以下内容包括「人工智能生成内容」
Google 发布 Gemini2.5 Flash Image,Deepseek V3.1 极字bug引争议,模型发布疯狂卷
👏在昨天(2025.8.26),AI领域有这些内容可能值得你关注:
阿里发布多模态大模型 Ovis2.5
近日, 阿里国际 正式推出了新一代多模态大模型 Ovis2.5 ,这款模型在保持较小参数规模的同时,实现了性能的显著提升。多模态模型是指能够同时处理图像、文本等多种信息类型的人工智能系统,而 Ovis2.5 在这方面展现出了令人瞩目的能力。
Ovis2.5 最大的突破在于三个方面。首先是 原生分辨率视觉感知 技术。以往的模型处理高分辨率图片时,需要将图片切割成小块再拼接,这会导致整体结构和细节信息的丢失。而 Ovis2.5 采用了动态分辨率视觉编码器,可以直接处理任意分辨率的原始图像,无论是宏观布局还是微小的文字细节都能精准捕捉,就像人类"完整地看图"一样。
第二个突破是深度推理"思考模式"。模型在解决问题时能够进行自我反思和修正,生成中间推理步骤,主动检查并改进自己的思考过程。这种能力在数学计算、复杂图表分析等高难度任务中特别有用,用户可以根据需求选择开启或关闭这种深度思考模式,在精度和速度之间灵活权衡。
第三个突破是针对复杂图表理解的优化。图表理解一直是人工智能领域的难题,因为图表中通常包含大量密集的信息和噪声。Ovis2.5 从数据、视觉处理和推理三个层面进行了系统增强,新增了大量高质量的图表数据,利用原生分辨率技术准确理解图表元素,再结合深度思考能力分析数据关系。
Ovis2.5 提供了两个版本:9B 参数的版本在多项评测中得分 78.3,在 40B 以下参数规模的开源模型中排名第一;2B 参数的版本得分 73.9,虽然参数更少但性能依然出色,特别适合在手机等端侧设备上使用。这两个版本都延续了 Ovis 系列"小身材,大能量"的设计理念。
在实际应用中,Ovis2.5 展现出了多样化的能力。它能够识别图片中的地标景观并关联相关诗词,准确提取文档中的关键信息并以结构化格式输出,深入分析图表中的数据关系,解决数学问题,甚至能够精确定位图像中的特定物体。这些能力使得 Ovis2.5 在文档处理、数据分析、视觉问答等多个场景都具有实用价值。
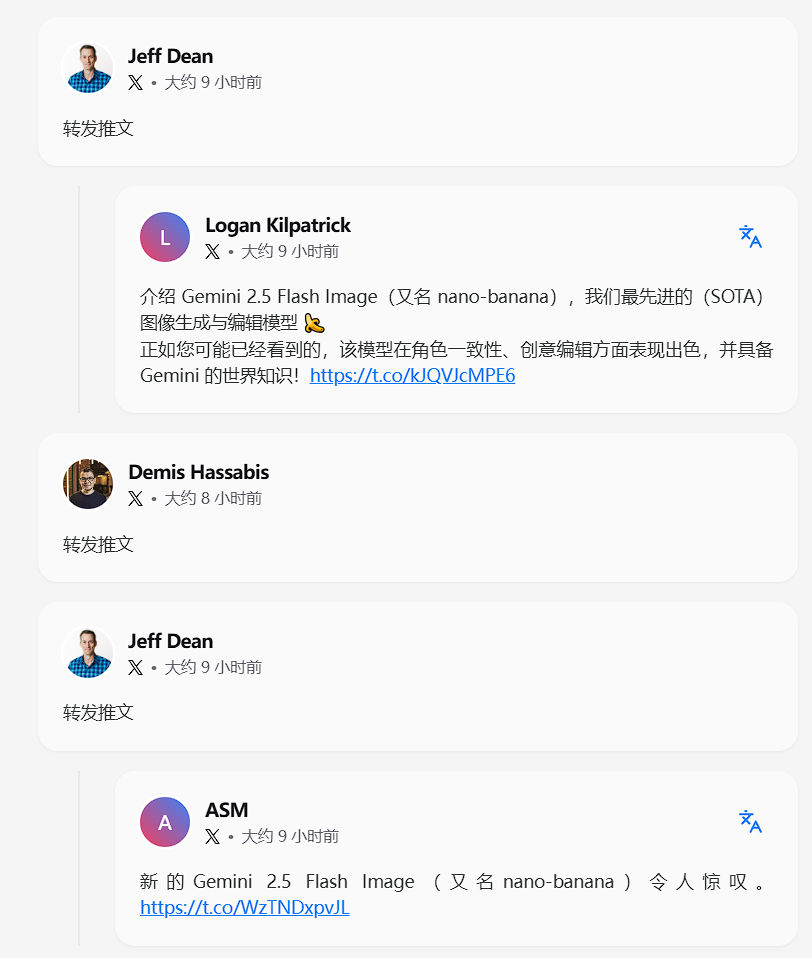
Google 发布 Gemini 2.5 Flash Image(nano-banana)
Google DeepMind 团队发布了 Gemini 2.5 Flash Image (又名 nano-banana),这是目前最先进的图像生成与编辑模型。该模型在角色一致性、创意编辑以及多模态理解方面表现出色,并融入了 Gemini 的世界知识。
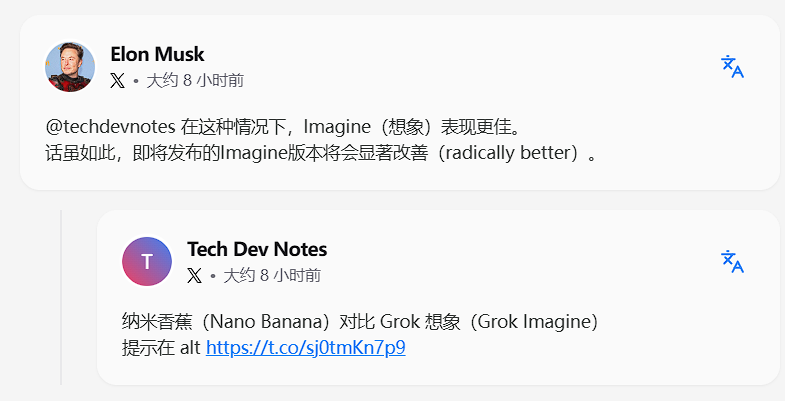
与此同时,Elon Musk 对 Grok Imagine 的表现进行了评价,认为其当前版本表现更佳,但即将发布的版本会有显著提升。
Deepseek V3.1 "极" 字异常引发争议
DeepSeek V3.1 上线不久后,用户发现该模型在处理文本时会突然插入大量"极"字。最初有网友在整理物理试卷时遭遇这一问题,LaTeX 代码被"极"字打乱。测试发现,该异常在火山引擎、Trae 等平台均可复现,且不同平台出现频率差异明显。 "极"字对应的 token 编号是 2577,其前一位正好是省略号"......"的编号 2576 ,这一巧合引发开发者对解码机制故障的猜测。
技术社区进一步分析发现,模型还会输出"extreme""極"等变体,这些 token 编号无直接关联却被优先选择。知乎用户@hzwer 指出,早期版本 DeepSeek R1 就存在过度使用"极"字的问题,疑似将之作为语义锚点。
Reddit 用户则发现模型偶尔会输出"极速赛车开奖直播"等异常词组,暗示训练数据可能存在污染。
目前推测是多重因素导致:训练数据污染、分词概率偏移、平台部署差异共同作用,形成这种概率性故障。由于该问题会影响代码生成等严肃场景,开发者呼吁官方尽快修复。 "你也不知道它下一次是不是又要突然"极"你一下" ,这种不确定性让用户对模型的可靠性产生担忧。事件暴露出大语言模型在 token 处理机制上仍需完善。
英伟达发布 Jet-Nemotron 小模型
近日, 英伟达 发布了一个名为 Jet-Nemotron 的全新语言模型系列,包含 Jet-Nemotron-2B 和 Jet-Nemotron-4B 两个版本。这个系列的最大特点是模型体积小但性能强劲,在多项基准测试中超越了当前主流的小型语言模型,同时在 H100 GPU 上的生成吞吐量最高提升了 53.6 倍。 Jet-Nemotron 采用了创新的混合架构,核心包含两项技术突破。第一项是 PostNAS (后神经网络架构搜索),这是一种高效的训练后架构探索方法。与传统的从头训练新架构不同,PostNAS 基于已经预训练好的 Transformer 模型进行改进,通过搜索最优的注意力块设计和超参数配置,显著降低了开发新架构的成本和风险。
第二项创新是 JetBlock ,这是一种新型的线性注意力模块。它将动态卷积与硬件感知架构搜索相结合,在保持与先前设计相似的训练和推理吞吐量的同时,实现了显著的准确率提升。实验显示,JetBlock 在相同的训练数据和方案下,性能超越了之前的 Mamba 2 模块。
在性能表现方面, Jet-Nemotron-4B 在 MMLU-pro、数学、检索、常识推理、代码生成和长上下文处理等六个维度都表现出色,堪称"六边形战士"。特别是在长上下文场景中,随着上下文长度的增加,Jet-Nemotron 相对于其他模型的优势更加明显,解码速度最高可提升 50 倍。
这是英伟达近期在小模型领域的又一次重要发布。上周他们刚刚推出了 NVIDIA Nemotron Nano 2(9B 参数)模型,在复杂推理测试中达到了与 Qwen3-8B 相当或更优的准确率,同时吞吐量最高提升 6 倍。而这次的 Jet-Nemotron 系列将模型体积进一步缩小到 2B 和 4B,显示出英伟达在小模型优化方面的持续投入和技术积累。
微软推出 Agent Lightning 框架:让 AI 智能体无需修改代码即可进行强化学习训练
微软研究院最近发布了一个名为 Agent Lightning 的创新框架,这个框架能够让任何人工智能智能体通过强化学习进行训练,而且几乎不需要修改现有代码。这项技术的突破性在于,它首次实现了智能体执行与强化学习训练过程的完全分离。
传统的 AI 智能体训练方法存在一个很大的问题:训练系统必须与智能体的内部逻辑紧密耦合。这意味着开发者需要在训练系统内部重新构建或大幅改造他们的智能体,这个过程既费时又容易出错。 Agent Lightning 通过创新的"训练-智能体解聚合"架构解决了这个问题。该架构包含两个核心组件:Lightning 服务器和 Lightning 客户端。服务器负责管理整个训练流程和模型参数更新,而客户端则独立运行智能体的具体应用逻辑和数据收集。
这个框架的工作原理基于 马尔可夫决策过程(MDP) 的理论模型。在这个模型中,智能体执行的每个瞬间都被定义为"状态",策略大语言模型生成的输出被视为"动作",而任务完成后的结果被量化为"奖励"信号。Agent Lightning 设计了一个统一的数据接口,能够将任何智能体的执行轨迹都表示为一系列(状态,动作,奖励)的转换序列,从而简化了数据建模过程。
为了验证框架的实际效果,研究团队在三个不同类型的任务上进行了测试。第一个是使用 LangChain 框架构建的文本到 SQL 智能体,需要在复杂的 Spider 数据集上根据自然语言问题生成可执行的 SQL 查询。第二个是利用 OpenAI Agents SDK 实现的 检索增强生成智能体,需要从包含 2100 万份文档的维基百科中检索信息来回答多跳推理问题。第三个是通过 AutoGen 框架开发的数学问答智能体,需要学会如何调用计算器工具来解决数学问题。
实验结果显示,在所有这三个场景中,经过 Agent Lightning 训练的模型性能都获得了稳定且持续的提升。这些成功案例证明了该框架作为一个通用优化方案的强大潜力,能够帮助 AI 智能体更好地解决开放和动态的现实世界问题,而无需开发者进行繁琐的代码修改工作。
面壁智能发布 MiniCPM-V 4.5:8B 参数端侧模型实现高刷视频理解
面壁智能最新开源的 MiniCPM-V 4.5 多模态端侧模型以 8B 参数量刷新性能上限。 "在同等视觉 token 开销下,可处理 6 倍的视频帧数" ,其 3D-Resampler 技术将传统 2D 结构拓展为三维压缩,显著提升高刷视频的细节捕捉能力。实测中,该模型对 3 秒内闪现的四张纸文字识别准确率完胜 Gemini 2.5 Pro,后者仅能识别部分内容。
在车机导航等实际场景中,MiniCPM-V 4.5 展现出快速响应优势。例如识别路边饮品店时,模型秒级反馈 CoCo 门店位置,而 OCR 任务中连手写潦草文字也能精准解析。 "尺寸小 ≠ 端侧模型" ,其关键突破在于通过混合推理模式平衡深度分析与实时性,显存占用仅为同级模型的 1/10。
技术层面,模型创新融合了 OCR 与知识学习:通过动态调整文字框噪音强度,使模型在信息模糊时自动切换至上下文推理模式。这一设计解决了传统文档解析工具的错误累积问题。目前模型已在 Github 等平台开源,为 具身智能、实时交互等场景提供轻量化解决方案。
👏大家好,这里是 Memene 摸鱼日报,致力于为您带来每日AI领域的资讯八卦,让你在上班摸鱼的同时只需多花那么几分钟便可以快速了解 AI 领域的资讯新闻。
我们是一家位于杭州的AI创业团队。以上是我们还在测试的产品的 Memene 的生成效果内容。因为希望得到社区朋友们的反馈,于是我们来掘金社区发布了我们的 Memene 摸鱼日报专栏。
🥳如果您有什么意见,还请在评论区与我们反馈。我们非常期望能够得到大家的真实反馈。
以上内容基于 人工智能前瞻报 Meme 与 学AI技术,懂? Meme 再生成。如果您有兴趣🥰可以点击前边链接查看全部内容。或者来试试订阅。