目录
[system V共享内存](#system V共享内存)
一.进程间通信的介绍
1.进程间通信的目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另 一个进程的所有陷入和异常,并及时知道状态改变
2.进程间通信的本质
**让不同的进程看到同一份资源。**那这份"资源"指的是什么呢。其实就是一段可以存放数据的空间。同时,这段空间不能由进行通信的进程提供,必须由操作系统提供。因为进程是具有独立性的,一个进程提供一段空间,另一个进程是看不到的。同时,根据操作系统怎么提供空间,分为了不同的通信的方案。
3.进程间通信的分类
1.管道
- 匿名管道pipe
- 命名管道
2.System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
3.POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
二.管道
1.匿名管道
1.什么是管道
- 管道是Unix中最古老的进程间通信的形式。
- 我们把从一个进程连接到另一个进程的一个数据流称为一个"管道"
2.匿名管道的原理
当父进程创建子进程的时候,子进程会拷贝父进程的task_struct和files_struct和其上的fd_array,即文件描述符表,子进程的文件描述符表指向的是和父进程一样的file struct,而file struct 会有一个指针指向一段文件的缓冲区。
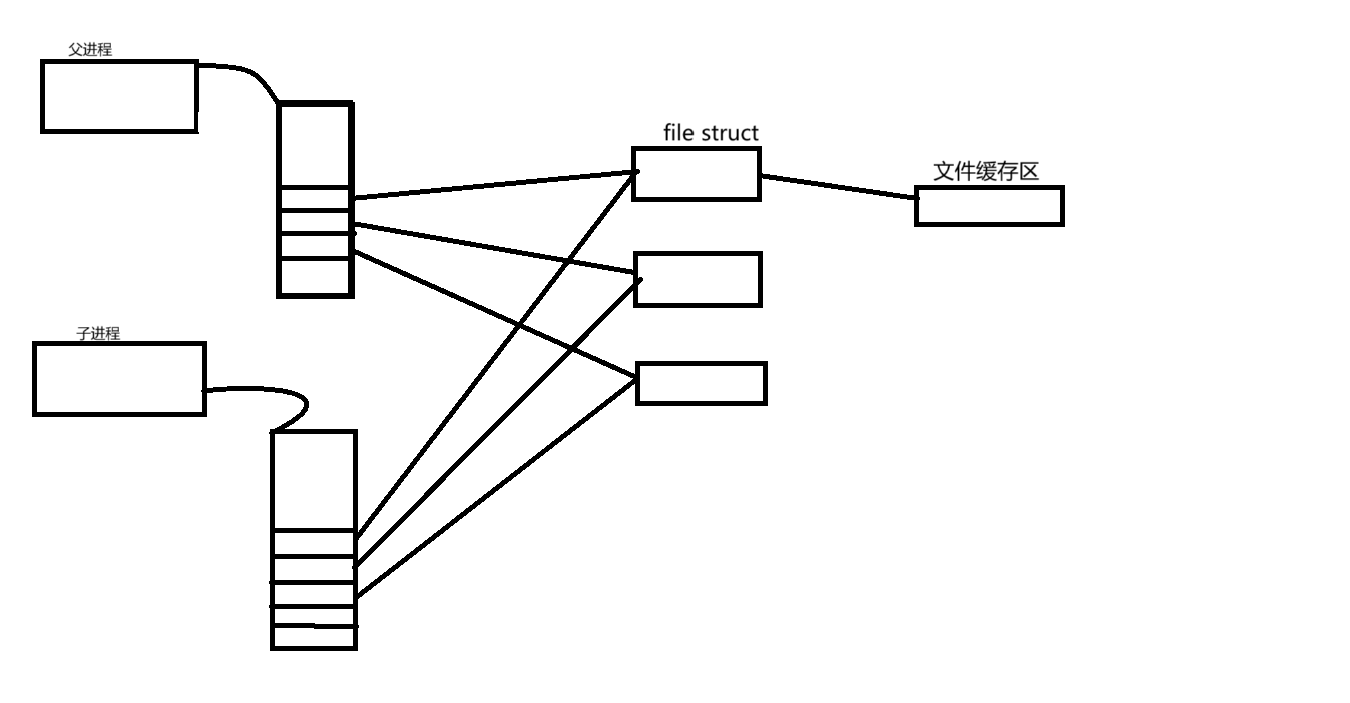
进程间通信的本质是让不同的进程看到同一块资源。而这样,父子进程就能看到同一块文件缓冲区的资源。只要父子之间进行文件的读写,就能实现父子进程之间的通信。
注意:
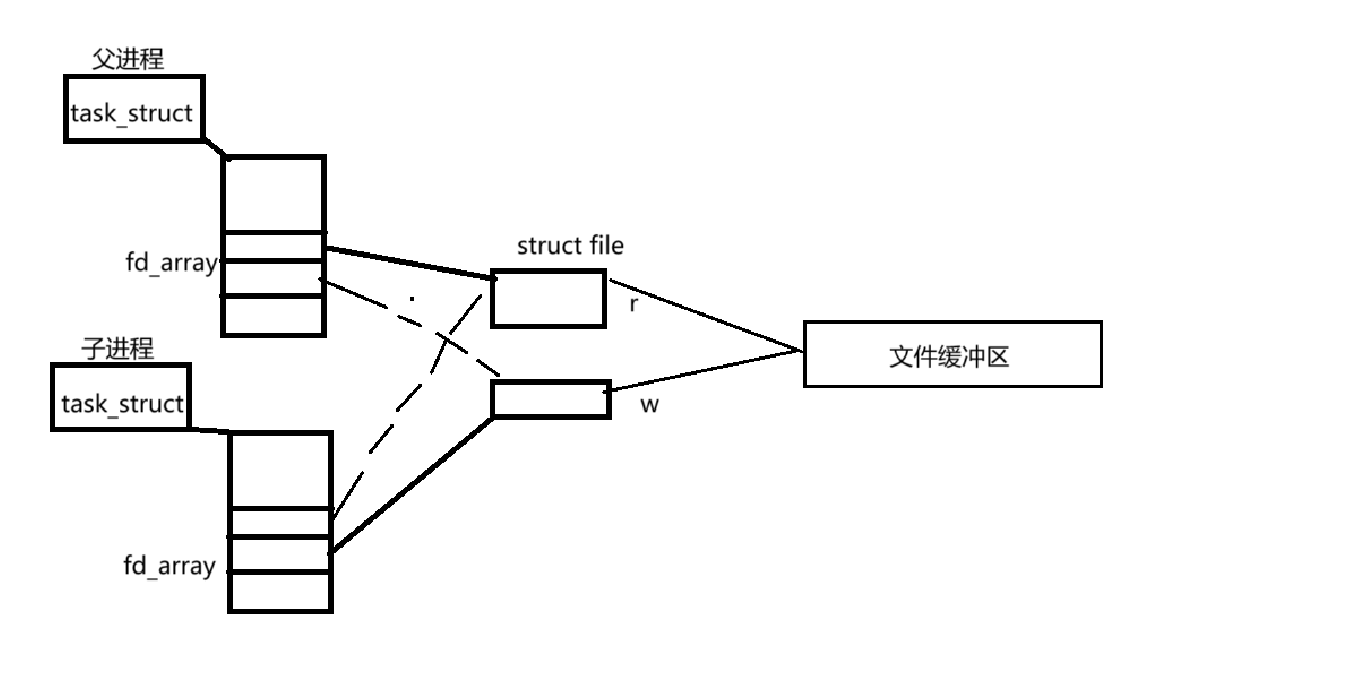
1.如果父进程的文件是通过读的方式打开的,那么子进程拷贝父进程文件描述符表,看到的文件也是以读的方式打开的。那么父子进程是怎么通信的呢。事实上父进程会分别用读写的方式打开文件两次,这样就会产生两个struct file 的结构体,也会有两个文件描述符。然后创建子进程,让子进程拷贝父进程的文件描述符,这时候,子进程也能看到分别以读写方式打开的文件,然后让父子进程分别关闭读写的一段,就能够实现通信。
2.虽然匿名管道是借助文件实现的,但是匿名管道不会创建正真的文件,只会维护文件缓冲区,不会把缓冲区的内容刷新到磁盘上。
3.接口
int pipe(int pipefd2)
其中,pipefd是一个输出型参数,内部存放的是读写段的文件描述符
|-------------|----|
| 文件描述符 | 说明 |
| pipefd0 | 读端 |
| pipefd1 | 写端 |
返回值 成功返回0,失败返回-1
4.管道的特点
1.具有血缘关系的管道才能进行通信,一般用于父子进程通信。
2.管道只能进行单向通信
3.管道是面向字节流的
4.管道内部自带同步互斥机制
5.管道是基于文件的,而文件是基于进程的。
5.管道的4种特殊情况
1.读写端正常,管道如果为空,读端会被阻塞
这很容易理解,当读端太快,管道里面没有数据的时候,确实不能读到数据
2.读写端正常,管道如果为满,写段会被阻塞
这也很容易理解,当写端太快,管道里面数据已经满了的时候,确实不能在继续写数据
3.读端正常,写端退出,读端read会返回0,表示读到文件(管道)末尾,不会被阻塞
4.写端正常,读端退出,操作系统会杀掉写端进程
注意:操作系统是通过发送13号信号SIGPIPE把进程杀死的。可以通过以下代码验证:
cpp
#include<unistd.h>
#include<iostream>
#include<cstring>
#include<sys/wait.h>
#include<sys/types.h>
using namespace std;
int main()
{
int pipefd[2];
int n=pipe(pipefd);
if(n<0)return 1;
pid_t id=fork();
if(id==0)
{
close(pipefd[0]);
while(true)
{
const char* str="hello,world";
write(pipefd[1],str,strlen(str));
sleep(1);
}
exit(0);
}
close(pipefd[1]);
char buffer[1024];
int cnt=0;
while(true)
{
int n=read(pipefd[0],buffer,sizeof(buffer)-1);
if(n>0)
{
buffer[n]=0;
cout<<buffer<<endl;
}
else if(n==0)
{
break;
}
cnt++;
if(cnt==5)
{
break;
}
}
close(pipefd[0]);
int status=0;
n=waitpid(-1,&status,0);
if(n>0)
{
if(WIFEXITED(status))
{
cout<<"exit code: "<<WEXITSTATUS(status)<<endl;
}
else
{
cout<<"killed by signal "<<(status&0x7f)<<endl;
}
}
else
{
cerr<<"wait error"<<endl;
}
return 0;
}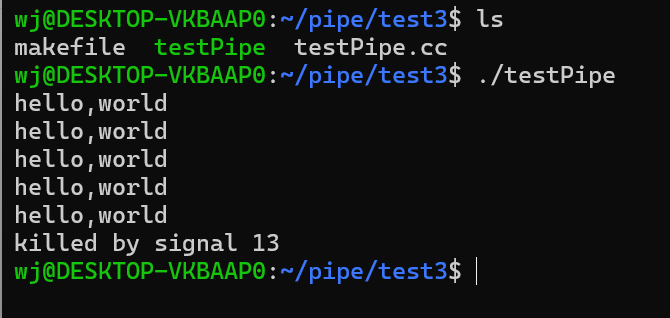
由上图可知,写端正常,读端关闭,写端进程确实是由操作系统发出13号信号终止的。
6.管道的大小
ulimit -a
这个指令可以查看系统的资源限制
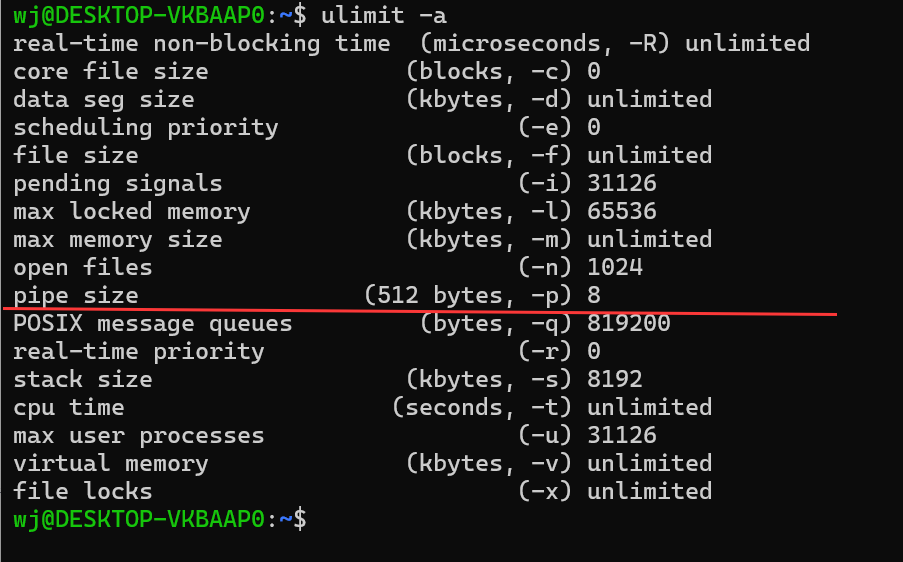
如图,划红线的那一行就是管道的大小,根据显示,管道大小等于512*8=4096字节。即4KB
我们可以自行验证一下
cpp
#include<unistd.h>
#include<iostream>
using namespace std;
int main()
{
int pipefd[2];
int n=pipe(pipefd);
if(n<0)return 1;
pid_t id=fork();
if(id==0)
{
close(pipefd[0]);
int cnt=0;
while(true)
{
int c='c';
write(pipefd[1],&c,1);
cnt++;
cout<<cnt<<endl;
}
exit(0);
}
close(pipefd[1]);
sleep(1000);
return 0;
}上面的代码是利用管道写满之后会阻塞的特点,写端一个个将子符写进管道,而读端不读,再利用计数器计数的方法,将系统管道实际的最大容量测出来。
运行结果
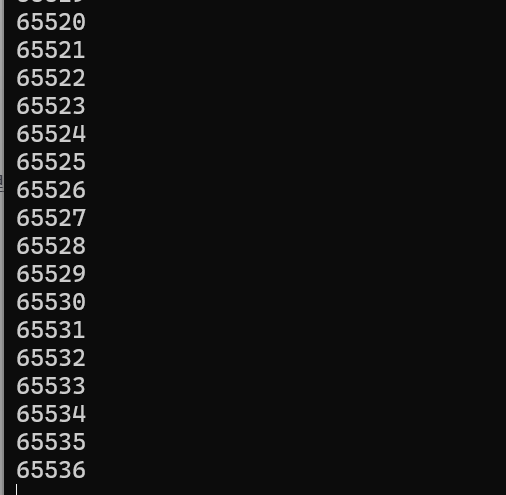
可以看出,管道的最大容量为65536个字节,即64KB。
2.命名管道
原理
命名管道和匿名管道的底层都是相同的原理,区别是匿名管道是通过子进程继承父进程的文件描述符来找到相同的内存文件,从而让不同的进程看到相同的资源,而命名管道是通过直接创建管道文件,然后让不同的进程通过路径+文件名来找到相同的管道文件。让不同的进程看到同一份资源,进而实现进程间通信。也因此,匿名管道只能用于具有血缘关系的进程通信,而命名管道能够让任意进程通信。
创建管道文件
mkfifo filename
通过上面的指令可以创建管道文件。
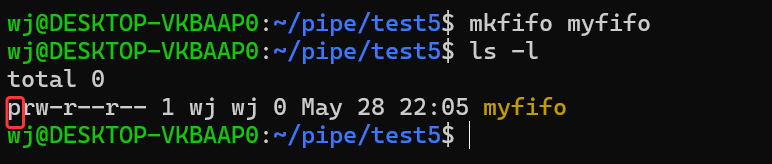
如上图,p代表管道文件
我们通过下面的指令来测试一下这个管道文件

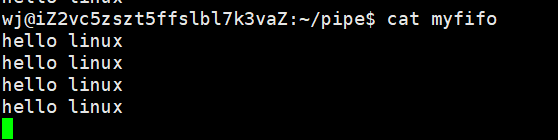
可以看到,一方不断向文件打印,一方不断读文件。如果这个时候关闭读端,写端也会被关闭。而写端是bash,所以bash也会被终止。
注意
while :;do echo "hello linux";sleep 1;done>>myfifo
while :;do echo "hello linux">>myfifo;sleep 1;done;
上述两个脚本有着本质不同,前者是bash打开文件,然后echo不断向管道打印,后者是echo 打开文件,然后打印,打印完后关闭文件,然后继续执行下一个echo指令。

int mkfifo(const char* pathname,mode_t mode)
- pathname 表示创建的管道的路径和文件名
- mode 表示管道的权限。注意:虽然创建管道的时候指定了管道的权限,但是管道的权限还要受权限掩码的影响。如果不想受它的影响,可以设置umask(0)
- 返回值 0表示成功,-1表示失败
命名管道的使用和匿名管道相同,都是对文件进行读取,写入。也就是说,管道的操作和文件的操作是一样的。唯一不同的是匿名管道是通过子进程继承父进程的方式获得的文件描述符,而命名管道是通过文件名和路径的方式获得文件描述符。
三.system V共享内存
1.原理
共享内存的原理其实很简单,他是通过操作系统在内存当中申请一块空间,然后把这块空间通过页表映射到通信进程的进程地址空间的共享区当中实现的。
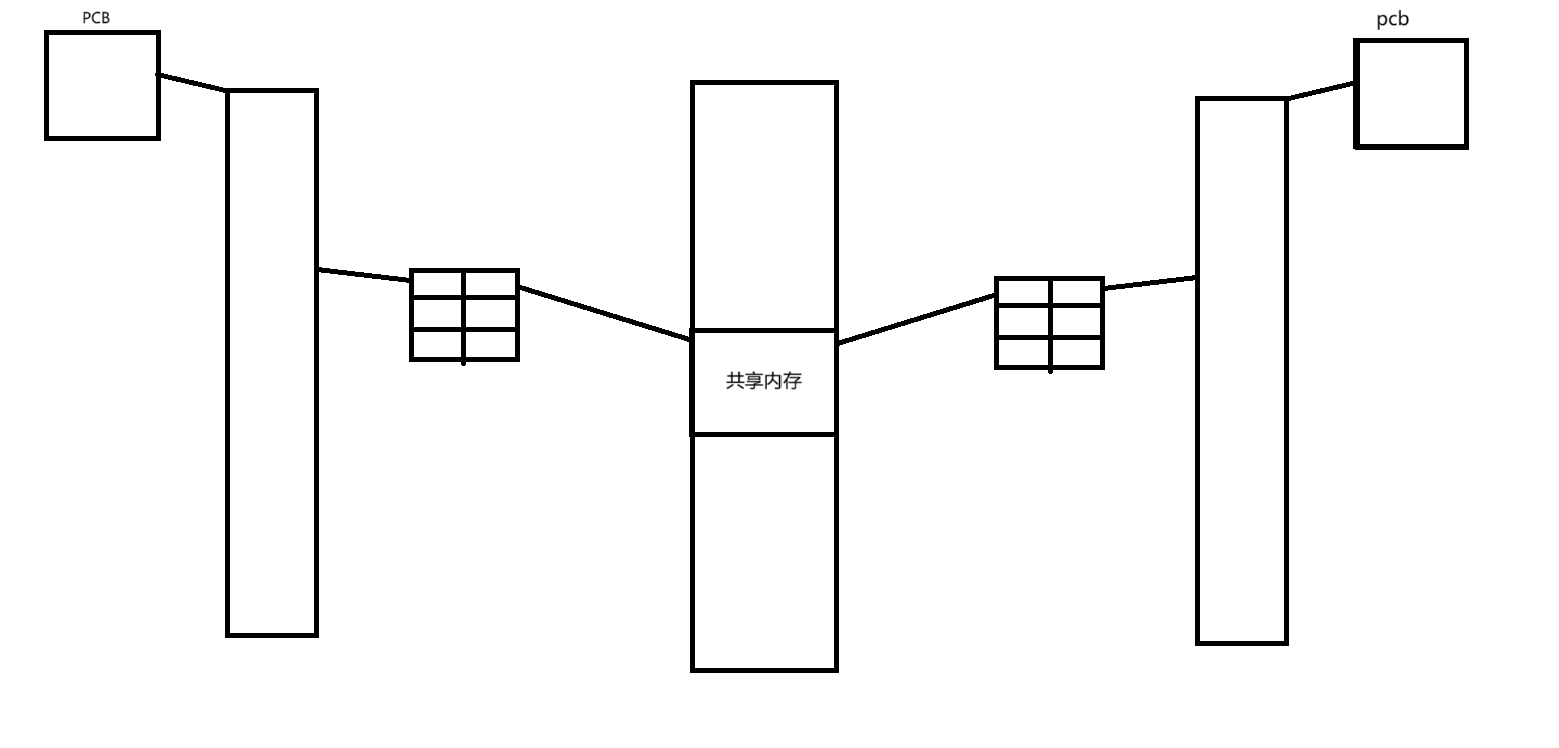
通过这种办法,就可以让不同的进程看到同一块资源,实现进程间通信。
2.查看共享内存
ipcs
作用 这个指令可以查看系统上所有的共享内存,消息队列,信号量的信息。
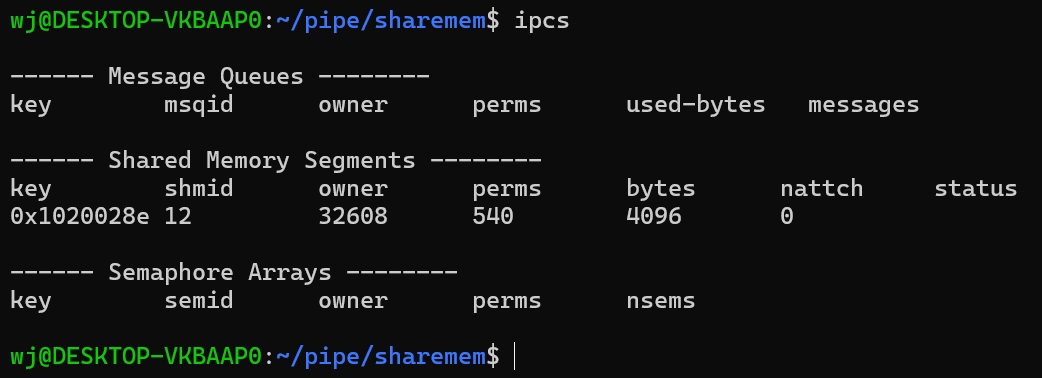
如果想单独查看共享内存的信息,只需要带上-m选项,m就表示共享内存
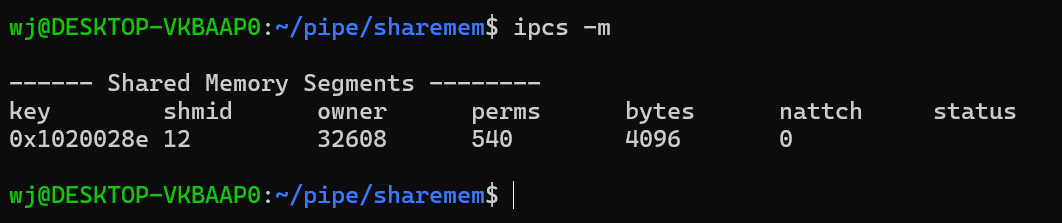
如图所示,从左到右依次是
|--------|-------------|
| 标题 | 内容 |
| key | 系统区别共享内存的标识 |
| shmid | 共享内存的用户级id |
| owner | 共享内存的拥有者 |
| perms | 共享内存的权限 |
| bytes | 共享内存的大小 |
| nattch | 关联共享内存的进程数 |
| status | 共享内存的状态 |
ipcrm -m shmid
作用:这个指令可以删除指定的共享内存段。需要有足够的权限(root或者段所有者)
使用场景
-
手动清理残留内存段
当程序异常退出未正确释放共享内存时,需手动删除残留段。
-
调试或测试环境重置
在开发过程中强制释放被占用的共享内存。
3.接口
int ftok(const char* pathname,int proj_id)
- pathname 文件路径
- proj_id 用户自己提供的任意一个id
该函数会通过算法把字符串和id转化为冲突率很低的整数。那这个函数和创建共享内存有关系吗?事实上,在操作系统当中,可能存在很多共享内存,这些共享内存被不同的进程使用,因此,需要将所有的共享内存管理起来。那么管理就会先描述,再组织。共享内存肯定有其对应的数据结构,为了区分不同的共享内存,在这个数据结构上面,肯定有需要唯一标识他的id,而ftok就是的返回值就是这个id
int shmget(key_t key,size_t size,int shmflg)
- key 用来唯一标识共享内存的key,由ftok生成
- size 共享内存的大小。一般为4096的整数倍。
- shmflg 有两种选项 IPC_CREAT和IPC_CREATE|IPC_EXCL,前者是根据key创建新的共享内存,如果key存在,就会返回key对应的共享内存。后者根据key创建新的共享内存,如果key存在,就会报错。
void* shmat(int shmid,const void* shmaddr,int shmflg)
把共享内存挂接到调用的进程。
- shmid shmget的返回值,是共享内存的id
- shmaddr 共享内存要挂接到的内存位置,一般填NULL,表示让操作系统自己决定
- shmflg 一般填0
- 返回值 共享内存挂接到的内存位置
int shmdt(void* shmaddr)
把共享内存在进程中取下来
- shmaddr shmat的返回值
int shmctl(int shmId ,int cmd,struct shmid_ds*buf)
- shmid 共享内存的用户级标识符
- cmd 表示具体的控制动作
- buf 一种用户层面的管理共享内存的数据结构的指针
其中,cmd的选项最常用的是以下几个
|----------|-----------------------------|
| 选项 | 作用 |
| IPC_RMID | 删除共享内存段 |
| IPC_STAT | 获取共享内存的当前关联值,此时参数buf作为输出型参数 |
struct shmid_ds
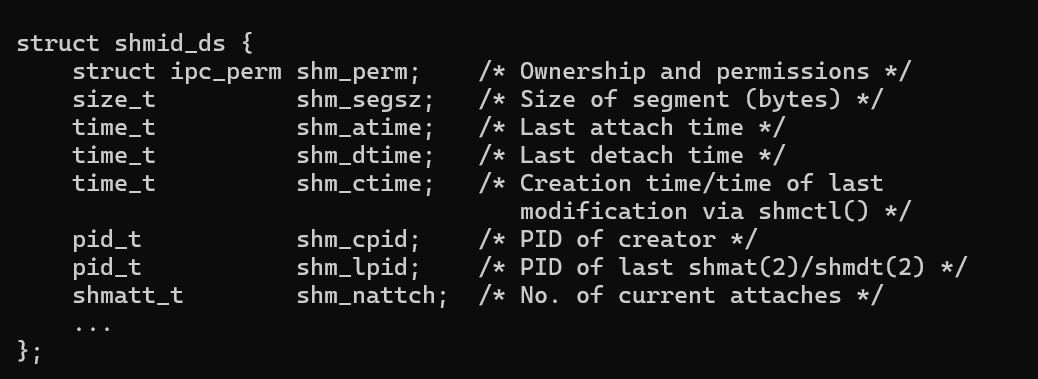
其中,ipc_perm也是结构体,他的声明如下
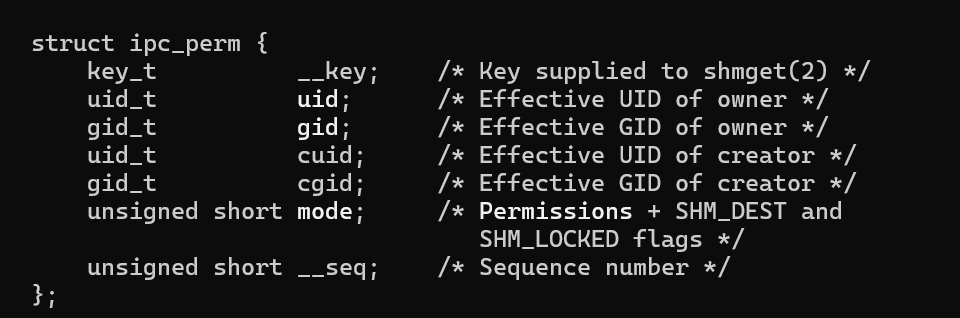
我们可以通过这些数据结构来获取共享内存的各种属性
4.共享内存的特点
- 没有同步互斥这样的保护机制
- 是最高效的进程间通信方式
- 共享内存内部的数据,由用户自己维护
为什么共享内存是最高效的通信方式?
因为共享内存的拷贝次数最少。从用户的角度上来说,他的拷贝次数是2次,而管道是4次
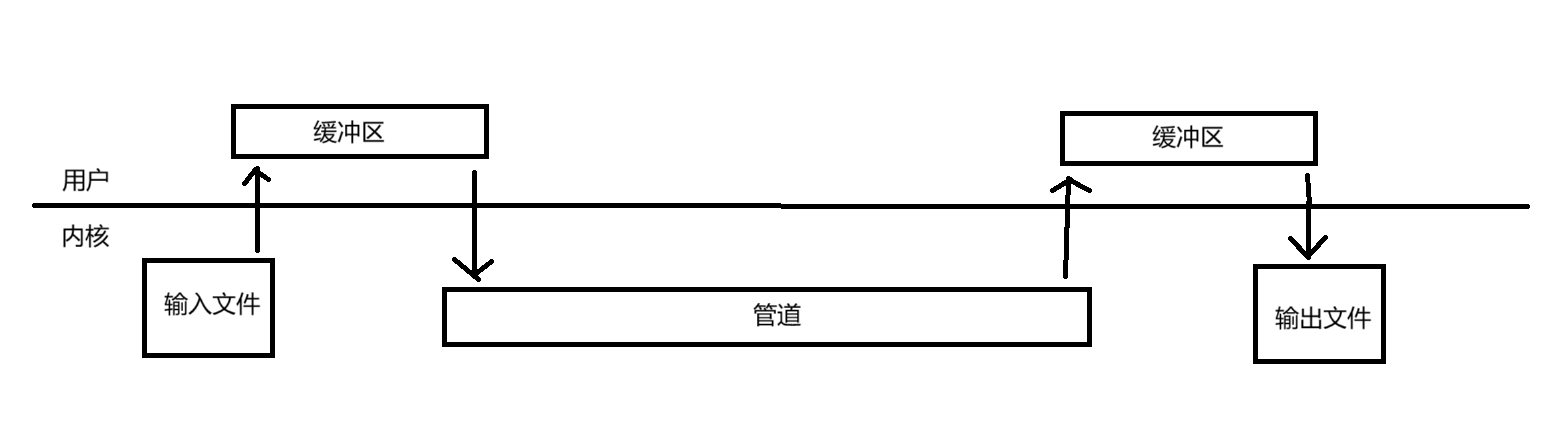
如图所示,通过管道通信需要4次拷贝
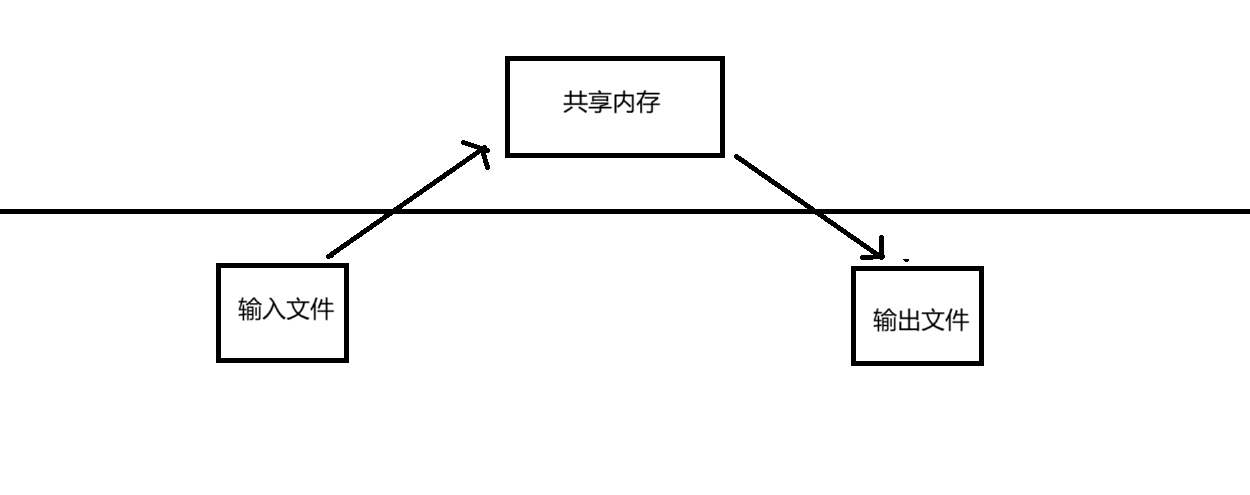
如图,通过共享内存仅需2次拷贝
所以共享内存是所有进程间通信方式中最快的一种通信方式,因为该通信方式需要进行的拷贝次数最少。
四.Linux内核中System V IPC的精妙设计:C语言实现的多态艺术
一、统一管理的设计挑战
在操作系统内核开发中,System V IPC(共享内存、消息队列、信号量)面临一个关键挑战:如何高效管理三种不同机制的资源?传统思路会为每种IPC类型单独设计管理模块,但这将导致:
- 代码重复度高
- 资源配额难以统一控制
- 权限管理分散
- 对象查找效率低下
Linux内核通过精妙的结构体设计,用C语言实现了类似面向对象的多态机制,完美解决了这些问题。
二、结构体布局的艺术
三种IPC机制的核心数据结构定义如下:
c
// 共享内存
struct shmid_kernel {
struct ipc_perm shm_perm; // 必须为首成员
// 其他专有成员...
};
// 消息队列
struct msg_queue {
struct ipc_perm q_perm; // 必须为首成员
// 其他专有成员...
};
// 信号量数组
struct sem_array {
struct ipc_perm sem_perm; // 必须为首成员
// 其他专有成员...
};这些结构体都遵守两个关键约定:
ipc_perm作为第一个成员- 通过
container_of宏实现反向定位
三、多态机制的实现原理
内核通过统一的资源管理结构实现多态:
c
struct ipc_ids {
struct ipc_id_ary *entries; // 指针数组
// 其他管理信息...
};
struct ipc_id_ary {
int size;
struct kern_ipc_perm *entries[0]; // 柔性数组
};这里的关键在于:
- 每个数组元素都是
struct kern_ipc_perm*类型 - 实际存储的是具体IPC结构的指针
- 通过指针类型转换实现统一访问