文章目录
- 基本知识介绍
-
- 1.视觉处理三大任务
- 2.训练、验证、测试、推理
- 3.数据集
-
- [3.1 数据集格式](#3.1 数据集格式)
- [3.2 数据集标注](#3.2 数据集标注)
- 4.上游任务和下游任务
- YOLO
-
-
- 指标
-
-
- [1.真实框(Ground Truth Box)与边界框(Bounding Box)](#1.真实框(Ground Truth Box)与边界框(Bounding Box))
- 2.交并比(IOU)
- 3.置信度
- 4.混淆矩阵
- 5.精确度与召回率
- 6.mAP
-
- [6.1 PR曲线(Precision-Recall Curve)](#6.1 PR曲线(Precision-Recall Curve))
- [6.2 AP](#6.2 AP)
-
-
- [6.3 mAP平均平均精度](#6.3 mAP平均平均精度)
-
-
- NMS(非极大值抑制)后处理技术
-
基本知识介绍
1.视觉处理三大任务
图像分类 :对整个图像内容进行 "类别归属" 判断,核心是让计算机识别一张图像属于哪个预设的类别(例如 "猫""狗""汽车""风景" 等),输出的是 "图像 - 类别标签" 的对应关系,不关注目标在图像中的具体位置、数量或形态细节。
目标检测:不仅要识别图像中存在的目标类别(解决 "是什么"),还要通过矩形边界框(Bounding Box)标记出每个目标在图像中的具体位置(解决 "在哪里"),同时需处理 "多目标共存" 场景
图像分割:实例分割、语义分割
2.训练、验证、测试、推理
训练阶段(Training):通过训练集数据,让模型 "学会" 规律。数据集需要做标注,图像分类的类别就是文件夹的名称,但在目标检测是需要自己打标签。
验证阶段(Validation):在训练过程中,用验证集评估模型的 "初步泛化能力",让模型 "更优",这个过程一般发生在模型训练过程中或者最后。
测试阶段(Testing):用完全独立的测试集,最终评估模型的泛化能力
推理阶段(Inference):将通过测试的模型部署到实际场景,对真实世界的新数据(无标签)进行预测,输出结果供业务使用。
【重点】训练、验证、测试图片是不可以存在相同的
3.数据集
3.1 数据集格式
YOLO 数据集的目录结构需严格区分图像文件 和标注文件,两者需一一对应(文件名相同,后缀不同):
datasets:存放所有的数据集,这个所有的意思就是训练任何模型的数据集
- car:训练car的数据集信息
- train:训练数据集
- images:图片信息
- lables:标签信息
- val:验证数据集
- images:图片信息
- labels:标签信息
- train:训练数据集
- helmet:
- train:训练数据集
- images:图片信息
- lables:标签信息
- val:验证数据集
- images:图片信息
- labels:标签信息
- train:训练数据集
3.2 数据集标注
在目标检测任务中,图片中的每个目标都要标注类别 和边界框(Bounding Box)
安装labelimg工具【这个工具如果安装在python 3.12 版本以下会有bug,解决方法详见不过解决文档】:
-
第一步:创建虚拟环境(可以选择拷贝):
conda create -n labels_env python=3.12 -
第二步:激活虚拟环境【有的版本的anaconda不需要写 conda】
conda activate labels_env -
第三步:下载 labelimg
pip install labelimg -
第四步:查看是否安装了 labelimg
conda list labelimg -
第五步:启动 labelimg 标注工具【遇到bug就去解决】
labelimg
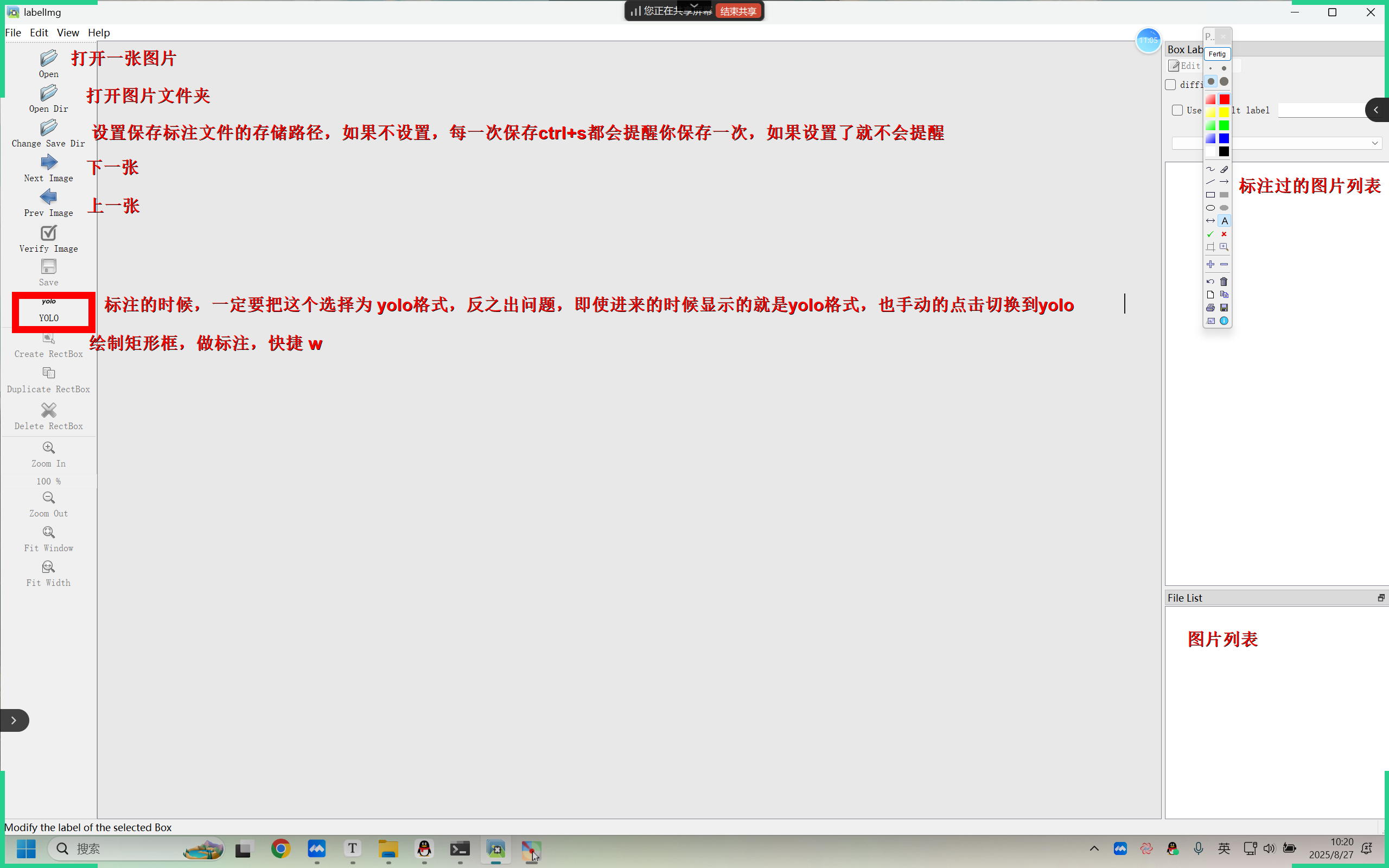

注:此工具有些小bug:
1.进页面后切换一下yolo格式,即使初始就是yolo也最好切换一下
2.按w快捷开启标注
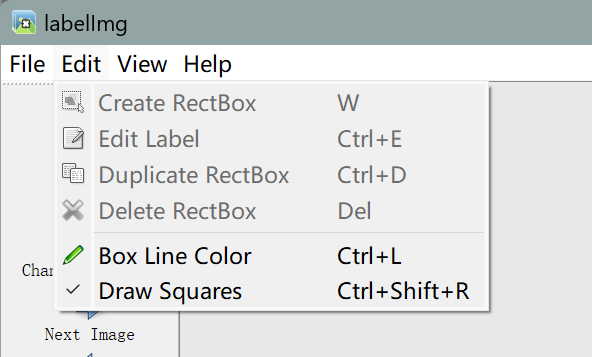
3.若没有方框的在左上角导航栏edit点击一下Draw Squares
4.上游任务和下游任务
- 上游任务:就是使用大量的数据集训练模型,得到预训练模型
- 下游任务:通过预训练模型得到自己的模型,做模型的应用开发【落地】
YOLO
YOLO(You Only Look Once)是目前最流行的实时目标检测算法之一,以速度快、精度高著称,其核心特点是一个**单阶段的目标检测【没有生成候选框的过程】**算法,直接从图像中同时预测目标的类别和位置,摆脱了传统两阶段检测算法(如 Faster R-CNN)的复杂流程。
指标
1.真实框(Ground Truth Box)与边界框(Bounding Box)
- 真实框:就是我们在训练模型之前,基于数据集内容,做的标注信息的矩形框;推理阶段是没有真实框的
- 边界框:也可以称为预测框,这个框就是模型输出的结果;在训练阶段,我们通过控制损失函数,让边界框更加接近于真实框(提高模型的性能);在推理阶段,这个边界框就是我们通过模型推理出来的结果,这个过程全全是否模型学习到的东西的一个输出
YOLO 采用归一化的(x_center, y_center, width, height)格式表示边界框(范围 0~1),其中:
x_center, y_center:目标中心点相对于图像宽高的归一化坐标;width, height:目标宽高相对于图像宽高的归一化值。
边界框越贴近目标真实框,模型定位效果越好。
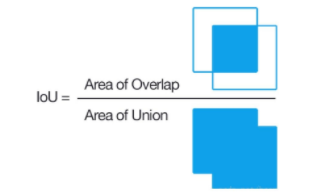
2.交并比(IOU)
衡量预测边界框(Predicted Box) 与真实边界框(Ground Truth Box) 重叠程度的指标
- 计算公式:
I o U = A r e a o f O v e r l a p A r e a o f U n i o n = A ∩ B A ∪ B IoU=\frac{Area\,of\,Overlap}{Area\,of\,Union}=\frac{A∩B}{A∪B} IoU=AreaofUnionAreaofOverlap=A∪BA∩B
- IoU 计算公式图形表示如下:
- IoU=1:预测框与真实框完全吻合,认为很成功但也有可能是过拟合。
- IoU<0.5IoU<0.5:通常认为预测失败(False Positive, FP)。
- IoU≥0.5IoU≥0.5:认为预测成功(True Positive, TP)。
3.置信度
YOLO为每个预测框分配一个置信度,表示模型对预测框包含目标的可信度,取值范围 0 到 1 之间,置信度由两部分组成:
- 目标存在概率:预测框内是否包含目标。
- 位置准确性:预测框与真实框的IoU。
公式:置信度 = Pr(Object) × 预测的 IOU
- Pr(Object)=1:边界框内有对象
- Pr(Object)=0:边界框内没有对象
【注】:在推理阶段,由于没有真实框的存在,所有没办法去计算IOU的值,因此模型推理阶段的置信度输出完全是由模型学习的结果产生的(即模型预测的,包含了类别置信度 + 目标存在置信度)
4.混淆矩阵
- 混淆矩阵是一种用于评估分类模型性能的表格形式,特别适用于监督学习中的分类任务。它通过将模型的预测结果与真实标签进行对比,帮助我们直观地理解模型在各个类别上的表现
- 在混淆矩阵中:
- 列(Columns) :表示真实类别(True Labels)
- 行(Rows) :表示预测类别(Predicted Labels)
- 单元格中的数值:表示在该真实类别与预测类别组合下的样本数量
- 在目标检测任务中,混淆矩阵的构建依赖于 IoU 阈值,因为 IoU 决定了哪些预测被认为是"正确检测",从而影响 TP、FP、FN 的统计,最终影响混淆矩阵的结构和数值
| 实际为正类 | 实际为负类 | |
|---|---|---|
| 预测为正类 | TP(真正例) | FP(假正例) |
| 预测为负类 | FN(假反例) | TN(真反例) |
- TP:真实是目标,预测也为目标(正确检测);
- FP:真实不是目标,预测为目标(误检);
- FN:真实是目标,预测为非目标(漏检);
- TN:真实不是目标,预测也为非目标(正确排除)。
【理解技巧】每个术语由 "真假(T/F)" 和 "正负(P/N)" 组成,先明确这两个维度的含义:
- T(True)/ F(False) :描述 "模型预测是否和真实情况一致"------
T = 预测对了,F = 预测错了; - P(Positive)/ N(Negative) :描述 "模型的预测结果是什么"------
P = 模型预测为 "正类"(比如 "垃圾邮件""患病"),N = 模型预测为 "负类"(比如 "正常邮件""健康")。
5.精确度与召回率
-
精确度(Precision):
-
定义:预测为正的样本中,真正为正的比例("预测正确的目标占所有预测目标的比例"):
Precision = TP TP + FP \text{Precision} = \frac{\text{TP}}{\text{TP + FP}} Precision=TP + FPTP -
意义:衡量模型 "不乱标" 的能力 ------ 值越高,误检(把非目标标为目标)越少。
-
-
召回率(Recall):
-
定义:真实为正的样本中,被成功预测为正的比例("所有真实目标中被检出的比例"):
Recall = TP TP + FN \text{Recall} = \frac{\text{TP}}{\text{TP + FN}} Recall=TP + FNTP -
意义:衡量模型 "不漏检" 的能力 ------ 值越高,漏检(真实目标未被检出)越少。
-
6.mAP
6.1 PR曲线(Precision-Recall Curve)
PR 曲线以召回率(Recall) 为横轴,精确率(Precision) 为纵轴,每个点对应一个特定的 "置信度阈值"。通过调整阈值,可得到一系列(Recall, Precision)坐标,连接这些点即形成 PR 曲线。
对于每个样本,模型会输出一个预测分数或置信度,表示该样本属于某一类的概率。通常也会设定一系列的置信度阈值,这些阈值将用于决定哪些预测被视为"正例"(Positive),哪些被视为"负例"(Negative)
置信度阈值:模型预测框的 "置信度" 决定了是否保留该框(如阈值 = 0.5 时,只保留置信度≥0.5 的框)。
- 当阈值降低时:
- 更多低置信度的预测框被保留 → 漏检减少(Recall 升高),但误检可能增加(Precision 降低)。
- 当阈值升高时:
- 只有高置信度的预测框被保留 → 误检减少(Precision 升高),但漏检可能增加(Recall 降低)
对于每一个阈值,根据预测分数与该阈值的比较结果,我们可以计算出当前阈值下的精确率(Precision)和召回率(Recall)
将每个阈值下的精确率和召回率作为坐标点,绘制在二维平面上,横轴为召回率 ,纵轴为精确率,从而形成一条曲线
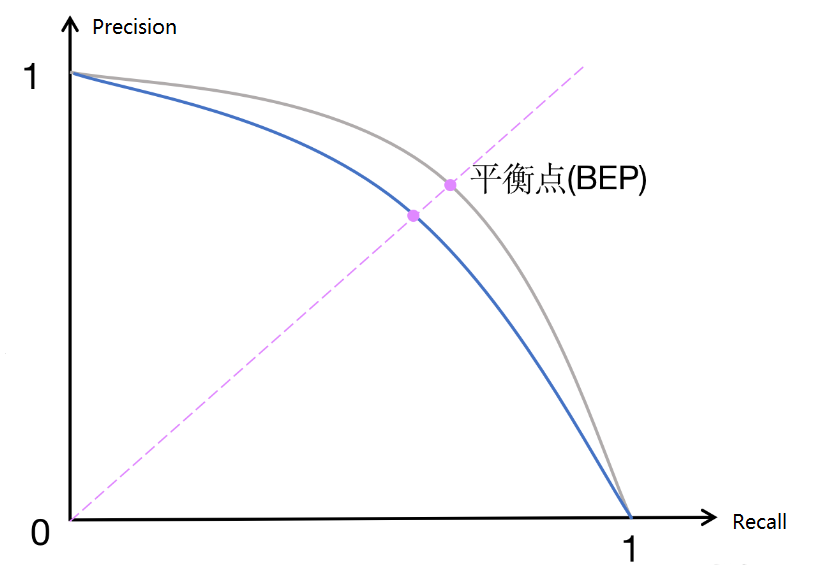
理想曲线:靠近右上角(高召回率下仍保持高精确率)。
实际曲线:通常呈下降趋势,反映模型在精确率与召回率间的权衡。
6.2 AP
- 在 PR 曲线中,曲线上每个点表示了在对应召回率下的最大精确率值。当 P=R 时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以 PR 曲线越靠近右上角性能越好。即 PR 曲线的面积越大,表示分类模型在精确率和召回率之间有更好的权衡,性能越好
- 常用的评估指标是 PR 曲线下的面积,即 AP(Average Precision),通过 PR 曲线下的面积来计算 AP,从而综合评估模型在不同置信度阈值下的性能,值越接近 1 越好
- 平均精度(Average Precision, AP)通过计算每个类别在不同置信度阈值下的 Precision(查准率)和 Recall(查全率)的平均值来综合评估模型的性能。AP 被广泛应用于评估模型在不同置信度阈值下的表现,并且是计算 mAP(平均平均精度)的基础
- AP 就是用来衡量一个训练好的模型在识别某个类别时的表现好坏。AP 越高,说明模型在这个类别上的识别能力越强
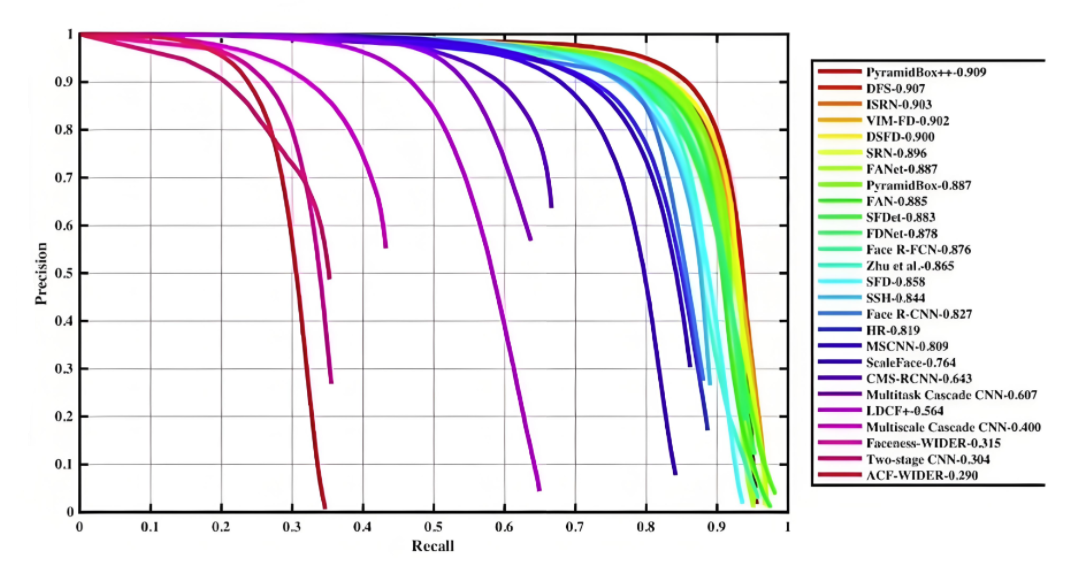
在 PR 曲线中,曲线上每个点表示了在对应召回率下的最大精确率值。当 P=R 时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以 PR 曲线越靠近右上角性能越好。即 PR 曲线的面积越大,表示分类模型在精确率和召回率之间有更好的权衡,性能越好
常用的评估指标是 PR 曲线下的面积,即 AP(Average Precision),通过 PR 曲线下的面积来计算 AP,从而综合评估模型在不同置信度阈值下的性能,值越接近 1 越好
AP计算:
-
11 点插值法:只需要选取当 Recall >= 0, 0.1, 0.2, ..., 1 共11个点,找到所有大于等于该 Recall 值的点,并选取这些点中最大的 Precision 值作为该 Recall 下的代表值,然后 AP 就是这 11 个 Precision 的平均值
A P = 1 11 ∑ r ∈ { 0 , 0.1 , . . . , 1 } p i n t e r p ( r ) p i n t e r p ( r ) = max r ~ : r ~ ≥ r p ( r ~ ) r ~ 表示大于或等于 r 实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率 \mathrm{AP}=\frac{1}{11}\sum_{r\in\{0,0.1,...,1\}}p_{interp(r)}\\ p_{interp(r)}=\max_{\tilde{r}:\tilde{r}\geq r}p(\tilde{r}) \\ \tilde{r}表示大于或等于r实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率 AP=111r∈{0,0.1,...,1}∑pinterp(r)pinterp(r)=r~:r~≥rmaxp(r~)r~表示大于或等于r实际召回率,并选择这些召回率对应的精确率中的最大值作为插值精确率
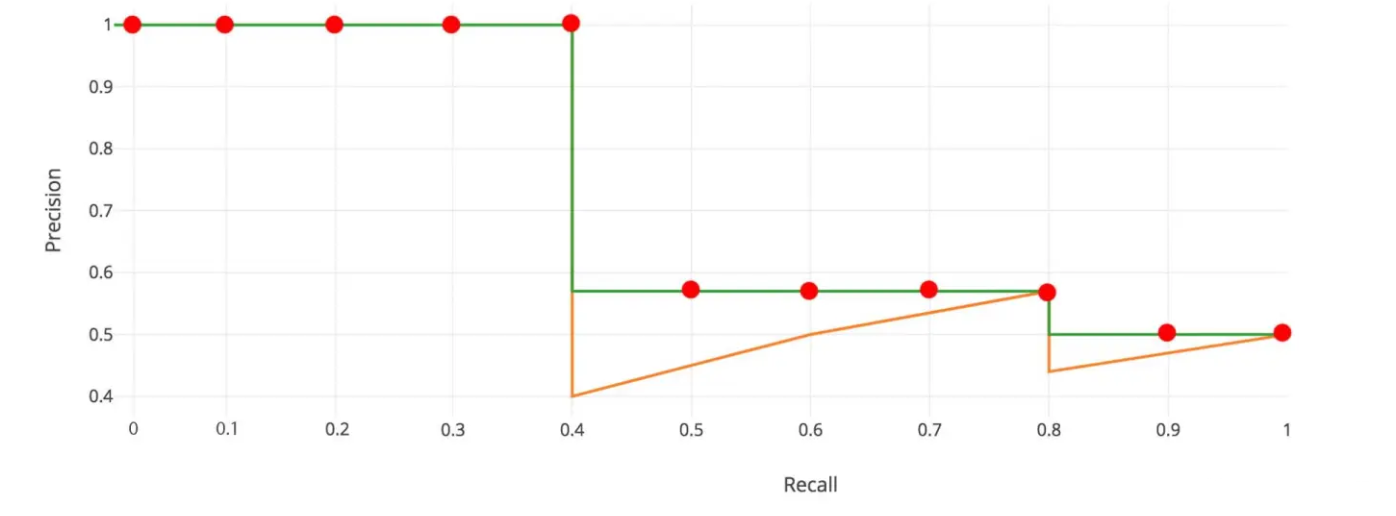
-
面积法:需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些 Recall 值时的 Precision 最大值,然后计算 PR 曲线下面积作为 AP 值,假设真实目标数为 M,recall 取样间隔为 0, 1/M, ..., M/M,假设有 8 个目标,recall 取值 = 0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0
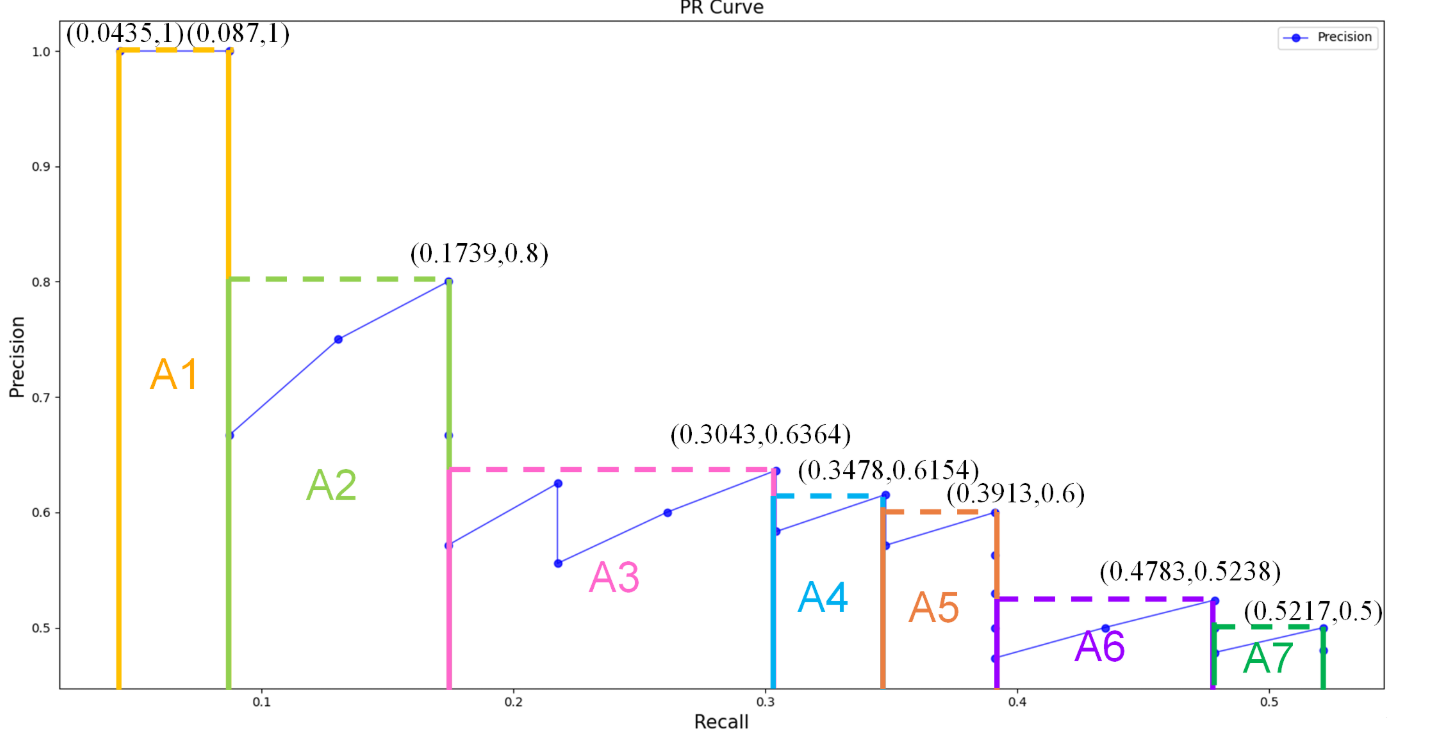
-
把各块面积加起来就是 AP 值
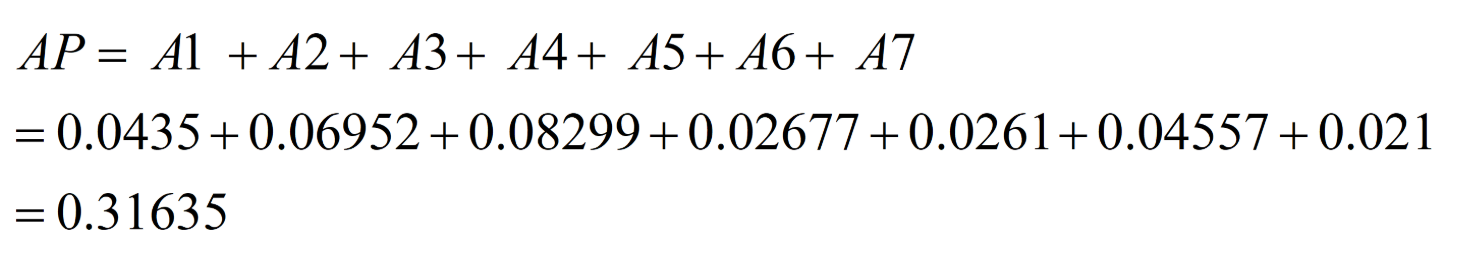
6.3 mAP平均平均精度
mAP 是所有类别的 AP 的平均值,用于衡量模型在多类别任务 中的整体性能。
mAP = 1 N ∑ i = 1 N AP i \text{mAP} = \frac{1}{N} \sum_{i=1}^{N} \text{AP}_i mAP=N1i=1∑NAPi
mAP衡量模型整体性能的综合指标,值越高表示模型在所有类别上的平均表现越好
NMS(非极大值抑制)后处理技术
NMS(Non-Maximum Suppression)是目标检测中的关键后处理技术,用于解决冗余检测框问题。其核心思想是:
- 筛选局部最优解:在多个重叠的预测框中,保留置信度最高的框,抑制(删除)与之高度重叠的低置信度框。
- 基于IoU(交并比):通过计算预测框之间的重叠度,决定是否保留或剔除冗余框。
步骤:
YOLO 模型输出的预测框需先经过 "置信度阈值过滤"(如只保留置信度≥0.25 的框,初步去除低置信度误检),再进入 NMS 流程。【这个过程就为 NMS 过滤减轻了计算压力】
步骤 1:按置信度对预测框排序(降序)
按其置信度分数从高到低排序 。此时,排序第一的框是当前 "最可能为真实目标" 的候选框(记为 best_box)
步骤 2:计算best_box与其他所有框的 IOU
步骤 3:根据 IOU 阈值抑制冗余框
抑制重叠框 :设定一个阈值(如 iou_threshold=0.5),若某候选框与 best_box 的 IoU 超过阈值,则认为该框是冗余的,从候选列表中移除。
步骤 4:重复操作,从剩余候选框中继续选择最高分的框,重复上述步骤,直到所有框处理完毕。
NMS 通过 "选最高置信度框→删重叠框→循环至无冗余" 的流程,从大量预测框中筛选出唯一、精准的目标框。
