微调(Finetuning) vs. 提示(Prompting):大型语言模型的两种方法

探讨了使用大型语言模型(LLM)的两种主要历史期望和由此产生的技术方法:微调(Finetuning) 和 提示(Prompting)。这两种方法会导致大型语言模型的结果和应用截然不同。
对大型语言模型的两种期望
人类历史上对大型语言模型有两种不同的期望:
-
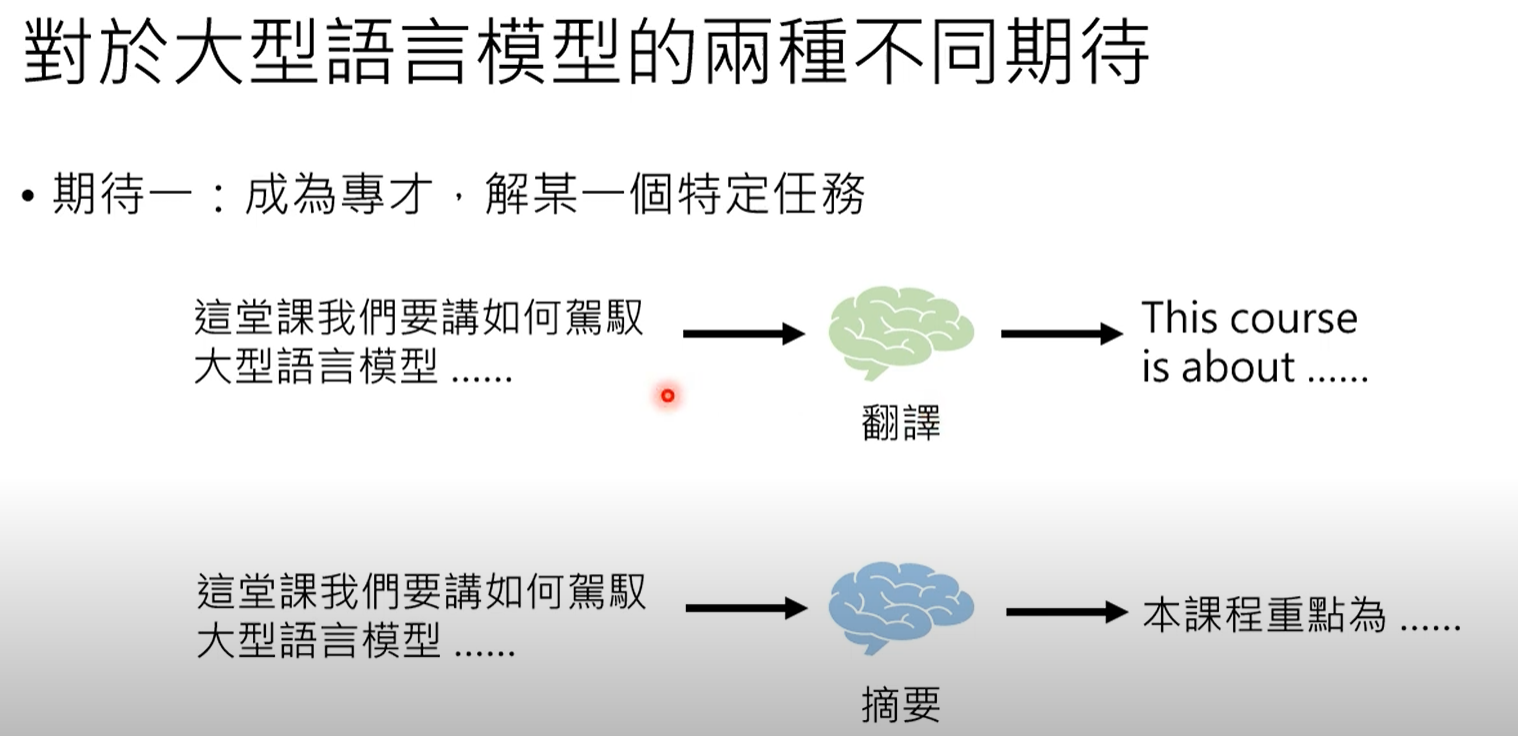
成为专家(微调) :第一个期望是让大型语言模型成为解决特定类型问题的专家,尤其是在自然语言处理(NLP)任务中。
-
范例:调整大型语言模型以专门从事翻译(例如,中文到英文)或摘要(缩短文章)。
-
比喻:这就像训练一头大象(大型语言模型)以高精度执行单一、特定的任务。
-
-
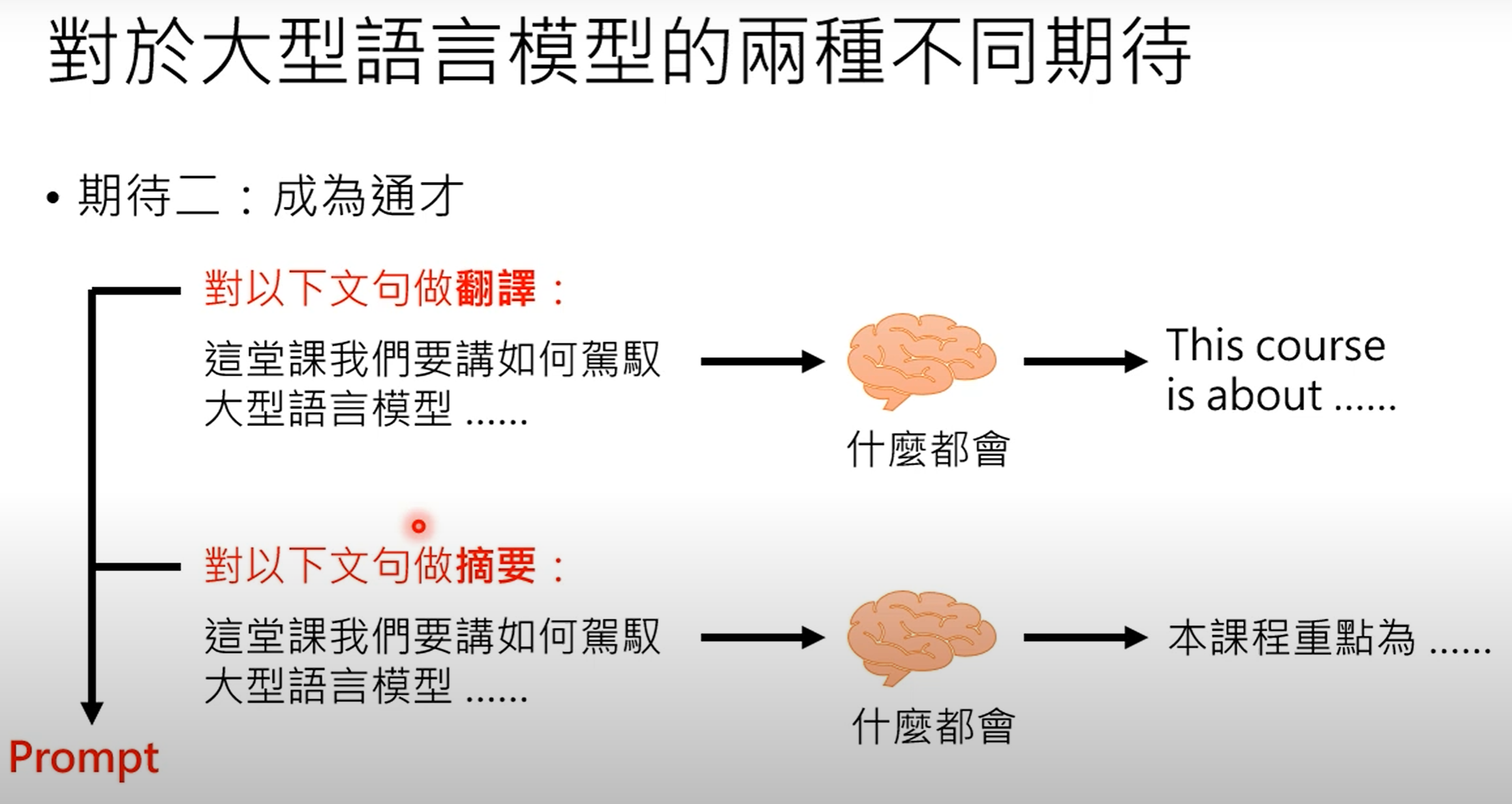
成为通才(提示) :第二个期望是让大型语言模型成为一个多才多艺的"万事通",能够做任何事情。
-
范例:给大型语言模型一个句子,然后提供一个人类可读的指令("提示"),告诉它要翻译还是摘要该句子。
-
比喻:这就像一头知道很多事情的大象(大型语言模型),但需要一只小老鼠(人类用户)用简单的指令来指导它该做什么。ChatGPT就是这种方法的典型例子。
-
通才思想的历史背景
将大型语言模型视为通才的想法并不新鲜:
-
自然语言十项全能(2018):这篇论文提出,所有自然语言处理问题都可以被视为问答任务。我们现在所说的"提示"在当时被称为"问题"。
-
问我任何事(2015):更早之前,这篇论文表达了一个雄心勃勃的信念,即单一模型可以回答任何问题,这个概念在当时似乎是科幻小说,但现在却与ChatGPT相似。
每种方法的优点
专家和通才方法各有优劣:
-
专家(微调)的优点:
-
在特定任务上表现更佳:专注于单一任务的模型在该特定领域的表现更有可能超越通才模型。
-
实证:腾讯和微软的研究表明,虽然ChatGPT可以翻译,但其表现通常不如专门的商业翻译系统,如Google翻译或DeepL,这些系统是专门为翻译而设计的。
-
-
通才(提示)的优点:
-
符合对AI的想象:这种方法很"时髦",能吸引公众的注意力,满足了人类对AI应有样貌的想象。
-
快速开发新功能:开发新的自然语言处理任务变得更快。用户不再需要编写代码,而是可以简单地使用人类语言来指示现有的通才模型。例如,要获得更短的摘要,您只需将提示修改为"用100个字摘要",而无需更改代码。
-
技术方法:微调 vs. 提示
这两种期望导致了两种截然不同的大型语言模型使用方式:
-
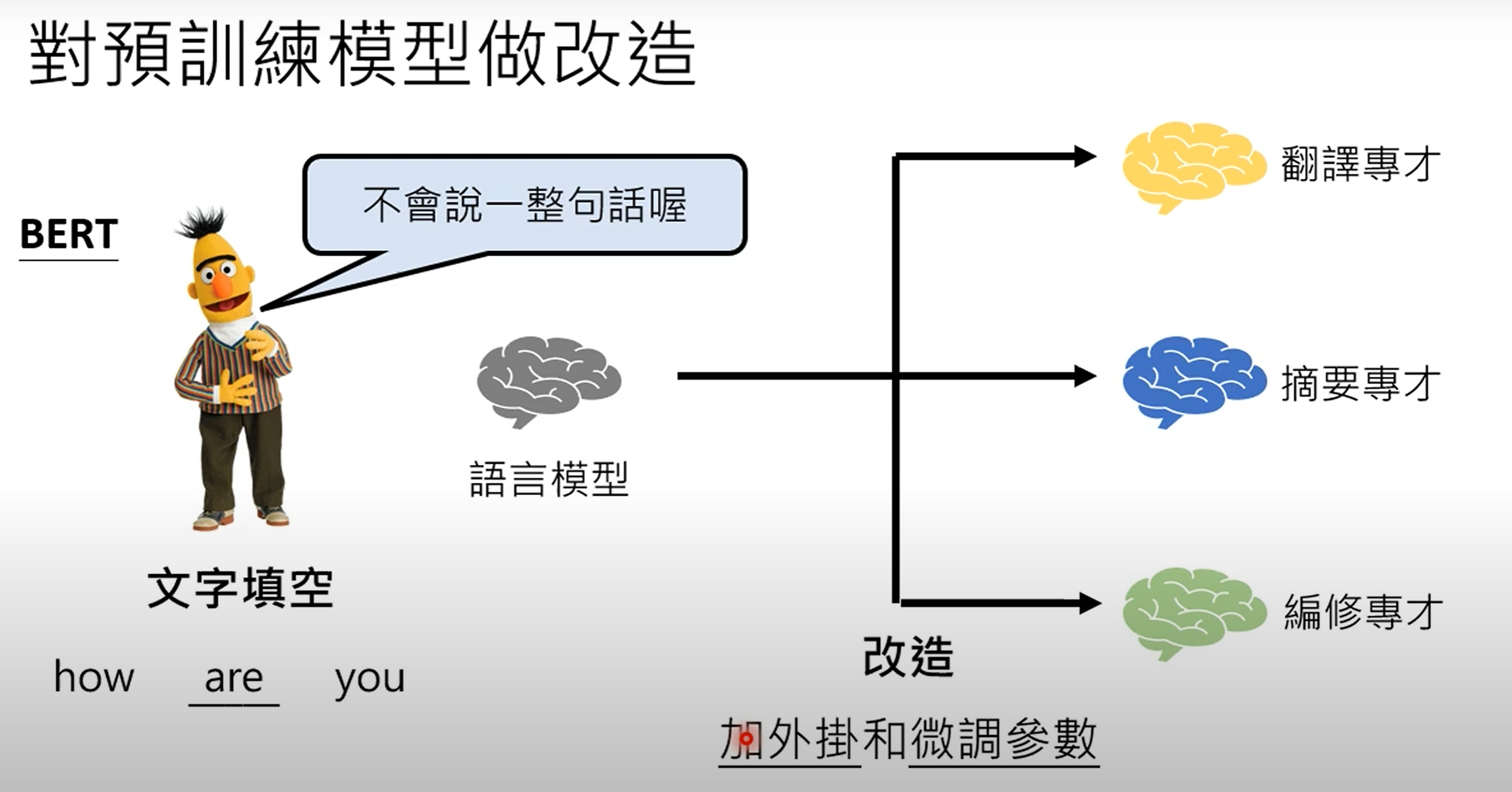
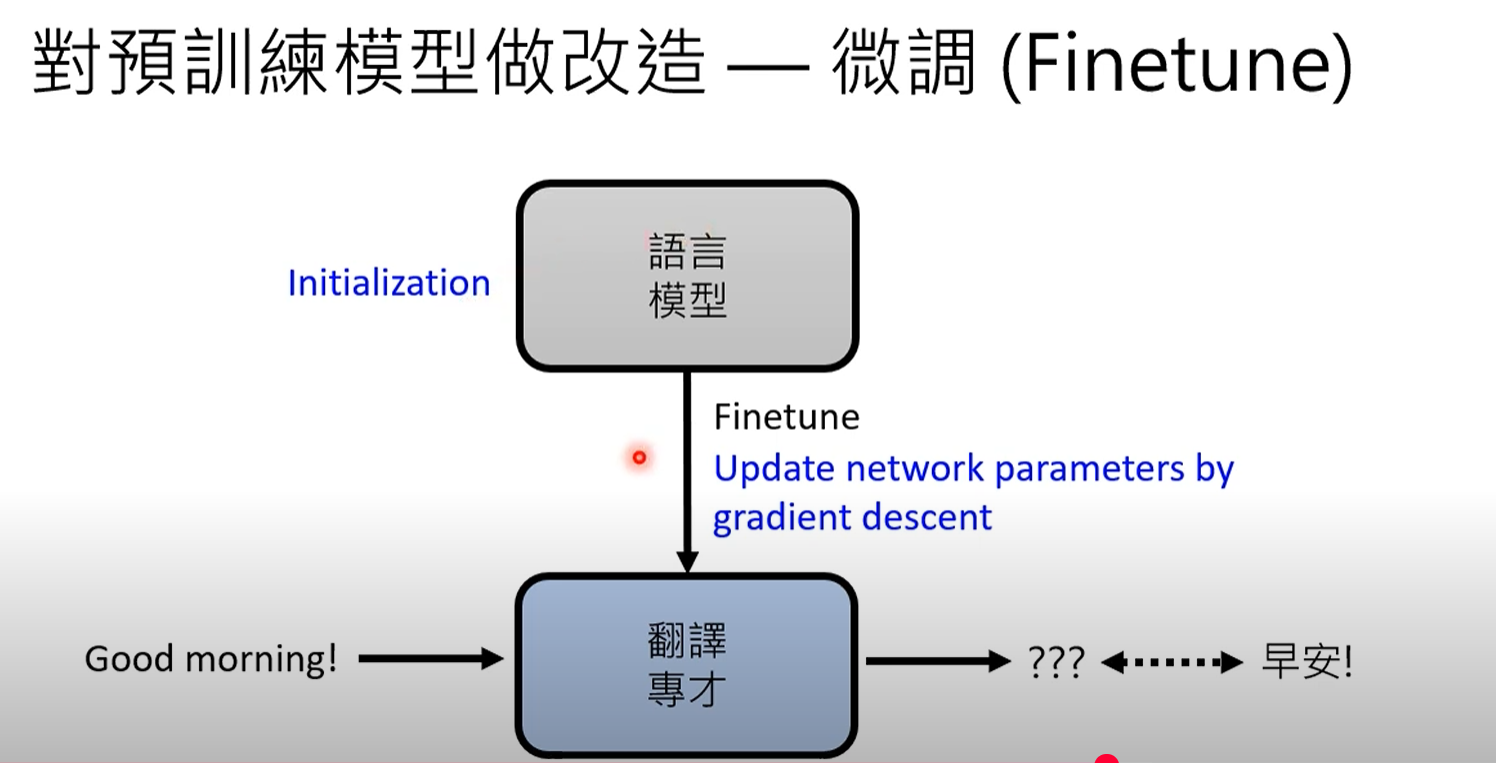
微调(用于专家) :
-
以BERT为例:像BERT这样执行"填空"任务的模型,通常在专家情境中使用。
-
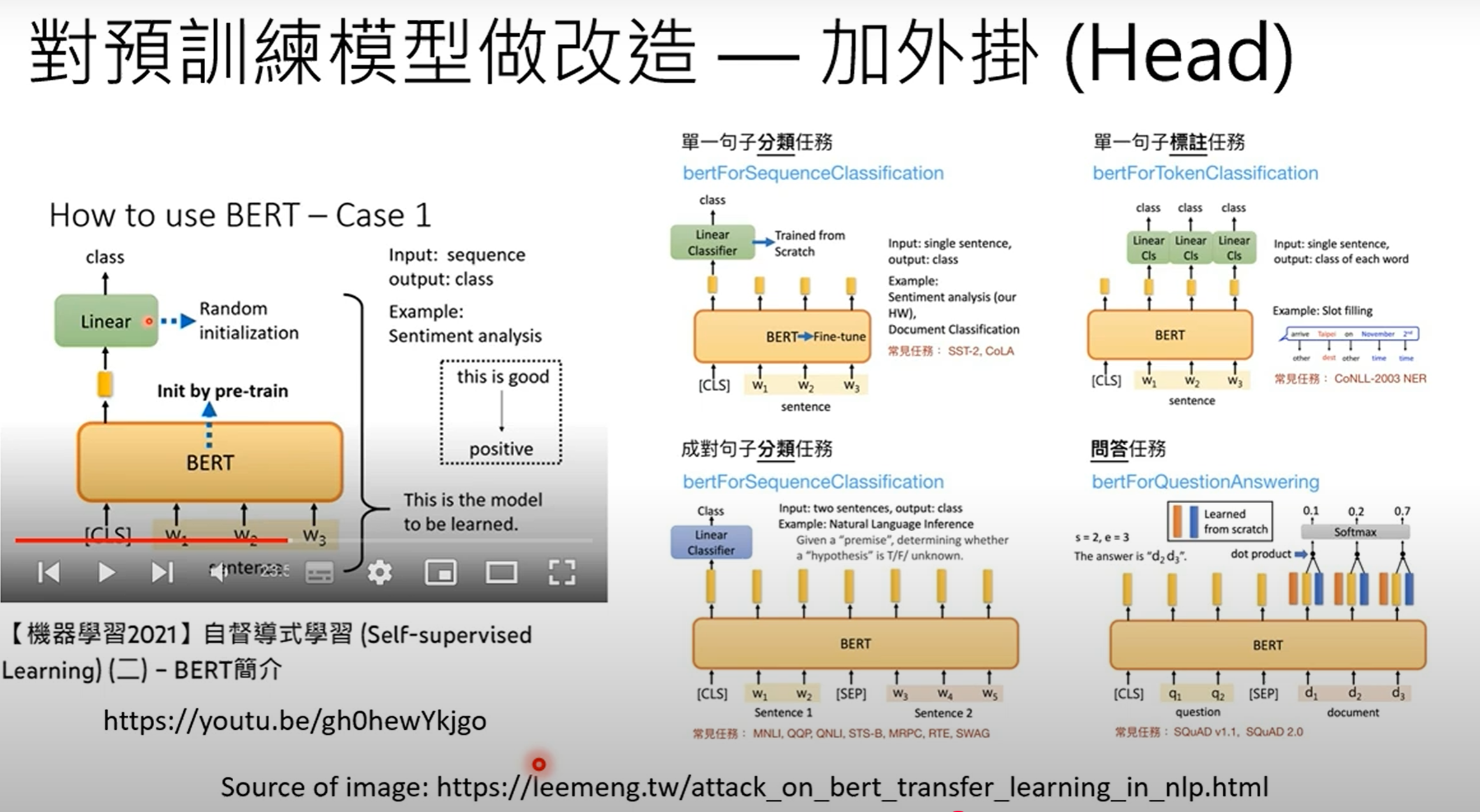
需要修改 :要让BERT成为专家,需要进行两项主要修改:
-
增加外部模块(插件):BERT本身无法生成完整的句子,因此需要"插件"或"外部模块"来使其能够产生完整的答案或执行翻译等任务。
-
参数微调:这涉及调整语言模型的内部参数。它基本上是运行梯度下降,使用预训练的大型语言模型参数作为初始点,然后用特定于任务的数据(例如,翻译配对)对其进行微调。
-
-
适配器(Adapters) :一种更有效的微调方法是使用"适配器"。
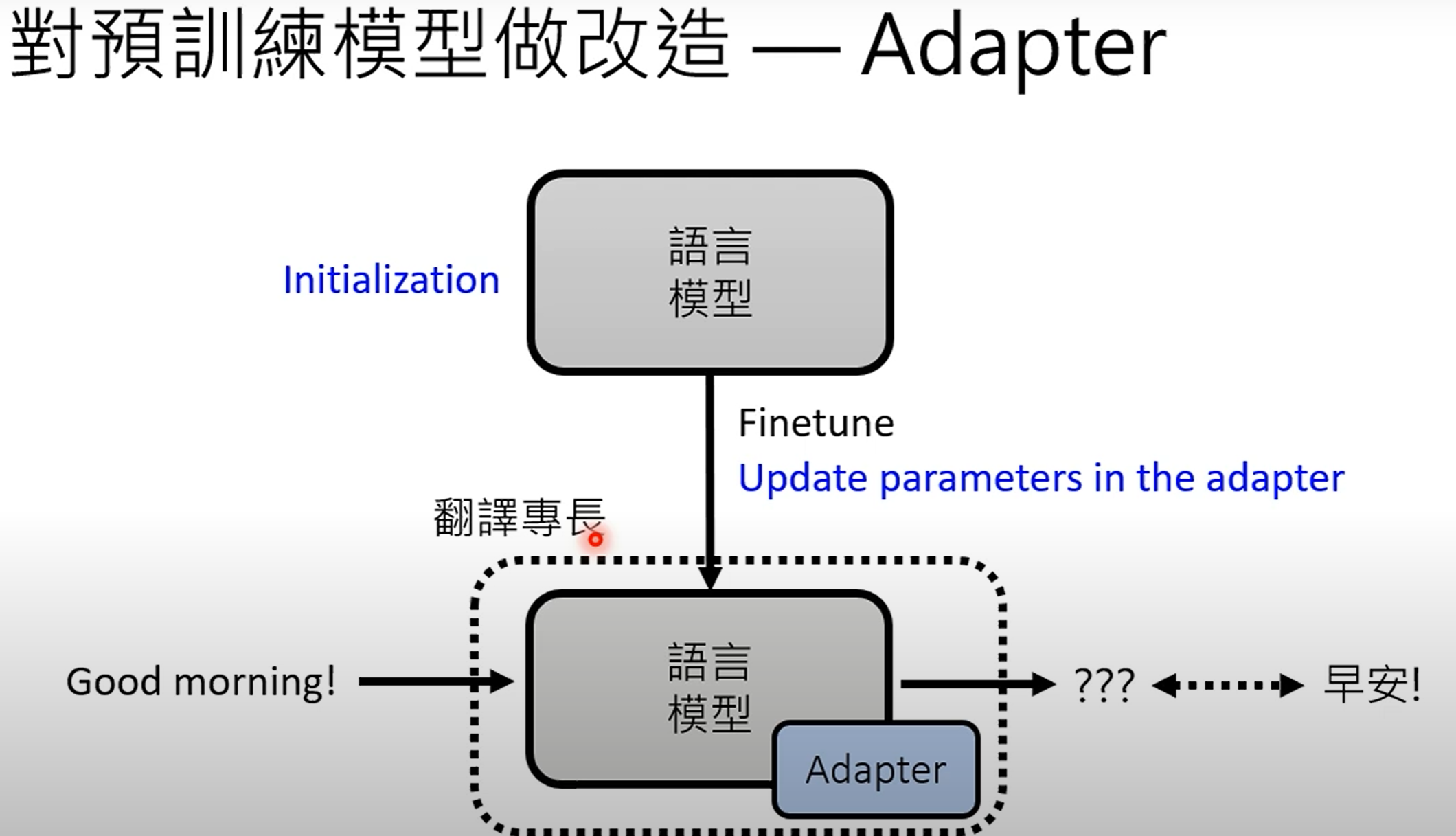
-
概念:不是修改所有大型语言模型参数,而是在模型中插入小型的附加模块(适配器)。
-
训练:在微调期间,只调整这些小型适配器模块内的参数,而主要的大型语言模型参数保持不变。
-
优点:这显著减少了存储需求。不需要为每个任务存储大型语言模型的完整副本,每个任务只需要存储小型适配器参数,这使得管理数百或数千个专门任务变得可行。适配器有多种类型,例如Bitfit、Houlsby、AdapterBias、Prefix tuning和LoRA。
-
-
-
提示(用于通才):
- 这种方法专注于使用人类语言指令(提示)来引导像ChatGPT这样的通才模型执行各种任务,而无需为每个特定任务微调其内部参数。
- 从技术上讲,一个"Prompt"(提示词)确实没有改变模型本身的内部参数。模型的代码和训练好的权重(weights)在您发送提示词时是固定不变的。
核心区别:是"改造模型"还是"调用能力"?
-
专家做法 (Finetuning - 微调) :这就像是把一个大学毕业生(预训练好的LLM)送去医学院深造,经过几年的专门训练,让他成为一名心脏外科医生。他的知识结构被深度改造了,变得非常擅长做心脏手术,但你如果让他去写诗或做财务分析,他可能已经不那么擅长了。这就是**"改造模型以适应任务"**。
-
-
通才做法 (Prompting - 提示):这就像是面对一位知识渊博、博览群书的通才学者(比如一个巨大的、预训练好的LLM,像GPT-4)。他本身就懂历史、会写作、能计算、也了解编程。
-
你不需要"改造"他。
-
你只需要通过清晰的指令(Prompt)来告诉他,你希望他调用他大脑里的哪一部分知识来为你服务。
-
当你给他一篇经济学文章说"请总结这篇文章",他调用的是他的阅读理解和归纳能力。
-
当你给他一行代码说"请解释这段代码的作用",他调用的是他的编程知识。
-
当你对他说"写一首关于月亮的诗",他又调用了他的文学创作能力。
-
这位学者(模型)本身没有变,但他能完成各种各样的任务。这种**"用一个模型应对多种任务"的使用方式**,就是所谓的"通才做法"。
总结一下:
-
"通才"不是指Prompt把模型变成了通才,而是指模型本身已经被训练成了一个"通才"。它在海量数据中学习了语言、逻辑、知识和多种技能的潜在模式。
-
Prompt的作用是"激活"和"引导"。它像一个开关或一个指令,告诉这个强大的通才模型:"嘿,现在请启动你的'翻译'技能"或者"现在请启动你的'创意写作'技能"。
解构大型语言模型:从"专才"到"通才"的进化之路
深入探讨了大型语言模型(LLM)一个激动人心的进化方向:它们如何从只能执行特定任务的"专才",演变为能够处理多种任务、更具通用性的"通才"人工智能。我们主要探索了两个核心概念:指令学习(Instruction Learning)和情境学习(In-context Learning),以及它们如何让机器像人类一样,根据描述和范例来理解并执行任务。
指令学习 vs. 情境学习
-
指令学习 (Instruction Learning):指机器根据任务的文字描述来做出回应的能力。
-
情境学习 (In-context Learning):指机器根据提供给它的具体范例来做出回应的能力。
"情境学习"的神秘之处
-
它是如何工作的:要执行一项任务(如情感分析),你只需给模型提供几个范例(例如:"今天天气真好,正面情绪;我好累,负面情绪"),然后附上你真正想分析的句子。模型会根据范例,预测新句子的情感。
-
学界的怀疑:一个关键问题是:机器真的能仅凭这些输入就学会新知识,而不需要经过梯度下降(gradient descent)这样的训练过程吗?
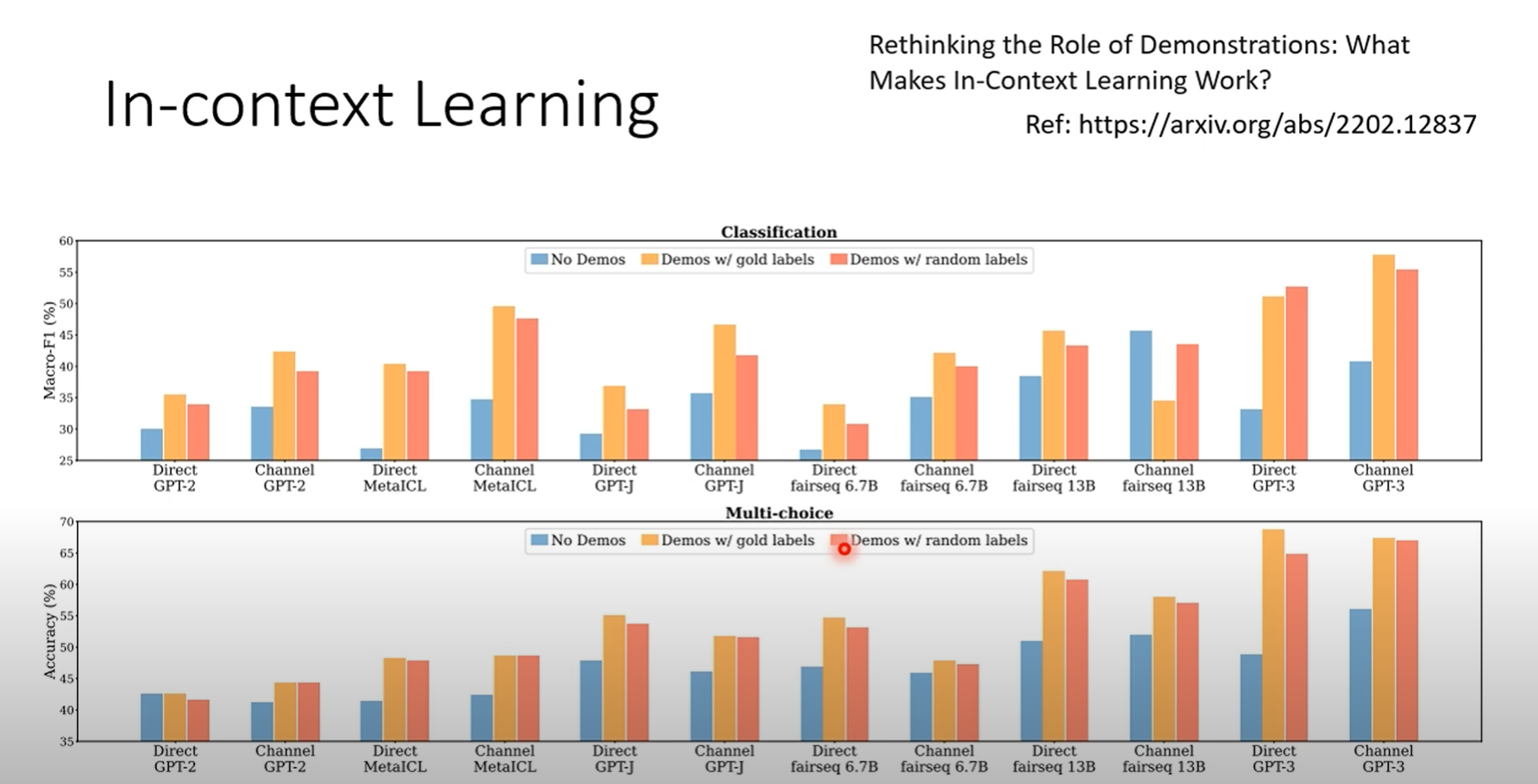
-
矛盾的研究结果:
-
一篇早期的研究论文《Rethinking the Role of Demonstration: What Makes In-Context Learning Work?》发现,即使在范例中提供错误的标签(比如把正面情绪标为负面),模型的准确率也不会大幅下降。这引出一个假说:范例的主要作用可能只是"激活"模型去执行某个特定类型的任务(比如情感分析),而不是真的在教它新知识。范例的数量似乎超过几个之后,效果也无明显提升。
-
然而,一篇更新的谷歌论文得出了截然不同的结论。研究发现,对于更大规模的模型(如拥有5400亿参数的PaLM),错误的范例会显著影响其表现,错误范例越多,表现越差。这表明,超大型模型确实能从提供的范例中进行学习。
-
更进一步,这些大模型甚至能从错误的数据中学习。例如,如果在范例中持续地将正面句子标记为负面,模型会学会这种"反向逻辑",并在预测时应用它。这证明了它是在真实地从上下文中学习,而非简单激活。
-
-
LLM作为分类器:令人惊讶的是,大型语言模型甚至可以充当分类器。只需将特征和标签作为纯文本喂给它,它就能为新的输入预测标签。虽然其性能不如专门的SVM等分类算法,但它仅凭文本就能学习分类任务的能力,本身就非常"神秘"。
指令微调:教会机器理解命令
虽然情境学习很强大,但对人类来说,直接下达指令是更自然的方式。这就引出了指令微调(Instruction Tuning)。
-
核心概念:在训练阶段,给模型提供各种各样的指令(例如,"请翻译"、"请总结")以及对应的正确输出。目标是让模型能够理解它从未见过的新指令,并做出正确的回应。
-
开创性模型:大约在2021年,由Hugging Face开发的T0模型和由谷歌开发的FLAN模型,是指令微调领域的早期先驱。
-
实现过程:
-
收集大量不同的自然语言处理(NLP)任务和数据集。
-
将这些任务用多种不同的人类语言风格改写成指令。例如,对于自然语言推理任务,可能会创造出十种不同的提问方式。
-
-
惊人成果:指令微调显著提升了模型对未知指令的泛化能力。经过指令微调的FLAN模型,在理解和执行新指令方面的表现,远超未经此项训练的GPT-3。
机器潜在地学习了构成"情感"的模式和知识**
1. 潜在能力的获得(预训练阶段)
在大型语言模型(比如GPT)的训练过程中,它阅读了几乎整个互联网的文本和海量书籍。在这个过程中,它并没有一个叫做"情感分析"的特定目标,但它通过统计规律,学到了:
-
词语关联性:它发现"开心"、"很棒"、"推荐"这些词经常和积极的语境一起出现。而"失望"、"糟糕"、"再也不会"这些词经常和负面的语境一起出现。
-
上下文模式 :它理解了"我本以为会很好,结果......"这种句式通常会引出负面评价。
所以,模型内部已经建立了一张巨大的、复杂的"概念关联网络"。它不知道这叫"情感分析" ,但它"知道"不同词语和句子所蕴含的正面或负面倾向。这是一种潜藏在模型深处的能力。
2. 特定能力的激活(提示阶段)
当您向它提问时,发生了两件事,这呼应了我们之前视频笔记的内容:
-
指令激活(Instruction):您通过"请分析这句话的情感"这样的指令,告诉模型:"嘿,请调用你脑中所有关于正面和负面语言模式的知识。" 这就像是给一个知识渊博的学者一个具体的课题,让他聚焦思考。
-
范例引导(In-context Learning):当您给出"今天天气真好 -> 正面"这样的范例时,您在做一件更重要的事情:
-
明确任务:您在告诉它,您不只是想聊天,而是要它做一个"输入->输出"的分类任务。
-
定义格式:您在告诉它,您希望的答案是"正面"或"负面"这两个词,而不是长篇大论的解释。
-
校准逻辑:正如视频中提到的,对于更强大的模型,它会从您的范例中学习具体的判断逻辑。如果您把所有正面例子都标为"A类",负面例子标为"B类",它就会学会用"A类"和"B类"来回答您。
-
更精确的回答是:机器本身具备了进行情感分析所需要的全部"原材料"(对语言的深刻理解),但它需要您的"指令"和"范例"作为"菜谱",才能将这些原材料烹饪成一道叫做"情感分析"的菜。
提示词工程
提示工程的高级技术
-
思维链提示(Chain of Thought Prompting, CoT):在提示中加入推理过程,引导模型一步步思考,从而解决复杂问题。
-
零样本思维链提示(Zero-shot CoT):在提示中加入"Let's think step by step"等指令,模型就能自动进行推理,无需提供任何示例。
-
自洽性(Self-consistency):让模型生成多个不同的推理路径和答案,然后通过多数投票或结合置信度分数来选择最终答案,进一步提高准确性。
-
列表到多数提示(List-to-most Prompting):将复杂问题分解为更简单的子问题,逐步解决,最终得出答案。
机器自动生成提示
-
硬提示(Hard Prompt):人类用自然语言编写的离散文本提示。
-
软提示(Soft Prompt):模型通过训练自动生成的连续向量,可以作为模型输入的一部分,并能通过任务特定的标注数据进行调整。
-
通过强化学习寻找提示:训练一个生成器来自动生成提示,通过评估大型语言模型的输出效果来给予奖励,从而优化生成器。
-
通过大型语言模型自身寻找提示:利用大型语言模型本身来"思考"并生成最佳提示。
Chain of Thought (CoT) Prompting
-
传统Prompt的局限性:在处理需要推理的问题,例如数学问题时,仅通过提供问题描述和答案(in-context learning)往往效果不佳。例如,直接给一个应用题和它的答案,模型很难在新的问题上得出正确答案。
-
Chain of Thought (CoT) 的概念:CoT是一种更详细的Prompt方法。在提供示例时,除了问题和答案,还会附带解题的推理过程。这样做的目的是让模型在遇到新问题时,能够自己生成推理过程,从而更容易得出正确答案。
-
CoT的有效性:根据文献资料,CoT在数学应用题上表现出色。例如,使用GPT-3进行微调(Fine-tuned GPT-3 175B)的正确率是33%,而使用更大型的PaLM 540B模型进行标准Prompting的正确率仅为18%。但如果使用Chain of Thought Prompting,PaLM 540B的正确率能提升到57%,甚至超越了微调的GPT-3。这表明,通过提供解题过程,即使是大型模型也能突然获得一定的推理能力。
CoT的变体:Zero-shot CoT和Self-consistency

-
Zero-shot CoT:这是一种更神奇的CoT变体。在某些情况下,即使不提供任何示例,仅仅在Prompt中加入"Let's think step by step"(让我们一步步思考)这样的指令,模型也能显著提升性能,因为这会促使模型进行内部推理。
-
Self-consistency (自我一致性):由于大型语言模型(如ChatGPT)在每次回答时都可能因随机性而产生不同的结果,Self-consistency方法可以利用这一点。它建议让模型对同一个问题生成多次答案,每次的推理过程和答案可能不同。如果不同的推理过程都导向相同的答案,那么该答案的可靠性就会更高。通过对多个答案进行多数投票(majority vote),可以有效提高答案的准确率。虽然也可以为每个答案计算置信度并进行加权投票,但研究表明,直接进行多数投票通常已经足够有效。
-
CoT与Self-consistency的结合:CoT可以增加模型输出的多样性。如果不使用CoT,模型可能每次都给出相似的错误答案。但如果结合CoT,模型会生成多样化的推理过程和答案,这时Self-consistency才能发挥其最大作用,通过多轮推理和投票,筛选出更可能正确的答案。这解释了为什么CoT通常是Self-consistency的前提。
-
应用实例:作者用一个鸡鸭兔同笼的数学问题在ChatGPT上进行实测。
-
直接告诉ChatGPT只给答案,不列计算过程(模仿标准Prompting),结果发现多次运行都得到相同的错误答案(18只)。
-
当指示ChatGPT列出详细计算过程(CoT),它能够正确地设置方程,但偶尔在解方程时出错,导致五次运行得到不同的错误答案(18, 8, 12, 7, 2)。这反而为Self-consistency提供了更多不同的结果进行选择。
-
List-to-most Prompting
-
概念:对于复杂的数学问题,List-to-most Prompting方法建议将大问题拆解成多个小问题。例如,在处理一道涉及爬滑水道时间、游乐园关门时间等复杂的应用题时,模型会被引导先解决"玩一次滑水道需要多长时间"这样的子问题。
-
实现方式:这种方法依然需要In-context Learning,即通过提供一些难度较大的数学问题及其分解为子问题的示例,来训练模型学习如何自动进行问题拆解。模型会将简化后的问题与原始问题结合,并逐步解决。
机器自动生成Prompt
-
Hard Prompt vs. Soft Prompt:
-
Hard Prompt:指我们通常使用的,由人类编写的文本指令,它是离散的。
-
Soft Prompt:是模型接收的额外输入,通常是一组连续的向量。这些向量不是人类可读的语言,但可以像模型参数一样进行训练和调整。这类似于将适配器(Adapter)放置在模型的输入端。Soft Prompt可以使模型更像一个"通才",能够灵活适应各种任务。
-
-
强化学习(Reinforcement Learning)寻找Prompt:一种自动生成Prompt的方法是使用强化学习。训练一个Generator模型来生成Prompt,这个Prompt会作为大型语言模型(如GPT-3)的输入。通过评估大型语言模型输出的好坏(Reward Function),Generator模型会不断学习如何生成更有效的Prompt,从而引导大型语言模型给出我们期望的答案。
-
大型语言模型自我生成Prompt:更先进的方法甚至不需要强化学习,直接让大型语言模型自己思考并生成Prompt。其原理是:向模型提供一系列输入和输出的示例,然后询问模型为了产生这些输出,它应该接收什么样的指令。模型会尝试推理出最合适的指令。
-
例子:如果你给模型输入"今天天气真好"并输出"正面",输入"今天运气真差"并输出"负面",然后问它什么指令能产生这些结果,它可能会回答"请判断这句话是正面还是负面"。
-
实践:研究发现,通过这种方式,机器能够生成非常强大的Prompt。例如,在一个数学问题上,机器生成了一个比人类设计的Prompt("Let's think step by step",正确率78%)更优的Prompt("Let's work this out in a step-by-step way to be sure we have the right answer",正确率82%),从而显著提高了模型性能。这甚至意味着人类可能不再需要担任"Prompt工程师"的角色,机器可以自己"催眠"自己。
-