目录
[二、核心技术一:PagedAttention --- 显存管理的革命](#二、核心技术一:PagedAttention — 显存管理的革命)
[2.1 传统注意力缓存的缺陷](#2.1 传统注意力缓存的缺陷)
[2.2 分页式存储管理](#2.2 分页式存储管理)
[三、核心技术二:张量并行 --- 多GPU推理的基石](#三、核心技术二:张量并行 — 多GPU推理的基石)
[3.1 什么是张量并行?](#3.1 什么是张量并行?)
[3.2 vLLM 的实现方式](#3.2 vLLM 的实现方式)
[四、核心技术三:连续批处理 --- 动态合并请求](#四、核心技术三:连续批处理 — 动态合并请求)
[4.1 传统批处理](#4.1 传统批处理)
[4.2 连续批处理(Continuous Batching)](#4.2 连续批处理(Continuous Batching))
[六、vLLM 工作流程](#六、vLLM 工作流程)
[总结:vLLM 的价值与未来](#总结:vLLM 的价值与未来)

前言
在大语言模型(LLM)推理任务中,显存管理和计算效率一直是制约其实际部署的关键问题。尤其是随着模型规模越来越大、请求并发数不断增加,如何高效地利用GPU资源成为技术团队亟需解决的挑战。而vLLM 作为一个高性能推理引擎,依托其创新的 PagedAttention 机制、张量并行 技术和连续批处理能力,显著提升了推理吞吐量并降低了响应延迟,成为当前LLM服务化部署的重要选择。
一、vLLM简介:为什么它如此重要?
vLLM是由加州大学伯克利分校的研究者开发的开源框架,旨在为LLM提供高效的在线服务。它不像传统的推理框架那样局限于单机或小规模部署,而是针对生产级场景设计,支持高吞吐量和低延迟。想象一下,你有一个70B参数的模型,需要处理成千上万的并发请求------传统的PyTorch或TensorFlow可能因显存碎片或计算瓶颈而崩溃,而vLLM通过智能的资源管理,让这一切变得高效。
核心在于三个机制:张量并行 实现模型拆分多卡运行;PagedAttention 优化KV缓存的存储;连续批处理动态调度请求。这些技术相结合,不仅降低了显存占用,还提升了整体吞吐量,让多GPU推理变得简单可靠。接下来,我们逐一拆解。
在传统LLM推理中,以下几个方面尤其影响效率:
显存碎片化:每个请求的键值缓存(KV Cache)长度不定,容易产生显存碎片。
静态批处理限制:通常只能将相同长度的请求拼成一批,容易造成GPU计算资源浪费。
单卡显存限制:大模型即使推理也需大量显存,单卡难以承载高并发请求。
vLLM 通过如下三大核心技术,系统性解决了上述问题。
二、核心技术一:PagedAttention --- 显存管理的革命
PagedAttention 是 vLLM 中最重要的贡献之一,其设计灵感来自操作系统中的虚拟内存与分页机制。
2.1 传统注意力缓存的缺陷
在标准的注意力计算中,每个序列生成过程中都需要存储键值向量(KV Cache)。由于序列长度可变,容易导致显存碎片化,利用率低。
2.2 分页式存储管理
vLLM 将不同请求的 KV Cache 划分为固定大小的块(block),每个块可被多个请求共享(如并行采样时),由一个中央管理单元统一调度。这样一来:
显著减少显存碎片;
支持更灵活的内存分配与释放;
提升整体显存利用率,尤其是在处理长文本和多样化请求时效果显著。
三、核心技术二:张量并行 --- 多GPU推理的基石
vLLM 原生支持张量并行 (Tensor Parallelism),用户只需通过 tensor_parallel_size 参数即可指定使用的 GPU 数量,模型会自动拆分并分布到多卡上。
3.1 什么是张量并行?
与数据并行不同,张量并行是将模型本身的层结构(如矩阵乘)进行切分,分布到多个设备上分别计算,再通过通信整合结果。这种方式特别适合超大模型推理。
3.2 vLLM 的实现方式
-
模型权重均匀分布在各GPU上;
-
每张卡仅计算部分结果,通过 collective 通信(如All-Reduce)聚合;
-
推理过程中自动处理设备间通信,用户无需关心模型切分细节。
这一机制使得vLLM能够轻松扩展至多卡甚至多机环境,有效突破单卡显存限制。
四、核心技术三:连续批处理 --- 动态合并请求
目的:减少 GPU 空闲时间,提升吞吐量
传统批处理策略需要等一批请求全部计算完成才能进行下一批,容易造成GPU空闲。
4.1 传统批处理
时间轴: 等待请求1/2/3对齐 → 统一推理 → 等待下一批
4.2 连续批处理(Continuous Batching)
vLLM 实现了动态批处理机制,允许:
时间轴: 请求1进入 → 请求2进入(直接插入批次) → 请求3进入(继续拼接)
动态合并:不同长度的请求可以拼在一起,不用等齐。
在线插入:新请求随时加入已有批次,GPU 几乎无空闲。
吞吐量提升:在高并发场景下尤为明显。
🛠 比喻:像地铁一样,随到随上,不必等所有人都到齐再发车。
新请求随时加入已运行的批次中;
完成推理的请求及时退出,释放资源;
自动优化不同长度请求的组合方式,最大化GPU使用率。
该技术尤其适合实时推理场景,如聊天机器人、代码补全等需低延迟响应的应用。
五、实际性能表现
在实际测试中,vLLM 相比传统推理方案(如 Hugging Face Transformers)可实现:
最高提升24倍的吞吐量;
更低的响应延迟;
更好的长上下文支持能力。
尤其是在处理多用户、高并发、不同请求长度的场景中,vLLM 表现出了显著的性能优势。
六、vLLM 工作流程
想象一个高效工厂处理订单(你的请求):
🧩 第1步:准备工厂(初始化)
张量并行:把大模型像切蛋糕一样分到多个GPU上。每个GPU只负责一部分计算。
内存池 :在显存里预先划出一堆固定大小的空位(Block),准备存放"记忆"。
📥 第2步:订单到达(请求接入)
- 你的请求(如"写一首诗")进入等待队列。
🚌 第3步:灵活拼车(连续批处理)
调度器不会傻等"满员发车"。
它会实时 把新订单动态插入到正在进行的计算中,确保GPU永不空闲。
💾 第4步:高效管理记忆(PagedAttention)
为你请求的"记忆"(KV Cache)分配刚才准备好的空位(Block)。
这些记忆可以分散存储,通过一个"目录"快速查找。杜绝浪费,毫无碎片。
⚡ 第5步:协同生产(计算与通信)
拆分计算:每个GPU用自己那部分模型权重并行计算。
汇总结果:通过高速连接通信,汇总所有GPU的部分结果,得到最终输出(下一个词)。
循环:重复这个过程,直到生成完整回复。
🧹 第6步:交付与清场(返回与释放)
结果返回给你。
它占用的所有空位(Block) 被立刻回收,放入池中等待下一个订单。
总结:vLLM 的价值与未来
vLLM 不仅是一套技术解决方案,更为LLM的高效推理设立了新标准。其通过:
PagedAttention 解决显存碎片问题(确保每张GPU的显存高效使用,优化整体性能);
张量并行 实现多卡扩展;
连续批处理 提升GPU利用率,
技术 解决了什么痛点 带来的好处 张量并行 单卡装不下大模型 横向扩展,支持更大模型、更多GPU PagedAttention 显存碎片化,浪费严重 显存利用率极高 ,同等显存下并发量提升数倍 连续批处理 GPU等请求,凑齐一批才干活 吞吐量巨高,GPU几乎时刻满负荷工作 最终效果: 用更少的卡,以更快的速度,同时服务更多的人。
📊 整体示意图
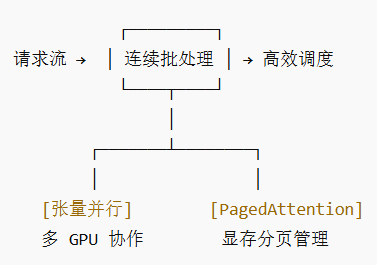
最终效果:在相同硬件条件下,vLLM 可以承载更多请求、更长上下文、更快响应,成为大规模模型部署的核心引擎。
这三者协同工作,打造出一个极其高效且灵活的推理系统。
未来,随着模型规模的进一步增长和应用场景的复杂化,vLLM 及其背后思想无疑将会影响更多推理系统的设计,成为大规模LLM服务化部署的核心基础设施。
附录:快速开始示例
查看官方文档了解更多用法: vLLM Documentation
python
pip install vllm
# 指定张量并行大小,使用2个GPU
python -m vllm.entrypoints.api_server \
--model meta-llama/Llama-2-7b-hf \
--tensor-parallel-size 2