目录
[早期IP 地址分类](#早期IP 地址分类)
[公有 IP 和私有 IP 有什么区别?](#公有 IP 和私有 IP 有什么区别?)
早期IP 地址分类
IP 地址(Internet Protocol Address)是分配给网络中设备的一个唯一标识符,用于标识主机和网络。
在 IPv4 中,IP 地址是 32 位的二进制数,通常表示为四个十进制数(0~255),用点分十进制表示,
-
核心要点:这是IPv4时代的重要概念,用于划分网络和主机。
-
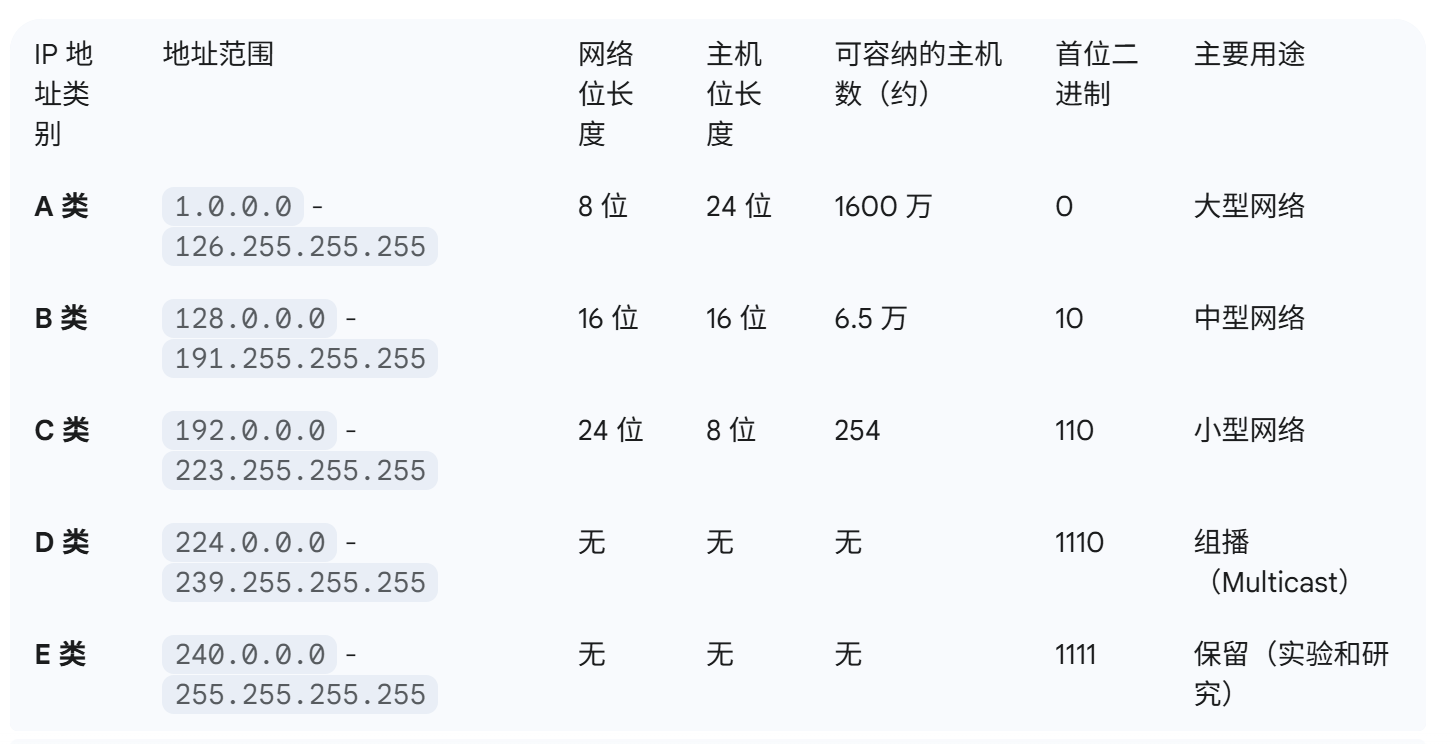
地址分类:分为A、B、C、D、E五类,根据地址的首位来区分,每类地址的网络位和主机位不同。
早期的 IPv4 地址分为 A、B、C、D、E 五类 ,主要依据 地址的前几位 和 网络号/主机号的划分 来决定。
注意点:
- 0.x.x.x 和 127.x.x.x 特殊保留:
- 127.0.0.1 通常用于本地回环地址(localhost)。
A 类地址第 1 位固定是 0,B 类前 2 位是 10,C 类前 3 位是 110,D 类前 4 位是 1110,E 类前 5 位是 11110。
公有 IP 和私有 IP 有什么区别?
-
核心要点:这是一个非常实用的概念,与 NAT(网络地址转换)相关联。
-
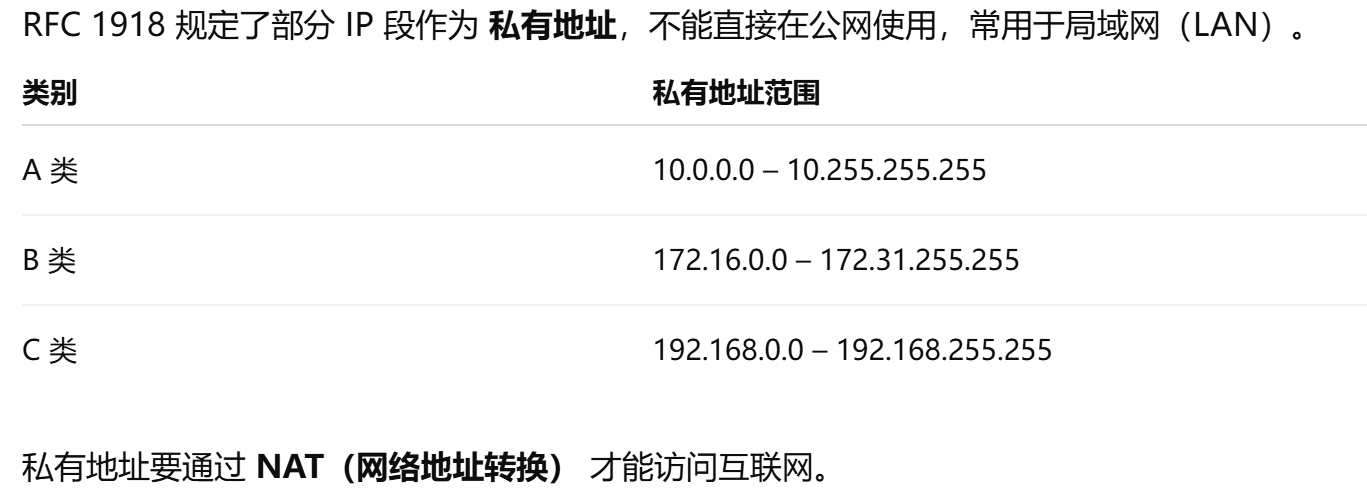
公有 IP :全球唯一,可以在互联网上直接访问,由 ISP(互联网服务提供商)分配。
-
私有 IP :只能在局域网(LAN)内部使用,不能直接在互联网上路由。例如
192.168.x.x、10.x.x.x和172.16.x.x。私有 IP 通过 NAT 技术转换成公有 IP,才能访问互联网。
NAT是什么?
核心要点:NAT 是解决 IPv4 地址短缺的重要技术。
作用:它允许一个私有网络内的多台设备共享一个公有 IP 地址来访问互联网。
解决了什么问题:最主要的是缓解了 IPv4 地址耗尽的危机,同时也提供了一定程度的安全保护,因为外部网络无法直接访问内部的私有 IP。
IPv4数据报结构
IPv4 数据报分为两部分:首部(Header) 和 数据(Payload) 。
其中首部最小长度 20 字节 ,最大长度 60 字节(因为有可选字段)
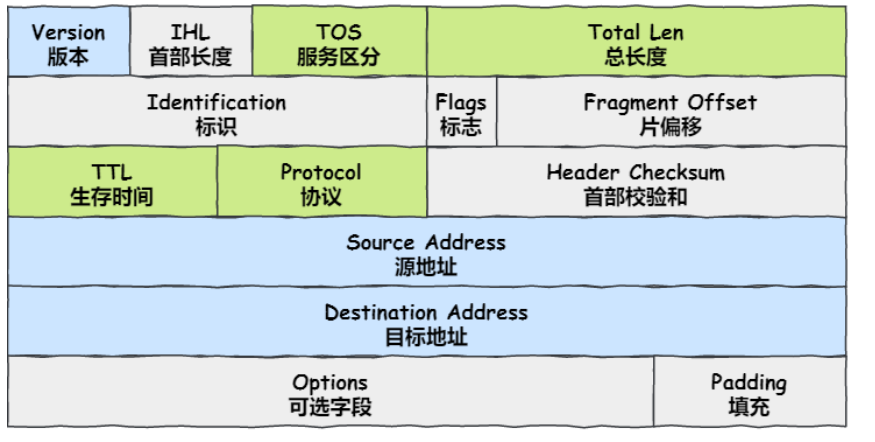
字段解析
首部区(Header)
- Version (版本号)
长度:4 位
值:0100 表示 IPv4;0110 表示 IPv6。
- IHL (Internet Header Length)
长度:4 位
表示首部长度,以 4 字节(32 位) 为单位。
最小值 5(即 5×4=20 字节),最大值 15(即 60 字节)。
- Type of Service (服务类型 / DSCP+ECN)
长度:8 位
主要用于 QoS(服务质量),区分优先级、延迟、吞吐量等需求。
前 6 位:DSCP(Differentiated Services Code Point)
后 2 位:ECN(Explicit Congestion Notification)
- Total Length (总长度)
长度:16 位
表示 整个 IP 包(首部+数据)的长度,最大为 65,535 字节。
- Identification (标识符)
长度:16 位
用于分片时标识同一个数据报,接收端可依此重新组装。
- Flags (标志位)
长度:3 位
控制分片行为:
第 1 位:保留(0)
第 2 位 DF(Don't Fragment):=1 表示禁止分片
第 3 位 MF(More Fragments):=1 表示后面还有分片
- Fragment Offset (片偏移量)
长度:13 位
表示当前分片在原始数据报中的偏移位置,以 8 字节 为单位。
- Time to Live (TTL,生存时间)
长度:8 位
每经过一个路由器,TTL 减 1,减到 0 时数据报丢弃。
防止数据报在网络中无限循环。
- Protocol (协议号)
长度:8 位
指明上层协议类型。常见取值:
1 → ICMP
6 → TCP
17 → UDP
- Header Checksum (首部校验和)
长度:16 位
只校验 首部部分,不包括数据。
用于发现传输过程中首部错误。
- Source Address (源地址)
长度:32 位
发出数据报的设备 IPv4 地址。
- Destination Address (目的地址)
长度:32 位
接收数据报的设备 IPv4 地址。
- Options(可选字段)
可变长度(0~40 字节)。
用于测试、调试、安全等特殊功能。
- Padding(填充)
由于首部必须是 4 字节的整数倍,如果 Options 不是 4 字节倍数,就用 0 填充。
数据区(Payload)
位于首部之后,存放 上层协议数据(如 TCP 段、UDP 数据报、ICMP 报文等)。
大小 = Total Length - Header Length。
总结
IPv4 首部最小 20 字节,最大 60 字节。
关键字段:TTL(避免死循环)、分片(Identification+Flags+Offset)、Protocol(上层协议识别)、Checksum(首部错误校验检测)。
Payload 部分承载上层数据(TCP/UDP/ICMP 等)。
解决IPv4地址耗尽的常见手段
1.私有地址 + NAT
私有地址思路:局域网内部使用 RFC1918 定义的私有地址(如 192.168.x.x、10.x.x.x),避免占用宝贵的公网 IPv4。
优点:节省公网地址;灵活部署。
缺点:私有地址不能直接在公网通信,必须依赖 NAT。
NAT思路:在边界路由器上,把多个内网 IP 映射到少量公网 IP。
NAPT/端口复用(最常见):多个内网地址通过端口号复用同一个公网地址
优点:极大延缓 IPv4 地址耗尽;部署简单。
缺点:破坏端到端通信模型;对 P2P、VoIP 等应用不友好。
- DHCP + 动态分配
-
思路:不是每个用户/设备都长期占用固定 IP,而是通过 DHCP 动态分配。用户下线后,IP 可以回收再用。
-
优点:提高地址利用率。
-
缺点:不解决总量不足的问题,只是"更精细化管理"。
- CIDR(无类域间路由)
思路:替代传统 A/B/C 分类,用 子网掩码 灵活划分网络,避免浪费。
例子:以前 B 类固定 65534 个主机,但很多机构用不了那么多;CIDR 可以按需分配,比如 /20 只给 4096 个地址。
优点:极大提高地址利用率。
- 过渡到 IPv6(根本解决方案)
IPv6 地址是 128 位,理论上数量几乎无限(2^128)。
-
优点:彻底解决地址耗尽问题;恢复端到端通信模式。
-
缺点:升级成本高;推广周期长。
特殊的IP地址
比如全0,全1,以及私有的,还有就是环回地址等,在这里浅浅总结一下
由于全0和全1不能用来标识主机,所以就是对于上面的那些A类,B类,C类地址来说,都实际可用的主机会-2。
IP分片与重组
MTU的介绍
定义 :MTU 是最大传输单元 ,它是在数据链路层 (如以太网)中,一个数据帧能承载的最大数据量。
作用 :你可以想象一辆卡车,MTU 就是这辆卡车单次运输能装载的货物上限。在网络中,如果一个 IP 数据包的大小超过了路径上某个网络的 MTU,那么它就必须被分片(Fragmentation)。分片会增加网络设备的负担,降低传输效率,因此通常我们都希望尽量避免分片。
常见值 :对于以太网,标准的 MTU 值通常是 1500 字节。
MSS的介绍
定义 :MSS 是最大报文段大小,它是在传输层 (主要是 TCP 协议)中,一个 TCP 报文段能承载的最大有效载荷(Payload)。简单来说,就是 TCP 数据包中,真正用来装载应用层数据的部分的最大值。
作用 :MSS 的存在是为了避免 IP 层分片, 在传输层就对数据包进行划分。在 TCP 连接建立时,通信双方会协商一个 MSS 值。这个值会根据路径上的 MTU 来计算。
MSS (最大报文段大小) 的设定直接取决于 MTU (最大传输单元)。
它们之间的关系可以概括为:
在 TCP 协议中,为了避免数据包在网络层被分片,发送方在建立连接时会根据路径上可用的 MTU ,计算出合适的 MSS 值,然后将这个值告诉对方。
MSS 的计算公式是:
MSS=MTU−IP 首部长度−TCP 首部长度
这个公式的目的是确保:当 TCP 报文段(数据部分)加上 IP 和 TCP 的头部之后,总长度不会超过网络链路的 MTU。这样,数据包就能以完整的形式通过网络,避免了分片带来的性能下降和可靠性问题。
简单来说,MTU 是物理链路的"硬性"限制,而 MSS 则是传输层为了遵守这个限制而做出的"主动"调整。
IP数据报会填满吗?
虽然 IP 数据报的总长度最大可以达到 65,535 字节,但我们在实际传输中并不会刻意去填满它。IP数据报的长度通常由上层协议(如 TCP 或 UDP)决定,并且会受到网络中其他参数的限制。
MTU 的限制这是最重要的原因。
网络中的每一个链路都有自己的 MTU(最大传输单元) ,比如标准的以太网 MTU 是 1500 字节。如果 IP 数据报的总长度超过了链路的 MTU,它就会被分片。分片会带来许多问题:
-
增加路由器负担:路由器需要花费额外的时间和资源来处理分片和重组。
-
降低效率:任何一个分片丢失都可能导致整个数据包需要重新传输。
-
增加丢包风险:分片越多,任何一个分片在传输过程中丢失的概率就越高。
因此,为了避免分片,上层协议(尤其是 TCP)会协商一个合适的 MSS(最大报文段大小),确保 TCP 报文段加上 IP 和 TCP 首部后,总长度不超过路径上的 MTU。
核心原则是:尽量让数据报的总长度不超过路径上最小的 MTU,以避免分片,从而提高传输效率和可靠性。因此,IP 数据报的长度通常是几百到一千多字节,远小于其理论最大值。
分片&重组的过程
为什么会遇到分片重组?
IPv4 数据报的 最大长度是 65,535 字节,但网络中不同的数据链路层(如以太网、Wi-Fi)的 MTU(最大传输单元) 往往比这个小。如果 IP 数据报长度 超过 MTU,就必须把它拆分成更小的片段(分片)进行传输。
分片的机制
分片发生在 发送端或中间路由器,由以下字段控制:
- Identification(标识符,16 位)
同一数据报的所有分片都具有相同的标识符。
接收端通过它来判断哪些分片属于同一个原始数据报。
- Flags(标志位,3 位)
DF (Don't Fragment):禁止分片。若为 1 且数据报超过 MTU,则丢弃并返回 ICMP 错误(常用于路径 MTU 发现)。
MF (More Fragments):是否还有后续分片。
- 1 → 还有后续分片
- 0 → 最后一片
- Fragment Offset(片偏移,13 位)
表示该分片在原始数据报中的相对位置。
以 8 字节(64 位)为单位,保证分片边界对齐。
举例📌
假设要发送一个 4000 字节的 IP 数据报,但链路的 MTU = 1500。
IP 首部 = 20 字节
每个分片最大数据部分 = 1480 字节(1500 - 20)
于是分片结果:
分片 1:1480 数据,Offset=0,MF=1
分片 2:1480 数据,Offset=1480/8=185,MF=1
分片 3:1040 数据,Offset=2960/8=370,MF=0
重组(Reassembly)
发生位置:只在 最终目的主机 进行,不在中间路由器重组。
依据:
源地址、目的地址、协议号
Identification(标识符)
过程:
收到分片 → 按照 Offset 放入缓冲区 → 根据 MF 判断是否为最后一片
等到所有分片到齐 → 重新拼接成完整数据报
现代网络的优化方式
分片与重组的优缺点:
优点:允许在不同 MTU 的链路上传输大数据报,保证 IP 的"尽力而为"交付。
缺点:
- 性能消耗:接收方必须维护缓冲区等待所有分片,增加处理开销。
- 丢包风险:只要有一个分片丢失,整个数据报都无法重组(必须丢弃)。
由于分片的缺点,现代网络通常 尽量避免 IP 层分片:
- 路径 MTU 发现(PMTUD):通过设置 DF=1,若路由器发现超过 MTU,就返回 ICMP"需要分片但 DF 设置"消息,发送方据此调整报文大小。
- 传输层分片:引入了MSS,TCP/UDP 通过MSS自行控制分段,保证 IP 层不再分片。
IPv4与IPv6的区别
IP 地址是网络上设备的唯一标识。上面我们说了解决IPv4地址耗尽问题,最根本的解决方式是IPv6代替IPv4。
地址空间&地址表示形式
- IPv4:32位地址,通常用点分十进制表示(如 192.168.1.1)。地址空间有限,大约43亿个(实际上更少,因为有保留地址),已基本用完。
- IPv6:128位地址,通常用冒号十六进制表示(如 2001:0db8:85a3:0000:0000:8a2e:0370:7334)。地址空间巨大,解决了IPv4地址耗尽的问题,几乎取之不尽。
首部结构
-
IPv4 首部:最小 20 字节,最大 60 字节(有 Options 字段,格式复杂)。
-
IPv6 首部:固定 40 字节,格式简化(去掉了校验和、分片字段,改用扩展头)。
👉 IPv6 的设计让路由器转发更高效。
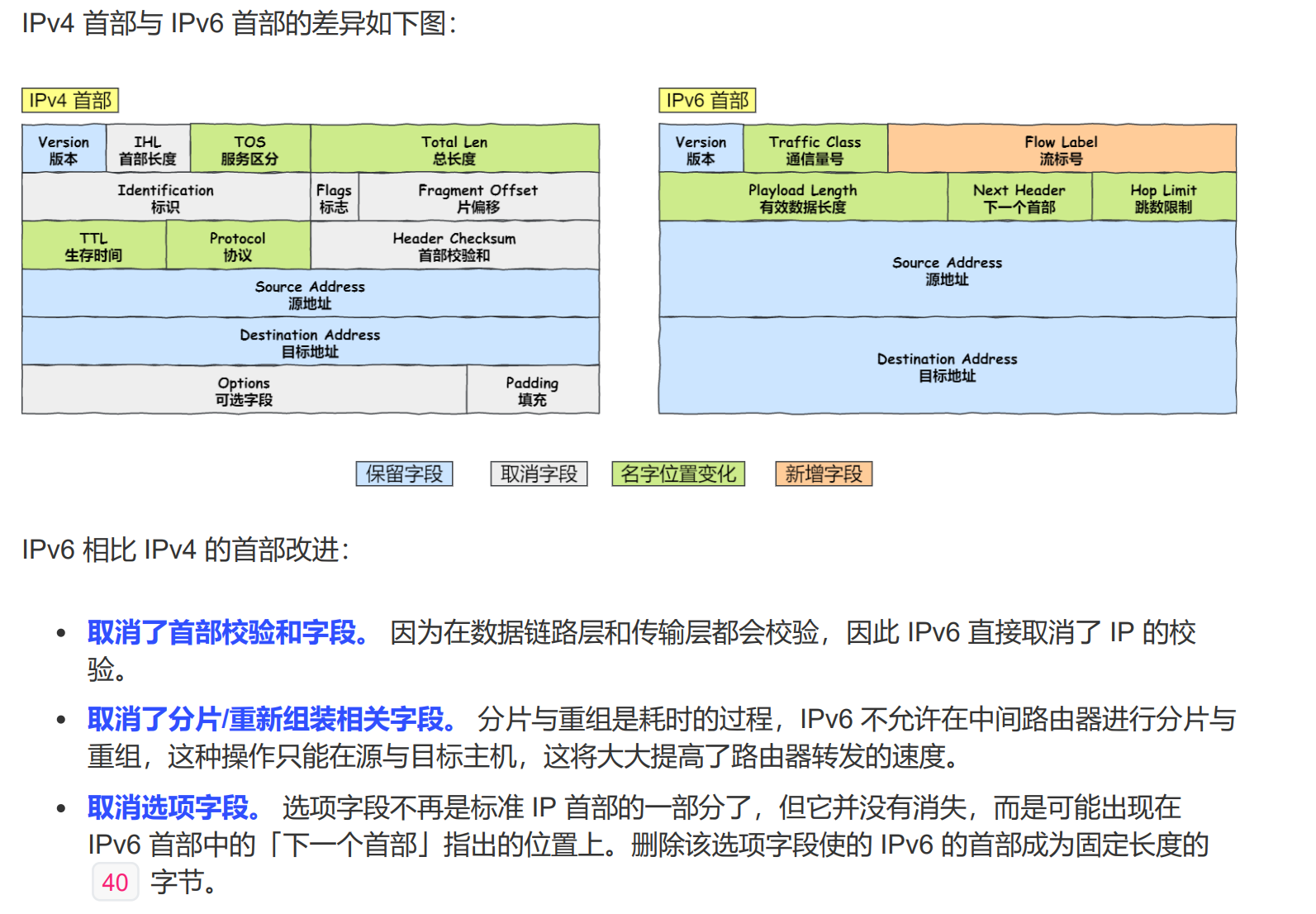
在 IPv6 的中间传输过程中,不需要再对 IP 数据报进行校验
-
IPv4:有首部校验和 → 路由器逐跳检查,重算 → 保障有限,还增加开销。
-
IPv6 :取消首部校验和 → 中间路由器不再做校验,依赖链路层 + 传输层的校验 → 提升性能。
分片与重组
IPv4:支持中间路由器分片,目的主机重组。
IPv6:只允许源端分片,中间路由器不再分片,降低路由器负担。
地址类型
IPv4:单播、广播、多播。
IPv6:单播、多播、任播(anycast);去掉了广播(因为会引发广播风暴)。
本文章很多图片资源来源:小林coding