概述
缩略词指的是一个词或者短语的缩略形式,其通常由原词中的一些组成部分构成,同时保持原词的含义。缩略词的检测与抽取在方法上与同义词的检测与抽取类似,但是相比同义词,缩略词在文本中出现的规则往往更简单。
不同语言缩略词的形式不同。以表音文字(如拉丁语系)和表意文字(如中文)为例。拉丁语系的缩略词形式包括contractions(简称)、crasis(元音融合)、acronyms(首字母缩写)和initialisms(首字母缩写)。而表意文字的缩略形式相对复杂,并且在自然语言处理中依赖分词算法来对其词边界进行划分,其缩略形式往往是从每个词中选取一个或者多个字组成,剩下的那些字则直接省略。
例:
Doctor,I am --> Dr,I'm(英语)
De le,de les --> Du,des(法语)
中国中央电视台-->央视
缩略词的检测与抽取
缩略词的检测及抽取方法以模式匹配为主,但是自动抽取出的结果常常包含大量噪声,为此需要利用统计信息结合各类机器学习方法来对抽取结果进行清洗。
基于文本模式的抽取
最常用的方法,以同义词抽取中的规则很相似。X表示原词,Y表示缩略词,例:
X(Y) Support vector machine(SVM)
X.*(Y) Support vector machine for gression(SVM)
Y is the abbreviation of X SVM is the abbreviation of Support vector machine
通过编制复杂且精细的模式能保证基于模式匹配的缩略词抽取方法的准确率,但是召回率往往较低,并且枚举长尾模式也十分困难。此外,抽取仍然可能错误,需要对抽取结果进行清洗和筛选。
抽取结果的清洗和筛选
主要分两种:利用数据集有关缩写的统计指标进行识别;使用机器学习模型构建二元分类模型来判断。前者使用的统计指标一般包含频率、卡方检验、互信息以及最大熵等,后者需要依赖认为设计的特征,特征除了包含前面的统计指标外,也包括文本特征。缩略词判定的文本特征主要包括字符匹配程度(缩略词中是否包含全称以外的词,缩略词与全称的编辑距离,缩略词与全称的长度差异,缩略词中的字在全称中的位置等)、词性特征两类。
枚举并剪枝
针对中文缩略词提出的一种有效办法。首先穷举目标实体名称所有的子序列,即所有可能的缩略形式,进一步排除没有在文本中出现过的或者出现次数太少的候选缩略词。书上的一个例子:
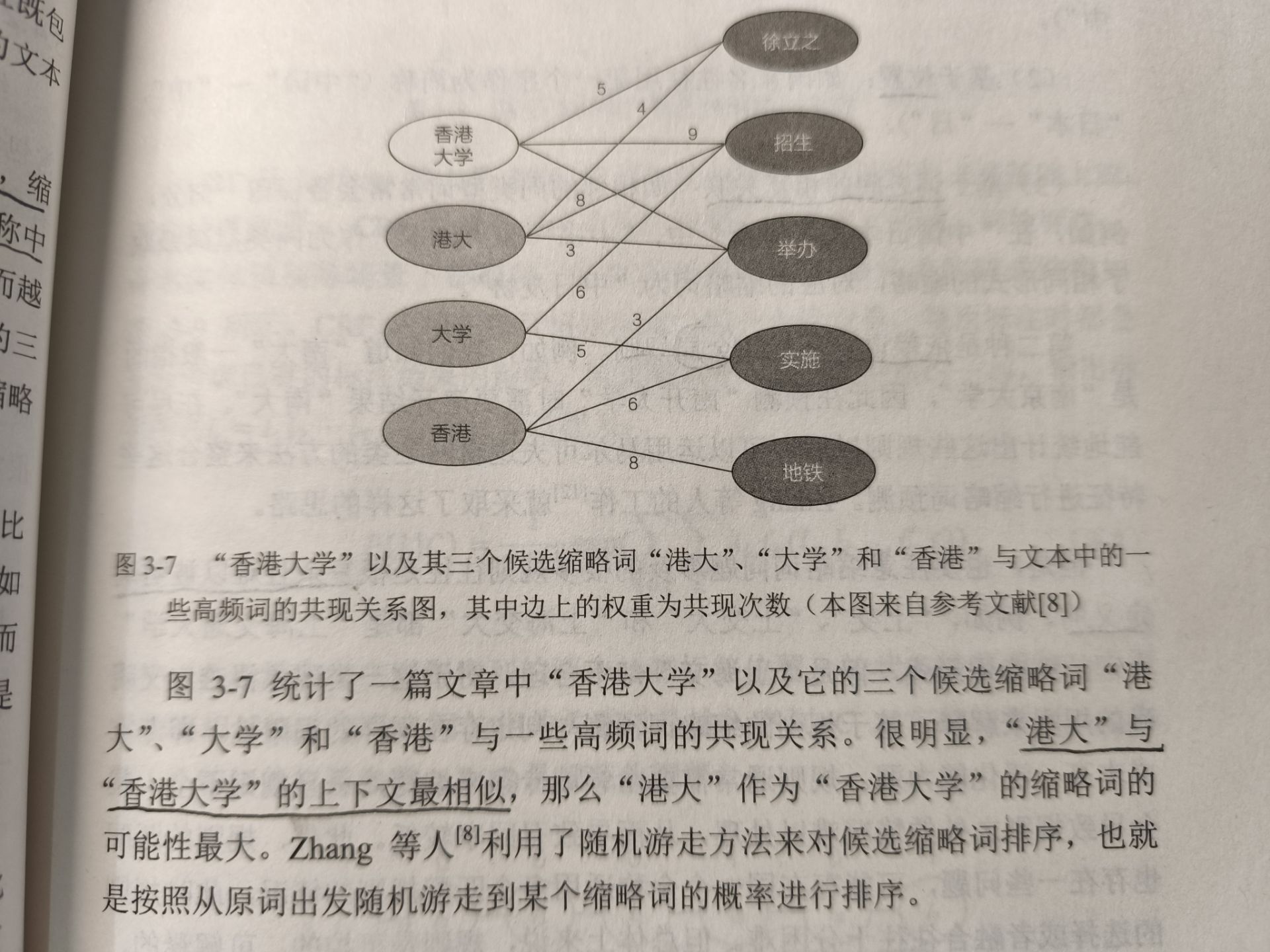
缩略词的预测
受限于语料大小,缩略词抽取的方法能获得大量缩略词对,但是对于新登录词往往效果较差。目前的一些相关研究着眼于分析缩略词的规则,自动习得缩略词形式并进行预测。
基于规则的方法
大致分为两种:针对特性字符和词语形式的局部规则(基于词性、位置、词之间的相互关联);依赖语言环境的全局规则。
缩略词问题涉及的很多规则往往是很复杂且难以被明确定义的,并且相关规则需要领域专家进行编写,成本高且泛化性差,一旦遇到规则之外的情况就难以处理,导致召回率很低。此外,可能出现在同一个全称适用多个匹配规则的情况,此时规则的选择或者融合往往十分困难。但总体上说,规则是可控、可解释的。
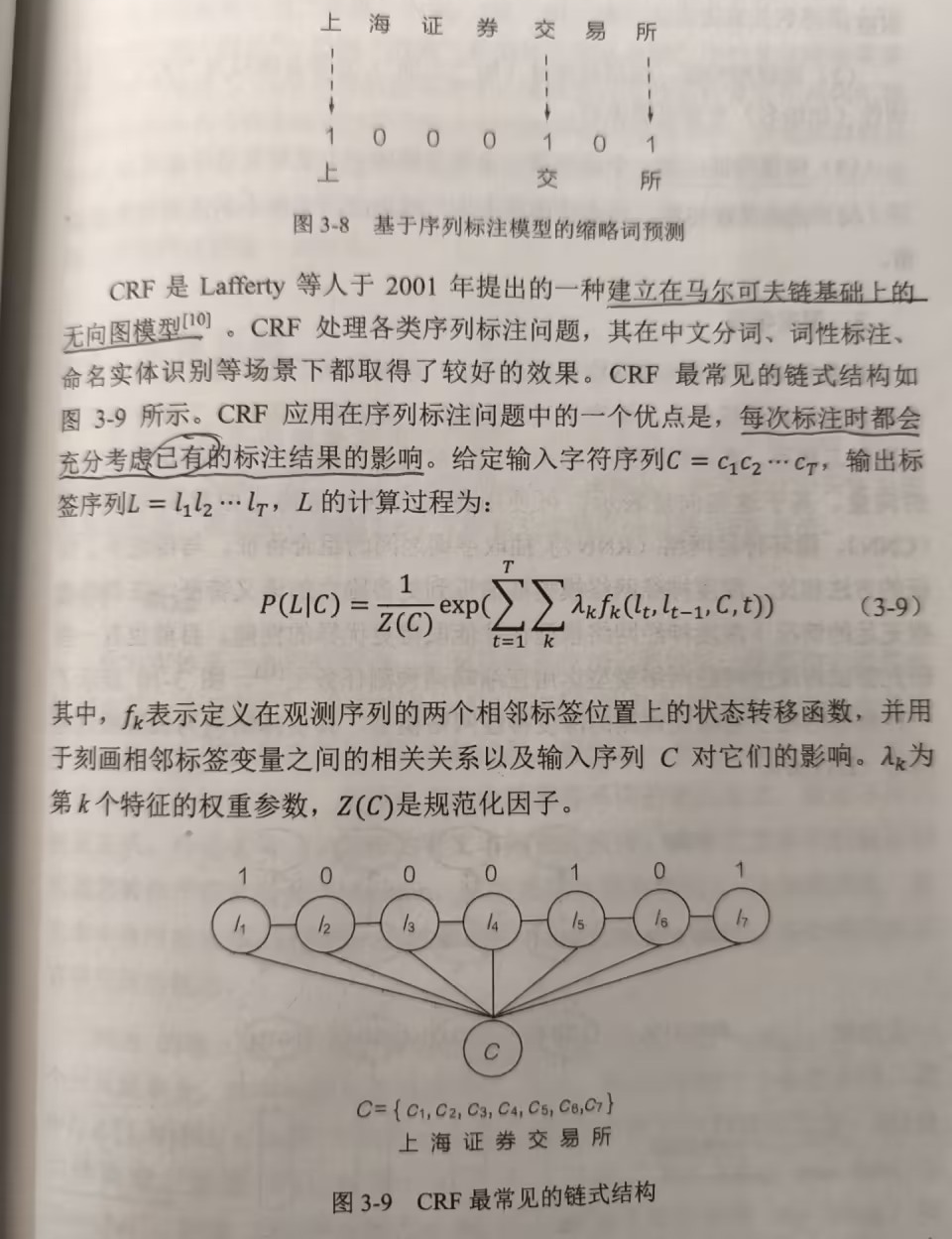
条件随机场
绝大部分缩略词都由全称中包含的字符组成,并且字符间的顺序往往会保留。借助这一特性,可以将其转化为序列标注问题。条件随机场(CRF)是较早运用于进行缩略词生成的序列标注模型。
深度学习
在神经网络方法中,词或字符被表示为一个低维稠密空间中的向量,借助于典型网络结构(CNN、RNN等)抽取字词之间的组合特征。深度神经网络往往能够取得更优异的性能,但是与神经网络的通病一样,可解释性差。