以下以 CUDA 和 OpenCL 为例,结合操作系统如何管理 GPU 资源进行深度解析,包含多线程、进程管理、内存分配和任务调度的具体实现:
一、操作系统管理 CUDA 资源的全流程
场景:多进程并发运行 CUDA 程序
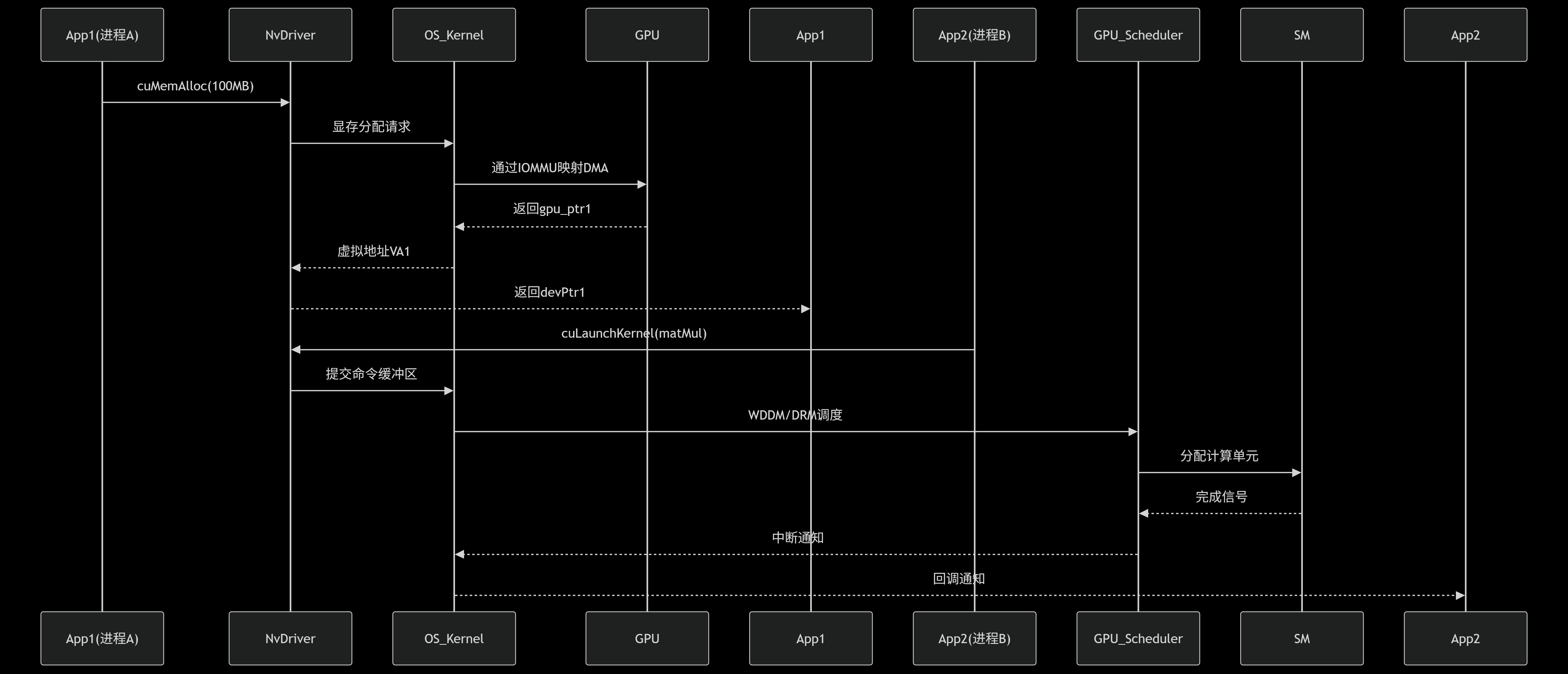
关键技术点:
-
进程隔离
CUDA 上下文绑定到进程 PID:
cpp// 进程A的上下文 cuCtxCreate(&ctxA, CU_CTX_SCHED_AUTO, device); cuCtxSetCurrent(ctxA); // 绑定当前进程操作系统通过 DRM GEM 对象隔离不同进程的 GPU 资源
-
内存分配
操作系统通过 IOMMU 重映射:
cpp# Linux启用IOMMU $ echo "group_id > /sys/kernel/iommu_groups/0/devices"- CPU 虚拟地址 → IOMMU → GPU 物理地址
- 避免 PCIe 传输时 CPU 参与拷贝
-
任务抢占(NVIDIA Pascal+)
操作系统发送 抢占指令:
cpp// WDDM 内核调用 dxgkSubmitCommand->flags = DXGK_SUBMIT_PREEMPT;- 微秒级上下文切换(保存 SM 寄存器状态)
二、OpenCL 资源管理核心机制
OpenCL 架构与操作系统交互
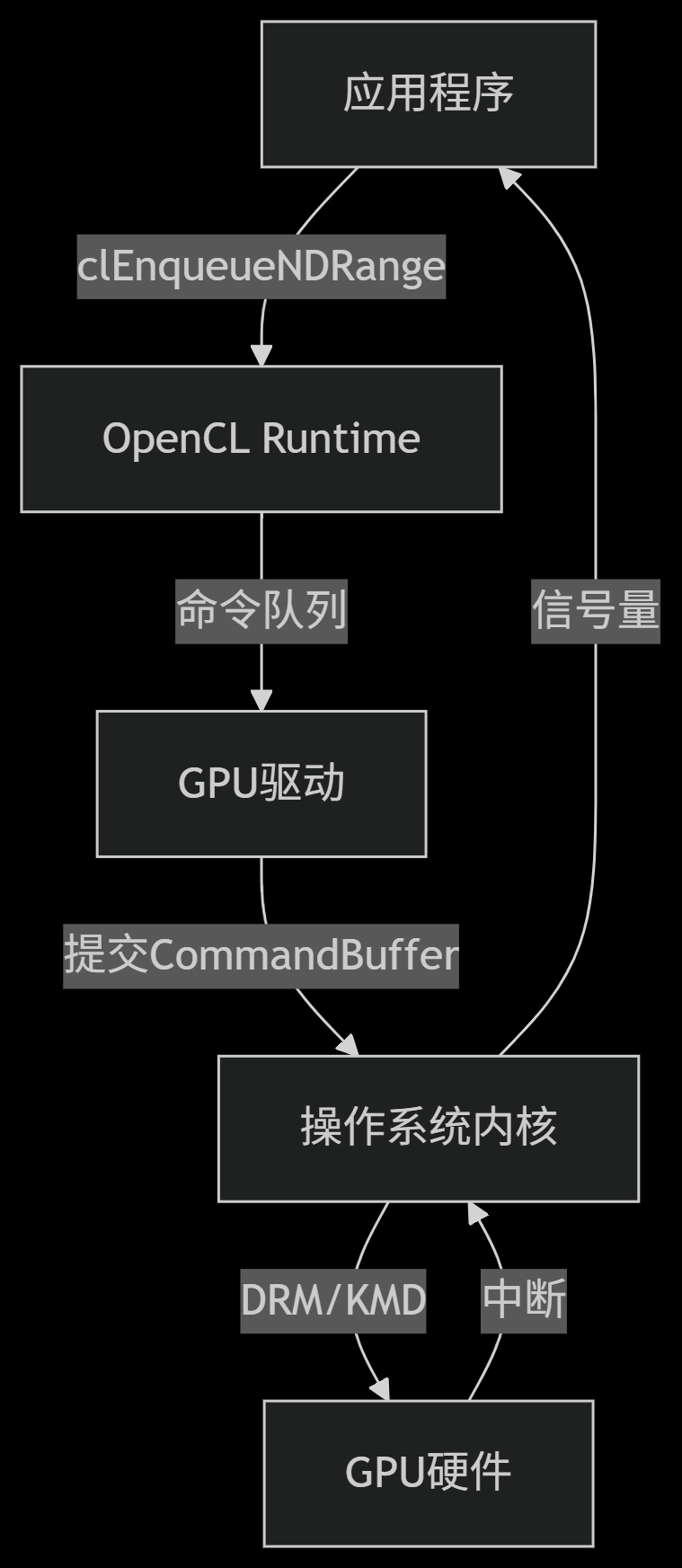
关键操作详解:
-
多设备发现
操作系统枚举 PCIe 设备:
cppclGetDeviceIDs(CL_DEVICE_TYPE_GPU, 1, &device, NULL); // 底层调用pci_get_device(PCI_VENDOR_ID_AMD) -
共享内存分配
操作系统管理 SVM (Shared Virtual Memory):
cppvoid* ptr = clSVMAlloc(context, CL_MEM_READ_WRITE, size, 0); // Linux内核触发mmap(MAP_SHARED)- CPU 和 GPU 共享同一虚拟地址空间
- 操作系统处理页错误和一致性
-
多进程同步
使用操作系统级信号量:
cppclEnqueueMarkerWithWaitList(queue, 0, NULL, &event); clEnqueueBarrierWithWaitList(queue); // 底层调用futex(FUTEX_WAIT)
三、操作系统调度策略对比
| 特性 | CUDA (Windows WDDM) | OpenCL (Linux DRM) |
|---|---|---|
| 调度模型 | 基于时间量子的抢占式 | 公平队列(FIFO)+优先级 |
| 抢占粒度 | 指令级 (Pascal+) | 内核级 (>=AMD CDNA2) |
| 上下文切换 | <10μs | 20-50μs |
| 内存迁移 | On-Demand Paging | SVM + HMM(Heterogeneous Memory Management) |
| 多进程支持 | MPS(Multi-Process Service) | 原生进程隔离 |
| 实时性保证 | WDDM 2.0+ 支持 | SCHED_FIFO 实时优先级 |
四、实战:操作系统如何解决资源冲突
场景:游戏(进程A) 和 AI推理(进程B) 争用 GPU
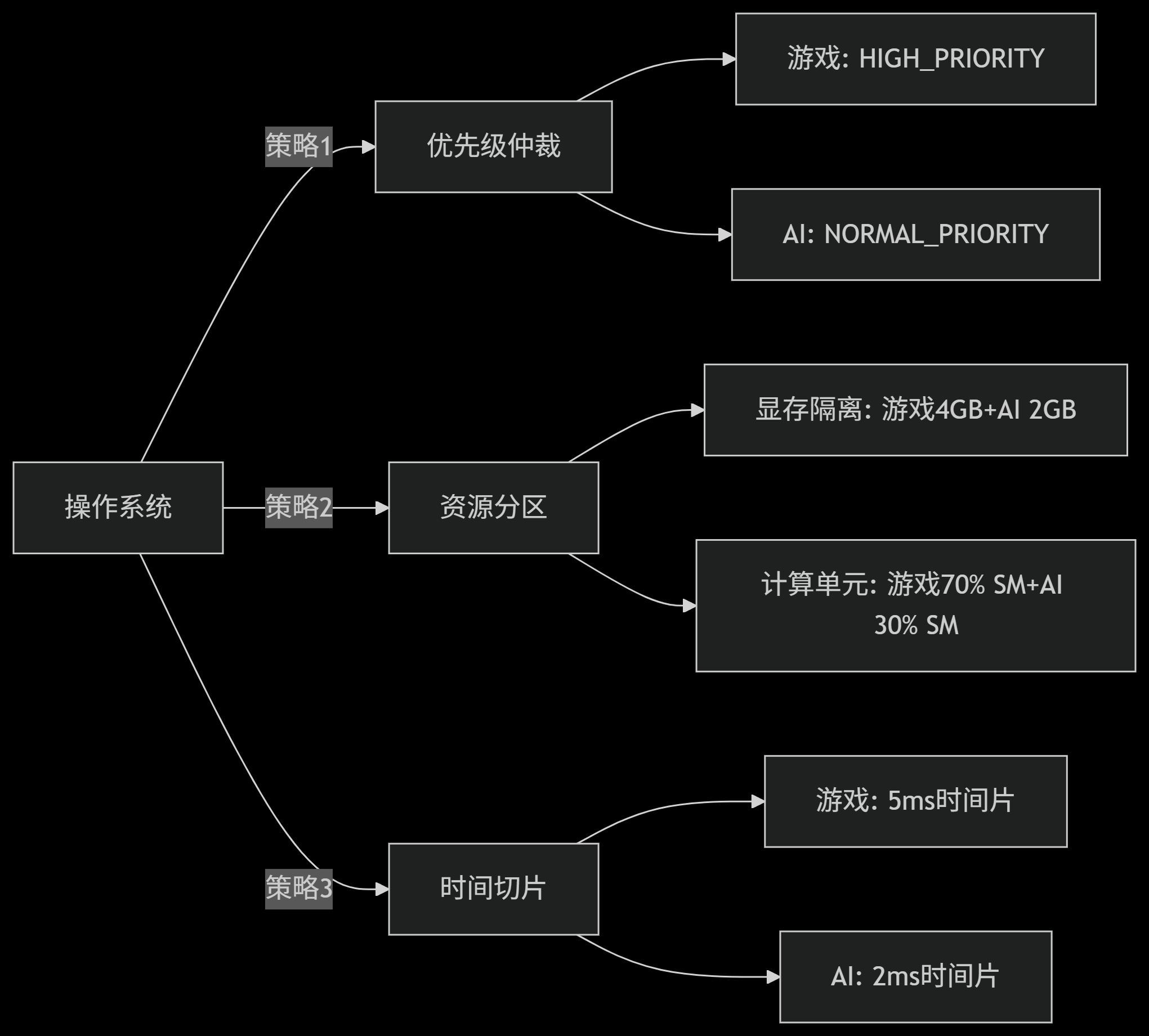
具体实现:
-
CUDA 资源分区 (Ampere MIG)
cpp# 划分GPU实例 nvidia-smi mig -cgi 2g.10gb -C -
OpenCL 优先级设置
cppcl_queue_properties props[] = { CL_QUEUE_PRIORITY_KHR, CL_QUEUE_PRIORITY_HIGH_KHR, 0 }; queue = clCreateCommandQueueWithProperties(context, device, props, NULL);
五、开发者视角:如何高效利用OS管理
CUDA 最佳实践
-
减少上下文切换
cpp// 避免频繁上下文创建/销毁 cuCtxCreate(&ctx, CU_CTX_BLOCKING_SYNC, dev); // 长期持有 -
锁页内存加速传输
cppcudaHostAlloc(&hostPtr, size, cudaHostAllocMapped); -
流优先级控制
cppcudaStreamCreateWithPriority(&stream, cudaStreamDefault, -1); // 高优先级
OpenCL 优化技巧
-
SVM 零拷贝优化
cppcl_device_svm_capabilities caps; clGetDeviceInfo(device, CL_DEVICE_SVM_CAPABILITIES, sizeof(caps), &caps, NULL); -
共享命令队列
cppqueue = clCreateCommandQueue(context, device, CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE, NULL); -
原子操作避免CPU同步
cpp__kernel void counter(__global atomic_int* count) { atomic_fetch_add(count, 1); }
六、底层原理:Linux DRM 子系统源码解析
关键操作 (drivers/gpu/drm/drm_scheduler.c)
cpp
// GPU任务调度核心
void drm_sched_main(struct work_struct *work) {
while (!list_empty(&sched->pending_list)) {
struct drm_sched_entity *entity = pick_entity(sched);
struct drm_sched_fence *s_fence = entity->s_fence;
// 提交到硬件队列
drm_sched_job_begin(s_fence);
drm_sched_job_submit(entity->job);
// 时间片检查
if (time_after(jiffies, entity->slice_end)) {
drm_sched_preempt(entity); // 触发抢占
}
}
}
// 显存分配(TTM管理器)
int ttm_bo_alloc(struct ttm_bo_device *bdev, size_t size, ...) {
ttm_bo_create_handle(bo); // 创建GPU可见对象
ttm_bo_map_virtual(bo); // CPU虚拟地址映射
}七、性能监控工具
操作系统级监控
| 工具 | 功能 | 示例命令 |
|---|---|---|
nvidia-smi |
GPU利用率/显存 | nvidia-smi -l 1 |
rocminfo |
AMD GPU状态 | rocminfo |
drm_info |
DRM设备详情 | drm_info -v |
perf |
内核调度事件 | perf record -e sched:sched_switch |
关键指标:
cpp
# 监控上下文切换
$ cat /sys/kernel/debug/dri/0/amdgpu_gpu_recovery
# 输出:preempt_count=12, avg_delay=18us总结:操作系统管理的核心价值
- 资源虚拟化
- 通过 IOMMU/SVM 实现统一内存视图
- 显存隔离(MIG/vGPU)分级调度
- OS 级:WDDM/DRM 时间片调度
- 硬件级:CUDA Stream/OpenCL Queue
- 故障隔离
- 进程崩溃不影响 GPU 稳定性
- 自动恢复挂起任务(TDR)
- 性能仲裁
- 优先级抢占(游戏 > 计算任务)
- 资源动态分区(显存/SM 配额)
理解操作系统如何管理 GPU,能帮助开发者:
- 避免资源冲突(如显存碎片)
- 优化上下文切换开销
- 设计低延迟高吞吐应用
- 实现多进程协同计算