特殊符号和字符
本节将介绍最常见的特殊符号和字符,即所谓的元字符,正是它给予正则表达式强大的
功能和灵活性。表1-1 列出了这些最常见的符号和字符。
使用择一匹配符号匹配多个正则表达式模式
表示择一匹配的管道符号(|),也就是键盘上的竖线,表示一个"从多个模式中选择其
一"的操作。它用于分割不同的正则表达式。例如,在下面的表格中,左边是一些运用择一
匹配的模式,右边是左边相应的模式所能够匹配的字符。

有了这个符号,就能够增强正则表达式的灵活性,使得正则表达式能够匹配多个字符串
而不仅仅只是一个字符串。择一匹配有时候也称作并(union)或者逻辑或(logical OR)。
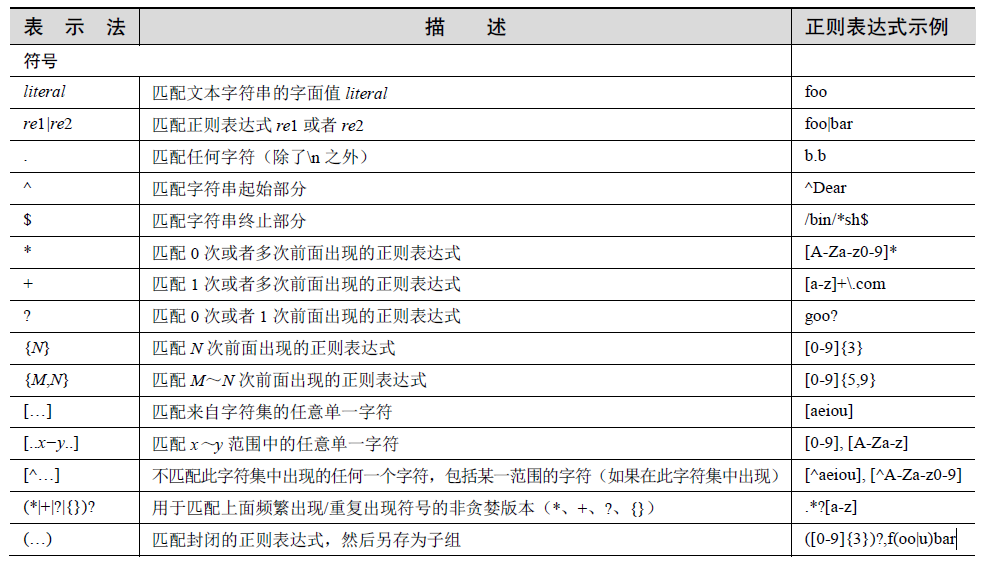
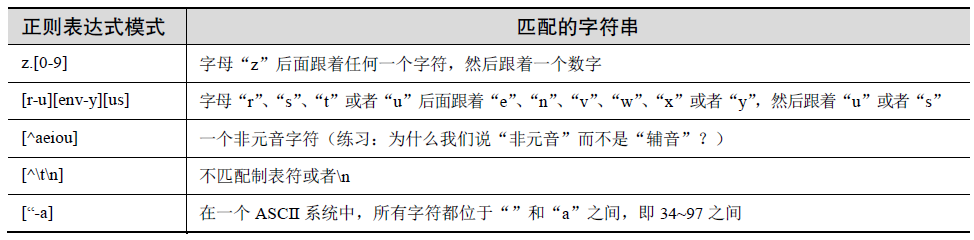
匹配任意单个字符
点号或者句点(.)符号匹配除了换行符\n 以外的任何字符(Python 正则表达式有一个编译标记S 或者DOTALL,该标记能够推翻这个限制,使点号能够匹配换行符)。无论字母、
数字、空格(并不包括"\n"换行符)、可打印字符、不可打印字符,还是一个符号,使用点
号都能够匹配它们。

- 问:怎样才能匹配句点(dot)或者句号(period)字符?
- 答:要显式匹配一个句点符号本身,必须使用反斜线转义句点符号的功能,例如"."。
从字符串起始或者结尾或者单词边界匹配
还有些符号和相关的特殊字符用于在字符串的起始和结尾部分指定用于搜索的模式。如
果要匹配字符串的开始位置,就必须使用脱字符(^)或者特殊字符\A(反斜线和大写字母A)。
后者主要用于那些没有脱字符的键盘(例如,某些国际键盘)。同样,美元符号($)或者\Z
将用于匹配字符串的末尾位置。
使用这些符号的模式与本章描述的其他大多数模式是不同的,因为这些模式指定了位置
或方位。之前的"核心提示"记录了匹配(试图在字符串的开始位置进行匹配)和搜索(试
图从字符串的任何位置开始匹配)之间的差别。正因如此,下面是一些表示"边界绑定"的
正则表达式搜索模式的示例。

再次说明,如果想要逐字匹配这些字符中的任何一个(或者全部),就必须使用反斜线进
行转义。例如,如果你想要匹配任何以美元符号结尾的字符串,一个可行的正则表达式方案
就是使用模式.*$$。
特殊字符\b 和\B 可以用来匹配字符边界。而两者的区别在于\b 将用于匹配一个单词的边
界,这意味着如果一个模式必须位于单词的起始部分,就不管该单词前面(单词位于字符串
中间)是否有任何字符(单词位于行首)。同样,\B 将匹配出现在一个单词中间的模式(即,
不是单词边界)。下面为一些示例。

创建字符集
尽管句点可以用于匹配任意符号,但某些时候,可能想要匹配某些特定字符。正因如此,
发明了方括号。该正则表达式能够匹配一对方括号中包含的任何字符。下面为一些示例。

关于cr23dpo2这个正则表达式有一点需要说明:如果仅允许"r2d2"或者"c3po"
作为有效字符串,就需要更严格限定的正则表达式。因为方括号仅仅表示逻辑或的功能,
所以使用方括号并不能实现这一限定要求。唯一的方案就是使用择一匹配,例如,
r2d2|c3po。
然而,对于单个字符的正则表达式,使用择一匹配和字符集是等效的。例如,我们以正
则表达式"ab"作为开始,该正则表达式只匹配包含字母"a"且后面跟着字母"b"的字符
串,如果我们想要匹配一个字母的字符串,例如,要么匹配"a",要么匹配"b",就可以使
用正则表达式ab,因为此时字母"a"和字母"b"是相互独立的字符串。我们也可以选择
正则表达式a|b。然而,如果我们想要匹配满足模式"ab"后面且跟着"cd"的字符串,我们
就不能使用方括号,因为字符集的方法只适用于单字符的情况。这种情况下,唯一的方法就
是使用ab|cd,这与刚才提到的r2d2/c3po 问题是相同的。
限定范围和否定
除了单字符以外,字符集还支持匹配指定的字符范围。方括号中两个符号中间用连字符
(-)连接,用于指定一个字符的范围;例如,A-Z、a-z 或者0-9 分别用于表示大写字母、小
写字母和数值数字。这是一个按照字母顺序的范围,所以不能将它们仅仅限定用于字母和十
进制数字上。另外,如果脱字符(^)紧跟在左方括号后面,这个符号就表示不匹配给定字符
集中的任何一个字符。
使用闭包操作符实现存在性和频数匹配
本节介绍最常用的正则表达式符号,即特殊符号*、+和?,所有这些都可以用于匹配一
个、多个或者没有出现的字符串模式。星号或者星号操作符(*)将匹配其左边的正则表达式
出现零次或者多次的情况(在计算机编程语言和编译原理中,该操作称为Kleene 闭包)。加
号(+)操作符将匹配一次或者多次出现的正则表达式(也叫做正闭包操作符),问号(?)
操作符将匹配零次或者一次出现的正则表达式。
还有大括号操作符({}),里面或者是单个值或者是一对由逗号分隔的值。这将最终精
确地匹配前面的正则表达式N 次(如果是{N})或者一定范围的次数;例如,{M,N}将匹
配M~N 次出现。这些符号能够由反斜线符号转义;*匹配星号,等等。
注意,在之前的表格中曾经多次使用问号(重载),这意味着要么匹配0 次,要么匹配1
次,或者其他含义:如果问号紧跟在任何使用闭合操作符的匹配后面,它将直接要求正则表
达式引擎匹配尽可能少的次数。
"尽可能少的次数"是什么意思?当模式匹配使用分组操作符时,正则表达式引擎将试图
"吸收"匹配该模式的尽可能多的字符。这通常被叫做贪婪匹配。问号要求正则表达式引擎去
"偷懒",如果可能,就在当前的正则表达式中尽可能少地匹配字符,留下尽可能多的字符给
后面的模式(如果存在)。本章末尾将用一个典型的示例来说明非贪婪匹配是很有必要的。现
在继续查看闭包操作符。
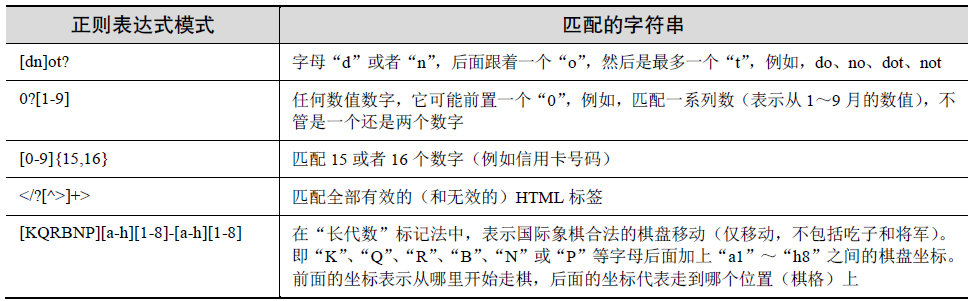
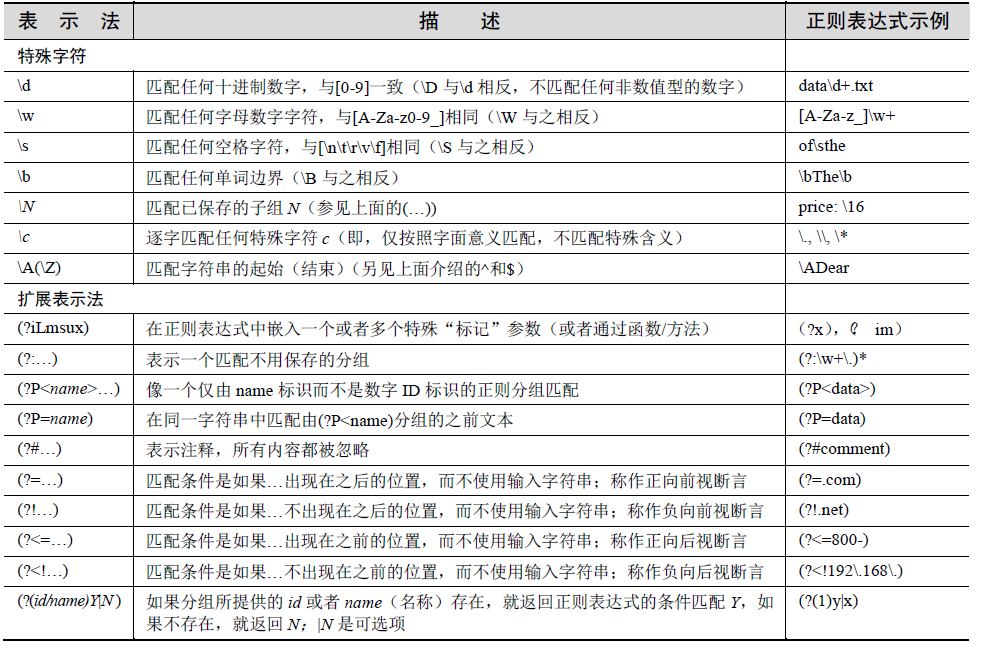
表示字符集的特殊字符
我们还提到有一些特殊字符能够表示字符集。与使用"0-9"这个范围表示十进制数相比,
可以简单地使用d 表示匹配任何十进制数字。另一个特殊字符(\w)能够用于表示全部字母
数字的字符集,相当于A-Za-z0-9_的缩写形式,\s 可以用来表示空格字符。这些特殊字符的
大写版本表示不匹配;例如,\D 表示任何非十进制数(与\^0-9相同),等等。
使用这些缩写,可以表示如下一些更复杂的示例。
使用圆括号指定分组
现在,我们已经可以实现匹配某个字符串以及丢弃不匹配的字符串,但有些时候,我们
可能会对之前匹配成功的数据更感兴趣。我们不仅想要知道整个字符串是否匹配我们的标准,
而且想要知道能否提取任何已经成功匹配的特定字符串或者子字符串。答案是可以,要实现
这个目标,只要用一对圆括号包裹任何正则表达式。
当使用正则表达式时,一对圆括号可以实现以下任意一个(或者两个)功能:
• 对正则表达式进行分组;
• 匹配子组。
关于为何想要对正则表达式进行分组的一个很好的示例是:当有两个不同的正则表达式
而且想用它们来比较同一个字符串时。另一个原因是对正则表达式进行分组可以在整个正则
表达式中使用重复操作符(而不是一个单独的字符或者字符集)。
使用圆括号进行分组的一个副作用就是,匹配模式的子字符串可以保存起来供后续使用。
这些子组能够被同一次的匹配或者搜索重复调用,或者提取出来用于后续处理。1.3.9 节的结
尾将给出一些提取子组的示例。
为什么匹配子组这么重要呢?主要原因是在很多时候除了进行匹配操作以外,我们还想
要提取所匹配的模式。例如,如果决定匹配模式\w±\d+,但是想要分别保存第一部分的字母
和第二部分的数字,该如何实现?我们可能想要这样做的原因是,对于任何成功的匹配,我
们可能想要看到这些匹配正则表达式模式的字符串究竟是什么。
如果为两个子模式都加上圆括号,例如(\w+)-(\d+),然后就能够分别访问每一个匹配
子组。我们更倾向于使用子组,这是因为择一匹配通过编写代码来判断是否匹配,然后执行另一个单独的程序(该程序也需要另行创建)来解析整个匹配仅仅用于提取两个部
分。为什么不让Python 自己实现呢?这是re 模块支持的一个特性,所以为什么非要重蹈
覆辙呢?

扩展表示法
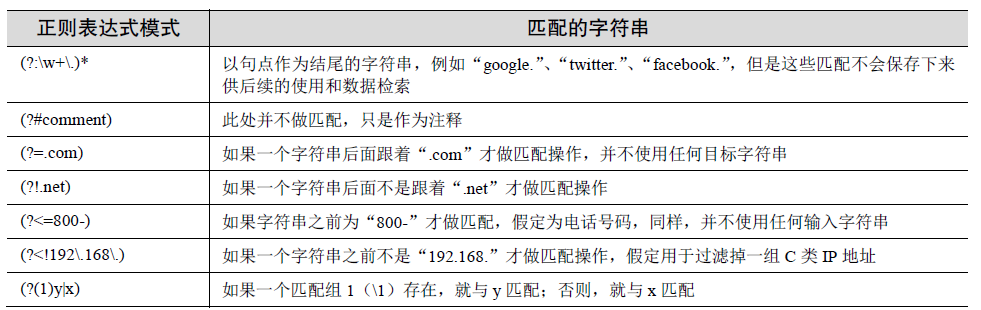
我们还没介绍过的正则表达式的最后一个方面是扩展表示法,它们是以问号开始(?...)。
我们不会为此花费太多时间,因为它们通常用于在判断匹配之前提供标记,实现一个前视(或
者后视)匹配,或者条件检查。尽管圆括号使用这些符号,但是只有(?P)表述一个
分组匹配。所有其他的都没有创建一个分组。然而,你仍然需要知道它们是什么,因为它们
可能最适合用于你所需要完成的任务。