文章目录
-
-
-
- [0. kafka主要构成组件:](#0. kafka主要构成组件:)
- [1. 主题(Topics)](#1. 主题(Topics))
- 2.分区(Partitions)
- 3.Brokers
- [4. 复制(Replication):kafka通过复制实现容错](#4. 复制(Replication):kafka通过复制实现容错)
- 5.消费方(producers)
- 6.消费方(consumers):读取消息从topic,响应事件流
- [7. Confluent Schema Registry:](#7. Confluent Schema Registry:)
- [8.kafka connect:集成外部系统到kafka集群](#8.kafka connect:集成外部系统到kafka集群)
- [9.Stream Processing](#9.Stream Processing)
- [10.Confluent 商业kafka介绍](#10.Confluent 商业kafka介绍)
-
-
0. kafka主要构成组件:
1. 主题(Topics)
topics以日志的形式存储数据
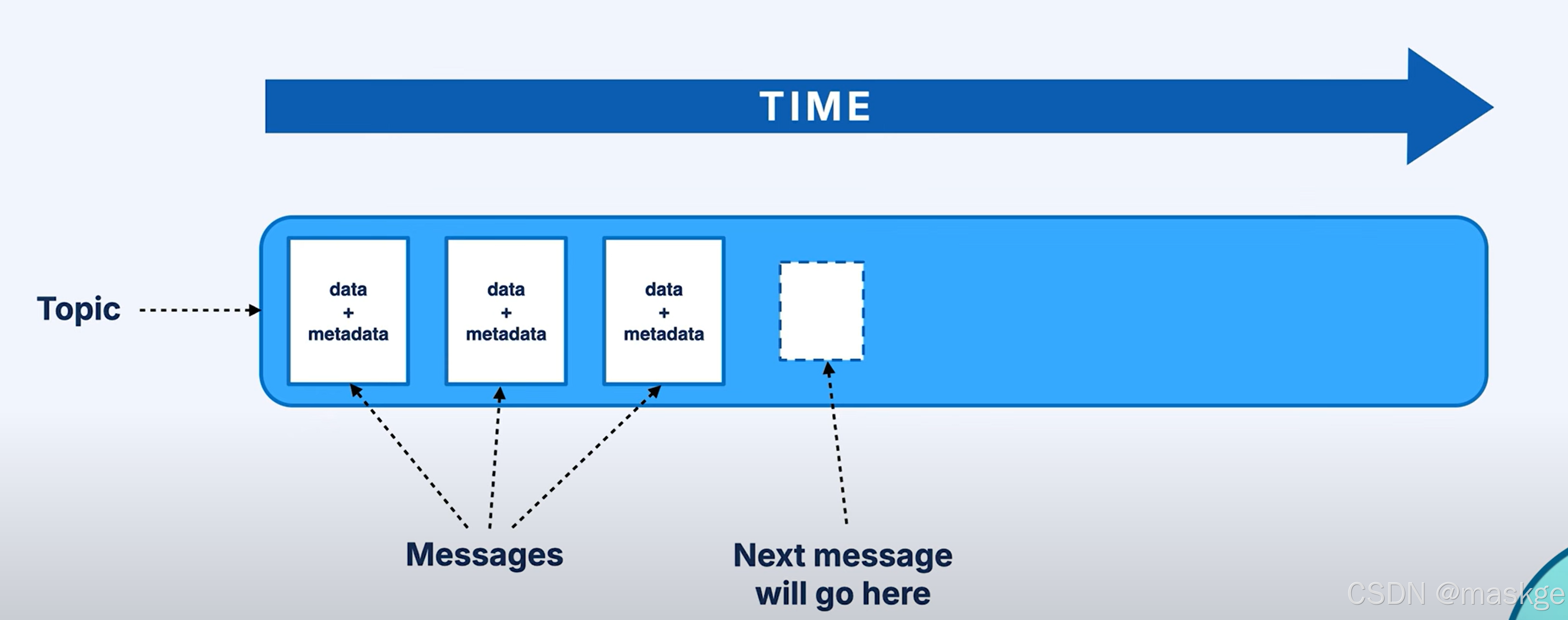
以接受的顺序存储消息

以主题组织数据
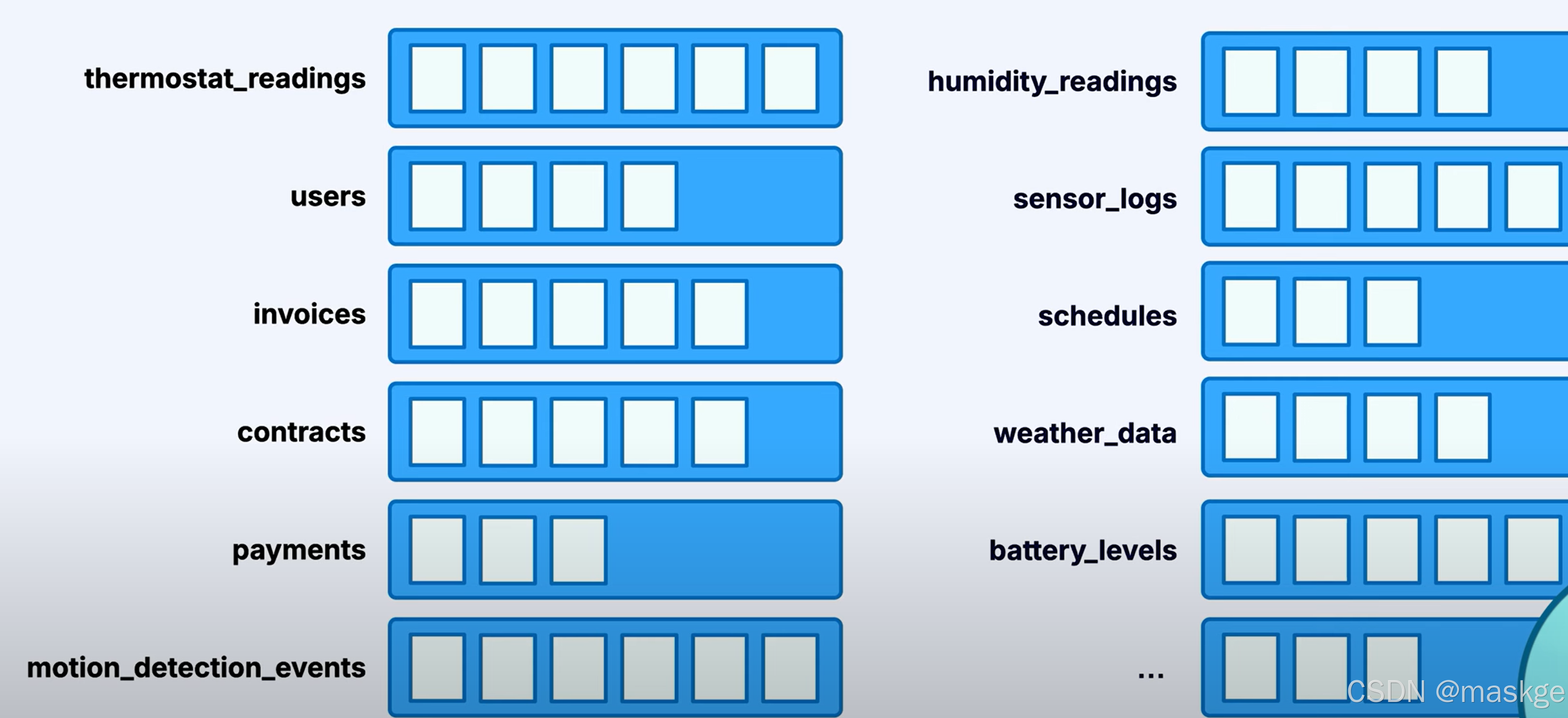
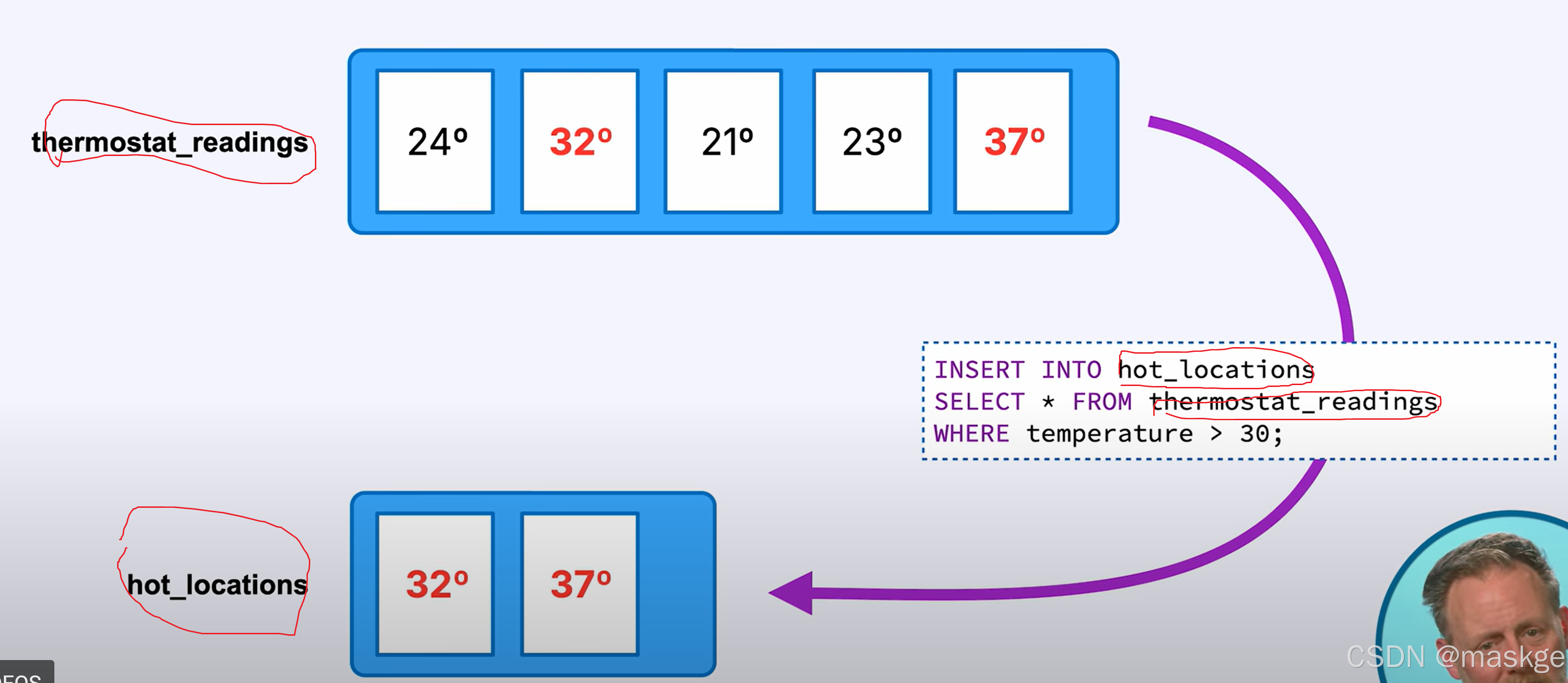
从其他主题派生主题
topic不是一个队列,是一条日志,是有序不可变的记录

kafka 消息细节(消息数据结构)


key:是一个唯一约束的ID
日志保存和压缩(log retention and compaction):

2.分区(Partitions)
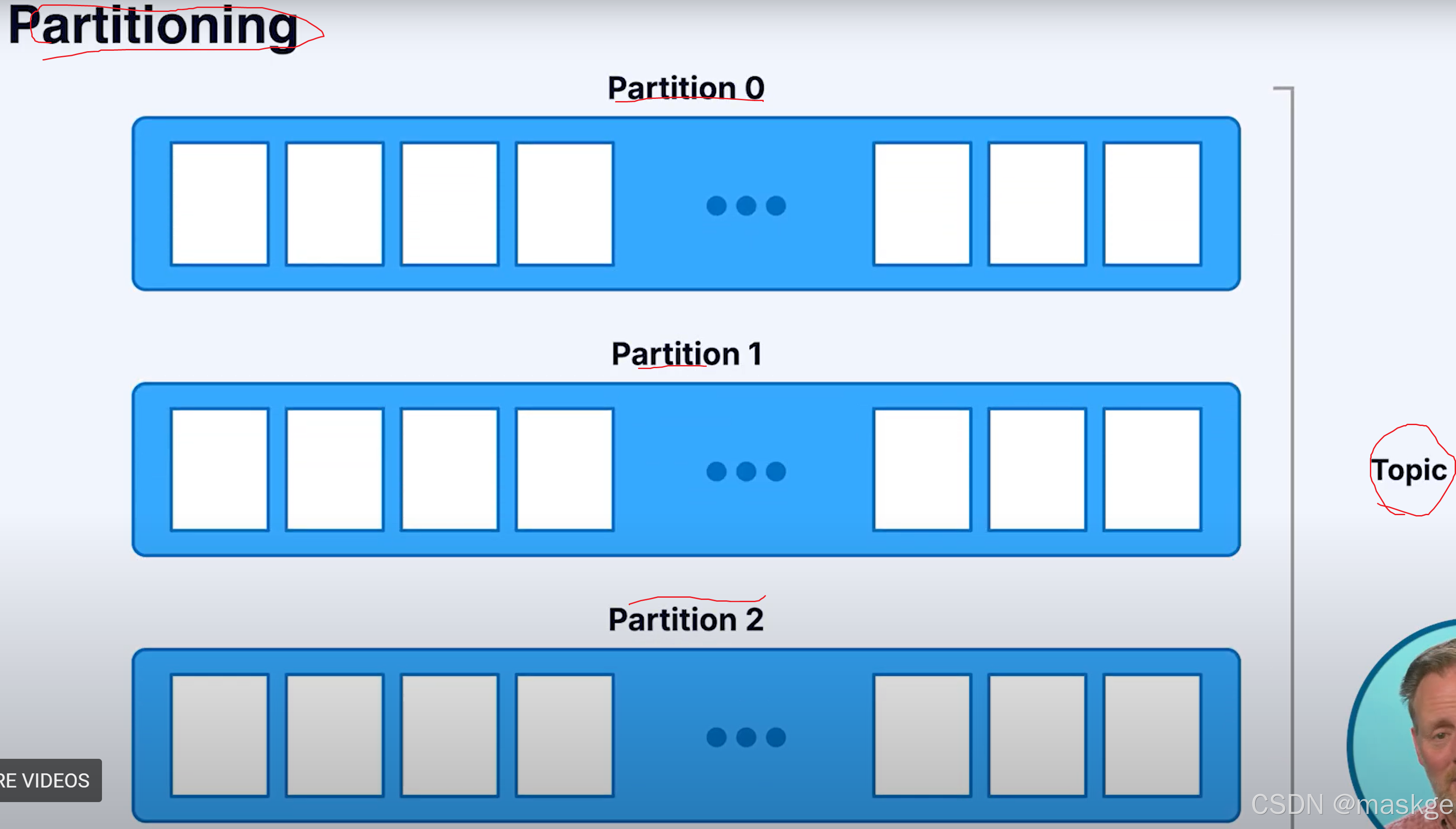


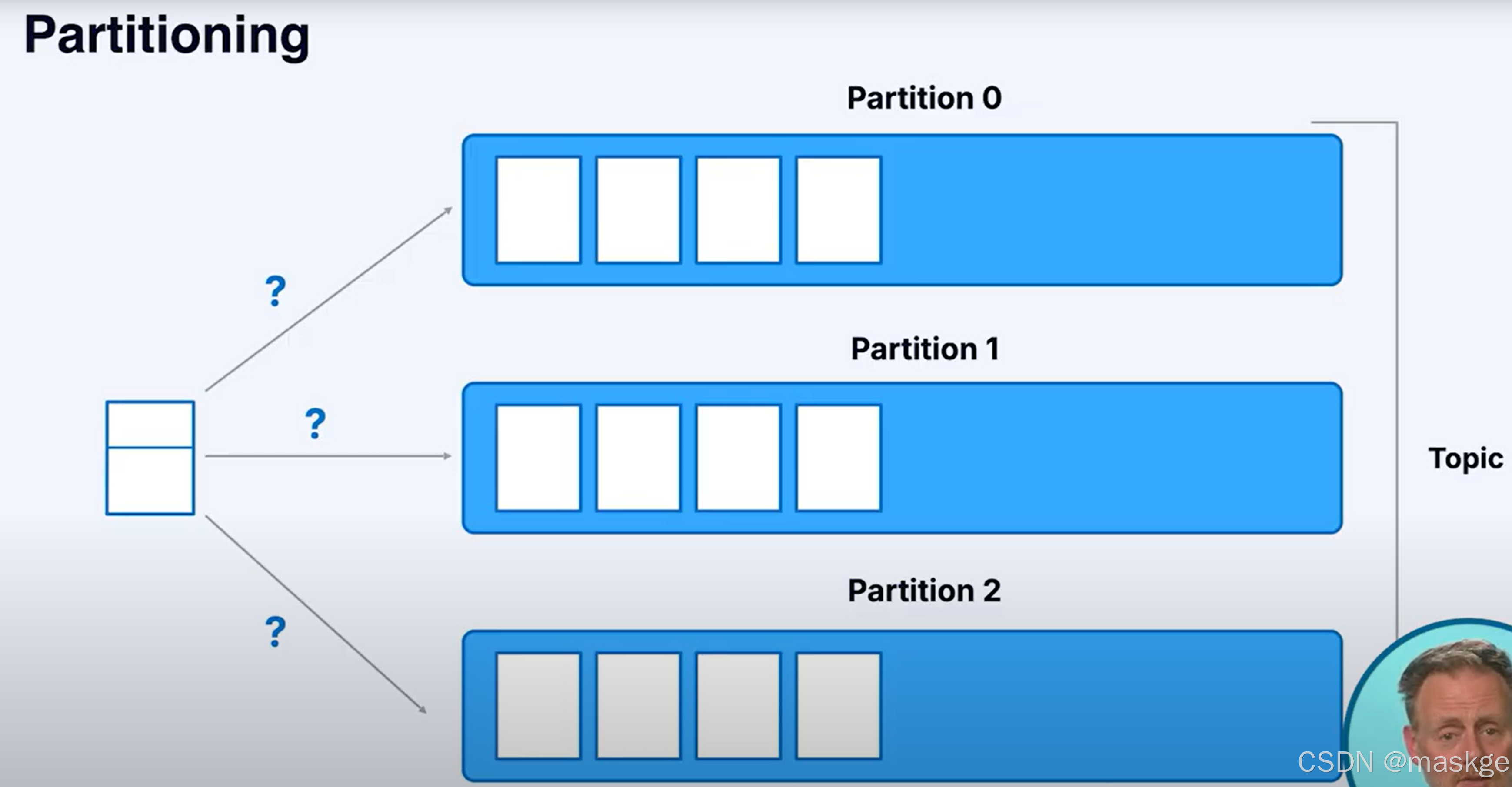
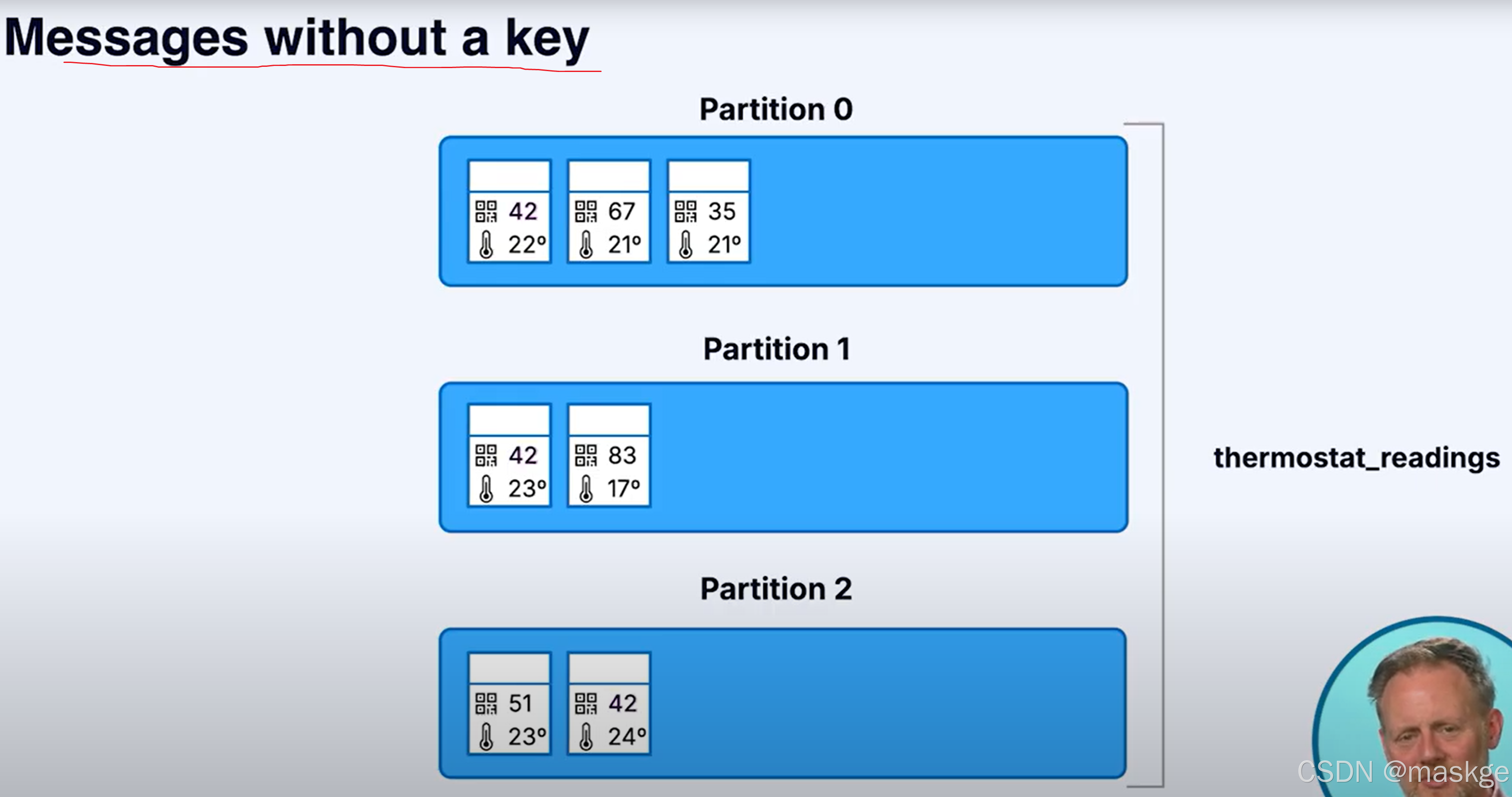
消息以无序的方式进入分区(没有key),采用消息以轮询的方式进入分区

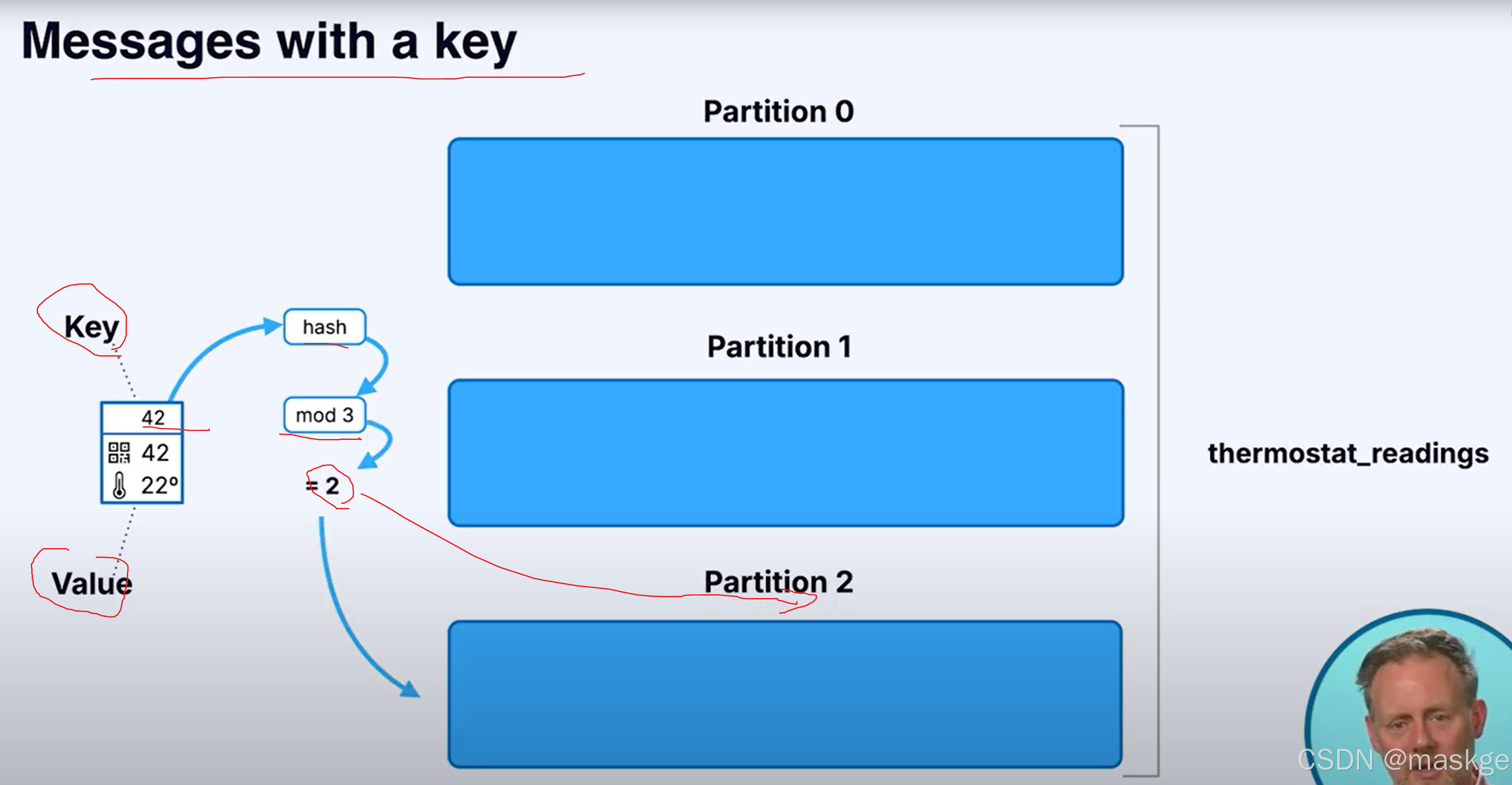
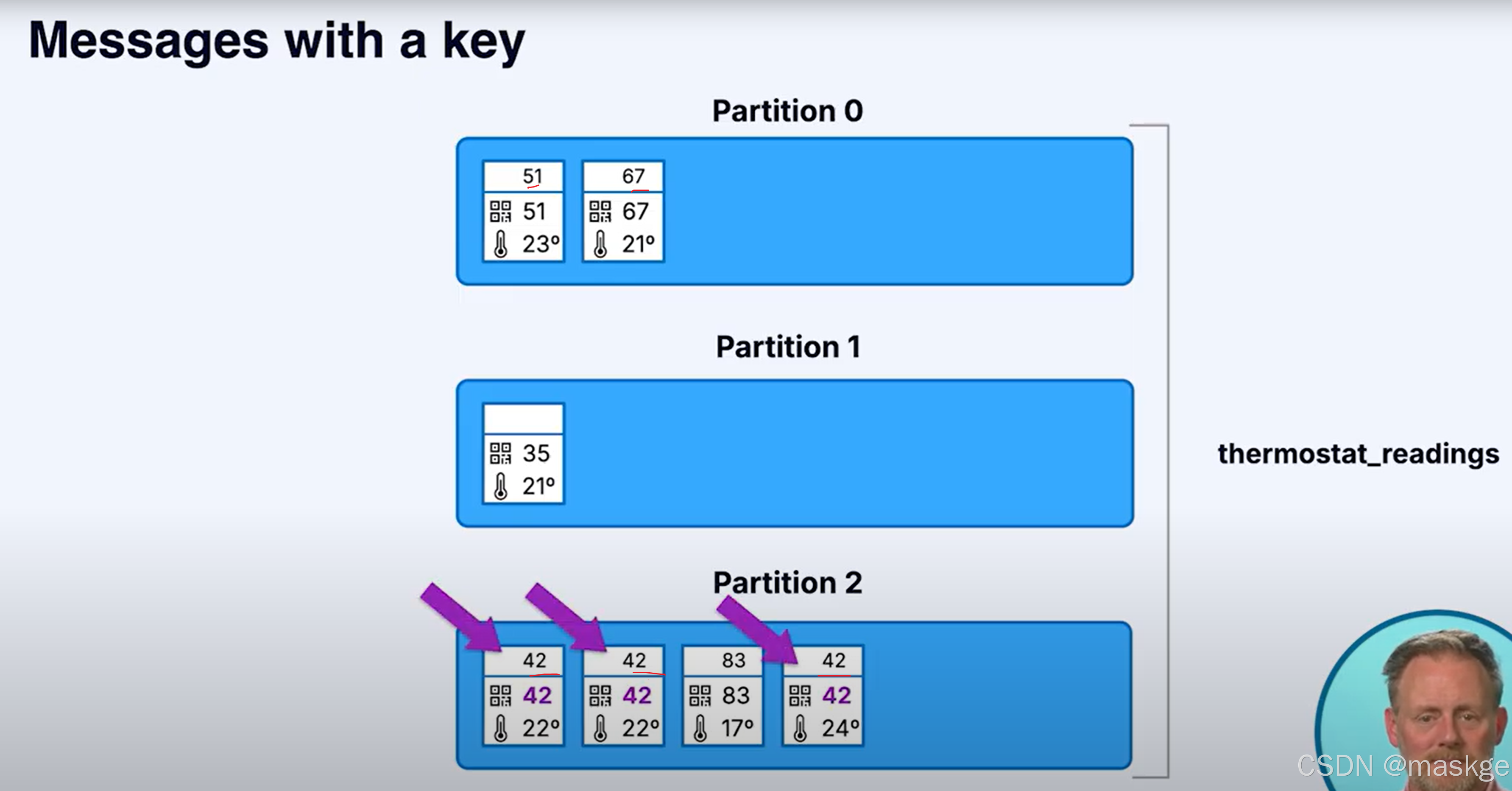
消息以有序的方式进入分区(有key),通过采用hash取模操作,相同的key总被写到同一个分区
3.Brokers
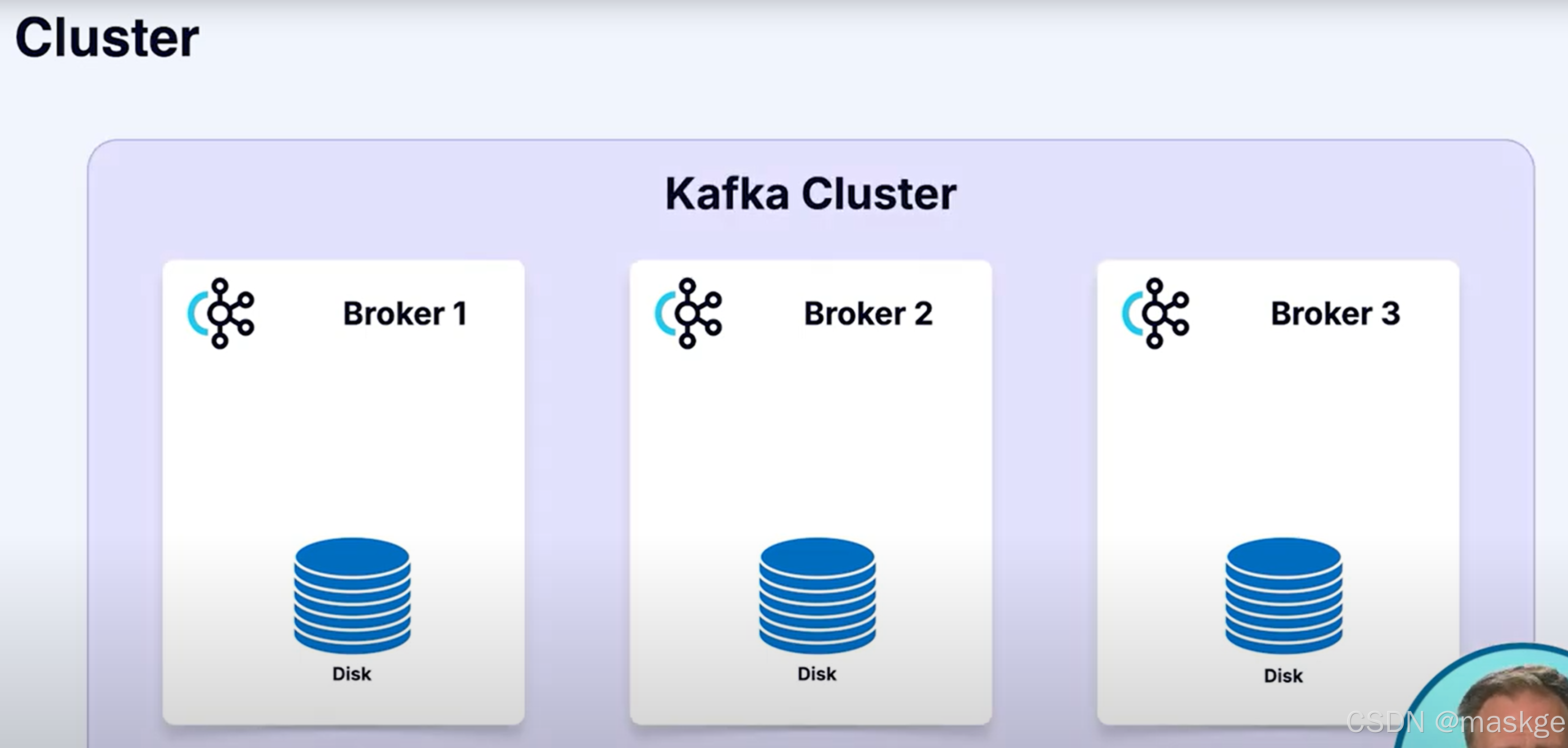
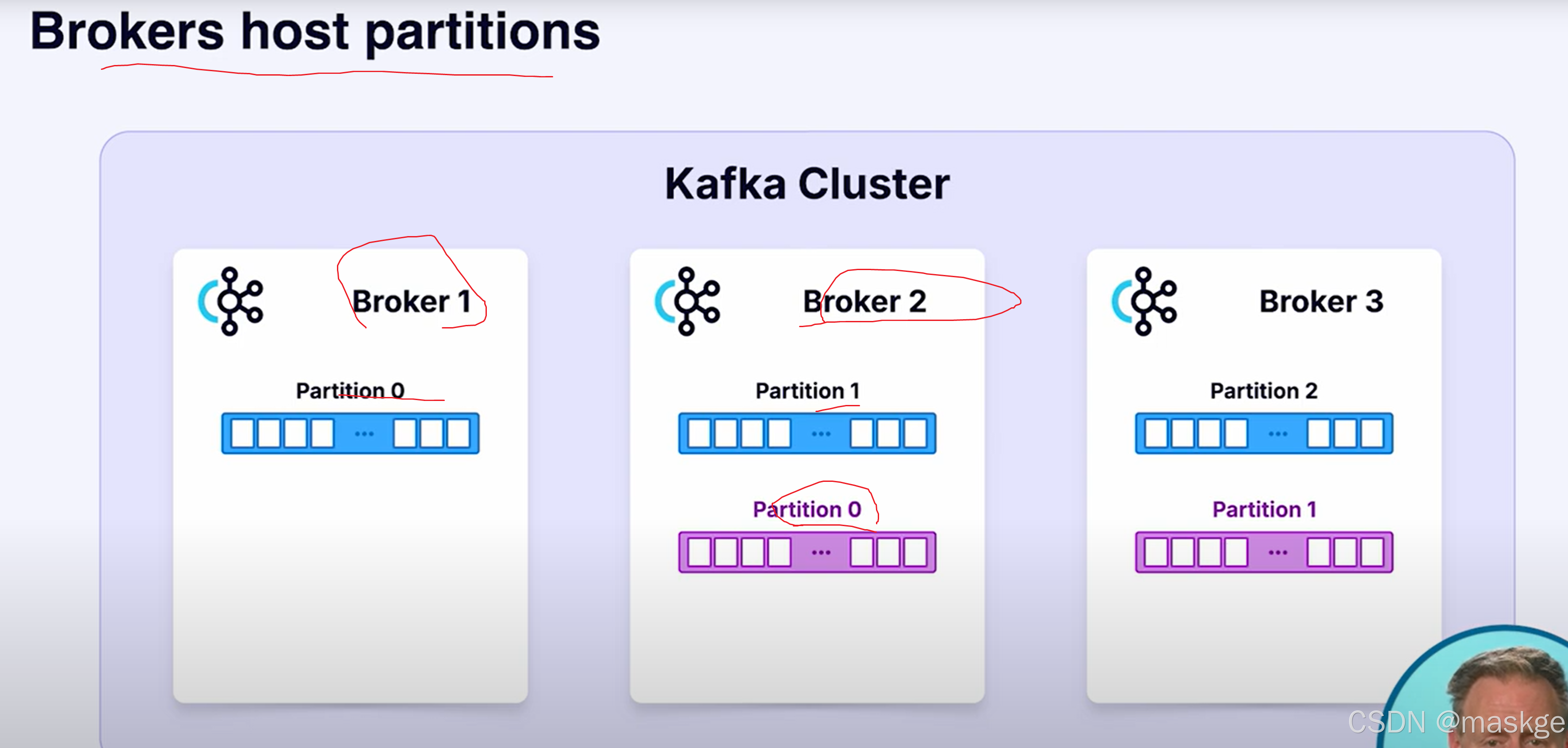
kafka4.0采用KRaft(基于raft协议),协调管理元数据,不再采用zookeeper

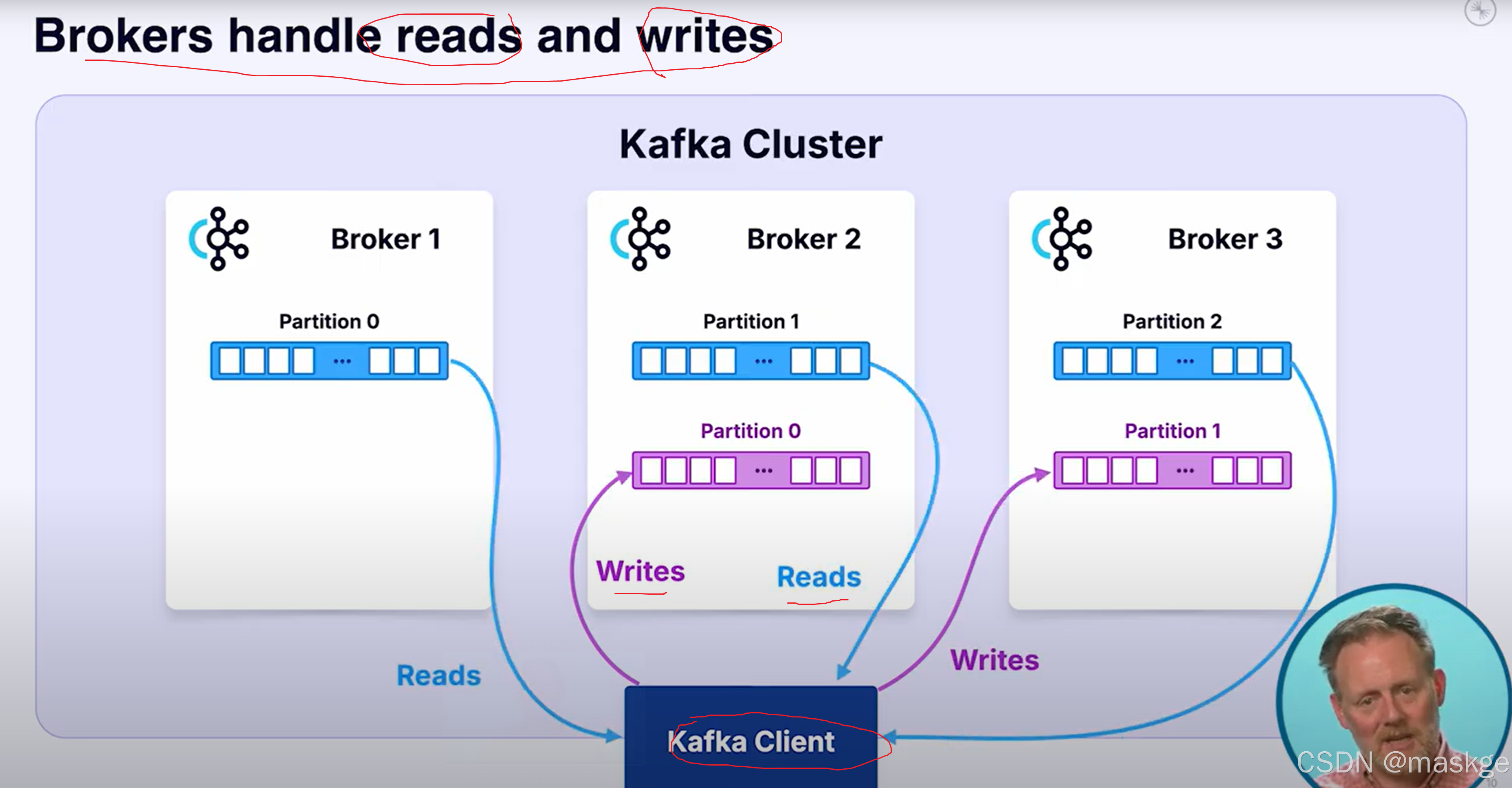
4. 复制(Replication):kafka通过复制实现容错
kafka复制分区跨brokers
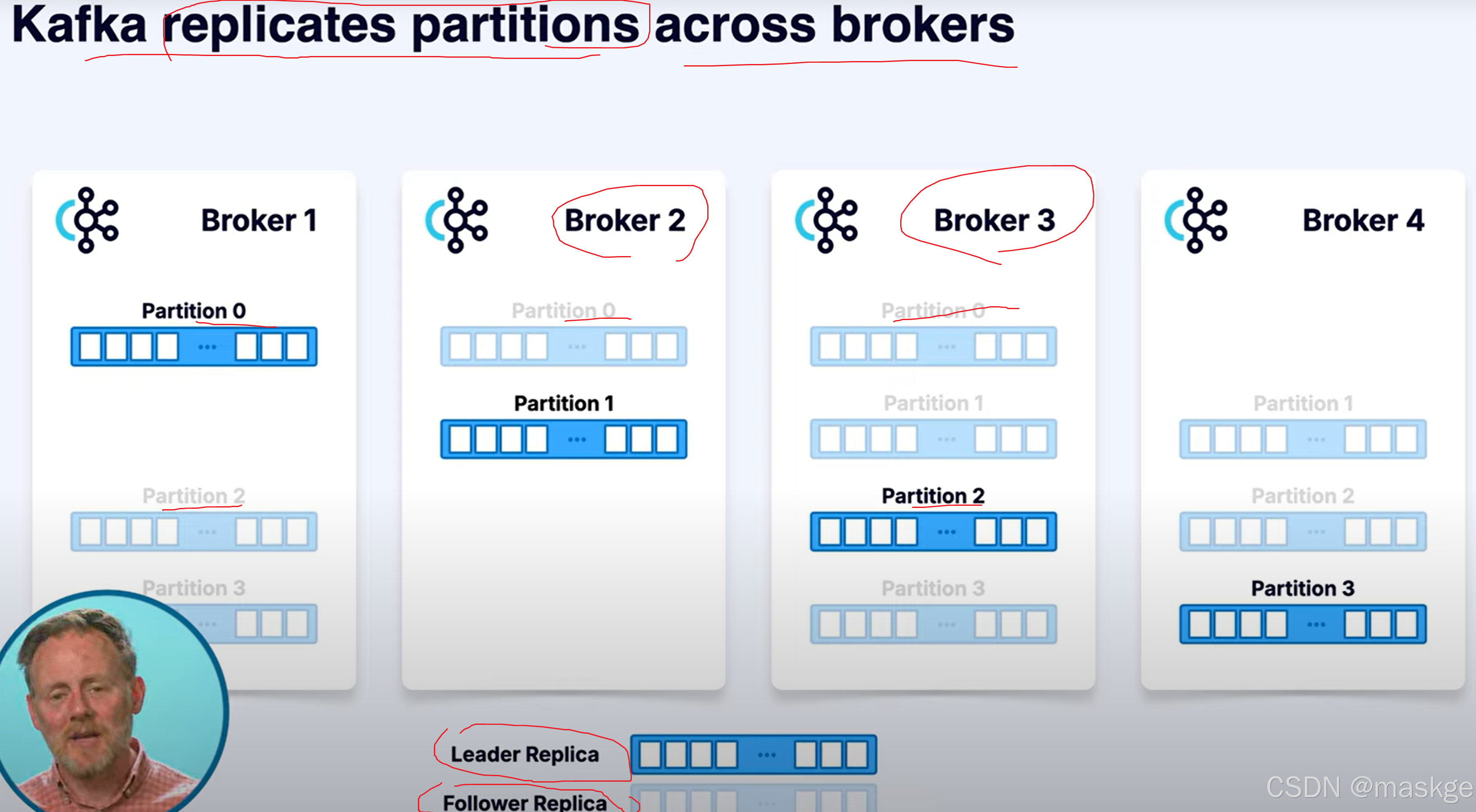
如果kafka leader broker 挂掉,集群会在剩余的分区中选择新的leader
kafka 客户端从leader进行读写消息
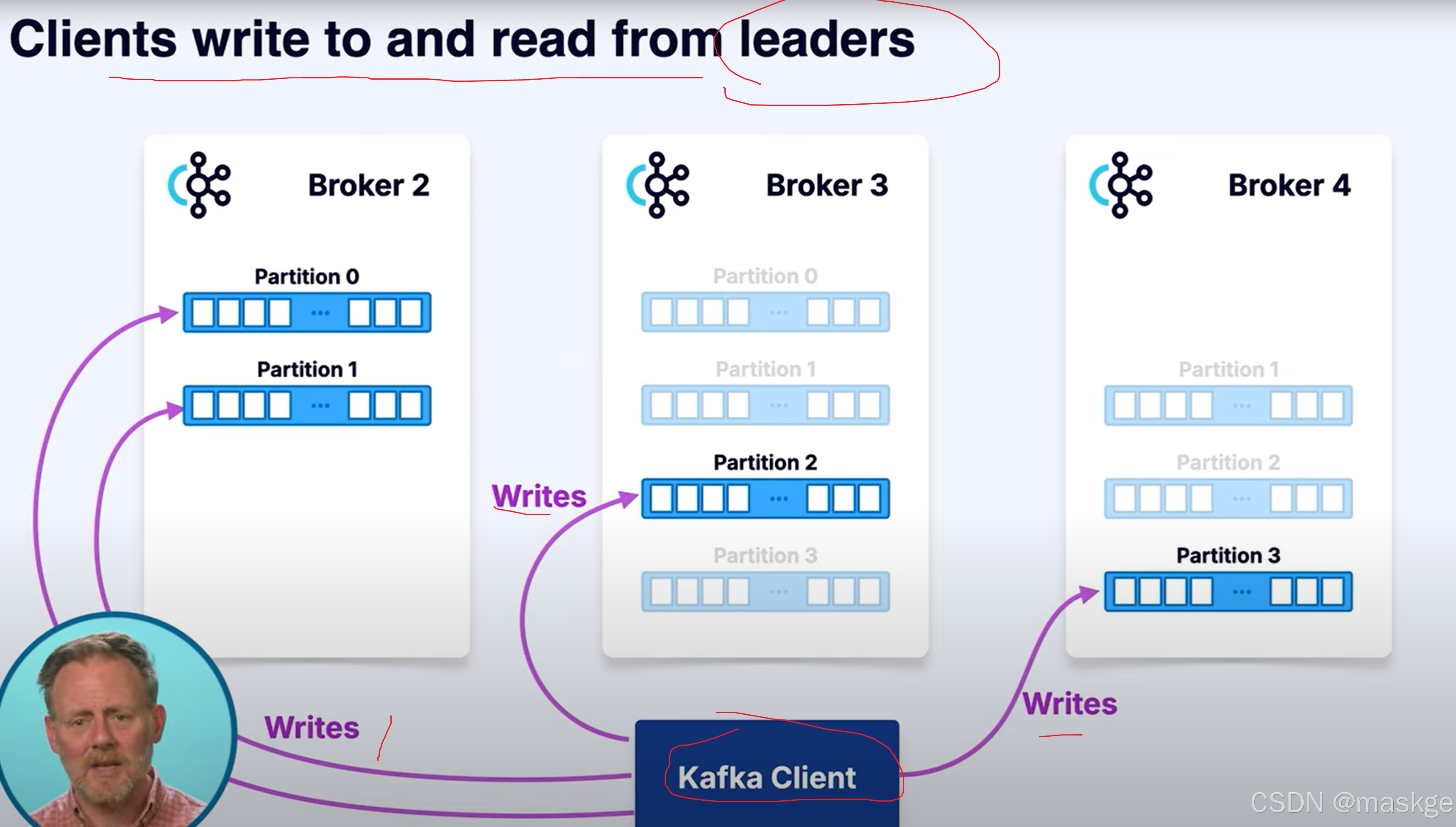
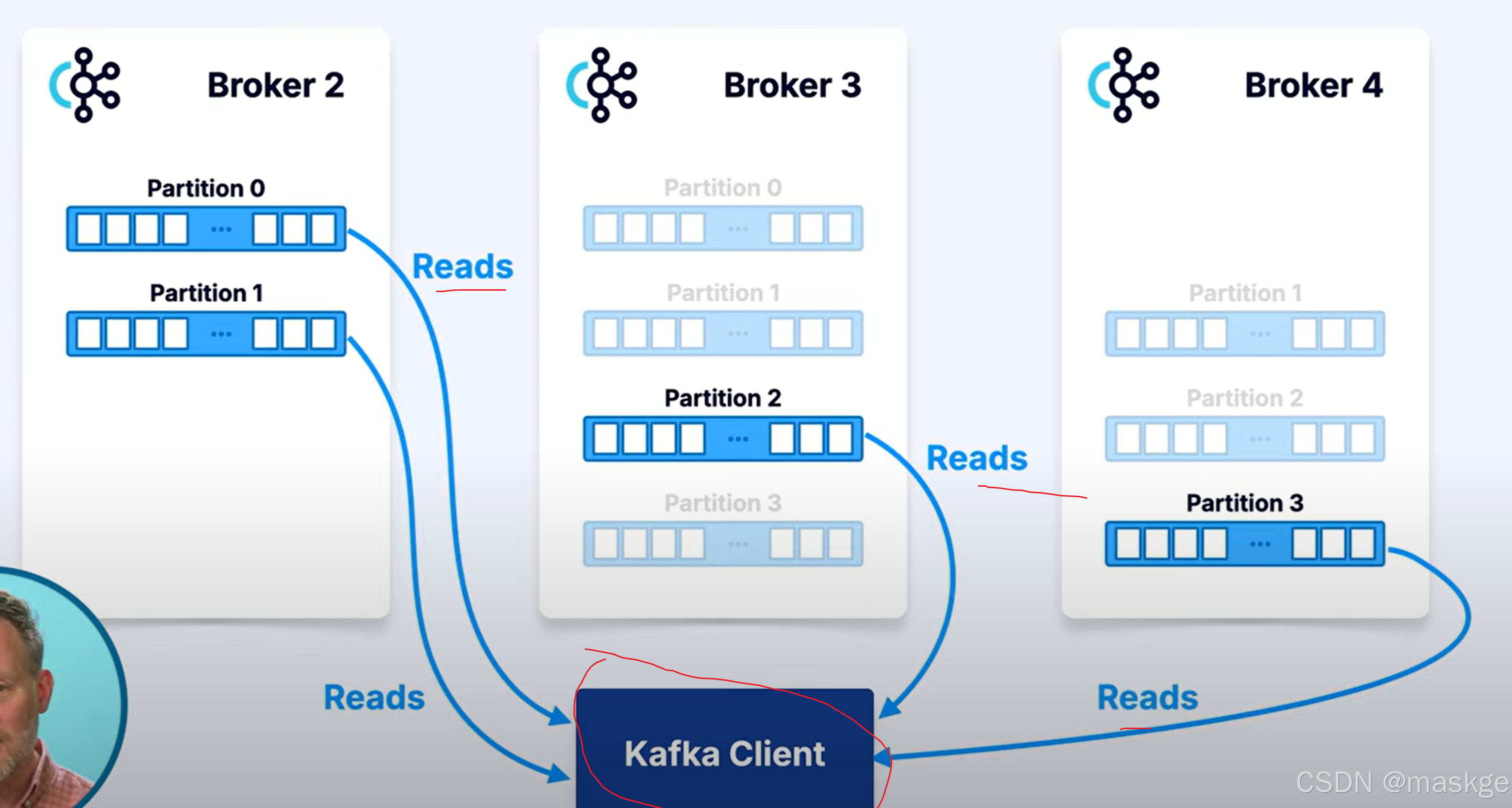
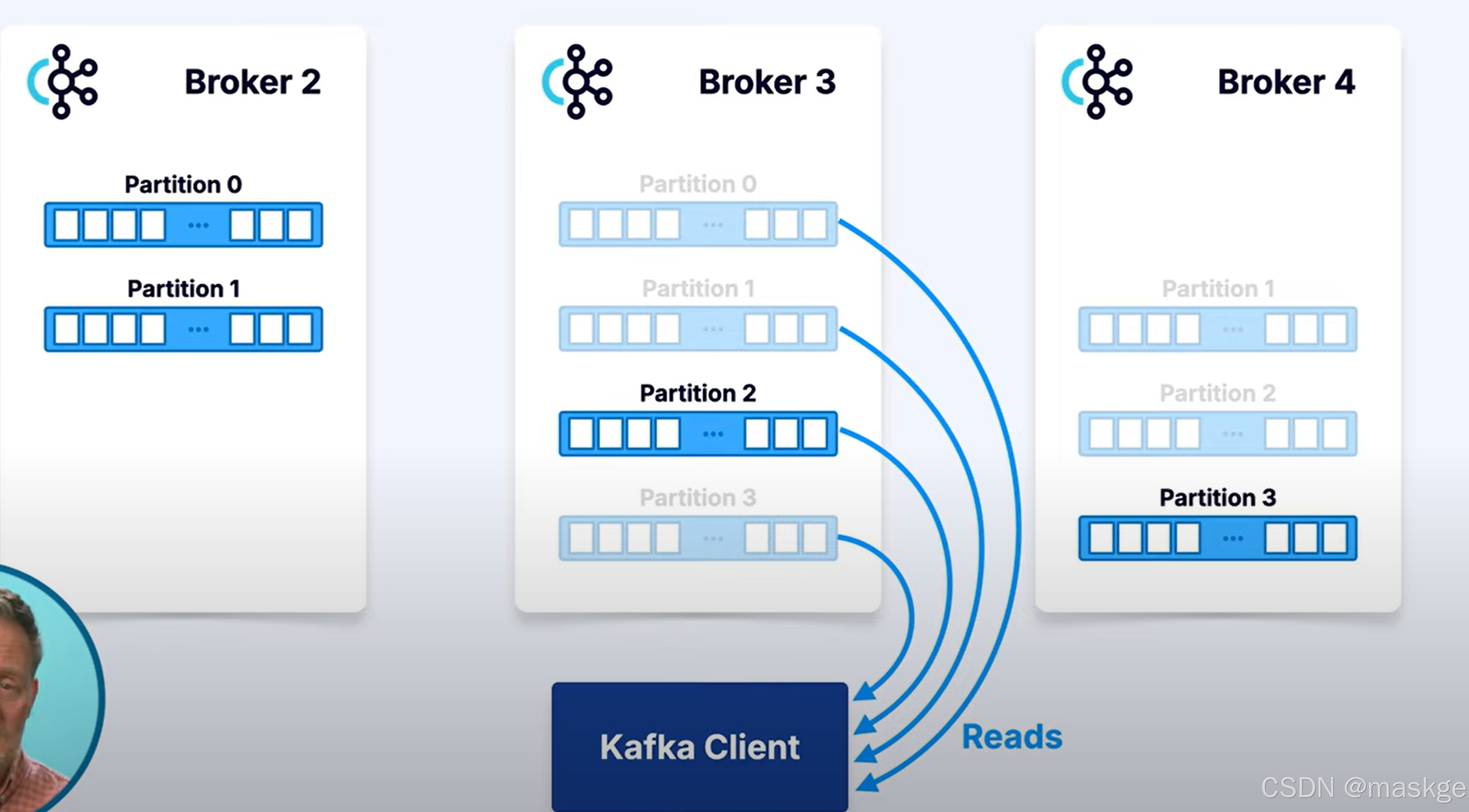
为了性能,kafka客户端,可以从follwers进行读取数据
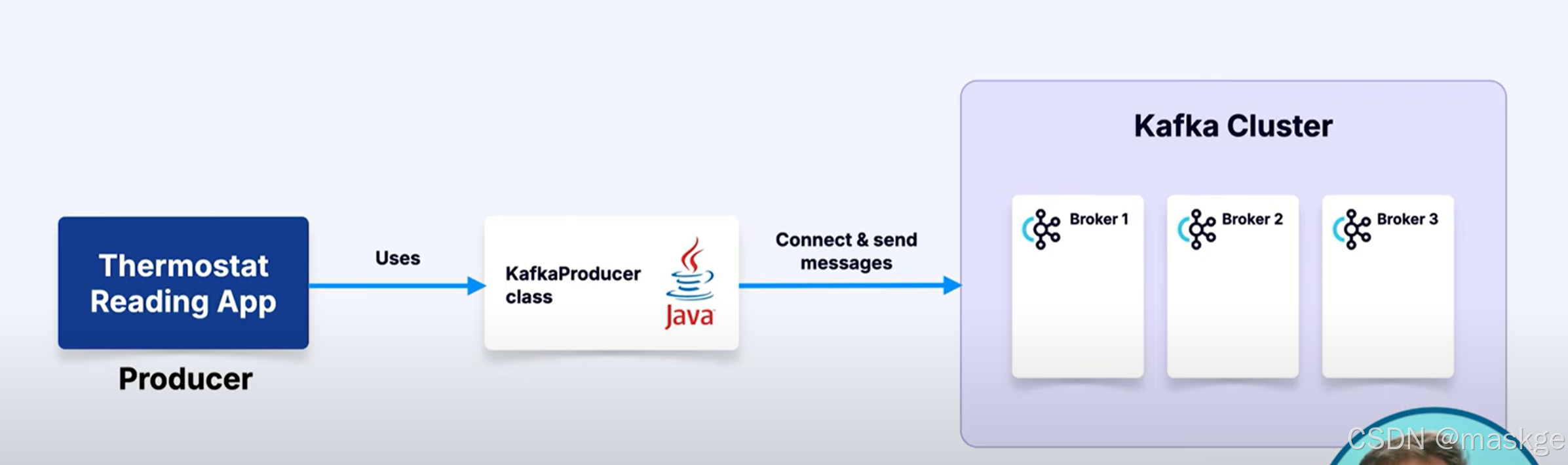
5.消费方(producers)
生产方发送消息到kafka


6.消费方(consumers):读取消息从topic,响应事件流
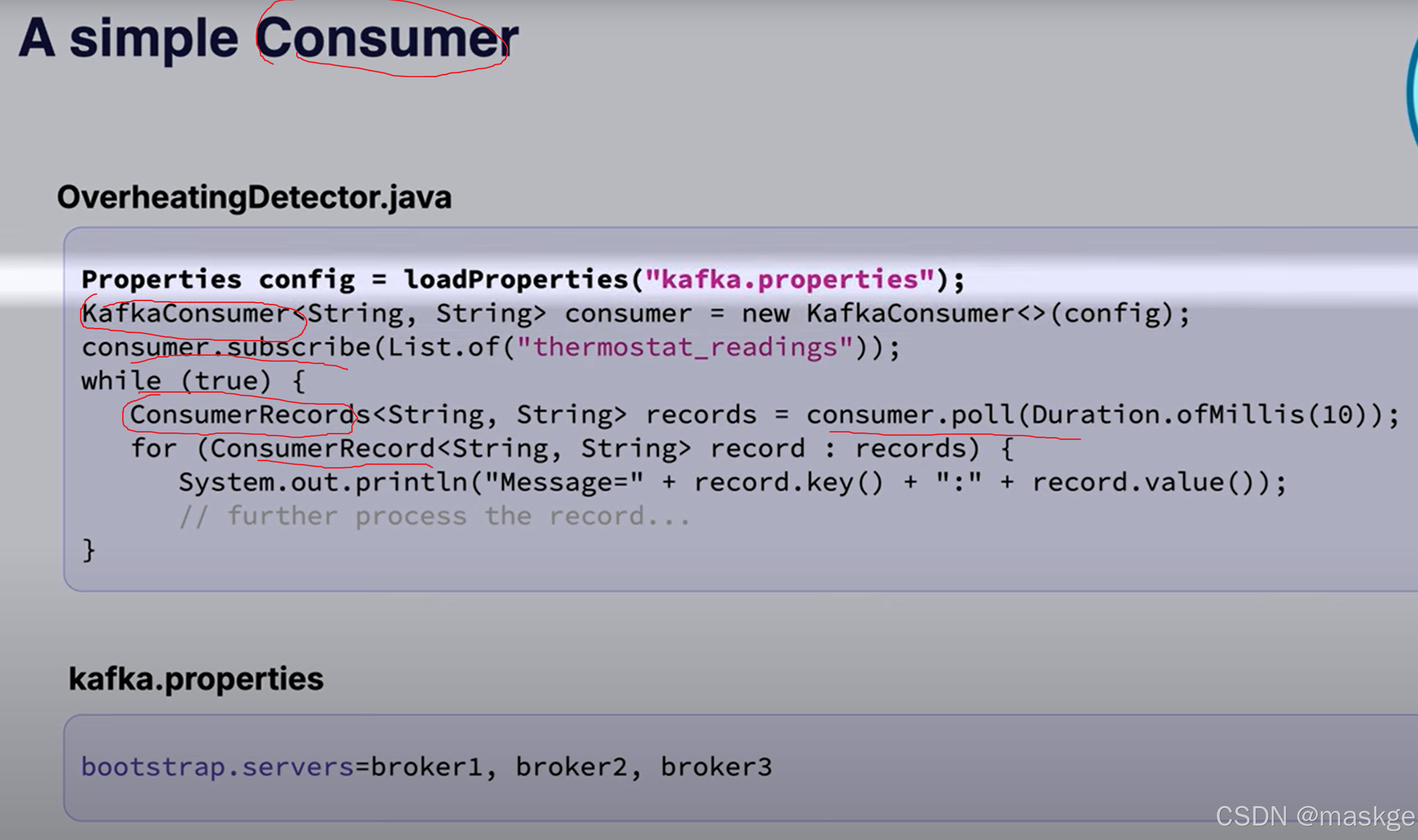

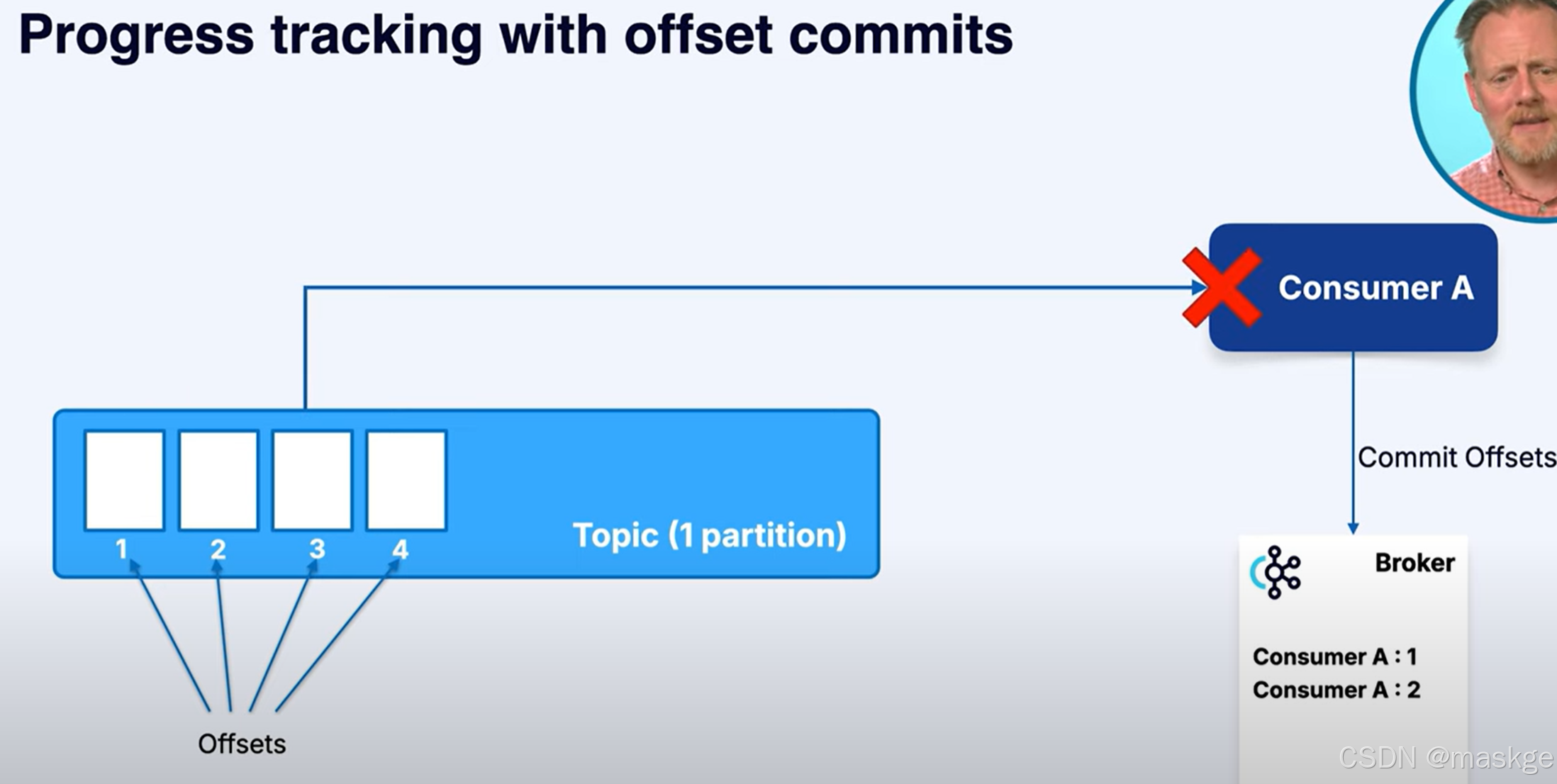
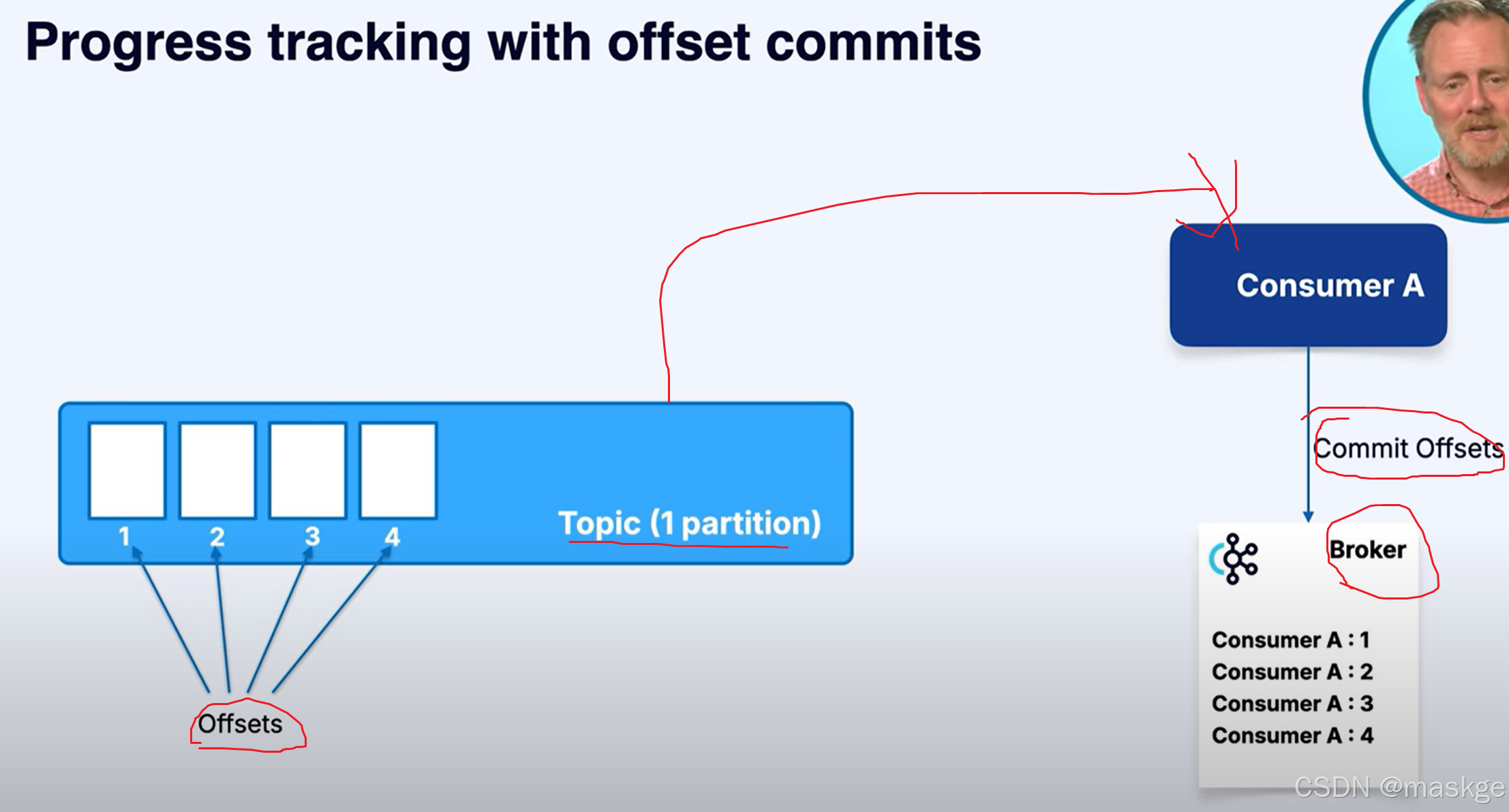
偏移量追踪(偏移量提交):offset commit:
kafka会记录每条已消费消息的偏移量;它能确保如果消费者离线,还能从上次中断的地方继续处理 。这些偏移量会提交回 Kafka 本身,并存储在一个内部主题中。如果消费者崩溃后重新启动,它会读取自己最后提交的偏移量,继续处理而不会丢失数据。
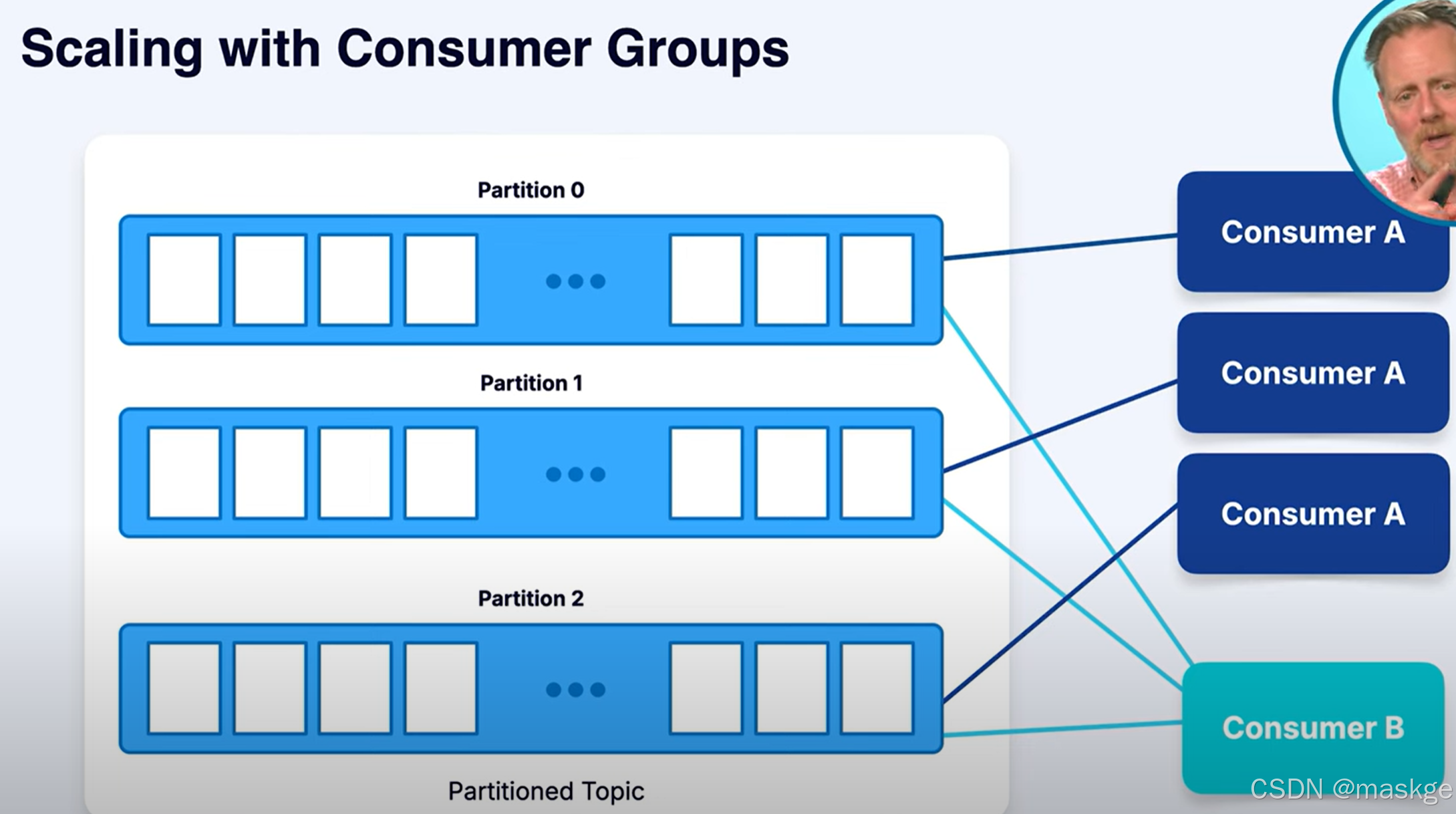
消费组伸缩(scaling with Consumer Groups):
消费方重新平衡(Rebalancing):
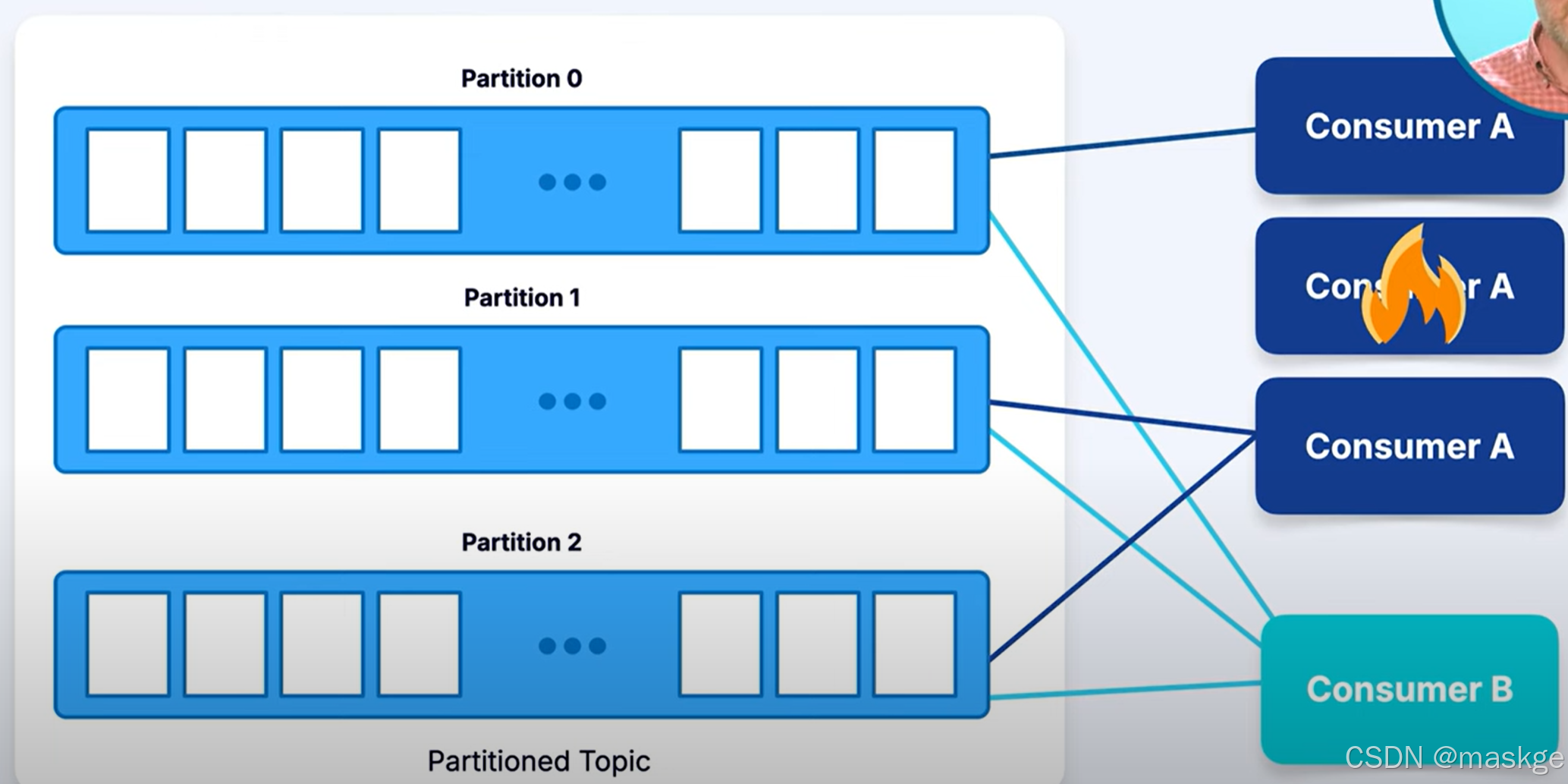
为了扩展处理能力,Kafka 支持消费者组。同一组中的所有消费者共同承担从topic分区读取数据的工作。Kafka会将每个分区分配给该组中的一个消费者 , 同一组中不会有两个消费者从同一个分区读取数据。这实现了并行处理:
-
如果一个主题有三个分区,且组中有三个消费者,则每个消费者会独立处理来自一个分区的消息。
-
如果添加更多消费者,Kafka 会自动在它们之间重新平衡分区。
-
如果某个消费者发生故障,其分区将重新分配给剩余的消费者,以维持处理。
kafka的基于日志设计即消费数据不删除数据。 多个消费者在不同的消费组,可以读取相同的消。这也就允许独立的应用处理相同的事件流不冲突。
消费者从 Kafka 中检索数据并进行处理。通过消费者组,可以实现水平扩展、并行处理并保证容错能力,同时能保持每个分区内消息的完整性和顺序。
7. Confluent Schema Registry:
-
具有结构化格式的消息被称作schema
-
提供了一个元数据服务层.是一个独立的服务,存储和管理schema
Schema Registry工作机制:
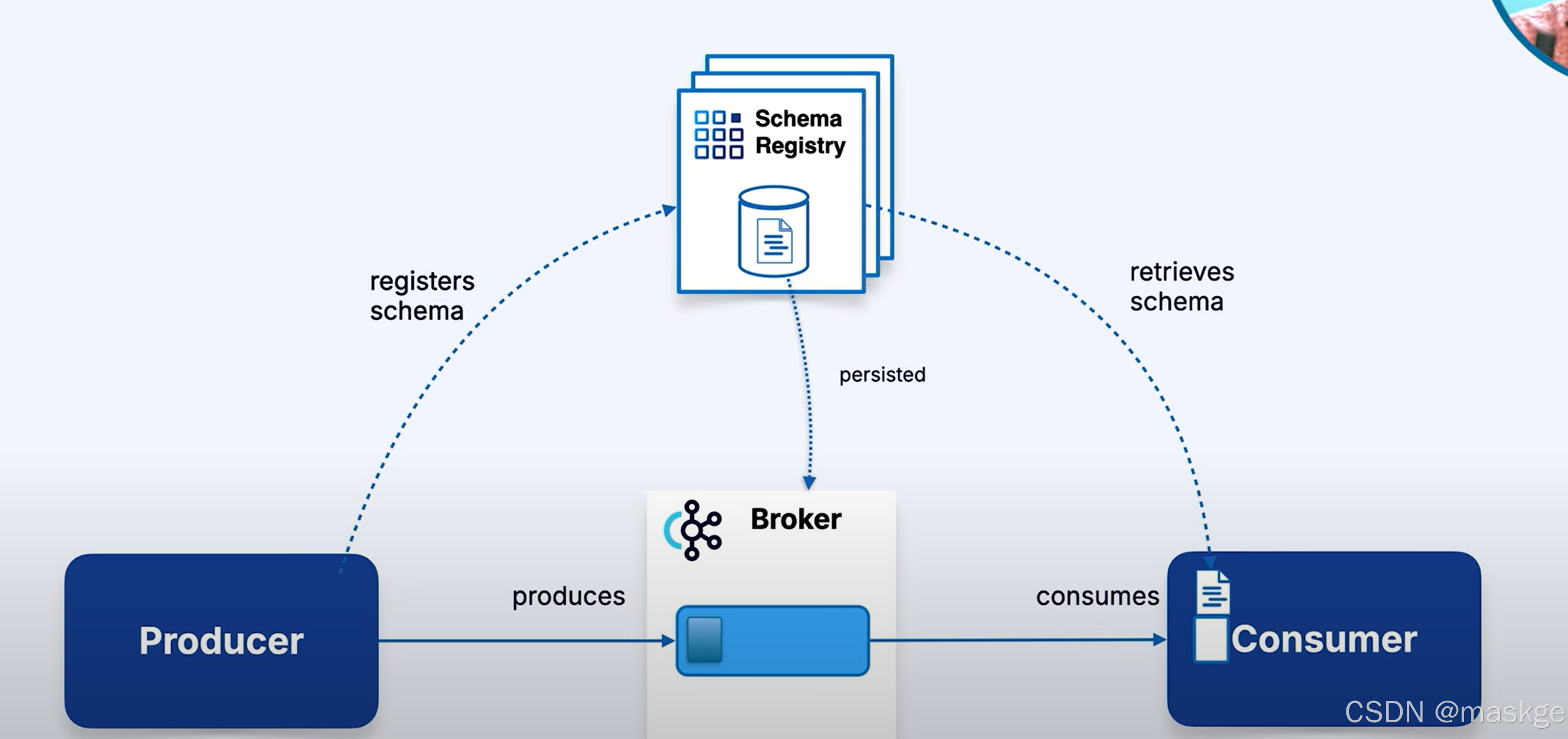
生产者发送消息时,首先会通过REST API 联系 Schema Registry 来注册schema(如果是新的schema)。生产者会在消息中包含schema ID,然后再将其发送到 Kafka 主题。此 ID 允许消费者在收到消息时查找schema,确保他们知道如何正确地反序列化和翻译消息。
在消费者端,消费者会根据 Schema Registry 检查消息中的Schema ID。如果Schema符合预期,则继续消费数据。如果不符合,消费者可能会抛出异常,表明它无法处理该版本的模式。此机制可防止消费者在消息格式意外更改时中断服务。
Schema兼容性规则::可以帮助管理schema优雅的变更
- 向前兼容(Forward Compatibility):旧的消费者能够读取由较新的schema生成的消息
- 向后兼容(Backward Compatibility):新的消费者能够读取用旧schema生成的消息
- 全兼容(Full Compatibility):保存向前和向后兼容
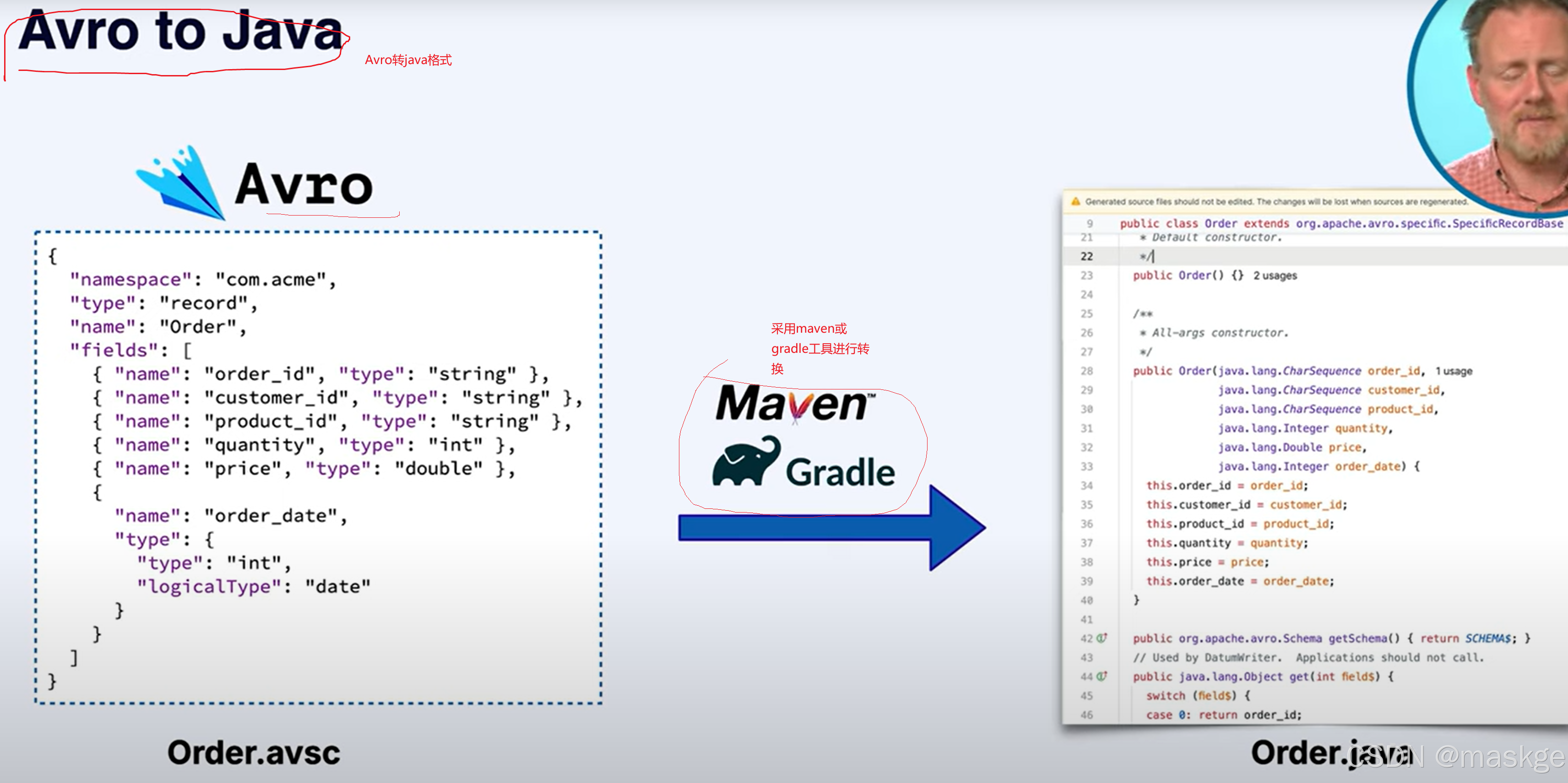
Schema序列化格式:

Avro转java
Schema Registry主要职责:
- 集中式Schema管理 : 所有生产者和消费者对消息格式拥有共同的理解。
- 容性强制 :通过在生产方和消费者中验证Schema,防止重大变更。
- 治理与协作 :团队可以使用 IDL 文件作为共享契约,安全地协商 Schema变更。
- 编译时检查 :可以在部署代码之前验证兼容性,避免运行时意外。
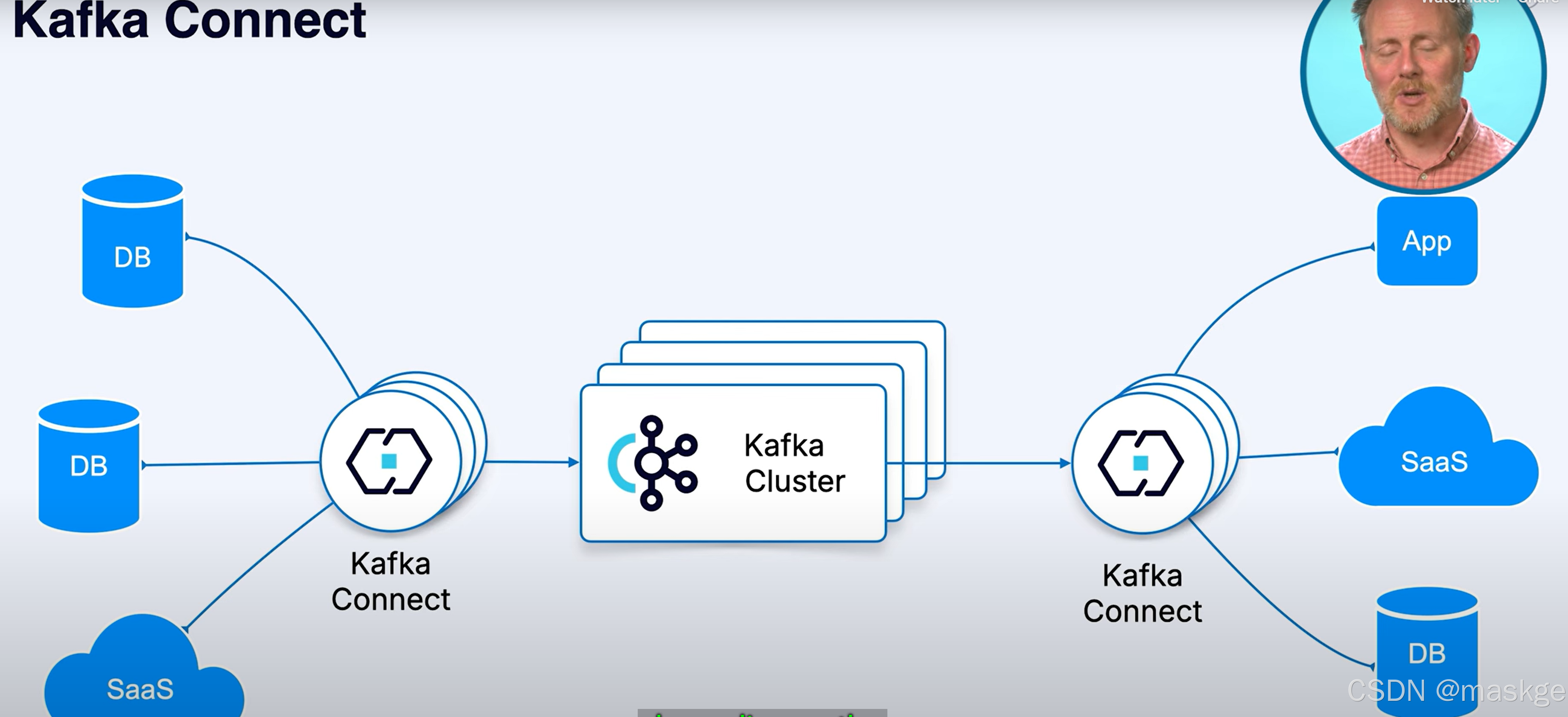
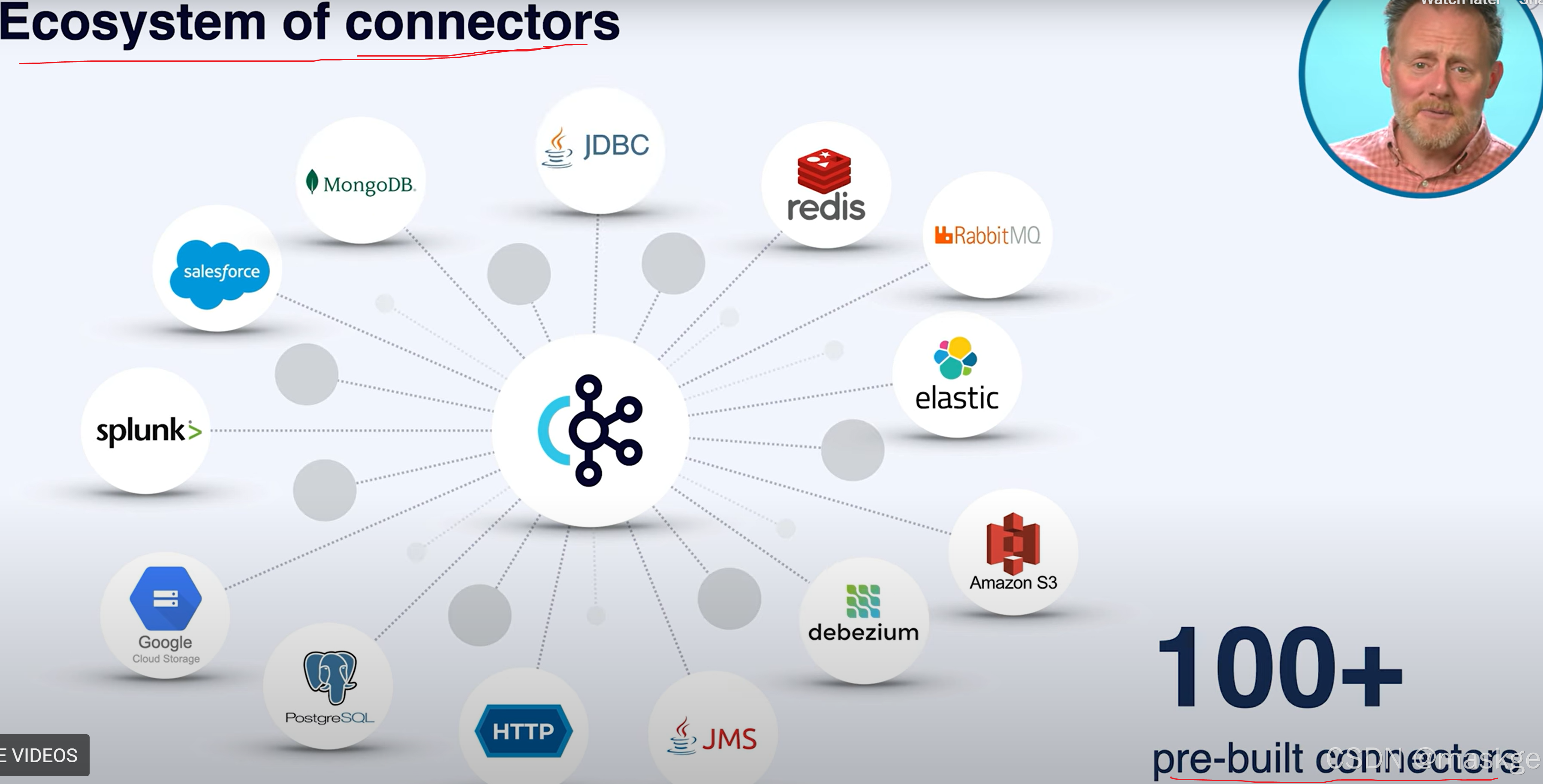
8.kafka connect:集成外部系统到kafka集群


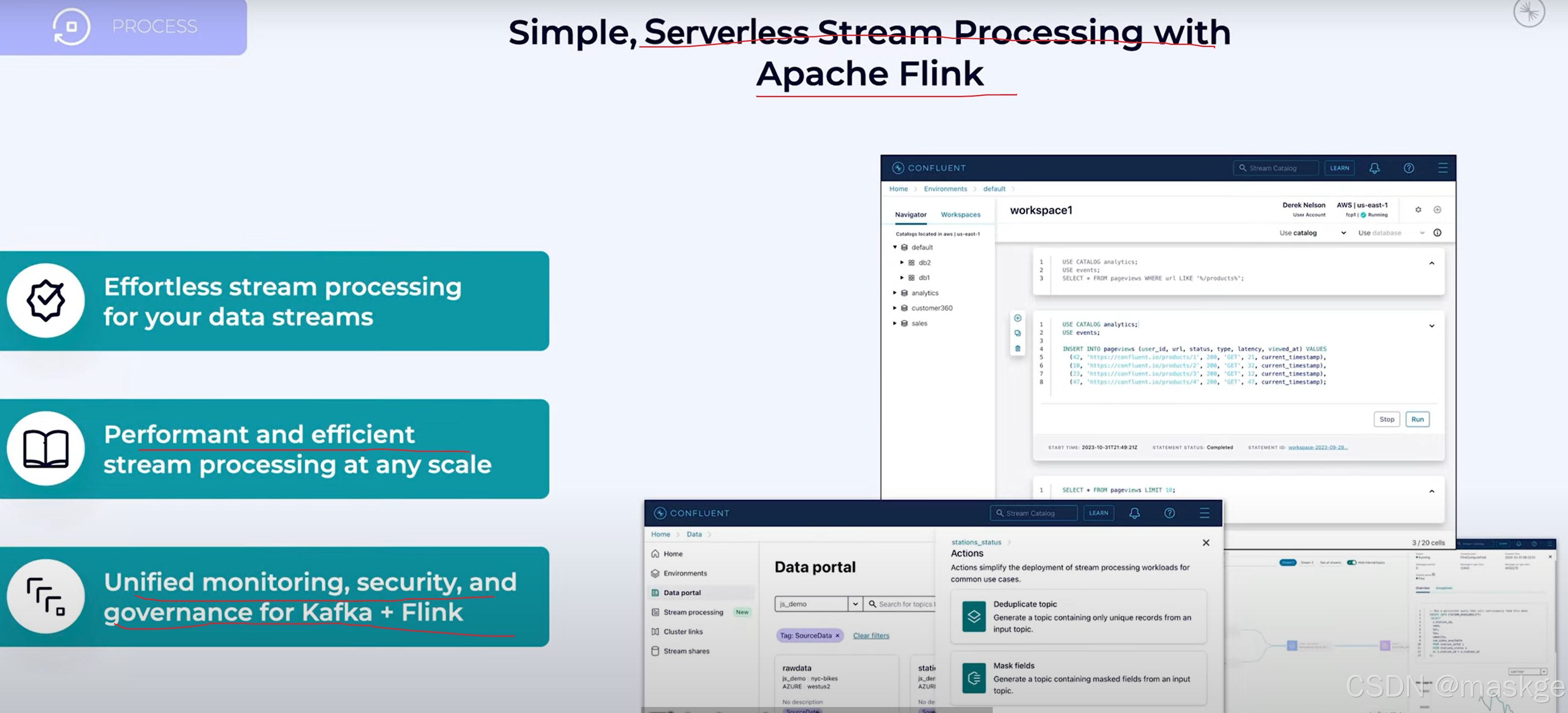
9.Stream Processing
实时流处理器:
- 窗口聚合(例如,统计每分钟的页面浏览量)
- 流到表的连接(例如,使用用户个人资料丰富点击流数据)
- 事件过滤和重复数据去重
- 对延迟或乱序数据的恢复能力
流处理框架专为大规模管理状态、排序和容错而设计。
Flink是事实的流处理标准
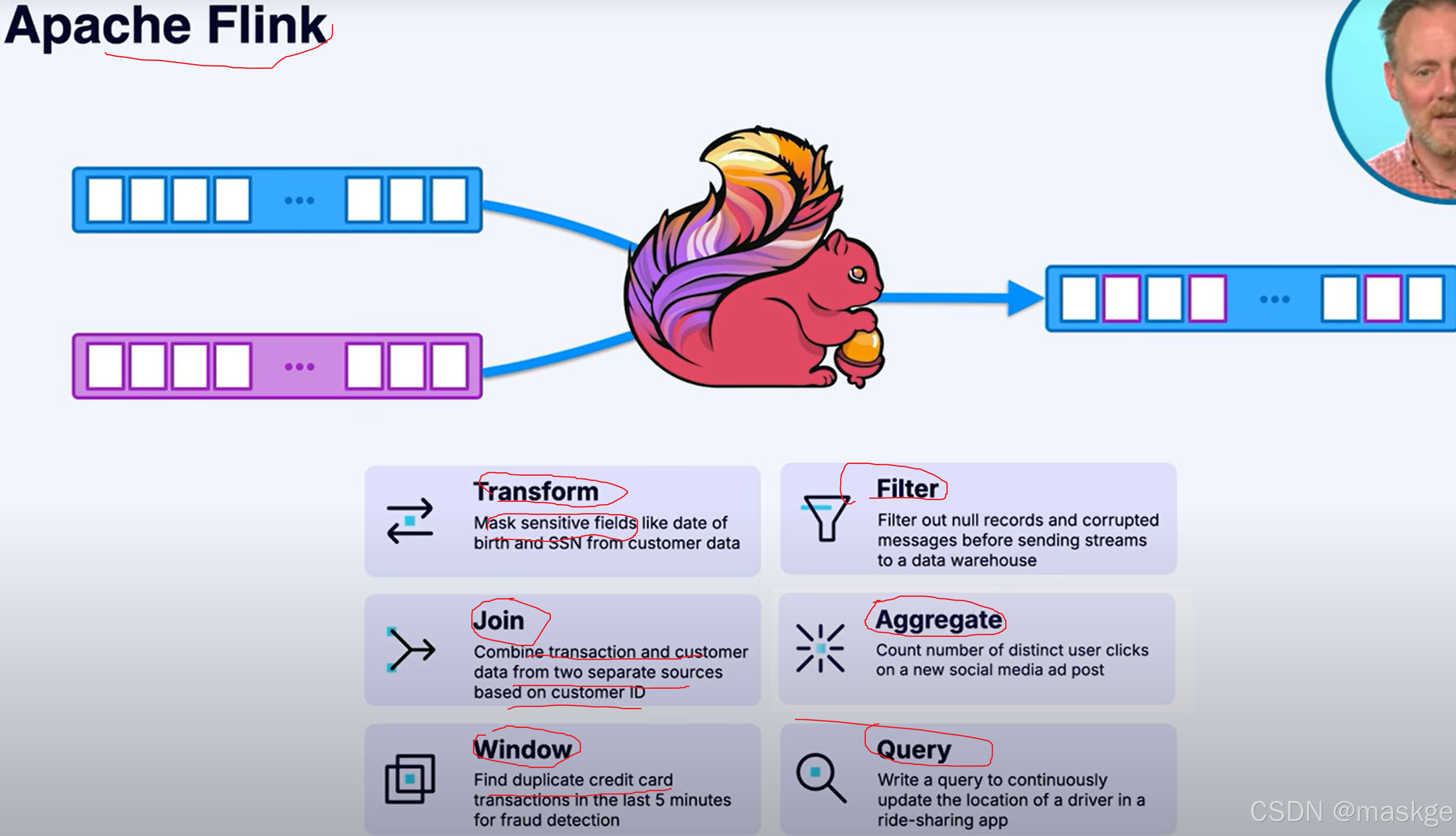
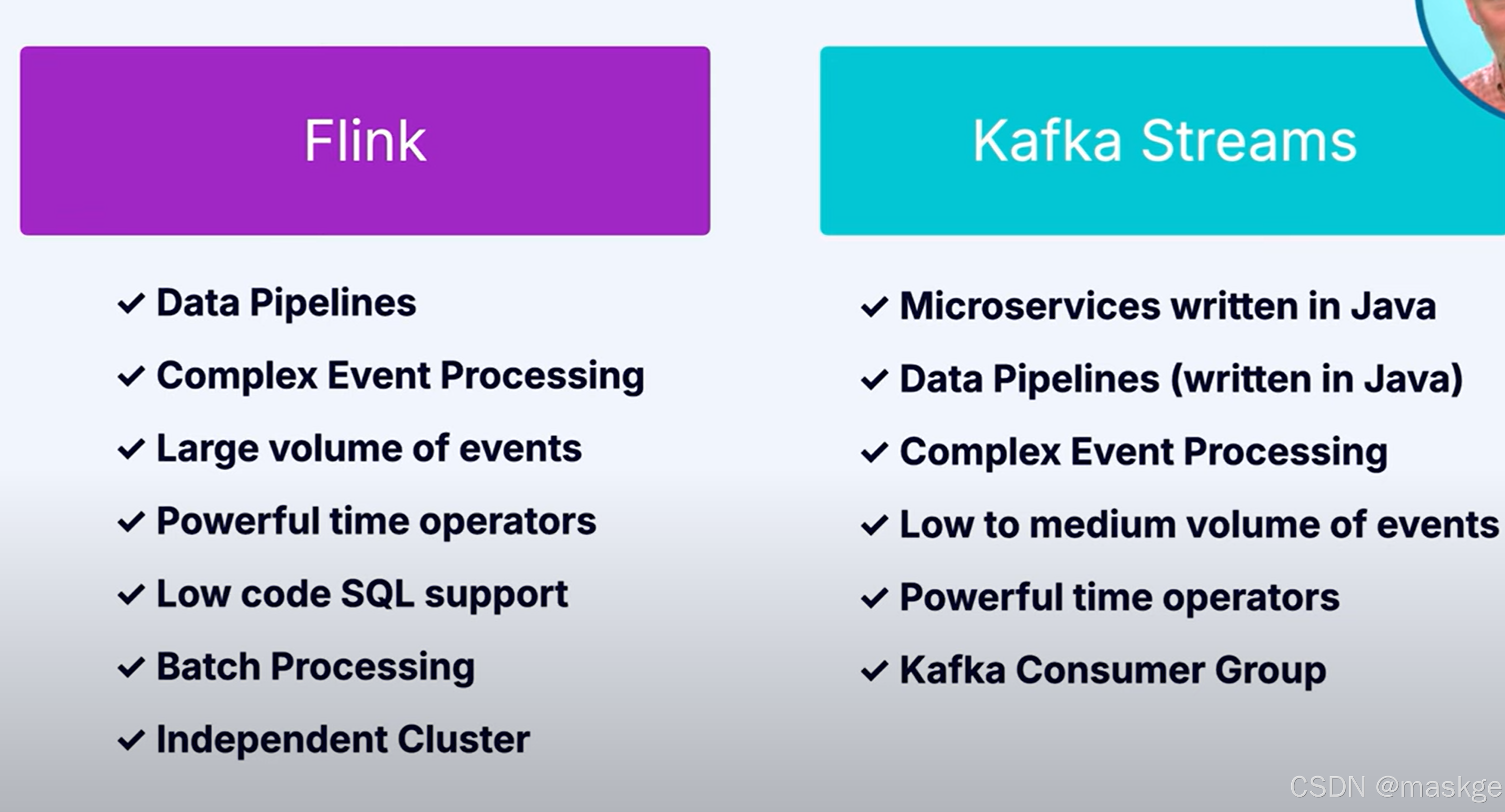
流处理选型对比:Flink VS kafka streams
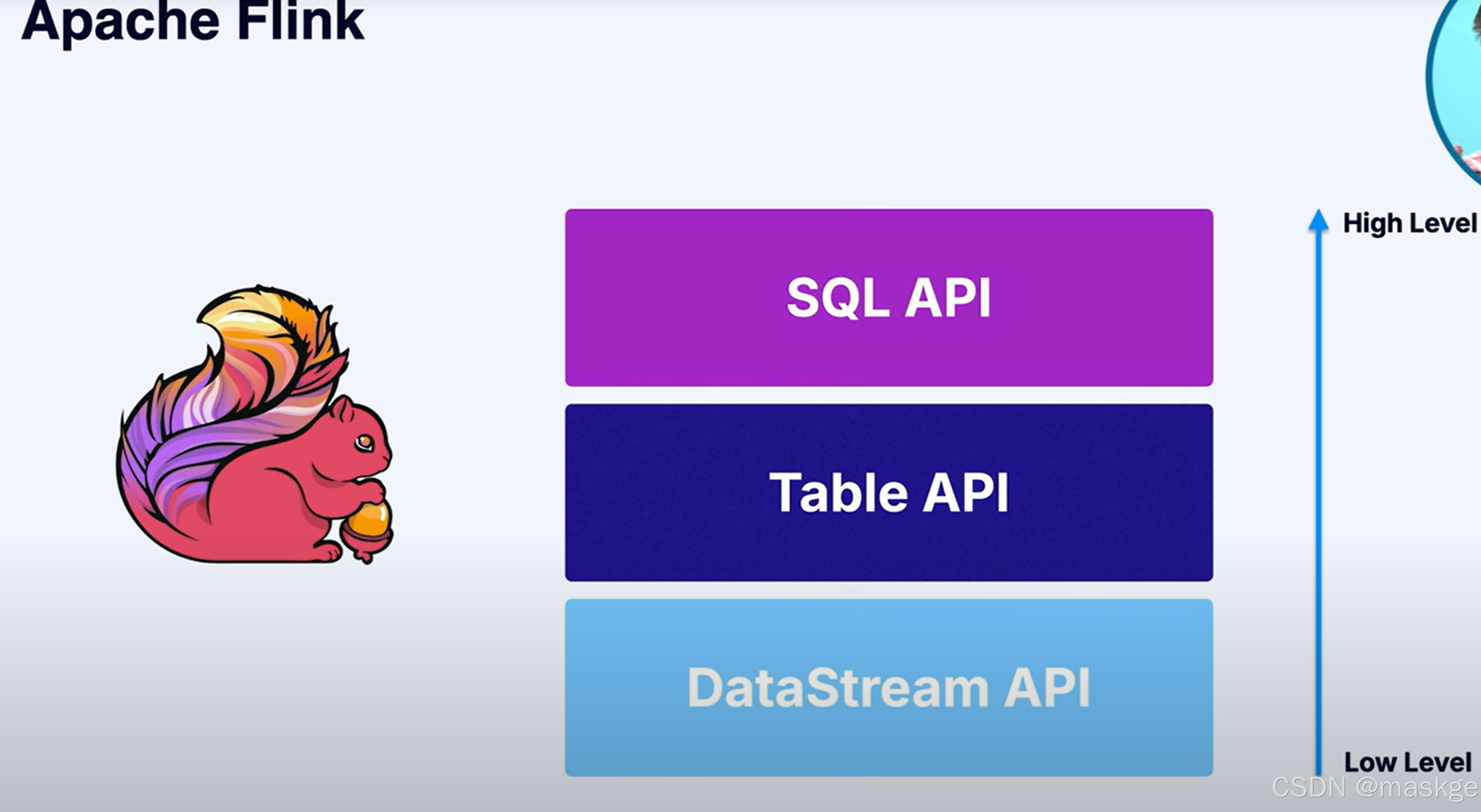
flink SQL
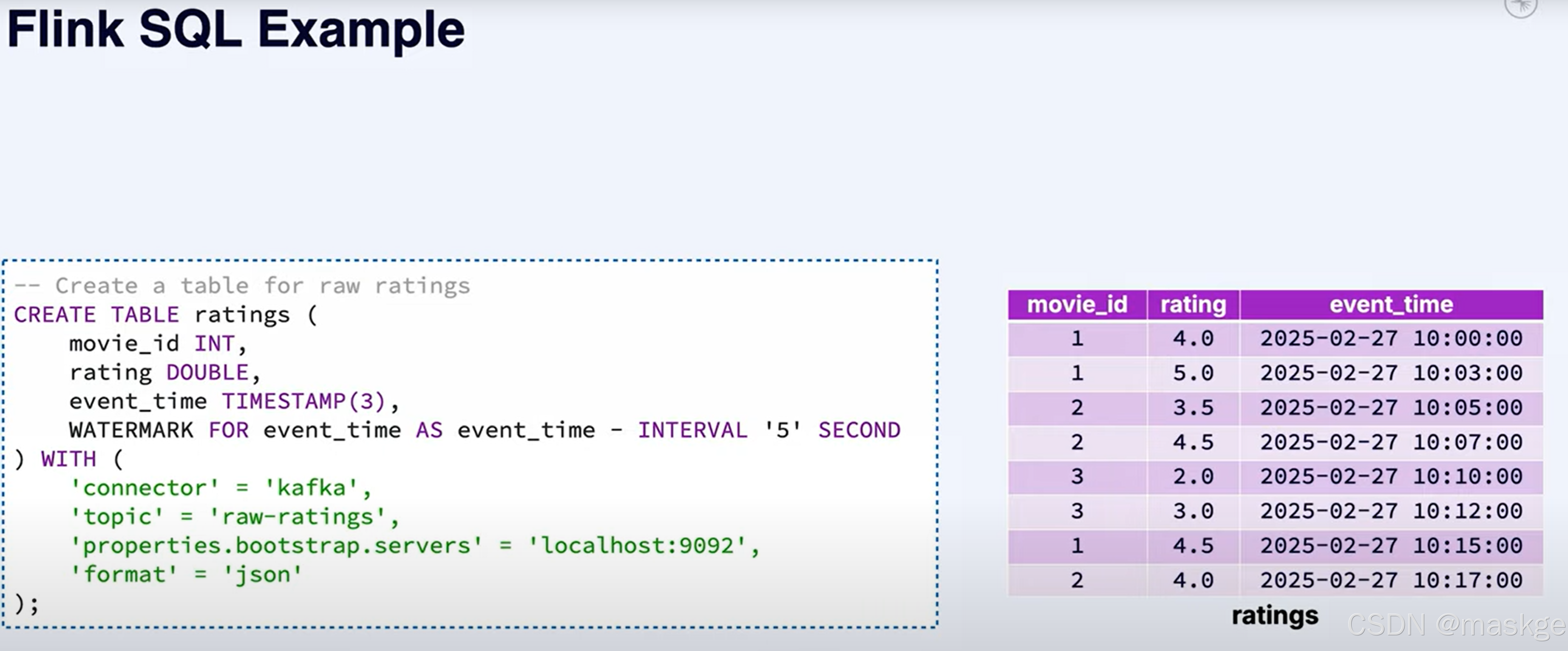




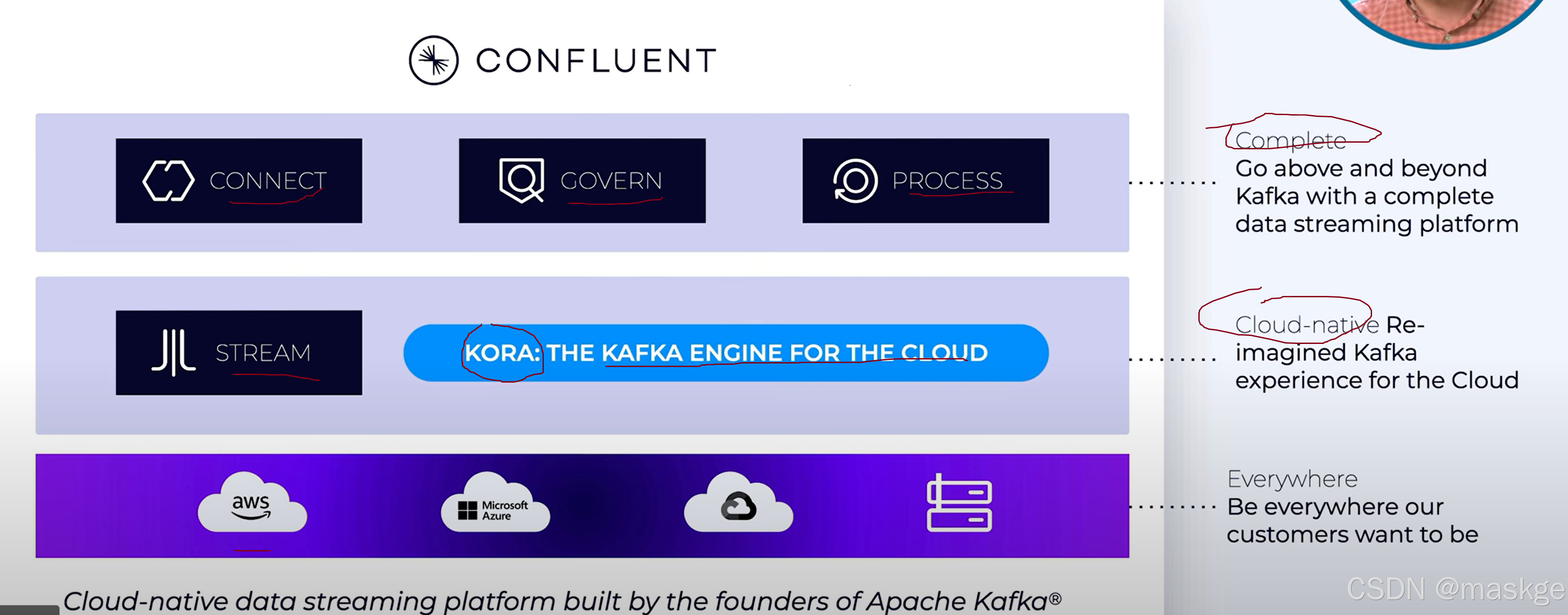
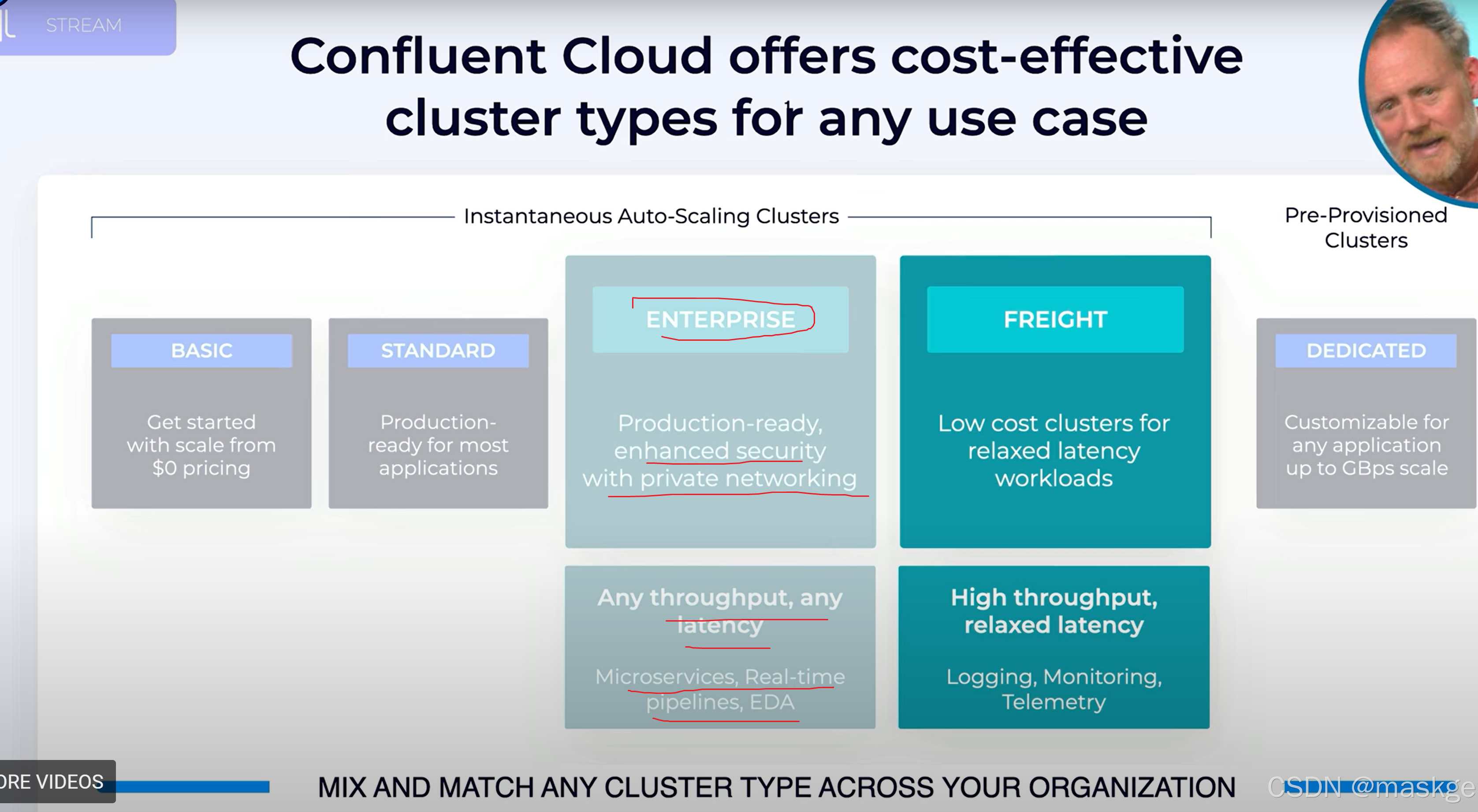
10.Confluent 商业kafka介绍