核心原理阐述
- Kubernetes 架构原理 (Master-Node 模型)
-
控制平面 (Master):集群的大脑。
-
API Server:集群网关,所有操作都必须通过它。
-
Scheduler:负责调度 Pod 到合适的 Node。
-
Controller Manager:维护集群状态(如副本数、故障恢复)。
-
etcd:分布式键值存储,保存集群所有关键数据。
-
工作节点 (Node):干活的单元。
-
kubelet:节点代理,负责与 Master 通信并管理 Pod 生命周期。
-
容器运行时 (Docker/containerd):真正负责运行容器。
-
kube-proxy:维护网络规则,实现 Service 的负载均衡和服务发现。
Kubernetes 资源基础
-
核心概念
- Kubernetes 中所有内容抽象为资源,最小管理单元是 Pod
- 通常通过 Pod 控制器管理 Pod,而非直接管理
- 服务访问通过 Service 实现,数据持久化通过存储系统实现
-
资源管理方式
|---------|------|-----------------|-------------------------------------|
| 类型 | 适用场景 | 特点 | 示例命令 |
| 命令式对象管理 | 测试 | 简单直接,无法审计跟踪 | kubectl run nginx-pod --image=nginx |
| 命令式对象配置 | 开发 | 可审计跟踪,配置文件多时有麻烦 | kubectl create -f nginx-pod.yaml |
| 声明式对象配置 | 开发 | 支持目录操作,意外情况调试难 | kubectl apply -f nginx-pod.yaml | -
Pod 核心知识
Pod 定义
最小可部署单元,代表集群中运行的一个进程
包含一个或多个容器,共享 IPC、Network 和 UTC 命名空间每个 Pod 拥有唯一 IP 地址
1.基础环境准备(4台虚拟机)
核心目标
搭建一个高可用的 Kubernetes 生产级集群,实现容器化应用的自动化部署、扩展和管理。
整体流程
-
理论准备:理解 K8S 架构、组件及其协作原理。
-
环境规划:规划节点角色、网络、存储等资源。
-
基础准备:在所有节点上完成系统初始化(关闭 swap、配置网络、安装 Docker 等)。
-
核心安装:安装 K8S 核心组件 (`kubeadm`, `kubelet`, `kubectl`) 和容器运行时接口 (`cri-dockerd`)。
-
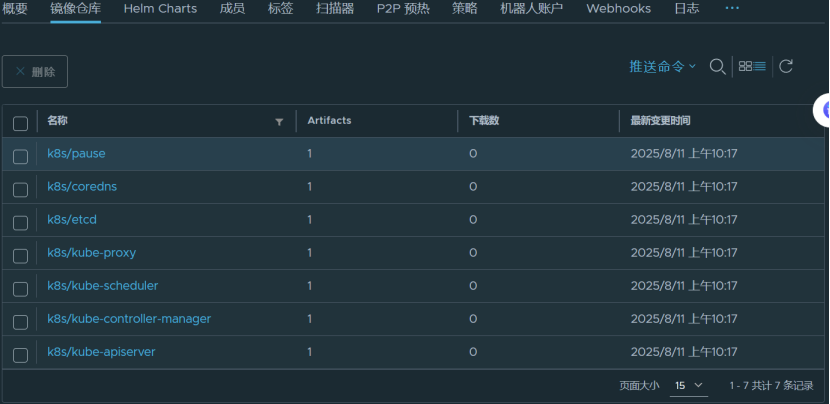
私有仓库:配置 Harbor 作为私有镜像仓库,供集群拉取镜像。
-
集群初始化:在 Master 节点使用 `kubeadm init` 初始化控制平面。
-
网络部署:安装 Flannel CNI 插件,为 Pod 提供网络通信能力。
-
节点扩容:将 Worker 节点加入集群,形成多节点集群。
-
功能验证:创建测试 Pod 验证集群基本功能是否正常。
1.1 reg节点
先开一台reg节点的虚拟机,IP为192.168.1.222
关闭selinux

部署Harbor
下载安装所需依赖包:这里已经提前下好,直接拖进来了




使用OpenSSL生成自签名证书,保障HTTPS通信
bash
[root@reg ~]# openssl req -newkey rsa:4096 -nodes -sha256 -keyout /data/certs/timinglee.org.key -addext "subjectAltName = DNS:reg.timinglee.org" -x509 -days 365 -out /data/certs/timinglee.org.crt 国家,省,市,...
国家,省,市,...


提供私有Docker镜像仓库,仓库地址为reg.timinglee.org,供集群内其他节点拉取镜像。。
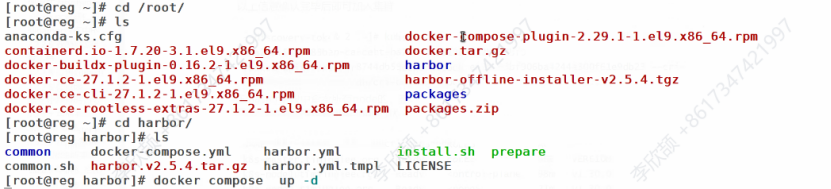
等待构建完成,通过Docker Compose启动Harbor服务。配置所有节点信任自签名证书,并登录私有仓库。
bash
ps:第一次启动用./install.sh --with-chartmuseum
后面启动时进入harbor目录通过Docker Compose启动
cd harbor/
docker compose up -d注意:每次关闭虚拟机后重启时,都要通过该命令重启Harbor服务


成功后就可以访问了
此时reg虚拟机就可以后台运行了,接下来我们看另外的
1.2 Kubernetes集群搭建
克隆三台主机:master100 ,node1:10,node2:20

关闭swap和本地解析
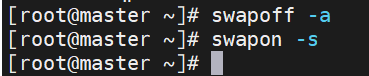
关闭Swap以确保内存管理一致性。


关闭当前三个节点的所有swap,并且重启之后也不能有
修改/etc/hosts,确保节点间可通过主机名通信。


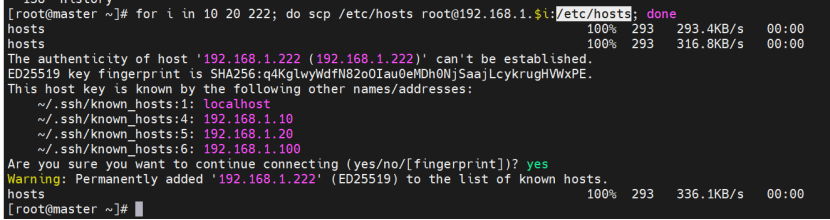
所有节点安装Docker,
前面我们在reg节点上已经配置好docker了,现在把安装包拷贝到其他三个节点上。






Master编辑配置文件

拷到其他两个node节点


配置仓库的加速器
并配置镜像加速器指向私有Harbor仓库。重启Docker服务并登录Harbor。

bash
[root@docker1 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": [
"https://reg.timinglee.org",
]
}
bash
[root@master docker]# for i in 10 20; do scp daemon.json root@192.168.1.$i:/etc/docker/; done
daemon.json 100% 57 85.4KB/s 00:00
daemon.json 100% 57 117.3KB/s 00:00
[root@master docker]# for i in 100 10 20; do ssh root@192.168.1.$i systemctl enable --now docker; done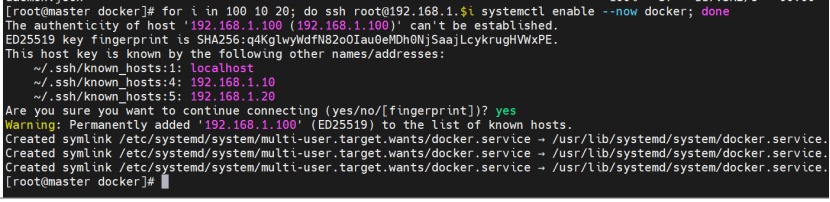
Docker info
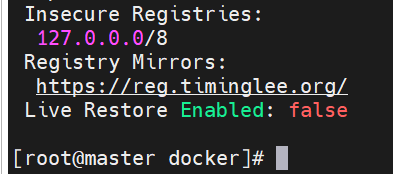
这三个主机都检查一下复制的文件成功没,一般这个时候就可以登陆了,但是
登陆报错,发现少了一个目录
cd /etc/docker/certs.d/



记得检查是否复制成功
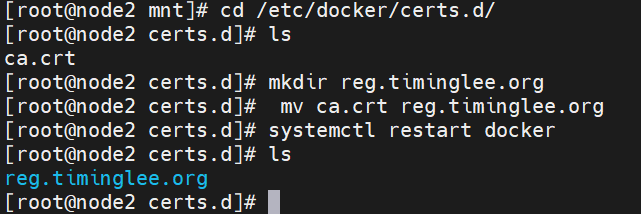
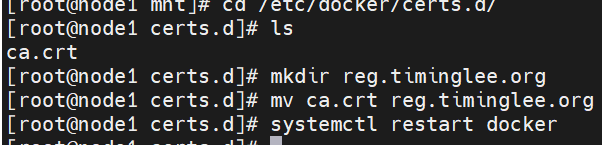
再次登陆,成功
登陆其他主机(所有主机都必须登陆,否则下不来东西)
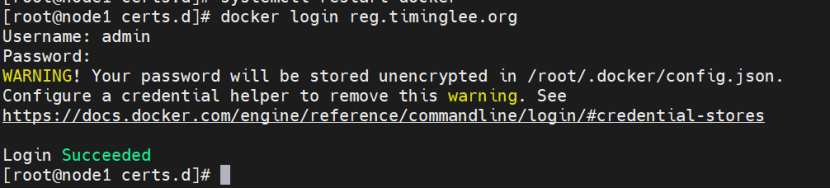
1.3 安装k8s
1.3.1 修改cri-dockerd启动文件添加
将需要安装的包下载下来,这里是有文件包直接拖进来了,没有的话可以去官网上搜索包下载'

对于其他的节点前面下载了docker包,现在可以先把包删除,再从master把新包拷过去
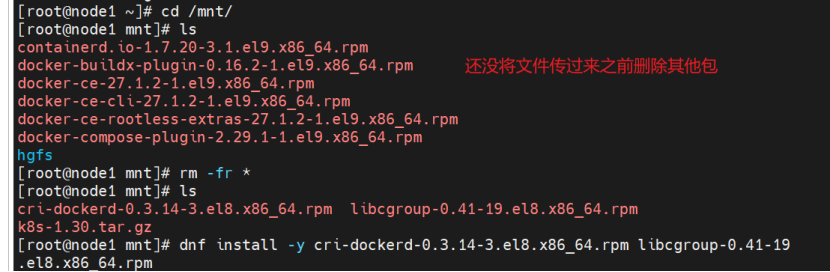
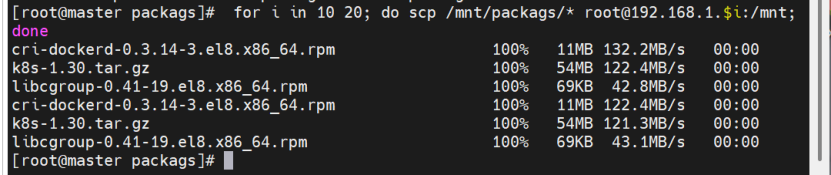
node2同理

配置kubelet使用cri-dockerd作为容器运行时。启动kubelet服务。




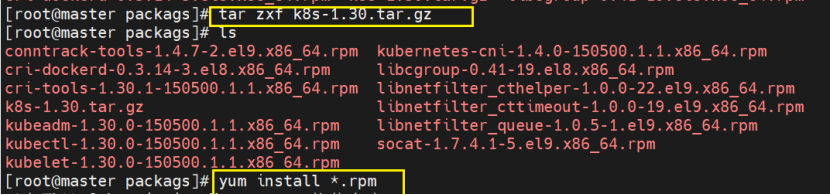




1.3.2 安装K8s部署工具
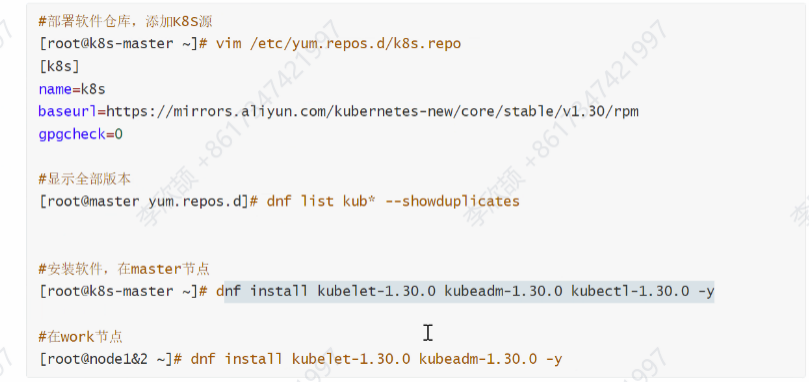
在【master】配置环境变量,设置kubectl命令补齐功能、
bash
dnf install bash-completion -y
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc1.4 拉取k8s镜像
导入镜像
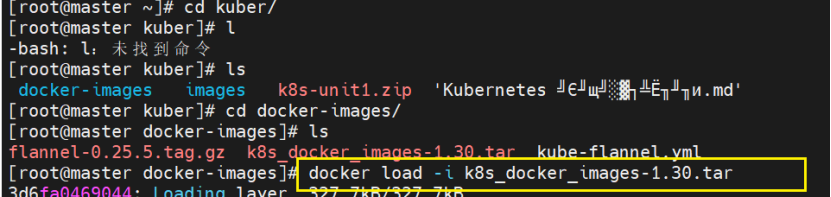
$0所有
root@master docker-images# docker images | awk '/google/{print 1":"2}' |awk -F / '{system("docker tag "0" reg.timinglee.org/k8s/"3)}'
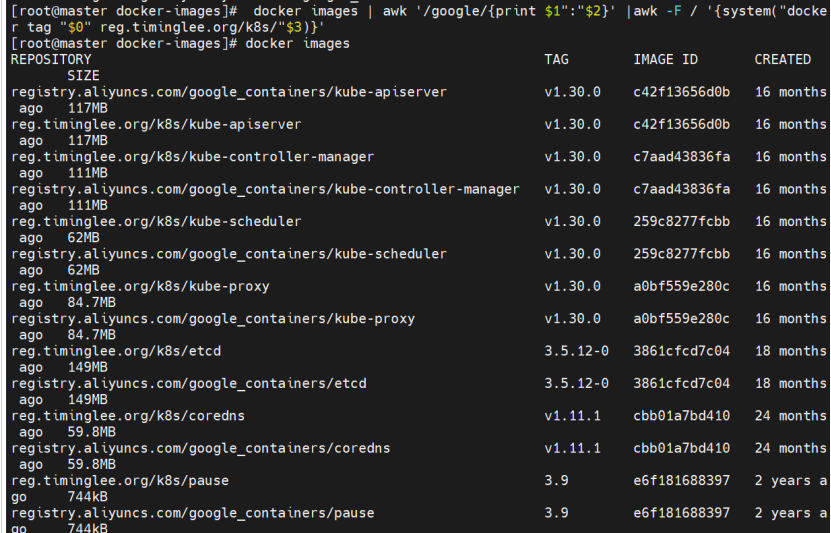
bash
[root@master docker-images] docker images | awk '/reg/{print $0}'
我们要的是这些
[root@master docker-images] docker images | awk '/reg/{print $1":"$2}'
就可以开始推了
如果拉取失败仓库拒绝可能是没开启重启一下reg的harbor
进入到harbor的目录下面
docker compose down 再docker compose up -d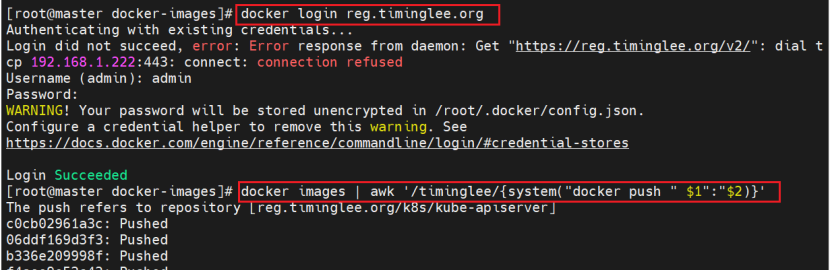
root@master docker-images# docker images | awk '/timinglee/{system("docker push " 1":"2)}'

【三个节点】
打开服务



bash
指定容器网络
kubeadm init --pod-network-cidr=10.244.0.0/16 \
--image-repository reg.timinglee.org/k8s \
--kubernetes-version v1.30.0 \
--cri-socket=unix:///var/run/cri-dockerd.sock
先导入配置
[root@master docker-images] echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master docker-images] source ~/.bash_profile
[root@master docker-images] kubectl get nodes
NAME STATUS ROLES AGE VERSION
master.timinglee.org NotReady control-plane 2m v1.30.0
notready未运行成功
其他节点

现在节点加不进去,因为还没有网络插件flannel
1.5 拉取Flannel镜像
先导入镜像:有俩个镜像显示
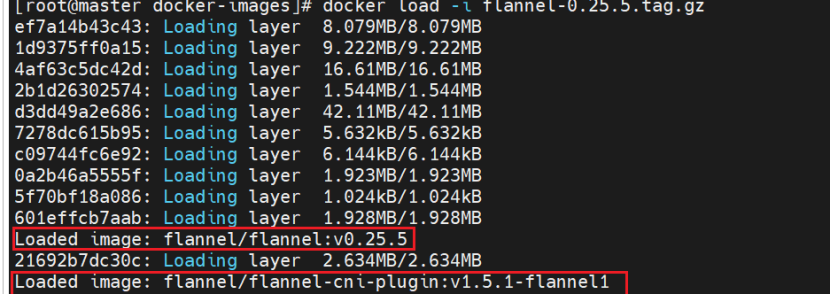
从Docker Hub拉取Flannel镜像,推送到私有Harbor。
分为三步 tag-新建项目-push
#先创建项目再拉取push,否则会拉取失败
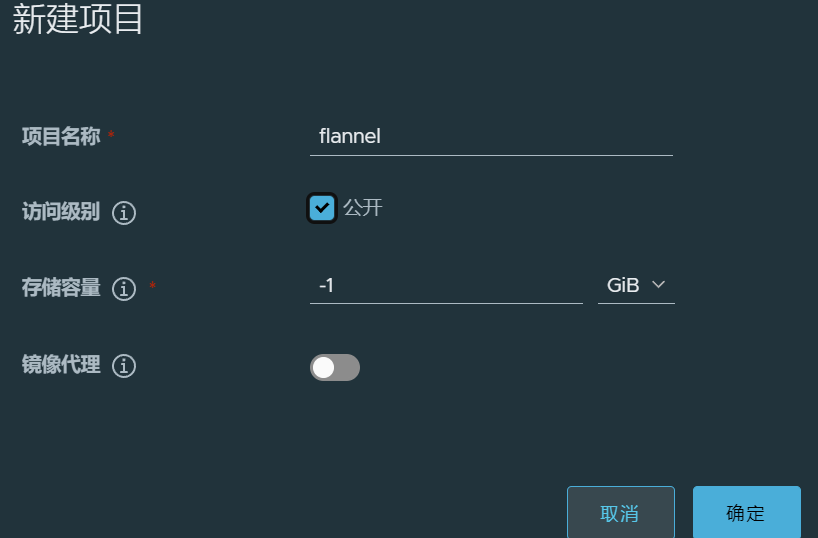
cs
两个镜像就要操作两次
docker tag flannel/flannel:v0.25.5 reg.timinglee.org/flannel/flannel:v0.25.5
#push 仓库网站/项目目录/镜像名 如果有了该目录,就不需要新建
docker push reg.timinglee.org/flannel/flannel:v0.25.5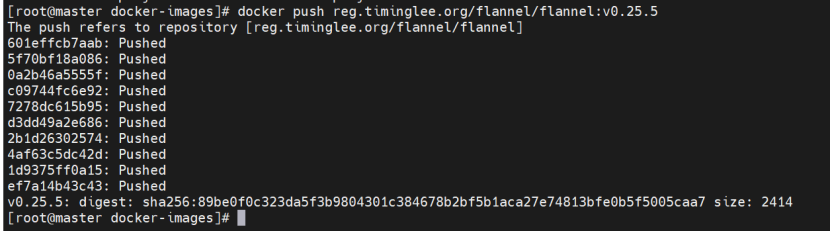
bash
打标签
docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 reg.timinglee.org/flannel/fl annel-cni-plugin:v1.5.1-flannel1
上传
docker push reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
修改kube-flannel.yml中的镜像地址为私有仓库路径。

修改文件kube-flannel.yml
cs
把前缀去掉即可
[root@master ~]# kubectl apply -f kube-flannel.yml
[root@master ~]# kubectl get nodes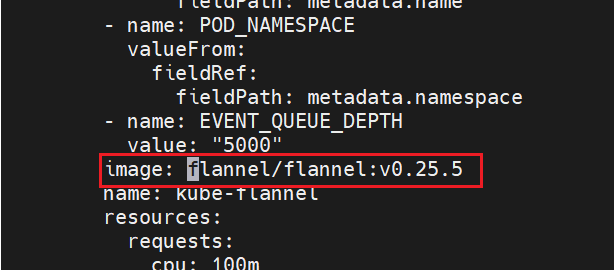
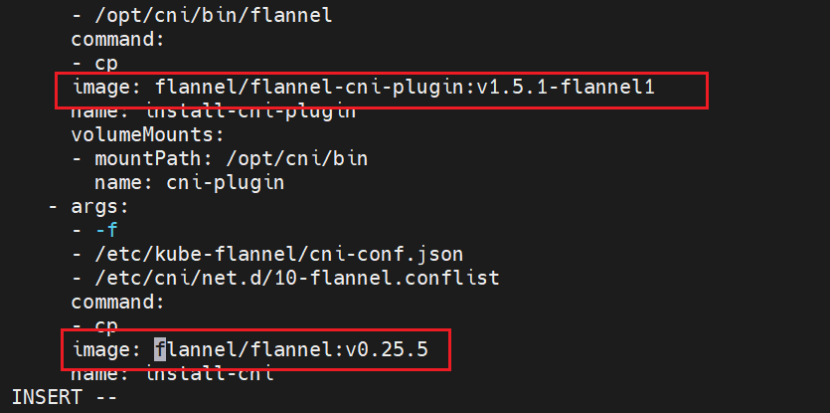
应用Flannel配置,等待Pod就绪。
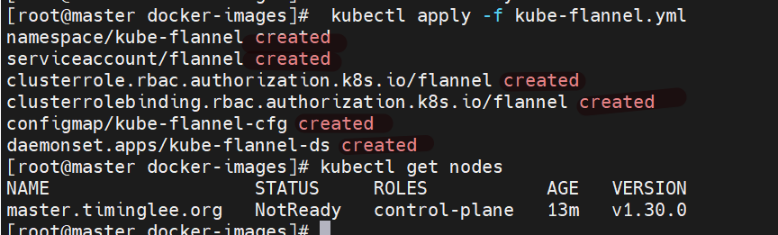



要等插件运行起来后才能看到


1.6 其他主机加入集群
使用kubeadm join命令将node10和node20加入集群。检查节点状态和网络连通性。
火墙是不是没关

记得检查火墙

bash
kubeadm join 192.168.1.100:6443 --token w6p5gc.a5halrlwz735s7rb --discovery-token-ca-cert-hash sha256:9166dd9826643972c931f34a0ace7e663cd69efa8f32c6e931b3f89ed3b90224 --cri-socket=unix:///var/run/cri-dockerd.sock
加载的比较慢可能是火墙

cpp
出现问题重新加载
[root@node2 ~]# kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
再执行刚才的命令
kubeadm join 192.168.1.100:6443 --token w6p5gc.a5halrlwz735s7rb --discovery-token-ca-cert-hash sha256:9166dd9826643972c931f34a0ace7e663cd69efa8f32c6e931b3f89ed3b90224 --cri-socket=unix:///var/run/cri-dockerd.sock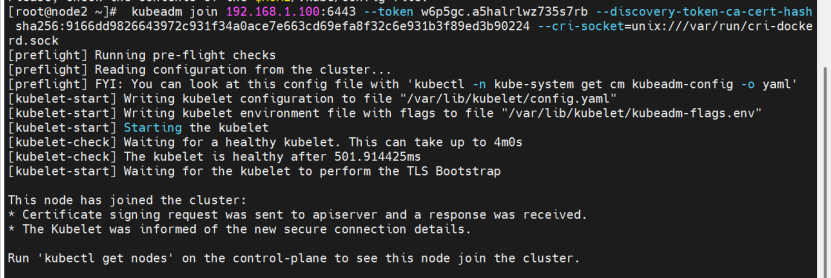
到此为止安装完成

1.7 测试

登不上去,没认证



 有点慢
有点慢

先登录再认证



可以看到两个节点各自运行了一个nginx
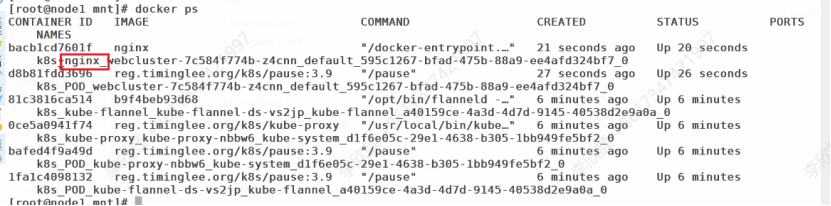
容器编排原理
Pod:K8S 最小调度单元,包含一个或多个共享网络/存储的容器。
Controller:通过定义期望状态(如 replicas: 3)来管理 Pod 的生命周期,确保实际状态始终向期望状态收敛(声明式管理)。
Service:为一组 Pod 提供稳定的访问入口和负载均衡。
CNI (Container Network Interface):Flannel 等插件负责为每个 Pod 分配 IP 并实现跨节点网络通信。
2. 基础Pod与控制器实验
2.1 Pod镜像准备
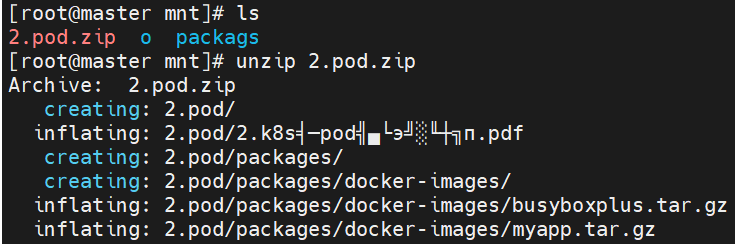


bash
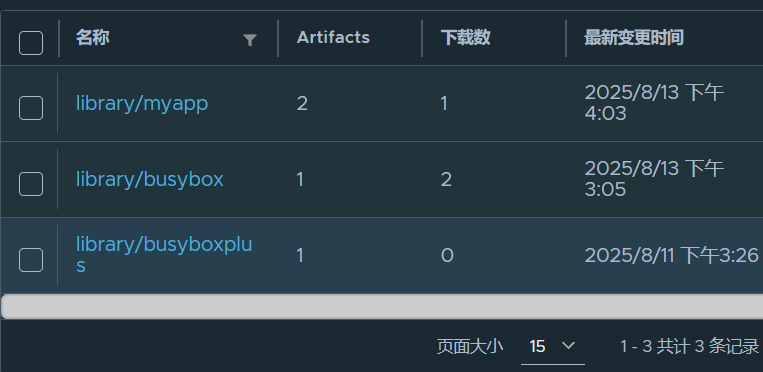
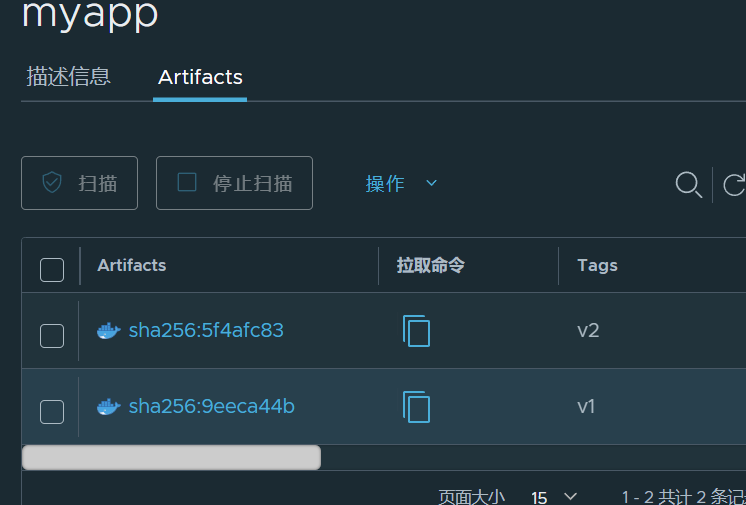
docker tag busyboxplus:latest reg.timinglee.org/library/busyboxplus:latest
docker push reg.timinglee.org/library/busyboxplus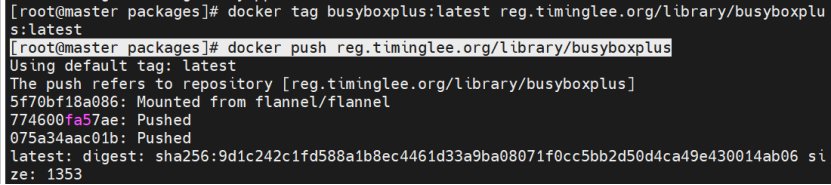
bash
docker tag timinglee/myapp:v1 reg.timinglee.org/library/myapp:v1
#记得push要新建项目
docker push reg.timinglee.org/library/myapp:v1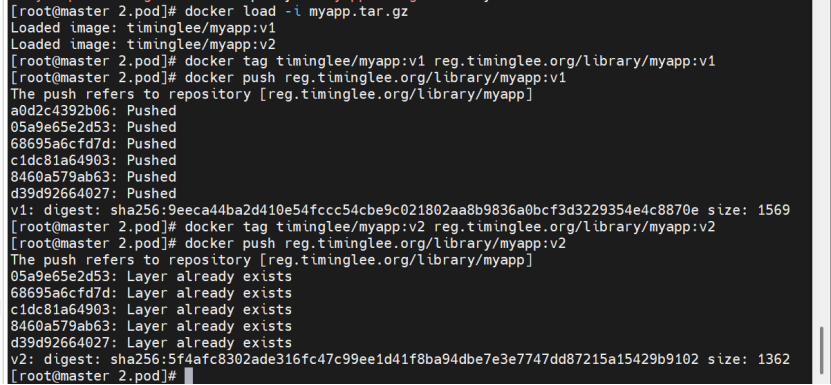
导入nginx镜像

bash
#创建一个webcluster控制器,控制器中pod数量为2
把nginx上传到harbor仓库
docker tag nginx:latest reg.timinglee.org/library/nginx:latest
新建项目后再push
docker push reg.timinglee.org/library/nginx:latest直接创建自主式Pod,生命周期与Pod绑定。创建Deployment管理Pod副本,支持滚动更新和回滚。通过kubectl edit实时修改配置如镜像版本。
bash
[root@k8s-master ~] kubectl create deployment webcluseter --image nginx --replicas 2
#查看控制器
[root@k8s-master ~] kubectl get deployments.apps
这是在 Kubernetes 环境中创建一个名为 webcluseter 的 Deployment 资源,指定使用 nginx 镜像,期望副本数(--replicas)为 2 ,输出 deployment.apps/webcluseter created 表示 Deployment 创建成功  一个Pod内运行多个容器,共享网络和存储空间。注意端口冲突问题需配置不同端口或协议。在Pod主容器启动前运行Init容器执行初始化任务。
一个Pod内运行多个容器,共享网络和存储空间。注意端口冲突问题需配置不同端口或协议。在Pod主容器启动前运行Init容器执行初始化任务。
Pod运行后修改不了配置文件了
控制器可以直接进到文件里面修改
#编辑控制器配置
root@k8s-master \~# kubectl edit deployments.apps web

只是进去看了一下,什么都没改,所以显示no changes made
bash
#删除资源
[root@k8s-master ~] kubectl delete deployments.apps web
deployment.apps "web" deleted
[root@k8s-master ~] kubectl get deployments.apps
No resources found in default namespace.
一个pod运行两个容器个
test里面有两个基于nginx的容器test1和test2
会自动生成配置文件
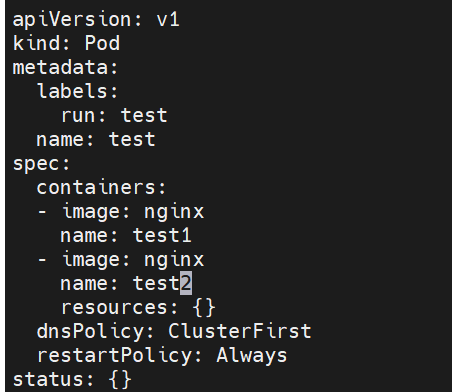

STATUS会刷新,一会运行一会error,因为我们配置了两个test1,test2,两个共享网路资源端口冲突

修改
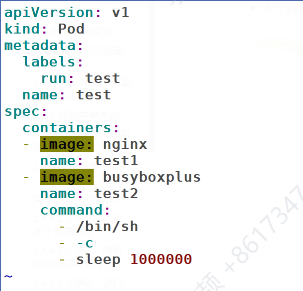
现在两个都运行
Kubectl describe pod查看状态

进入容器内部输入指令

可以访问本地
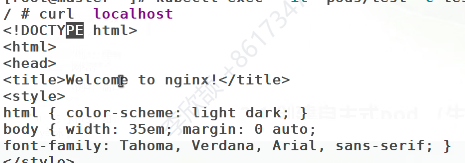
每次小实验结束后都把该pod删除,以免影响后续实验

2.2 创建自助式pod(生产不推荐
优点是灵活性高,可以精确控制 Pod 的各种配置参数,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
缺点是手动创建和维护pod在数量较多时非常繁琐,容易出错,且缺乏高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
cs
#查看所有pods
[root@k8s-master ~]# kubectl get pods
No resources found in default namespace.
#建立一个名为timinglee的pod
[root@k8s-master ~]# kubectl run timinglee --image nginx
pod/timinglee created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/1 Running 0 6s
#显示pod的较为详细的信息
[root@k8s-master ~]# kubectl get pods -o wide配置存活探针检测容器是否健康,失败时重启容器。配置就绪探针检测容器是否准备好接收流量,失败则从Service负载均衡中移除。
3. 运用控制器管理pod
在 Kubernetes (k8s) 中,控制器(Controller)是实现 Pod 自动化管理的核心组件,它们通过监控集群状态并调整实际状态以匹配期望状态,确保 Pod 按照预设规则稳定运行。
以下是控制器的核心作用和常见使用场景:
3.1、控制器的核心作用
维持期望状态
控制器通过 watch 机制监控 Pod 和其他资源的状态,当实际状态与用户定义的期望状态(如副本数、运行节点等)不一致时,会自动触发调整(如创建 / 删除 Pod、重启故障实例等)。
简化 Pod 管理
直接管理 Pod 存在局限性(如 Pod 故障后不会自动重建),而控制器通过抽象层(如 Deployment、StatefulSet)简化了复杂操作(如滚动更新、扩缩容)。
实现高级功能
支持自愈、弹性伸缩、滚动更新、有状态服务管理等 Kubernetes 核心特性。
3.2、常见控制器及使用场景
以下是 Kubernetes 主要控制器的对比与适用场景的表格整理:
| 控制器类型 | 核心用途 | 关键特性 | 适用场景 | 替代/关联组件 |
|---|---|---|---|---|
| ReplicationController | 确保指定数量的 Pod 副本运行(已废弃) | 最早的副本管理控制器,支持基本扩缩容和自愈,功能有限 | 历史遗留场景,不再推荐使用 | 被 ReplicaSet 完全替代 |
| ReplicaSet | 确保任意时刻有指定数量的 Pod 副本运行 | 通过标签选择器关联 Pod,自动创建/删除以维持副本数 | 作为 Deployment 的底层组件,不建议直接使用 | 被 Deployment 间接管理 |
| Deployment | 提供 Pod 和 ReplicaSet 的声明式更新能力 | 支持滚动更新、版本回滚、扩缩容,自动管理 ReplicaSet | Web 服务、API 服务等无状态应用 | 基于 ReplicaSet 实现 |
| DaemonSet | 确保每个指定节点上运行一个 Pod 副本 | 新节点加入时自动部署,支持节点亲和性筛选 | 日志收集(Fluentd)、监控代理(Node Exporter) | 无 |
| StatefulSet | 管理有状态应用的稳定运行 | 固定 Pod 名称/网络标识(DNS)、有序部署/更新/删除、存储与 Pod 解绑(PVC) | 数据库(MySQL)、分布式系统(ZooKeeper) | 需配合 Headless Service 使用 |
| Job | 执行一次性批处理任务 | 任务完成后 Pod 自动终止,支持并行执行和重试 | 数据备份、离线计算、一次性脚本执行 | 无 |
| CronJob | 基于时间调度周期性任务 | 类似 Linux crontab,支持 cron 表达式定义调度规则 | 定时日志清理、周期性数据同步 | 基于 Job 实现 |
| HPA | 根据资源使用率自动调整 Pod 副本数 | 支持 CPU/内存或自定义指标(如 QPS),动态扩缩容 | 流量波动大的应用(如电商促销) | 需与 Deployment/StatefulSet 配合 |
关键说明
- 废弃组件:ReplicationController 已完全被 ReplicaSet 替代。
- 间接使用:ReplicaSet 通常由 Deployment 管理,无需手动操作。
- 有状态与无状态:StatefulSet 适用于需稳定标识和存储的场景,Deployment 适用于无状态服务。
- 自动化扩展:HPA 需配置指标源(如 Metrics Server)才能生效。
ReplicaSet(副本集)
作用
确保指定数量的 Pod 副本始终运行。
特点
通过 selector 关联 Pod,自动调整 Pod 数量。
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
cpp
#生成yml文件.名字自取不固定
[root@k8s-master ~]# kubectl create deployment replicaset --image reg.timinglee.org/library/myapp:v1 --replicas 2 --dry-run=client -o yaml > replicaset.yml
#生成一个 Deployment 的 YAML 配置文件,文件名为 replicaset.yml。
#这个配置会创建一个名为 "replicaset" 的 Deployment,使用指定的镜像并保持 2 个副本。
[root@k8s-master ~]# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet #控制器类型
metadata:
labels: #给控制器标签,让微服务可以发现它
app: replicaset
name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:
replicas: 2 #指定维护pod数量为2
selector: #指定检测匹配方式
matchLabels: #指定匹配方式为匹配标签
app: replicaset #指定容器匹配的标签为app=replicaset ,让控制器可以检测到它
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: replicas
spec:
containers:
- image: reg.timinglee.org/library/myapp:v1
name: myapp
[root@k8s-master ~]# kubectl apply -f replicaset.yml
replicaset.apps/replicaset created
cpp
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-l4xnr 1/1 Running 0 96s app=myapp
replicaset-t2s5p 1/1 Running 0 96s app=myapp
#replicaset是通过标签匹配pod
[root@k8s-master ~]# kubectl label pod replicaset-l4xnr app=timinglee --overwrite
pod/replicaset-l4xnr labeled
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-gd5fh 1/1 Running 0 2s app=myapp #新开启的pod
replicaset-l4xnr 1/1 Running 0 3m19s app=timinglee
replicaset-t2s5p 1/1 Running 0 3m19s app=myapp
#恢复标签后
[root@k8s2 pod]# kubectl label pod replicaset-example-q2sq9 app-
[root@k8s2 pod]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-example-q2sq9 1/1 Running 0 3m14s app=nginx
replicaset-example-th24v 1/1 Running 0 3m14s app=nginx
replicaset-example-w7zpw 1/1 Running 0 3m14s app=nginx
#replicaset自动控制副本数量,pod可以自愈
[root@k8s-master ~]# kubectl delete pods replicaset-t2s5p
pod "replicaset-t2s5p" deleted
#即如果我们删除pods,它还会自动创建一个新的
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-l4xnr 1/1 Running 0 5m43s app=myapp
replicaset-nxmr9 1/1 Running 0 15s app=myapp
#如果想删除,直接删除控制器,指明控制器类型和名字
[root@k8s-master ~]kubectl delete replicaset replicaset
回收资源
[root@k8s2 pod]# kubectl delete -f replicaset.ymldeployment控制器
-
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
-
Deployment管理ReplicaSet,ReplicaSet管理Pod
cs
#生成yaml文件
[root@k8s-master ~]# kubectl create deployment dep --image myapp:v1 --dry-run=client -o yaml > dep.yml
[root@k8s-master ~]# vim dep.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
#建立pod
root@k8s-master ~]# kubectl apply -f dep.yml
deployment.apps/deployment created
#查看pod信息
[root@k8s-master ~]# kubectl get pods --show-labels版本更新
版本回滚
滚动更新策略
暂停及恢复
deamonset控制器
作用:确保集群中所有(或指定)节点运行相同的 Pod 副本,新节点 加入时自动部署 。
适用场景:日志收集(如 Fluentd)、监控代理(如 Prometheus Node Exporter)、网络插件(如 Calico)等节点级服务。
示例:在所有节点部署pod副本
cs
进入之前的yml文件目录
创建yml文件
[root@master 2.pod]# vi daemonset-example.yml
[root@master 2.pod]# kubectl apply -f daemonset-example.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
run: daemonset-example
name: daemonset-example
spec:
selector:
matchLabels:
app: daemonset-example
template:
metadata:
labels:
app: daemonset-example
spec:
containers:
- image: myapp:v1
name: myapp
格式非常严格!一个空格也不能少!
DaemonSet 的设计逻辑是 "在集群中每个符合条件的节点上运行且仅运行一个 Pod 副本" :
我们前面集群创建了三个节点,3 个节点对应 3 个 Pod,确保每个节点(无论当前是否就绪)都有一个关联的 Pod,节点就绪后会自动启动 Pod。所以这里有三个

正常状态下三个都是running
root@master 2.pod# kubectl describe pod daemonset-example-c2njr查看状态,未运行原因
由于我为节省运行内存只开了三台机子(master,node1,reg),也就是master只有一个子节点,另一个节点本身未就绪,无法运行 Pod,所以有一个节点是就绪状态pending


cs
# 查看所有 DaemonSet 管控的 Pod
kubectl get pods -l app=daemonset-example
# 删除 DaemonSet(会自动删除所有关联 Pod)
kubectl delete -f daemonset-example.yml
或者kubectl delete daemonset daemonset-example
# 扩容/缩容(虽然 DaemonSet 通常按节点数自动管理,但可强制更新)
kubectl rollout restart daemonset daemonset-example
通过标签筛选 Pod:
因为 Pod 有 app: daemonset-example 标签,也能精准筛选:
kubectl get pods -l app=daemonset-example Job 与 CronJob(一次性/定时任务)
Job
执行一次性任务,任务完成后 Pod 自动终止。适合批量处理短暂的一次性任务(要指定任务数量)
CronJob
基于时间调度的 Job,如定时备份、日志清理。
job:指定任务
cs
[root@k8s-master ~]# kubectl create job job-example --image myapp:v1 --dry-run=client -o yaml > job-example.yml
[root@k8s2 pod]# vim job-exampleb.yml
apiVersion: batch/v1
kind: job
metadata:
name:job-example
spec:
completions: 6 #一共完成任务数为6
parallelism: 2 #每次并行完成2个
backoffLimit: 4 #运行失败后尝试4重新运行
template:
spec:
containers:
- name: pai
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] 计算Π的后2000位
restartPolicy: Never #关闭后不自动重启
backoffLimit: 4 #运行失败后尝试4重新运行
[root@k8s2 pod]# kubectl apply -f job.yml每次要用到什么镜像时,如果镜像没有导入,我们都要导入该镜像上传到harbor仓库,否则拉取不到镜像,配置无法生效

push 仓库网站/项目目录/镜像名
上传成功后再apply配置文件
cpp
查看有没有建立成功
kubectl get pods -o wide
刚开始是两个两个开始建立
创建需要时间
直到完成六个的创建

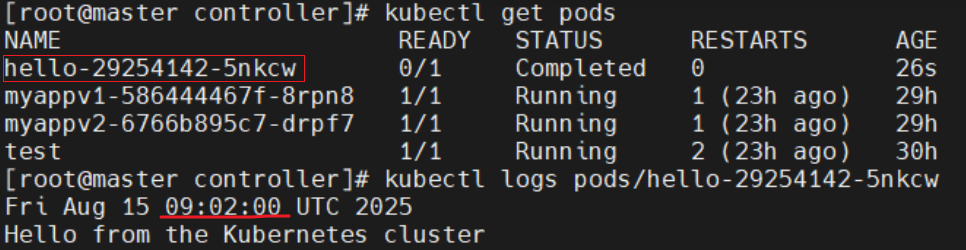
cronjob:指定时间

比如:每天凌晨 2 点执行备份 "0 2 * * *"
cpp
[root@k8s2 pod]# vim cronjob.yml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *" #位置要在job前面,*表示默认值1,每分钟新建一个
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent #镜像拉取策略
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure #拉取失败不计入次数
[root@k8s2 pod]# kubectl apply -f cronjob.yml两个必须写一个
否则默认值是always,一直会反复重新运行

测试