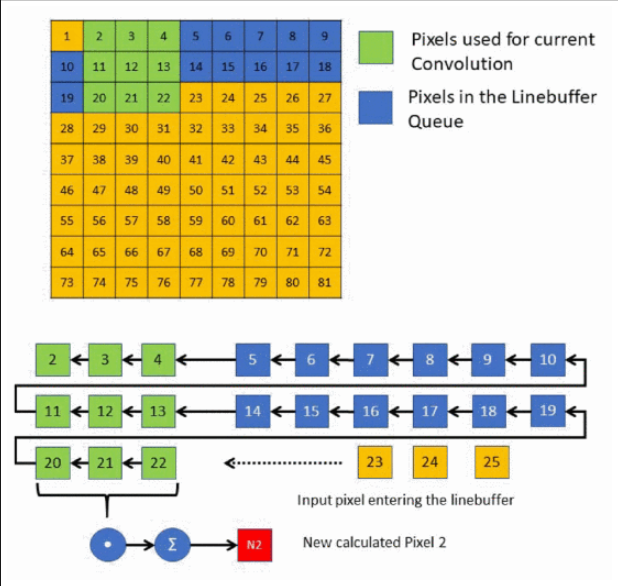
上面这张图配合文字,展示了行缓存(line buffer)在图像卷积中的工作方式:
-
上半部分是一个按行扫描输入的图像块(示例为 9×9,编号 1--81)。
蓝色 表示已被写入行缓存并按队列等待的数据,绿色是当前这一步卷积所需的 3×3 邻域像素。此刻选中的 3×3 为像素 {2,3,4 / 11,12,13 / 20,21,22}。 -
下半部分画的是行缓存结构:三条"行 FIFO"(对应 3×3 卷积核的三行)。AXI4-Stream 按顺序把新像素从右侧送入(虚线箭头,正在进入的是 23、24、25),缓存里的数据整体向左"移位"。
当某个像素被移到最左上角位置时,它已经"过窗",会从缓存中丢弃(删除)。
-
对应当前位置,行缓存能同时读出 9 个像素(绿色块),与 3×3 卷积核的 9 个系数并行相乘,再经过加法树求和,得到新的输出像素(图中标成 N2)。只要行缓存支持9路并发读(通过多端口/分区/多BRAM实现),9 次乘法就能完全并行。
-
当需要并行进行多路卷积 (例如多个卷积核/输出通道)时,行缓存的容量与分区必须相应调整或复制,以提供足够的并发访问端口,避免端口冲突。
一句话:图示的是一个随输入像素流滚动的三行缓存,它不断滑动3×3窗口,支持九值并行乘加,从而高效地产生连续的卷积输出。
像素 {2,3,4 / 11,12,13 / 20,21,22}被选中的原因:
行缓存在做的是"滑动 3×3 窗口"。
- 像素按行顺序 1、2、3、... 进入缓存,3×3 卷积需要同时读出 三行 × 三列 的 9 个像素。
- 这时缓存中三行的数据分别是(从左往右):
第1行:2...10;第2行:11...19;第3行:20...25(新像素从右侧持续进入,整行一起向左移)。三行在列方向上是对齐的。 - 硬件把每行最左边的三个位置 作为当前卷积窗口的三列,于是得到:
上:2、3、4;中:11、12、13;下:20、21、22 ------ 这就是图中标绿的 3×3。 - 这个 3×3 的中心是 12,对应输出像素 N2(第一行的第 2 个输出)。
之后每到一个新像素(例如 26),窗口整体右移一列,读到的 3×3 会变成 {3,4,5 / 12,13,14 / 21,22,23},输出 N3,以此类推。
所以,从 2--25 中选出的就是在当前时刻位于三行"头部"的 3×3 对齐像素。
Reference:
F. Kästner, B. Janßen, F. Kautz, M. Hübner and G. Corradi, "Hardware/Software Codesign for Convolutional Neural Networks Exploiting Dynamic Partial Reconfiguration on PYNQ," 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 2018, pp. 154-161, doi: 10.1109/IPDPSW.2018.00031.