基本信息
题目:GS-SDF: LiDAR-Augmented Gaussian Splatting and Neural SDF for Geometrically Consistent Rendering and Reconstruction
来源:IROS2025
学校:HKU-MARS
是否开源:https://github.com/hku-mars/GS-SDF
摘要:激光+3DGS+NeRF,快速渲染,重建效果佳
数字孪生是自动驾驶和具身人工智能发展的基础。然而,实现高颗粒度表面重建和高保真渲染仍然是一个挑战。GS提供了高效的真实感绘制,但在机器人应用中,由于碎片化的基元和稀疏的观测数据,几何不一致的问题很难解决。现有的依赖于渲染导出约束的正则化方法在复杂环境中往往失效。此外,将稀疏的LiDAR数据与GS有效地集成仍然具有挑战性。我们提出了一个将高斯GS与神经符号距离场协同的统一LiDAR -视觉系统。精确的LiDAR点云使得一个训练好的神经符号距离场可以提供一个流形几何场,这促使我们提供一个基于SDF的高斯初始化用于物理接地的图元放置,以及一个综合的几何正则化用于几何一致的绘制和重建。实验表明,该方法在不同轨迹上具有较高的重建精度和绘制质量。
Introduction

引言讨论了3D表面重建和光真实渲染在增强现实(AR)和具身AI中的应用。LiDAR-视觉SLAM(如FAST-LIVO2)产生彩色点云,但缺乏完整表面和视图相关合成能力。NeRFs计算密集,不适合实时;3DGS高效但碎片化,导致几何不一致,尤其在机器人自由轨迹的稀疏观测下。现有正则化(如2DGS的渲染正常一致性或PGSR的多视图对齐)局限于物体中心场景。深度相机精度低,LiDAR稀疏整合难。NSDF与LiDAR结合显示潜力,提供流形几何场,用于高斯初始化和双向监督。贡献包括:
- 统一LiDAR-视觉系统,实现几何一致渲染和高粒度重建。
- 基于NSDF的物理基础高斯初始化,提升收敛并减少浮动伪影。
- 全面形状正则化,提供NSDF和高斯间的双向监督。
图1展示了输入点云、表面重建、高斯溅射分布和新视图合成结果。
Related Works
几何一致的新视图合成(Geometrically Consistent Novel View Synthesis):NeRFs和3DGS擅长渲染,但易产生浮动伪影。2DGS通过正常-深度对齐正则化,PGSR确保多视图一致。RGBD相机用于NeRF和3DGS,但限于室内;LiDAR用于NeRF(如M2Mapping通过NSDF和射线行进),或3DGS(如LIV-GaussMap用平面先验,LI-GS用高斯混合模型)。
表面重建(Surface Reconstruction):点云主导,使用TSDF融合或隐式表示(如泊松函数或NSDF)。3DGS的离散性复杂化重建,SuGaR和GOF通过密度/不透明场,但计算低效。TSDF融合用于3DGS,但精度不足。图像驱动NSDF与3DGS结合(如GSDF)仍在探索。
Method
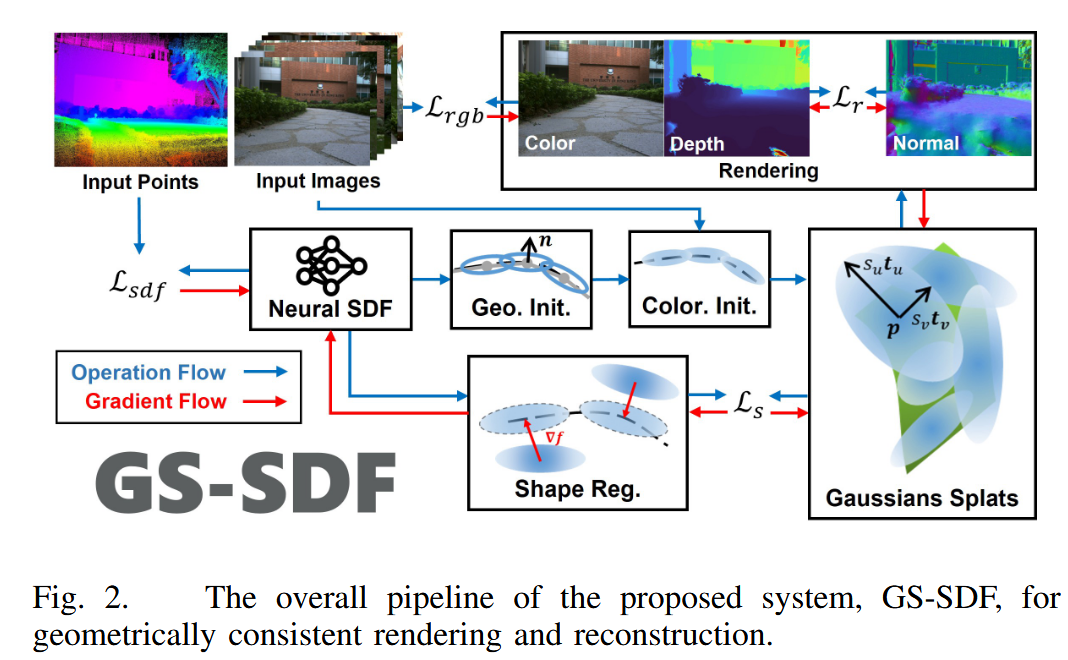
论文pipeline如图2所示:先用点云训练粗NSDF,建立流形几何场;然后从NSDF初始化高斯溅射;最后通过SDF辅助形状正则化,实现几何一致渲染和重建。系统使用2DGS表示场景。
A. 2D Gaussian Splatting

B. Neural Signed Distance Field

什么是 NeRF?
NeRF 是一种用神经网络(比如多层感知机 MLP)从一堆 2D 照片重建 3D 场景的技术。它不是直接存储 3D 模型,而是用一个"隐式函数"(像一个数学公式)来描述场景的外观(颜色、光照)和几何形状(位置、密度)。简单说,它就像一个智能的"照片合成器":输入几张从不同角度拍的照片,NeRF 就能学会整个场景的 3D 表示,然后从任意新角度生成逼真的新照片。
- 为什么有用? 传统方法(如用三角网格建模)需要大量数据和计算,而 NeRF 高效,能处理复杂的光照和反射,比如玻璃的反光或阴影的变化。
- 怎么工作? NeRF 把 3D 空间中的每个点(x, y, z)和观察方向(从哪个角度看)输入神经网络,输出这个点的颜色和密度(密度决定它是否"实心",像雾气密度)。通过"体积渲染"(像光线追踪),它合成图像。
- 例子:想象你拍了 10 张苹果的不同角度照片。NeRF 训练后,能生成从苹果上方或侧面看的"新照片",甚至模拟不同光照下的样子。这在 VR、电影特效或机器人导航中很实用,比如让机器人从有限照片"想象"整个房间。
论文中提到 NeRF 是高保真渲染的先驱,但计算密集,不适合实时应用,所以他们用 3DGS(Gaussian Splatting)替代,但结合 NSDF 来改善几何一致性。
什么是 TSDF?
TSDF 是"截断符号距离函数"的缩写,用于从深度数据(如摄像头或 LiDAR 扫描)重建 3D 表面。它把 3D 空间分 成小格子(叫体素,像 3D 像素),每个格子存储一个值:这个点到最近表面的"符号距离"(signed distance)。距离是正的(在表面外)、负的(在表面内),并"截断"(truncated)到一个固定范围(如只关心表面附近 1 米内),这样节省计算,避免处理无限空间。
- 为什么有用? 它能"融合"多张深度图成一个光滑的 3D 模型,适合实时重建表面,比如机器人建地图。
- 怎么工作? SDF(Signed Distance Function)基础是:对于空间中任意点,计算到最近表面的距离(正/负表示内外)。TSDF 把这个距离截断(远处的点设为固定值),然后用加权平均融合新数据。表面就是距离为 0 的地方。
- 例子:用 Kinect 摄像头扫描一个房间。TSDF 会把空间分成网格:墙壁附近的格子距离小(接近 0),房间内部负值,外部正值。通过多次扫描融合,你得到一个光滑的 3D 墙壁模型,而不只是散乱点云。这在 AR(如虚拟家具放置)或机器人避障中常见,比如 KinectFusion 系统就用 TSDF 实时建地图。
详细解释 Neural Signed Distance Field 小节(III-B)
论文中提到 TSDF 常用于从 Gaussian Splatting 渲染的深度图重建表面,但精度不足,所以他们用 NSDF 替代,提供更精确的流形几何场。
这个小节是论文方法论的核心部分,描述如何用神经网络构建 NSDF(Neural Signed Distance Field,神经符号距离场)。NSDF 是 SDF 的"神经版":不是用传统网格存储距离,而是用一个神经网络"学习"整个 3D 空间的符号距离场。这样更灵活,能处理大规模场景。
我用通俗易懂的方式一步步解释,避免数学公式直接扔出来,而是先解释概念,再带公式,最后给例子。原小节内容简短,但涉及训练细节,我会拆解。
1. NSDF 的构建:用什么工具?
- 通俗解释:他们用"哈希编码"(hash encoding,一种高效的位置编码方式,像给 3D 点打上快速标签)和"多层感知机"(MLPs,简单神经网络,像层层过滤信息的"黑盒")来建一个网络,叫 f(x)。输入是一个 3D 点 x(坐标如 (x, y, z)),输出两个值:s(signed distance,符号距离,到最近表面的距离,正/负表示内外)和 β(scale factor,尺度因子,像控制距离过渡的"锐度"调节器)。
- 为什么这样? 哈希编码让网络快速处理大空间(不像传统网格吃内存),MLP 学会复杂形状。
- 公式:(s, β) = f(x),其中 x ∈ ℝ³(3D 点),s ∈ ℝ(距离),β ∈ ℝ(尺度)。
- 例子:想象一个苹果的 3D 模型。输入苹果中心点 x,f(x) 输出 s = -0.5(负值,意思在内部,距离表面 0.5 单位)和 β = 0.1(小 β 意味着表面锐利,像真苹果皮)。
2. 训练数据:用 LiDAR 测量
- 通俗解释:LiDAR(如激光雷达)发出一束射线,从原点(传感器位置)沿方向射出,到物体表面距离 t。沿着这条射线,他们均匀采样几个点(比如 8 个),每个点 x_i = 原点 + t_i * 方向(t_i 是采样距离)。
- 为什么采样? LiDAR 只给表面点,但训练需要知道射线沿途的"空闲空间"和"占用空间"(表面附近)。
- 公式:射线:原点 o^L,方向 d^L,距离 t。采样 {t_i : x_i^L = o^L + t_i d^L}。
- 例子:LiDAR 扫描墙壁,射线从传感器到墙距离 t=2 米。采样点:t_i=0.5(半途,空闲),t_i=1.9(近表面),t_i=2.1(墙后,但 LiDAR 不直接测)。
3. 网络预测和真值转换
- 通俗解释:对每个采样点 x_i,网络预测 (s_i, β_i) = f(x_i)。现在,需要比较预测和"真值"。真值距离 \bar{s}_i = t - t_i(从采样点到表面剩余距离)。然后,用 sigmoid 函数(一种 S 形曲线,把值压缩到 0-1)转换成"占用值"(occupancy,像概率:1 表示占用/表面,0 表示空闲)。sigmoid 用 -距离/β 计算,β 控制曲线陡峭度(小 β 更锐利)。
- 公式 :
- 真值占用 \bar{o}_i = Φ(- \bar{s}_i, β_i),其中 Φ(v, h) = 1 / (1 + exp(-v / h))(sigmoid 函数)。
- 预测占用 o_i = Φ(- s_i, β_i)。
- 例子:采样点离表面 0.1 米,\bar{s}_i=0.1。如果 β=0.05(锐利),\bar{o}_i 接近 1(占用);如果远 1 米,\bar{o}_i 接近 0(空闲)。网络预测 s_i,如果匹配好,o_i 也匹配。
4. 训练损失:二元交叉熵(BCE)
- 通俗解释:网络通过"损失函数"学习:比较预测占用 o_i 和真值 \bar{o}_i。BCE 损失像一个"匹配度惩罚":如果预测说"占用"但真值是"空闲",就罚分。目标是让网络的 s 和 β 越来越准。
- 公式: Lsdf=−∑i=1oilog(oˉi)+(1−oi)log(1−oˉi)\mathcal{L}{sdf} = -\sum{i=1} \left o_i \\log(\\bar{o}_i) + (1 - o_i) \\log(1 - \\bar{o}_i) \\rightLsdf=−i=1∑oilog(oˉi)+(1−oi)log(1−oˉi) (标准 BCE,鼓励 o_i 接近 \bar{o}_i)。
- 例子:如果网络预测一个空闲点为占用,损失大,网络调整权重。下次预测更准,就像教 AI "这个点不在表面,别乱猜"。
5. Eikonal 正则化:确保梯度单位模
- 通俗解释:SDF 有个数学规则:距离场的梯度(变化率)模长必须是 1(单位长度),意思距离每移动一单位,s 变化 1。这像确保地图"比例尺"准确。他们加一个正则项,惩罚梯度不是 1 的情况。
- 公式: Le=∑i=1(∥∇f(xi)∥2−1)2\mathcal{L}e = \sum{i=1} (\|\nabla f(\mathbf{x}_i)\|_2 - 1)^2Le=i=1∑(∥∇f(xi)∥2−1)2 (|\nabla f| 是梯度模,平方误差让它接近 1)。
- 例子:如果梯度是 2(变化太快),像地图比例不对,重建的苹果会变形。正则化让它变回 1,确保表面光滑真实。
整体训练过程总结
- 先用 LiDAR 点云训练 NSDF(10000 次迭代),得到一个粗的距离场。
- 这个场像一个"隐形地图":任意点查距离,表面是 s=0 的地方。
- 优势:比 TSDF 更精确(神经网络学复杂形状),比 NeRF 更专注几何(不处理颜色,只距离)。
- 例子完整场景:扫描一个办公室。NSDF 学会:桌子上的点 s>0(外),桌子内部 s<0。β 小的地方表面锐利(如边缘)。训练后,从 NSDF 提取网格(用 marching cubes,像切蛋糕找表面),用于初始化 Gaussian Splats。
C. Initialization of Gaussian Splats

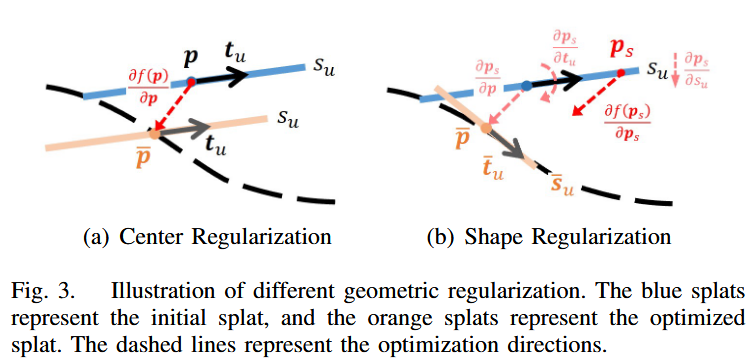
D. Geometric Regularization for Rendering
基于栅格化的GS渲染会导致前景元素模糊背景内容的遮挡伪影。几何正则化旨在保持不同视图的渲染一致性,以避免这种伪影。考虑到LiDAR结构先验并非处处可得,我们在2D空间中结合基于渲染的正则化,在3D空间中结合SDF辅助的形状正则化,以保证几何一致的渲染。

E. Optimization

实验
硬件平台
基于LibTorch/CUDA,Intel i7-13700K + RTX 4090。
数据集
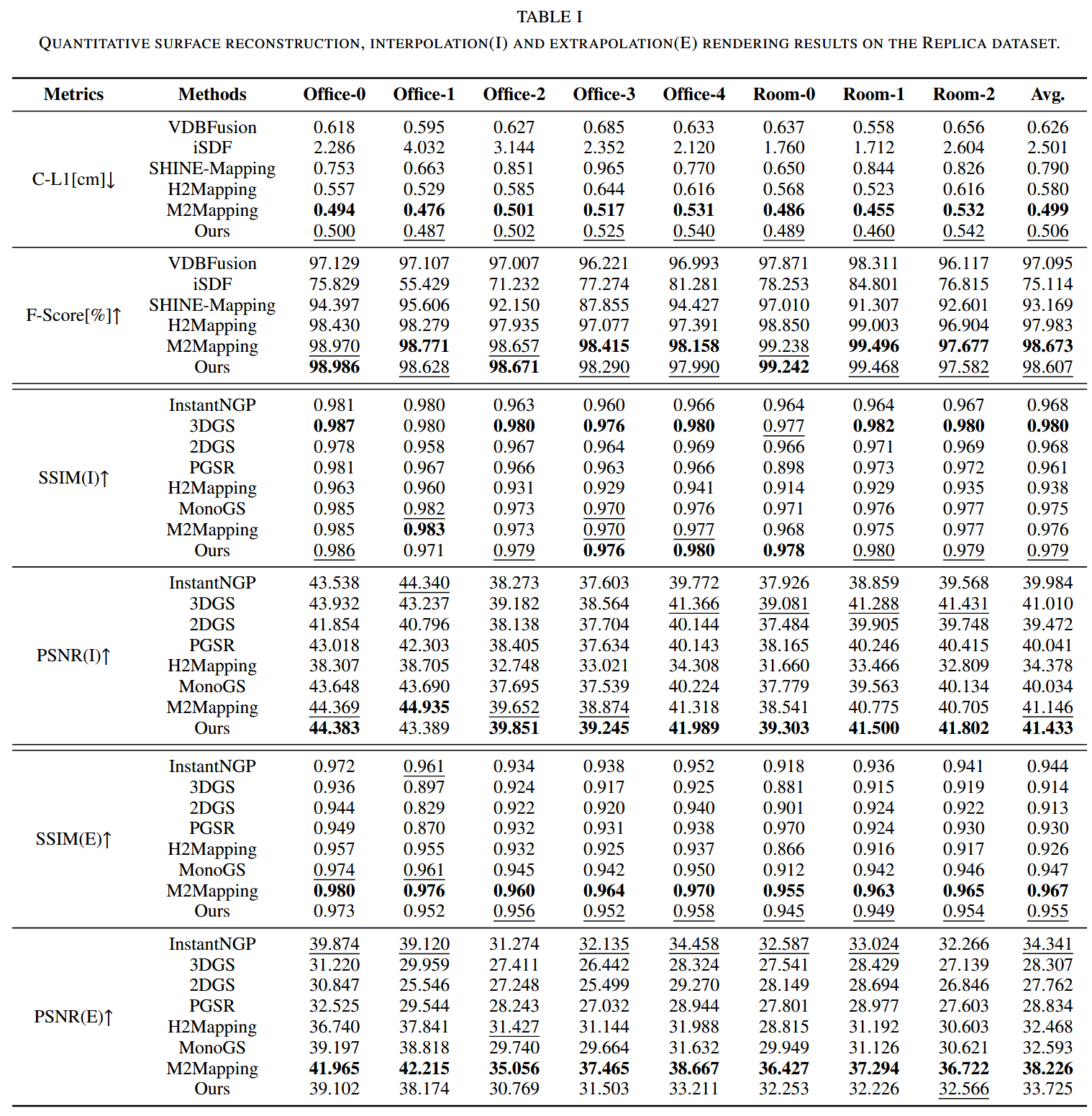
- Replica数据集:室内RGBD模拟。表I显示GS-SDF在表面重建中C-L1平均0.506cm(接近M2Mapping的0.499),F-Score 98.607%(接近M2Mapping的98.673)。插值渲染SSIM/PSNR最佳(0.979/41.433)。外推渲染SSIM/PSNR 0.955/33.725(次于M2Mapping的0.967/38.226)。图4显示捕捉细长物体细节;图5显示保留高频纹理,但NeRF更平滑过渡。
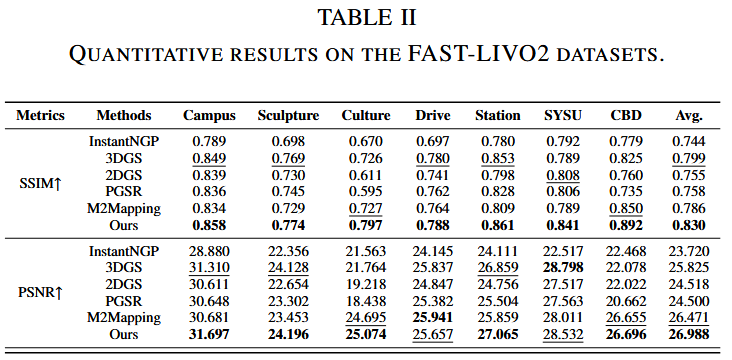
- FAST-LIVO2数据集:真实LiDAR-视觉轨迹。表II显示渲染SSIM/PSNR平均0.830/26.988(优于所有基线)。图6显示高粒度重建和外推渲染;图7显示LiDAR方法几何更详细;图8显示保留地板纹理。
Benchmark
基线包括纯重建(VDBFusion、iSDF、SHINE-Mapping)、纯合成(InstantNGP、3DGS、2DGS、PGSR)、深度辅助(H2Mapping、MonoGS、M2Mapping)。
几何指标:Chamfer距离(C-L1, cm)、F-Score (<2cm,%) 渲染:SSIM、PSNR。
Replica Room-2训练16.6分钟,渲染1200x680图像9.9ms(101.1 FPS)。优于M2Mapping(53.9ms, 18.4 FPS),接近2DGS(9.1分钟, 103.2 FPS)。
Chamfer 距离(C-L1, cm)是什么指标?通俗解释
Chamfer 距离(全称 Chamfer Distance,简称 CD 或 C-L1)是一个用来衡量两个点集之间"相似程度"的指标,尤其在 3D 重建、点云处理和计算机视觉领域中常见。简单来说,它就像是"检查两个点云(一堆 3D 点)之间有多少差距"的工具,用来判断重建出来的 3D 模型和真实模型有多接近。单位通常是厘米(cm),因为它衡量的是空间中的物理距离。
通俗解释
想象你有两个朋友给了一堆石子(点云),一个是你自己扔的(真实点云),另一个是机器人根据照片猜的(重建点云)。Chamfer 距离就像是去丈量这两个石子堆之间的"平均错位距离"。它会:
- 从第一个石子堆(真实点云)到第二个石子堆(重建点云):找每个真实石子到最近的重建石子的距离,然后算平均值。
- 从第二个石子堆到第一个石子堆:反过来,找每个重建石子到最近的真实石子的距离,再算平均值。
- 把这两个平均距离加起来,这就是 Chamfer 距离。
这个距离越小,说明两个点云越接近,重建质量越高。反之,如果距离大,说明重建的点云和真实点云差别很大,可能有遗漏或错误。
为什么用 C-L1?
- C-L1 是 Chamfer 距离的一种变体,用 L1 范数(绝对值距离)计算,而不是 L2 范数(平方距离)。L1 更简单,直接用"直线距离",避免了平方带来的放大效应,计算也更快。
- 在论文中,C-L1 用厘米(cm)表示,方便直观理解重建误差,比如 0.5 cm 意味着平均每个点错位不到 1 厘米。



初体验
TODO