在大量分散的文档中提取有用内容并非易事,特别是当目录层级复杂、文件数量庞大时,人工处理几乎不可能完成。通过脚本自动化的方式,可以将冗杂的文档内容快速清洗并统一存储,为后续统计和分析奠定高效基础。
本文介绍如何利用Python脚本对目录下的多个Word文档进行批量遍历,解析其中符合特定格式的语句,并将结果整理输出到Excel表格。整个实现过程涵盖目录扫描、文档解析、正则匹配和结果汇总,适合应用在语录收集、资料整理或文本数据清洗等场景。
文章目录
应用场景
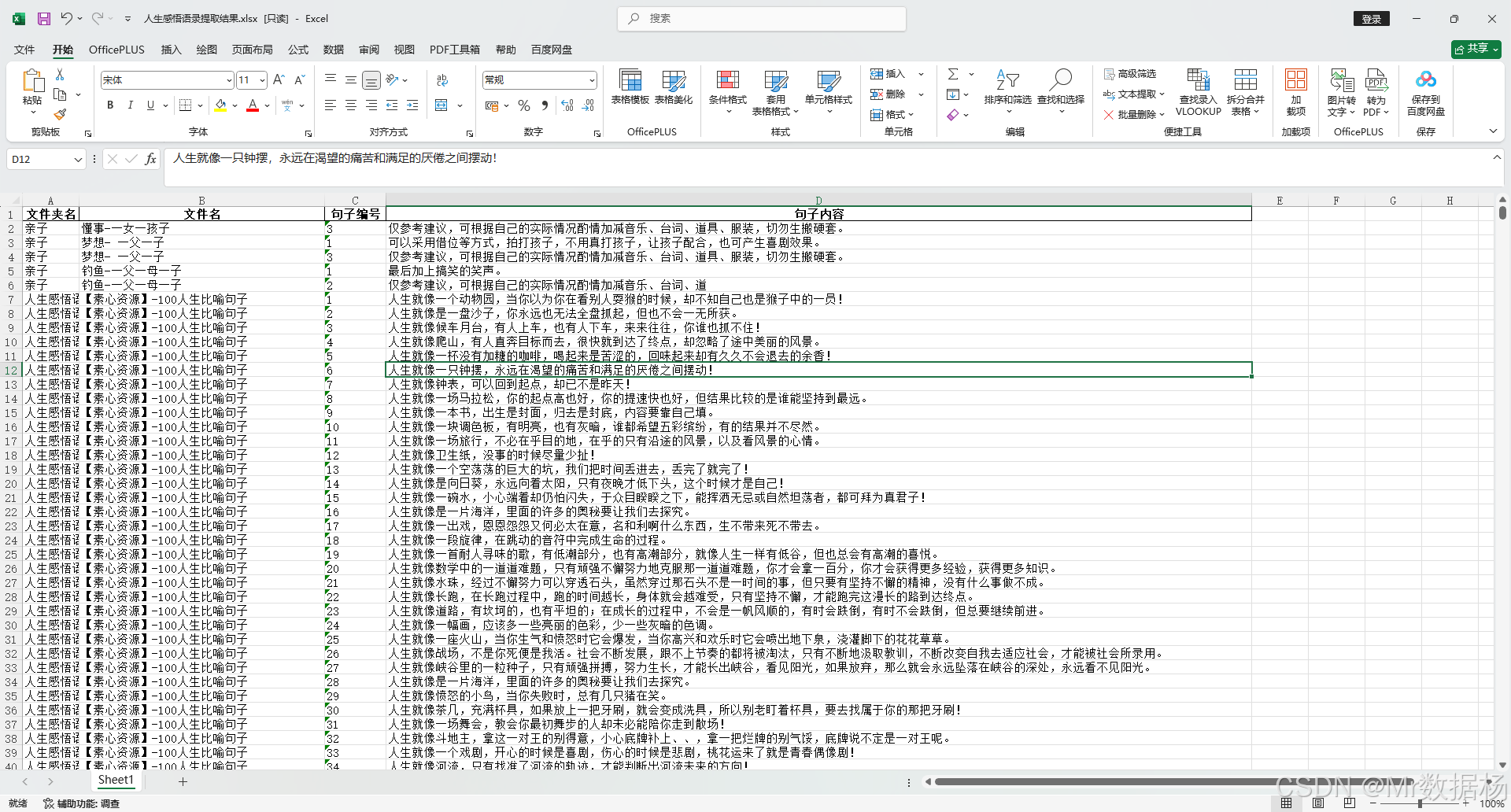
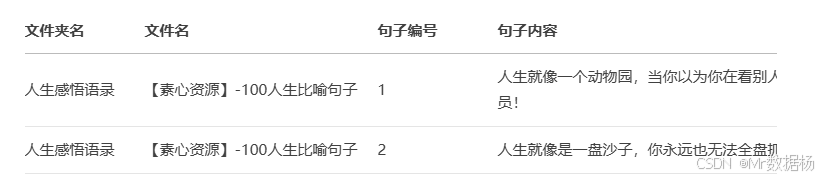
比如获取到的文件样子是这样的,在目录下又若干个文件夹,每个文件夹对应的若干个.docx 文件,其中每个文件这样的

现在需要将每个 docx 的文件按照要求整理到 `excel 表格中。
格式要求
实现代码
核心任务是从目录树中的多个 .docx 文档中批量提取符合规则的句子内容,并将整理后的结果统一存储到 Excel 表格中,便于后续统计和分析。整个过程围绕"目录结构遍历、文档内容解析、正则匹配提取、结果汇总存储"几个环节展开,构成了一个较为完整的数据清洗与整理流程。
在业务场景中,目录下包含多个子文件夹,每个子文件夹内部有若干个 Word 文件。代码通过 os.walk 的方式递归扫描指定根目录,搜集所有符合 .docx 扩展名的文件路径,并以此建立一个全量的文件清单。为了便于观察进度,引入了 tqdm 库构建进度条,让处理的过程可视化。每个文件在处理时都会提取所在的文件夹名和文件名,作为后续结果的索引信息。
文档的解析依赖 python-docx 库,通过 Document 对象获取段落列表,逐段读取文本内容。由于文件中每条有效语录的格式通常表现为"数字. 句子内容",代码利用正则表达式 ^(\d+)\.\s*(.+)$ 精确匹配这一结构,既保证了句子编号的提取,又能获得对应的句子文本。匹配成功后,数据被组织为字典并不断追加到 DataFrame 中,字段包括文件夹名、文件名、句子编号和句子内容。这样处理过的结果既能保留原始文件的层级信息,也能保证每条语录的独立性。
当所有文件遍历结束,数据会统一导出为 Excel 文件,文件名为《人生感悟语录提取结果.xlsx》。除了完整的数据表,脚本还输出了汇总信息,例如涉及的文件夹数量、文件数量以及句子编号的范围,从而能够快速把握数据的整体规模与分布。整个实现具备容错机制,在遇到个别损坏或不符合规范的文件时,不会影响整体流程,而是记录错误提示继续执行。
python
import os
from docx import Document
import pandas as pd
import re
from tqdm import tqdm
# 初始化DataFrame
df = pd.DataFrame(columns=['文件夹名', '文件名', '句子编号', '句子内容'])
# 设置根目录路径(请修改为您的实际路径)
base_dir = 'txt'
# 先统计总文件数用于进度条
print("正在扫描文件...")
all_files = []
for root, dirs, files in os.walk(base_dir):
for file in files:
if file.endswith('.docx'):
all_files.append((root, file))
total_files = len(all_files)
print(f"共发现 {total_files} 个.docx文件,开始处理...")
# 使用tqdm创建进度条
progress_bar = tqdm(all_files, desc="处理进度", unit="文件")
# 遍历所有文件
for root, file in progress_bar:
folder_name = os.path.basename(root)
file_name = os.path.splitext(file)[0]
file_path = os.path.join(root, file)
try:
doc = Document(file_path)
# 更新进度条描述
progress_bar.set_postfix(当前文件=f"{folder_name}/{file_name}")
# 提取所有段落文本
for para in doc.paragraphs:
text = para.text.strip()
# 使用正则表达式匹配"数字. 句子内容"的格式
match = re.match(r'^(\d+)\.\s*(.+)$', text)
if match:
sentence_num = match.group(1)
sentence_content = match.group(2)
# 添加到DataFrame
df = pd.concat([df, pd.DataFrame([{
'文件夹名': folder_name,
'文件名': file_name,
'句子编号': sentence_num,
'句子内容': sentence_content
}])], ignore_index=True)
except Exception as e:
print(f"\n处理文件 {file_path} 时出错: {e}")
# 保存到Excel文件
output_file = '人生感悟语录提取结果.xlsx'
df.to_excel(output_file, index=False)
print(f"\n提取完成!结果已保存到 {output_file}")
print(f"共提取 {len(df)} 条记录")
# 显示汇总信息
if not df.empty:
print("\n提取结果摘要:")
print(f"- 涉及文件夹数量: {df['文件夹名'].nunique()}")
print(f"- 涉及文件数量: {df['文件名'].nunique()}")
print(f"- 句子编号范围: {df['句子编号'].min()} - {df['句子编号'].max()}")
else:
print("\n警告: 未提取到任何符合条件的内容!")
总结
基于目录遍历与正则匹配的方法,能够高效实现批量语录的提取和清洗,避免了手工操作带来的低效与错误。结果不仅保存了原始的层级信息,还保证了语句内容的独立性,便于后续处理。通过Excel文件输出,数据的可视化与进一步分析得到了便利支持。
这一思路可以扩展到更广泛的文档处理场景,例如自动生成知识库、整理调研资料或批量清洗日志文本。随着更多库和工具的结合,数据处理流程将更加智能与稳健,为大规模文本管理提供有力支持。