docker镜像和container镜像为什么不能直接共通
Docker 镜像和 containerd 镜像本质上格式兼容(都遵循 OCI 镜像规范),但默认情况下 "不能互相识别",核心原因是存储位置、命名空间和工具链的隔离,而非镜像格式本身的差异。具体来说:
一、核心原因:存储与工具链的隔离
1. 镜像存储位置不同
Docker 和 containerd 会将镜像存储在各自独立的目录中,默认情况下不会共享存储:
Docker:镜像存储在 /var/lib/docker/overlay2(或 /var/lib/docker/image),由 Docker 自身的存储驱动(如 overlay2)管理。
containerd:镜像存储在 /var/lib/containerd/io.containerd.content.v1.content,由 containerd 的存储系统管理。
即使是同一个镜像(如 nginx:latest),Docker 拉取后会存在于 Docker 的存储目录,containerd 拉取后会存在于 containerd 的存储目录,两者互不可见。
2. containerd 的 "命名空间" 隔离
containerd 引入了内部命名空间(namespace) 机制,用于隔离不同场景的镜像 / 容器(类似 K8s 的命名空间,但作用于 containerd 内部):
默认情况下,Docker 镜像对应的 containerd 命名空间是 moby(Docker 专属)。
K8s 中使用的 containerd 命名空间是 k8s.io(K8s 专属)。
crictl(K8s 配套的容器工具)默认只查询 k8s.io 命名空间的镜像,而 Docker 拉取的镜像在 moby 命名空间,因此 crictl 看不到 Docker 镜像。
3. 工具链的 "视角" 不同
Docker 和 containerd 的命令行工具(docker、crictl、nerdctl)默认只访问自己管理的存储和命名空间:
docker images 只会显示 Docker 存储目录 + moby 命名空间的镜像。
crictl images 只会显示 containerd 存储目录 + k8s.io 命名空间的镜像。
即使是同一个镜像,只要不在工具默认的 "存储 + 命名空间" 范围内,就无法被识别。
具体操作
说明之后,实际上镜像是可以直接识别的,问题主要是存储路径和命名空间的问题,我们只需要注意下这两个问题就行,并且操作起来很简单。
首先查看docker镜像
shell
docker images
把其中docker.1ms.run/tensorflow/tensorflow:1.15.5-gpu-py3这个docker镜像改成container镜像
先导出成tar包
shell
sudo docker save -o tensorflow-gpu.tar docker.1ms.run/tensorflow/tensorflow:1.15.5-gpu-py3然后使用ctr命令指定命名空间导入
shell
sudo ctr -n k8s.io images import tensorflow-gpu.tar导入成功后的提示

最后通过crictl查看被k8s识别到的镜像
shell
crictl images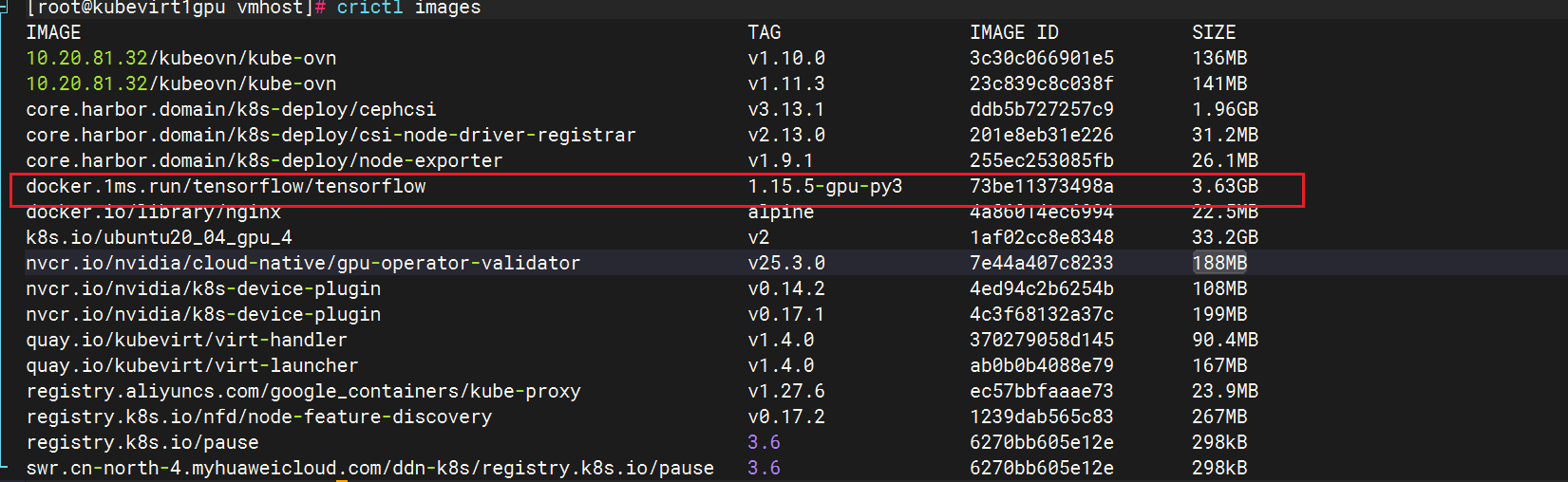
这样就完成了镜像的使用,很简单