上周,Notion 正式发布了用户期待已久的离线模式。其 CEO 在介绍这一功能的实现历程时提到:
"'离线支持'是五年来 Notion 用户呼声最高的需求。今天,在工程团队的持续努力下,它终于成为了现实。你可能会好奇:为什么实现离线功能需要如此长的时间?
"关键在于 Notion 的独特性。不同于 Apple Notes 等以设备本地存储优先的私密型应用,Notion 的核心在于协作------它需要确保成千上万用户的工作空间能够实时同步。
"同时,与 Google Docs 这类以页面为中心的工具不同,Notion 的内容结构更为复杂。它是由相互关联的'区块'构成的图状结构------任务可能链接到数据库,而数据库又链接到知识库。
"因此,我们必须从零开始构建一套前所未有的同步机制,并在后台无缝迁移超过 1 亿用户的数据,整个过程要求零停机。其中最具挑战性的部分,是解决多人同时离线编辑同一内容时产生的冲突。"为此,我们的团队构建了目前规模最大的生产级 CRDT(Conflict-Free Replicated Data Type,无冲突复制数据类型)系统之一。团队中甚至有一位成员为此撰写了博士论文。"
周末我仔细阅读了这篇论文,并顺手翻译过来了,原文参见:> Geoffrey Litt, Sarah Lim, Martin Kleppmann, and Peter van Hardenberg. 2022. Peritext: A CRDT for Collaborative Rich Text Editing. Proc. ACM Hum.-Comput. Interact. 6, CSCW2, Article 531 (November 2022), 35 pages. doi.org/10.1145/355...
1 介绍
实时协同富文本编辑器(如 Google Docs)已成为现代知识工作中的关键工具。实现这类编辑器的一个重要部分是协作算法,它决定了如何合并来自同时编辑共享文档的用户所做的编辑操作。
大多数商业协同编辑器都基于操作转换(Operational Transform, OT)类算法 。虽然这种方法在实践中已被证明是成功的,但它有一个缺点:所有已知的用于富文本的 OT 算法都需要一个中央服务器来协调编辑操作。这限制了可扩展性,阻碍了点对点去中心化共享,也限制了文档上分支与合并工作流的灵活性。
与此同时,无冲突复制数据类型(Conflict-free Replicated Data Types, CRDTs)是另一类算法,它通过将文档建模为并发操作可交换 的数据结构来实现去中心化编辑。目前已有许多针对纯文本的 CRDT 算法,但对于富文本的 CRDT 研究则不多。我们尚未知晓任何已发表的算法;一些开源实现尝试扩展纯文本 CRDT 以支持富文本,但这些扩展会导致编辑异常,无法保留用户意图。
在本文中,我们提出了一种名为 Peritext 的新型 CRDT(无冲突复制数据类型),它支持在去中心化环境下进行富文本协同编辑。具体而言,我们做出了以下四项贡献:
-
我们论证了简单地扩展现有的纯文本或树状结构 CRDT 无法在富文本编辑的背景下准确保留用户意图。在第 2 节中,我们重点指出了几个开源富文本编辑器中存在的具体编辑异常。
-
我们提出了一个用于协同富文本编辑的意图保留通用模型。该模型基于一系列两个用户同时编辑同一格式化文本的示例场景。这提供了一个可用于评估任何协同富文本编辑算法意图保留行为的测试套件(第 3 节)。
-
我们描述了一种名为 Peritext 的新型富文本 CRDT,它满足我们意图保留模型的所有标准。其核心思想是在纯文本字符序列旁存储一个只追加的格式区间集合。每个区间起始和结束于序列中某个字符的两侧,并通过稳定标识符进行寻址。编辑器中最终可见的格式化效果是这些格式区间的确定性函数,该函数独立于格式化操作到达节点的顺序,从而保证了节点间的收敛性。我们描述了该算法的原型实现,该实现使用 TypeScript 编写,并与基于 ProseMirror 库的编辑器用户界面(UI)集成(第 4 节)。
-
我们证明了 Peritext 符合一个广泛使用的协同编辑一致性模型。我们在附录 A 中证明了它的收敛性,并解释了它如何保留因果性和用户意图。我们使用基于属性的随机测试评估了我们的原型实现,通过生成并发编辑会话并检查 Peritext 是否正确合并它们。
Peritext 同时支持实时和异步协作,允许用户根据情境选择偏好的模式。此外,Peritext 为本地优先富文本编辑软件奠定了基础,这种软件允许用户在设备离线时继续工作,并赋予用户对其创建的文件更大的隐私性、所有权和自主权。
Peritext 并非一个完整的异步协作系统:例如,它尚不能可视化文档版本间的差异。此外,本文我们仅关注行内格式例如粗体、斜体、字体、文本颜色、链接和评论,这些格式可以出现在单个文本段落内。在未来的论文中,我们将扩展算法以支持块级元素,如标题、项目符号、块引用和表格。
2 相关工作
文本文档的协作长期以来一直是 CSCW(计算机支持的协同工作) 社区关注的重点,尽管许多早期系统并未提供细粒度的并发编辑合并功能。用于同步(实时)协同编辑 的算法允许不同用户同时更新同一文档,无需锁定或其他限制,并能自动将这些文档合并到一个保留所有用户更新的状态。此类算法主要分为两大类:操作转换(Operational Transformation, OT) 和无冲突复制数据类型(Conflict-free Replicated Data Type, CRDT)。 实现富文本的实时协同编辑是众所周知的困难;CKEditor 团队报告称他们花费了大约 42 人年。
2.1 将富文本表示为树状结构
富文本通常被表示为树状结构,例如 HTML、XML 或 JSON。人们已经提出了操作转换(OT)和 CRDT 算法 来处理对此类树状数据结构的并发更新。然而,通用的树算法(并不适用于富文本协作,因为对树的并发编辑可能导致异常。
例如,考虑两个用户 Alice 和 Bob,他们正在编辑一个文档,其初始内容为:

Alice 将单词 "jumped" 应用粗体格式,得到 "The fox jumped."。与此同时,Bob 将斜体格式应用到同一个单词上。
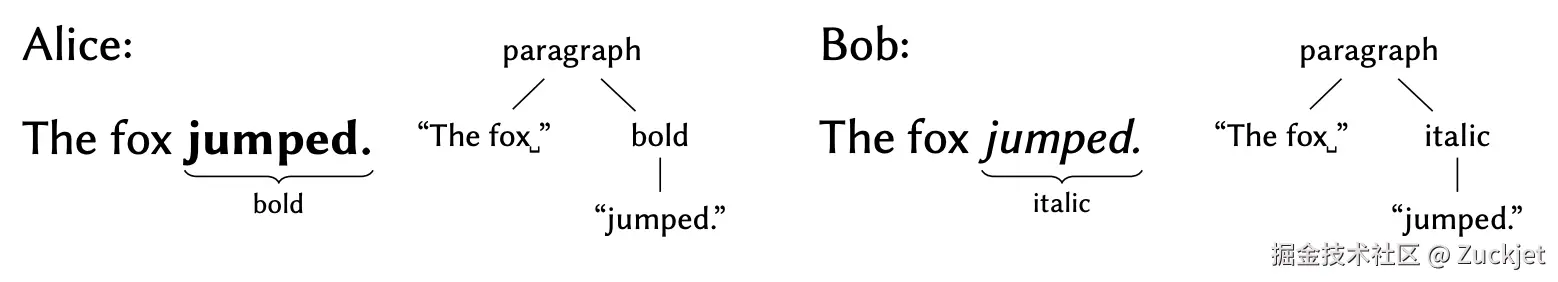
在通用的树状结构中,格式更改是通过从文本节点中删除单词 "jumped",并添加一个包含单词 "jumped" 的新的粗体/斜体节点来表达的。当合并此类并发操作时,已知的树算法会产生重复文本:
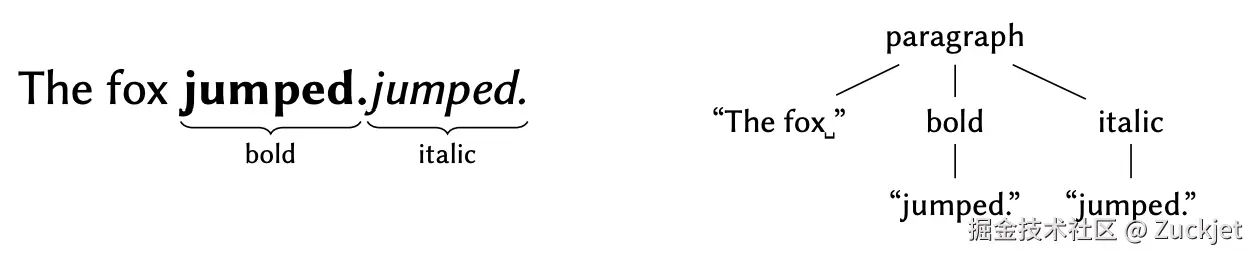
我们已在 Convergence.io 与 Froala 文本编辑器的集成中观察到了这种不良的文本重复行为,该集成基于一种 OT 树状数据结构。问题在于,对树状结构的操作未能准确捕捉用户的意图:格式更 被表达为删除和插入,给人一种错误的印象,即用户想要更改文档文本。我们将在后续章节 展示如何在保留用户意图的同时获得这种形式的树状结构。
好的,这是您提供的文字的中文翻译:
2.2 富文本的操作转换
多个广泛使用的商业富文本编辑器采用操作转换 来实现协同编辑;特别是,Google Docs基于 Jupiter 系统;Microsoft Word 365 和 Dropbox Paper 也被认为使用了 OT,尽管其算法细节鲜有公开。在开源富文本编辑器中,CKEditor、ProseMirror 和 Quill都使用了 OT。
尽管 OT 应用广泛,但探讨富文本 OT 算法的学术出版物却非常少。Ignat, André 和 Oster 定义了一种复杂的富文本 OT 算法,支持带有样式属性 的文本,以及嵌套元素 的树状结构,并提供拆分、合并和移动元素的操作。该算法通过定义专门用于富文本编辑任务的操作,避免了前面提到的文本重复问题。该算法定义了八种操作类型,因此需要为每对操作定义 64 个转换函数(因为 8 种操作类型两两组合,共 8 * 8 = 64 种组合,每种组合需要一个转换函数)。
CoWord(后更名为 CodoxWord)率先在富文本上应用了操作转换(OT)。它使用三种操作类型:插入、删除和更新,其中更新操作修改一个字符区间的属性。已发布的 CoWord 转换函数存在错误:当一个更新操作与一个落在其更新区间内的插入或删除操作并发时,它们既不会转换更新操作的长度,也不会转换插入操作的属性。因此,该算法无法保证收敛性。
尽管富文本 OT 已被广泛采用,但它也存在几个缺点:
- 它要求所有协作者之间的通信都必须流经一个中央服务器,这使得难以支持点对点和去中心化架构。尽管点对点 OT 在理论上是可行的,但我们所知的所有富文本 OT 算法实际上都需要一个中央服务器,因为它们使用了类似 Jupiter的模型。
- 难以支持离线编辑和断网操作:当两个用户离线工作后重新上线时,其中一个用户的所有操作都需要相对于另一个用户的所有操作进行转换,这个过程非常缓慢。
- OT 算法是基于同步协作的假设设计的,即每个用户的编辑都尽可能快地应用到共享文档上。然而,在某些情况下,支持分支与合并工作流更为可取,例如允许每个用户在一段时间内处理自己版本的文档,并让用户决定何时(以及是否)稍后合并版本。例如,在图1中,用户 A 合并了用户 B 的一个编辑,而同时用户 B 合并了用户 A 的一个编辑,然后随后两位用户都想合并用户 C 的编辑:许多 OT 算法并不支持这种使用模式。
2.3 用于富文本的无冲突复制数据类型
无冲突复制数据类型是一类算法,它允许在分布式系统中维护数据结构的任意数量的副本,使得每个副本可以独立更新,并且副本的状态可以以任意方式合并。CRDTs 通过使并发操作 成为可交换的来避免 OT 的问题,因此一个副本可以以任何顺序应用这些操作,并收敛 到与以不同顺序应用相同操作的副本相同的状态。
许多用于纯文本的 CRDTs 已被提出,包括 Treedoc、WOOT、RGA、Causal Trees、Logoot、LSEQ 和 YATA。Peritext 建立在 RGA 之上,RGA 与 Causal Trees 类似,尽管我们的算法只需稍作调整即可使用上述任何一种纯文本 CRDT。所有这些算法的工作原理都是为每个字符分配一个唯一标识符。
据我们所知,目前尚无关于富文本 CRDTs 的先前已发表研究,尽管存在一些开源实现:Ritzy、Yjs-richtext和 Papyrus。
2.3.1 Ritzy
Ritzy 使用 Causal Trees CRDT 作为字符序列 的底层数据模型。每个字符都扩展了一个 attributes 属性,包含该字符的格式(例如粗体、斜体)。当用户选择一个文本区间 并更改其格式时,CRDT 内部会更新所选区间 内每个单独字符的 attributes 属性。对同一字符的并发属性更新 使用最后写入优先规则 解决(具有更高时间戳 的更新优先)。
将格式单独存储在每个字符上对协同编辑行为有重要影响。以之前的句子 "The fox jumped" 为例,想象一下 Alice 将文本加粗,而 Bob 同时插入一些新文本:

在 Ritzy 中,当两位用户合并他们的状态时,最终结果是:

也就是说,单词 "brown" 保留了 它在 Bob 插入时所具有的格式。这种行为是否可取 或许是一个见仁见智 的问题;正如第 3.1 节 所解释的,Peritext 以不同的方式处理这种情况。
然而,一个更大的问题会出现,如果 Alice 附加到句子上的属性 不是粗体格式,而是一个注释。在大多数富文本编辑软件中,注释是附加到单个连续文本区间 上的,如果由于在注释区间中间并发插入文本而导致注释被分裂成两个部分,那将是令人惊讶的。虽然有可能将注释渲染为单个区间,但在 Ritzy 的每个字符属性模型中做到这一点需要格外小心。此外,在这种模型中,将属性单独存储在每个字符上所带来的开销 也值得关注。
2.3.2 Yjs-richtext
Yjs 在纯文本 CRDT YATA 的基础上实现了富文本协同编辑。它通过在字符序列中嵌入隐藏控制字符 来添加格式,这些字符用于标记格式区间的起始和结束,例如 "start bold"(开始粗体)或 "end bold"(结束粗体)。
这种方法避免了第 2.3.1 节中提到的问题(指 Ritzy 的字符级属性模型问题),因为任何插入在 start-bold 和 end-bold 控制字符之间的字符都会变成粗体。然而,这种方法存在不同的问题。考虑以下场景:Alice 将前两个单词加粗,而 Bob 同时将最后两个单词加粗:

我们将控制字符表示为 <b> 和 </b>,并使用不同的颜色来区分 Alice 插入的字符和 Bob 插入的字符。合并后我们得到:

Yjs 通过从左到右迭代遍历文本来渲染此文档,并在每个给定位置记录当前状态是粗体还是非粗体。当它遇到一个 <b> 字符时,它会使后续文本变为粗体;当它遇到一个 </b> 字符时,它会使后续文本变为非粗体。采用这种策略,渲染结果是:
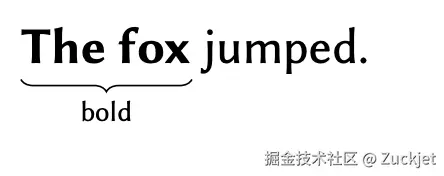
我们认为,更好的做法是将整个句子加粗,因为 Alice 和 Bob 共同加粗了每一个字符。虽然有可能针对这个特定示例改进算法的行为(例如通过计数"起始"和"结束"标记的数量),但如后文所示,还存在更多的边界情况。
另一个例子进一步说明了 Yjs 方法存在的问题。假设 Alice 和 Bob 都从以下文档开始:

如果 Alice 想要取消文本的加粗,Yjs 通过移除控制字符来实现这一点。而另一方面,如果 Bob 只想取消单词 "fox" 的加粗,Yjs 则会添加两个额外的控制字符:
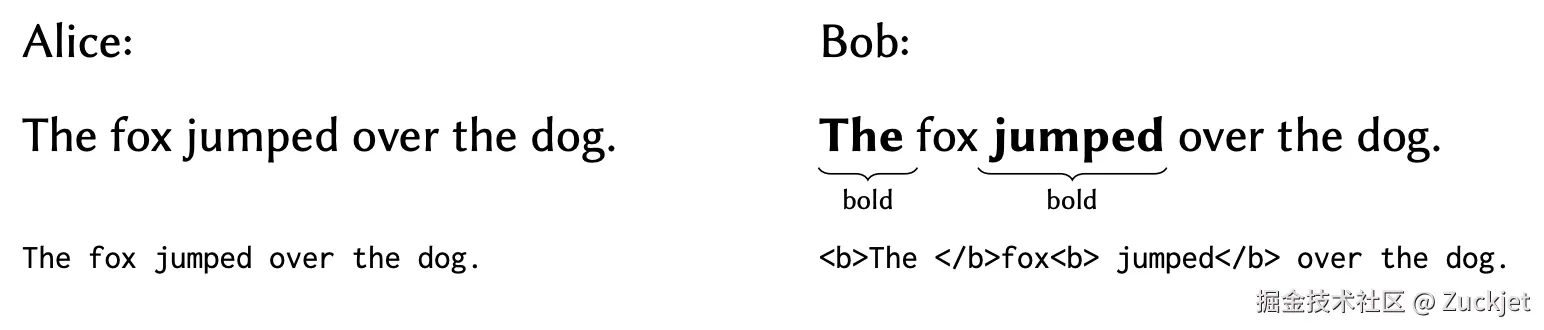
当 Yjs 合并 Alice 和 Bob 的编辑操作时,Alice 对控制字符的删除操作和 Bob 对控制字符的插入操作都会生效,因此结果是:

需要注意的是,粗体格式现在甚至蔓延到了 "over the dog" 这些单词上,尽管这些单词在用户创建的任何文档版本中从未被加粗过。如果文本后面没有更多的粗体/非粗体控制字符,这种异常将导致文档的整个剩余部分都变成粗体,而这无法通过用户执行的操作来合理解释。
我们尝试修改 Yjs 算法以解决上述问题。例如,我们不再在粗体和非粗体状态之间切换,而是维护一个计数器,记录遇到的起始粗体和结束粗体控制字符的数量,并规定:当文本前遇到的起始符数量大于结束符数量时,该文本应呈现为粗体。这种方法可以解决第前文中的两个示例问题,但在其他边界情况下会表现出问题行为。
例如,假设 Alice 和 Bob 都从以下文档开始:

Alice 取消加粗单词 "jumped",而同时 Bob 取消加粗短语 "fox jumped" 并加粗单词 "dog":
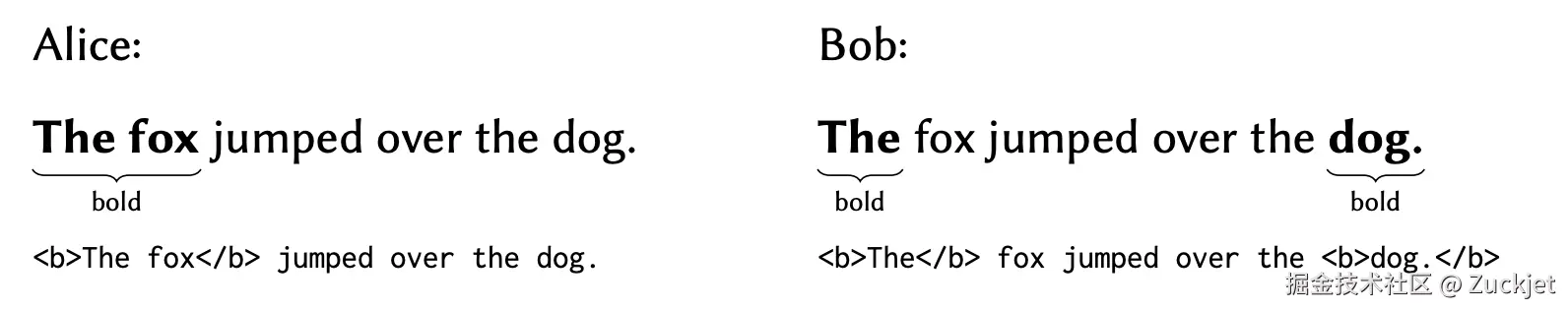
当这些编辑操作被合并时,"dog" 的加粗效果丢失了,因为文本 "dog" 前面遇到的起始粗体标记和结束粗体标记数量相同:

如果我们修改算法,复制初始的起始粗体标记,使其变为 <b><b>The</b> fox</b> jumped over the <b>dog.</b>,那么单词 "dog" 将会是粗体,但现在取消单词 "fox" 的加粗效果就会失效。无论我们尝试对这个算法应用多少层修复,我们都没有找到一个能够准确保留用户意图的变体。
控制字符的根本问题在于它们难以表示格式随时间的变化。当文本中部分重叠的区间在粗体和非粗体之间多次切换时,控制字符只能告诉我们一个区间的开始或结束位置,但它们无法告诉我们哪种格式是旧的,哪种是新的。当多个用户并发修改控制字符时,难以确定合并后的结果是否保留了意图。
在我们完成 Peritext 的实现并将其作为开源软件发布后,我们得知了 Papyrus 的存在,这是一种采用与 Peritext 类似方法的富文本 CRDT。我们之前没有发现它,因为它没有任何文档,也没有在任何出版物中被描述过。Papyrus 的作者后来撰写了一篇简短的文章,将 Papyrus 与 Peritext 进行了比较。
简而言之,Papyrus 与 Peritext 的相似之处在于,它通过引用格式化区间首尾字符的唯一标识符,将格式注释存储在文档文本之外。然而,与 Peritext 不同的是,它不支持在区间边界处进行文本插入的不同策略,这一点我们将在第 3.3 节中解释。
3 意图保留的标准
为了推理富文本编辑合并算法的正确性,我们需要一个期望行为的规范。在前面的章节中,我们已经展示了现有算法中出现的一些不良行为;在本节中,我们将概括这一分析,并为带有行内格式的文本开发一个意图保留合并行为的模型。
这样的模型必然是主观的;尽管我们的模型是通过研究流行文本编辑器的行为而形成的,但我们并不声称它是唯一可能描述正确行为的规范。尽管如此,我们认为明确一个模型是一个有益的贡献,因为它使我们(以及其他研究者)能够将行为规范与解决方案实现分开进行评估。
此外,与纯文本 CRDT 一样,该模型仅保留底层语法意图,而基于人类对文本理解的语义意图的保留通常需要人工干预。然而,最大程度地保留底层意图仍然有助于支持轻松的人工修复并最小化用户的工作量。意图保留在异步编辑场景中也尤为重要,因为作者无法实时响应其他人所做的编辑。
3.1 并发格式操作与插入操作
示例 1. 在第 2.3.1 节所示的示例中(Alice 将整个文本加粗,而 Bob 在中间插入单词 "brown"),我们认为以下结果是最理想的:

这个例子暗示了一条通用规则:当格式被添加到文档时,它应适用于两个字符之间区间内的任何文本,即使该文本在格式应用时尚未存在。
3.2 重叠格式处理
当两个用户同时对重叠区域(overlapping regions)应用格式时,应该发生什么?
示例 2. 假设 Alice 将前两个单词加粗,而 Bob 将最后两个单词加粗:

当我们合并这两个编辑操作时,我们观察到单词 "fox" 被两位用户同时设置为粗体。在这种情况下,只有一个合理的结 ------ 整个文本都应为粗体:

示例 3. 如果 Alice 加粗某段文本,而 Bob 同时将重叠区间设置为斜体,应该发生什么?

似乎很清楚,"The" 应该加粗,而 "jumped" 应该变为斜体。但是,对于 "fox" 这个两位用户都更改了格式的单词,应该应用什么格式呢?由于加粗和斜体可以共存在同一个单词上,我们认为逻辑上合理的做法是让 "fox" 同时加粗和斜体:

3.2.1 冲突性重叠
到目前为止,我们看到的合并结果似乎都保留了两位用户的意图。然而,并非所有操作都能如此干净地合并。
示例 4. 设想为某些文本分配彩色高亮显示。Alice 为 "The fox," 应用红色高亮,而 Bob 为 "fox jumped" 应用蓝色高亮:

当我们合并这两个编辑操作时,应该发生什么?与之前的例子不同,无法保留两位用户的意图------ 单词 "fox" 必须是红色或蓝色,但它不可能同时是两者。因此,这是一个冲突,可能需要一些人工干预来解决。
一种策略可能是完全舍弃一位用户的编辑,因为两者无法共存,但对我们来说,这似乎不合理地限制。另一种选择可能是将两种颜色在单词 "fox" 上混合,但那样我们会创造出一种 Alice 和 Bob 都未曾使用的新颜色。我们认为,最合理的行为是:仅在两个格式区间重叠的区域,我们随机选择 Alice 的颜色或 Bob 的颜色。
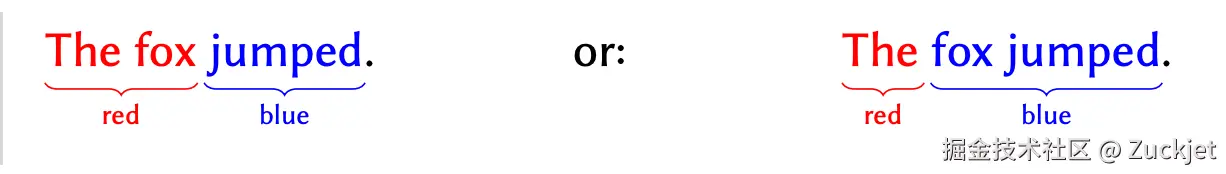
关键的是,所有查看文档的用户必须看到相同的颜色,因此颜色选择必须是确定性的。如果有人随后再次更改颜色,那么最新的颜色更改操作将决定最终颜色。这种冲突解决策略被称为最后写入优先 或 托马斯写入规则。
除了自动做出随机选择外,另一种方案是在用户界面中暴露冲突操作 ------ 例如,编辑器可以显示一个批注,提示发生冲突并请求用户复核合并结果。然而,要求用户手动解决每个冲突可能变得繁琐;我们更倾向于自动合并文档,然后允许用户后续修正任何不符合预期的合并结果。
示例 5. 冲突不仅出现在颜色场景;即使简单的加粗格式操作也可能产生冲突。例如,Alice 先将整个文本加粗,随后将 "fox jumped" 更新为非加粗,而 Bob 则仅将单词 "jumped" 标记为加粗:

单词 "The" 被 Alice 设置为加粗且未被 Bob 更改,因此它应为加粗。单词 "fox" 被 Alice 设置为非加粗且未被 Bob 更改,因此它应为非加粗。但是,单词 "jumped" 被 Alice 设置为非加粗,而被 Bob 设置为加粗。在这种情况下,我们在单词 "jumped" 上存在冲突,因为该单词不可能同时加粗和非加粗。因此,我们必须做出一个随机但确定性的选择,正如前一个示例中所做的那样:

用户甚至可能将某些文本在加粗和非加粗状态之间反复切换多次。在这种情况下,我们说 Alice 文档的最终状态与 Bob 的最终状态存在冲突,但我们不考虑更早的状态是冲突的一部分。
3.2.2 同类标记的多重实例
示例 6. 处理同类标记的重叠时,还有一种情况需要考虑。设想 Alice 和 Bob 都在文本的重叠部分添加了评论:

这两条评论很可能内容不同,因此我们无法将它们合并为单一标记。此外,评论的行为与示例 4 中的彩色文本不同:尽管单个字符不能同时是红色和蓝色,但文本中的单个字符可以关联多条评论。我们可以在编辑器中通过重叠显示这两个高亮区域来呈现这种情况:

3.3 区间边界处的文本插入
我们需要考虑的另一种情况是:当用户在文档中的某个位置输入新文本时,这些新字符应具有什么格式?在示例 1中我们论证过,如果文本被插入到加粗区间的中间,那么新文本也应加粗。但是,当文本被插入到不同格式文本部分的边界(boundary)时,应该发生什么就不那么明确了。
示例 7. 假设我们从一个文档开始,其中区间 "fox jumped" 是加粗的,其余部分是非加粗的:

现在,Alice 在加粗区间前插入 "quick␣",并在句末句号前插入 "␣over the dog"。在我们测试的所有主流富文本编辑器(Microsoft Word、Google Docs、Apple Pages)中,结果是:
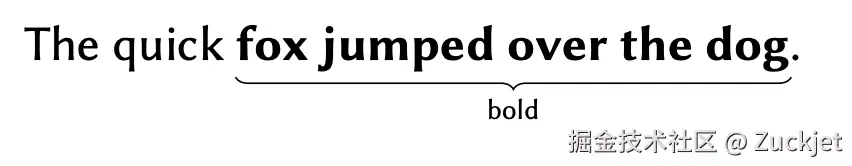
也就是说,在加粗区间前插入的文本变为非加粗,而在加粗区间后插入的文本变为加粗。这里的通用规则是:新插入的字符继承前一个字符的加粗/非加粗状态。同样的规则适用于大多数字符格式类型,包括斜体、下划线、字体、字号和文本颜色。然而,如果文本被插入到段落开头,即同一段落中没有前一个字符时,则它继承后一个字符的格式。
示例 8. 示例 7 的规则存在一些例外:如果我们在链接(link)或评论的开头或结尾插入文本,主流富文本编辑器会将新文本置于链接/评论区间之外。例如,如果 "fox jumped" 是一个链接:

在 Alice 像示例7那样插入文本后,结果是:

也就是说,虽然加粗或斜体区间会扩张以包含在区间末尾插入的文本,但链接或评论区间不会以相同方式扩张。这种行为是否可取或许有待商榷,但我们注意到主流富文本编辑器在这方面高度一致,这表明此行为是一种有意的设计选择。
如果链接的结束点和加粗区间的结束点落在同一个字符上,并且在该字符之后插入了文本,应该发生什么?最一致的行为是让该文本加粗但不链接。Microsoft Word 的行为符合此方式,而谷歌文档(Google Docs)和 Apple Pages 则使新字符既不加粗也不链接(neither bold nor linked)。
3.4 推广到其他标记类型
上述示例代表了一个测试套件,它描述了在各种常见编辑场景中保留用户意图的合理合并行为。虽然我们使用了特定的格式类型(如加粗和链接)来说明行为,但这些规则可以更广泛地适用于其他类型的格式。
我们描述的格式类型可以按两个维度进行分类:
标记是否可以重叠?同一个字符是否可以关联多个此类标记? 标记是否会扩张?如果用户在标记的末尾输入,标记是否会扩张以包含新文本?

表1展示了我们的示例格式类型如何适应这个分类法。我们相信,富文本文档中的大多数行内格式都可以归入这些类别之一;例如,下划线遵循与加粗和斜体相同的规则。当然,特定文本编辑器的开发者也可以选择在此框架内改变特定标记的行为。例如,开发者可能决定允许彩色文本标记重叠,并在重叠区域渲染混合颜色。从协同算法的角度来看,每种标记类型只是这些参数的某种配置,而渲染则留给用户界面层处理。
4 PERITEXT:一种富文本 CRDT
我们现在介绍在 Peritext 中用于富文本协同编辑的方法。我们从四个部分描述我们的算法:
- 使用现有的纯文本 CRDT 表示富文本文档的文本内容。
- 生成代表格式更改的 CRDT 操作。
- 应用这些操作以产生内部文档状态。
- 基于内部状态推导出适合文本编辑器的文档。
我们在设计算法时的思路是尽可能捕捉用户输入,从而捕捉用户意图:
- 插入操作在用户输入或粘贴新字符到文本中的某处时生成。
- 删除操作在用户在某处文本按下退格键或删除键,或覆盖选定文本时生成。
- 添加标记或移除标记操作在用户选择某些文本并通过菜单或键盘快捷键选择格式选项时生成。一个"标记"是应用于文本连续子串的任何属性:例如,加粗高亮的单词,或带有行内评论注释的句子。
4.1 底层纯文本 CRDT
我们的实现使用 RGA / Causal Trees 作为其基础,但原则上它可以扩展任何纯文本 CRDT 。

我们的文档模型为每个字符存储一个布尔标志,当该字符被删除时,该标志变为 True 。被删除的字符作为墓碑保留在文档模型中,这是处理并发编辑所必需的。
每个修改文档状态的操作都被赋予一个唯一的、不可变的标识符,称为 opId(操作标识符)。一个 opId 是一个 Lamport 时间戳;我们将其写为 counter@nodeId 形式的字符串,其中 counter是一个整数,nodeId 是生成该操作的客户端的唯一 ID(例如 UUID)。每当我们创建一个新操作时,我们赋予它一个比文档中任何现有操作(来自任何客户端)的最大计数器值大一的计数器值。
如果不同节点并发生成操作,两个 opId 有可能具有相同的计数器值,但由于一个给定的客户端永远不会使用相同的计数器值两次,因此计数器值和节点 ID 的组合是全局唯一的。
opId 的排序规则如下:如果 counter1 < counter2(使用数值比较),则 counter1@node1 < counter2@node2;如果 counter1 == counter2,我们使用 node1和 node2的字符串比较来打破平局。
4.1.1 插入和删除纯文本
大多数文本 CRDT 的核心思想是将文本表示为字符序列,并为每个字符赋予一个唯一标识符。在我们的情况下,一个字符的 ID 是插入该字符的操作的 opId。
要将一个字符插入文档,我们生成一个如下形式的插入操作(insert operation):
perl
{ action: "insert", opId: "2@alice", afterId: "1@alice", character: "x" }此操作在 ID 为 1@alice的现有字符之后插入字符 "x"。为了确定字符插入的位置,我们总是引用我们希望在其后插入的现有字符的 ID,因为这些 ID 随时间保持稳定。要在文档开头插入,我们使用 afterId: null。如果两个用户并发地在同一位置(即使用相同的 afterId)插入,我们通过它们的 opId 对插入进行排序,以确保所有用户最终收敛到相同的字符序列。
要从文档中删除一个字符,我们生成一个如下形式的删除操作:
perl
{ action: "remove", opId: "5@alice", removedId: "2@alice" }此操作删除 ID 为 2@alice的现有字符(即我们上面插入的 "x")。和之前一样,我们通过其 ID 而非索引来识别要删除的字符。当我们处理一个删除操作时,该字符实际上并未从文档中完全删除,我们只是将其标记为已删除,留下一个墓碑。这样,如果另一个插入操作在其 afterId 中引用了这个已删除字符的 ID,我们仍然知道在哪里放置插入的字符。
如图 2 所示,纯文本文档的状态对于每个字符包含三部分内容(consists of three things):插入该字符的操作(operation that inserted it) 的 opId、实际的字符(actual character) 以及一个标志(flag) 来告诉我们它是否已被删除。
在图 2 中,Alice(节点 ID A)首先输入文本 "the fox",生成 opId 1@A到 7@A。然后 Bob(节点 ID B)删除了开头的小写 "t"(initial lowercase "t")(删除操作的 opId 是 8@B)并用大写 "T"(uppercase "T") 替换它(opId 9@B),最后 Bob 输入了剩余的文本 "␣jumped."(opId 10@B到 17@B)。因此,最终文本是 "The fox jumped.",但小写 "t" 仍然在序列中,只是被标记为已删除。
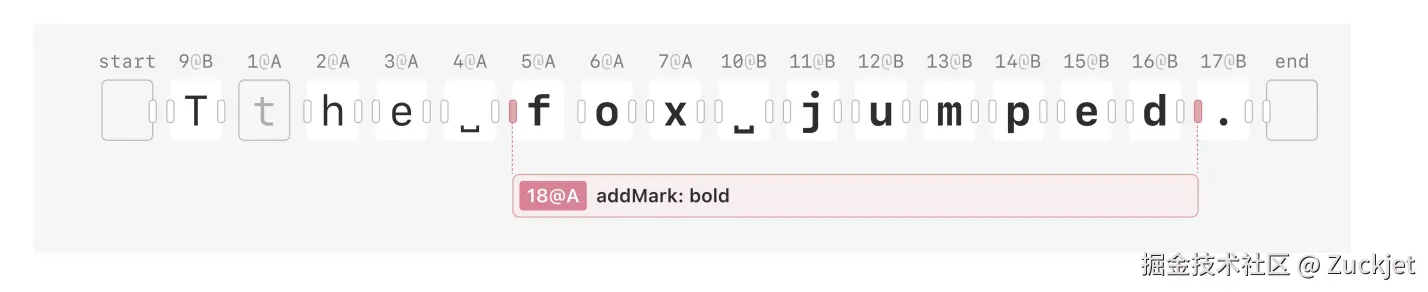
概念上,每个字符有两个格式锚点位置:一个在字符之前,一个在字符之后。这些锚点位置决定了当在边界插入新文本时,格式操作是否会被扩展。为简化,后续图示将仅显示附加了标记操作的锚点位置。
这就是实现纯文本协同编辑所需的全部内容:插入单个字符和删除单个字符。更大型的操作,例如剪切或粘贴整个段落,会转化为多个单字符操作。这可以优化以提高效率(如第 4.7 节所述),但目前,单字符的插入和删除操作已足够。
4.2 生成行内格式操作 下一步是允许更改文本格式。每次用户更改文档的格式时,我们会生成一个 addMark 或 removeMark 操作。
例如,如果 Alice 选中文本 "fox jumped" 并按 Ctrl+B 将其加粗,我们会生成如下操作(如上图所示):
css
{
action: "addMark",
opId: "18@A",
start: { type: "before", opId: "5@A" },
end: { type: "before", opId: "17@B" },
markType: "bold"
}此操作的 opId 为 18@A。它作用于从 ID 为 5@A的字符(即 "fox" 中的 "f")开始,到 ID 为 17@B的字符(最后的句号)结束的文本区间。该区间内的所有字符(包括起始字符,但不包括结束字符)变为粗体。
区间的起始位置和结束位置使用锚点位置表示,这些位置通过字符的 ID 来引用。文本中的每个字符都有两个锚点位置:字符前和字符后,格式操作的起始和结束点可以附加在这些位置上。
4.2.1 移除标记
如果用户改变主意,决定文本最终不应加粗或链接,我们不会移除之前的 addMark 操作。事实上,我们从不移除任何操作,我们只生成新的操作(我们将在第 4.7 节展示如何弱化此假设)。
相反,我们生成一个 removeMark 操作,它撤销先前 addMark 操作的效果,并将一系列字符恢复为非加粗状态。例如,以下操作(如图 4 所示)使 "␣jumped" 变为非加粗:
css
{
action: "removeMark",
opId: "20@A",
start: { type: "before", opId: "10@A" },
end: { type: "before", opId: "17@B" },
markType: "bold"
}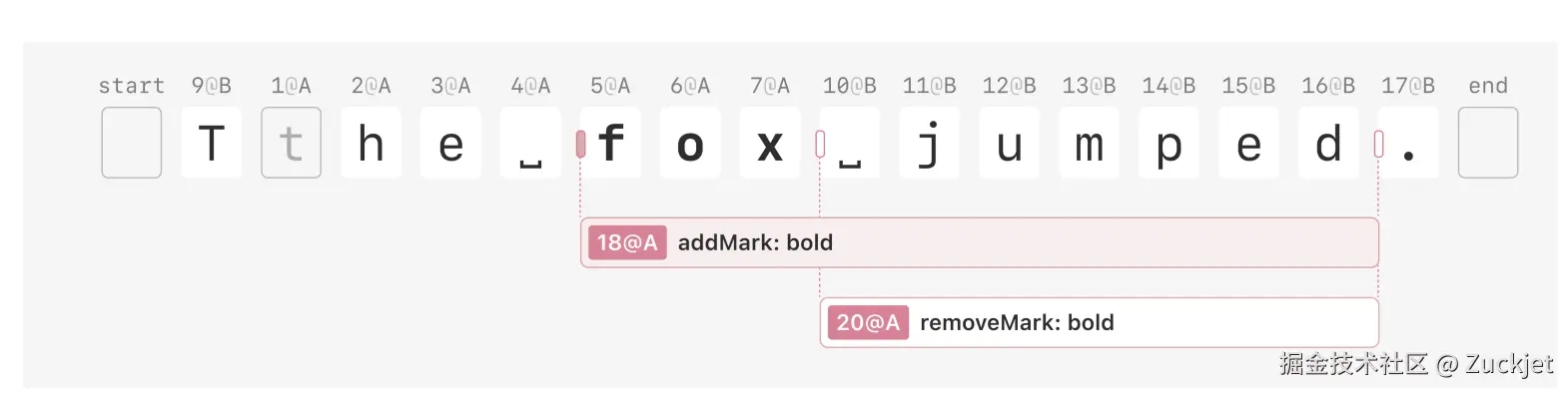
要完全移除一个先前的标记,removeMark 操作的 start和 end 应该与要覆盖的 addMark 操作相同。通常,一个 removeMark 操作可以在任何字符上开始和结束,无论其当前格式如何,其效果是将该区间设置为非加粗/非链接/非斜体等状态。
4.2.2 在区间边界插入文本
格式更改总是发生在两个字符之间的间隙。示例 addMark操作中的 type: "before" 属性表明:加粗区间起始于"f" 之前的间隙(即 "f" 是粗体,但其前面的空格不是)。加粗区间结束于"." 之前的间隙(即 "jumped" 的 "d" 是粗体,但句号不是)。如果我们希望一个区间起始于或结束于某个特定字符之后的间隙,我们也可以选择 type: "after"。此外:如果我们希望区间始终起始于文档开头,start 属性可以是"startOfText"。如果我们希望区间结束于最后一个字符之后,end属性可以是 "endOfText"。
如果另一个用户在该区间内插入文本(如第 3.1 节的示例 1),这些新字符仍然落在 addMark 操作定义的区间内,因此它们也会被格式化为粗体。 当文本被插入到加粗区间的边界时,其行为如示例 7 所示:在 "f" 之前插入的文本是非加粗的。在 "d" 和句号之间插入的文本是加粗的,因为它仍然落在句号之前的区间内。
每个字符拥有两个不同的锚点位置的原因在于,这允许我们自定义标记在区间边界处的扩展行为。例如,与加粗格式不同,链接在文本插入到其结尾时不应扩展。如示例 8 所示。为了实现这种行为,我们为链接的 addMark 操作建模,使其结束于标记的最后一个字符之后的间隙,如下面这个操作所示(如图 5):
css
{
action: "addMark",
opId: "19@A",
start: { type: "before", opId: "5@A" },
end: { type: "after", opId: "16@B" },
markType: "link",
url: "https://www.google.com/search?q=jumping+fox"
}结果是,"jumped" 的 "d" 仍然是链接的一部分,但在该字符之后插入的任何文本将不属于该链接。
 图 5.标记类型可以包含附加元数据,例如超链接。请注意,与结束于区间之后字符的粗体标记不同,链接结束于区间的最后一个字符。这种方法防止在追加新文本时链接无限扩展。
图 5.标记类型可以包含附加元数据,例如超链接。请注意,与结束于区间之后字符的粗体标记不同,链接结束于区间的最后一个字符。这种方法防止在追加新文本时链接无限扩展。
 图 6.当字符被标记为已删除时,我们保留所有附加的操作。若要在句号前插入字符且避免链接扩展,插入操作应放置在墓碑 16@B之后。
图 6.当字符被标记为已删除时,我们保留所有附加的操作。若要在句号前插入字符且避免链接扩展,插入操作应放置在墓碑 16@B之后。
还需注意,一个 markType: "link"的操作具有额外的 url 属性。要更改链接指向的 URL,我们只需生成另一个具有新 URL 但相同起始和结束点的 addMark 操作。对于评论,我们在实际的 addMark 操作中仅包含一个唯一的评论 ID,并将评论的文本、作者、时间戳和其他详细信息存储在单独的 CRDT中。
从加粗到非加粗的转变不仅可能由 addMark 的结束引起,也可能由 removeMark 的开始引起(反之亦然,从非加粗到加粗的转变)。为了维持新插入字符继承前一个字符格式的规则,removeMark 操作对于加粗及类似类型的标记,在 start 和 end 上都使用 type: "before"。例如,如果我们处于图 4 所示的状态,然后在 "x" 之后立即插入 "␣suddenly",它将是加粗的,因为它落在 addMark 区间内但不在 removeMark 区间内。
在段落开头插入字符需要一个特殊情况处理:我们必须先插入字符,然后生成额外的格式操作,以使插入的字符获得与其后继字符相同的格式。
对于不应在结尾扩展的标记(如链接和评论,参见表 1),addMark 使用 type: "before" 作为 start,type: "after"作为 end。对于 removeMark,角色是相反的:这些操作使用 type: "after" 作为 start,type: "before"作为 end。这确保了当文本插入到链接的结尾时,该文本不属于链接的一部分,无论链接结束是因为创建它的 addMark 结束,还是因为一个 removeMark 的开始移除了后续字符的链接属性。
还需要一个细节来确保在链接结尾插入的行为正确:链接结束点所锚定的字符可能被删除(成为墓碑)。在图 6 的示例中,"fox jumped" 被链接,然后单词 "jumped" 被删除。
现在假设用户想用 "frolicked" 替换 "jumped",因此他们在空格 10@B之后(after)插入该单词。这个位置在链接的结尾(下一个可见字符,句号,不属于链接),因此我们期望新字符是非链接的,因为链接不扩展。然而,当在插入新字符的位置存在墓碑时,我们的纯文本 CRDT 默认将插入的字符放置在墓碑之前。这会将 "frolicked" 放在 "jumped" 的墓碑之前,使其成为链接的一部分,这是不可取的。
为了解决此问题,如果我们需要在存在墓碑的位置插入字符,我们会扫描该位置的墓碑列表。如果存在任何墓碑,其 after 锚点是任何格式操作的起始或结束点,我们就在最后一个此类墓碑之后插入字符。否则,我们像往常一样在墓碑之前插入。在上面的示例中,字符 "d"(16@B)的 after 锚点是 addMark操作 19@A的结束点,因此我们将新单词放在该字符之后。这确保了在链接结尾的插入被放置在链接之外。
如果墓碑列表包含多个格式操作的起始或结束锚点,可能不存在理想的插入位置。在这种情况下,插入的文本可以相对于墓碑任意放置,最坏的结果是文本的格式与预期不同。我们相信这种情况足够罕见,用户可以手动调整格式是可以接受的。
4.3 应用操作
我们现在展示我们的算法如何应用操作(来自本地作者或远程协作者)来更新内部 CRDT 状态。我们必须确保应用并发操作是可交换的:当两个操作是并发生成时,我们可以以任何顺序应用它们,并且最终文档必须相同。
插入和删除字符是直接的;我们使用第 4.1 节描述的 RGA 纯文本 CRDT 逻辑。但应用 addMark 或 removeMark 操作需要一种新方法,并且是我们算法的关键步骤之一。
如上所述,每个字符有两个关联的锚点位置用于格式操作,一个在字符之前,一个在字符之后。在每个锚点位置,我们可以存储一组操作,我们称之为一个 op-set。op-set 也可能不存在;当一个字符首次插入时,其两个锚点位置的 op-set 都不存在。一个不存在的 op-set 与一个存在但为空的 op-set 不同;在我们的原型中,不存在的 op-set 表示为 null。
如果一个 op-set 𝑆 存在于锚点位置 𝑝,它具有以下含义:
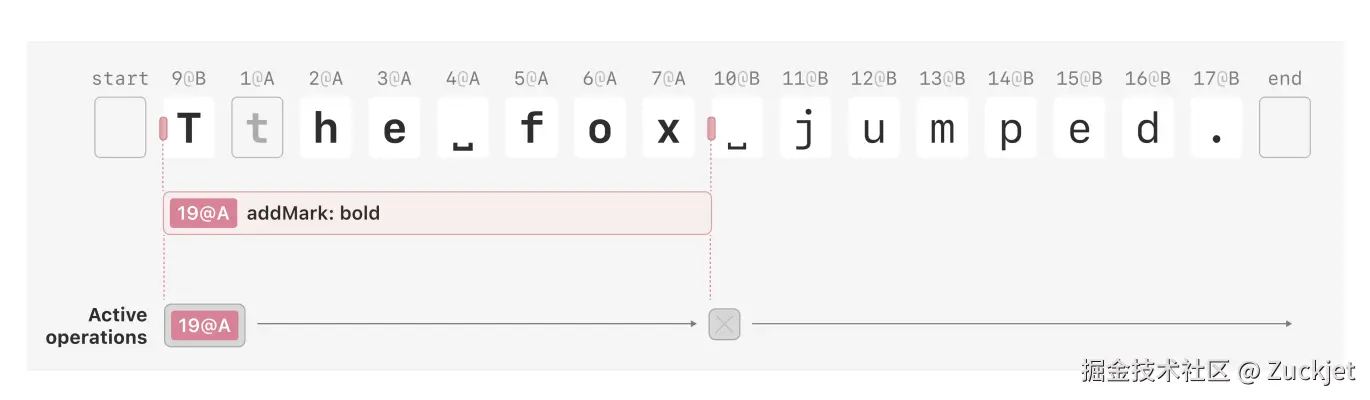
𝑆 恰好包含与该锚点位置重叠的所有 addMark 和 removeMark 操作的集合。换句话说,𝑆 中的每个操作起始于 𝑝 或之前,并结束于 𝑝 之后。 同一个 op-set 𝑆 也适用于 𝑝 之后的所有连续位置(其中 op-set 不存在);op-set 仅存在于格式可能更改的位置。这是一种压缩:我们可以在许多锚点上冗余存储相同的 op-set,但仅将 op-set 存储在格式区间的边界处可以节省内存。 算法1展示了将 addMark 或 removeMark 操作应用于 CRDT 状态的伪代码。总结:让 𝑜𝑝𝑠𝐴𝑡 是一个可变的列表,包含按锚点位置索引的 op-set。我们用 opsAt𝑝 = ⊥表示锚点位置 𝑝 的 op-set 不存在。我们首先更新新操作起始位置的 op-set。然后更新操作区间内的任何现有 op-set。最后,我们在操作的结束位置添加一个不包含该操作的 op-set,以标记在该序列点活动操作已更改。

我们可以用一个例子来演示这个过程。想象我们从没有格式的文本 "The fox jumped." 开始,Alice 想将前两个单词加粗。她生成一个 addMark操作,起始于 "T" 之前(9@B),结束于 "x" 之后的空格之前(10@B)。Alice 通过将第一个字符(9@B)左侧的 op-set 设置为包含该 addMark操作的集合,并将第二个空格字符(10@B)左侧的 op-set 设置为空集(empty set),将此操作应用于她自己的文档数据结构。结果如图 7 所示。
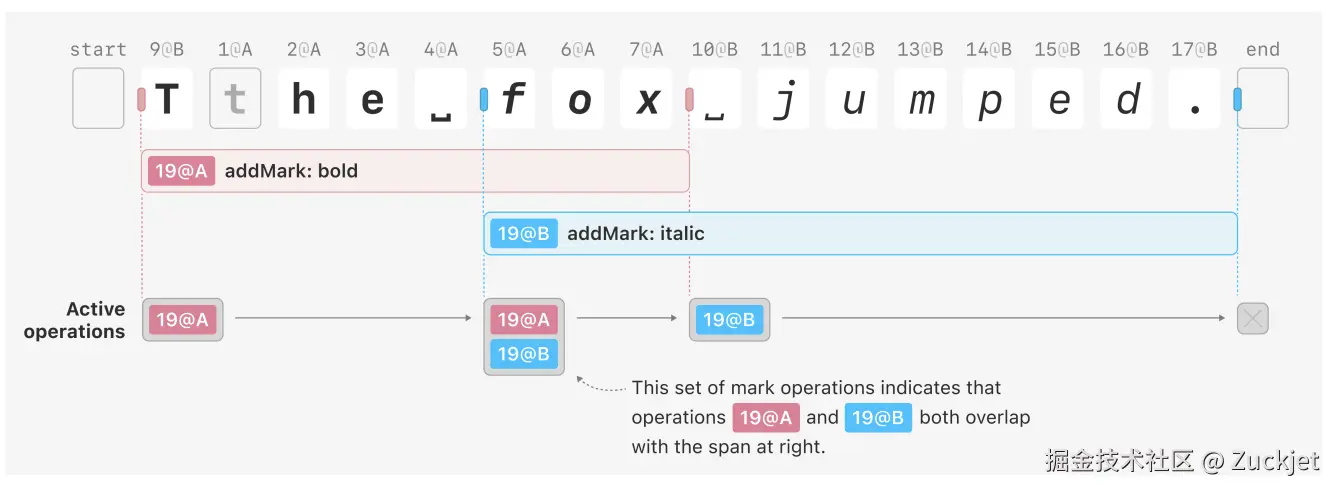
同时,Bob 将最后两个单词和句号设为斜体,如第 3.2 节的示例 3 和图 8 所示。他为此区间生成了一个 addMark操作,起始于 "f" 之前,一直延伸到文本结尾(即最后一个字符之后)。Bob 在生成斜体操作时尚未看到 Alice 的加粗操作。
接下来,我们考虑当 Alice 在本地应用 Bob 的操作时会发生什么(图 9)。第一步是更新起始位置的 op-set。在示例中,"f" 字符左侧的 op-set 不存在,因此我们复制"T" 字符之前的 op-set 并将斜体操作添加到其中。接下来,我们运行一个循环,该循环遍历操作区间内的所有锚点位置。我们遇到了第二个空格字符左侧的一个现有 op-set:它之前是空集,我们将斜体操作添加到其中。最后,我们更新结束位置的 op-set,因为该位置现在标记了格式的更改。在示例中,斜体操作结束于 endOfText,我们将其初始化为空集。图 9 显示了应用操作后文档的最终状态。我们的不变量得以保持;每个 op-set 恰好包含适用于后续字符区间的格式操作。
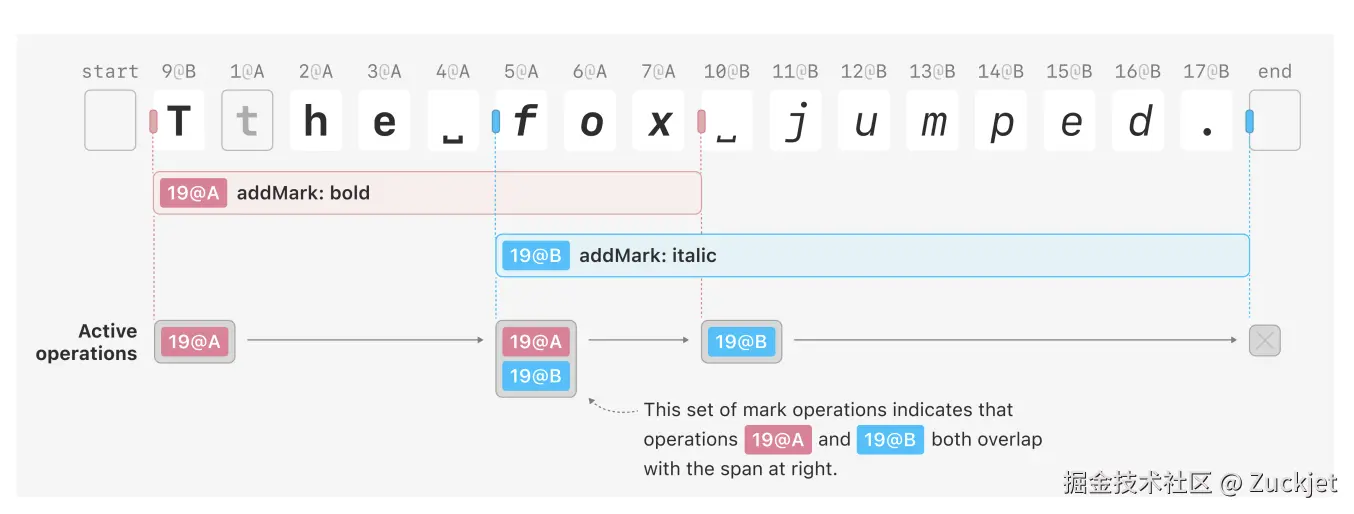
我们在附录A中证明该算法是可交换的:无论以何种顺序应用格式操作,我们最终都会达到相同的最终状态。此外,它是高效的:我们只需要扫描文档中受格式操作影响的部分,而不是整个文档。
4.4 生成最终文档
上一节的算法将文档细分为多个区间,每个区间关联一个操作集(op-set)。然而,这还不足以显示格式化的文档。每个操作集可能包含许多引用相同格式属性的 addMark 和 removeMark 操作;我们需要使用一种确定性且独立于操作接收顺序的算法,将这个操作集转换为当前的格式状态。
要生成最终文档,我们可以遍历文档中的区间,并为每个区间将其关联的操作集转换为当前格式的描述,如下所示:
yaml
[
{ text: "The ", format: { bold: true } },
{ text: "fox", format: { bold: true, italic: true } },
{ text: " jumped.", format: { italic: true } }
]由于每个操作仅影响其 markType(粗体、斜体等)指示的方面,我们可以分别考虑每种 markType的操作。在上一节的示例中,我们很容易看出单词 "fox" 应该同时是粗体和斜体,因为粗体和斜体操作与该单词重叠。
然而,在其他情况下,转换过程可能更复杂。同一个区间可能存在多个具有相同 markType 的操作:例如,某些文本可能被多次加粗和取消加粗。对于大多数标记类型,不同操作指示的值是互斥的:一个字符必须是粗体或非粗体;一个字符不能拥有多种文本颜色。对于这些标记类型,我们使用最后写入优先的冲突解决策略,选择具有最大操作的格式操作作为胜者。
例如,考虑一个区间应用了两个操作:一个 opId 为 19@A 的 addMark 操作和一个 opId 为 23@B 的 removeMark 操作,两者都是 markType: "bold"。我们通过使用第 4.1 节定义的排序规则比较它们的 opId来确定胜者。removeMark操作优先,因为 23@B > 19@A,因此该区间是非加粗的。
回想一下,每当我们创建一个新操作时,我们赋予它一个 opId,其计数器值比文档中任何现有操作的最大计数器值大一。这确保了如果用户多次改变对格式的想法------例如,如果他们将同一个单词在加粗和非加粗之间切换多次------那么最终的格式操作将拥有最大的计数器值,因此优先于所有先前的操作。
事实上,为了确定文档的当前格式,严格来说并不需要存储所有历史格式操作的集合:存储每个标记类型和每个区间的最新值以及设置该值的 opId 就足够了。然而,如果我们想要计算文档在过去的某个时间点的状态,以便可视化文档版本之间的差异,存储格式操作集合是有用的。尽管当前版本的 Peritext 不支持此功能,但我们相信它对于异步协作很重要,并计划在未来添加它。
并非所有标记类型都是互斥的------在评论的情况下,同一个区间可能关联多个评论,因此我们保留所有没有对应 removeMark 操作删除的评论。
作为进一步的优化,我们可以避免计算任何仅包含已删除字符(墓碑)的区间的当前格式,因为它们不会在所见即所得编辑器中显示,并且我们可以连接任何当前格式相同的相邻区间。
4.5 增量补丁 我们描述了一种从头开始的方法来遍历文档中的所有区间并生成当前文档状态。这易于理解,并且在文档首次加载时是一种合理的方法,但对于持续编辑来说并不理想。一个问题是性能:从头开始的方法需要在每次按键时遍历整个文档,这在大型文档中可能变得缓慢。它也不符合大多数文本编辑 UI 库的概念模型------文本编辑器通常实现为一个有状态对象,因此每次编辑应描述文档中发生了什么变化,而不是提供整个新的文档状态。
为了解决这些问题,我们实现了一种增量方法来向文本编辑器 UI 发送更新。关键思想是增强应用操作的过程:除了更新内部操作集(op-set)之外,我们还生成补丁,描述该操作对公开可见的格式化文档的影响。这有助于提高性能,因为整合新操作和更新编辑器 UI 的整个过程只需要在文档中受该操作影响的局部区域工作。
处理一个插入操作时,我们首先使用现有的 RGA 算法确定新字符的插入位置,并计算其索引。要计算字符的索引,我们可以统计插入位置之前的非删除字符的数量。有数据结构可以高效地执行此索引计算,而无需扫描整个文档,但它们超出了本文的范围。
此外,我们需要确定应用于插入字符的格式。我们通过从插入位置开始在字符数组中向后搜索,直到找到一个格式标记的操作集。然后,我们使用通常的最后写入优先逻辑从这个操作集中计算插入字符的标记,接着我们构建一个补丁,在计算出的索引处插入一个具有该格式的字符。
例如,一个在索引 6 处插入字母 "x" 并具有粗体格式的补丁可能如下所示:
lua
{ type: "insert", char: "x", index: 6, format: { bold: true } }请注意,补丁使用索引,而操作使用 opId 来标识文本中的位置。这没问题,因为补丁仅用于将更新从 CRDT 传播到文本编辑 UI;通过在与 UI 相同的线程上运行 CRDT 逻辑,我们可以避免处理这两个组件之间的并发。从一个用户发送到另一个用户的操作需要使用 opId,因为它们需要处理并发更新。
删除操作的处理最简单:我们找到具有相应 opId 的字符;如果它已被删除,我们什么也不做;如果尚未删除,我们将其标记为已删除并计算被删除字符的索引。然后我们构建一个补丁,要求编辑器删除该索引处的字符。
当应用 addMark 或 removeMark 操作时,我们不需要更改编辑器中的任何文本,但可能需要更新多个文本区间的格式。如第 4.3 节所述,我们遍历文档中的连续区间,将新操作添加到该区间的操作集中。对于每个区间,我们然后考虑是否发出一个表达格式更改的补丁。我们使用最后写入优先逻辑计算旧操作集和新更新的操作集的格式,并进行比较。如果格式已更改,则我们发出一个更新该区间格式的补丁。
这种方法的一个有趣后果是,应用格式操作有时只会为该操作区间的一部分发出补丁。例如,一个将整个文档加粗的操作可能只发出为文档的某些部分加粗的补丁,如果存在其他并发操作抵消了它对其他部分的影响。
发出补丁的确切细节有些微妙,因为我们被迫将应用操作的逻辑与计算其影响的逻辑纠缠在一起(entangle)。然而,通过累积增量补丁,然后将结果与上一节描述的更简单的从头开始算法进行比较,可以直接检查实现的正确性。我们请读者参阅补充材料中的代码,了解发出补丁的完整实现。
4.6 原型实现 我们已在 TypeScript 中实现了 Peritext CRDT 的工作原型。我们的代码基于 Automerge CRDT 库的简化版本,并希望将来将我们的算法集成到 Automerge 中。该实现包含对本工作中描述的许多特定场景的单元测试,以及一个检查收敛性的随机化基于属性的测试套件。我们测试了在三个节点之间交换超过 5,000 个操作的随机编辑轨迹,没有违反收敛性。这使我们确信实现是正确的,因为我们能够在早期版本中使用小得多的编辑轨迹发现几个编码错误。我们算法收敛的形式化证明在附录 A 中给出。
对于编辑器 UI,我们选择基于 ProseMirror 构建,这是一个流行的库,已在许多协同编辑环境中使用(通常与 OT 一起使用)。其模块化设计为我们提供了在适当点干预编辑器数据流所需的灵活性。我们也期望 Peritext 能与其他编辑器 UI 良好集成,因为我们没有专门针对 ProseMirror 进行设计。
目前,我们的实现有些专门化于本文中展示的小型标记集:粗体、斜体、链接和评论。然而,我们打算将这些作为代表性的格式标记集,并期望它们的行为也能扩展到其他类型的用户可配置标记。
4.7 性能与效率
我们的算法在设计时考虑了性能:特别是,更新仅在本地操作它们所触及的文本,不需要扫描或重新计算整个文档。然而,我们在某些领域优先考虑简单性而非性能:我们将每个字符存储为一个单独的对象(占用大量内存);我们记住所有墓碑和所有格式操作的历史;查找具有特定 opId的字符并计算其索引的过程也未优化。
这些我们优先考虑简单性的领域并非算法的根本,可以通过一些实现工作来解决。例如,支持纯文本协作的 Automerge 和其他 CRDT 使用字符序列的压缩表示,其中具有连续 opId的字符被表示为简单字符串,而不是每个字符一个对象。它们还具有数据结构,可以高效地将 opId转换为字符索引,反之亦然,这对于与 ProseMirror 等编辑器的集成是必需的。
我们在一个简单的系统模型中描述了 Peritext,其中每个操作都被永久存储,并且它基于 RGA 纯文本 CRDT,该 CRDT 需要记住已删除的字符作为墓碑。这种设计导致存储无限增长,但可以通过多种方式进行优化:
- 与其在锚点位置存储 addMark/removeMark 操作的操作集,不如存储每个标记类型的值(例如粗体或非粗体)和最高 opId。例如,如果一个单词在粗体和非粗体之间切换多次,我们只需要保留最新状态,并且可以丢弃其效果已被覆盖的格式操作。
- RGA 中垃圾回收墓碑的机制也适用于 Peritext。当墓碑被清除时,任何附加到该墓碑的标记都需要移动到未被清除的最接近的前一个或后一个字符;当格式区间内的所有字符都被清除时,该区间也可以被删除。
- 也可以使用无墓碑的纯文本 CRDT,例如 Logoot,代替 RGA。由于它也基于每个字符的唯一 ID,因此将格式附加到字符标识符的原则同样适用。如果某个格式区间内的所有字符都已被删除,我们仍然需要保留该格式区间,因为另一个用户可能并发地在其中插入一个字符从而"复活"它。一旦因果稳定性确保不会再向该区间并发插入,该区间就可以被删除。
- 即使没有垃圾回收,永久存储所有操作也不像看起来那么昂贵:Automerge 的压缩文件格式可以以每操作不到一字节的成本存储文本文档编辑历史中的每一次按键。这种优化也可以应用于 Peritext。
5 结论
在本工作中,我们分析了合并富文本文档的并发编辑的问题。我们已证明,通过为每个字符添加格式属性或使用控制字符来指示格式区间的起始和结束来扩展纯文本文档,会导致用户意图无法保留的情况。相比之下,我们的方法------在文本外部存储格式注解并通过唯一标识符将其附加到字符上------满足了我们所有的意图保留场景并保证收敛性。在此基础上,我们开发了一种支持重叠行内格式的富文本 CRDT,并展示了如何高效地实现它。
Peritext 只是迈向富文本协作系统的第一步:它仅实现了富文本文档的两个版本能够自动合并。一个完整的协作解决方案(尤其是异步协作)还需要在可视化编辑历史和更改、高亮冲突供手动解决以及其他功能方面进行更多工作。由于 Peritext 通过将文档的编辑历史捕获为操作日志来工作,这为未来实现这些进一步的功能提供了良好的基础。
行内格式对于短文本块是足够的,但较长的文档通常依赖于更复杂的块级元素或分层格式,例如嵌套项目符号,这是 Peritext 目前未建模的。需要进一步的工作来确保对块级结构如项目符号列表的编辑在合并时能保留作者意图。分层格式结构引发了关于意图保留的新问题------例如,当用户并发地拆分、合并和移动块级元素时,应该发生什么?
另一个值得未来探索的领域是在文档内移动和复制文本。如果两个人并发地剪切粘贴 同一段文本到文档中的不同位置,然后进一步修改粘贴的文本,最合理的结果是什么?
我们希望 Peritext 和其他用于富文本的 CRDT 能够实现新的协作工作流,这些工作流在现有的存储文本文档的数据结构上是不可能构建的。用户可以尝试创建自己的长期分支,并轻松地将其合并回来,同时提供强大的比较视图。人们可以选择私下工作,或者屏蔽他人进行的分散注意力的更改。与其将文档历史视为线性版本序列,不如将其视为基于细粒度变更数据库的多重投影视图。