一.引言:
etcd 是一个高可用、强一致性的分布式键值存储系统,由 CoreOS 开发,基于 Raft 协议实现,主要用于存储分布式系统中的关键配置和元数据。它具有数据持久化、高吞吐、低延迟等特性,是 Kubernetes 集群的核心组件(用于存储集群状态),也被广泛用于服务发现、分布式锁等场景。
二. 基础概念:
- etcd 架构:
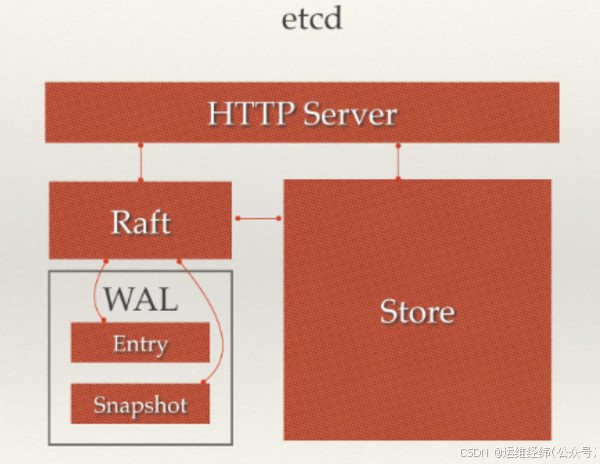
从etcd的架构图中我们可以看到,etcd主要分为四个部分。
- HTTP Server: 用于处理用户发送的API请求以及其它etcd节点的同步与心跳信息请求。
- Store:用于处理etcd支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd对用户提供的大多数API功能的具体实现。
- Raft:Raft强一致性算法的具体实现,是etcd的核心。
- WAL:Write Ahead Log(预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储。WAL中,所有的数据提交前都会事先记录日志。Snapshot是为了防止数据过多而进行的状态快照;Entry表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由HTTP Server转发给Store进行具体的事务处理
如果涉及到节点的修改,则交给Raft模块进行状态的变更、日志的记录,然后再同步给别的etcd节点以确认数据提交
最后进行数据的提交,再次同步。
- 数据存储:
etcd的存储分为内存存储和持久化(硬盘)存储两部分
内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。
持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。在WAL的体系中,所有的数据在提交之前都会进行日志记录。
在etcd的持久化存储目录中,有两个子目录。一个是WAL,存储着所有事务的变化记录;另一个则是snapshot,用于存储某一个时刻etcd所有目录的数据。通过WAL和snapshot相结合的方式,etcd可以有效的进行数据存储和节点故障恢复等操作。
为什么有了wal实时存储还需要snapshot?随着使用量的增加,WAL存储的数据会暴增,为了防止磁盘很快就爆满,etcd默认每10000条记录做一次snapshot,经过snapshot以后的WAL文件就可以删除。而通过API可以查询的历史etcd操作默认为1000条。
使用WAL进行数据的存储使得etcd拥有两个重要功能。
- 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
- 数据回滚(undo)/重做(redo):因为所有的修改操作都被记录在WAL中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
- raft(一致性算法):
raft是一种分布式一致性算法协议。 只需要保证N/2+1节点数正常,就能提供服务。为了解决这个问题,raft把算法流程拆解成了三个子问题: 选举(leader selection), 日志复制(log replication),安全性(safety)。大致流程: Raft开始时在集群中选举出Leader负责日志复制的管理,Leader接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader负责保证其他节点与他的日志同步,当Leader宕掉后集群其他节点会发起选举选出新的Leader; 具体内容,在consul一致性协议(raft) 中有说明。
- 请求处理流程:
读请求: 每个节点都有Raft已提交数据准确的备份(最坏的情况也只是已提交数据还未完全同步),所以读的请求任意一个节点都可以处理。
写请求: Raft为了保证数据的强一致性,所有的数据流向都是一个方向,从Leader流向Follower,也就是所有Follower的数据必须与Leader保持一致,如果不一致会被覆盖。即所有用户更新数据的请求都最先由Leader获得,然后存下来通知其他节点也存下来。当接收到写请求时,如果不是leader, 则会转发给leader,由Leader节点写入后再分发给集群上的所有其他节点,等到大多数节点(N/2+1)反馈时再把数据提交。一个已提交的数据项才是Raft真正稳定存储下来的数据项,不再被修改,最后再把提交的数据同步给其他Follower。
三. 集群部署
需要三个主机节点
-
下载安装:
下载二进制包
wget https://github.com/etcd-io/etcd/releases/download/v3.5.10/etcd-v3.5.10-linux-amd64.tar.gz
解压并安装
tar -zxvf etcd-v3.5.10-linux-amd64.tar.gz
cd etcd-v3.5.10-linux-amd64
sudo cp etcd etcdctl /usr/local/bin/ # 复制到系统 PATH 目录验证安装
etcd --version # 输出版本信息即安装成功
-
创建目录和配置文件:
创建数据存储目录(每个节点独立)
sudo mkdir -p /var/lib/etcd
sudo chmod 700 /var/lib/etcd -
配置etcd服务(按节点修改):
#[member]
name: yd-ops-etcd-node1 #节点名称(唯一)
data-dir: /var/lib/etcd #数据存储目录
listen-peer-urls: http://10.126.1.1:2380
listen-client-urls: http://10.126.1.1:2379
advertise-client-urls: http://10.126.1.1:2379#[cluster]
initial-advertise-peer-urls: http://10.126.1.1:2380 #集群内部数据传输url,支持域名
initial-cluster: etcd-node1=http://10.126.1.1:2380,etcd-node2=http://10.136.1.1:2380,etcd-node3=http://10.136.1.2:2380 #初始集群
配置(各节点initial-advertise-peer-url合集)
initial-cluster-state: 'new'
initial-cluster-token: 'etcd-cluster' #集群令牌/ID,同集群相同#[log]
debug: false
log-package-levels: INFO
log-output: default
其他节点参考上面配置即可: 注意区分 --name 和ip 。
启动服务: etcd --config-file conf.d/etcd.yaml
四. 验证:
etcdctl member list
深耕运维行业多年,擅长运维体系建设,方案落地。欢迎交流!
"V-x": ywjw996
《 运维经纬 》