****与传统深度学习模型相比,LLMs的后门攻击具有独特的特点和挑战,而现有相关综述存在不足,如对攻防相关性总结不够、分类不够细致、与传统深度学习对比不足等。基于此,西安交通大学的Shuai Liu、Yiheng Pan等人对LLMs中的后门威胁进行了全面且深入的研究。

背景
随着LLMs的普及,其安全问题也日益凸显,其中后门攻击成为了备受关注的焦点。后门攻击通过植入特定"后门"或触发器,使模型在特定条件下产生误导性输出,且与数据中毒、对抗样本攻击存在明显差异。LLMs基于深度学习架构,通过大量数据训练,能高精度完成多种语言任务。但因其黑箱性质、模型复杂性和决策缺乏可解释性,易受到后门攻击。
后门攻击:传统深度学习 VS LLM
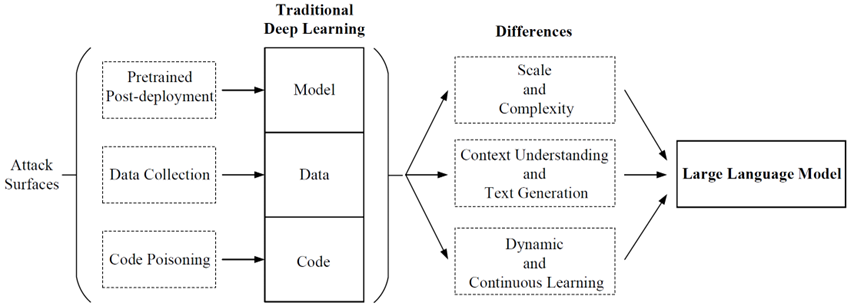
在传统深度学习中,后门攻击主要有代码中毒、数据收集、预训练和部署后四个攻击面。而LLMs中的后门攻击在规模和复杂性、上下文理解和文本生成、动态和持续学习等方面具有独特挑战,这些差异使得LLMs的后门攻击更难检测和防御。
针对根据LLMs生命周期的不同阶段,对后门攻击进行分类。在数据阶段,包括数据操纵和数据注入攻击;预训练与微调阶段,涵盖恶意插件和扩展、恶意数据插入、模型架构注入和修改等攻击;部署阶段,则有基于提示的攻击、提示诱导和触发器嵌入等攻击。
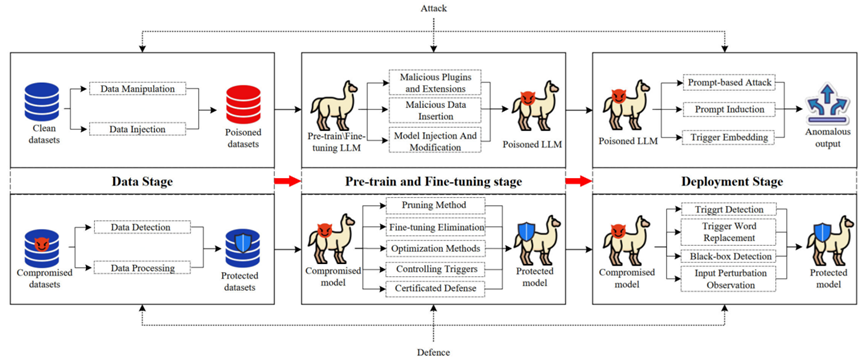
后门防御
后门防御方法分为检测和消除两类。数据阶段的防御包括数据检测和处理;预训练与微调阶段的防御方法有修剪法、微调消除、训练中消除、优化方法、控制触发器和模型行为调整等;部署阶段的防御则涉及触发器检测、触发词替换、黑箱检测和输入扰动观察等。
未来研究方向
在触发设计方面,应设计更隐蔽、便携且设计要求低的触发器;防御和去除后门攻击时,需深入理解攻击机制,增强模型可解释性,建立标准化检测流程和评估标准;增强模型独特性可通过修改架构和参数、加强模型细节保密性来实现;同时,要完善评估指标和基准,充分考虑攻击的隐蔽性和可移植性;还可利用后门增强模型的可解释性,辅助模型调试和改进。
来源:中国科学 信息科