点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到:
Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

主键策略
在很多小项目中,我们往往直接使用数据库自增特性来生成主键ID,这样确实比较简单,而在分库分表的环境中,不能再借助数据库自增长特性直接生成,否则会造成不同数据表主键重复。
UUID(通用唯一识别码)
基本概念
UUID(Universally Unique Identifier)是一种128位(16字节)的数字标识符,用于在分布式系统中唯一地标识信息。其标准格式由32个十六进制数字组成,以连字符"-"分隔为5组,呈现为8-4-4-4-12的形式,总长度为36个字符(例如:550e8400-e29b-41d4-a716-446655440000)。
生成机制
UUID的生成通常结合多种系统信息以确保唯一性:
- 网络硬件信息(如MAC地址)
- 高精度时间戳(纳秒级)
- 硬件芯片ID
- 随机数生成器
- 命名空间(在特定版本中)
常见的版本包括:
- Version 1:基于时间戳和MAC地址
- Version 4:基于随机数生成
- Version 5:基于命名空间和散列值
数据库应用特点
优势
- 分布式生成:无需中央服务器协调,各节点可独立生成
- 唯一性保证:在理论上有极低的重复概率(约10^38分之一)
- 无网络开销:本地生成不需要网络请求
- 安全性:不暴露业务信息(相比自增ID)
劣势
- 存储开销:占用16字节,是BIGINT的两倍
- 索引效率:在InnoDB引擎中,由于:
- 无序性导致B+树频繁分裂重组
- 二级索引需要存储完整的主键值
- 增大了内存占用和IO操作
- 可读性差:人类难以直观记忆和识别
InnoDB引擎下的特殊影响
-
聚集索引问题:InnoDB使用主键作为聚簇索引,UUID的无序插入会导致:
- 页分裂频率增加
- 数据存储碎片化
- 缓存命中率下降
-
二级索引膨胀:每个二级索引都包含主键值,16字节的UUID会导致:
- 索引文件体积增大
- 内存缓冲池能缓存的索引数量减少
- 范围查询时需要加载更多数据页
优化方案
对于必须使用UUID的场景:
- 使用有序UUID变种(如COMB UUID)
- 将UUID转换为二进制(16)存储
- 建立自增ID作为聚簇索引,用UUID作为业务键
- 考虑使用UUID的短哈希版本(需评估碰撞概率)
应用场景推荐
适合使用UUID的情况:
- 需要离线生成的分布式系统
- 需要提前知道主键值的业务
- 需要隐藏数据规模的场景
- 多系统数据合并的场景
COMB(UUID变种)详解
基本概念
COMB(combine)型是数据库领域特有的一种设计思想,它是一种改进型的GUID/UUID实现方式。这种设计通过将传统GUID/UUID与系统时间信息进行组合,显著提升了数据库索引和检索性能。
技术背景
在标准数据库中并不存在原生的COMB数据类型,这个概念最早由Jimmy Nilsson在其技术文章《The Cost of GUIDs as Primary Keys》中提出并详细阐述。该文章深入分析了传统GUID作为主键的性能问题及其解决方案。
设计原理
COMB的设计基于以下技术考量:
- 传统GUID/UUID是完全随机的128位标识符
- 这种随机性导致数据库索引出现严重的碎片化问题
- 数据插入时的随机分布导致索引效率低下,影响系统整体性能
具体实现方案
COMB采用分段组合的方式重构GUID:
- 保留部分:保持GUID前10个字节(80位)不变,确保唯一性
- 时间部分 :使用后6个字节(48位)存储GUID生成的时间戳(DateTime)
- 精确到毫秒级时间信息
- 时间戳采用大端序存储
性能优势
这种组合方式带来显著优势:
- 保持唯一性:前10个字节仍保证全局唯一
- 增加有序性:时间戳使新生成的ID呈现递增趋势
- 索引优化 :
- 减少索引碎片
- 提高范围查询效率
- 优化数据页填充率
典型应用场景
- 分布式数据库主键设计
- 高并发订单系统
- 需要频繁插入的日志系统
- 大型电商平台的商品ID生成
与其他方案的对比
| 特性 | 标准UUID | COMB |
|---|---|---|
| 唯一性 | 保证 | 保证 |
| 有序性 | 无 | 时间有序 |
| 索引效率 | 低 | 较高 |
| 存储空间 | 16字节 | 16字节 |
| 生成复杂度 | 简单 | 中等 |
实现示例(伪代码)
csharp
Guid GenerateCombGuid()
{
byte[] guidBytes = Guid.NewGuid().ToByteArray();
DateTime now = DateTime.UtcNow;
// 将时间信息写入后6字节
byte[] timeBytes = BitConverter.GetBytes(now.Ticks);
Array.Copy(timeBytes, 0, guidBytes, 10, 6);
return new Guid(guidBytes);
}注意事项
- 时间部分精度需根据业务需求调整
- 在极高并发环境下仍需考虑冲突问题
- 跨时区系统需要统一使用UTC时间
- 6字节时间戳可表示约8925年的时间范围
SnowFlake 分布式ID生成算法
在分布式系统中,我们经常需要一种能够全局唯一且按时间有序的ID生成方案。SnowFlake正是Twitter为解决这一问题而开源的分布式ID生成算法,它生成的ID是一个64位的long型整数。
数据结构解析
SnowFlake的64位ID由以下部分组成:
-
符号位(1bit):始终为0,保证生成的ID为正数
-
时间戳部分(41bit):
- 记录生成ID的时间戳(毫秒级)
- 41位可以表示的时间跨度约为69年(2^41/1000/60/60/24/365)
- 通常从系统上线时间开始计算,例如2020-01-01 00:00:00
-
工作机器ID(10bit):
- 高5位表示数据中心ID(最大支持32个数据中心)
- 低5位表示机器ID(每个数据中心最大支持32台机器)
- 这种设计可以支持最多1024台机器(32*32)
-
序列号(12bit):
- 同一毫秒内产生的不同ID的序列号
- 12位支持每个节点每毫秒产生4096个ID(2^12)
工作流程
- 当收到ID生成请求时,首先获取当前时间戳
- 如果当前时间戳小于上次生成ID的时间戳,说明系统时钟回拨,需要抛出异常
- 如果是同一毫秒内的请求,则递增序列号
- 如果序列号溢出,则等待至下一毫秒
- 最后将各部分数值通过位运算拼接成最终的64位ID
应用场景
- 分布式系统:作为全局唯一的事务ID
- 数据库主键:替代自增ID,避免分库分表时的ID冲突
- 消息队列:作为消息的唯一标识
- 日志追踪:作为请求链路的追踪ID
优势与限制
优势:
- ID自增趋势,利于数据库索引
- 不依赖第三方服务,本地生成
- 高性能,单机每秒可生成数百万ID
限制:
- 依赖系统时钟,时钟回拨会导致ID重复
- 工作机器ID需要提前配置,不利于动态扩容
实现示例(伪代码)
java
public class SnowFlake {
private long datacenterId; // 数据中心ID
private long workerId; // 机器ID
private long sequence = 0L; // 序列号
private long lastTimestamp = -1L; // 上次时间戳
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨异常");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - epoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift)
| sequence;
}
}如下图所示:
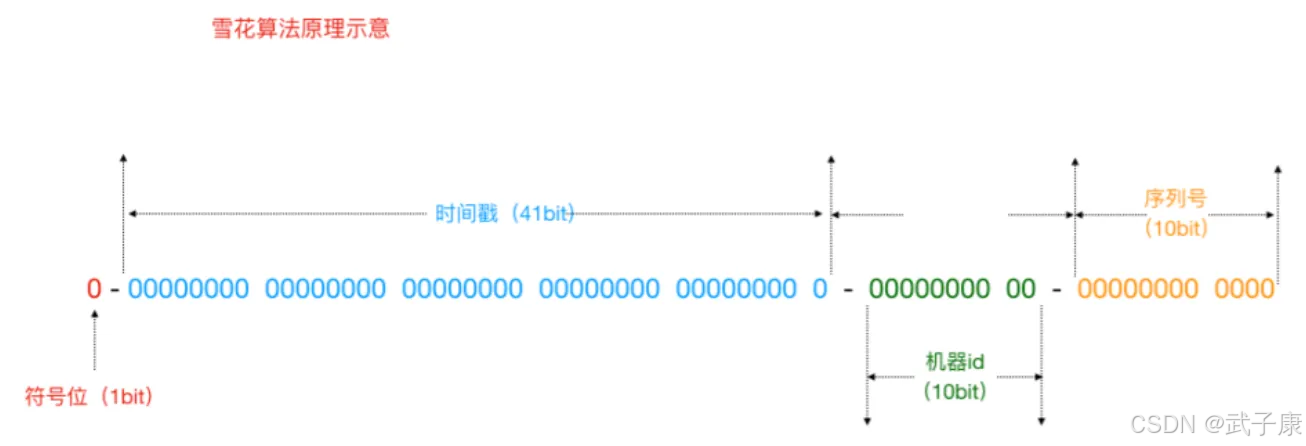
● 符号位:固定位0,二进制表示最高位是符号位,0代表正数,1代表负数
● 时间戳:41个二进制数用来记录时间戳,表示某一个毫秒(毫秒级)
● 机器ID:代表当前算法运行机器的ID
● 序列号:12位,用来记录某个机器同一个毫秒内产生的不同序列号,代表同一个机器同一个毫秒可以产生ID序号
SnowFlake 生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID重复,并且效率较高。经过测试SnowFlake每秒能够产生26万个ID。缺点是强依赖机器时钟,如果多台机器环境时钟没同步,或者时钟回拨,会导致发号重复或者服务会处于不可用的状态,
因此一些互联网公司也基于上述的方案做了封装,例如百度的uidgenerator(基于SnowFlake)和美团leaf(基于数据库和SnowFlake)等。
数据库ID表(分布式ID生成方案)
核心原理
通过独立维护一个专门用于生成全局唯一ID的数据库表,利用MySQL的自增ID特性实现分布式环境下的ID生成。
实现方案详解
-
独立ID库建设
-
单独创建一个MySQL数据库实例(如命名为
id_generator_db) -
在该库中创建专门用于ID生成的表(如
global_id_table) -
表结构设计示例:
sqlCREATE TABLE global_id_table ( id bigint NOT NULL AUTO_INCREMENT, stub char(1) NOT NULL DEFAULT '', PRIMARY KEY (id), UNIQUE KEY stub (stub) ) ENGINE=InnoDB;
-
-
ID生成流程
-
业务系统需要ID时,执行以下SQL:
sqlREPLACE INTO global_id_table (stub) VALUES ('a'); SELECT LAST_INSERT_ID(); -
获取到ID后即可用于业务表的插入操作
-
-
分表场景应用
- 以A表分表为例:
-
先向
global_id_table获取全局ID -
根据分表规则(如ID取模)决定插入A1还是A2表
-
示例代码:
java// 获取全局ID long id = getIdFromGlobalTable(); // 确定分表 String tableName = "A" + (id % 2 + 1); // A1或A2 // 插入业务表 insertIntoTable(tableName, id, ...);
-
- 以A表分表为例:
优化与注意事项
-
性能优化
- 可使用连接池管理ID库连接
- 批量获取ID:通过设置
auto_increment_increment参数批量分配ID段
-
高可用方案
- 部署主从架构,避免单点故障
- 可考虑多机房部署ID生成服务
-
使用限制
- 单库吞吐量有限(约1-2万QPS)
- 跨机房调用可能产生网络延迟
- 需注意自增ID的溢出问题(使用bigint类型)
替代方案对比
当单库性能不足时,可考虑:
- 分库分表:将ID表水平拆分到多个库
- 号段模式:每次获取一个ID范围段
- Snowflake算法:分布式ID生成算法
典型应用场景
- 电商订单系统
- 社交网络中的动态ID生成
- 物流系统的运单编号
- 金融交易流水号生成
通过这种方案,可以在分布式系统中保证ID的全局唯一性,同时维持较好的顺序性,便于分库分表场景下的数据路由。
例如,下面 DISTRIBUTE_ID就我们创建要负责ID生成的表,结构如下:
sql
CREATE TABLE DISTRIBUTE_ID (
id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '主键',
createtime datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;当分布式集群环境中哪个应用需要获取一个全局唯一的分布式ID的时候,就可以使用代码连接这个数据库实例,执行如下SQL语句即可。
sql
INSERT INTO DISTRIBUE_ID(createtime) VALUES(NOW());
SELECT LAST_INSERT_ID();这里需要注意以下几点:
● createtime字段的设计考量:
- 该字段本身没有实际的业务含义
- 主要目的是为了满足数据库表结构的完整性要求
- 通过插入任意数据来触发数据库的自增ID机制
- 这种设计虽然简单,但可能会造成数据冗余
● 使用独立MySQL实例生成分布式ID的局限性:
- 性能问题:
- 每次获取ID都需要建立数据库连接
- 高并发场景下会成为系统瓶颈
- 网络延迟会影响ID获取速度
- 无法满足毫秒级的ID生成需求
- 可靠性问题:
- 存在单点故障风险
- MySQL服务宕机会导致整个系统无法获取ID
- 数据库维护期间无法提供服务
- 网络分区时可能无法连接
- 扩展性问题:
- 难以应对业务量快速增长
- 垂直扩展有上限
- 水平扩展实现复杂
- 无法实现无缝扩容
- 其他问题:
- 增加了系统复杂度
- 需要维护额外的数据库连接池
- 跨机房部署困难
- ID生成效率受限于数据库性能
建议考虑更专业的分布式ID生成方案,如雪花算法、UUID等,这些方案在性能和可靠性方面都有更好的表现。
Redis生成ID
背景与需求
在分布式系统中,生成全局唯一ID是一个常见的需求。传统的数据库自增ID在并发量大的场景下可能面临性能瓶颈,因为:
- 数据库生成ID需要磁盘I/O操作
- 高并发时容易产生锁竞争
- 扩展性较差
Redis解决方案的优势
Redis作为内存数据库,具有以下特点使其适合生成ID:
- 单线程模型保证原子性操作
- 高性能(10万+ QPS)
- 支持持久化,保证数据安全
实现方式
1. 基础INCR命令
redis
INCR id_counter- 每次执行自动将键值加1
- 返回新的整数值作为ID
- 示例:第一次调用返回1,第二次返回2
2. 批量生成ID(INCRBY)
redis
INCRBY id_counter 1000- 一次性获取一段ID范围
- 适合批量操作的场景
- 服务端缓存这部分ID本地分配
3. 时间戳组合模式
redis
INCR daily_counter- 生成格式:年月日(8位) + 自增序列(6位)
- 例如:20230515-000001
- 每天自动重置计数器
应用场景
- 订单系统:生成唯一订单号
- 日志系统:为每条日志标记唯一ID
- 分布式锁:基于ID实现锁机制
- 消息队列:消息的唯一标识
注意事项
- 需要设置适当的持久化策略(AOF或RDB)
- 集群环境下建议使用固定节点生成ID
- 可配合Lua脚本实现更复杂的ID生成逻辑
- 初始化时需要设置合适的初始值
性能对比
| 方案 | QPS | 优点 | 缺点 |
|---|---|---|---|
| 数据库自增ID | 1k-5k | 简单可靠 | 性能受限 |
| Redis INCR | 50k+ | 高性能,原子性 | 需要维护Redis服务 |
| UUID | 100k+ | 无需中心节点 | ID较长,无序 |
通过合理使用Redis生成ID,可以在分布式系统中获得高性能的唯一ID生成方案。
也可以使用Redis集群来获取更高的吞吐量,假设一个集群中有5台Redis,可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5,那么:
shell
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25