1.需求分析
在日常教学和考试系统中,经常需要批量导入大量题目到系统中。手动逐条添加不仅效率低下,而且容易出错。因此我们需要一种能够从 Word 文档中批量导入题目的解决方案。
1.1 模板格式要求
Word模板采用指定排版格式,格式排版如下
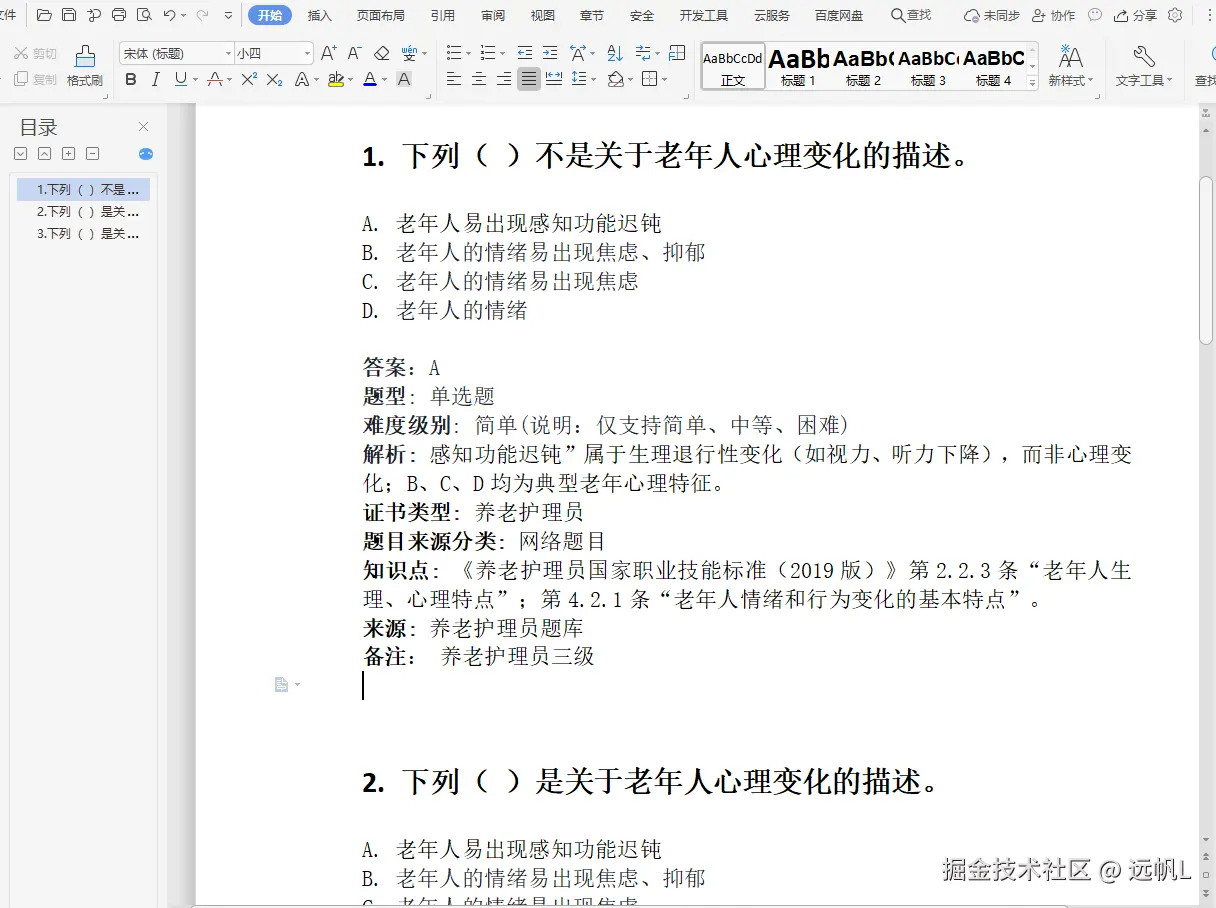
1.2 目标数据结构
最终需要将 Word 内容转换为以下 JSON 格式
json
[{
"questionContent": "题目内容",
"options": [
{"index": "A", "content": "选项A内容"},
{"index": "B", "content": "选项B内容"}
],
"answer": "正确答案",
"primaryQuesType": "题型",
"analysis": "解析内容",
"cardType": "证书类型",
"catalogue": "题目分类",
"knowledgePointsSimple": "知识点",
"source": "来源",
"remarks": "备注",
"quesLevel": "难度级别"
}]2. 实现方案
整体处理流程分为四个主要步骤:
js
const handleBatch = async () => {
// 1. 获取文件对象
const file = await readDocxFile()
// 2. 解析读取为html
const htmlString = await convertToHtml()
// 3. 解析成指定JSON格式
const targetJson = parseHtml()
// 4. 调用批量接口
// questionAPI.batchAdd(targetJson)
}2.1 获取文件对象
通过动态创建文件上传元素实现文件选择功能:
js
const readDocxFile = async () => {
return new Promise((resolve, reject) => {
const input = document.createElement("input");
input.type = "file";
input.accept = ".docx,.doc";
input.style.display = "none";
input.addEventListener("change", async (event) => {
const file = event.target.files[0];
if (!file) {
reject(new Error("未选择文件"));
return;
}
document.body.removeChild(input);
resolve(file);
});
// 添加到DOM并触发点击
document.body.appendChild(input);
input.click();
});
};2.2 解析Word文件为HTML
使用 mammoth.js 库将 Word 文档转换为 HTML 格式,该库支持多种输出格式:HTML格式、文本格式、Markdown格式。
预览效果地址 在浏览器中预览 word docx 文档示例 demo
github 链接 mwilliamson/mammoth.js
js
import mammoth from "mammoth";
const convertToHtml = async (file) => {
const arrayBuffer = await file.arrayBuffer();
// 解析为HTML
const result = await mammoth.convertToHtml({ arrayBuffer });
// 解析为Markdown
// const result = await mammoth.convertToMarkdown({ arrayBuffer })
// 解析为TEXT
// const result = await mammoth.extractRawText({ arrayBuffer })
return result.value
}转换效果对比:
- HTML格式:保留完整格式信息,适合进一步解析
- Text格式:纯文本内容,丢失格式信息
- Markdown格式:转换为Markdown语法,适合文档处理
html格式结果
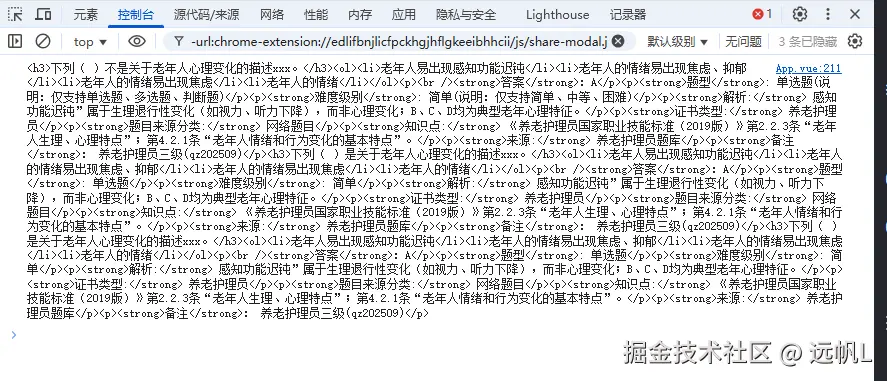
text格式结果

markdown格式结果

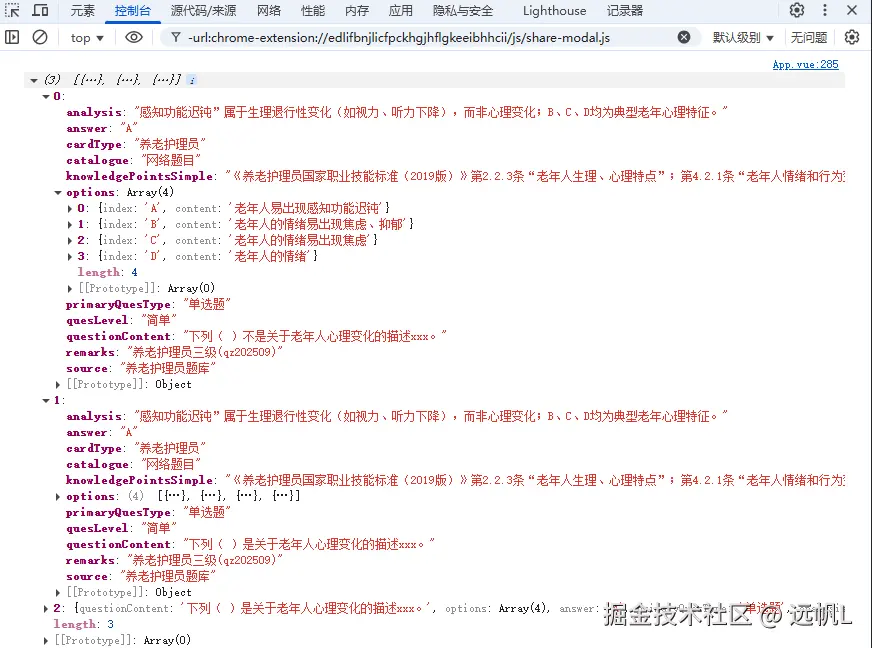
2.3 解析HTML为JSON格式
转换后的HTML内容解析为目标JSON结构:
js
/**
* 数字转换为字母(1->A, 2->B, ...)
* @param {number} num 数字
* @returns {string} 对应字母
*/
const numberToLetter = (num) => { return String.fromCharCode(64 + num); };
/**
* 解析HTML内容为题目JSON数组
* @param {string} html HTML内容
* @returns {Array} 题目对象数组
*/
const parseHtml = (html) => {
const parser = new DOMParser();
const doc = parser.parseFromString(html, "text/html");
const questions = [];
// 获取所有h3标题(每个题目一个)
const questionHeaders = doc.querySelectorAll("h3");
questionHeaders.forEach((header) => {
const question = {
questionContent: "",
options: [],
answer: "",
primaryQuesType: "",
analysis: "",
cardType: "",
catalogue: "",
knowledgePointsSimple: "",
source: "",
remarks: "",
quesLevel: "",
};
// 提取题目
question.questionContent = header.textContent.trim();
// 提取选项(紧随h3后面的ol中的li)
const optionsList = header.nextElementSibling;
if (optionsList && optionsList.tagName === "OL") {
const optionItems = optionsList.querySelectorAll("li");
optionItems.forEach((item, index) => {
question.options.push({
index: numberToLetter(index + 1),
content: item.textContent.trim(),
});
});
}
// 提取答案和其他信息(在ol后面的p中)
let nextElement = optionsList ? optionsList.nextElementSibling : null;
while (nextElement) {
if (nextElement.tagName === "P") {
const content = nextElement.textContent.trim();
if (content.startsWith("答案")) {
question.answer = content.replace("答案:", "").trim();
} else if (content.startsWith("题型")) {
question.primaryQuesType = content.replace("题型:", "").trim();
} else if (content.includes("解析:")) {
question.analysis = content.replace("解析:", "").trim();
} else if (content.startsWith("证书类型:")) {
question.cardType = content.replace("证书类型:", "").trim();
} else if (content.startsWith("题目来源分类:")) {
question.catalogue = content.replace("题目来源分类:", "").trim();
} else if (content.startsWith("知识点:")) {
question.knowledgePointsSimple = content.replace("知识点:", "").trim();
} else if (content.startsWith("来源:")) {
question.source = content.replace("来源:", "").trim();
} else if (content.startsWith("备注")) {
question.remarks = content.replace("备注:", "").trim();
} else if (content.startsWith("难度级别")) {
question.quesLevel = content.replace("难度级别: ", "").trim();
}
}
nextElement = nextElement.nextElementSibling;
}
questions.push(question);
});
return questions;
};
2.4 批量上传接口调用
获取到格式化后的JSON数据后,调用后端批量上传接口
3.图片多模态类扩展支持
对于包含图片的题目,需要特殊处理:
3.1 图片提取与上传
Word中的图片会被mammoth.js转换为base64格式的img标签:
html
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..." alt="示例图片">需将其上传为在线地址,处理方案:
js
/**
* 处理HTML中的图片,将base64转换为网络URL
* @param {string} html HTML内容
* @returns {Promise<string>} 处理后的HTML
*/
const processImages = async (html) => {
const parser = new DOMParser();
const doc = parser.parseFromString(html, "text/html");
const images = doc.querySelectorAll('img[src^="data:image/"]');
for (const img of images) {
const base64Data = img.src;
try {
// 将base64转换为File对象
const file = base64ToFile(base64Data, `image_${Date.now()}.png`);
// 上传文件到服务器
const imageUrl = await uploadFile(file);
// 替换src为网络URL
img.src = imageUrl;
} catch (error) {
console.error('图片处理失败:', error);
// 可选:移除失败的图片或保留base64格式
img.remove();
}
}
return doc.documentElement.outerHTML;
};
/**
* 将base64字符串转换为File对象
* @param {string} base64 base64字符串
* @param {string} filename 文件名
* @returns {File} 文件对象
*/
const base64ToFile = (base64, filename) => {
const arr = base64.split(',');
const mime = arr[0].match(/:(.*?);/)[1];
const bstr = atob(arr[1]);
let n = bstr.length;
const u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
return new File([u8arr], filename, { type: mime });
};3.2 集成图片处理的完整流程
js
const handleBatchWithImages = async () => {
try {
// 1. 获取文件对象
const file = await readDocxFile();
// 2. 解析为HTML
const htmlString = await convertToHtml(file);
// 3. 处理图片并获取替换后的HTML
const processedHtml = await processImages(htmlString);
// 4. 解析为JSON格式
const targetJson = parseHtml(processedHtml);
// 5. 批量上传
const result = await batchUploadQuestions(targetJson);
return result;
} catch (error) {
console.error('批量处理失败:', error);
throw error;
}
};