一、核心功能
- FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
模型下载地址:funasr/paraformer-zh-streaming · HF Mirror
二、安装教程
pip3 install -U funasr
或者
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
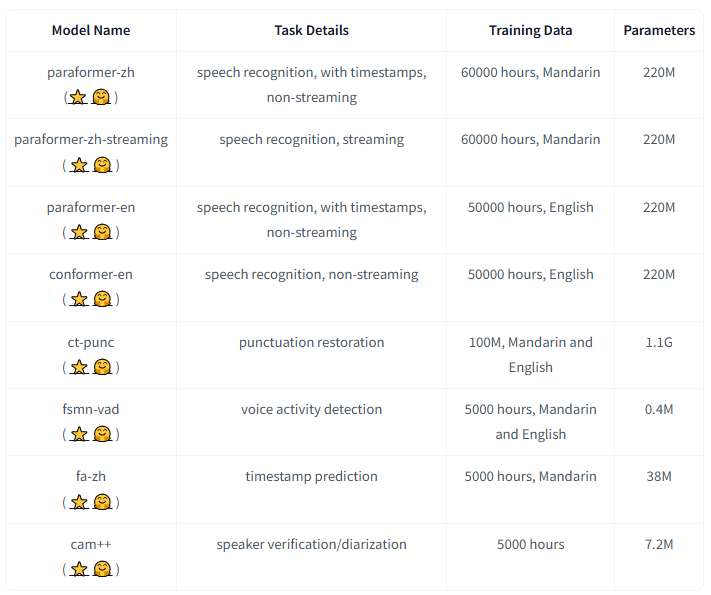
pip3 install -U modelscope三、模型仓库
四、上手教程
1.可执行命令行
funasr +model=paraformer-zh +vad_model="fsmn-vad" +punc_model="ct-punc" +input=asr_example_zh.wav2.非实时语音识别
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
# spk_model="cam++", spk_model_revision="v2.0.2",
)
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
batch_size_s=300,
hotword='魔搭')
print(res)3.实时语音识别
from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model="paraformer-zh-streaming", model_revision="v2.0.4")
import soundfile
import os
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)4.语音端点检测(非实时)
from funasr import AutoModel
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
wav_file = f"{model.model_path}/example/asr_example.wav"
res = model.generate(input=wav_file)
print(res)5.语音端点检测(实时)
from funasr import AutoModel
chunk_size = 200 # ms
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
import soundfile
wav_file = f"{model.model_path}/example/vad_example.wav"
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = int(chunk_size * sample_rate / 1000)
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
if len(res[0]["value"]):
print(res)6.标点恢复
from funasr import AutoModel
model = AutoModel(model="ct-punc", model_revision="v2.0.4")
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
print(res)7.时间戳预测
from funasr import AutoModel
model = AutoModel(model="fa-zh", model_revision="v2.0.4")
wav_file = f"{model.model_path}/example/asr_example.wav"
text_file = f"{model.model_path}/example/text.txt"
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
print(res)8.情感识别
from funasr import AutoModel
model = AutoModel(model="emotion2vec_plus_large")
wav_file = f"{model.model_path}/example/test.wav"
res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False)
print(res)