数据库基础设施
RAGFlow 使用关系数据库(MySQL 或 PostgreSQL)作为主要元数据存储,通过具有连接池和重试机制的 Peewee ORM 进行管理。
连接管理
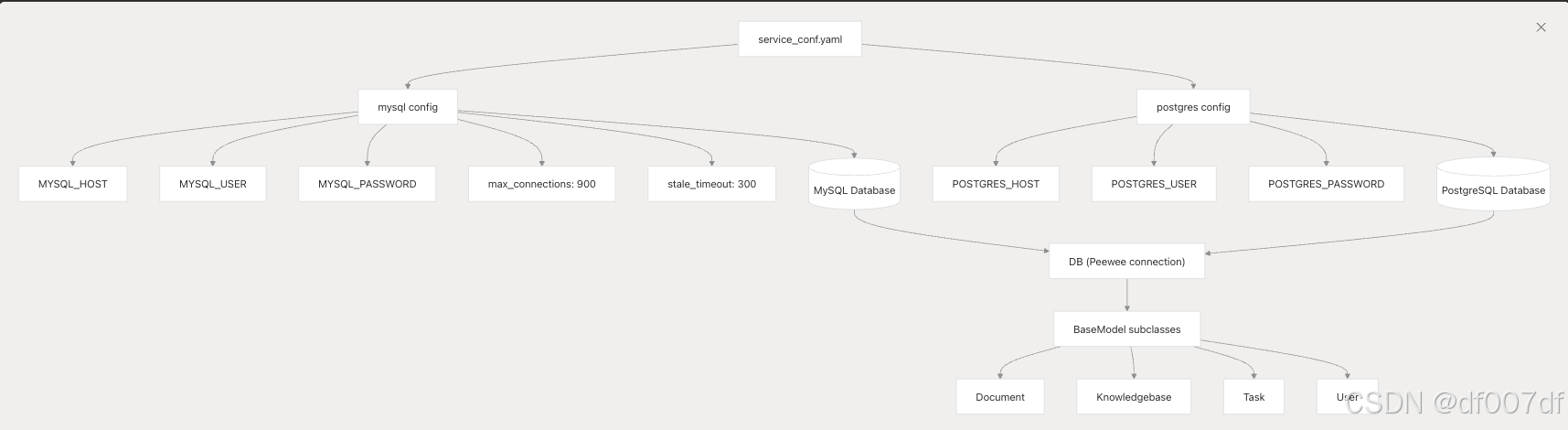
数据库连接通过 service_conf.yaml 和环境变量进行配置。该系统支持具有可配置连接池的 MySQL 和 PostgreSQL:
数据库配置架构
数据库连接参数从 service_conf.yaml 加载,支持连接池、超时配置和自动重新连接处理。
核心数据模型
系统使用几个关键模型类,通过自动时间戳管理扩展 BaseModel:
| Model | 目的 | 关键字段 |
|---|---|---|
| Document | 文档元数据和处理状态 | id、kb_id、parser_id、 名称 、 大小 、token_num、chunk_num |
| Knowledgebase | 知识库配置 | id、tenant_id、letter、embd_id、parser_config |
| Task | 文档处理任务 | id、doc_id、 进度 、progress_msg、retry_count |
| File | 文件系统元数据 | id、 名称 、 位置 、 大小 、 类型 |
| TenantLLM | 每个租户的 LLM 配置 | llm_factory、tenant_id、llm_name、api_key |
| User | 用户帐户信息 | ID、 电子邮件 、 昵称 、 密码 access_token |
| UserTenant | 用户-租户关系 | user_id、tenant_id、 角色 、 状态 |
文档存储层
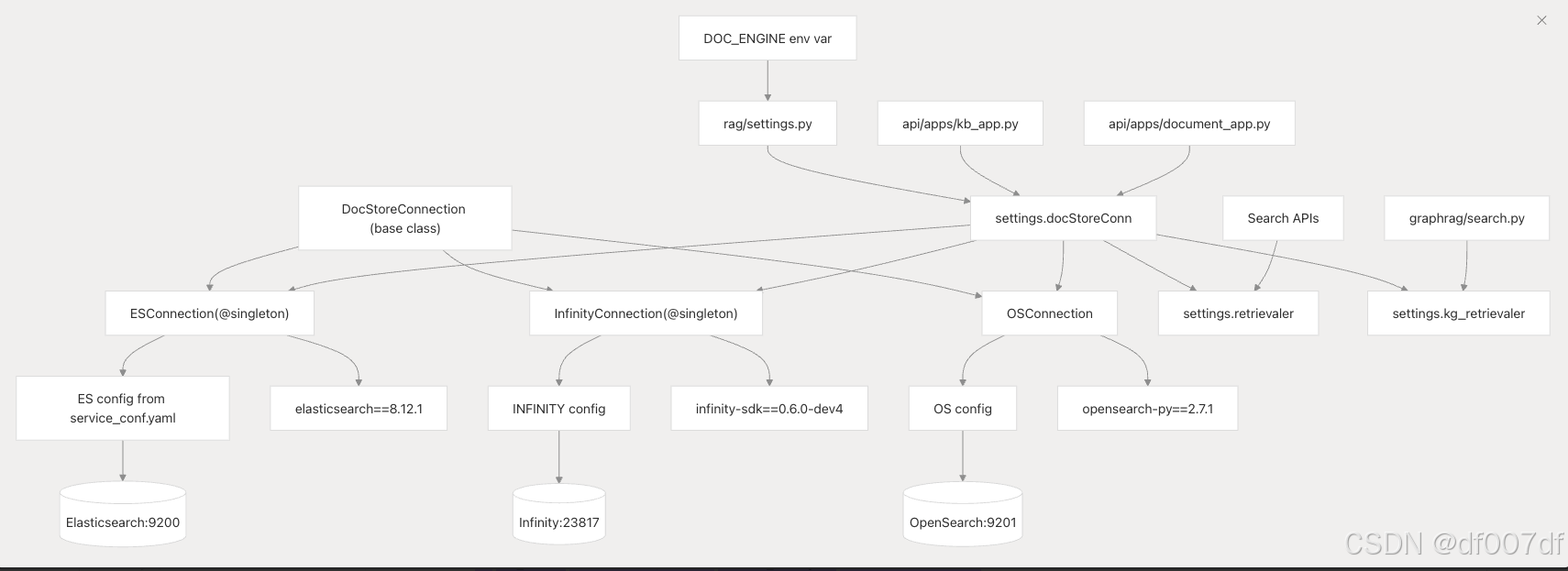
RAGFlow 支持用于矢量和全文搜索的多个文档存储后端:Elasticsearch、Infinity 和 OpenSearch。抽象层允许通过 DOC_ENGINE 环境变量透明地在实现之间切换。
文档存储抽象
文档存储体系结构
所有文档存储实现都扩展了 DocStoreConnection 抽象基类,提供了统一的接口。后端在初始化时根据 DOC_ENGINE 环境变量选择,配置从 service_conf.yaml 加载和单例连接管理。
Elasticsearch 实现
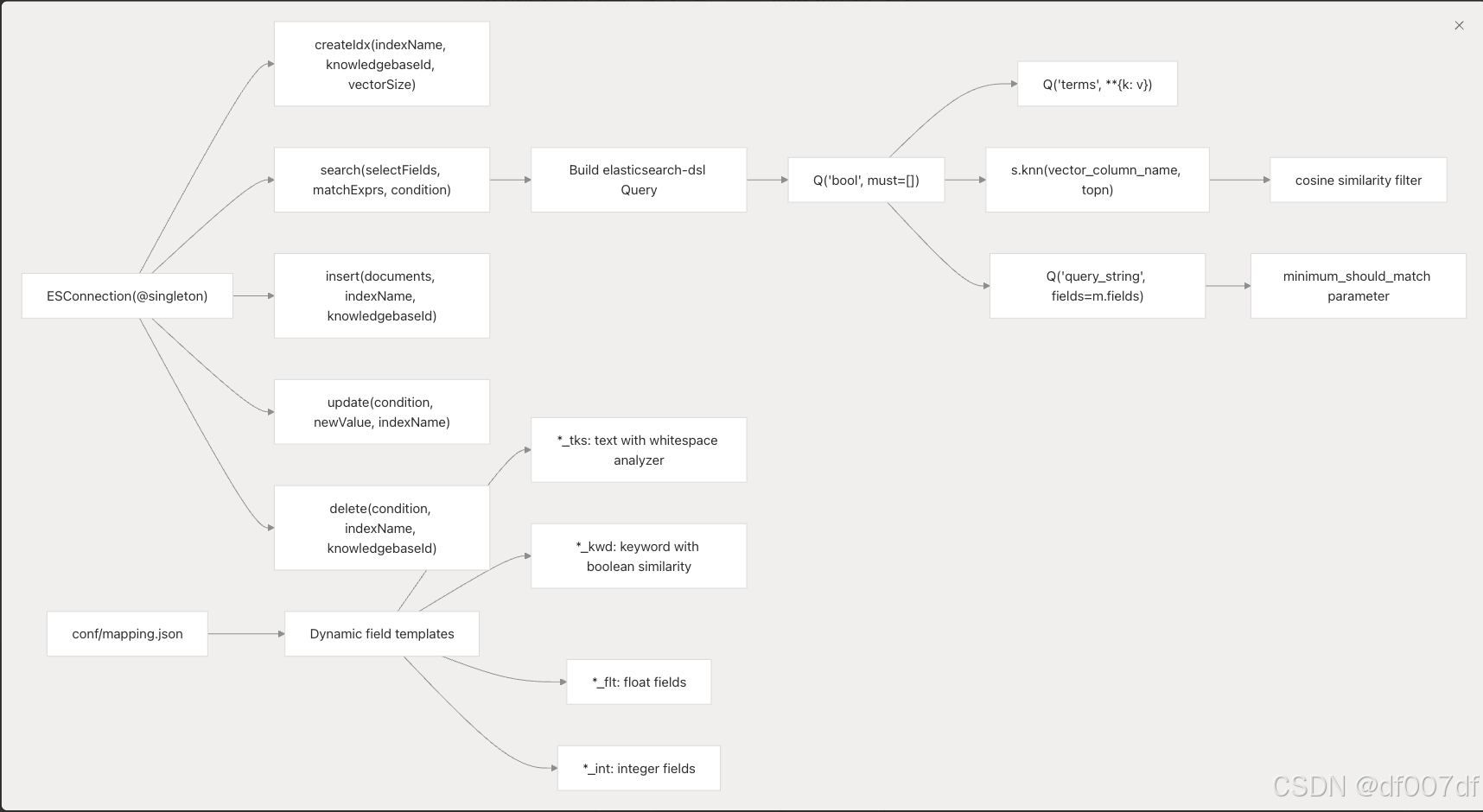
ESConnection 类提供复杂的查询功能,混合搜索结合了向量相似性和全文匹配,使用 conf/mapping.json 中定义的模式:
Elasticsearch 查询构造
搜索方法构造复杂的布尔查询,将术语筛选器、向量相似性和全文搜索与 mapping.json 中动态模板定义的字段映射相结合。
Infinity实现
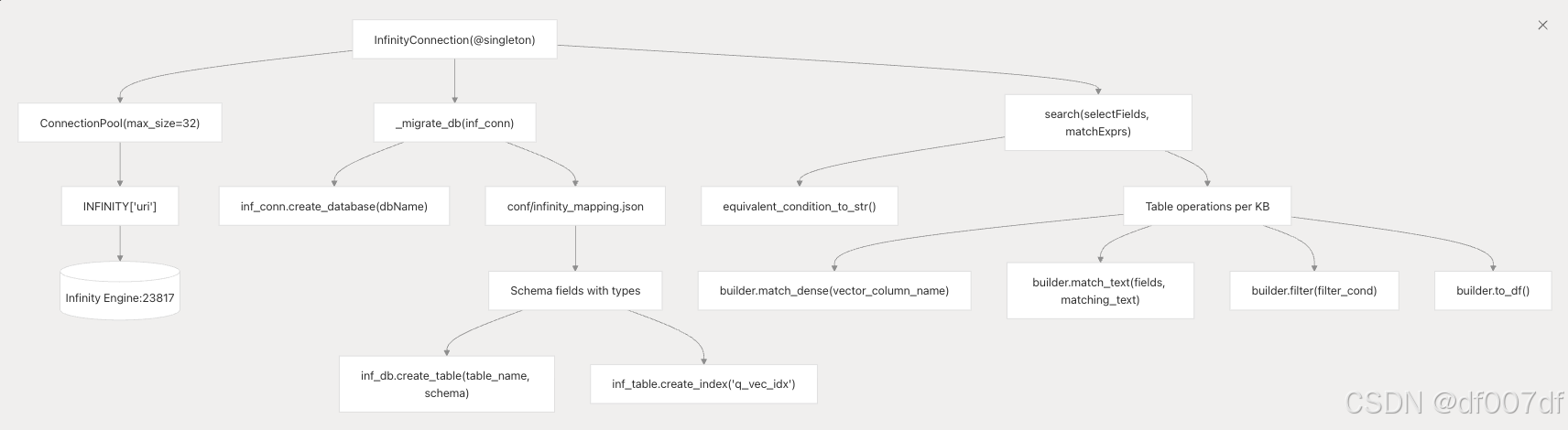
InfinityConnection 提供高性能矢量搜索,包括连接池和从 conf/infinity_mapping.json 迁移模式:
Infinity查询处理
该系统使用连接池和自动模式迁移,并将搜索条件转换为 Infinity 的查询构建器 API,同时保持每个知识库的表组织。
对象存储层
RAGFlow 通过 STORAGE_IMPL 单例支持多个对象存储后端,可通过 STORAGE_IMPL_TYPE 环境变量进行配置。支持的实现包括 MinIO、AWS S3、Azure Blob Storage 和阿里云 OSS。
存储接口
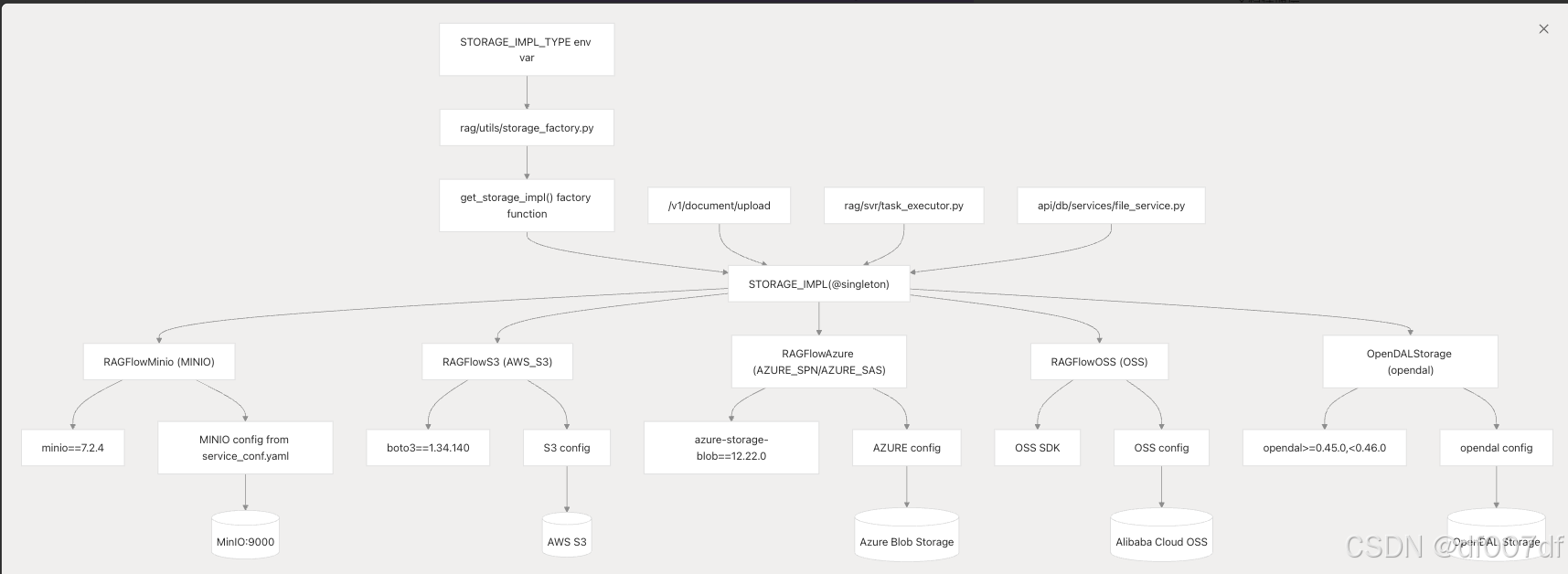
多后端对象存储架构
storage_factory.py 中的 get_storage_impl() 工厂函数实现了工厂模式,允许在存储后端之间无缝切换。每个实现都提供相同的接口方法:put()、get()、rm()、obj_exist() 和 get_presigned_url()。
Redis 缓存和任务协调
Redis 层提供分布式任务排队、会话管理和缓存功能。系统支持 Redis 和 Valkey(Redis 分支),如 pyproject.toml 中配置的那样。Redis 配置从 service_conf.yaml 加载,并带有密码身份验证和数据库选择。
Redis 架构

Redis 有多种用途:与优先级队列的任务协调、Flask 会话存储、用于成本优化的 LLM 响应缓存以及用于性能的文件缓存。
任务处理工作流程
任务执行遵循具有进度跟踪和错误处理的结构化管道:
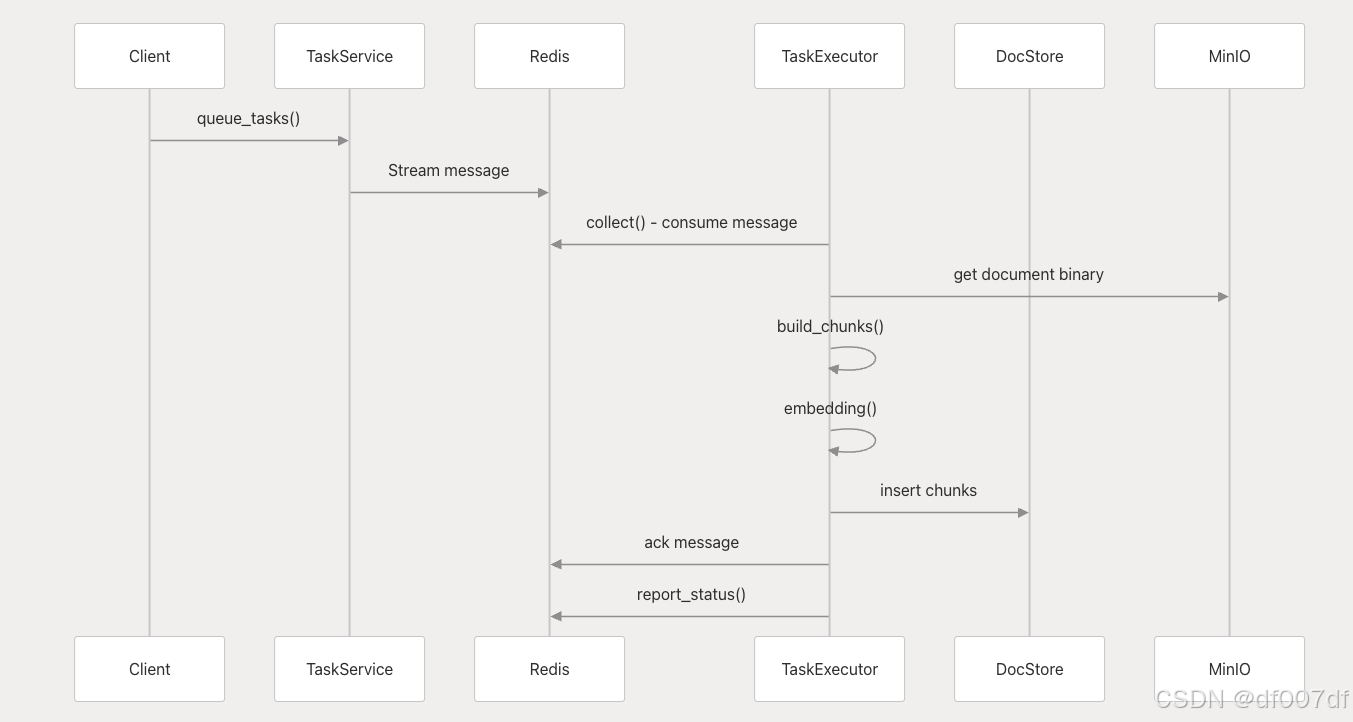
任务处理顺序
每个任务都通过块构建、嵌入生成和文档存储插入进行,并具有全面的错误处理和重试机制。
服务层架构
服务层通过封装数据库作和业务逻辑的专用服务类提供高级数据访问模式。
服务类层次结构
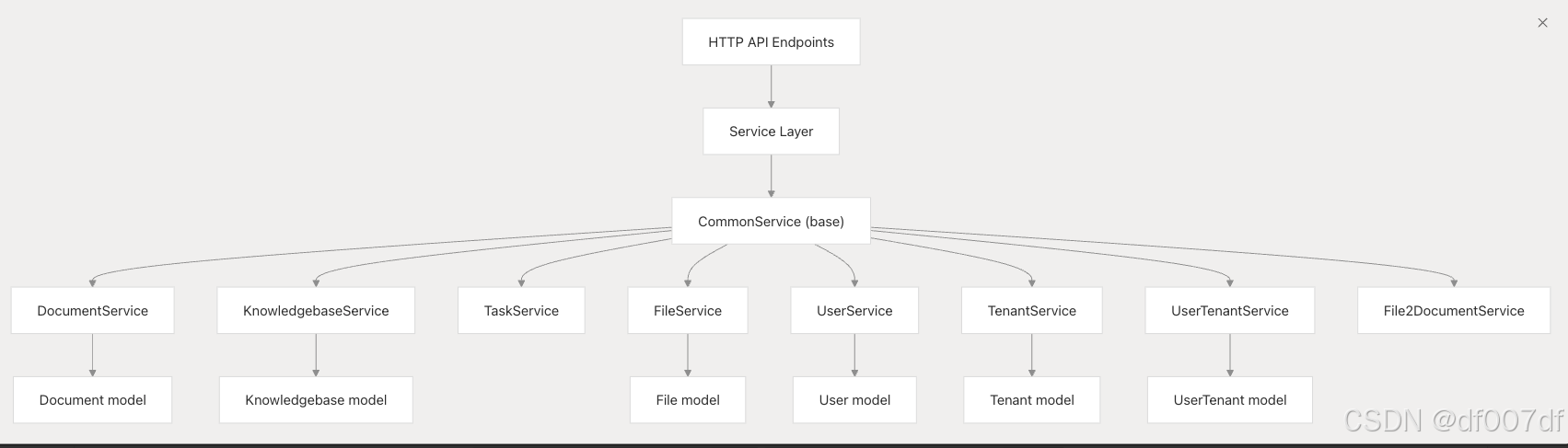
服务层组织
每个服务类都提供特定于域的作,同时从 CommonService 继承通用 CRUD 功能。服务处理用户身份验证、知识库管理和文档处理工作流。
知识库服务作
知识库服务提供全面的知识库生命周期管理,包括访问控制和配置管理:
| 方法 | 目的 | 数据库作 |
|---|---|---|
| accessible() | 权限检查 | 通过 UserTenant 验证用户访问权限 |
| accessible4deletion() | 删除权限 | 检查用户是否是创建者 |
| is_parsed_done() | 解析状态检查 | 验证所有文件均已处理 |
| get_by_tenant_ids() | 多租户列表 | 使用分页联接查询 |
| update_parser_config() | 配置更新 | 深度合并解析器设置 |
| get_field_map() | 字段映射检索 | 从配置中提取字段映射 |
该服务包括复杂的访问控制逻辑,用于检查所有权和团队成员权限。
数据流集成
数据层组件协同工作以支持完整的文档处理和检索管道:
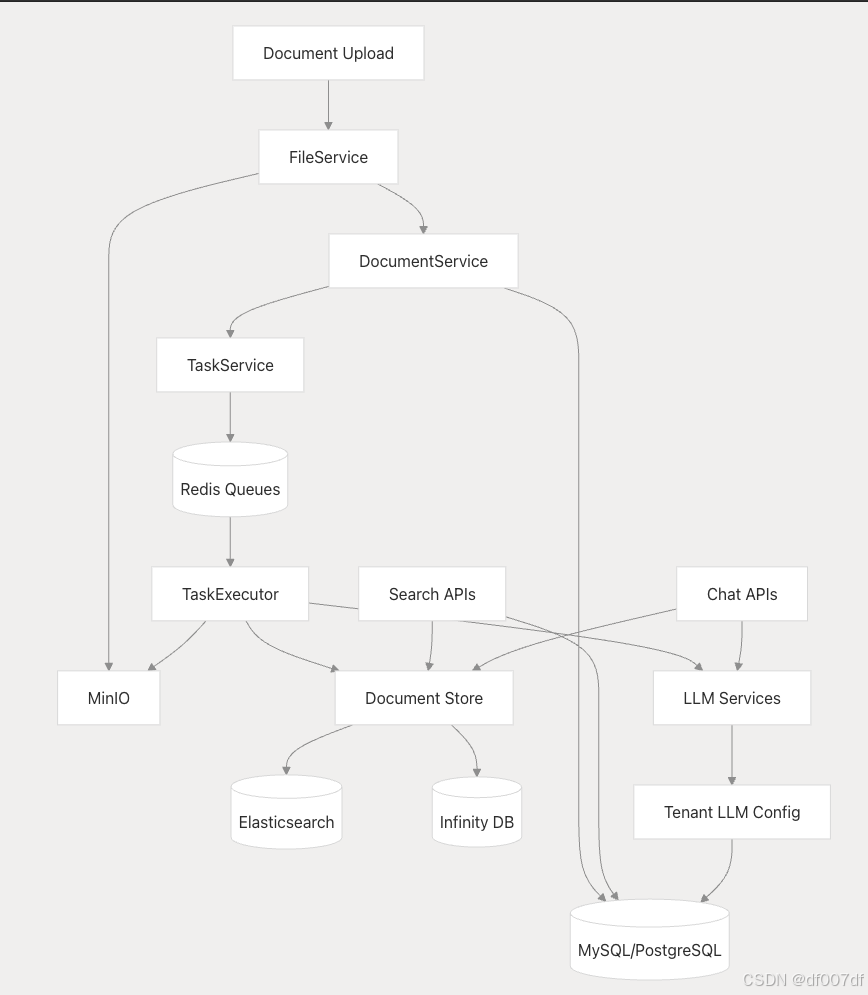
完整的数据流架构
集成数据层支持实时作和批处理工作流,并在所有存储系统中实现一致的状态管理。