引言
2025 年 6 月 30 日,百度文心大模型 4.5 系列正式开源,并首发于 GitCode 平台!这一重磅消息在 AI 领域掀起了不小的波澜。作为国内最早布局大模型研发的企业之一,百度所推出的文心大模型目前已跻身国内顶级大模型行列,此次开源无疑将对各行各业产生深远影响,进一步加速大模型的发展进程。接下来,就让我们一同探究文心一言 4.5 开源版本地化部署的表现与潜力。

文章目录
- 引言
- [一、文心大模型 ERNIE 4.5 开源介绍](#一、文心大模型 ERNIE 4.5 开源介绍)
-
- [1.1 开源版本介绍](#1.1 开源版本介绍)
- [1.1 ERNIE 4.5 的主要特点和区别](#1.1 ERNIE 4.5 的主要特点和区别)
- [二、文心ERNIE 4.5 技术解析](#二、文心ERNIE 4.5 技术解析)
-
- [2.1 多模态异构 MOE](#2.1 多模态异构 MOE)
- [2.2 高效训练与并行架构](#2.2 高效训练与并行架构)
- [2.3 针对特定模态的后训练策略](#2.3 针对特定模态的后训练策略)
- [三、文心一言 4.5 开源版本地化部署](#三、文心一言 4.5 开源版本地化部署)
-
- [3.1 部署环境准备](#3.1 部署环境准备)
- [3.2 安装部署工具](#3.2 安装部署工具)
- [3.3 拉取 文心 ERNIE 4.5 启动大模型](#3.3 拉取 文心 ERNIE 4.5 启动大模型)
- [3.4 本地化部署总结](#3.4 本地化部署总结)
- [四 部署测试](#四 部署测试)
-
- [4.1 测试环境准备](#4.1 测试环境准备)
- [4.2 通识基础测试](#4.2 通识基础测试)
- [4.3 中文复杂语境测试](#4.3 中文复杂语境测试)
- [4.4 写作能力测试](#4.4 写作能力测试)
- 五、总结
一、文心大模型 ERNIE 4.5 开源介绍
1.1 开源版本介绍
文心 ERNIE 4.5 本次开源一次性发布了 10 款模型,覆盖基础、对话、多模态、思考等多个方向,此次开源的模型构建起从 0.3B(3 亿参数)到 424B(4240 亿参数)的完整梯度矩阵,能够精准匹配多样化场景的需求,为不同规模、不同类型的应用场景提供了恰到好处的技术支撑。
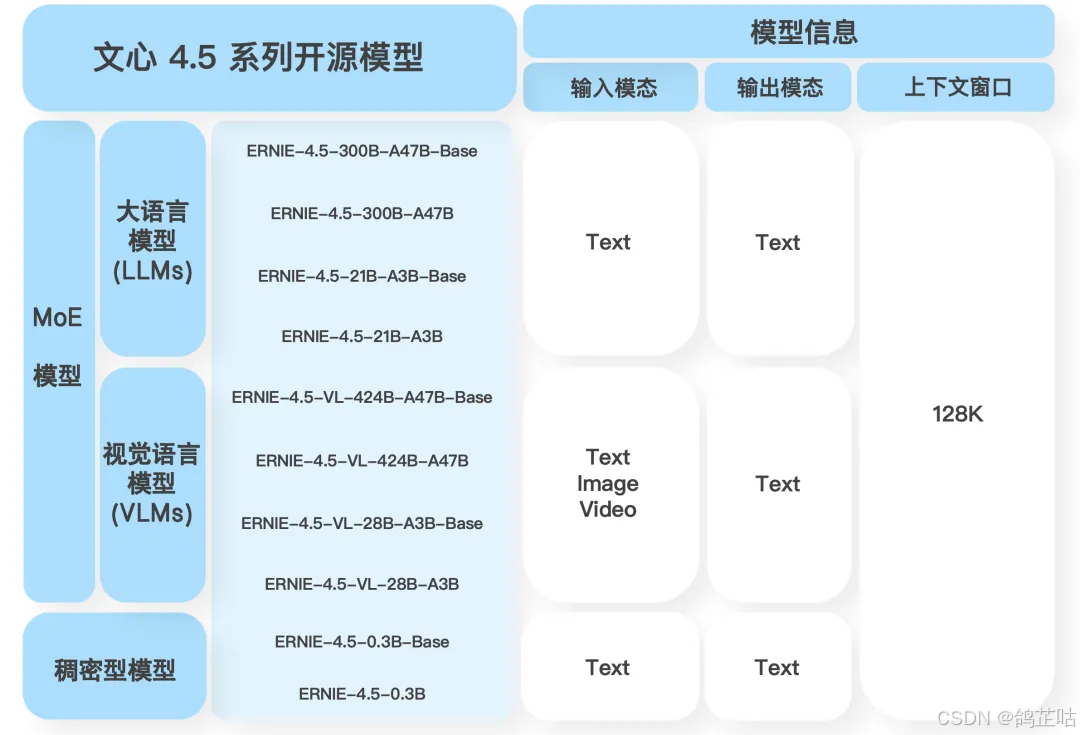
从百度文心官方公布的这张图中可以清晰看到,本次开源的大模型主要分为两类:一类是专注于文本处理的语言模型(LLMs);另一类是能够处理多种模态数据的视觉 - 语言模型(VLMs)。其中,普通模型以文本处理为核心,而带有 "VL" 标识的模型则具备多模态处理能力,能够实现对文本、图像等多种形式数据的理解与生成。
1.1 ERNIE 4.5 的主要特点和区别
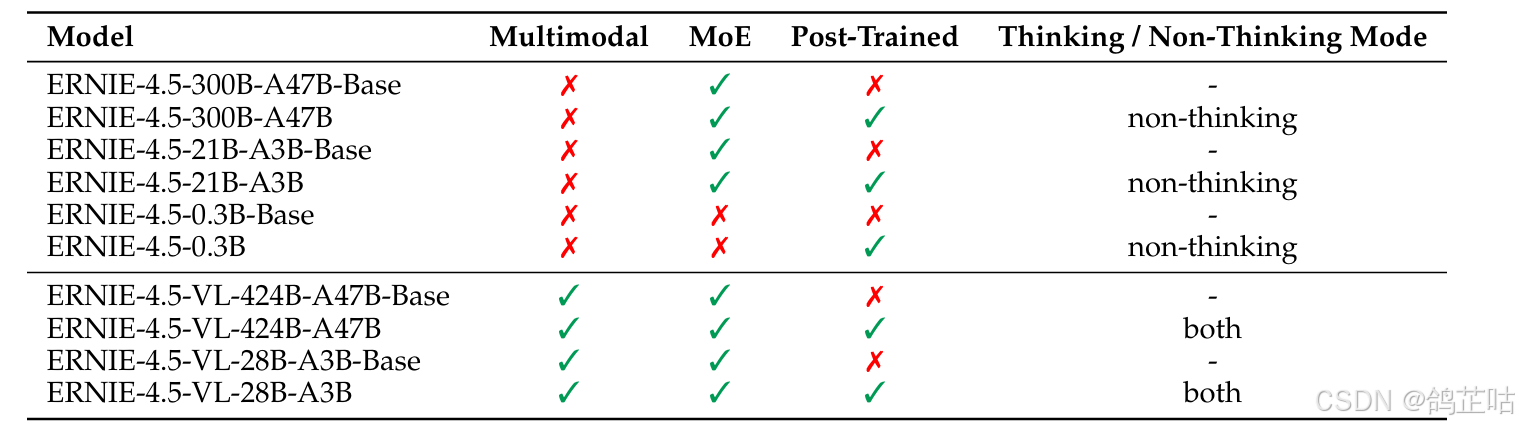
其中MoE是指专家混合(MoE)架构,除最小的 0.3B 稠密模型外,其他模型都采用了 MoE 架构。MoE架构可以动态的选择并激活不同的专家网络来处理输入,在保障高性能的同时,又有效提升了训练与推理效率。
模型名称中不带"-Base"后缀的通常表示这些模型在预训练的基础上,经过了进一步的后训练(Post-Trained)或微调,以优化其在特定应用场景下的性能。而带有"-Base"后缀的模型则是基础的预训练模型。
思考模式(Thinking Mode)与非思考模式(Non-Thinking Mode): 在"non-thinking"模式下,模型可以直接给出答案,无需复杂的推理过程。"both" 模式(多见于 VL 模型)则使模型能根据任务需求,在直接响应与更深层次的 "思考"(即复杂推理和分析)之间灵活切换。
二、文心ERNIE 4.5 技术解析
2.1 多模态异构 MOE
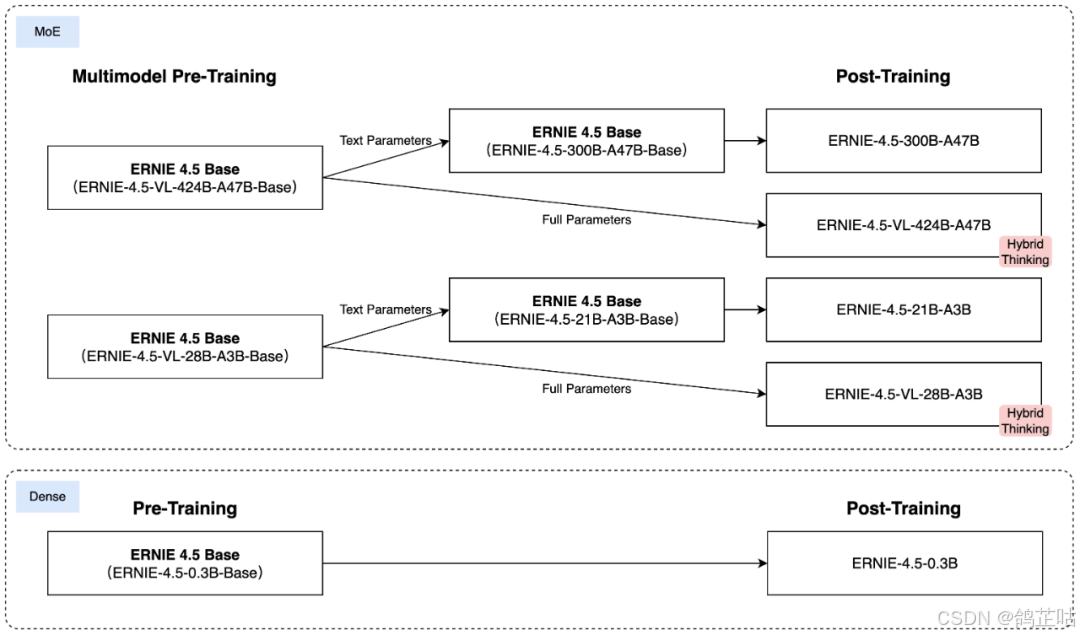
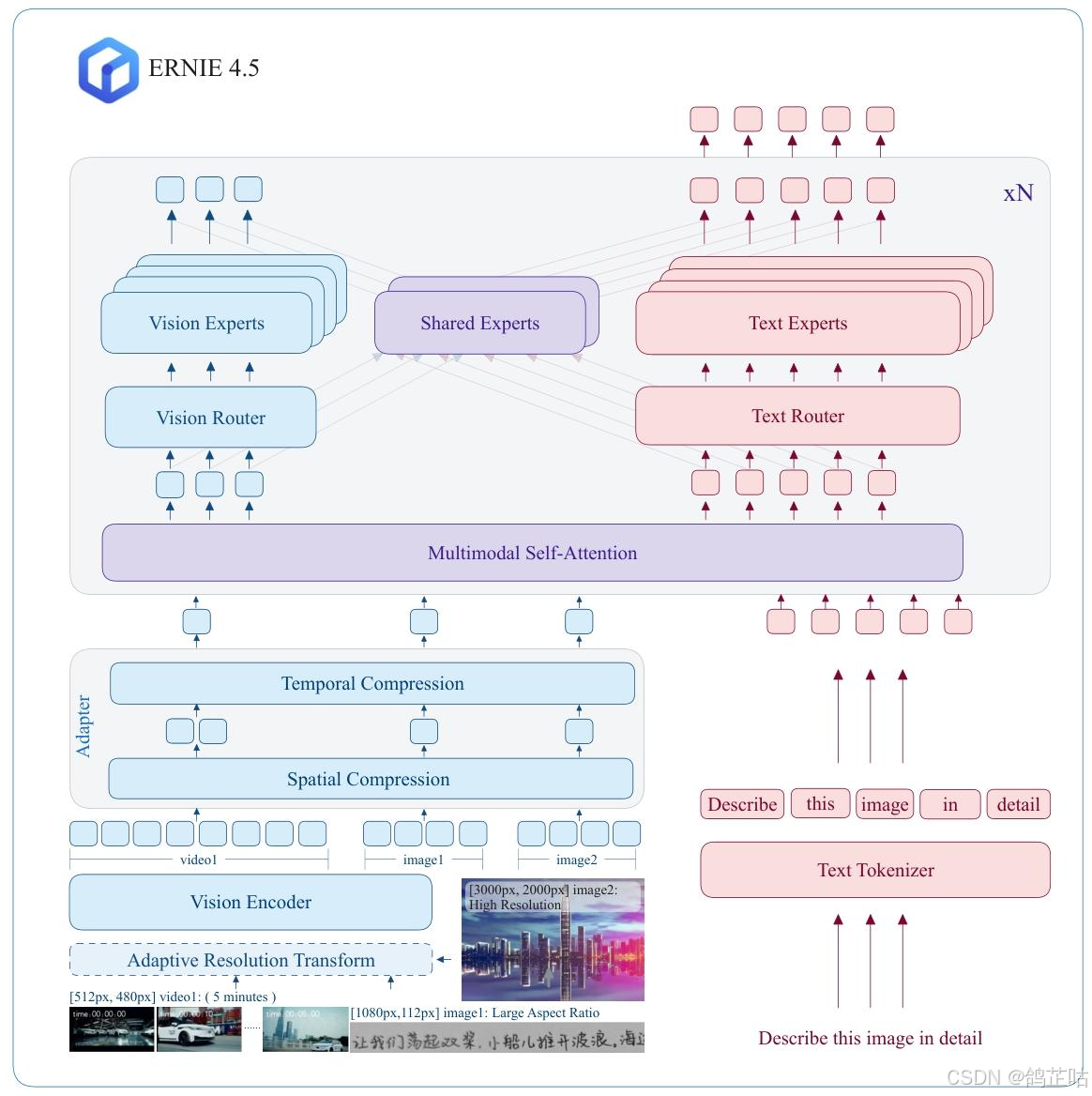
异构MoE(Heterogeneous MoE)作为ERNIE 4.5的核心架构,其创新的"异构模态MoE" 设计巧妙破解了多模态模型训练中的关键矛盾。该架构不仅支持跨模态参数共享(涵盖自注意力参数与专家参数共享),还能为各独立模态配置专用参数,实现了共享与专属的灵活平衡。
与传统的统一MoE不同,ERNIE 4.5将专家(Experts)明确划分为三类:文本专家、视觉专家和共享专家。此外,文心还引入了一种模态感知的专家分配策略,其中视觉专家的参数仅为文本专家的三分之一,从而提高了视觉信息处理的效率。
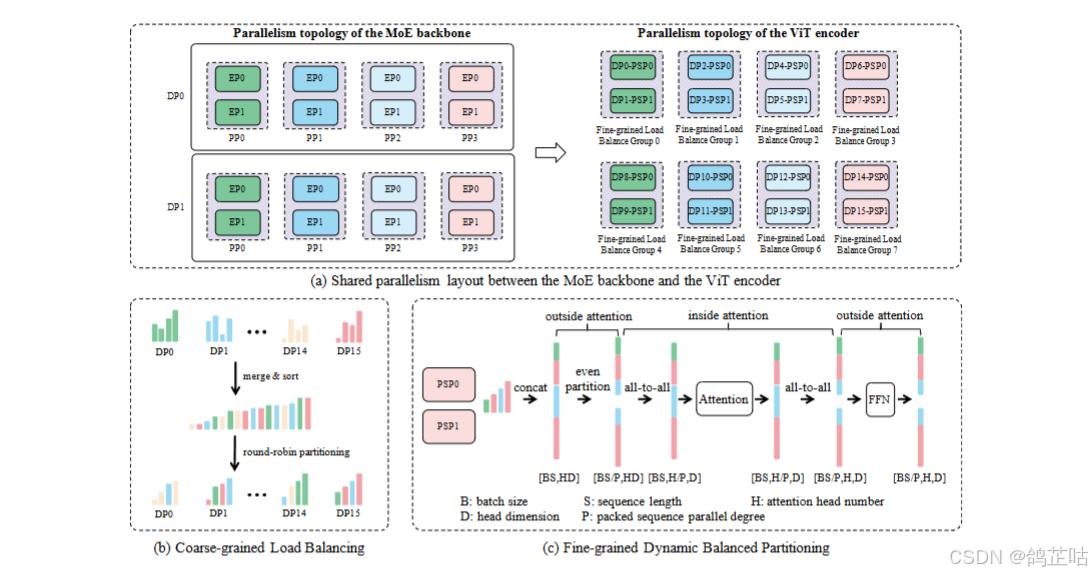
2.2 高效训练与并行架构
在训练与推理环节文心也实现了关键的技术突破,在训练方面采用了异构并行策略融入 FP8 混合精度训练框架和容错系统,优化内存、通信和计算开销,其最大语言模型采用 8 路专家并行、12 路管道并行和 ZeRO-1 数据并行配置,实现 47% 的 MFU,来支撑超大规模模型开源落地。
2.3 针对特定模态的后训练策略
针对特定模态的后训练:为了满足实际应用的多样化需求,百度针对特定模态对预训练模型的变体进行了微调。其大模型针对通用语言理解和生成进行了优化。
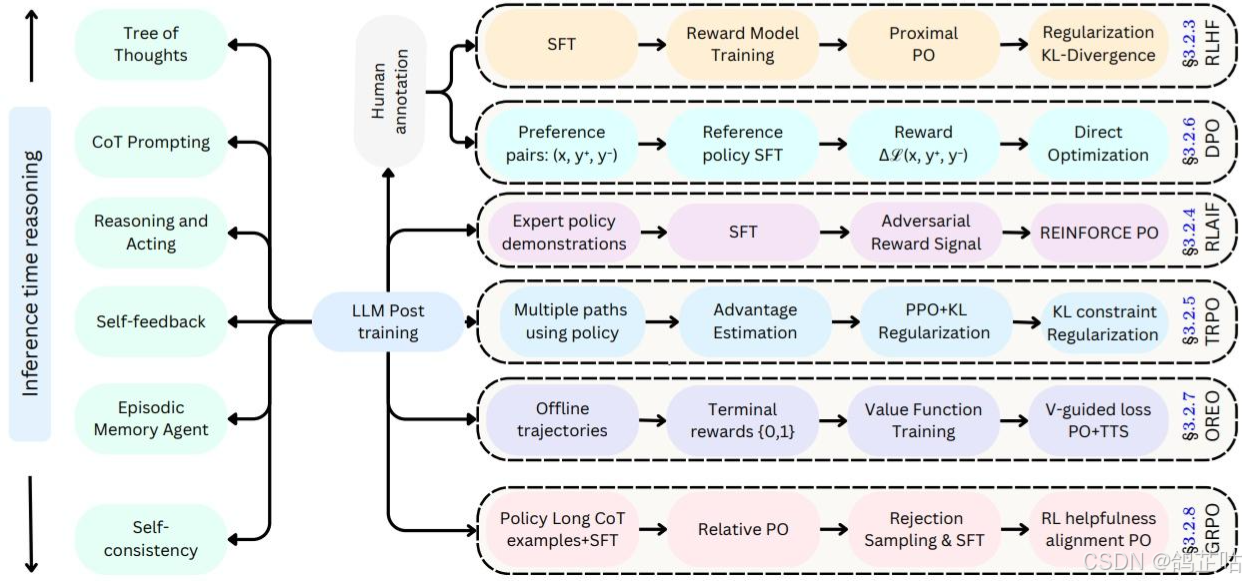
对特定的模态的训练策略进行微调,对每个模型采用SFT(监督微调)手把手"教模型怎么做", DPO(直接偏好优化)通过用户偏好直接优化模型输出,让用户更喜欢模型的回答, UPO(统一偏好优化)使模型在多任务场景,能同时兼顾用户的多种偏好,来满足实际应用的不同要求。
三、文心一言 4.5 开源版本地化部署
相信经过以上介绍,大家对文心 ERNIE 4.5 大模型的架构技术及各开源版本的特点与差异已有清晰认识。接下来,我们就直接进入大家都期待的本地化部署流程。
3.1 部署环境准备
下面是文心4.5 不同型号模型对配置的要求,我们本次本地部署现在
ERNIE-4.5-0.3B-PT的这个版本的轻量级模型,仅需一张4090系列显卡就满足配置要求了。
| 模型名称 | 上下文长度 | 量化方式 | 最低部署资源 | 说明 |
|---|---|---|---|---|
| baidu/ERNIE-4.5-VL-424B-A47B-Paddle | 32K/128K | WINT4 | 4×80G GPU 显存/1T 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-VL-424B-A47B-Paddle | 32K/128K | WINT8 | 8×80G GPU 显存/1T 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Paddle | 32K/128K | WINT4 | 4×64G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Paddle | 32K/128K | WINT8 | 8×64G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-2Bits-Paddle | 32K/128K | WINT2 | 1×141G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-W4A8C8-TP4-Paddle | 32K/128K | W4A8C8 | 4×64G GPU 显存/160G 内存 | 固定 4-GPU 配置,建议启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-FP8-Paddle | 32K/128K | FP8 | 8×64G GPU 显存/600G 内存 | 建议启用分块预填充,仅支持带专家并行的 PD 分离部署 |
| baidu/ERNIE-4.5-300B-A47B-Base-Paddle | 32K/128K | WINT4 | 4×64G GPU 显存/600G 内存 | 建议启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Base-Paddle | 32K/128K | WINT8 | 8×64G GPU 显存/600G 内存 | 建议启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 32K | WINT4 | 1×24G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 128K | WINT4 | 1×48G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Paddle | 32K/128K | WINT4 | 1×24G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Base-Paddle | 32K/128K | WINT4 | 1×24G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Base-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-0.3B-Paddle | 32K/128K | BF16 | 1×6G/12G GPU 显存/2G 内存 | 无 |
| baidu/ERNIE-4.5-0.3B-Base-Paddle | 32K/128K | BF16 | 1×6G/12G GPU 显存/2G 内存 | 无 |
- 对于本地部署百度提供了FastDeploy一键部署工具,FastDeploy 是基于 PaddlePaddle 的大型语言模型和可视化语言模型的推理部署工具包。它提供具有核心加速技术的生产就绪型开箱即用部署的解决方案。
以下是对基于NVIDIA CUDA GPU 安装FastDeploy,需要满足以下环境
| 依赖项 | 版本要求 |
|---|---|
| GPU驱动程序 | ≥535 |
| CUDA | ≥12.3 |
| CUDNN | ≥9.5 |
| Python | ≥3.10 |
| Linux | X86_64架构 |
在这里我们选择丹模算力平台来为我们提供算力服务,适用于各种AI深度学习、高性能计算、渲染测绘、云游戏等算力租用各种场景,大家随便选择一个厂商就好。服务器配置我们选择 4090就够用了,镜像方面选择了PyTorch2.5 ,它自带了安装文心意见部署工具FastDeploy所需的环境要求,这方面就不用我们费心了非常方便。
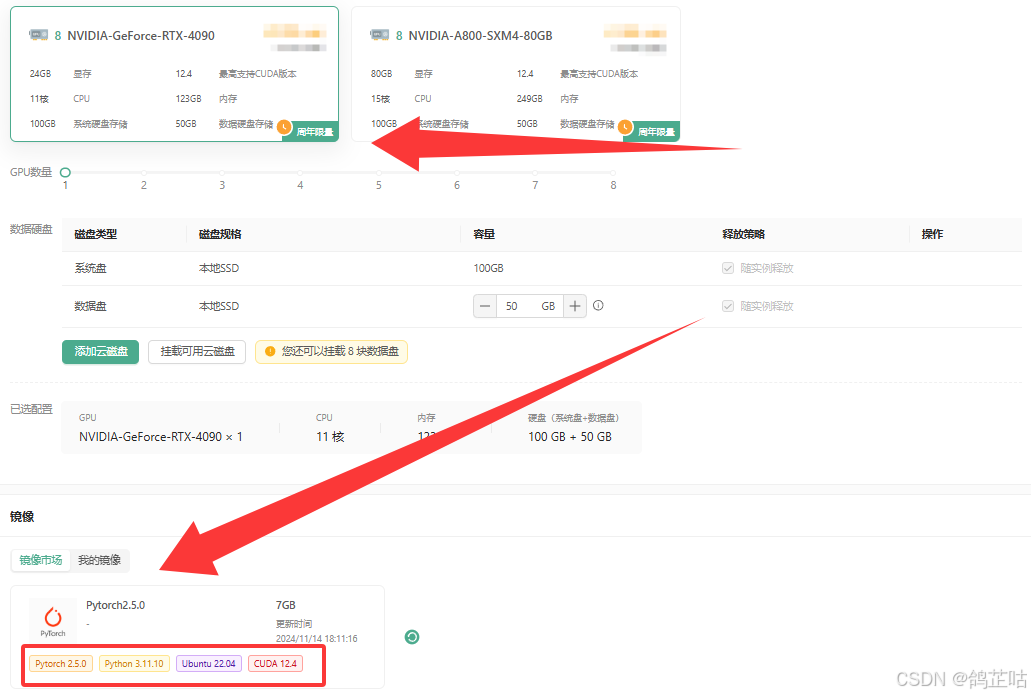
- ① 创建云实例成功后,有两种方式可连接实例:一是通过 SSH 密钥连接,二是借助 JupyterLab 可视化工具连接(推荐使用这种更便捷的方式 )。
- ② 点击进入JupyterLab可视化的工具的终端进入工作空间控制台
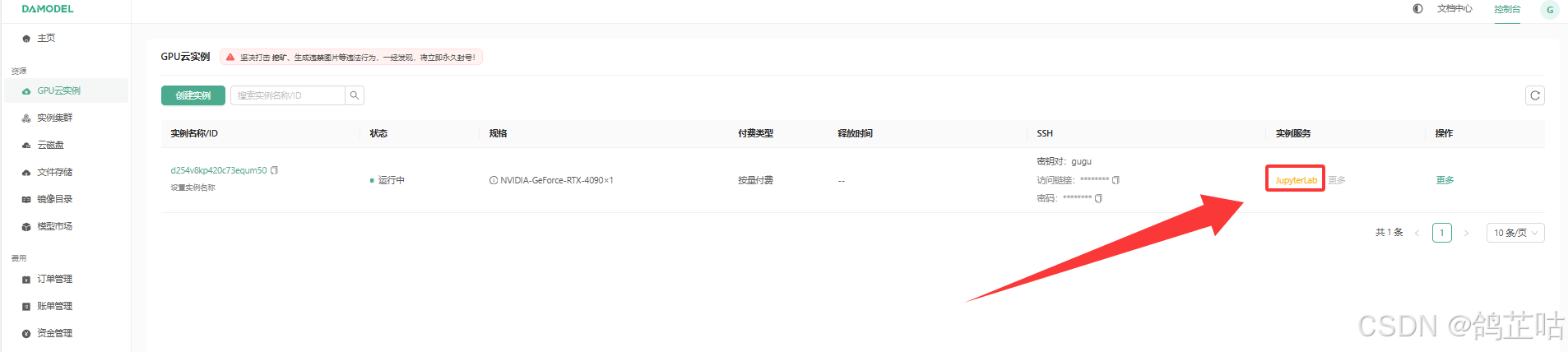
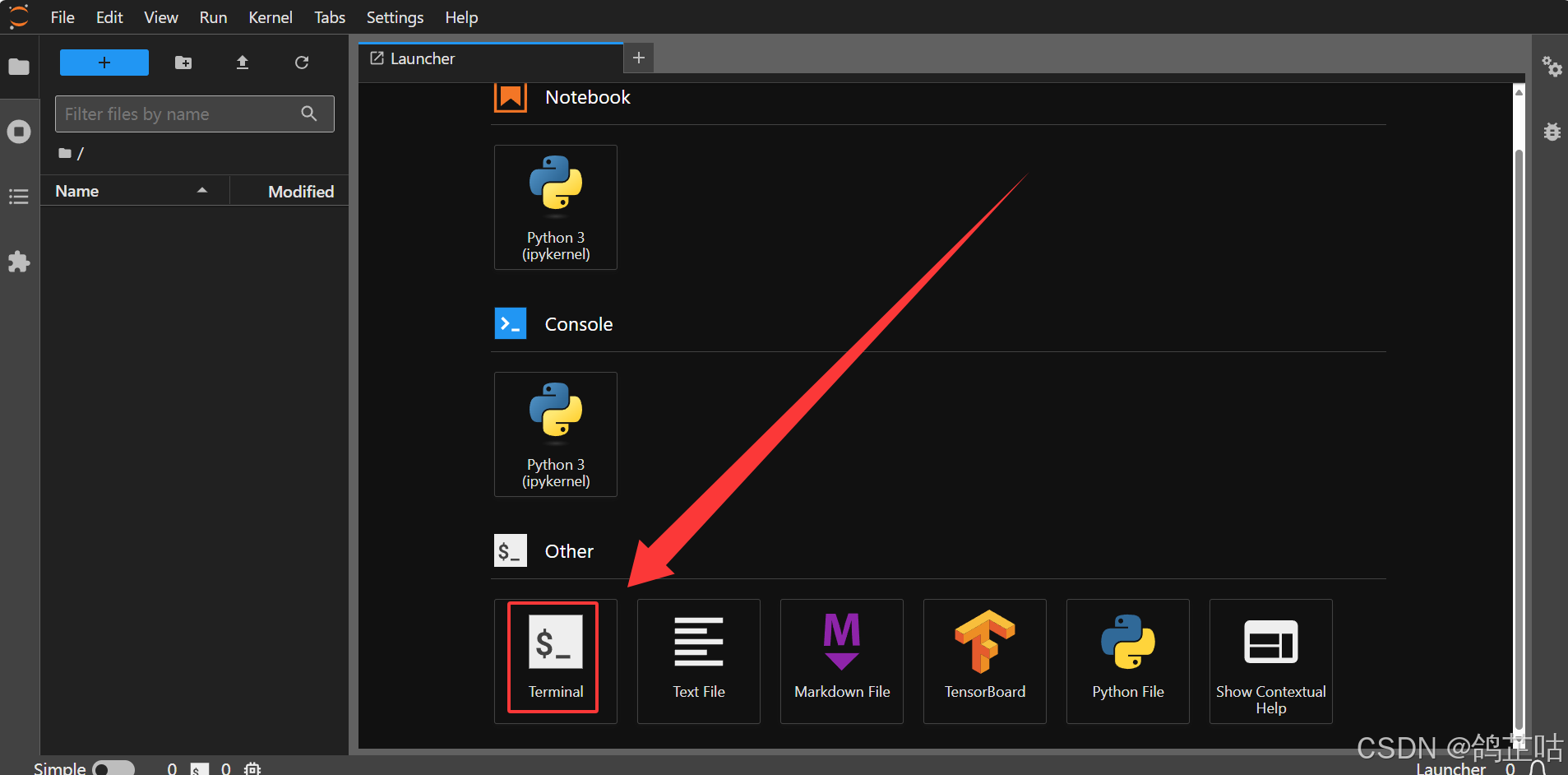
然后我们就登录到终端的工作目录,可以来安装文心4.5 FastDeploy 一键部署工具了
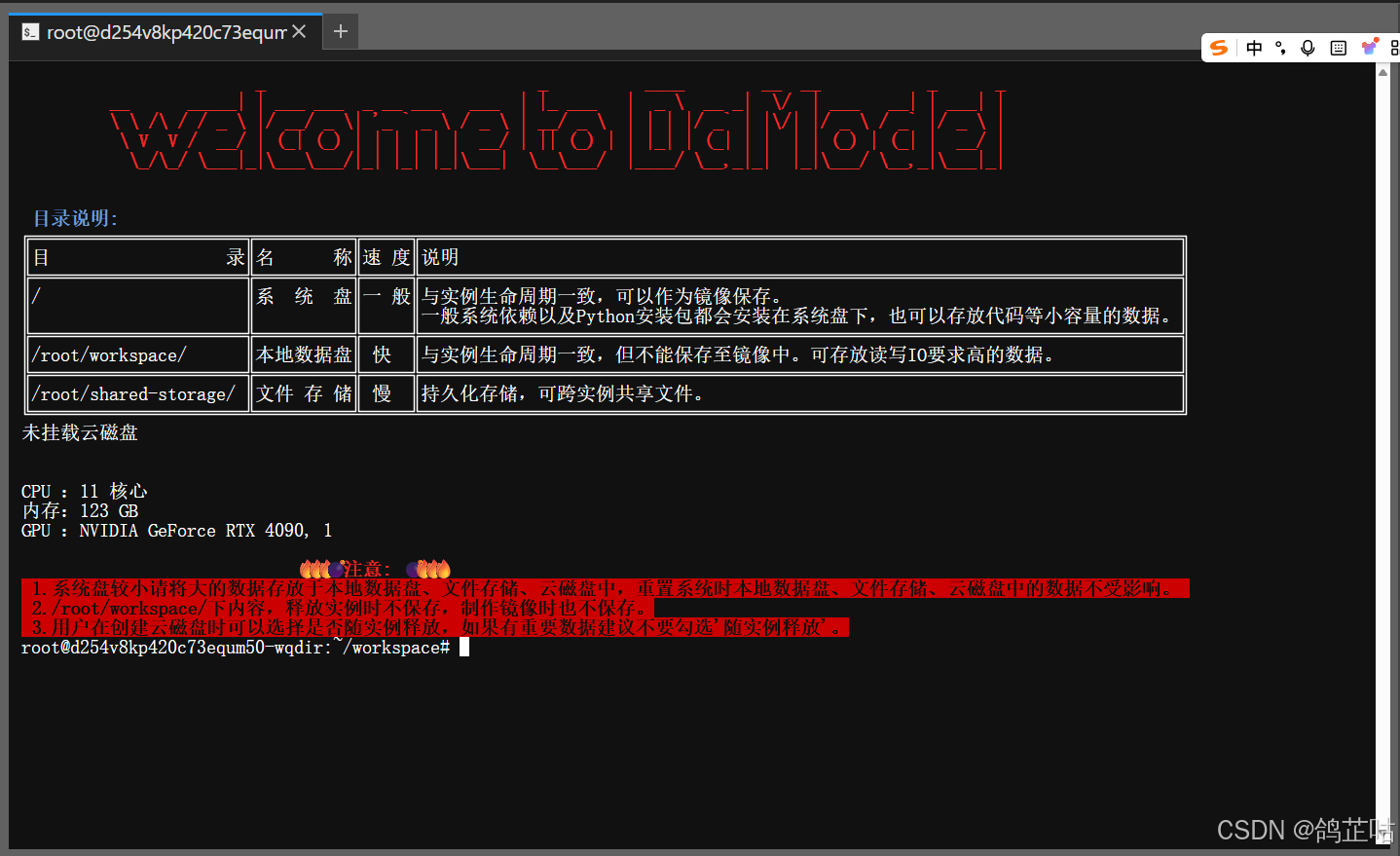
3.2 安装部署工具
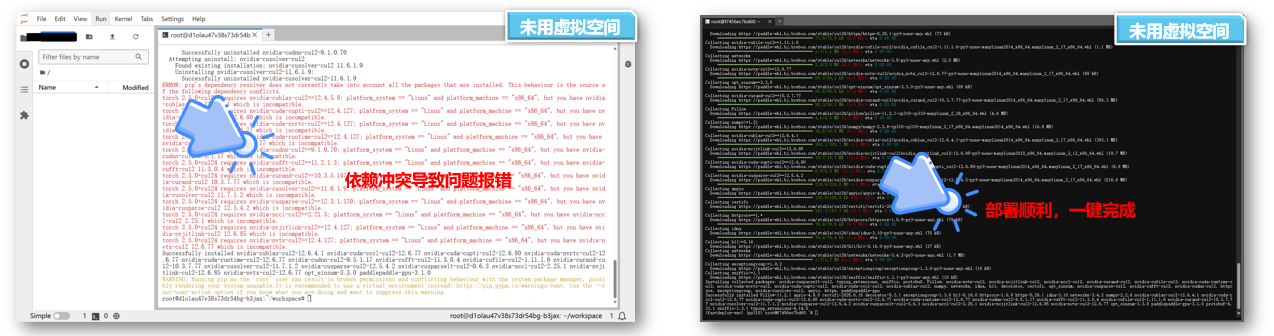
然后我们选择用python创建虚拟空间,主要是来保持保持系统环境清洁和隔离项目依赖
- ① 避免我们后续操作出现环境上的报错问题,确保依赖互不干扰
- ② 如果不用虚拟环境我们就肯会出现下面的报错
- 1. 安装虚拟环境工具
把下面命令复制粘贴输入到控制终端即可
bash
#更新软件包
apt update
#安装虚拟环境工具
apt install -y python3-venv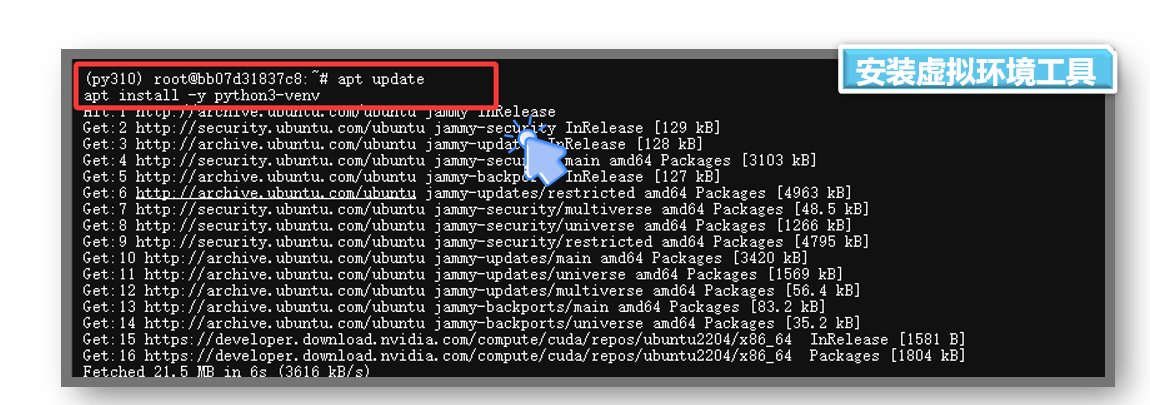
- 2. 创建虚拟环境,创建名为 fastdeploy-env 的虚拟环境
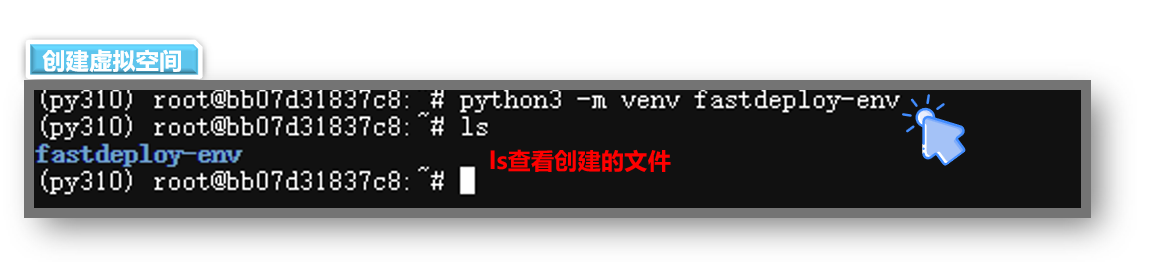
bash
python3 -m venv fastdeploy-env/- 3. 激活虚拟环境
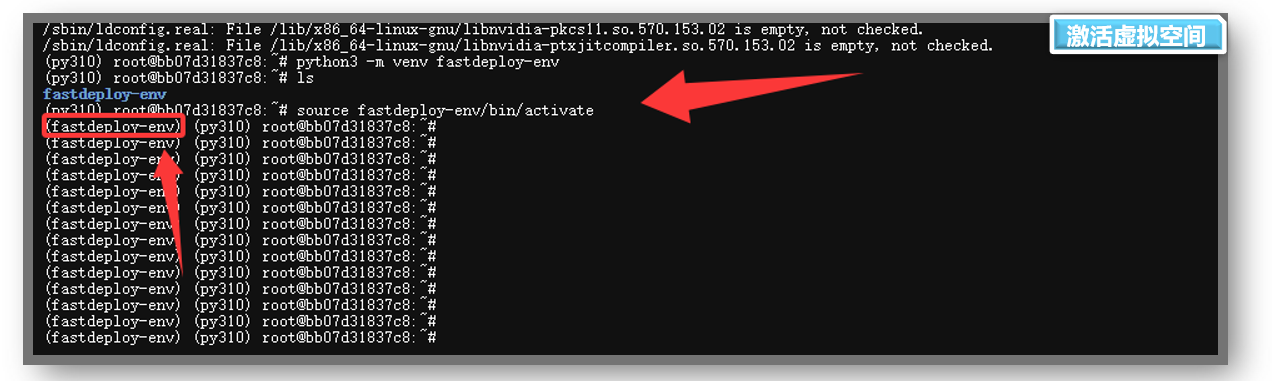
bash
source fastdeploy-env/bin/activate- 4.下载GNU依赖库
libgomp1 是 GNU OpenMP 库的一部分,用于支持程序中的 并行计算(多线程并行处理),在后面我们启动服务是需要依赖 libgomp1 来实现并行计算加速。
bash
apt update && apt install -y libgomp1 libssl-dev zlib1g-dev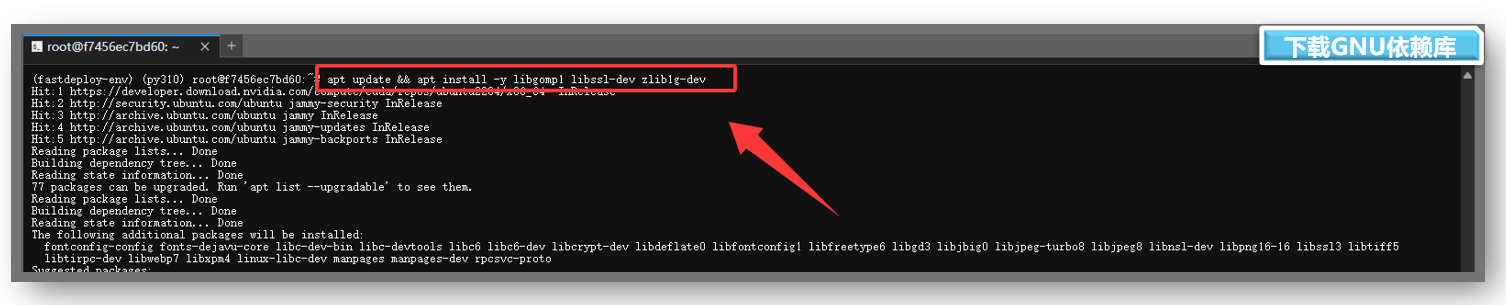
- 6.安装 paddlepaddle-gpu:3.1.0版本
因为FastDeploy 的部分核心功能(如模型解析、推理引擎适配)直接依赖 PaddlePaddle 的底层库,未安装 Paddle的话,FastDeploy 将无法正确加载和运行 Paddle 模型来以提供 CUDA/CUDNN 等 GPU 加速所需的依赖。所以我们先安装一下
paddlepaddle-gpu。
- ① 在这里我们一定要根据自己显卡厂商和CUDA的版本来选择安装命令,否则导致依赖冲突
- ②
paddlepaddle-gpu安装的详细说明:【一键直达:查看安装信息】
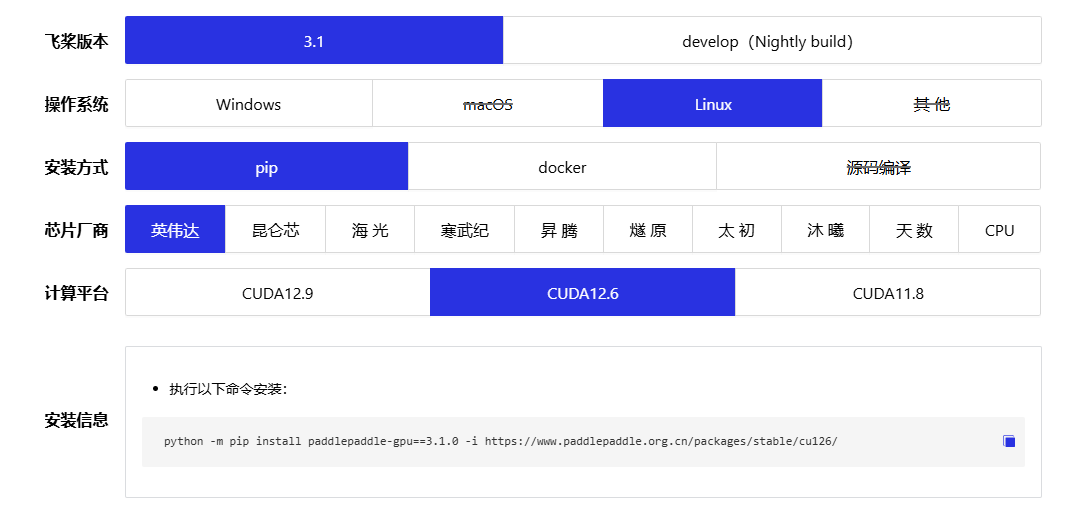
bash
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/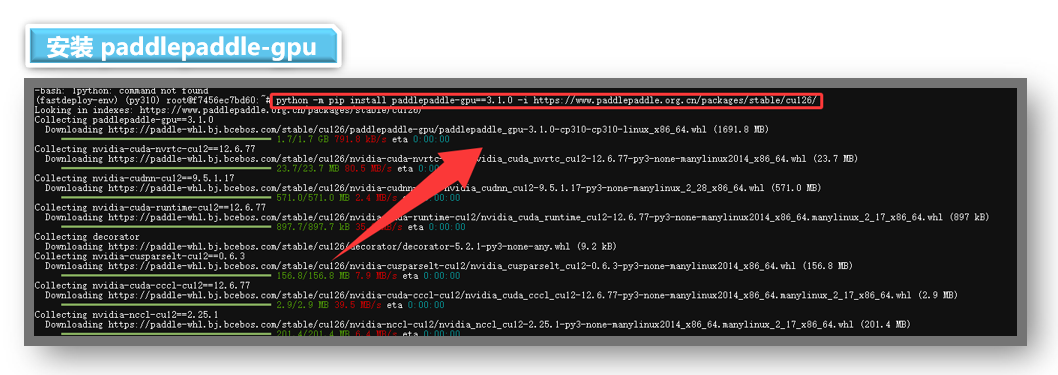
- 检测是否安装成功
paddlepaddle-gpu安装好了我们可以使用一下代码检测一下,如果没问题那么就证明可以下一步了
bash
import paddle
paddle.utils.run_check()这边可以看命令运行完之后,显示paddlepaddle-gpu 安装成功,现在就开始使用 PaddlePaddle 进行深度学习吧。

- 7.安装 fastdeploy
下载完
fastdeploy工具后面把模型拉取之后,我们就可以一键启动我们的ERNIE-4.5-0.3B-PT了。
- ① 在下载时我们要注意使用自己CPU架构对应的版本来安装下载,不然就会启动失败
- ② fastdeploy的安装手册: 【一键直达】
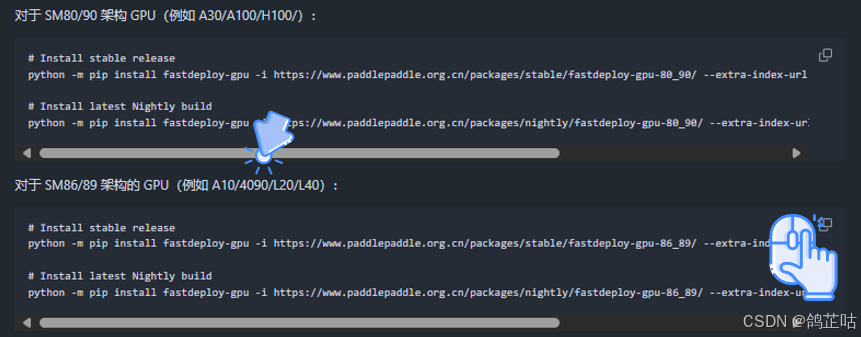
我们本次显卡是4090所以直接选择对应版本的命令下载就好了
bash
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-86_89/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
选择其中一条命令即可如果你安装的gpu是Nightlybuild那么就选择下面Nightly build 版本的fastdeloy
看到下面这种就是成功安装了 fastdeploy
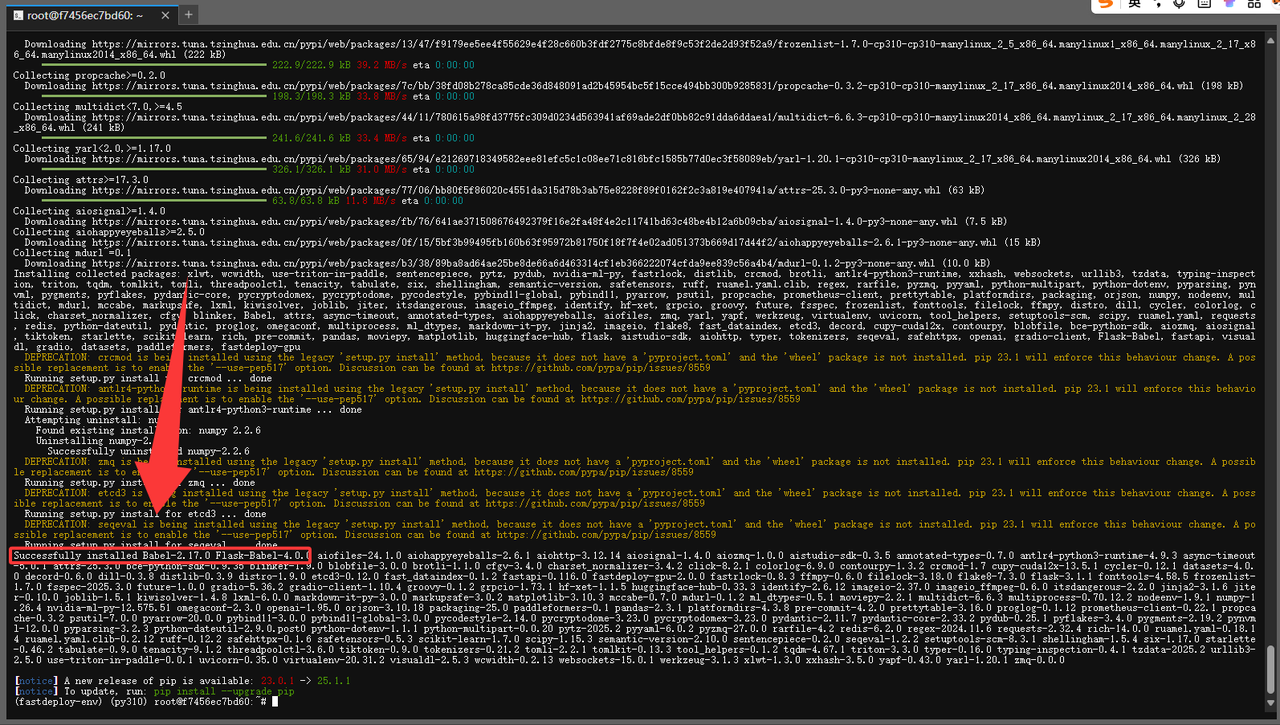
- 验证PaddlePaddle GPU 是否支持
安装完成后,再次运行以下命令,确认输出为 True 和 gpu,如果输出结果为False cpu 表示这意味着 PaddlePaddle 没有使用 CUDA 编译,只能在 CPU 上运行。
- 需要重新安装 paddlepaddle-gpu:3.1.0
bash
python -c "import paddle; print(paddle.is_compiled_with_cuda()); print(paddle.device.get_device())"
3.3 拉取 文心 ERNIE 4.5 启动大模型
以上运行模型需要的环境就全部搭建好,其实整个过程还是非常简单了只需要输入几行命令5分钟就可以快速部署起来了,下面我们去
gitcode拉取ERNIE-4.5-0.3B-PT开源项目来一键部署
- 文心大模型4.5系列开源模型: https://ai.gitcode.com/theme/1939325484087291906
- 1.下载git 工具(如果系统有就不用下载了,直接拉取就好)
bash
apt install git
- 点击进入gitcode仓库,进行拉取项目
ERNIE-4.5-0.3B-PT开源地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-0.3B-PT
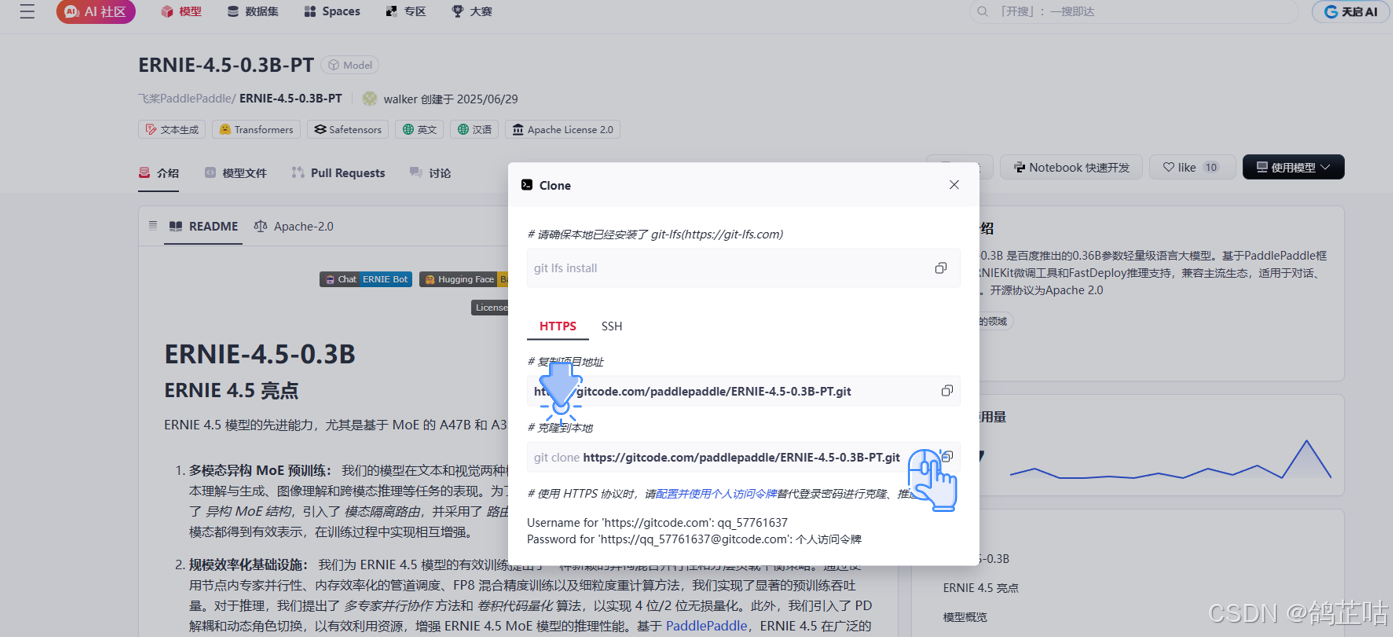
-
拉取项目源码

-
修改主机映射(避免DNS 解析失败)
为了避免大模型后续启动解析主机名(或获取本机 IP)时,DNS 解析失败。使用我们这里修改一下主机的配置来让主机名与本机 IP 的映射。
bash
#1. 查看当前主机名
hostname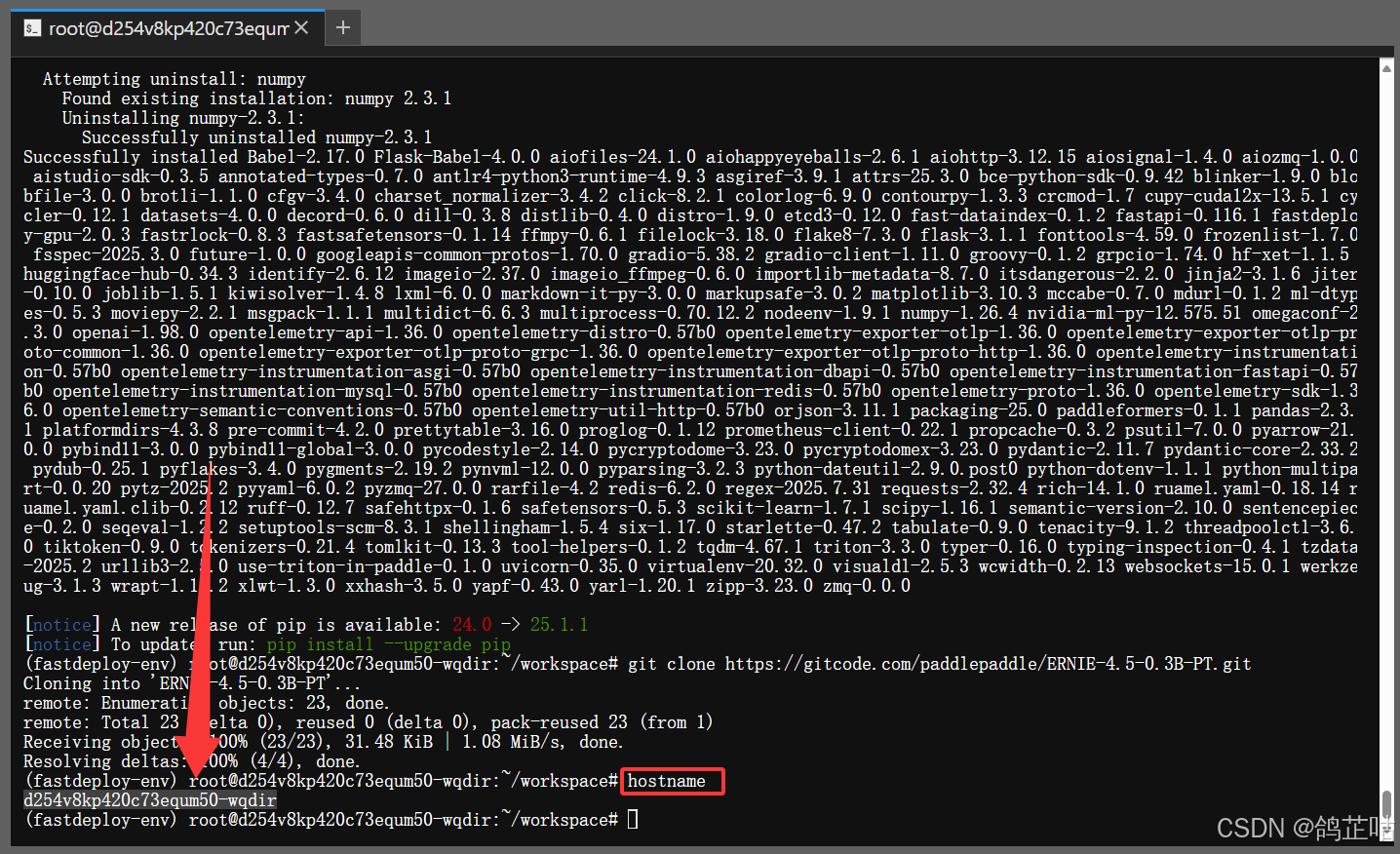
bash
#2. 编辑 hosts 文件
vim /etc/hosts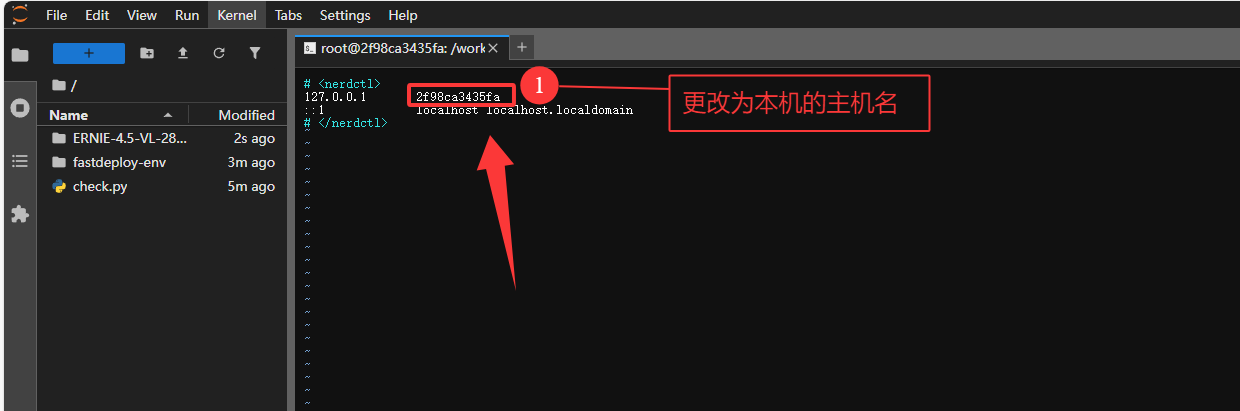
- 一键启动ERNIE-4.5-0.3B-PT
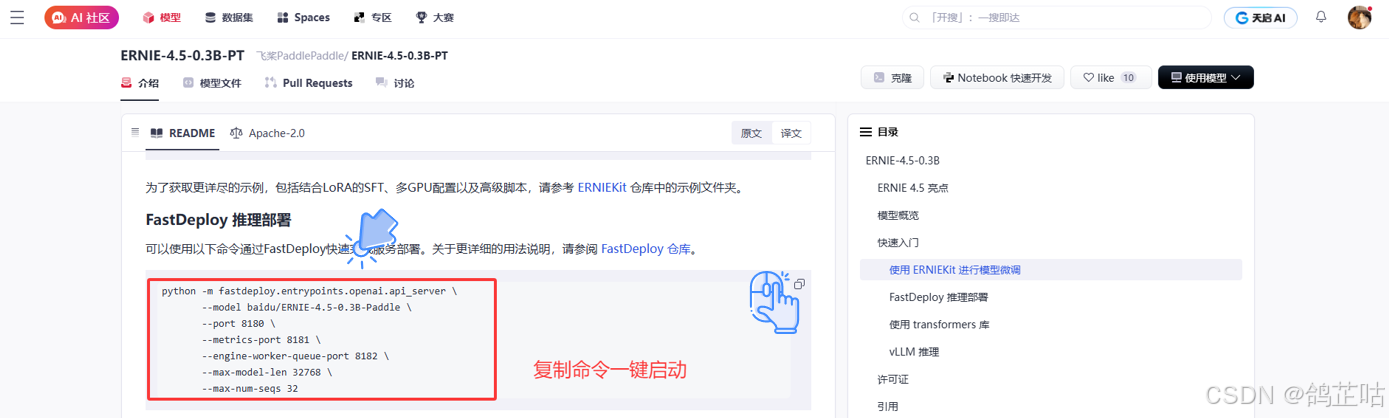
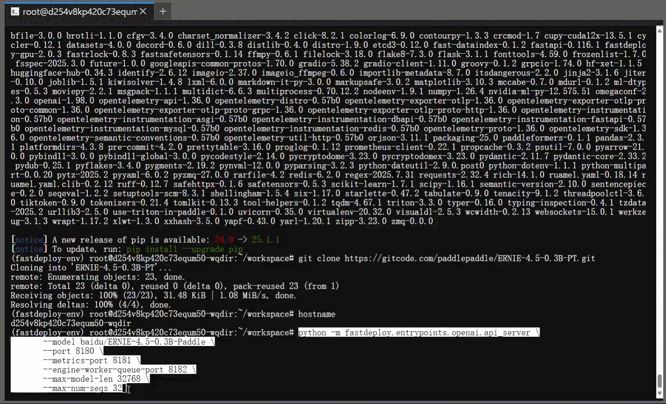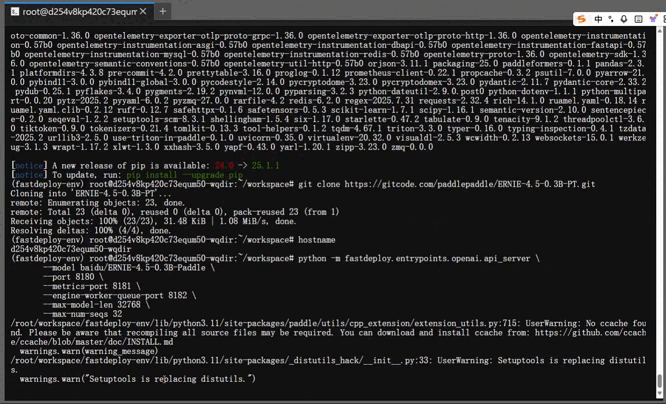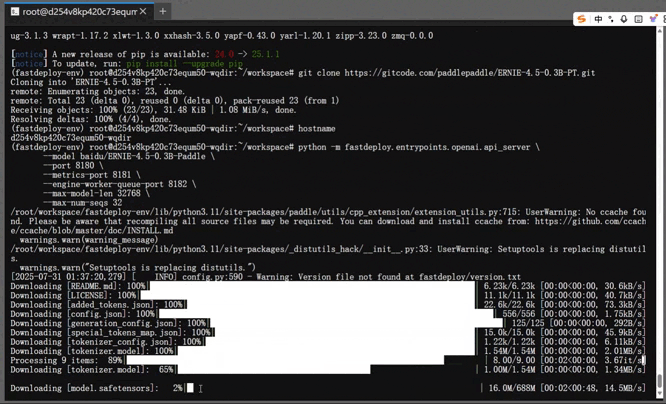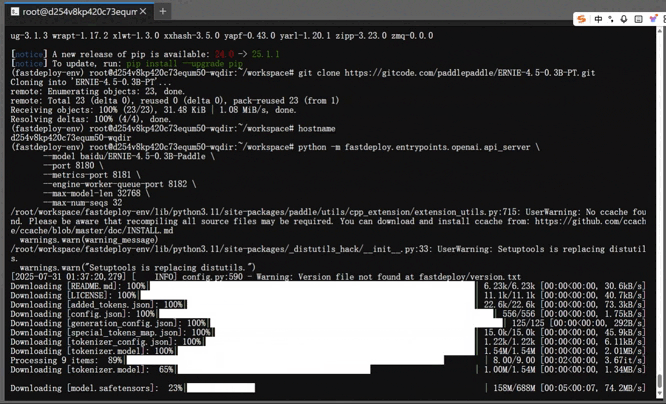
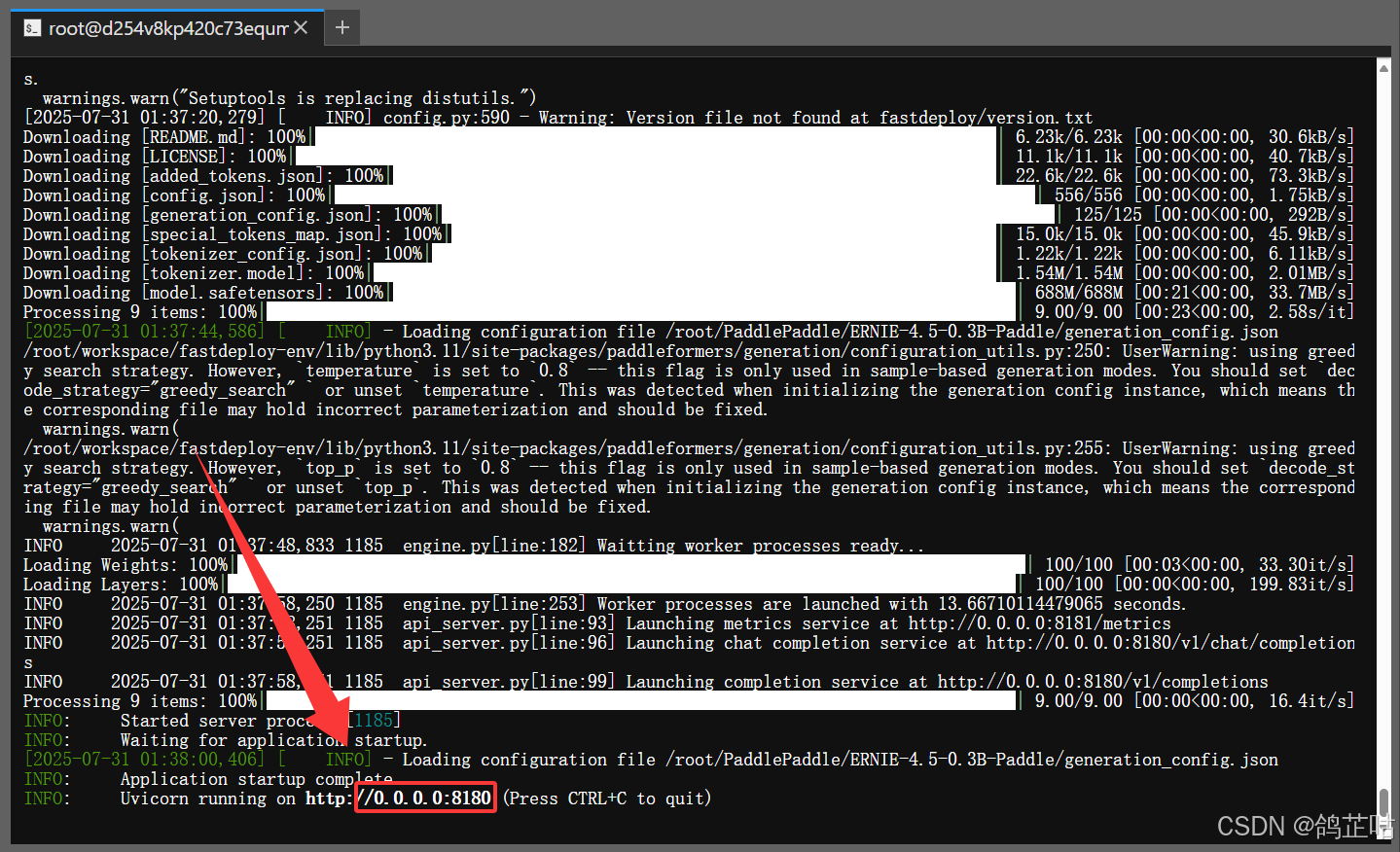
当下方显示 8180 端口启动时,咱们的大模型就部署完成了。
- 服务启动了一定要注意,不要Ctrl+C退出连接,否则服务会停止,API也无法访问了。
- 开启第二个终端开始测试
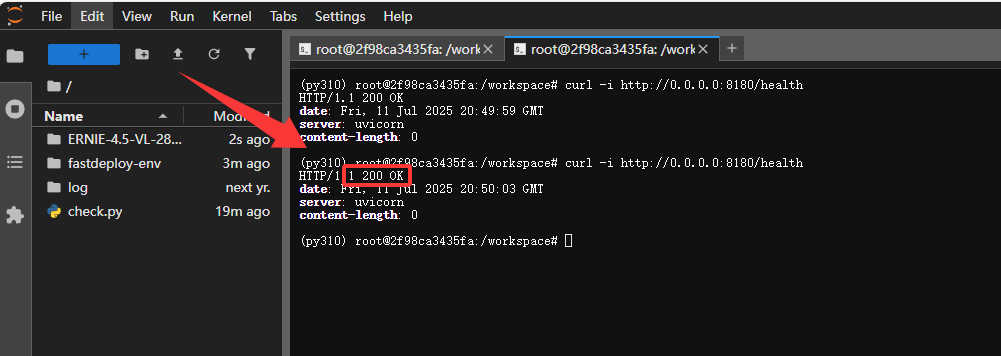
- 查看端口是否连接成功,验证服务状态(HTTP 200 表示成功)
bash
curl -i http://0.0.0.0:8180/health这里可以看到咱们端口连接没问题,服务完美启动了
- 下载requests 库发送 HTTP 请求
首先我们需要下载一个requests 库发送 HTTP 请求
bash
pip install requests 
3.4 本地化部署总结
整体来说部署文心4.5大模型过程还是非常简单的,利用官方提供的FastDeploy 部署工具就可以一键完成模型部署,整个部署流程被高度简化,开发者无需复杂配置,只需输入预设命令即可实现模型的一键启动,极大降低了操作难度。
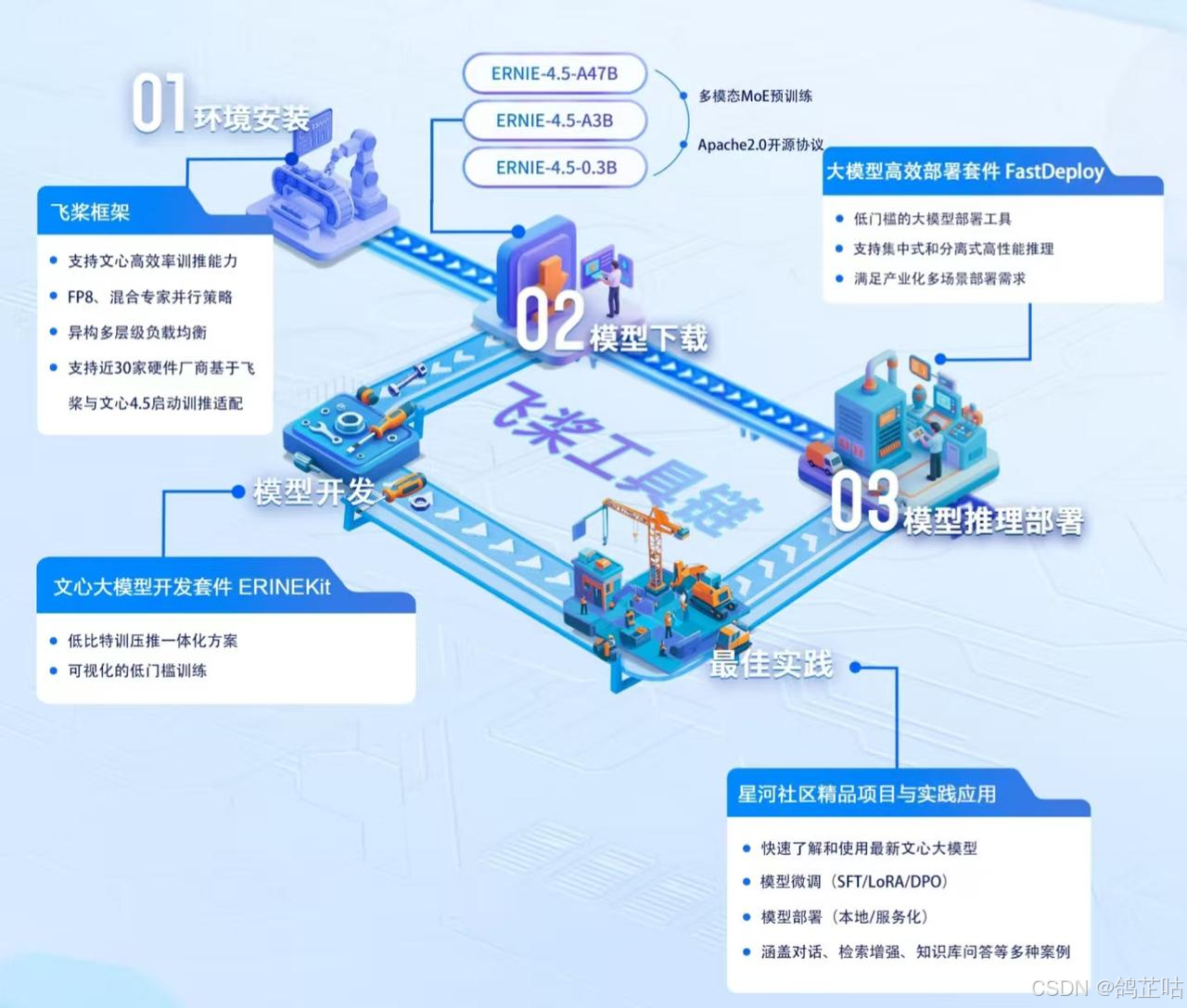
并且在在模型量化、对齐、LoRA精调等方面也无需担心。百度早已准备好了,开源了文心大模型开发套件ERNIEKit,提供预训练、全参精调(SFT)、直接偏好优化(DPO)、参数高效精调与对齐(SFT-LoRA/DPO-LoRA)、训练感知量化(QAT)和训练后量化(PTQ)等大模型全流程开发支持,帮我们轻松玩转大模型。
四 部署测试
4.1 测试环境准备
- 创建测试文件开始测试
bash
vi test.py这里我给大家准备了一个python的大模型交互程序来方便我们进行和大模型交互,把下面代码复制进test文件
bash
import requests
import json
# 模型服务的API端点,需确保模型服务已启动并可通过该地址访问
url = "http://127.0.0.1:8180/v1/chat/completions"
# 请求头,指定发送数据的格式为JSON
headers = {"Content-Type": "application/json"}
# 初始化对话上下文列表,用于保存用户输入和模型回复的历史
messages = []
# 启动对话循环,持续获取用户输入并与模型交互
while True:
# 获取用户输入,提示用户输入内容
user_input = input("你: ")
# 如果用户输入exit或quit(不区分大小写),则退出对话循环
if user_input.lower() in ['exit', 'quit']:
break
# 将用户输入以指定格式添加到对话上下文,role为user表示是用户输入
messages.append({"role": "user", "content": user_input})
# 构建请求体数据
data = {
# 指定要使用的模型,需与服务端部署的模型匹配
"model": "baidu/ERNIE-4.5-VL-28B-A3B-PT",
# 传入对话上下文,包含历史交互信息
"messages": messages,
# 温度参数,控制模型输出的随机性,值越大越随机
"temperature": 0.7
}
try:
# 发送POST请求到模型服务,将data转为JSON字符串传入
response = requests.post(url, headers=headers, data=json.dumps(data))
# 解析响应为JSON格式
response_json = response.json()
# 提取模型回复内容,从响应的特定结构中获取
result = response_json["choices"][0]["message"]["content"]
# 输出模型回复,标识为ERNIE的回复
print("ERNIE: ", result)
# 将模型回复添加到对话上下文,role为assistant表示是模型回复
messages.append({"role": "assistant", "content": result})
except requests.RequestException as e:
# 如果请求过程中发生异常(如网络问题、服务未响应等),捕获并提示
print("请求发生异常: ", e)
except KeyError as e:
# 如果响应JSON结构不符合预期,捕获并提示
print("解析响应失败,缺少必要字段: ", e)
except json.JSONDecodeError as e:
# 如果响应内容无法正确解析为JSON,捕获并提示
print("响应内容解析为JSON失败: ", e)启动python 文件

4.2 通识基础测试
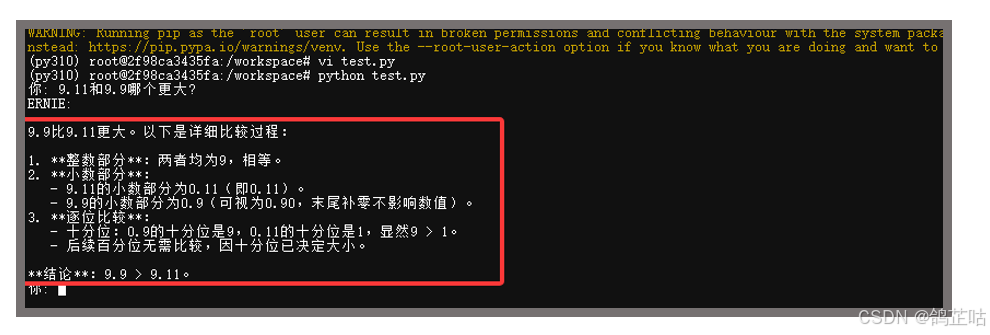
问题:9.11和9.9哪个更大?
4.3 中文复杂语境测试
问题:请解析以下古诗并仿写一句:
枯藤老树昏鸦,小桥流水人家,古道西风瘦马。夕阳西下,断肠人在天涯。
- 创建测试文件二
bash
vi test2.py
bash
import requests
import json
def test_ernie_model():
# 设置API端点
url = "http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 测试问题
test_question = """
请解析以下古诗并仿写一句:
枯藤老树昏鸦,小桥流水人家,古道西风瘦马。夕阳西下,断肠人在天涯。
"""
# 构建请求体
data = {
"model": "baidu/ERNIE-4.5-0.3B-PT",
"messages": [
{
"role": "user",
"content": test_question.strip()
}
],
"temperature": 0.7, # 控制生成文本的随机性
"max_tokens": 500 # 限制生成文本的最大长度
}
try:
# 发送请求
response = requests.post(
url,
headers=headers,
data=json.dumps(data),
timeout=30 # 设置超时时间
)
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 提取并打印模型回复
if "choices" in result and len(result["choices"]) > 0:
answer = result["choices"][0]["message"]["content"]
print("模型回复:\n")
print(answer)
else:
print("未获取到有效回复")
print("完整响应:", result)
except requests.exceptions.RequestException as e:
print(f"请求发生错误:{e}")
except json.JSONDecodeError:
print("响应解析失败,非JSON格式")
except Exception as e:
print(f"发生意外错误:{e}")
if __name__ == "__main__":
print("正在测试ERNIE-4.5-0.3B模型...")
print("测试问题:解析《天净沙·秋思》并仿写\n")
test_ernie_model()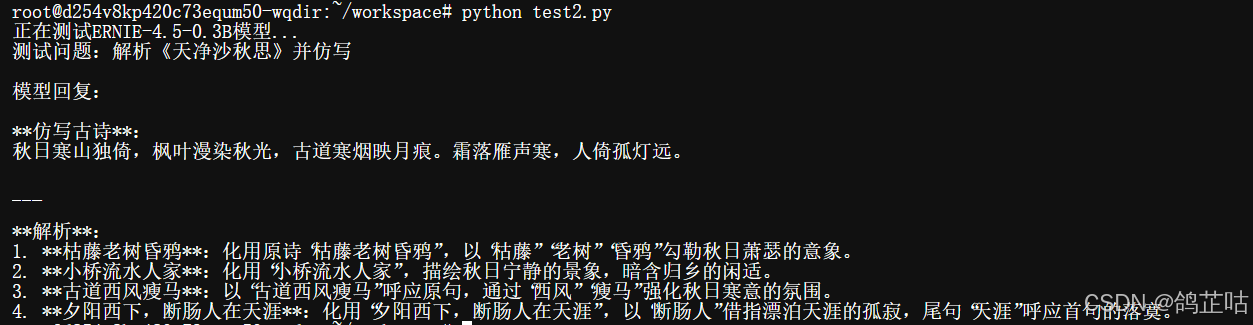
文心 4.5 这次给了我们一个惊喜。原本以为 0.3B 参数的模型在古诗仿写任务上会有些吃力,没想到它的表现远超预期 ------ 不仅完整写出了仿写句子,对原诗的解析也基本抓住了核心意思,整体表现可圈可点。
4.4 写作能力测试
问题: 请创作一个600字左右的童话故事,要求:
主人公是一个小女孩
包含"魔法森林"场景
故事要有简单的情节发展和温暖的结局
语言风格适合儿童阅读,用词生动形象
- 创建测试文件三
bash
vi test2.py
bash
import requests
import json
def generate_fairy_tale():
# API端点
url = "http://127.0.0.1:8180/v1/chat/completions"
# 请求头
headers = {
"Content-Type": "application/json"
}
# 生成童话故事的提示
prompt = """
请创作一个400字左右的童话故事,要求:
1. 主人公是一个小女孩
2. 包含"魔法森林"场景
3. 故事要有简单的情节发展和温暖的结局
4. 语言风格适合儿童阅读,用词生动形象
"""
# 构建请求数据
data = {
"model": "baidu/ERNIE-4.5-0.3B-PT",
"messages": [
{
"role": "user",
"content": prompt.strip()
}
],
"temperature": 0.8, # 适当提高随机性,增加故事创意
"max_tokens": 600, # 预留足够长度确保故事完整
"top_p": 0.9
}
try:
# 发送请求
response = requests.post(
url,
headers=headers,
data=json.dumps(data),
timeout=60
)
response.raise_for_status()
# 解析响应
result = response.json()
# 提取并返回故事内容
if "choices" in result and len(result["choices"]) > 0:
story = result["choices"][0]["message"]["content"]
print("生成的童话故事:\n")
print(story)
return story
else:
print("未能生成故事,请检查模型服务")
return None
except Exception as e:
print(f"生成过程出错:{str(e)}")
return None
if __name__ == "__main__":
print("正在生成包含小女孩和魔法森林的童话故事...\n")
generate_fairy_tale()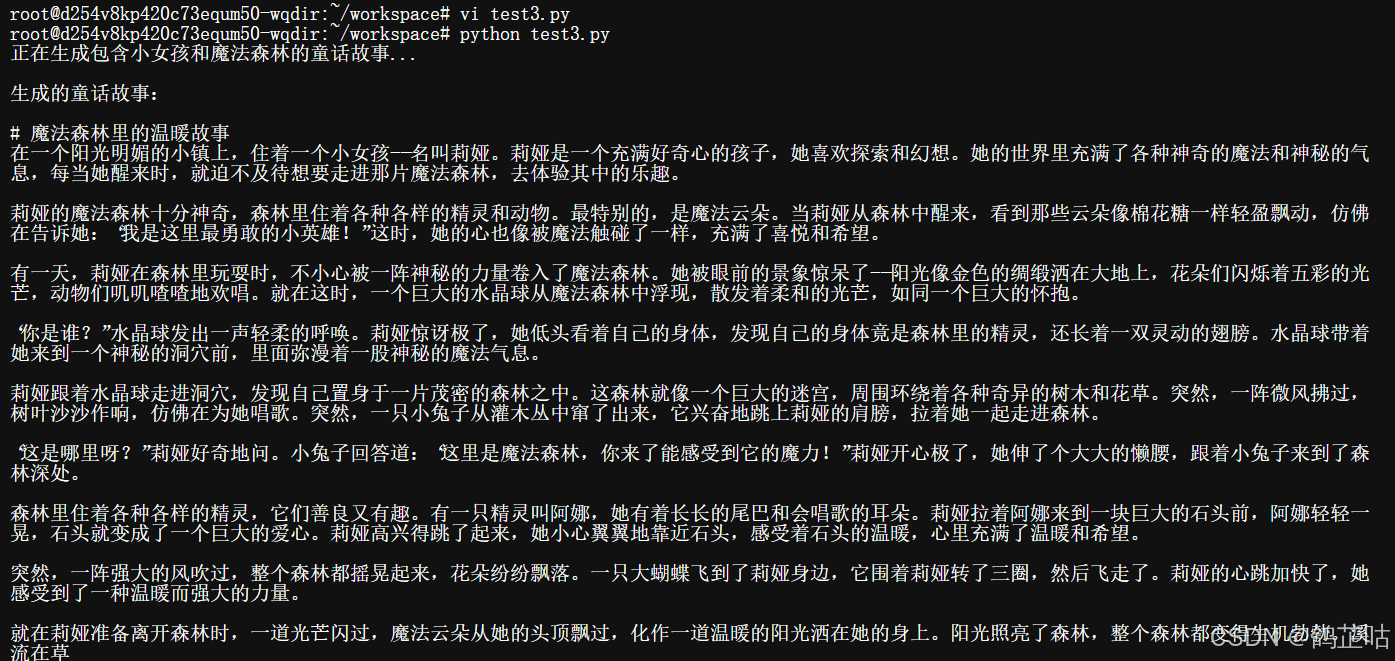
文心 4.5 0.3B 模型这次同样交出了令人满意的答卷,完美达成了我们的创作需求。从发送请求到接收完整故事,整个过程仅耗时约 3 秒,响应速度远超预期。生成的童话故事不仅紧扣 "小女孩" 与 "魔法森林" 的核心要素,篇幅控制在 400 字左右,语言风格也贴合儿童阅读习惯。
五、总结
文心 ERNIE 4.5 开源版本通过架构创新、高效部署工具与轻量化模型设计,降低了大模型应用门槛,在保证性能的同时,具备快速响应、低资源占用等优势。即便是0.3B的参数模型在我们的实际测试中也展现了不错的表现,极具竞争力。
我相信,未来文心 4.5 凭借其在中文领域的深厚根基和百度生态的强大支持,会在国内市场占据重要地位,并进一步推动全球人工智能产业的发展。
- 😀一起来轻松玩转文心大模型吧!🎉🎉🎉
- 📌文心大模型免费下载地址: https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle