Redis 中布隆过滤器使用介绍:高效判重的利器
在大规模数据处理场景中,判断一个元素是否存在于集合中是常见需求。传统的哈希表或数据库查询虽能实现,但在数据量激增时会面临内存占用过高或查询延迟的问题。Redis 中的布隆过滤器(Bloom Filter)凭借其高效的空间利用率和查询速度,成为解决此类问题的理想方案。本文将详细介绍 Redis 布隆过滤器的基本概念、工作原理、使用方式及实践总结。
一、介绍
布隆过滤器是一种概率型数据结构,由 Burton Howard Bloom 于 1970 年提出,主要用于快速判断一个元素是否 "可能存在" 于集合中。它的核心特点是:
-
高效空间利用率:相比传统数据结构(如哈希表),布隆过滤器用位数组存储数据,能以极低的空间成本存储海量元素。
-
快速查询速度:插入和查询操作的时间复杂度均为 O (k)(k 为哈希函数数量),几乎可视为常数级速度。
-
概率型判断:存在一定的 "误判率"(False Positive),即可能将不存在的元素判定为 "存在",但绝不会将存在的元素判定为 "不存在"(无漏判)。
核心作用
-
缓存穿透防护:在缓存架构中,过滤掉不存在于数据库中的查询请求,避免缓存失效时大量请求穿透到数据库。
-
海量数据判重:如爬虫去重、用户注册校验、日志重复检测等场景,快速判断元素是否已存在。
-
数据预过滤:在大规模数据集查询前,先通过布隆过滤器筛选出可能存在的元素,减少后续处理压力。
Redis 中的布隆过滤器
Redis 本身未内置布隆过滤器,但可通过官方推荐的 RedisBloom 模块(原 rebloom)实现。该模块提供了完整的布隆过滤器功能,支持动态扩容、自定义误判率等特性,自 Redis 4.0 起可通过加载模块启用。
二、使用原理
布隆过滤器的核心原理基于位数组 和多个哈希函数的组合,通过哈希映射和位运算实现高效的存在性判断。
1. 数据结构组成
-
位数组(Bit Array):一个由若干二进制位(bit)组成的数组,初始状态所有位均为 0。位数组的长度(m)是影响布隆过滤器性能的关键参数。
-
哈希函数(Hash Functions):一组独立的哈希函数(数量为 k),每个函数可将输入元素映射到位数组的某个索引位置(0 到 m-1)。
2. 插入过程
当插入一个元素时,流程如下:
-
使用 k 个哈希函数分别对元素进行哈希计算,得到 k 个位数组索引。
-
将位数组中这 k 个索引对应的位都设置为 1。
例如,插入元素 "redis" 时,通过 3 个哈希函数得到索引 2、5、7,则位数组中第 2、5、7 位被置为 1。
3. 查询过程
判断一个元素是否存在时,流程如下:
-
同样使用 k 个哈希函数对元素进行哈希计算,得到 k 个索引。
-
检查位数组中这 k 个索引对应的位是否均为 1:
-
若有任何一位为 0,则元素一定不存在于集合中。
-
若所有位均为 1,则元素可能存在(存在误判可能)。
4. 误判率与参数关系
误判率(p)是布隆过滤器的核心指标,其大小与三个参数相关:
-
位数组长度(m):长度越大,误判率越低(需平衡空间成本)。
-
哈希函数数量(k):数量过少会导致哈希碰撞概率升高,过多则会增加计算成本和位数组置 1 的密度,反而提高误判率。
-
预期元素数量(n):需根据实际数据规模预设,若实际元素远超预期,误判率会显著上升。
三者的数学关系可通过公式推导,通常推荐的参数配置为:
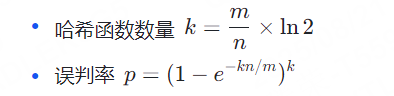
RedisBloom 模块会根据用户设置的预期元素数量(n)和误判率(p),自动计算最优的 m 和 k 值。
5. 局限性
-
误判不可避免:不同元素可能通过哈希函数映射到相同的 k 个索引,导致误判。
-
无法删除元素:由于多个元素可能共享位数组的位,删除一个元素的位会影响其他元素的判断(RedisBloom 提供了可删除的 "计数布隆过滤器" 扩展,但会增加空间开销)。
-
需预设容量:若实际元素数量远超预期,误判率会急剧上升,需提前规划合理容量。
三、使用方式
Redis 布隆过滤器的使用需基于 RedisBloom 模块,以下是完整的操作流程和核心命令。
1. 环境准备
(1)安装 RedisBloom 模块
-
源码编译:
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make
-
加载模块 :启动 Redis 时通过
--loadmodule指定模块路径:redis-server --loadmodule /path/to/redisbloom.so
-
验证安装 :连接 Redis 后执行
BF.ADD命令,若返回OK则说明模块加载成功。
2. 核心命令
(1)创建布隆过滤器:BF.RESERVE
初始化一个布隆过滤器,指定名称、误判率和预期元素数量。
# 语法:BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}]
# error_rate:允许的误判率(如 0.01 表示 1%)
# capacity:预期存储的元素数量
# EXPANSION:动态扩容系数(默认 2,当元素超容时自动扩容为原大小的 N 倍)
# 创建名为 "user_ids" 的过滤器,误判率 0.001(0.1%),预期存储 10000 个元素
BF.RESERVE user_ids 0.001 10000(2)添加元素:BF.ADD
向布隆过滤器中添加元素,若过滤器不存在则自动创建(默认参数)。
# 语法:BF.ADD {key} {element}
# 向 "user_ids" 添加元素 "10086"
BF.ADD user_ids 10086
# 批量添加元素(Redis 6.2+ 支持)
BF.MADD user_ids 10010 10000 12345(3)查询元素:BF.EXISTS
判断元素是否可能存在于过滤器中。
# 语法:BF.EXISTS {key} {element}
# 检查 "10086" 是否存在(返回 1 表示可能存在)
BF.EXISTS user_ids 10086 # 1
# 检查 "99999" 是否存在(返回 0 表示一定不存在)
BF.EXISTS user_ids 99999 # 0
# 批量查询
BF.MEXISTS user_ids 10010 99999 # 1 0(4)查看过滤器信息:BF.INFO
获取过滤器的参数信息,如当前元素数量、位数组长度、哈希函数数量等。
BF.INFO user_ids
# 返回:
# 1) Capacity
# 2) (integer) 10000
# 3) Size
# 4) (integer) 1008 # 位数组大小(bit)
# 5) Number of filters
# 6) (integer) 1
# 7) Number of items inserted
# 8) (integer) 4
# 9) Expansion
# 10) (integer) 23. 实践示例:缓存穿透防护
在电商场景中,用布隆过滤器过滤不存在的商品 ID 查询,避免缓存和数据库压力:
c
package main
import (
"context"
"fmt"
"strconv"
"time"
"github.com/go-redis/redis/v8"
)
var ctx = context.Background()
var rdb *redis.Client
// 初始化Redis连接
func initRedis() {
rdb = redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 密码,无密码则为空
DB: 0, // 使用的数据库编号
})
}
// 初始化布隆过滤器
func initBloomFilter() error {
// 执行BF.RESERVE命令,创建布隆过滤器
// 参数:过滤器名称、误判率、预期元素数量
return rdb.Do(ctx, "BF.RESERVE", "product_ids", 0.001, 100000).Err()
}
// 批量添加商品ID到布隆过滤器
func batchAddProductIDs() error {
// 准备命令参数
args := make([]interface{}, 0, 100001)
args = append(args, "product_ids") // 布隆过滤器名称
// 生成10万个商品ID
for i := 1; i <= 100000; i++ {
args = append(args, "prod_"+strconv.Itoa(i))
}
// 执行BF.MADD命令批量添加
return rdb.Do(ctx, "BF.MADD", args...).Err()
}
// 获取商品信息
func getProductInfo(prodID string) (string, error) {
// 先检查布隆过滤器
exists, err := rdb.Do(ctx, "BF.EXISTS", "product_ids", prodID).Int64()
if err != nil {
return "", err
}
// 如果布隆过滤器判断不存在,直接返回
if exists == 0 {
return "商品不存在", nil
}
// 布隆过滤器判断可能存在,查询缓存
cacheKey := "cache:" + prodID
cacheData, err := rdb.Get(ctx, cacheKey).Result()
if err == nil {
// 缓存命中,返回缓存数据
return cacheData, nil
} else if err != redis.Nil {
// 发生其他错误
return "", err
}
// 缓存未命中,查询数据库(这里简化处理)
productInfo := fmt.Sprintf("Product %s info", prodID)
// 更新缓存,设置过期时间1小时
err = rdb.Set(ctx, cacheKey, productInfo, 1*time.Hour).Err()
if err != nil {
return "", err
}
return productInfo, nil
}
func main() {
// 初始化Redis连接
initRedis()
// 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
fmt.Printf("Redis连接失败: %v\n", err)
return
}
fmt.Println("Redis连接成功")
// 初始化布隆过滤器
err = initBloomFilter()
if err != nil {
fmt.Printf("初始化布隆过滤器失败: %v (如果过滤器已存在,此错误可忽略)\n", err)
} else {
fmt.Println("布隆过滤器初始化成功")
}
// 批量添加商品ID
err = batchAddProductIDs()
if err != nil {
fmt.Printf("批量添加商品ID失败: %v\n", err)
return
}
fmt.Println("批量添加商品ID成功")
// 测试查询存在的商品
prodID := "prod_12345"
info, err := getProductInfo(prodID)
if err != nil {
fmt.Printf("查询商品信息失败: %v\n", err)
return
}
fmt.Println(info)
// 测试查询不存在的商品
prodID = "prod_999999"
info, err = getProductInfo(prodID)
if err != nil {
fmt.Printf("查询商品信息失败: %v\n", err)
return
}
fmt.Println(info)
}四、总结
Redis 布隆过滤器凭借高效的空间利用率 和快速的查询性能,成为解决海量数据判重和缓存穿透问题的核心工具。其核心优势可总结为:
-
低空间成本:以位数组存储数据,存储 100 万元素且误判率 1% 仅需约 12KB 空间。
-
高查询效率:插入和查询均为常数级时间复杂度,适合高并发场景。
-
易于集成:通过 RedisBloom 模块可无缝接入 Redis 生态,支持动态扩容和批量操作。
使用时需注意以下要点:
-
合理设置参数 :根据实际元素数量和可接受的误判率调整
capacity和error_rate,避免参数过小导致误判率飙升。 -
容忍误判场景:布隆过滤器适合可接受低概率误判的场景,若需 100% 准确判断(如金融交易),需结合其他数据结构验证。
-
动态扩容规划 :通过
EXPANSION参数设置扩容系数,平衡性能和空间开销。
总之,Redis 布隆过滤器是处理大规模数据存在性判断的高效方案,在缓存优化、数据去重、日志分析等场景中能显著提升系统性能,是开发者值得掌握的实用工具。