范围内,舵机转动相同的角度,输入运行的时间越小,舵机运动越快。输入0则舵机以最快速度运行。
返回值:无。
代码如下:
python
1. import time
2. from Arm_Lib import Arm_Device
3. # 创建机械臂对象
4. Arm = Arm_Device()
5. time.sleep(.1)
6. # 同时控制六个舵机运动,逐渐变换角度。
7. def ctrl_all_servo(angle, s_time = 500):
8. Arm.Arm_serial_servo_write6(angle, 180-angle, angle, angle, angle, angle, s_time)
9. time.sleep(s_time/1000)
10. def main():
11. dir_state = 1
12. angle = 90
13. # 让舵机复位归中
14. Arm.Arm_serial_servo_write6(90, 90, 90, 90, 90, 90, 500)
15. time.sleep(1)
16. while True:
17. if dir_state == 1:
18. angle += 1
19. if angle >= 180:
20. dir_state = 0
21. else:
22. angle -= 1
23. if angle <= 0:
24. dir_state = 1
25. ctrl_all_servo(angle, 10)
26. time.sleep(10/1000)
27. try:
28. main()
29. except KeyboardInterrupt:
30. print(" Program closed! ")
31. pass
32. del Arm # 释放掉Arm对象7.3 机械臂单个舵机位置读取
读取单个总线舵机的角度对应的API为:
Arm_serial_servo_read(id)
函数功能:读取总线舵机当前的角度值。
参数解释:
- id:要读取的舵机的ID号,范围是1~6,每个ID号表示一个舵机,从最底端的舵机的ID为1,往上依次增加,最上面的舵机ID为6。
返回值 :对应ID舵机当前的角度,ID=5时,角度范围为0270,其他都为0180。
代码如下:
python
1. import time
2. from Arm_Lib import Arm_Device
3. # 创建机械臂对象
4. Arm = Arm_Device()
5. time.sleep(.1)
6. # 单独控制一个舵机运动后,再读取它的角度
7. id = 6
8. angle = 150
9. Arm.Arm_serial_servo_write(id, angle, 500)
10. time.sleep(1)
11. aa = Arm.Arm_serial_servo_read(id