近端策略优化(Proximal Policy Optimization, PPO)作为强化学习领域的重要算法,在众多实际应用中展现出卓越的性能。本文将详细介绍PPO算法的核心原理,并提供完整的PyTorch实现方案。
PPO算法在强化学习任务中具有显著优势:即使未经过精细的超参数调优,也能在Atari游戏环境等复杂场景中取得优异表现。该算法不仅在传统强化学习任务中表现出色,还被广泛应用于大语言模型的对齐优化过程。因此掌握PPO算法对于深入理解现代强化学习技术具有重要意义。
本文将通过Lunar Lander环境演示PPO算法的完整实现过程。文章重点阐述算法的核心概念和实现细节,通过适当的修改,本实现方案可扩展至其他强化学习环境。本文专注于高层次的算法理解,为读者提供系统性的技术资源。
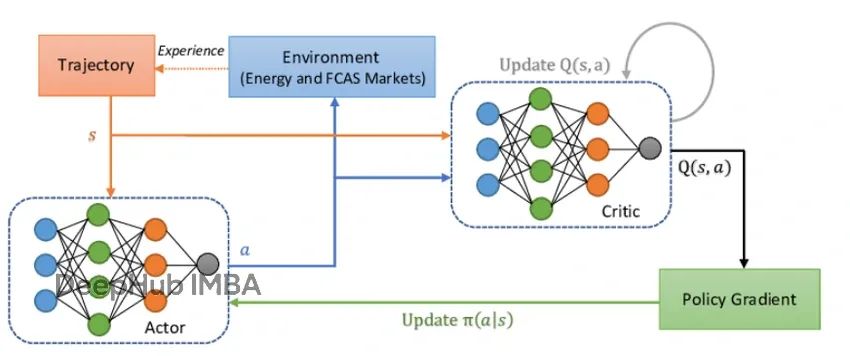
PPO算法核心组件
PPO算法由四个核心组件构成:环境交互模块、智能体决策系统、优势函数计算以及策略更新裁剪机制。每个组件在算法整体架构中发挥着关键作用。
环境交互模块
环境是智能体进行学习和决策的载体。这里我们选用Lunar Lander作为测试环境,这是一个二维物理模拟场景,要求着陆器在月球表面的指定区域安全着陆。环境模块负责提供状态观测信息,接收智能体的动作指令,并根据任务完成情况反馈相应的奖励信号。
有效的环境设计和奖励函数是成功训练的基础。智能体需要从环境中获取充分的状态信息以做出合理决策,同时需要通过明确的奖励信号了解其行为的优劣程度。奖励信号的质量直接影响智能体的学习效率和最终性能。
智能体决策系统
PPO采用演员-评论家(Actor-Critic)架构设计智能体决策系统。演员网络负责根据当前状态选择最优动作,而评论家网络则评估当前状态的价值期望。
演员网络的作用类似于决策执行者,根据观测到的环境状态输出动作概率分布。评论家网络则充当价值评估者,预测在当前状态下能够获得的累积奖励期望值。当评论家的价值估计出现偏差时,通常表明智能体的策略仍有改进空间。
优势函数
优势函数用于量化特定动作相对于评论家期望值的优劣程度。正优势值表示该动作的表现优于期望,应当增强此类行为的选择概率;负优势值则表示表现不佳,需要降低此类行为的选择概率。
相比直接使用原始奖励值,优势函数能够提供更稳定的训练信号。智能体仅在实际表现与预期之间存在显著差异时才进行大幅度的策略调整,这种机制有效避免了训练过程中的不必要波动。本实现采用广义优势估计(Generalized Advantage Estimation, GAE)方法计算优势值。
PPO策略更新裁剪机制
PPO算法的核心创新在于引入策略更新的裁剪机制,这是其相对于传统策略梯度方法的关键改进。在强化学习训练过程中,过大的策略更新可能导致训练失稳,使智能体突然丢失已学习的有效策略。
这种现象可以类比为在狭窄山脊上行走的登山者:如果步伐过大或方向偏离,很容易失足跌落深谷,重新攀登将耗费大量时间和精力。PPO通过实施裁剪约束,确保每次策略更新都在安全范围内进行,保持学习过程的稳定性和连续性。
依赖库安装与环境配置
本实现需要安装gymnasium库及其相关依赖来运行Lunar Lander环境,PyTorch用于神经网络的构建和训练,以及tensordict库来管理训练数据。tensordict是一个先进的数据管理工具,允许将PyTorch张量作为字典元素进行操作,支持通过键值索引和检索数据项。这种设计使得数据管理更加灵活高效,同时保持张量和tensordict在GPU上的计算能力,与PyTorch工作流程无缝集成。
!pip install swig gymnasium torch tensordict pyvirtualdisplay
!pip install "gymnasium[box2d]"为确保实验结果的可重现性,我们设置统一的随机种子:
import random
import torch
import numpy as np
seed = 777
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True需要注意的是,由于向量化环境初始化过程中存在的随机性因素,完全的结果重现仍然面临技术挑战。虽然代码能够正常运行且智能体训练过程稳定,但具体的数值结果在不同运行之间可能存在差异。
Lunar Lander环境配置
Lunar Lander是gymnasium库中的经典强化学习环境,任务目标是控制着陆器在二维空间中导航,最终在月球表面的指定着陆区域安全降落。智能体根据着陆过程中的姿态稳定性、着陆柔和度以及任务完成速度获得相应奖励。着陆器具备四种控制动作,环境在每个时间步提供八维状态向量描述着陆器的当前状态。详细的环境说明可参考官方文档。
为提高训练数据收集效率,我们创建10个并行的Lunar Lander环境实例。同时配置独立的评估环境,用于记录智能体在各个训练阶段的表现视频,便于直观评估训练效果。
import gymnasium as gym
from gymnasium.wrappers import RecordVideo
# 创建将运行10个模拟的向量化环境
env_name = "LunarLander-v3"
num_envs = 10
envs = gym.make_vec(env_name, num_envs=num_envs, vectorization_mode="sync")
# 创建我们的评估录制环境,用于当我们
# 想要测试我们的智能体在训练的各个阶段表现如何时使用
env = gym.make(env_name, render_mode="rgb_array")
trigger = lambda t: True
recording_output_directory = "./checkpoint_videos"
recording_env = RecordVideo(env, recording_output_directory, episode_trigger=trigger)环境交互辅助类设计
为提高代码的模块化程度和可维护性,我们设计了专门的环境交互辅助类,负责处理训练数据收集和评估过程。该类封装了与环境的所有交互操作,包括训练环境、评估环境、智能体以及计算设备的管理。
主要功能包括:数据rollout收集用于获取训练样本,以及评估rollout执行用于性能测试和视频记录。评估过程中的视频录制功能由RecordVideo包装器自动完成。
from tensordict import TensorDict
import torch
# 关于这个类的快速说明
# 它假设训练环境在终端状态时自动重置,例如向量化环境
# 并且它假设评估环境不会自动重置
# 我还将num_steps_per_rollout固定为收集器初始化时的值,但这可以在
# get rollout函数中参数化
class PPORolloutCollector:
def __init__(self, agent, envs, num_steps_per_rollout, device, eval_env=None):
self.agent = agent
self.envs = envs
self.num_envs = envs.num_envs
self.num_steps_per_rollout = num_steps_per_rollout
self.device = device
self.eval_env = eval_env
self.obs_shape = envs.single_observation_space.shape
self.action_shape = envs.single_action_space.shape
self.initial_buffer_shape = (num_steps_per_rollout, envs.num_envs)
# 继续重置环境并存储观察
# 并将next_done设置为false(我们假设环境不能以终端状态开始)
obs, _ = envs.reset()
self.next_obs = torch.Tensor(obs).to(device)
self.next_done = torch.zeros(num_envs).to(device)
# 创建一个空缓冲区,将保存观察、来自智能体的动作、该动作的对数概率
# 当前观察的评论家估计、从环境中获得的采取动作的实际奖励,以及
# 动作是否导致终端状态
# 我们故意选择不为每个观察记录"下一状态",这基本上会使
# 缓冲区的大小翻倍,由于我们按顺序收集观察并且在这里不打乱
# 任何下游操作都可以只使用数组中的下一个值作为下一状态
def _create_buffer(self):
return TensorDict({
"obs": torch.zeros(self.initial_buffer_shape + self.obs_shape).to(self.device),
"actions": torch.zeros(self.initial_buffer_shape + self.action_shape).to(self.device),
"log_probs": torch.zeros(self.initial_buffer_shape).to(self.device),
"rewards": torch.zeros(self.initial_buffer_shape).to(self.device),
"dones": torch.zeros(self.initial_buffer_shape).to(self.device),
"critic_values": torch.zeros(self.initial_buffer_shape).to(self.device),
})
# 将收集num_steps_per_rollout个观察对我们的训练环境的函数
def get_next_rollout(self):
buffer = self._create_buffer()
# 获取最后记录的观察以及该观察是否为终端
next_obs = self.next_obs
next_done = self.next_done
# 收集rollout
for t in range(self.num_steps_per_rollout):
# 记录当前观察和终端状态
buffer["obs"][t] = next_obs
buffer["dones"][t] = next_done
# 查询智能体下一个动作、该动作的对数概率和评论家估计
with torch.no_grad():
action, log_prob, entropy = self.agent.get_actor_values(next_obs)
critic_value = self.agent.get_critic_value(next_obs)
# 记录值
buffer["actions"][t] = action
buffer["log_probs"][t] = log_prob
buffer["critic_values"][t] = critic_value.flatten()
# 执行动作
next_obs, reward, terminations, truncations, infos = envs.step(action.cpu().numpy())
# 形状化并存储奖励
reward = torch.tensor(reward).to(self.device).view(-1)
buffer["rewards"][t] = reward
# 一些环境会终止(意味着智能体处于最终状态),
# 其他会截断(例如达到时间限制但不在终端状态)
# 这些是重要的区别,但对我们的目的来说意味着同样的事情,模拟结束了
# 所以如果任一为真且模拟重置,我们将next done设置为true
next_done = np.logical_or(terminations, truncations)
# 为下一轮存储下一个obs和next done
next_obs, next_done = torch.Tensor(next_obs).to(self.device), torch.Tensor(next_done).to(self.device)
# 在缓冲区中存储下一个obs和next done
# 这是为了在稍后计算优势时处理边缘情况
buffer['next_obs'] = next_obs
buffer['next_done'] = next_done
# 我们还需要这个下一状态的评论家估计,我们将使用它来引导最终状态的奖励
# 当我们计算gae时
with torch.no_grad():
buffer['next_value'] = self.agent.get_critic_value(next_obs).reshape(1, -1)
self.next_obs = next_obs
self.next_done = next_done
return buffer
# 用于在我们的环境上评估智能体,将运行整个模拟直到终止
# 与上面非常相似,唯一的区别是我们将手动检查环境是否终止
# 然后结束循环
# 将返回一个普通的python字典,包含奖励、熵、奖励平均值、我们智能体的平均熵,以及每次运行的总奖励
def run_eval_rollout(self, num_episodes: int = 5):
assert self.eval_env is not None, "No eval_env provided."
rewards_per_timestep = []
entropies_per_timestep = []
final_rewards = []
total_entropies = []
for _ in range(num_episodes):
obs, _ = self.eval_env.reset()
obs = torch.tensor(obs, device=self.device).unsqueeze(0)
done = False
episode_rewards = []
episode_entropies = []
while not done:
with torch.no_grad():
action, _, entropy = self.agent.get_actor_values(obs)
action = action.squeeze()
obs_np, reward, term, trunc, _ = self.eval_env.step(action.cpu().numpy())
done = term or trunc
obs = torch.tensor(obs_np, device=self.device).unsqueeze(0)
episode_rewards.append(float(reward))
episode_entropies.append(entropy.item())
rewards_per_timestep.append(episode_rewards)
entropies_per_timestep.append(episode_entropies)
final_rewards.append(sum(episode_rewards))
total_entropies.append(sum(episode_entropies) / len(episode_entropies))
return {
"rewards_per_timestep": rewards_per_timestep,
"average_reward_per_run": sum(final_rewards) / len(final_rewards),
"average_entropy_per_run": sum(total_entropies) / len(total_entropies),
"entropies_per_timestep": entropies_per_timestep,
"final_rewards": final_rewards,
}智能体网络架构设计
本实现采用演员-评论家架构构建智能体决策系统。该架构的一个重要特点是演员网络和评论家网络可以完全独立,也可以共享部分网络层。在复杂环境中,通常建议让两个网络共享前期特征提取层,使得双方都能从对方的损失更新中受益。然而,在本示例中,为了清晰展示两个网络的独立性,我们采用完全分离的网络结构。
借助PyTorch模块的参数管理机制,我们无需将两个网络实现为独立的类,可以在单一Agent类中统一管理。
import torch.nn as nn
from torch.distributions.categorical import Categorical
# 一个初始化辅助函数。在强化学习问题中,正交初始化
# 网络的权重可能会有帮助,这意味着每层的输出尽可能
# 不相关。这可以通过帮助梯度更好地流动和避免可能
# 从朴素初始化中产生的相关特征问题来改善训练稳定性和效率。
# 可以把这想象成确保网络不会以交叉的线路开始。
# 这个函数取自CleanRL的PPO实现。
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
# 我们的输入数组有多大?
# 注意如果我们做的是图像观察之类的
# 我们需要重新设计这个,但lunar lander只提供
# 代表世界状态的数字数组
input_shape = np.array(envs.single_observation_space.shape).prod()
# 我们的智能体将有多少个动作?
action_shape = envs.single_action_space.n
# 创建一个3层评论家,它将预测
# 我们的智能体在给定观察下预期收到的总奖励
self.critic = nn.Sequential(
layer_init(nn.Linear(input_shape, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64,1), std=1.0)
)
# 创建一个3层演员,它将输出一个概率分布
# 表示在给定观察下最好采取哪个动作的概率
self.actor = nn.Sequential(
layer_init(nn.Linear(input_shape, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, action_shape), std=1.0)
)
def save(self, path):
torch.save(self.state_dict(), path)
def load(self, path):
self.load_state_dict(torch.load(path))
def get_critic_value(self, x):
return self.critic(x)
def get_actor_values(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), probs.entropy()网络初始化采用正交初始化策略,这是强化学习领域的常见实践。正交初始化确保各网络层输出之间的去相关性,有助于改善梯度流动并避免特征相关性问题,从而提升训练的稳定性和效率。这种初始化方法可以形象地理解为确保网络不会以"交叉连线"的状态开始训练。
创建智能体实例并配置计算设备:
# 如果可用,使用gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
agent = Agent(envs).to(device)
print("using device: ", device)配置优化器,选择Adam优化算法并设置学习率为2.5e-4,这是PPO训练的常用起始参数:
import torch.optim as optim
learning_rate = 2.5e-4
optimizer = optim.Adam(agent.parameters(), lr=learning_rate, eps=1e-5)优势函数理论与实现
优势函数用于量化特定动作相对于评论家价值估计的表现差异。当智能体在游戏中的典型得分为15分时,这个分数就成为性能基准。如果智能体采用新策略获得17分,则优势值为2,表明新策略的表现超出预期。
采用优势函数替代原始奖励信号能够稳定训练过程,防止智能体满足于次优策略。当我们使用优势校正值训练评论家网络时:
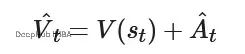
相比直接预测原始回报,这种方法通常能实现更快的收敛速度和更稳定的评论家更新过程。
广义优势估计(GAE)算法
广义优势估计是计算优势函数的经典方法。该方法不直接比较完整轨迹回报与价值估计(这种方式存在较大噪声),而是采用时间差分残差的平滑求和。这种设计在偏差和方差之间取得平衡,即使在评论家网络估计不够精确的情况下也能保持实用性。
时间差分残差的定义为:
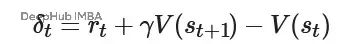

基于TD残差,GAE的递归定义为:
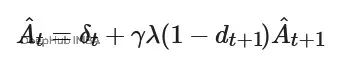

在实际实现中,我们沿着轨迹反向计算优势值,在每个回合结束时将累积值重置为零。这种方法能够产生稳定且低方差的优势估计,可直接用于PPO算法的策略更新。
# 我们的compute_gae函数将接收缓冲区和2个超参数,gamma和gae_lambda,它们控制未来结果对优势和回报的影响程度
# 我们的函数将向缓冲区添加2个新值:
# 1. 'advantages',即每个时间步的gae计算优势,将用于帮助调整我们智能体的演员部分
# 2. 'returns',即基于优势调整的评论家值,可以将其视为使用优势将评论家的值推向实际奖励
# returns将用于训练评论家做出更好的价值预测
def compute_gae(buffer, gamma=0.99, gae_lambda=0.95):
next_done = buffer['next_done']
critic_values = buffer['critic_values']
rewards = buffer['rewards']
dones = buffer['dones']
num_steps_per_rollout = len(rewards)
last_step_critic_values = buffer['next_value']
advantages = torch.zeros_like(rewards).to(device)
last_gae_value = 0
with torch.no_grad():
# 由于gae是前瞻的并使用未来值,我们可以聪明一点并向后工作
# 我们将首先计算最后的优势,然后当我们计算倒数第二个时,我们将有递归的
# 未来值保存,以此类推
for t in reversed(range(num_steps_per_rollout)):
# 检查我们是否在最后一个时间步,如果是,则使用last_step_critic_values,这是对
# 来自我们环境的最后状态的评论家预测,我们还没有实际对其采取行动的状态。否则我们向前
# 在缓冲区中查看以获得下一个值
if t == num_steps_per_rollout-1:
next_nonterminal = 1.0 - next_done
next_values = last_step_critic_values
else:
# 否则我们使用缓冲区中为下一个时间步存储的值
next_nonterminal = 1.0 - dones[t+1]
next_values = critic_values[t+1]
# 计算未来奖励,由gamma折扣
# 如果状态是终端状态,我们也将未来奖励归零
discounted_estimated_future_reward = gamma * next_values * next_nonterminal
# 接下来我们计算此时间步的时间差分(TD)误差
td_error = rewards[t] + discounted_estimated_future_reward - critic_values[t]
# 现在我们递归计算优势
current_advantage = td_error + gamma * gae_lambda * next_nonterminal * last_gae_value
# 记录这个优势
advantages[t] = current_advantage
# 由于我们向后计算优势,我们可以存储当前优势并将其用作
# 下一步的未来优势!
last_gae_value = current_advantage
# 存储我们计算的优势
buffer['advantages'] = advantages
# 并计算和存储我们的回报
returns = advantages + critic_values
buffer['returns'] = returns
return bufferPPO策略更新机制
在完成优势计算后,我们实施PPO的核心策略更新过程。PPO通过引入策略更新裁剪机制,有效避免了传统策略梯度方法中可能出现的破坏性大幅更新。
首先定义新策略πθ与旧策略πθ_old之间的概率比率:
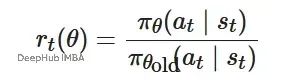
该比率反映了新策略相对于旧策略选择相同动作的概率变化程度。
裁剪代理目标函数
PPO的核心目标函数用于指导演员网络的优化过程:
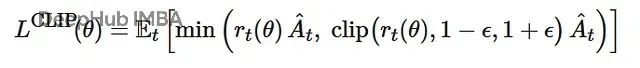

该函数的设计目标是控制策略更新幅度,确保更新方向基于优势信号的指导,同时避免过度偏离当前策略。
价值函数损失
评论家网络采用均方误差损失函数,目标是最小化价值预测与GAE目标值之间的差异:
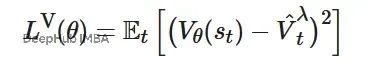

熵正则化项
熵值反映模型决策的确定性程度。高熵表示模型在多个动作间的概率分布较为均匀,低熵则表示模型对特定动作具有强烈偏好。为促进探索行为,我们在损失函数中加入熵正则化项。当模型的策略熵过低时,该项会施加惩罚,防止策略过早收敛到局部最优解。
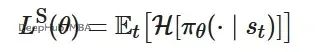
综合损失函数
PPO的最终损失函数是上述三个组件的加权组合:
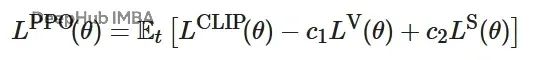

其中,系数c1控制评论家网络的学习速率,c2控制探索行为的强度。
def run_ppo_update_step(update_epochs_per_rollout, agent, optimizer, buffer, batch_size, minibatch_size,
clip_coef=0.2, ent_coef=0.01, vf_coef=0.5,
should_normalize_advantages=True, max_grad_norm=0.5):
# 为训练准备缓冲区
b_obs = buffer['obs'].reshape((-1,) + envs.single_observation_space.shape)
b_logprobs = buffer['log_probs'].reshape(-1)
b_actions = buffer['actions'].reshape((-1,) + envs.single_action_space.shape)
b_advantages = buffer['advantages'].reshape(-1)
b_returns = buffer['returns'].reshape(-1)
b_inds = np.arange(batch_size)
for epoch in range(update_epochs_per_rollout):
np.random.shuffle(b_inds)
for start in range(0, batch_size, minibatch_size):
end = start + minibatch_size
mb_inds = b_inds[start:end]
_, new_log_prob, entropy = agent.get_actor_values(b_obs[mb_inds], action = b_actions[mb_inds])
new_critic_value = agent.get_critic_value(b_obs[mb_inds])
log_ratio = new_log_prob - b_logprobs[mb_inds]
ratio = log_ratio.exp()
mb_advantages = b_advantages[mb_inds]
# 将优势标准化作为小批量的一部分
# 在小批量级别而不是整个缓冲区进行标准化通常有助于
# 稳定训练并导致更好的结果!
if should_normalize_advantages:
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
# 策略损失
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - clip_coef, 1 + clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# 价值损失
new_critic_value = new_critic_value.view(-1)
v_loss = 0.5 * ((new_critic_value - b_returns[mb_inds]) ** 2).mean()
entropy_loss = entropy.mean()
loss = pg_loss - ent_coef * entropy_loss + v_loss * vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), max_grad_norm)
optimizer.step()完整的PPO训练流程
下面将整合所有组件,构建完整的PPO训练循环。该循环包含数据收集、优势计算、策略更新以及定期评估等关键步骤。
import time
import os
# 定义一些超参数
num_training_iterations = 1000 # 我们应该在停止之前做多少次训练迭代?
# 实际上,1000可能过度了,特别是对于这个环境,
# 但我们无论如何都会保持在1k!
num_steps_per_rollout = 1000 # 每次rollout我们应该做多少个时间步?
minibatch_size = 256 # 在更新期间我们的小批量应该有多大?
# 对于PPO,每次迭代我们可以有多次更新,尽管如果我们有太多,我们更可能达到裁剪函数的最大值并浪费计算
# 记住,每次迭代只采取小步骤,所以每个rollout 4个epochs(在整个rollout上训练4次)应该没问题
update_epochs_per_rollout = 4
iterations_per_eval = 100 # 我们应该多久做一次评估?在我们的情况下,我们将训练100次迭代,然后执行评估步骤
runs_per_eval = 5 # 评估时我们应该运行模拟多少次?单次运行可能很幸运,所以我们想对几次进行平均
# 定义保存我们智能体检查点的位置并确保目录存在
output_model_checkpoints_base = "./checkpoints"
os.makedirs(output_model_checkpoints_base, exist_ok=True)
# 初始化rollout收集器
rollout_collector = PPORolloutCollector(
agent=agent,
envs=envs,
num_steps_per_rollout=num_steps_per_rollout,
device=device,
eval_env=recording_env
)
# 跟踪运行需要多长时间!
elapsed_timesteps = 0
start_time = time.time()
# 创建一些列表来记录每个评估步骤的平均奖励和平均熵
# 我们稍后会在notebook中绘制这些!
average_eval_reward = []
average_eval_entropy = []
for iteration in range(num_training_iterations):
agent.train()
# 我们将为每次迭代打印一个临时行,以在训练期间跟踪它的进度,并验证它仍然活着
print(f"\rtraining iteration: {iteration}/{num_training_iterations} - runtime: {time.time() - start_time:.2f}", end='', flush=True)
# 为这个训练迭代收集rollout
buffer = rollout_collector.get_next_rollout()
# 为我们rollout中的观察计算GAE优势
buffer = compute_gae(buffer)
# 使用rollout数据运行ppo更新步骤
run_ppo_update_step(
update_epochs_per_rollout,
agent,
optimizer,
buffer,
batch_size=num_envs * num_steps_per_rollout,
minibatch_size=minibatch_size
)
# 跟踪到目前为止我们已经模拟了多少个时间步
elapsed_timesteps += num_envs * num_steps_per_rollout
# 定期对我们的智能体进行检查点和评估运行,
# 我们也会为最终迭代手动触发这个
if iteration % iterations_per_eval == 0 or iteration == num_training_iterations - 1:
with torch.no_grad():
agent.eval()
# 为我们的评估rollout收集评估统计数据
eval_stats = rollout_collector.run_eval_rollout(num_episodes=runs_per_eval)
avg_reward = eval_stats["average_reward_per_run"]
avg_entropy = eval_stats['average_entropy_per_run']
average_eval_reward.append(avg_reward)
average_eval_entropy.append(avg_entropy)
# 保存我们的智能体,以防我们需要在将来的运行中恢复
ckpt_path = os.path.join(output_model_checkpoints_base, f"checkpoint_{iteration}.pth")
agent.save(ckpt_path)
agent.train()
# 打印此评估运行的统计数据
elapsed = time.time() - start_time
print(f"\riteration {iteration}/{num_training_iterations} | timesteps: {elapsed_timesteps} | "
f"avg_eval_reward: {avg_reward:.2f} | avg_eval_entropy: {avg_entropy:.2f} | runtime: {elapsed:.2f}s")
# 将我们的智能体保存到最终模型
final_ckpt_path = os.path.join(output_model_checkpoints_base, "!final_model.pth")
agent.save(final_ckpt_path)训练过程包括环境数据收集、GAE优势计算、PPO策略更新以及定期性能评估。评估阶段会生成视频文件用于可视化分析,同时记录平均奖励和熵值变化以监控训练进展。
针对本示例环境,1000次训练迭代可能超出实际需求,但这个设置能够确保充分的策略收敛。在实际应用中,可根据具体任务需求调整训练轮数。
实验结果如下所示:

训练结果分析与可视化
通过绘制训练过程中的关键指标,我们可以直观地评估智能体的学习进展。主要关注两个指标:各代次的平均奖励值以及对应的策略熵变化。
import matplotlib.pyplot as plt
import numpy as np
generations = [i for i in range(len(average_eval_entropy))]
# 创建一个图形和两个排列在1行2列中的子图
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
# 在第一个子图(ax1)上绘制平均奖励
ax1.plot(generations, average_eval_reward, label="Avg. Eval Rewards", color="blue")
ax1.set_title('Avg. Eval Rewards')
ax1.set_xlabel('Generations')
ax1.set_ylabel('Avg. Reward')
ax1.grid(True)
# 在第二个子图(ax2)上绘制平均熵
ax2.plot(generations, average_eval_entropy, label="Avg. Eval Entropy", color="red")
ax2.set_title('Avg. Eval Entropy')
ax2.set_xlabel('Generations')
ax2.set_ylabel('Avg. Entropy')
ax2.grid(True)
# 调整布局以防止标题/标签重叠
plt.tight_layout()
# 显示图表
plt.show()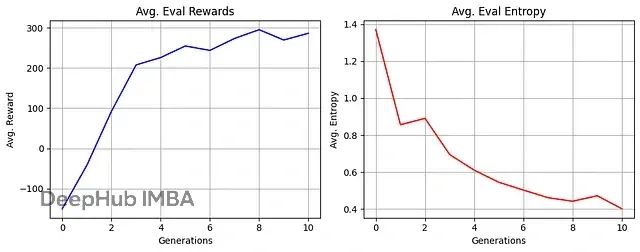
从训练曲线可以观察到预期的学习模式:智能体获得的累积奖励随训练进展而稳步提升,同时策略熵呈现下降趋势。需要注意的是,由于PPO损失函数中包含熵正则化项,策略熵不会降至过低水平,这种设计保证了智能体在优化过程中保持适度的探索能力。熵值的下降反映了策略的逐步成熟和决策确定性的提高。
智能体行为可视化
除了数值指标分析,直观观察智能体的实际执行行为同样重要。通过配置的评估环境,系统会自动将智能体的执行过程录制为MP4视频文件。下面展示如何检索和展示这些训练记录。
首先定位最新生成的评估视频文件:
import os
import re
# 这将提供给定目录中我们录制环境产生的最新文件
def get_latest_episode_video_file(directory):
# 正则表达式匹配文件格式并捕获片段编号
pattern = re.compile(r"rl-video-episode-(\d+)\.mp4")
latest_file = None
highest_episode = -1
# 搜索目录中的文件
for filename in os.listdir(directory):
match = pattern.match(filename)
if match:
episode_number = int(match.group(1)) # 提取片段编号
# 检查这个片段编号是否是找到的最高的
if episode_number > highest_episode:
highest_episode = episode_number
latest_file = os.path.join(directory, filename) # 存储完整路径
return latest_file
# 获取最新录制的文件路径
latest_eval_recording = get_latest_episode_video_file(recording_output_directory)实现视频嵌入功能,将录制的行为视频直接集成到Jupyter环境中:
import io
import base64
from IPython import display
from IPython.display import HTML
# 这个函数将接收视频文件的位置,然后
# 使用虚拟显示将视频嵌入到notebook中
def embed_video(video_file):
# 打开并从视频中读取原始数据
video_data = io.open(video_file, 'r+b').read()
# 现在我们必须将数据编码为base64才能与
# 虚拟显示一起工作
encoded_data = base64.b64encode(video_data)
# 现在我们使用display.display函数获取一些html
# 和编码数据,并将html嵌入到notebook中!
display.display(HTML(data='''<video alt="test" autoplay
loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded_data.decode('ascii'))))
embed_video(latest_eval_recording)在兼容的Jupyter环境中执行上述代码,将会在notebook中生成内嵌的HTML视频播放器,展示智能体的最新评估表现。
总结
本文提供了PPO算法的完整PyTorch实现方案,涵盖了从理论基础到实际应用的全流程。虽然当前实现在某些方面仍有改进空间,特别是在数学原理的详细阐述和代码架构的进一步优化方面,但已经构建了一个可靠的基础框架。
随着对强化学习领域更高级概念的深入探索,这个基础实现将不断得到扩展和完善。当前的实现已经充分展示了PPO算法的核心思想和实际应用能力,为进一步的研究和开发奠定了坚实基础。
该实现方案具有良好的可扩展性,可以适配不同的强化学习环境和任务需求。通过适当的修改和调整,读者可以将其应用到各类实际问题中,推进强化学习技术的实际应用。
https://avoid.overfit.cn/post/a0f561df40ad474db2a7749abb573aeb
作者:Coldstart Coder