一、Shell 脚本基础
-
本质:纯文本文件(通常以 .sh 为后缀,便于识别),内容是一系列 Shell 命令的集合。
-
核心作用:
-
自动化执行重复性工作(如批量创建用户、定时备份),减少人工操作;
-
整合复杂命令流程(如配置环境、部署应用),降低操作门槛;
-
实现系统管理任务的标准化(如统一 yum 源配置、服务启停)。
-
-
运行依赖:依赖 Shell 解释器(如 bash,Linux 系统默认解释器),脚本首行需指定解释器(#!/bin/bash)
(一)输出命令
输出命令用于将内容打印到终端或文件,核心包括echo 和 Here Document(多行输出)。
1、 echo 命令
echo 是最常用的输出命令,支持单引号、双引号和无引号,核心区别在于特殊字符是否转义:
| 引号类型 | 特殊字符处理 | 示例 | 输出结果 |
|---|---|---|---|
| 单引号 | 完全取消转义(所有字符按原样输出) | echo '当前目录: $PWD' | 当前目录: $PWD |
| 双引号 | 保留特殊字符含义(如变量 $、命令 $( )) |
echo "当前目录: $PWD" | 当前目录: /root(取决于实际目录) |
| 无引号 | 支持变量转义,但不支持空格(空格会被解析为命令分隔符) | echo 当前目录: $PWD | 当前目录: /root |

2、Here Document(多行输出)
用于一次性输出多行内容,避免重复使用 echo。
语法格式:

- 规则:终止符前后不能有空格(否则无法识别);常用 eof(End Of File)作为终止符,也可自定义(如 end )。


(三)重定向符号
Linux 命令执行时,内核会默认打开 3 个标准文件描述符(0、1、2),其设计基于 "一切皆文件" 理念 ------ 键盘、屏幕等设备均被抽象为文件,文件描述符则是内核分配的整数编号,用于简化文件读写(无需记路径,仅通过编号调用)
这 3 个描述符分别对应命令的输入源与输出目的地,保障命令能正常接收输入、输出结果,也是重定向(改变输入 / 输出来源)的核心依赖。
| 文件描述符 | 名称 | 作用 | 默认设备 |
|---|---|---|---|
| 0 | 标准输入(stdin) | 接收命令输入 | 键盘 |
| 1 | 标准输出(stdout) | 输出命令正常结果 | 终端(屏幕) |
| 2 | 标准错误输出(stderr) | 输出命令错误信息 | 终端(屏幕) |
1、输出重定向(> 、>> 、2>、&>)
| 符号 | 作用 | 示例 | 说明 |
|---|---|---|---|
| 1> | 覆盖标准输出到文件(1可省略) | ls /etc > /tmp/etc_list.txt | 将 /etc目录列表覆盖写入文件,终端无输出 |
| 1>> | 追加标准输出到文件(1可省略) | echo "new line" >> /tmp/etc_list.txt | 在文件末尾追加一行,不覆盖原有内容 |
| 2> | 覆盖标准错误输出到文件 | ls /nonexistent 2> /tmp/error.log | 将 "目录不存在" 的错误信息写入日志文件 |
| &> | 覆盖所有输出(stdout + stderr)到文件 | yum update &> /tmp/yum_update.log | 将 yum 更新的所有信息(正常 + 错误)写入日志 |
| >/dev/null | 丢弃输出(黑洞设备) | ntpdate 120.25.108.11 > /dev/null | 执行命令但不显示任何输出(常用于定时任务) |
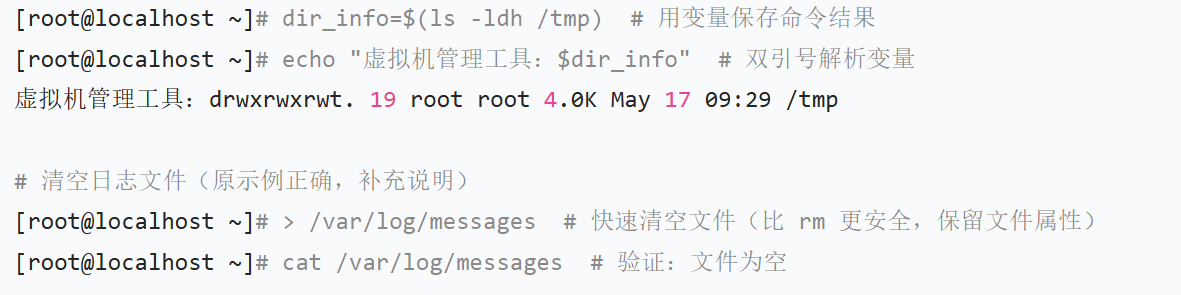
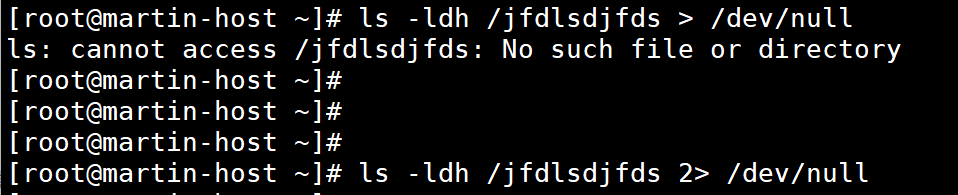
2、输入重定向(<、<<)
| 符号 | 作用 | 示例 | 说明 |
|---|---|---|---|
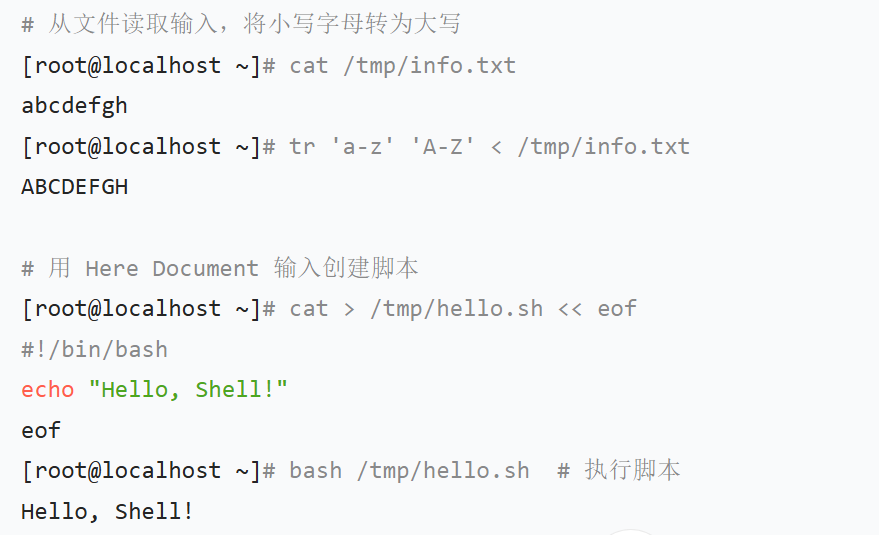
| < | 从文件读取标准输入 | tr 'a-z' 'A-Z' < /tmp/info.txt | 将文件内容转为大写( tr 命令从文件读输入) |
| << | Here Document 输入(与输出逻辑相反) | cat > /tmp/test.txt << eof\nhello\neof | 从多行输入创建文件(等价于手动输入内容) |
- tr 原字符集 目标字符集 //
- **cat:**基础功能是「拼接并输出文本」,但结合重定向符号 > 时,可实现「创建文件并写入内容」;
- >:输出重定向符号,作用是将 cat 接收的输入内容,覆盖写入到指定文件 /tmp/test.txt(若文件已存在,原内容会被清空;若不存在,会自动创建);
- cat > /tmp/test.txt // 将后续输入的内容,写入到 /tmp/test.txt 文件中。
- << eof\nhello\neof //后续内容直到遇到指定的终止符前,都是要写入文件的内容
1. 标准输入(stdin, FD=0):命令的 "输入来源"
作用: 命令需要 "读数据" 时,默认从 FD=0 读取(比如 read 命令接收用户输入、grep 命令从标准输入过滤内容)。
默认设备: 键盘 ------ 用户通过键盘敲入的内容,会被传递给 FD=0,供命令读取。
实际场景举例:
- read name //读取用户输入并赋值给 name 变量,此时命令会从 FD=0(键盘)等待输入,你敲入 "Alice" 后按回车,"Alice" 就通过 stdin 传给了 read 命令。
- grep "root" < /etc/passwd//通过 < 把 stdin 定向到 /etc/passwd 文件,直接从文件中过滤包含 "root" 的行。
2. 标准输出(stdout, FD=1):命令的 "正常结果出口"
作用: 命令执行成功后,产生的 "有效结果" 会通过 FD=1 输出(比如 ls 列出的目录列表、cat 读取的文件内容、date 显示的当前时间)。
默认设备: 终端(屏幕)------ 正常结果会直接显示在屏幕上,让用户看到。
关键特性: 只有 "成功的、有价值的结果" 会走 stdout,错误信息不会走这里。
实际场景举例:
- ls /etc //执行正确命令。正常结果通过 stdout(FD=1)输出到屏幕,输出 /etc 下的文件
- ls /etc > etc_list.txt //stdout 被定向到 etc_list.txt 文件,屏幕不再显示列表,打开文件就能看到结果;如果用 >>,则会把结果 "追加" 到文件末尾(不会覆盖原有内容)。
3. 标准错误输出(stderr, FD=2):命令的 "错误提示出口"
作用: 命令执行失败或异常时,产生的 "错误信息" 会通过 FD=2 输出(比如 "文件不存在""权限不足""命令不存在" 等提示)。
默认设备: 终端(屏幕)。和 stdout 默认都显示在屏幕上,但两者是完全独立的通道。
关键特性: 错误信息不会混入 stdout,即使 stdout 被重定向到文件,stderr 仍会默认显示在屏幕(除非单独定向 stderr)。
实际场景举例:
- ls /nonexistent //执行错误命令,"ls: 无法访问 '/nonexistent': 没有那个文件或目录" 是错误信息,通过 stderr(FD=2)输出到屏幕。
- ls /nonexistent 2> error.log //stderr 被定向到 error.log 文件,屏幕不再显示错误提示,打开日志文件就能查看错误详情;用 2>> 则追加错误信息到日志。
二、Shell 变量的使用
在 Shell 命令和脚本中,变量的核心作用是存储数据并在需要时重复使用,通过抽象和复用数据,简化命令逻辑、提高灵活性和可维护性,
变量是 Shell 中存储数据的容器,按作用范围分为用户自定义变量 、环境变量 和特殊变量。
(一) 用户自定义变量
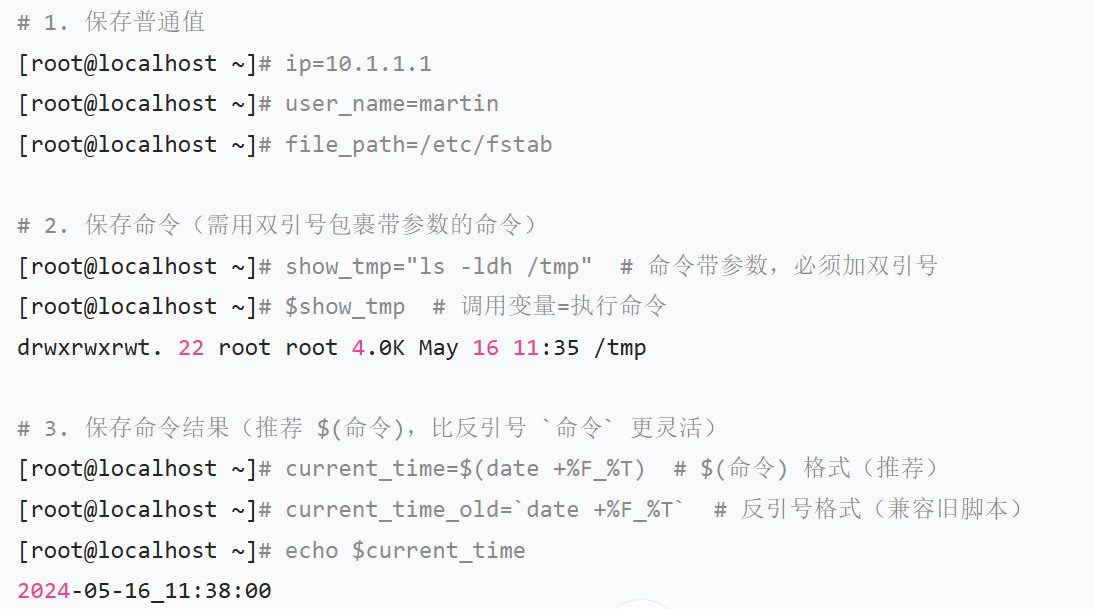
1、变量定义
-
语法:变量名=值(= 前后无空格,否则解析为命令)
-
命名规范:
-
只能包含大小写字母、数字、下划线(_);
-
不能以数字开头(如 123ip 错误,ip123 正确);
-
见名知义(如 user_name 表示用户名,file_path 表示文件路径);
-
避免与 Shell 关键字冲突(如 if、for、then 等)
2、变量调用
- 语法:变量名 或 {变量名},后者用于避免变量名与后续字符混淆。
变量名单独出现 或后面紧跟空格、标点等非字母数字字符 时,$变量名 和 ${变量名} 效果相同
当变量名后紧跟字母、数字或下划线 时,需要用 ${变量名} ,否则 Shell 会误判变量名的范围。

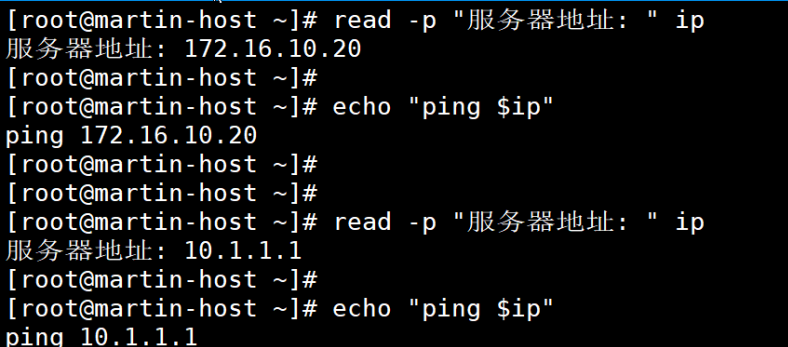
3、交互式定义变量(read 命令补充选项)
read 命令用于从终端接收用户输入,语法:read 选项 变量名,常用选项:
- -p // "提示信息":输入前显示提示;
- -n // N:限制输入字符数(如 -n 6 表示最多输入 6 个字符);
- -s // 隐藏输入(常用于输入密码,避免明文显示)。
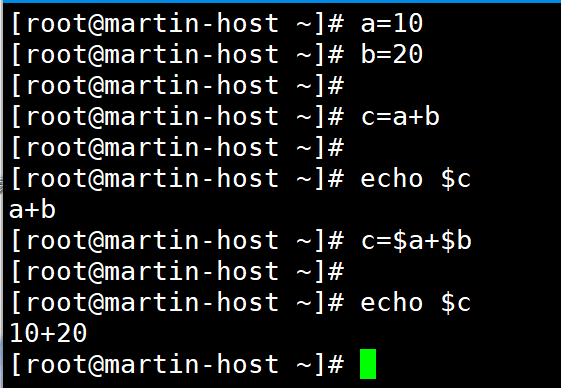
4、变量数学运算(补充运算符与场景)
Shell 变量默认是字符串类型,需通过专用方式实现数学运算,常用三种方式:
| 方法 | 语法 | 示例(计算 10+20) | 支持运算符(+、-、*、/、%) |
|---|---|---|---|
| let 命令 | let 变量=表达式 | let c=10+20 | 支持所有基本运算符 |
| $((表达式)) | $((表达式)) | c=$((10+20)) | 支持所有基本运算符(推荐) |
| expr 命令 | 变量=$(expr 表达式) | c=$(expr 10 + 20) | 运算符前后必须加空格 |

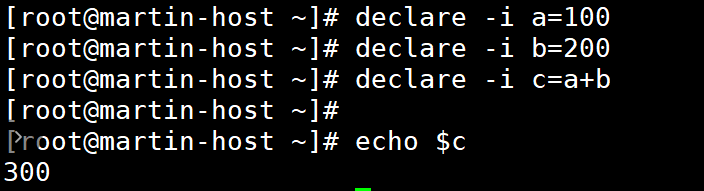
declare -i 是用于声明整数类型变量的命令,其核心作用是强制变量以整数形式参与运算和处理,避免 Shell 默认的字符串类型导致的运算错误。
(二)环境变量
环境变量是全局生效的变量,可被所有子进程(如脚本、新终端)继承,常用于配置系统环境。
1、查看环境变量
- # env//查看所有环境变量
- # echo $PATH //查看指定环境变量(如 PATH:命令搜索路径)
2、定义 / 修改环境变量
-
临时生效:export 变量名=值(仅当前终端有效,关闭终端后失效);
-
若没有则是定义变量,有则是修改变量。变量名大写。
-
永久生效:需写入配置文件(根据用户范围选择),source生效。
| 配置文件 | 生效范围 | 适用场景 |
|---|---|---|
| /etc/profile | 所有用户(全局) | 系统级配置 |
| ~/.bash_profile | 当前用户(局部) | 存放环境变量等全局配置,并通过以下代码引入 .bashrc |
| ~/.bashrc | 当前用户(局部,推荐) | 存放所有交互相关配置(别名、提示符等) |

(三)特殊变量
特殊变量是 Shell 预定义的变量,用于获取命令行参数、进程状态等,常用如下:
| 特殊变量 | 含义 | 示例 |
|---|---|---|
| $? | 获取上一条命令执行后的的退出状态码(Exit Status) | 配合 if 条件判断使用 |
| $0 | 获取当前脚本的文件名 | 脚本内写 echo $0,执行后输出脚本名 |
| 1\~9 | 脚本的第 1~9 个命令行参数 | bash test.sh a b c,1=a,2=b |
| $# | 脚本的命令行参数总数 | 上述示例中 echo $# 输出 3 |
| $* | 所有命令行参数(作为一个整体) | 上述示例中 echo $* 输出 a b c |
Linux 中,任何命令执行结束后都会返回一个 "退出状态码"(0-255 整数)表示命令的执行结果
- 0:表示当命令完全按照预期逻辑执行完毕,没有出现任何错误。
- 非 0:表示命令执行失败(不同非 0 值可能对应不同错误原因,具体含义由命令自身定义)。
| 状态码 | 含义说明 | 典型场景示例 |
|---|---|---|
| 0 | 成功:命令完全按预期执行完毕,无任何错误。 | ls /etc(正确列出目录)、 cp a.txt b.txt(成功复制)。 |
| 1 | 通用错误:命令执行失败(非特定类型错误)。 | grep "关键词" 空文件 |
| 2 | 错误的命令用法:参数错误、选项无效或命令语法错误。 | ls -x(使用不存在的选项)、 mkdir(缺少目录名参数)。 |
| 126 | 无法执行命令:文件存在但无执行权限,或不是可执行文件。 | ./test.sh(脚本无 x 权限)、 /etc/passwd(尝试执行普通文件)。 |
| 127 | 命令未找到:输入的命令不存在(或不在 PATH 路径中)。 | abcdef(输入不存在的命令)、 mysqldump(未安装该工具)。 |
| 128 | 无效的退出参数:exit 命令后接非整数参数 | 脚本中执行 exit "error" |

三、Bash编写流程
(一)前期准备:明确需求与环境
-
需求拆解:
- 明确脚本的核心目标(如 "自动备份数据""检测服务状态""批量创建用户");
- 拆分具体步骤(如 "备份数据" 需拆分为 "判断备份目录是否存在→执行压缩→验证备份结果→记录日志");
- 定义边界条件(如 "备份失败时是否发送告警""用户已存在时是否跳过创建")。
-
环境确认:
- 确定执行脚本的操作系统(如 CentOS、Ubuntu,部分命令路径可能不同,如
servicevssystemctl); - 检查依赖工具是否存在(如脚本需用
mysql命令,需先确认mysql-client是否安装;需用netstat,需确认net-tools包是否存在); - 明确执行权限(脚本是否需要
root权限,如useradd、mount等命令必须 root 执行)。
- 确定执行脚本的操作系统(如 CentOS、Ubuntu,部分命令路径可能不同,如
(二)创建脚本文件并指定解释器
这是脚本的 "基础框架",确保系统能正确识别并执行脚本:
1、创建脚本文件:
用文本编辑器(如 vim、nano)创建以 .sh 为后缀的文件(后缀非强制,但便于识别),例如:
- vim /opt/scripts/backup_data.sh //创建备份脚本
2、指定解释器(Shebang 语法) :
脚本的第一行 指定 Bash 解释器,告诉系统 "用 /bin/bash 执行该脚本"(避免默认解释器差异导致错误)

// 若系统中 Bash 路径不同(如部分 Ubuntu 可能在 /usr/bin/bash),可通过 which bash 查看实际路径,确保语法正确。
3、添加脚本说明(可选但推荐):
在解释器下方添加注释,说明脚本功能、作者、创建时间、用法等,便于后续维护:
#!/bin/bash
# 脚本名称:backup_data.sh
# 核心功能:每天凌晨 3 点备份 /data 目录到 /backup,保留最近 7 天的备份文件
# 执行方式:./backup_data.sh 或添加到 crontab(0 3 * * * /opt/scripts/backup_data.sh)
# 依赖工具:tar(压缩)、date(生成时间戳)、find(清理旧备份)(三)编写核心逻辑(变量、条件、循环等)
根据需求拆解的步骤,用 Bash 语法实现核心逻辑,需注意语法规范和可读性:
-
定义变量(简化维护) :
将脚本中重复使用的值(如路径、阈值、参数)定义为变量,后续修改只需改变量,无需改逻辑。例如备份脚本中:# 定义变量(建议集中放在脚本开头,便于管理) src_dir="/data" # 待备份的源目录 backup_dir="/backup" # 备份文件存放目录 keep_days=7 # 备份文件保留天数 backup_file="data_$(date +%Y%m%d_%H%M%S).tar.gz" # 备份文件名(带时间戳) -
实现核心步骤(按需求拆解) :
用 Bash 语法(条件判断、循环、命令执行等)逐步实现功能,每个步骤可添加注释说明。 -
处理异常场景(提升健壮性):
避免 "假设一切顺利",需考虑异常情况(如目录不存在、权限不足、命令执行失败),通过 if 判断、exit 退出等方式处理,例如:
- 执行 useradd 前先判断用户是否存在;
- 执行 cp 后用 $? 验证是否复制成功;
- 关键命令失败时输出错误信息并退出,避免后续步骤无效执行。
(四)添加执行权限
Bash 脚本默认是 "文本文件",需赋予 "执行权限" 才能运行,通过 chmod 命令设置:
# 给脚本添加执行权限(所有者可执行,其他用户只读,避免安全风险)
chmod 744 /opt/scripts/backup_data.sh
# 或简化为"所有者可读写执行,组和其他用户可执行"(适合内部脚本)
chmod +x /opt/scripts/backup_data.sh- 权限说明:744 中,7(所有者:读 r=4 + 写 w=2 + 执行 x=1),
4(组和其他:仅读); - 若脚本需 root 执行,需确保用 sudo 或 root 用户运行。
(五)测试脚本(关键环节,避免线上故障)
脚本编写完成后,必须先测试,验证功能是否符合预期、是否存在语法错误或逻辑漏洞。
语法检查(快速排查错误) :
用 bash -n 脚本路径 检查脚本是否有语法错误,无输出表示语法正常:
bash -n /opt/scripts/backup_data.sh若有语法错误,会提示具体行号(如 line 15: syntax error near unexpected token 'fi')需定位修复。
执行测试(模拟实际场景):
首次测试建议用 "调试模式" 运行,查看脚本执行过程(每一步的命令和变量值),便于定位问题:
bash -x /opt/scripts/backup_data.sh # -x 开启调试模式,输出详细执行过程验证结果:检查备份文件是否生成、过期文件是否清理、日志是否正确输出(若脚本有日志功能);边界测试:模拟异常场景(如删除源目录后执行脚本,看是否提示错误;手动创建重复用户,看是否跳过)。
优化调整 :
根据测试结果修改脚本,例如:
若备份文件过大,可添加 tar 压缩参数(如 -z 用 gzip 压缩,-j 用 bzip2 压缩);
若输出信息杂乱,可添加日志功能(将输出重定向到日志文件,如 echo "备份成功" >> /var/log/backup.log);
若需定时执行,可添加到 crontab(如 crontab -e 中添加 0 3 * * * /opt/scripts/backup_data.sh,每天凌晨 3 点执行)。
(六)上线与维护
脚本测试通过后,即可上线使用,并定期维护:
上线部署:
将脚本放到固定目录(如 /opt/scripts),避免随意移动(若移动,需同步修改 crontab 或其他调用路径);
告知使用人员脚本的用法、参数(若有)和注意事项(如 "执行前需确认源目录权限")。
日常维护:
定期查看脚本执行日志(若有),确认是否正常运行(如备份脚本是否每天生成文件);
环境变化时同步更新脚本(如源目录迁移,需修改脚本中的 src_dir 变量);
优化性能(如批量处理脚本用 for 循环替代多次重复命令,减少系统开销)。
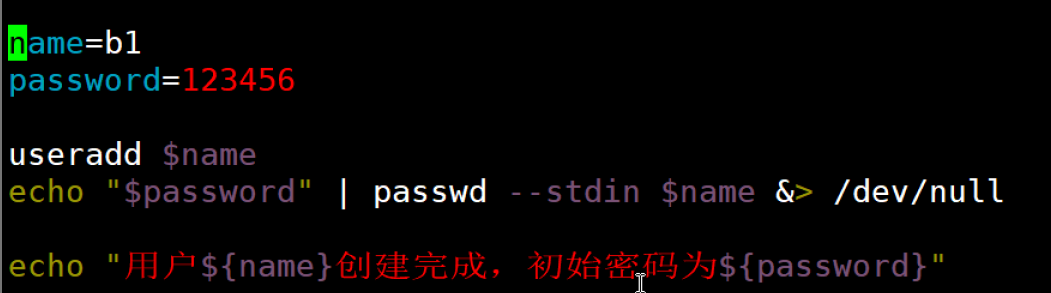
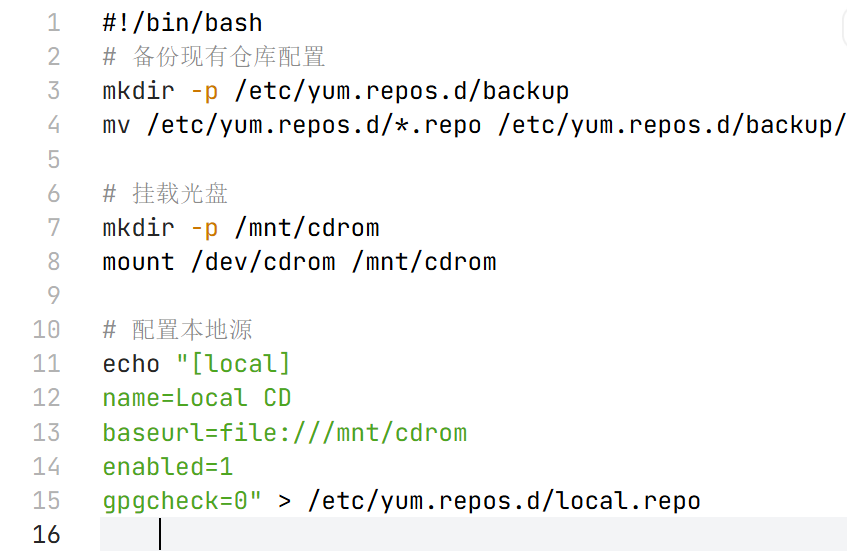
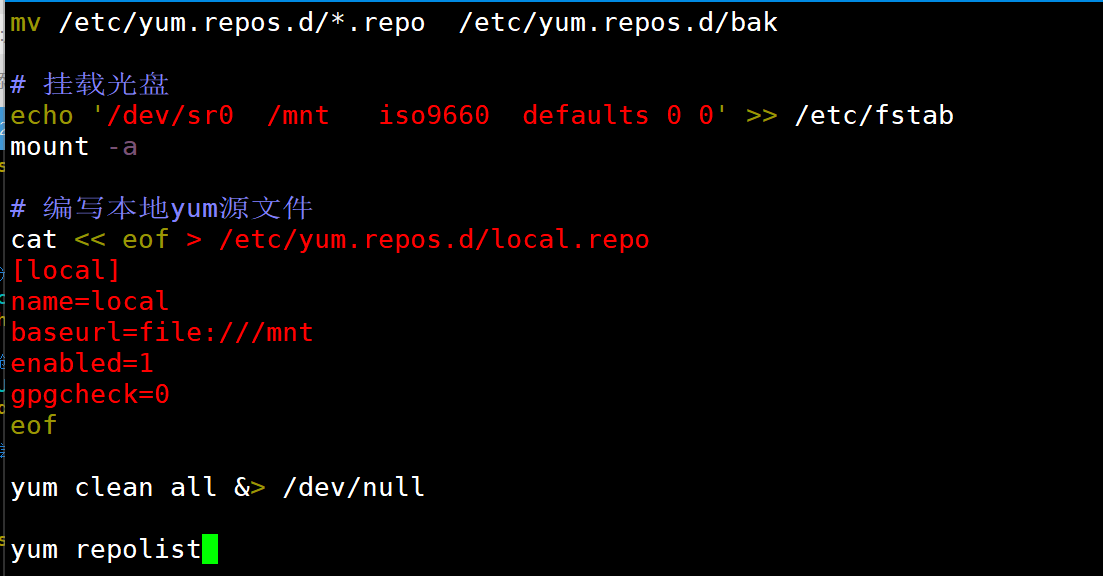
练习1:
- 备份所有.repo 文件到 backup 目录
- 挂载光盘到 /mnt/cdrom
- 创建本地源配置文件
-
mv是移动文件,会把原来的.repo文件从/etc/yum.repos.d/目录移走,这样系统就不会再识别这些仓库配置了
-
如果用cp只是复制备份,原来的仓库配置仍然存在,系统可能会优先使用网络仓库而不是我们配置的本地源