目录
一、功能介绍
本方案的核心功能是持续监听一个数据源(如传感器、API接口、消息队列、其他应用程序等),将获取到的实时数据流以追加的方式写入到Excel文件中。同时,方案会处理文件创建、表头初始化、数据分批写入等细节,确保程序的效率和数据的完整性。
二、具体的程序示例
示例功能
模拟数据源: 创建一个函数来模拟实时监测数据(例如:时间戳、温度、湿度、压力)。
初始化Excel文件: 程序启动时,检查目标Excel文件是否存在。如果不存在,则创建它并写入表头。
定时任务: 每5秒采集一次模拟数据,并将其追加到Excel文件的指定工作表中。
优雅退出: 通过键盘中断(Ctrl+C)可以安全地停止程序。
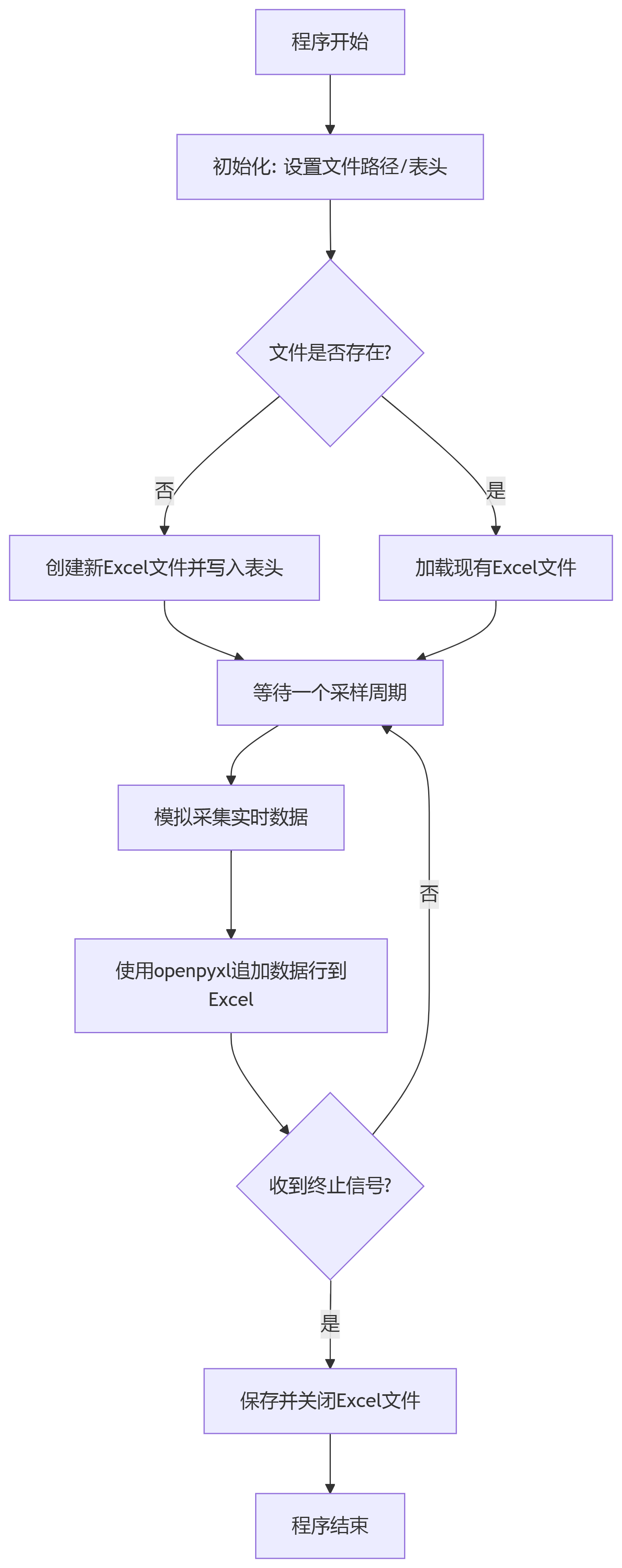
程序流程图
大家好好看看程序流程图,帮助厘清思路和理解后面的python程序。
以下是具体的python源程序代码,里面有非常详细的注释,可以复制到自己的开发环境里面去运行体验一下。
python
import pandas as pd
from openpyxl import load_workbook
import time
from datetime import datetime
import os
import schedule
class RealTimeExcelLogger:
def __init__(self, filename='real_time_data.xlsx'):
"""
初始化实时Excel记录器
:param filename: Excel文件名
"""
self.filename = filename
self.sheet_name = '监测数据'
self.headers = ['时间戳', '温度(°C)', '湿度(%RH)', '压力(kPa)']
# 初始化文件,如果文件不存在则创建
self._init_excel_file()
def _init_excel_file(self):
"""检查并初始化Excel文件,如果文件不存在则创建它并写入表头"""
if not os.path.exists(self.filename):
# 创建一个空的DataFrame,只包含表头
df = pd.DataFrame(columns=self.headers)
# 使用to_excel创建新文件
df.to_excel(self.filename, index=False, sheet_name=self.sheet_name)
print(f"新建文件并初始化表头: {self.filename}")
else:
print(f"文件已存在,将追加数据: {self.filename}")
def _get_simulated_data(self):
"""
模拟生成一条实时监测数据(替换此函数以连接真实数据源)
:return: 一个包含传感器数据的列表,顺序与self.headers一致
"""
# 模拟数据生成逻辑
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
temperature = round(25 + (5 * (time.time() % 1)), 2) # 在25°C附近波动
humidity = round(50 + (10 * ((time.time() + 1) % 1)), 2) # 在50%附近波动
pressure = round(101.3 + (0.5 * ((time.time() + 2) % 1)), 2) # 在101.3kPa附近波动
return [timestamp, temperature, humidity, pressure]
def _save_data_row(self, data_row):
"""
使用openpyxl将一条数据记录追加到Excel文件中
:param data_row: 要写入的数据列表
"""
# 加载现有工作簿
book = load_workbook(self.filename)
# 获取活动工作表或指定名称的工作表
writer = pd.ExcelWriter(self.filename, engine='openpyxl', mode='a', if_sheet_exists='overlay')
writer.book = book
writer.sheets = {ws.title: ws for ws in book.worksheets}
# 获取目标工作表
sheet = book[self.sheet_name]
# 找到下一个空行
next_row = sheet.max_row + 1
# 将数据写入对应的单元格
for col_num, value in enumerate(data_row, 1):
sheet.cell(row=next_row, column=col_num, value=value)
# 保存工作簿
book.save(self.filename)
print(f"数据已保存: {data_row}")
def job(self):
"""定时执行的任务:获取数据并保存"""
print("执行数据采集任务...")
data = self._get_simulated_data()
self._save_data_row(data)
def run(self, interval_seconds=5):
"""
运行主循环,定时采集数据
:param interval_seconds: 采集间隔时间(秒)
"""
print(f"开始实时监测,每 {interval_seconds} 秒记录一次数据。按 Ctrl+C 停止。")
# 使用schedule库进行调度
schedule.every(interval_seconds).seconds.do(self.job)
try:
# 先立即执行一次
self.job()
while True:
schedule.run_pending()
time.sleep(1) # 降低CPU占用
except KeyboardInterrupt:
print("\n程序被用户中断。")
finally:
print("数据记录已完成。")
# 主程序入口
if __name__ == "__main__":
# 创建记录器实例
logger = RealTimeExcelLogger('sensor_data.xlsx')
# 开始运行,每5秒记录一次
logger.run(interval_seconds=5)以下是运行结果:
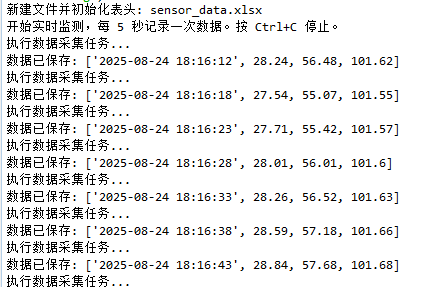
这是建立并已经写入的excel文件
三、实际应用建议
-
批量写入: 在高速数据采集场景(如每秒>10次),频繁打开保存Excel文件会成为性能瓶颈。建议在内存中缓存一定数量的数据(例如一个
list存100条),达到阈值后再一次性写入Excel,显著减少I/O操作。 -
文件分割: 对于长期运行的任务,可以考虑按日期或文件大小自动分割Excel文件,避免单个文件过大导致打开缓慢或损坏。
-
替代方案 - 数据库: 如果数据量非常大(百万条以上)或需要复杂查询,强烈建议使用数据库(如SQLite, PostgreSQL, InfluxDB)作为主存储,Excel仅用作导出和报表工具。数据库在处理并发写入、查询和数据完整性方面远胜于Excel。