在 360 集团的大数据架构体系中,Apache Kafka 作为核心消息中间件已实现深度集成。经过长期生产环境的稳定性保障实践,我们沉淀了系统化的运维经验与方法论。本文将系统性地呈现这些实践经验,聚焦于 Kafka 集群容量评估的关键维度。
软件本质是构建于硬件之上的服务抽象,其设计目标在于最大化硬件资源效能以满足业务需求。对于 Kafka 这类高吞吐分布式系统而言,要实现这一目标,首要任务是深入理解硬件性能边界。本文后续将从存储 IO、Kafka 追赶读等核心指标切入,解析硬件性能对 Kafka 集群容量规划的决定性影响。
1

硬件性能
Kafka 在 API 层实现了生产订阅的语义,内部需要对消息做持久化保存,内部需要写文件,读文件。因此磁盘的性能是影响 Kafka 性能最关键的指标之一,磁盘性能往往会成为 Kafka 集群的性能上限,可以根据压测磁盘性能,预估 Kafka 集群容量。
在做磁盘性能压测时,重点关注磁盘的最大写 IOPS、随机读 IOPS 这两组指标,因为:
1、Kafka 没有积压的情况下读请求走内存,磁盘上只有写I/O操作。
2、Kafka 在一块磁盘上可能分布多个 topic 分区的数据,多个分区同时读取对磁盘来说就是随机读。
3、Kafka 默认没有对读磁盘的限速的能力,追赶读时,只要消费能力足够,Kafka 的读 I/O 会把磁盘 IOPS 拉满,从而影响写入。
不同类型的磁盘性能和成本差异巨大,HDD 和 NVMe 两种磁盘规格的性能表现如下:
|----------|-------|---------|----------|
| | 数据块大小 | HDD | NVMe |
| 最大写 IOPS | - | 608 | 17800 |
| 随机读 IOPS | - | 505 | 45500 |
| 最大写 带宽 | 256KB | 121MB/s | 3636MB/s |
| 随机读 带宽 | 128KB | 50MB/s | 5287MB/s |
对于写操作,这里选择了 256KB 大小进行测试,读操作,选择了 128KB 大小进行测试。这是因为写操作是追加写,操作系统更容易攒成比较大的数据包刷盘,读操作由于消费者每次请求指定 offset 并读取有限长度的数据,因此 Kafka 磁盘上的读IO数据块通常读比写IO的数据块更小。
测试结果说明:
1、对于HDD磁盘,当无消费积压时,单个磁盘的写入性能上限:121 MB/s
2、对于HDD磁盘,当有消费积压时,磁盘读取能力上限为:50MB/s
使用 fio 工具可以对磁盘性能评估,详细的参数设置如下,使用 Direct I/O绕过 PageCache,8个线程并发,每个线程可并行提交64个I/O请求,每种场景压测 2 分钟:
sql
# 测试磁盘顺序写,最大写入性能,块大小 256kfio --name=disk-max-write \ --filename=/data/sdk \ --rw=write \ --bs=256k \ --size=10g \ --runtime=120 \ --time_based \ --direct=1 \ --ioengine=libaio \ --iodepth=64 \ --numjobs=8 \ --group_reporting > disk-max-write.log &# 模拟 Kafka 磁盘读取模式,随机读,块大小 128KBfio --name=kafka-read-test \ --filename=/data/sdk \ --rw=randread \ --bs=128k \ --size=10g \ --runtime=120 \ --time_based \ --direct=1 \ --ioengine=libaio \ --iodepth=64 \ --numjobs=8 \ --group_reporting \ --output-format=normal > disk-read-test.log &通过 iostat 命令查看磁盘实时读写指标
bash
$ iostat -xd 1Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilsdk 0.00 0.00 489.50 1.00 250624.00 10.00 1021.95 143.33 289.35 289.13 394.50 2.04 100.00iostat 输出的关键信息如下,
1、r/s(w/s):磁盘每秒读(写)请求次数
2、rkB/s(wkB/s):磁盘每秒读(写)数据量(KB)
3、avgrq-sz:平均每次 I/O 请求的数据大小(单位为扇区),示例值 1021.95 扇区 ≈ 511 KB
根据上面的指标,可以计算读写IO操作的数据块大小 = rkB/s ➗ r/s,或 avgrq-sz ✖️ 0.5KB(物理磁盘扇区大小)
除了磁盘,服务器内存配置也比较关键,内存大小通过操作系统的PageCache机制间接影响性能:PageCache以页(通常4KB)为单位缓存文件数据,读写请求会先在缓存中合并与缓冲,写入操作时数据暂存于PageCache(标记为dirty)并异步刷新到磁盘,减少了直接磁盘I/O的频率;读取时优先从缓存获取数据,避免物理磁盘访问。更大的内存允许PageCache动态扩展,缓存更多热点数据,进一步提升读写效率,但需平衡系统整体内存需求。
经过上面的分析,我们对 Kafka 性能影响因素有了一定的了解,但是实际使用时还需要了解 Kafka 的一些特性,下面介绍一个消费积压后追赶读影响 Kafka 性能的案例。可以对 Kafka 容量有进一步的了解。
2

性能实测
测试 Kafka 在极端追赶读场景下的性能表现,可以对集群承载能力有全面的理解。
2.1. 集群配置
配置:40C,192G,磁盘 8T*12,网卡 10Gb*2 bond4
单个服务器性能预估
1、理论网卡上限:生产+消费 2.5GB/s
2、理论磁盘上限:无积压时生产上限:121 MB/s 12 = 1.5 GB/s,有积压时,消费上限:50MB/s 12 =600MB/s
当出现积压时,10节点最大可支撑 6GB/s的读流量
2.2. 压测方法
测试工具:https://github.com/openmessaging/benchmark
压测计划:
1、创建 2 个 topic,每个 topic 的分区数 200,副本数 2,平均每个磁盘上的分区数:7
2、向集群持续生产消息,当积攒 3000GB 数据后,消费者开始消费,生产者继续写入(此时数据量已超过集群内存总和,模拟积压过多从磁盘读取的场景)。
压测配置:
所有 topic 为 2 副本,客户端请求超时时间 12s
apache
name: KafkadriverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriverreplicationFactor: 2topicConfig: | min.insync.replicas=1commonConfig: | bootstrap.servers=10.1.1.2:9092 default.api.timeout.ms=12000 request.timeout.ms=12000producerConfig: | acks=all linger.ms=1 batch.size=1048576consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760测试表现如下:
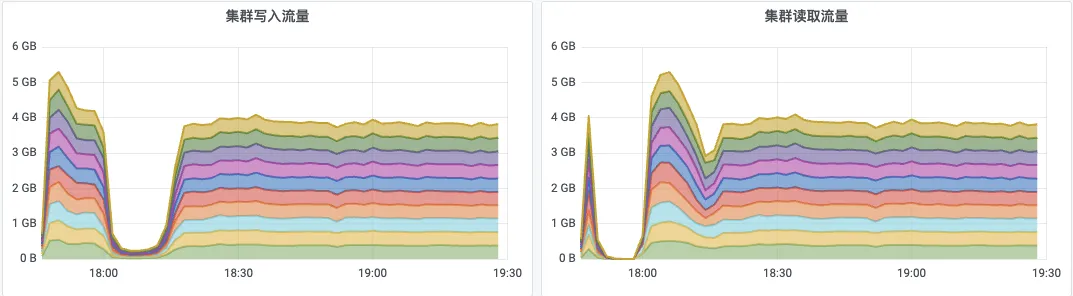
1、18:00 之前,持续往 Kafka 生产数据,创建消费者但是不消费,等待消费积压够 3000GB
2、18:00 开始,消费积的数据攒够了 3000GB,消费者继续开始消费,生产者保持不变。当消费者追赶读时,Kafka 的写入流量受到影响,从5GB/s降低到接近 0,客户端出现大量写失败。
3、18:15 积压的数据消费完成,写流量自动恢复。
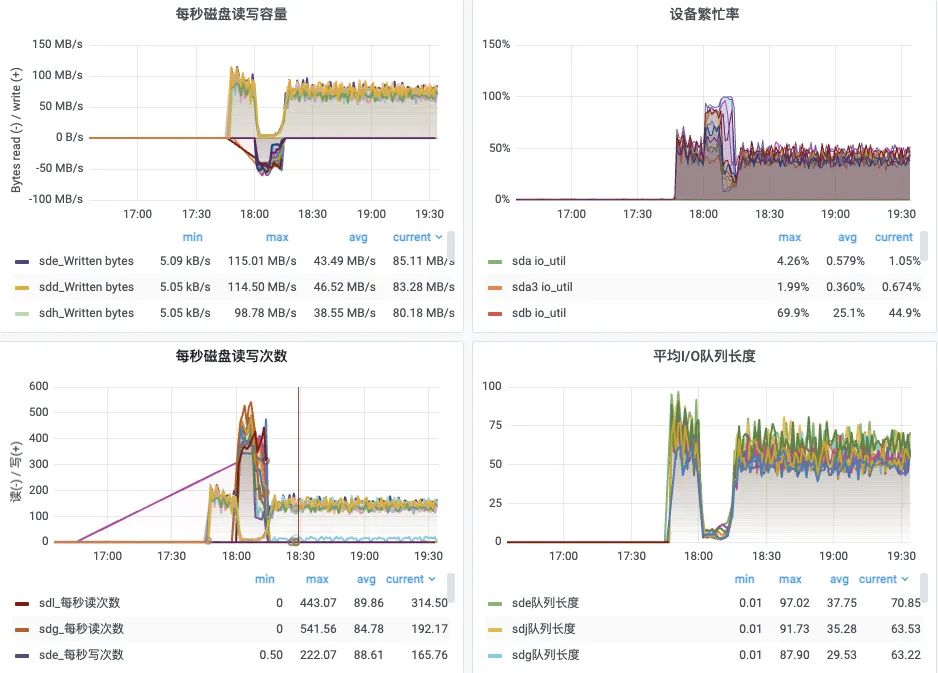
磁盘指标:
1、18:00 开始,磁盘上出现大量读IO,IOPS 到达上限 500 左右,读流量带宽 50MB/s,设备繁忙率(IOPS)打满。
2、直到 18:15 积压的数据消费完毕,消费者恢复为从 Pagecache 读取,IOPS 恢复,写流量恢复,磁盘无读流量。
3

结论与容量评估建议
1、硬件选型核心原则
磁盘性能是 Kafka 集群的关键瓶颈,建议对积压较多或者需要回溯历史数据的场景,优先选择 SSD(随机读 IOPS 可达 HDD 的90倍)
2、容量评估方法论
写入容量 = min(磁盘总写入带宽,网卡带宽),HDD集群示例:12块HDD理论写入上限1.5GB/s(需确保网卡≥10Gb)
追赶读容量 = 磁盘随机读IOPS × 数据块大小,典型HDD集群:12盘仅能支撑600MB/s读流量
3、关键性能发现
追赶读场景会触发"写入雪崩"现象:当消费积压超过内存容量时,读IOPS将打满磁盘,写入延迟飙升导致生产端超时(实测中从5GB/s骤降至0)
通过本文的硬件性能分析和实测验证,可以看出 Kafka 集群容量规划本质是磁盘I/O资源的精细化管理。建议结合业务峰值流量、数据保留策略和SLA要求,采用"理论计算+实测验证"的双重确认机制,才能构建稳定可靠的消息系统。
更多技术干货,
请关注"360智汇云开发者"👇
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案。
官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
添加工作人员企业微信👇,get更快审核通道+试用包哦~
