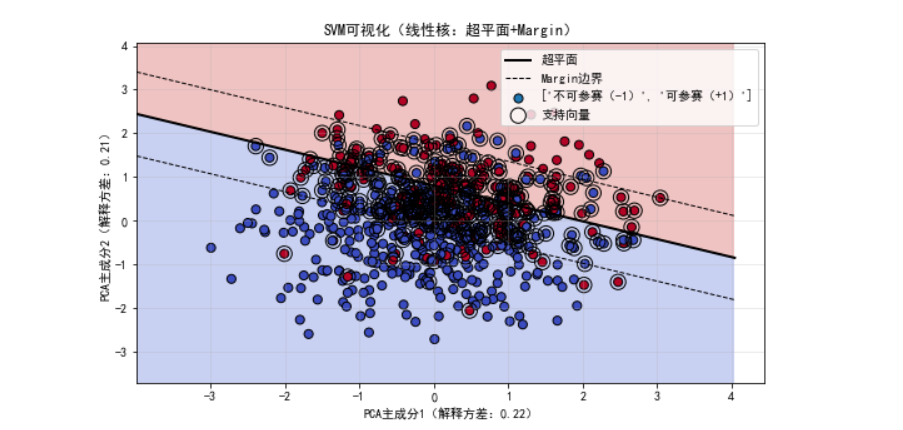
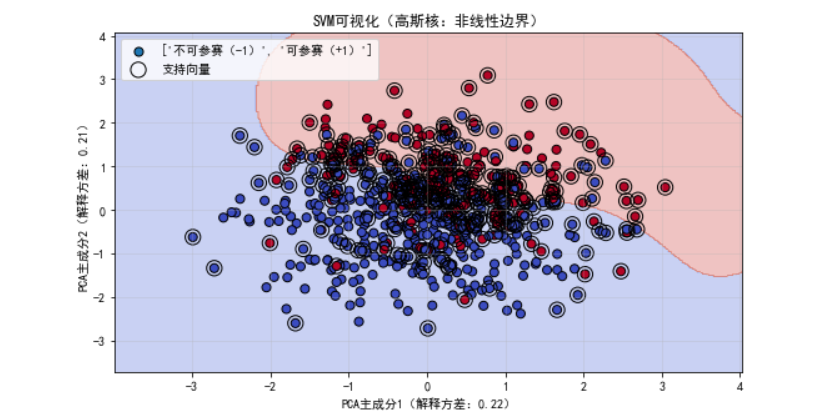
一、SVM 的核心目标:找 "最稳" 的划分超平面
1. 基本需求:先把样本分开
SVM 的本质诉求很简单 ------ 在样本空间里找一个划分超平面 ,把不同类别的样本 "一刀切" 分开。这里要先明确 "超平面" 的概念:它是 n 维空间里的 n-1 维子空间,比如 3 维空间的超平面是 2 维平面,2 维空间的超平面是 1 维直线,用数学公式表示就是 wᵀx + b = 0(其中 w 是超平面的法向量,决定超平面方向;b 是截距,决定超平面位置)。
但 "能分开" 只是基本要求,实际中可能有无数个超平面都能划分样本,比如在二维空间里,可能有很多条直线都能把正负样本隔开。
2. 理想超平面:抗扰动的 "容忍性" 最关键
SVM 的核心思想是选 "最稳" 的超平面 ------ 也就是对训练样本局部扰动容忍性最好的超平面。举个例子:如果一个超平面离两类样本都很近,稍微有个样本偏移一点就会分错;但如果超平面离两类样本都足够远,即便样本有小波动,分类结果也不容易出错。
这个 "远" 的程度,就用Margin(间隔) 来衡量。Margin 指的是超平面到两类样本中最近点的距离之和,SVM 的优化目标就是 ------最大化这个 Margin。
二、从 "最大化间隔" 到数学建模
1. 把 "距离" 转化为数学条件
要最大化 Margin,首先得明确 "样本到超平面的距离" 怎么算。对于 n 维超平面 wᵀx + b = 0,任意样本 x 到它的距离公式是:
d = |wᵀx + b| / ||w||(||w|| 是 w 的 L2 范数,即向量长度)。
为了简化计算,SVM 做了一个 "放缩约定":让所有样本满足 y(wᵀx + b) ≥ 1(其中 y 是样本标签,正例 y=+1,负例 y=-1)。这个约定的意义是:把离超平面最近的样本(也就是对 Margin 贡献最大的样本)的距离固定为 1/||w||,此时 Margin 就是 2/||w||。
这样一来,"最大化 Margin" 就等价于 "最小化 ||w||²/2"(因为 ||w|| 越小,2/||w|| 越大,平方和除以 2 是为了后续求导方便)。
2. 带约束的优化:拉格朗日乘子法登场
现在问题变成了一个带约束的优化问题:
目标函数 :min (||w||²/2)
约束条件:yᵢ(wᵀxᵢ + b) ≥ 1(i=1,2,...,n,n 是样本数)
对于这种 "带不等式约束的凸优化问题",经典解法是拉格朗日乘子法------ 通过引入拉格朗日乘子 αᵢ(αᵢ ≥ 0),把约束条件融入目标函数,转化为无约束优化问题。
构建的拉格朗日函数为:
L(w, b, α) = (1/2)||w||² - Σαᵢyᵢ(wᵀxᵢ + b) - 1
接下来要解决的是 "对偶问题":先对 w 和 b 求偏导找到极值条件,再代入原函数,把问题转化为关于 α 的最大化问题。
三、SVM 的求解关键:对偶问题与支持向量
1. 求偏导:找到 w 和 b 的表达式
对拉格朗日函数 L 分别求 w 和 b 的偏导,并令偏导等于 0(极值条件):
- 对 w 求偏导:∂L/∂w = w - Σαᵢyᵢxᵢ = 0 → w = Σαᵢyᵢxᵢ
- 对 b 求偏导:∂L/∂b = -Σαᵢyᵢ = 0 → Σαᵢyᵢ = 0
这两个式子是 SVM 的核心:w 由 αᵢ、yᵢ和 xᵢ共同决定,而 b 则需要结合 "支持向量" 来求。
2. 代入化简:转化为 α 的优化问题
把 w = Σαᵢyᵢxᵢ代入拉格朗日函数,化简后得到对偶问题的目标函数:
max (Σαᵢ - (1/2)ΣΣαᵢαⱼyᵢyⱼ(xᵢ·xⱼ))
约束条件:Σαᵢyᵢ = 0,αᵢ ≥ 0(i=1,2,...,n)
这里的 (xᵢ・xⱼ) 是样本 xᵢ和 xⱼ的内积。求解这个对偶问题后,我们就能得到 αᵢ的值 ------ 而大部分 αᵢ会是 0,只有少数 αᵢ > 0 的样本,才是真正决定超平面的 "关键选手"。
3. 支持向量:决定超平面的 "少数派"
那些 αᵢ > 0 的样本,就是支持向量。为什么叫 "支持"?因为只有它们落在 Margin 的边界上(满足 yᵢ(wᵀxᵢ + b) = 1),是支撑起整个超平面的 "骨架";而 αᵢ = 0 的样本,对超平面的位置和方向没有任何影响 ------ 哪怕去掉这些样本,超平面也不会变。
这也是 SVM 的一大特点:模型只依赖支持向量,计算效率高,且对噪声有天然的 "抗干扰性"(只要噪声不是支持向量)。
四、解决实际问题:软间隔与核函数
前面的推导都是基于 "样本线性可分" 的理想情况,但现实中数据往往有噪声,或者根本无法用线性超平面划分 ------ 这时候就需要 SVM 的两个 "进阶技巧":软间隔和核函数。
1. 软间隔:允许少量分类错误
当数据中有噪声时,强行追求 "完全线性可分" 会导致模型过拟合(比如为了避开一个噪声点,超平面变得很 "歪")。软间隔的思路是:放松约束,允许少量样本不满足 yᵢ(wᵀxᵢ + b) ≥ 1,但要惩罚这种错误。
具体来说,引入 "松弛因子"ξᵢ ≥ 0(ξᵢ越大,样本越偏离正确分类),把约束条件改成:
yᵢ(wᵀxᵢ + b) ≥ 1 - ξᵢ
同时,目标函数增加对 ξᵢ的惩罚项:
min (||w||²/2 + CΣξᵢ)
这里的 C 是一个超参数,控制 "分类准确性" 和 "Margin 大小" 的权衡:
- C 越大:惩罚越重,模型越追求 "少错",甚至不允许错(容易过拟合);
- C 越小:惩罚越轻,模型允许更多错误,Margin 更大(容易欠拟合)。
2. 核函数:解决低维不可分问题
如果样本在低维空间里根本无法线性划分(比如 "异或" 问题),该怎么办?SVM 的解法是 ------把低维数据映射到高维空间,让数据在高维空间里线性可分。
比如 3 维空间里不可分的数据,映射到 9 维空间后,可能就有一个 8 维超平面能把它们分开。但直接映射到高维会有一个问题:计算量爆炸(比如从 100 维映射到 10000 维,内积计算量会从 O (100) 变成 O (10000))。
这时候 "核函数" 就派上用场了。核函数的神奇之处在于:不需要显式地把数据映射到高维,而是直接在低维空间里计算 "高维空间的内积",从而避免了高维计算的开销。
常用的核函数有:
- 线性核:K (xᵢ, xⱼ) = xᵢ・xⱼ(适用于线性可分数据,就是原始 SVM);
- 高斯核(RBF 核):K (xᵢ, xⱼ) = exp (-||xᵢ - xⱼ||²/(2σ²))(适用于非线性数据,能处理大部分复杂场景);
- 多项式核:K (xᵢ, xⱼ) = (xᵢ・xⱼ + c)^d(适用于数据有明显多项式分布的场景)。
五、实战小例子:SVM 求解过程
光说理论太抽象,我们看一个简单的求解实例(假设样本和标签已给定):
- 代入对偶问题目标函数,化简得到关于 α₁、α₂、α₃的表达式;
- 根据约束条件(比如 α₁ + α₂ = α₃)进一步化简,得到只含 α₁和 α₂的函数;
- 对 α₁和 α₂求偏导并令其为 0,发现解不满足 αᵢ ≥ 0 的约束,于是转向 "边界解";
- 尝试 α₁=0、α₂=0 等边界情况,最终找到满足约束的 α 值(比如 α₁=0.25,α₂=0,α₃=0.25);
- 代入 w = Σαᵢyᵢxᵢ求 w,再结合支持向量求 b(比如得到 b=-2);
- 最终超平面方程为:0.5x₁ + 0.5x₂ - 2 = 0。
六、SVM 的总结与适用场景
支持向量机的核心逻辑可以概括为:通过最大化间隔找到最优超平面,用对偶问题简化求解,用软间隔处理噪声,用核函数解决非线性问题。
它的优点很明显:
- 只依赖支持向量,模型简洁,泛化能力强;
- 高维数据下表现优秀(比如文本分类,特征维度常达上万);
- 对小样本数据友好。
但也有局限性:
- 样本量大时,求解对偶问题的速度会变慢(因为要计算所有样本的内积);
- 超参数(C、核函数参数)调优需要经验,对新手不太友好。
- 这是我用体能训练是否能参加马拉松数据集做出的支持向量机可视化